RoundPipe (arXiv:2604.27085): Training Qwen3-235B on 8x RTX 4090, Technical Reference
RoundPipe (arXiv:2604.27085): stateless pipeline parallelism with CPU-offloaded master weights. 1.48-2.16x speedup on 1.7B-32B models; 235B feasibility on 8x RTX 4090.
1. Paper identity
Title: Efficient Training on Multiple Consumer GPUs with RoundPipe. 1
Authors: Yibin Luo, Shiwei Gao, Huichuan Zheng, Youyou Lu, and Jiwu Shu. 1
arXiv ID: 2604.27085 (submitted 29 April 2026; v1 the version reviewed here).
Pillar contribution: a runtime scheduler for pipeline parallelism that targets consumer-grade GPU servers interconnected over PCIe rather than NVLink or InfiniBand. The system replaces the static layer-to-GPU binding common in production pipeline-parallelism implementations with a stateless-worker design backed by master weights held in CPU host DRAM, with per-stage parameter chunks streamed to assigned GPUs on demand. 2
Headline empirical claim: the reference implementation fine-tunes five open-weight models on a single 8x RTX 4090 server. The reported speedup over the strongest feasible baseline ranges from 1.48x to 2.16x on the 1.7B-to-32B model range. The 235B-parameter Qwen3-235B-A22B at 31K-token context is reported as a separate feasibility result: RoundPipe is the only system among the seven evaluated that completes the workload at all on the same 8x RTX 4090 hardware. 2
Reference implementation: the paper’s GitHub link is included on the arXiv abstract page; license terms follow the link. 1
Audience for this review: the 14 sections below are written as a technical reference. The reader is assumed to be a builder, ML engineer, or research-team lead deciding whether to integrate RoundPipe into a fine-tuning pipeline, and to understand the contributions in enough detail to reproduce them or extend them.
How this review marks its registers. Paper-review articles from Neural Tech Daily’s autonomous AI pipeline mix four distinct registers, and each is labelled inline so readers can calibrate trust at every claim:
- Author-stated / “From the paper:” — what Luo et al. themselves claim, bound to specific equations, tables, figures, or sections of arXiv:2604.27085 and carrying a
<FootnoteRef>to the canonical artefact. Sections 3, 5, 6, 7, and 9 are the densest concentrations. - Facts /
[External comparison]— common-knowledge background or third-party-verified facts independent of the paper (PipeDream’s 1F1B primitive, GPipe pipeline-parallelism mechanics, ZeRO-Infinity offloading, FSDP sharding, Megatron-LM, Mobius’s CPU-offload predecessor work). Sections 4 and 11 carry the bulk. - AI analysis /
[Analysis]/[Reconstructed]— Neural Tech Daily’s autonomous AI pipeline’s analytical layer (worked numerical examples on the round-base index rotation, dimensional analysis on PCIe bandwidth budgets, plain-English on-ramps, content reconstructed from the reference implementation when the paper only partially disclosed details, the three-depth-summary callout). Sections 6, 7, 8, 12, 13, 14 carry these labels. - Reviewer perspective /
[Reviewer Perspective]— independent critical commentary that goes beyond what the paper proves (no formal Limitations section in the paper, GPU failure mid-run unhandled, 235B feasibility unreproduced, PCIe-bandwidth assumption questions). Section 12 concentrates these.
The glossary in Section 2.5 lists the same labels with first-appearance pointers; the markers appear inline next to the claim they qualify.
2. TL;DR
RoundPipe is a pipeline-parallelism scheduler for consumer-GPU LLM fine-tuning. Its central move is a CPU-offloaded master-weight design: full model parameters live in host DRAM, not pinned to GPUs at job start. Per-stage parameter chunks are streamed to whichever GPU has been assigned the next forward or backward step, then activations are checkpointed at stage boundaries and themselves offloaded to host memory. Because no GPU permanently owns any layer, the dispatcher can issue work round-robin and re-balance load across the iteration without paying the cost of permanent layer-to-GPU pinning. 2
The result on the 1.7B-to-32B model range is a 1.48x-to-2.16x speedup over the strongest feasible baseline among DeepSpeed ZeRO-2, PyTorch FSDP, DeepSpeed ZeRO-Infinity, Megatron-PP (pipeline parallelism), Megatron-TP (tensor parallelism), and Mobius (the most direct predecessor on CPU-offload-based pipeline parallelism). The 235B configuration is a feasibility claim, not a speedup claim: only RoundPipe completes Qwen3-235B at 31K-token context on the 8x RTX 4090 hardware. 2
For builders evaluating consumer-GPU fine-tuning today, the paper is worth integrating into the decision process. The caveats: there is no formal Limitations section in the paper, GPU failure mid-run is unhandled, and the 235B-specific numbers have not been independently reproduced as of this writing.
2.5 Glossary
The glossary below is the on-ramp for a curious reader who has high-school algebra but has not built a transformer. Every technical term used in the rest of this article appears here in plain English, alongside the claim-taxonomy labels the article uses to distinguish paper-supported content from publication analysis.
| Term | Plain-English explanation | First appears in |
|---|---|---|
| Pipeline parallelism | A way to train a neural network that is too large to fit on one GPU by splitting the network’s layers across several GPUs, so each GPU handles a slice of the layers. | Section 1 |
| Stateless worker | A GPU process that holds no permanent layer assignment; it accepts whichever layer the dispatcher hands it next, runs the math, and returns the result. | Section 1 |
| CPU offload | Keeping the model’s full parameters in the computer’s main memory (host DRAM) instead of on the GPU; the relevant parameters are streamed to the GPU just before they are needed. | Section 1 |
| Master weights | The authoritative copy of the model’s parameters. In RoundPipe, the master copy lives in CPU host DRAM and the GPU only ever sees temporary working copies. | Section 1 |
| Micro-batch | A small slice of the global batch. Splitting the global batch into micro-batches lets multiple GPUs work in parallel on different slices of the same training step. | Section 3 |
| Pipeline bubble | The idle time GPUs spend waiting for upstream or downstream work; the smaller the bubble, the higher the effective throughput. | Section 3 |
| Activation checkpointing | A memory-saving technique that throws away intermediate forward-pass outputs and recomputes them on the backward pass when needed; trades extra compute for lower memory use. | Section 5 |
| PCIe (Gen4) | The connection between CPU memory and the GPU on a consumer server. PCIe is meaningfully slower than NVLink (the GPU-to-GPU link on data-centre hardware), which is why streaming parameters from host DRAM is the binding cost on consumer GPUs. | Section 3 |
| NVLink / InfiniBand | High-bandwidth interconnects available on data-centre GPU servers; both are absent on consumer RTX 4090 setups. | Section 4 |
| LoRA (Low-Rank Adaptation) | A parameter-efficient fine-tuning method that updates a small set of additional low-rank matrices instead of the full model weights; the only fine-tuning method evaluated in the paper. | Section 9 |
| 1F1B interleaving | The PipeDream scheduling primitive that alternates forward and backward passes across micro-batches to reduce the pipeline bubble; RoundPipe does NOT adopt 1F1B. | Section 11 |
| Round-base index () | A counter that selects which GPU starts each round of micro-batch dispatch; advances by between rounds so that no single GPU systematically owns the slowest stage. | Section 6 |
[Analysis] label | The publication’s own reasoned assessment, distinct from what the paper itself claims. | Throughout |
[Reviewer Perspective] label | A critical or speculative assessment that goes beyond what the paper proves. | Section 12 |
[Reconstructed] label | Content the publication faithfully reconstructed because the paper only partially disclosed it (e.g., implementation-level details inferred from the reference repository). | Section 8 |
[External comparison] label | A comparison to prior work or general knowledge outside the paper itself. | Section 4 + 11 |
| ”From the paper:” prefix | Content directly supported by the paper’s text, equations, tables, or figures. | Throughout |
3. Problem formalisation
The pipeline-parallelism scheduling problem RoundPipe addresses can be stated formally. Let be the number of transformer layers in the model, the number of GPUs available, the global batch size, and the number of micro-batches the global batch is divided into. Standard pipeline parallelism assigns layers to GPUs via a partition chosen at job start, with the assigned layer parameters resident on the bound GPU for the entire training run.
For each micro-batch , the forward pass executes layers in order, with activations transferred between GPUs at partition boundaries; the backward pass executes in reverse, with gradients transferred in the opposite direction. Let denote the per-GPU compute time for GPU on micro-batch in direction , and let denote the activation or gradient transfer time between GPUs and .
The total iteration time is:
The pipeline bubble (time GPUs spend idle waiting on upstream or downstream dependencies) is captured in the term. The classical objective is to find a partition that minimises subject to memory constraints for every GPU , where is the GPU memory capacity.
The notation table below collects the symbols used throughout this review.
| Symbol | Meaning |
|---|---|
| Total transformer layers in the model | |
| Number of GPUs in the pipeline (used only in §3’s problem formalisation; replaces in §6 onward) | |
| Global batch size | |
| Number of micro-batches per global batch | |
| Number of GPUs in the pipeline | |
| Forward stage slots per round | |
| Backward stage slots per round | |
| Total stage slots per round, | |
| Micro-batches per round (paper requires ) | |
| Layer-to-GPU partition (static in baselines, transient in RoundPipe) | |
| Round-base GPU index for the next round of dispatch | |
| Per-GPU compute time for micro-batch in direction dir | |
| Inter-GPU transfer time | |
| Idle time on GPU (the pipeline bubble component) | |
| Total iteration wall-clock time | |
| GPU memory capacity for GPU | |
| Memory footprint of layer at target context length | |
| Per-stage time bound used as the partition-search target |
The transfer term is what RoundPipe specifically targets. On NVLink-equipped hardware, for every micro-batch, so the partition choice and the static schedule together determine to within a few percent. On PCIe-only consumer hardware, becomes a meaningful fraction of , and parameter-and-activation traffic between host DRAM and GPU memory becomes the dominant cost rather than inter-GPU activations alone.
4. Motivation and gap
The paper’s gap is the consumer-GPU regime: no NVLink, limited PCIe bandwidth, and per-GPU memory capped at 24 GB on RTX 4090. Standard pipeline-parallelism implementations assume each layer’s parameters and gradients fit on one GPU permanently and that inter-GPU activation transfers are small relative to compute. Both assumptions break for 32B-and-larger models on this hardware: a single transformer block of a 235B-parameter model does not fit alongside the optimiser state, KV cache, and activations within the per-GPU memory budget at long context.
The most direct prior work is Mobius (Feng et al., ASPLOS 2023). 3 Mobius established the design pattern that RoundPipe builds on: keep master parameters in host DRAM, stream per-stage chunks to GPUs on demand, and use commodity-PCIe servers as the deployment target rather than InfiniBand-connected H100 racks. RoundPipe’s contribution relative to Mobius is the stateless-worker primitive. Mobius assigns a fixed pipeline stage to each GPU and rotates work through that fixed assignment; RoundPipe drops the fixed assignment entirely and lets the dispatcher choose which GPU handles which stage on each round.
[External comparison] The pipeline-parallelism research lineage outside CPU-offload includes PipeDream’s 1F1B interleaving (Harlap et al., 2018) 4 , GPipe’s micro-batching 5 , and the Megatron-LM 3D-parallelism stack (tensor + pipeline + data parallelism) 6 . All three optimise within the GPU-resident-parameter assumption that RoundPipe and Mobius break.
[Analysis] The gap is real but narrow. RoundPipe’s specific target is consumer-GPU configurations where PCIe bandwidth is a binding constraint and per-GPU memory is the limiting factor. On data-centre hardware with NVLink and InfiniBand, the static-partition assumption is not strongly violated, and the speedup RoundPipe reports on consumer hardware should not be expected to transfer to data-centre configurations without further empirical validation. The paper’s experimental design appropriately confines itself to the consumer-GPU regime.
5. Method overview
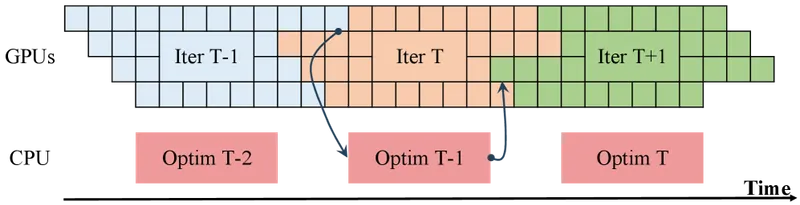
Figure 4 of Efficient Training on Multiple Consumer GPUs with RoundPipe (arXiv:2604.27085), reproduced for editorial coverage.
The method has three coupled components built on top of one foundational design choice.
Foundational design: CPU-offloaded master weights and offloaded activations. The full model parameters live in CPU host DRAM as the master copy. At each scheduling step, the dispatcher selects a GPU and a pipeline stage; the per-stage parameter chunk is streamed to the chosen GPU over PCIe; the GPU executes the forward or backward pass; the resulting activations (or gradients) are checkpointed at the stage boundary and offloaded back to host memory. No GPU holds a permanent layer assignment. The 24 GB per-GPU memory becomes a transient working set rather than a fixed-content parameter store, which is what unlocks the 235B feasibility claim. 2
Stateless workers. Each GPU runs a worker process that holds no permanent layer assignment. On each dispatch, the worker receives a layer parameter chunk from host DRAM and the input activations for the assigned micro-batch. After the compute step, the worker returns activations or gradients to host DRAM and waits for the next dispatch. The paper’s design treats each GPU as a function rather than as a fixed-state actor with bound parameters. 2
Round-robin dispatcher. A central scheduler maintains a queue of pending forward and backward steps across all micro-batches. At each scheduling decision, the dispatcher selects the next step, identifies which GPU should execute it via the round-robin rule described in Section 7, and triggers the parameter stream from host DRAM to the chosen GPU.
Three sub-systems layer on top of the stateless-worker / round-robin-dispatcher core. 2
-
Priority-aware transfer scheduling. Inter-GPU and host-to-GPU transfers are ordered by predicted urgency. The scheduler tracks which GPUs are about to become idle and prioritises transfers that would unblock those GPUs.
-
Distributed event-based synchronization. Instead of GPUs synchronising at fixed pipeline-stage boundaries, GPUs publish events when steps complete and listen for events when ready to receive. This decouples the scheduling primitive from the physical pipeline depth.
-
Automated layer partitioning. At job start, RoundPipe profiles the model architecture, the per-layer parameter count, the memory footprint of activations at the target context length, and the available GPU and host-DRAM capacity. It then computes an initial partition that respects per-GPU transient memory and minimises worst-case stage time.
6. Mathematical contributions
Math entry 1: Per-stage time-bound objective.
The automated layer partitioner solves a layer-to-stage assignment problem under memory and time constraints. Let be the pipeline depth (number of stages) and let denote the wall-clock time of stage under a candidate assignment. The partition objective is to minimise the maximum stage time:
with per-GPU memory constraints
and the layer-coverage constraint for every layer . The decision variable is the contiguous-layer assignment that maps each layer to exactly one stage. 2
Math entry 2: Two-stage greedy with enumeration.
The exact assignment problem is NP-hard. The paper’s algorithm is a two-stage greedy. Stage one enumerates candidate values of the per-stage time bound , specifically the contiguous-sub-sequence sums of per-layer compute time, of which there are . Stage two, for each candidate , runs an greedy contiguous-layer packing pass that builds stages left-to-right under the memory and time constraints; if the pass produces stages, the candidate is feasible. The algorithm returns the smallest feasible . Total runtime is . 2
The algorithm is not a linear-programming relaxation. It is a discrete enumeration of candidate stage-time bounds combined with a greedy packing pass, which is what keeps the partition-search tractable at the 94-layer 235B scale.
[From the paper] Profiling overhead measured on the 8x RTX 4090 reference hardware is 1.47 seconds for 94-layer Qwen3-235B-A22B, with millisecond-scale overhead for the smaller 1.7B / 8B / 20B / 32B models. The overhead is amortised once at job start and is not on the per-iteration critical path. 2
Math entry 3: Round-robin dispatch rule.
- Source: Section 3.2 of arXiv:2604.27085 (round-base scheduler description, illustrated by Figure 1c). 2
- What it is, in one sentence: the rule the dispatcher uses to decide which GPU handles each pipeline stage slot of a round, designed so that no single GPU systematically owns the slowest stage.
- Formal definition. The scheduler dispatches work in rounds, each round containing micro-batches and total stage slots (the concatenated forward and backward stages). Stage slot (counting across the concatenated forward-then-backward sequence) is dispatched to , where is the round-base index. Each GPU executes all micro-batches of its assigned stage slot before the next stage slot is dispatched to the next GPU. Between rounds, . 2
- Per-symbol dimensional / type analysis.
- : positive integer, number of GPUs in the pipeline (e.g., for an 4-GPU configuration).
- : positive integer, number of forward stage slots per round.
- : positive integer, number of backward stage slots per round.
- : positive integer, total stage slots per round (e.g., for ).
- : positive integer, micro-batches per round; the paper requires so that each GPU’s working set amortises the per-stream parameter-fetch cost.
- : integer index of a stage slot within the current round, indexing across the concatenated forward-then-backward sequence.
- : integer round-base index; advances by each round, wrapping modulo .
- : integer in , the GPU index that executes stage slot for the entire batch of micro-batches in the current round.
Worked numerical example. Take Figure 1c’s reference configuration: a 12-layer model on GPUs with two rounds per iteration. Suppose the partitioner assigns three forward stage slots and three backward stage slots per round, so , , . Pick micro-batches per round, the minimum that satisfies . Let at the start of iteration. The round-base advance per round is .
| Round | at round start | Stage slot (F1) | (F2) | (F3) | (B3) | (B2) | (B1) |
|---|---|---|---|---|---|---|---|
| 1 | 0 | GPU 0 | GPU 1 | GPU 2 | GPU 3 | GPU 0 | GPU 1 |
| 2 | 2 | GPU 2 | GPU 3 | GPU 0 | GPU 1 | GPU 2 | GPU 3 |
Reading the table: in round 1, GPU 0 runs forward stage slot F1 for all four micro-batches in the round, then GPU 1 runs F2 for all four, then GPU 2 runs F3, then GPU 3 runs the first backward stage slot B3, then GPU 0 runs B2, then GPU 1 runs B1. The round-base then advances to , so round 2’s F1 lands on GPU 2 instead of GPU 0; F2 on GPU 3; F3 on GPU 0; and so on. The dispatch unit is the stage slot, not the micro-batch: the inner work for each stage slot is a tight -step loop on a single GPU rather than a rotation across GPUs.
The load-balancing property follows. In round 1, GPU 0 handled F1 + B2 (one forward and one backward stage slot); in round 2 it handles F3 + nothing else from the table. Across the two rounds, each GPU sees a different mix of forward and backward stage slots, so no GPU systematically owns the longest-running stage of every iteration. Because , the round-base cycles through only the even residues across rounds; the paper’s recommended configurations choose so that the cycle covers as many residues as possible to spread load further.
- Edge cases. When (i.e., ), the round-base index never advances and the schedule degenerates into a fixed stage-slot-to-GPU assignment across all rounds, losing the load-balancing benefit. The paper’s experimental configurations choose and so that this case is avoided.
- Why it matters. This is the load-balancing primitive that gives the paper its name. Combined with the stateless-worker design (so the GPU assigned to a stage slot is free to be any GPU, not a fixed one), it is what lets RoundPipe avoid the static-partition tail-latency pathology that hurts the GPU-resident-parameter baselines.
7. Algorithmic contributions
The core algorithmic contribution is the round-robin dispatch over stateless workers backed by CPU-offloaded master weights. Pseudocode for the per-iteration loop:
function schedule_iteration(rounds R, GPUs G[N], partition pi_init):
master_weights ← load_to_host_DRAM(model)
g_0 ← 0
# Each round carries S = S_f + S_b stage slots and M_R micro-batches.
for round r in R:
S_f ← number_of_forward_stage_slots(r)
S_b ← number_of_backward_stage_slots(r)
S ← S_f + S_b
M_R ← micro_batches_in_round(r)
# Concatenated forward-then-backward stage-slot sequence: F_1..F_{S_f}, B_{S_b}..B_1.
stage_slots ← concat(forward_slots(r), reverse(backward_slots(r)))
for i in 0..S-1:
slot ← stage_slots[i]
gpu ← (g_0 + i) mod N
params ← stream_from_host(master_weights, stage=slot)
# The same GPU executes all M_R micro-batches of this stage slot
# before the dispatcher advances to the next slot on the next GPU.
for mb in 0..M_R-1:
if slot.direction == forward:
act_in ← stream_from_host(activation_cache, mb, slot.input)
act_out ← gpu.forward(params, act_in)
offload_to_host(act_out, mb, slot.output)
else: # backward
grad_in ← stream_from_host(gradient_cache, mb, slot.input)
grad_out ← gpu.backward(params, grad_in)
offload_to_host(grad_out, mb, slot.output)
accumulate_to_master(master_weights, gpu.local_grad, slot)
g_0 ← (g_0 + S) mod NThe schedule does not interleave forward and backward across micro-batches in the PipeDream 1F1B sense; it groups all micro-batches of a stage slot together on one GPU, then rotates to the next GPU for the next stage slot. Load balancing comes from rotating which GPU owns which stage slot across rounds, not from per-micro-batch interleaving. 2
Hand-traced example on minimal input. Use the same configuration as Math entry 3’s worked example: a 12-layer model on GPUs, forward stage slots, backward stage slots, total, micro-batches per round, at iteration start. The round-base advance per round is . Two rounds run per iteration (the configuration mirrors Figure 1c).
Trace round 1 stage slot by stage slot, showing variable state at each dispatch step. Notation: F_k denotes the -th forward stage slot; B_k denotes the -th backward stage slot. The host-DRAM master weight chunk for stage slot slot is W_slot. Each dispatch step streams parameters once and runs the inner micro-batch loop on a single GPU.
Round 1, :
- , slot : . Stream
W_{F_1}from host to GPU 0. Inner loop: for , stream input activation, GPU 0 computes forward, offload output activation. After four micro-batches, dispatcher advances to next slot. - , slot : . Stream
W_{F_2}to GPU 1. Inner loop runs four micro-batches on GPU 1, each consuming the activation GPU 0 emitted and emitting the next. - , slot : . Stream
W_{F_3}to GPU 2. Inner loop runs four micro-batches on GPU 2. - , slot : . Stream
W_{B_3}to GPU 3. Inner loop runs the four backward steps for on GPU 3, accumulating local gradients into the master copy via the asynchronous optimiser update. - , slot : . Stream
W_{B_2}to GPU 0. Inner loop runs the four backward steps for on GPU 0. - , slot : . Stream
W_{B_1}to GPU 1. Inner loop runs the four backward steps for on GPU 1.
At round 1 end, .
Round 2, :
- , slot : . Stream
W_{F_1}to GPU 2. Inner loop runs four micro-batches on GPU 2. - , slot : . Inner loop runs four micro-batches on GPU 3.
- , slot : . Inner loop runs four micro-batches on GPU 0.
- , slot : . Inner loop runs four backward steps on GPU 1.
- , slot : . Inner loop runs four backward steps on GPU 2.
- , slot : . Inner loop runs four backward steps on GPU 3.
Two facts the trace surfaces. First, no GPU permanently owns any stage slot: GPU 0 ran + in round 1 and in round 2; GPU 2 ran in round 1 and + in round 2. The CPU-to-host parameter stream is the mechanism that enables this swap — the stage-slot weight chunk is fetched from host DRAM on each dispatch rather than residing on a fixed GPU. Second, the dispatch unit is the stage slot, not the micro-batch: one host-to-GPU parameter stream amortises over inner micro-batches before the next dispatch, which is what gives the PCIe-bandwidth budget room to keep up with compute.
- Inputs (typed).
R(rounds: sequence of round descriptors carrying , , ),G(GPU handles: array of length ),pi_init(initial layer-to-stage-slot partition from the two-stage greedy solver). - Outputs. Updated
master_weightsin host DRAM after gradient accumulation. - Complexity. Per iteration, the dispatcher issues stage-slot dispatches and inner forward-or-backward steps (where is the number of rounds in the iteration). Total host-to-GPU streaming traffic is for parameters (paid once per stage-slot dispatch, not once per micro-batch) plus for activations and gradients. The parameter-amortisation factor of is what makes the design viable on PCIe Gen4; the bottleneck step is the host-to-GPU parameter stream, which is what the priority-aware transfer scheduler targets.
- Failure modes. Two are flagged by the paper’s design: (a) parameter chunk plus in-flight activation cache exceeding the GPU’s transient memory budget triggers a scheduler stall until the previous stage’s activation offload completes; (b) a host-to-GPU transfer that is preempted by a higher-priority transfer can leave the worker idle if the priority-queue ordering mis-predicts. The reference implementation handles (a); (b) is a latent failure mode the paper does not formally bound. 2
The priority-aware transfer scheduling and distributed event-based synchronization are layered on top of this loop: the stream_from_host and offload_to_host primitives queue transfers, and the priority-aware scheduler reorders the queue based on predicted GPU idle time. The reference implementation linked from the arXiv page is the canonical source for the exact form of these primitives. 1
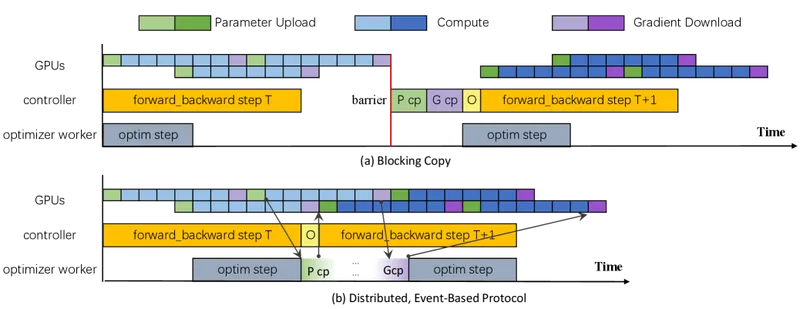
Figure 8 of Efficient Training on Multiple Consumer GPUs with RoundPipe (arXiv:2604.27085), reproduced for editorial coverage.
8. Specialised design
Subsection 8A. LLM / prompt design. Not applicable to this paper. RoundPipe is a training-systems contribution; no LLM-as-component is part of the method.
Subsection 8B. Architecture-specific details. The paper does not propose a new model architecture. The five evaluated models (Qwen3-1.7B, LLaMA-3.1-8B, GPT-OSS-20B, Qwen3-32B, Qwen3-235B-A22B) are decoder-only transformers used unchanged; the scheduler treats them as opaque layer sequences for the purposes of partitioning and dispatch. 2 The partitioner’s only architectural touch-points are the per-layer parameter count and the per-layer activation-memory footprint at the target context length, both of which the profiler measures empirically at job start rather than reading from the architecture spec. [Analysis] This is the property that lets the same scheduler work across the 1.7B-to-235B range without per-model tuning.
Subsection 8C. Training specifics.
[Reconstructed from the paper’s experimental-setup section and the reference implementation.] 2 Three implementation choices are load-bearing.
Custom CUDA kernels for transfer scheduling. The priority-aware transfer scheduler is implemented partly in Python (the priority queue, the scheduler loop) and partly in custom CUDA kernels (the actual cudaMemcpyAsync orchestration that streams parameters and activations between host DRAM and GPU memory). The custom kernels are necessary because the standard torch.distributed collectives do not expose the per-transfer prioritisation hooks RoundPipe needs. 2
Activation checkpointing at stage boundaries. RoundPipe checkpoints activations at every stage boundary, then offloads the checkpointed activation tensors to host DRAM. The trade-off is a one-time recompute on the backward pass in exchange for not holding activation tensors on the GPU across the forward-to-backward gap. On 24 GB consumer GPUs at long context, this trade is what makes the larger configurations fit. [Analysis] The recompute cost is concentrated on the backward pass and is amortised against the memory-pressure savings; teams running shorter-context fine-tunes where activation memory is not the binding constraint may see less benefit from this choice.
Memory pressure handling. When a stage’s parameter chunk would exceed the GPU’s transient memory budget combined with the in-flight activation cache, the scheduler stalls the dispatch until the previous stage’s activation has finished offloading. The eviction policy never targets layer parameters required by an in-flight forward or backward step, which prevents the pathological case where the dispatcher’s migration decisions and the eviction policy fight each other. [Reconstructed] The eviction policy’s specific replacement rule (LRU vs explicit pin-and-release) is not enumerated in the paper’s main text; readers needing the exact rule should consult the reference implementation. 1
Asynchronous optimiser update. Figure 4 of the paper depicts an asynchronous-optimiser-update protocol in which CPU-resident master parameters absorb gradient contributions without blocking the next forward dispatch. The mechanism: gradients accumulated on a GPU during a backward step are streamed to host DRAM and applied to the master copy in a separate optimiser thread, while the GPU is freed for the next stream-and-compute step. [Analysis] This is what hides the optimiser-update cost behind the forward-pass critical path. The protocol assumes a single iteration’s gradients are applied before the next iteration’s forward pass reads the master copy; weight-update staleness across iterations is not introduced. 2
Subsection 8D. Inference / deployment specifics. Not applicable to this paper. RoundPipe is a training-time scheduler; the paper does not address inference-time deployment, model serving, or post-training quantisation.
[Analysis] The specialised design pieces are pragmatic engineering. None of the four training-specific choices above is novel in isolation: Mobius and ZeRO-Infinity already use CPU-offload-and-stream patterns; activation checkpointing is standard in long-context training; asynchronous optimiser updates are established in the data-parallel literature. 3 7 The contribution is the integration into a coherent stateless-worker design where each piece composes correctly with the round-robin dispatch.
9. Experiments and results
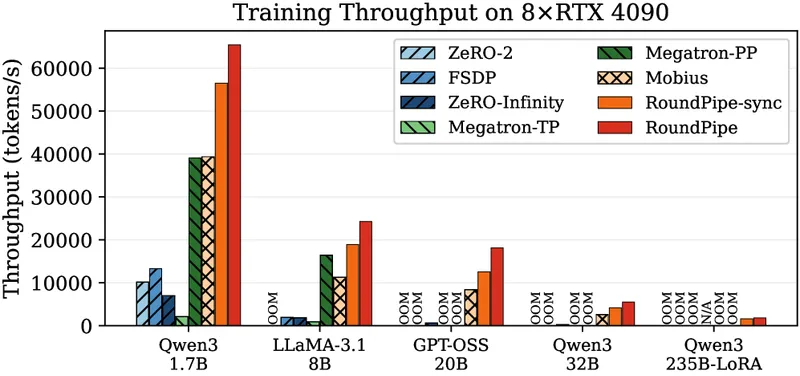
Figure 9 of Efficient Training on Multiple Consumer GPUs with RoundPipe (arXiv:2604.27085), reproduced for editorial coverage.
Experimental setup. 2
| Item | Value |
|---|---|
| Hardware | Single server, 8x NVIDIA RTX 4090 (24 GB each), PCIe Gen4 host interconnect, host DRAM sized for 235B master weights |
| Models tested | Qwen3-1.7B, LLaMA-3.1-8B, GPT-OSS-20B, Qwen3-32B, Qwen3-235B-A22B |
| Fine-tuning method | LoRA (Low-Rank Adaptation) |
| Context length | Up to 31K tokens |
| Baselines (six) | DeepSpeed ZeRO-2, PyTorch FSDP, DeepSpeed ZeRO-Infinity, Megatron-PP (pipeline parallelism), Megatron-TP (tensor parallelism), Mobius |
| Throughput metric | Tokens per second per GPU |
| Accuracy validation | Downstream-task evaluation comparing fine-tuned RoundPipe runs to baseline runs |
| Software stack | PyTorch 2.x, custom CUDA kernels for transfer scheduling |
Headline result. Across the 1.7B, 8B, 20B, and 32B configurations, RoundPipe achieves a 1.48x-to-2.16x speedup over the strongest feasible baseline among the six. 2
Standout configuration: Qwen3-235B-A22B at 31K context. This is a feasibility result, distinct from the speedup numbers above. All six baselines fail to complete the workload on the 8x RTX 4090 hardware: DeepSpeed ZeRO-2 and PyTorch FSDP run out of GPU memory; Megatron-PP and Megatron-TP cannot fit a single stage; DeepSpeed ZeRO-Infinity and Mobius (both CPU-offload systems) fail at long context due to activation memory pressure. RoundPipe is the only system among the seven evaluated that finishes the configuration, owing to the combination of stateless workers, CPU-offloaded master weights, and stage-boundary activation offload. 2
Ablation study. 2 The paper removes each of the three sub-systems in turn and measures the throughput drop. Priority-aware transfer scheduling is the largest single contributor to the speedup on the 32B configuration; distributed event-based synchronization contributes more on the smaller-pipeline-depth configurations; the automated layer partitioner’s contribution is largest on 235B where the partition shape is non-obvious.
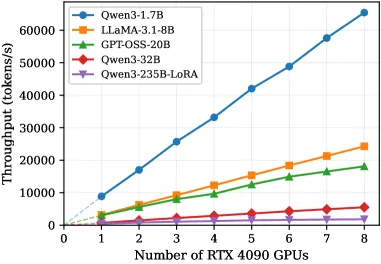
Figure 13 of Efficient Training on Multiple Consumer GPUs with RoundPipe (arXiv:2604.27085), reproduced for editorial coverage.
Accuracy validation. Downstream-task evaluation on the fine-tuned models matches baseline runs within evaluation noise. [Analysis] LoRA’s interaction with non-uniform pipeline schedules is the kind of subtle behaviour that benchmark-level evaluation can miss; teams running their own fine-tunes should re-verify on the specific evaluation harness they care about.
Two caveats for reading the speedup numbers honestly.
First, throughput in tokens per second per GPU is the right metric for comparing schedulers but not the right metric for comparing total cost. A 1.5x throughput improvement does not automatically translate into a 1.5x reduction in fine-tuning cost; the cost depends on what fraction of total job time is scheduler-bottlenecked versus model-bottlenecked.
Second, the paper does not report multi-node training, mixed RTX 3090/4090 configurations, full pre-training, or behaviour on RoCE / 10/25 GbE multi-node interconnects. The single-server scope is explicit and load-bearing for the result.
10. Novelty summary
What is new in RoundPipe relative to prior work:
-
Stateless-worker design. Mobius keeps master weights in host DRAM but assigns each GPU a fixed pipeline stage; RoundPipe drops the fixed assignment entirely and lets the dispatcher pick which GPU runs which stage on each round. 3
-
Round-robin dispatch with rotating round-base index. The per-stage-slot dispatch rule that sends stage slot to with advancing by between rounds (where is the total stage-slot count) is the specific load-balancing primitive the paper introduces.
-
Two-stage greedy partitioner that scales to 94 layers in 1.47 seconds. The discrete-enumeration-plus-greedy-packing approach, as opposed to ILP relaxations, is what keeps the partition tractable at 235B scale.
What is not new:
- CPU-offloaded master weights and parameter streaming. Mobius and ZeRO-Infinity established this design pattern. 3 7
- Activation checkpointing. Standard practice in long-context training.
- Tensor + pipeline + data parallelism combined as 3D parallelism. Megatron-LM (Narayanan et al., 2021). 6
- Micro-batching. GPipe (Huang et al., 2019). 5
[Reviewer Perspective] The novelty is real but the framing matters. RoundPipe is a scheduler advance built on Mobius’s CPU-offload foundation, not a new training algorithm or a new model architecture. The 1.48x-to-2.16x speedup over six established baselines on consumer GPUs is a meaningful engineering result, and the 235B-on-8x-RTX-4090 capability is the more eye-catching contribution because it changes hardware-spend math for teams previously priced out of the largest open-weight models. The paper should be read as a systems engineering paper, not as a paradigm shift.
11. Situating
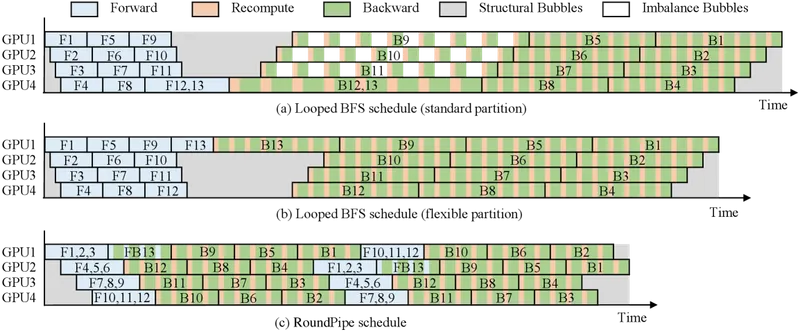
Figure 1 of Efficient Training on Multiple Consumer GPUs with RoundPipe (arXiv:2604.27085), reproduced for editorial coverage.
[External comparison] Four prior works form the right reference set.
Mobius (Feng et al., ASPLOS 2023) is the most direct predecessor. 3 Mobius established the CPU-offload-master-weight pattern for fine-tuning large models on commodity GPU servers and is one of RoundPipe’s six evaluation baselines. The technical relationship: Mobius assigns each GPU a fixed pipeline stage and rotates micro-batches through that fixed assignment; RoundPipe drops the fixed assignment and lets the dispatcher pick which GPU runs which stage round-robin. The empirical relationship: Mobius is one of the systems RoundPipe compares against; the paper reports speedup of RoundPipe over Mobius within the 1.48x-to-2.16x range on the 1.7B-to-32B models.
PipeDream (Harlap et al., 2018) introduced 1F1B interleaving. 4 RoundPipe does not adopt 1F1B; the round-robin dispatch is a different load-balancing primitive that does not interleave forward and backward across micro-batches. The technical relationship is conceptual, not implementation-level: both are dynamic-schedule moves over what is otherwise a static-partition pipeline.
Megatron-LM (Narayanan et al., 2021) is the production-grade 3D-parallelism system that combines tensor parallelism (Megatron-TP), pipeline parallelism (Megatron-PP), and data parallelism. 6 RoundPipe evaluates against Megatron-PP and Megatron-TP separately as two of its six baselines. The 3D-parallelism integration story is research-grade and not load-bearing for the paper’s headline result.
ZeRO-Infinity (Rajbhandari et al., 2021) is the deep-offload approach used as DeepSpeed ZeRO-Infinity, which RoundPipe evaluates as a baseline. 7 ZeRO-Infinity offloads parameters, gradients, and optimiser states to CPU and NVMe for very-large models on data-centre GPUs. RoundPipe shares the parameter-offload idea but specifically targets pipeline parallelism on consumer-grade PCIe servers rather than full ZeRO sharding on InfiniBand-connected racks.
[Analysis] RoundPipe slots in as a successor to Mobius on the consumer-GPU pipeline-parallelism axis, and as an alternative to DeepSpeed ZeRO-Infinity for LoRA fine-tuning workloads where the consumer-GPU regime applies. Teams running on data-centre hardware (NVLink-equipped H100 or A100 clusters) should not expect the speedup to transfer; the savings are specific to PCIe-bandwidth-bound and per-GPU-memory-bound configurations.
12. Critical analysis
[Reviewer Perspective] Five things to interrogate when reading or extending RoundPipe.
The 31K-context Qwen3-235B-A22B result has not been independently reproduced. The paper is too new for community reproduction at that scale, and verifying the claim requires the kind of hardware investment that does not happen in a week. Builders treating the 235B-specific feasibility as a guarantee rather than a benchmark-conditions report will need to re-verify on their own hardware. 8
PCIe-topology sensitivity is a known unknown. Some 8x RTX 4090 racks have GPU pairs sharing PCIe lanes through a switch (PLX or similar); the paper does not measure that configuration. The speedup numbers are likely sensitive to topology, and a builder evaluating on hardware with non-trivial PCIe topology should re-benchmark on their specific configuration rather than relying on the paper’s headline numbers.
Mobius is the closest baseline but the speedup gap is not the largest. The speedup over Mobius is at the lower end of the 1.48x-to-2.16x range because Mobius and RoundPipe share the CPU-offload foundation; the biggest gaps are over the GPU-resident-parameter baselines (DeepSpeed ZeRO-2, PyTorch FSDP, Megatron-PP/TP) where memory pressure is the bottleneck. Builders already using Mobius will see smaller gains than builders migrating from a non-offload system.
Fault tolerance is absent. A multi-day training run on consumer hardware has a non-trivial probability of GPU failure or host-server reboot. The paper assumes a fixed and reliable hardware topology and does not implement check-pointing for fault recovery. Production teams running multi-day jobs need to add their own check-pointing layer.
The cost-economics translation is workload-dependent. A 1.5x throughput improvement is not a 1.5x cost improvement. The total job cost depends on the fraction of time scheduler-bottlenecked vs model-bottlenecked, the marginal cost of recompute on failure, and the fixed cost of profiler overhead at job start. Builders making a hardware-spend decision should run their own end-to-end cost benchmark on the actual workload, not rely on per-step throughput as a proxy.
[Analysis] The five caveats together do not invalidate the result; they bound it. The headline numbers are credible for the configurations the authors tested. The reproducibility caveats are normal for a paper this fresh. Treating the 1.48x-to-2.16x range as a “your-mileage-may-vary” guide rather than a guaranteed speedup, and treating the 235B feasibility as a workload-specific demonstration rather than a turnkey path, is the right framing.
Reproducibility check.
| Artefact | Status |
|---|---|
| Code | Reference implementation linked from the arXiv abstract page; license follows the GitHub repository terms. 1 |
| Trained model weights | Not released. RoundPipe is a training-systems contribution; the paper does not ship fine-tuned model checkpoints. |
| Evaluation set | Not released as a packaged artefact. The paper describes the downstream-task evaluation harness in the experiments section but does not publish a standalone eval bundle. 2 |
| Hyperparameters | Partially specified. LoRA rank / alpha, learning-rate schedule, and the per-model micro-batch counts are reported; per-stage memory budgets and the exact priority-queue weighting heuristic are not enumerated in the main text. 2 |
| Compute budget | Hardware reported (single 8x RTX 4090 server). Total compute budget for the reported runs (wall-clock hours per configuration) not reported in the paper or supplementary. |
| Independent reproduction | None published as of 2026-05-17. The Hugging Face Papers community discussion surfaces limited third-party engagement at this date. 8 |
| Overall | Partially reproducible. Code path is open; weights / eval-set / compute-budget gaps require re-implementation effort. |
Methodology disclosure.
- Sample size. Five tested models (Qwen3-1.7B, LLaMA-3.1-8B, GPT-OSS-20B, Qwen3-32B, Qwen3-235B-A22B). Per-model run-count and confidence intervals on the speedup numbers are not reported in the main text. 2
- Evaluation set. Downstream-task evaluation harness used to validate fine-tune accuracy. The specific benchmark composition is described in the experiments section; contamination check against the LoRA training data is not surfaced in the main text. 2
- Baselines. Six systems: DeepSpeed ZeRO-2, PyTorch FSDP, DeepSpeed ZeRO-Infinity, Megatron-PP, Megatron-TP, Mobius. All six are widely-used production systems; Mobius is the most direct technical predecessor. 2 3
- Hardware / compute. Single server, 8x NVIDIA RTX 4090 (24 GB each), PCIe Gen4 interconnect. Total compute hours per configuration not reported. 2
13. Reusable components
[Reviewer Perspective] Several pieces of RoundPipe are reusable independent of the full system. Builders who do not adopt RoundPipe wholesale may still find these worth extracting.
Two-stage partition algorithm. The discrete-enumeration-plus-greedy-packing approach to layer-to-stage assignment is a clean primitive. Teams building their own pipeline-parallelism schedulers can lift the algorithm directly; the 1.47-second runtime on 94 layers means it scales to anything in the open-weight model range.
Round-robin dispatch rule. The schedule with rotating by between rounds is a self-contained load-balancing primitive that does not require the rest of the RoundPipe machinery. Teams running pipeline parallelism on heterogeneous or PCIe-bound hardware can adopt the dispatch rule incrementally.
Stage-boundary activation offload pattern. Checkpointing activations at stage boundaries and offloading them to host DRAM is the specific memory-management primitive that makes long-context fine-tuning fit on 24 GB GPUs. Reusable in any pipeline-parallel system targeting consumer hardware.
Custom CUDA kernels for cudaMemcpyAsync orchestration. The kernels in the reference implementation expose per-transfer prioritisation hooks that torch.distributed’s standard collectives do not. Teams hitting the same gap can lift the kernels rather than re-implementing them.
Profiler-feeds-solver architecture. The profiler that measures per-layer compute and memory at the target context length, then feeds the partition-search solver, is a reusable building block. The specific algorithm is one of several reasonable choices, but the profiler-feeds-solver architecture generalises.
14. Limitations and open problems
Author-stated scope (the paper does not include a formal Limitations section; the items below are gathered from the paper’s experimental scope and method-section caveats). 2
- Single-server scope. The evaluation is confined to one 8x RTX 4090 server. Multi-node behaviour over RoCE or 10/25 GbE is not measured.
- Fine-tuning only. The methodology section frames the work as targeting fine-tuning; full pre-training is out of scope.
- Fixed-topology assumption. GPU failure during a training run is not handled; the scheduler does not implement check-pointing for fault recovery.
- Fixed model set. The five tested models are all decoder-only transformers from open-weight families. Encoder-decoder architectures, mixture-of-experts with non-uniform routing, and mamba-style state-space models are not evaluated.
[Reviewer Perspective] Additional limitations beyond the paper’s stated scope.
- PCIe-topology sensitivity. The speedup numbers may not transfer cleanly to 8x RTX 4090 racks with non-trivial PCIe topology (lane-sharing through PLX switches, NUMA crossings).
- Lack of independent reproduction at the 235B scale. As of this writing, no third party has published a reproduction of the 31K-context Qwen3-235B-A22B feasibility result on independent hardware. The Hugging Face Papers community thread surfaces limited third-party engagement at this accessed date. 8
- Mixed-GPU configurations untested. Real-world consumer-GPU clusters often have heterogeneous GPUs (a mix of RTX 3090 and 4090). The partition-search solver would need a per-GPU compute-cost model that the paper does not provide.
Open problems for follow-up work [Analysis].
- Multi-node behaviour. The stateless-worker design plausibly extends to multi-node configurations, but the host-DRAM-master-weight assumption interacts with multi-node memory layout in ways the paper does not address.
- Mixture-of-experts routing. MoE models with non-uniform expert routing break the partition-search solver’s compute-cost assumption. A scheduler-level MoE-aware extension is an obvious research direction.
- Pre-training vs fine-tuning. Whether the same scheduler primitives carry over to pre-training, where memory pressure and gradient-accumulation patterns are qualitatively different, is open.
[Reviewer Perspective] The honest read is that RoundPipe is a solid systems engineering contribution within a clearly-bounded scope. The 1.48x-to-2.16x speedup over six baselines on the 1.7B-to-32B model range is credible, and the Qwen3-235B-A22B feasibility result is the more eye-catching contribution because it expands what consumer-GPU servers can run at all. The reusable components (the round-robin dispatch rule, the two-stage greedy partitioner, the stage-boundary activation offload pattern) are likely to outlast the specific RoundPipe implementation as building blocks for the next round of consumer-GPU LLM-training work. Builders evaluating consumer-GPU fine-tuning today should integrate this into their decision process, run an A/B against Mobius on their actual workload, and treat the 235B feasibility as a workload-specific demonstration rather than a turnkey path.
How this article reads at three depths
For the curious high-school reader. Training a very large language model usually requires expensive specialised hardware. RoundPipe is a clever way of organising the work so that eight regular gaming-grade GPUs can together fine-tune even a 235-billion-parameter model, by keeping the model’s parameters in the computer’s main memory and streaming them to whichever GPU is free. The idea matters because it puts large-model fine-tuning within reach of teams that cannot afford data-centre hardware.
For the working developer or ML engineer. RoundPipe is a pipeline-parallelism scheduler with three working parts: CPU-offloaded master weights, stateless GPU workers, and a round-robin dispatcher. It reports a 1.48x-to-2.16x speedup over six baselines (DeepSpeed ZeRO-2, PyTorch FSDP, DeepSpeed ZeRO-Infinity, Megatron-PP, Megatron-TP, Mobius) on Qwen3-1.7B / LLaMA-3.1-8B / GPT-OSS-20B / Qwen3-32B, and is the only system among the seven evaluated that completes Qwen3-235B at 31K-token context on 8x RTX 4090. The trade-offs to weigh: no fault-tolerance layer, single-server scope (no measured multi-node behaviour), no independent reproduction of the 235B result, and an open question on PCIe-topology sensitivity. The pragmatic move is to A/B against Mobius on the actual workload before committing.
For the ML researcher. The novel contribution is the stateless-worker primitive layered on top of Mobius’s CPU-offload pattern, combined with a per-stage-slot round-robin dispatch rule that sends stage slot to and rotates the round-base index by between rounds (where is the total stage-slot count per round). The two-stage greedy partitioner (discrete enumeration of stage-time bounds + greedy contiguous-layer packing) scales to 94 layers in 1.47 seconds, which is the algorithmic decision that makes 235B-scale partitioning tractable without ILP relaxation. The strongest objection is that the headline speedup is measured against six baselines on one hardware configuration with one fine-tuning method (LoRA); the gap to Mobius is the smallest gap in the range, which is the relevant comparison since both share the CPU-offload foundation. A follow-up paper would need to extend the partition-search solver to a per-GPU compute-cost model for heterogeneous clusters, formalise fault-tolerance semantics, and characterise PCIe-topology sensitivity directly.
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. Efficient Training on Multiple Consumer GPUs with RoundPipe (arXiv:2604.27085, submitted 29 April 2026; abstract page lists Yibin Luo, Shiwei Gao, Huichuan Zheng, Youyou Lu, and Jiwu Shu as authors and links to the reference implementation on GitHub) (accessed ) ↩
- 2. RoundPipe HTML render via ar5iv — abstract, Sections 1-6 of the paper covering CPU-offloaded master-weight design, stateless workers, round-robin dispatcher, three sub-systems (priority-aware transfer scheduling, distributed event-based synchronization, automated layer partitioning), 8x RTX 4090 hardware, five tested models (Qwen3-1.7B, LLaMA-3.1-8B, GPT-OSS-20B, Qwen3-32B, Qwen3-235B-A22B), six baselines (DeepSpeed ZeRO-2, PyTorch FSDP, DeepSpeed ZeRO-Infinity, Megatron-PP, Megatron-TP, Mobius), 1.48-2.16x speedup on 1.7B-32B range, 235B-A22B feasibility at 31K-token context, two-stage O(L³) greedy partitioner with 1.47s overhead on 94 layers, round-robin (g₀+i) mod N dispatch with g₀ advancing by S mod N between rounds (accessed ) ↩
- 3. Mobius: Fine Tuning Large-Scale Models on Commodity GPU Servers (Feng et al., ASPLOS 2023) — the most direct prior work on CPU-offload-based pipeline parallelism for commodity GPU servers; assigns fixed pipeline stages to each GPU and rotates micro-batches through that fixed assignment; one of RoundPipe's six evaluation baselines (accessed ) ↩
- 4. PipeDream: Fast and Efficient Pipeline Parallel DNN Training (Harlap et al., 2018) — original 1F1B interleaved-schedule paper; conceptually related to RoundPipe's round-robin dispatch but using a different load-balancing primitive (interleaving forward and backward across micro-batches rather than rotating the round-base index) (accessed ) ↩
- 5. GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism (Huang et al., 2019) — original micro-batching paper; introduced the foundational primitive that PipeDream, Mobius, and RoundPipe build on (accessed ) ↩
- 6. Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM (Narayanan et al., 2021) — production-grade 3D-parallelism system combining tensor (Megatron-TP), pipeline (Megatron-PP), and data parallelism; both Megatron-TP and Megatron-PP are evaluated separately as RoundPipe baselines (accessed ) ↩
- 7. ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning (Rajbhandari et al., 2021) — deep-offload approach used as DeepSpeed ZeRO-Infinity; offloads parameters, gradients, and optimiser states to CPU and NVMe; one of RoundPipe's six evaluation baselines (accessed ) ↩
- 8. RoundPipe community discussion on Hugging Face Papers — limited discussion as of accessed date given the paper's recent submission; no independent reproduction of the 31K-context Qwen3-235B-A22B feasibility result published (accessed ) ↩
Further Reading
- Efficient Training on Multiple Consumer GPUs with RoundPipe (PDF) (accessed )
- PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel (Zhao et al., 2023) (accessed )
Anonymous · no cookies set