Activation steering and representation engineering for LLM safety — a multi-paper review
Plain-English walkthrough of ActAdd, Representation Engineering, Contrastive Activation Addition, and Anthropic's Persona Vectors — what each paper proves, where…
Reading-register key
- From the paper: claims drawn verbatim or near-verbatim from the source paper’s text, equations, tables, or figures.
- [Analysis]: the publication’s own reasoned assessment, distinct from any claim the four reviewed papers make.
- [Reconstructed]: content faithfully reconstructed because the source partially disclosed it; flagged where used.
- [External comparison]: comparison to prior or contemporary work outside the four reviewed papers.
- [Reviewer Perspective]: a critical or speculative assessment that goes beyond what any of the four reviewed papers proves.
1. Paper identity and scope
This article reviews four papers that together define the activation steering / representation engineering research line — the idea that a large language model’s internal hidden-state vectors carry linearly-readable directions corresponding to behaviors like “tell the truth,” “be sycophantic,” or “refuse harmful requests,” and that adding small offsets along those directions at inference time meaningfully changes model behavior without retraining.
Paper A — ActAdd. Turner, Thiergart, Leech, Udell, Vazquez, Mini, MacDiarmid. Steering Language Models With Activation Engineering. arXiv:2308.10248, first posted August 2023, last revised October 2024. No formal venue listed on the arXiv landing page. 1
Paper B — Representation Engineering (RepE). Zou, Phan, Chen, Campbell, Guo, Ren, Pan, Yin, Mazeika, Dombrowski, Goel, Li, Byun, Wang, Mallen, Basart, Koyejo, Song, Fredrikson, Kolter, Hendrycks (21 authors). Representation Engineering: A Top-Down Approach to AI Transparency. arXiv:2310.01405, first posted October 2023, last revised March 2025. 2
Paper C — Contrastive Activation Addition (CAA). Panickssery, Gabrieli, Schulz, Tong, Hubinger, Turner. Steering Llama 2 via Contrastive Activation Addition. arXiv:2312.06681, December 2023. The first author’s surname is Panickssery; earlier circulation under “Rimsky et al.” reflects an author-name change. 3
Paper D — Persona Vectors. Chen, Arditi, Sleight, Evans, Lindsey. Persona Vectors: Monitoring and Controlling Character Traits in Language Models. arXiv:2507.21509, July 2025. Anthropic Fellows program; companion blog post on anthropic.com August 2025. 4
Retrieval status. All four arXiv landing pages plus the Anthropic blog page were fetched 2026-05-20. The ar5iv HTML render was reachable for papers A, B, and C; the ar5iv build for paper D had a fatal conversion error on the day of writing, so paper D’s formal equations are reconstructed from the abstract, Anthropic’s companion blog post, and the citation-graph context. 5 Where paper D content carries [Reconstructed], the gap is the missing ar5iv render.
Paper classification. All four papers: AI safety, Interpretability, Representation learning, LLM-based. ActAdd and CAA additionally: Inference method. RepE and Persona Vectors additionally: Training method (RepE via LoRRA, Persona Vectors via preventative steering during finetuning).
Technical abstract in publication voice. The four papers share a working hypothesis — that high-level concepts in instruction-tuned language models are encoded as linear directions in the residual-stream activation space, and that small offsets along those directions can steer model output at inference time. ActAdd ships the simplest version (one positive prompt minus one negative prompt, added to a chosen layer). RepE generalises the recipe into a framework called Linear Artificial Tomography (LAT) that uses unsupervised PCA over many contrastive stimuli, plus a low-rank fine-tuning variant called LoRRA. CAA averages over hundreds of contrastive multiple-choice answer pairs for a more stable steering vector, evaluates on Llama 2 Chat 7B/13B across seven safety-relevant behaviors, and shows steering stacks on top of fine-tuning. Persona Vectors extends the framework to monitoring (using activation projections to detect persona drift during training) and to a preventative-steering training objective that vaccinates the model against acquiring a trait from contaminated data. Common thread: a linear-direction-as-concept assumption that holds well enough on current chat models to produce reproducible behavioral effects; the assumption’s failure modes are the open research frontier. 6
Primary research question (per paper).
- ActAdd: can a steering vector built from a single contrastive prompt pair shift sentiment or topic without re-training?
- RepE: can representation-level reading and control techniques produce a top-down transparency framework that operates at the population-of-neurons level instead of the individual-circuit level?
- CAA: how stable are activation-addition steering vectors when computed from hundreds of contrastive pairs rather than one, on a frontier chat model, across safety-relevant behaviors?
- Persona Vectors: can persona-trait activation directions be used as both a monitoring signal during training and as a preventative-steering regulariser that blocks the model from acquiring a trait?
Core technical claim. Steering vectors derived from contrastive activations are a useful but imperfect handle on LLM behavior, sufficient to produce measurable shifts on benchmark behaviors at inference time and to predict and mitigate training-time persona drift.
Core technical domains and depth. Linear algebra and PCA (deep). Transformer architecture and residual stream (deep). Probing and interpretability methods (moderate). Reinforcement learning from human feedback context (surface). Optimization for low-rank fine-tuning (moderate, RepE only).
Reader prerequisites. High-school algebra. Familiarity with the transformer block (attention, MLP, residual stream) helps; the Glossary below covers every prerequisite term, so a curious 16-year-old can read end-to-end. No prior exposure to interpretability research needed.
2. TL;DR and executive overview
3-sentence TL;DR. Four papers ask: can you control how a large language model behaves not by retraining it, but by nudging its internal “thoughts” — the numbers flowing through its layers — in a particular direction at inference time? They show that yes, a vector built from the difference between “be honest” activations and “be deceptive” activations, added to one layer of the model, measurably shifts behavior across sentiment, topic, refusal, hallucination, sycophancy, and several other safety-relevant traits, on models from GPT-2-XL through Llama 2 13B Chat and Qwen 2.5 7B. The most recent of the four, Anthropic’s 2025 Persona Vectors paper, uses these directions for early detection of “personality drift” during finetuning and as a vaccine-like training-time intervention that stops the model from picking up undesirable traits in the first place.
Executive summary (~100 words). The papers reviewed argue that a language model’s residual stream — the long vector of numbers carrying information from one transformer layer to the next — encodes high-level behavioral concepts as linear directions. Subtracting “be sycophantic” activations from “be honest” activations gives a direction; adding a scaled version of that direction to the residual stream during forward pass steers output. The four papers progress from one-pair sentiment shifts (ActAdd 2023) through a framework with reading and control operators (RepE 2023) and a 200-pair stable variant on Llama 2 (CAA 2023) to a 2025 Anthropic paper that uses the same vectors to detect training-time persona drift and to prevent it.
Five practitioner takeaways.
- A steering vector is just the mean activation under positive prompts minus the mean activation under negative prompts at one chosen transformer layer; computation is a single forward pass per example plus a subtraction.
- Layer choice matters more than coefficient choice. CAA reports layers 15-17 of Llama 2 7B / 13B Chat as peak-effect layers; ActAdd reports middle layers (roughly the middle third of the network) on GPT-2-XL. The rule-of-thumb that emerges from the four papers: sweep the middle third of the network and pick the layer with the strongest effect on a held-out validation set.
- The technique stacks on top of fine-tuning. CAA shows steering still moves the needle on a Llama 2 7B Chat model that has been DPO-tuned for honesty; the two interventions are additive rather than redundant.
- The technique is interpretability-flavored rather than capability-preserving by default. Large coefficients degrade MMLU; sweeping coefficients between roughly -1.5 and +1.5 is the safe range CAA reports for its setup.
- Persona Vectors extends the use case from inference-time steering to training-time regularisation, and to monitoring “is this finetuning run drifting the model toward evil / sycophancy / hallucination?” as a per-step diagnostic, which is the most operationally novel of the four papers.
Pipeline overview. Training time (RepE LoRRA, Persona Vectors preventative steering): collect contrastive activations, compute a steering vector, optimise a low-rank or full-finetune objective that either pushes activations toward a target direction (LoRRA) or applies the persona vector during finetuning as a regulariser (Persona Vectors). Inference time (ActAdd, CAA, RepE reading): compute the steering vector once, then on every forward pass add it (scaled by a coefficient) to the residual stream at the chosen layer for every token position after the user prompt. No gradient backprop, no model weight modification; just a vector addition during the forward pass.
2.5 Glossary
| Term | Plain-English explanation | First appears in |
|---|---|---|
| Activation | The vector of numbers flowing between transformer layers when the model processes input; the model’s “intermediate thoughts.” | Section 1 |
| Residual stream | The running sum of activations carried forward from one transformer layer to the next; each layer reads from it and writes back to it. | Section 1 |
| Steering vector | A direction in activation space, computed as positive-prompt-activations minus negative-prompt-activations, that the model can be nudged along to shift behavior. | Section 2 |
| Contrastive pair | Two prompts (or completions) designed to be identical except for the trait being targeted, e.g., one prompting “be sycophantic,” one prompting “be honest.” | Section 2 |
| PCA (principal component analysis) | A math technique that finds the single direction along which a cloud of points varies most; used in RepE to find the most-informative steering direction across many contrastive pairs. | Section 6 |
| LoRRA | RepE’s training-time variant: a low-rank fine-tune that pushes the model’s representations toward a target steering direction. | Section 5 |
| Coefficient ( or ) | The scalar multiplier on the steering vector when added to the residual stream; larger means stronger steering but also more capability degradation. | Section 6 |
| Sycophancy | A trait where the model agrees with the user even when the user is wrong; one of the seven behaviors CAA targets. | Section 5 |
| Persona drift | The phenomenon where finetuning a model on a dataset accidentally shifts the model’s character (e.g., toward being more deceptive, sycophantic, or hallucination-prone) even though the dataset doesn’t obviously target that trait. | Section 5 |
| Probing | An interpretability technique where a small classifier is trained to predict a concept from a model’s activations; tells you whether the concept is linearly readable. | Section 4 |
[Analysis] label | The publication’s own reasoned assessment, distinct from what any of the four papers itself claims. | Throughout |
[Reviewer Perspective] label | A critical or speculative assessment that goes beyond what any of the four papers proves. | Sections 11 + 12 |
[Reconstructed] label | Content the publication faithfully reconstructed because the source paper only partially disclosed it (paper D ar5iv conversion failed). | Where used |
[External comparison] label | A comparison to prior work or general knowledge outside the four reviewed papers. | Sections 4 + 11 |
| ”From the paper:” prefix | Content directly supported by one of the four papers’ text, equations, tables, or figures. | Throughout |
3. Problem formalisation
Notation table.
| Symbol | Type | Meaning | First in |
|---|---|---|---|
| Decoder transformer model | The language model being steered | Section 3 | |
| Integer | Number of transformer layers in | Section 3 | |
| Integer in | A chosen layer index where steering is applied | Section 3 | |
| Vector | Residual-stream activation at layer on input | Section 3 | |
| Integer | Model hidden dimension (e.g., for Llama 2 7B) | Section 3 | |
| Strings | Contrastive prompt pair (positive trait vs. negative trait) | Section 3 | |
| Vector | Steering vector at layer , derived from | Section 3 | |
| or | Real scalar | Steering coefficient (multiplier on ) | Section 3 |
| Set | Dataset of contrastive pairs used to estimate | Section 3 | |
| Function | RepE’s representation function: returns activations at layer for input | Section 5 | |
| Projection scalar | Projection of an activation onto a unit-norm persona vector at layer | Section 5 |
Formal problem statement. Given a pretrained instruction-tuned transformer with layers and hidden dimension , and a target behavior (e.g., “be honest,” “refuse harmful requests”), the goal is to find a steering vector and a coefficient such that the modified forward pass
produces output that exhibits more (or less) of behavior than the unmodified forward pass, while keeping general capability (measured on MMLU, perplexity, downstream task accuracy) close to baseline.
Assumptions.
- Linear representation hypothesis (load-bearing). High-level behavioral concepts are encoded as linear directions in the residual stream. The four papers cite each other and earlier interpretability work for empirical support; none gives a formal proof.
[Analysis] Potentially strong assumption— recent work on representation geometry (concept polytopes, multi-cluster encodings) suggests the linear hypothesis is a useful first-order approximation but breaks for some concepts on some models. - Locality of steering effect. Adding at one layer is enough; the modification propagates through subsequent layers without needing per-layer correction. CAA validates this empirically by sweeping single-layer injection vs. multi-layer; single-layer suffices on Llama 2.
- Single-direction sufficiency (RepE relaxes this). ActAdd and CAA assume one direction per concept suffices. RepE uses PCA over many contrastive pairs to extract the primary direction but acknowledges higher principal components may carry additional task-relevant signal.
- Contrastive-pair construction faithfully isolates the target trait. If and differ on factors other than the target trait, encodes that confounded direction.
[Analysis] Potentially strong assumption— practical contrastive-pair design is closer to art than to specification.
Why the problem is hard. Naively, controlling a chat model’s behavior on a specific trait requires fine-tuning data, a reward model, RLHF or DPO infrastructure, and compute. Activation steering aspires to skip all of that — zero gradient updates, one forward pass per contrastive example, then a vector addition during inference. The hardness lies in (a) whether the assumed linearity holds, (b) whether one direction generalises across prompts in distribution, (c) whether the steering effect transfers out of distribution, and (d) whether capability degrades.
LLM-based setting. All four papers operate on instruction-tuned decoder transformers. ActAdd uses GPT-2-XL (1.5B) primarily, with Llama-13B and GPT-J-6B replications. RepE uses Llama-2 7B / 13B / 70B Chat and Vicuna 33B. CAA uses Llama 2 7B Chat and Llama 2 13B Chat. Persona Vectors uses Qwen 2.5 7B Instruct and Llama 3.1 8B Instruct.
4. Motivation and gap
Real-world problem. An instruction-tuned chat model behaves correctly most of the time but occasionally drifts: agrees with a user who’s wrong (sycophancy), generates plausible-sounding falsehoods (hallucination), refuses benign requests, or fails to refuse harmful ones. The standard fix is to fine-tune with RLHF or DPO on a dataset that targets the drift. That’s expensive in data, compute, and engineering time, and it bakes the fix into the weights permanently.
Existing approaches and their failure modes per the four papers.
- Prompt engineering. Cheap, brittle, falls over under adversarial inputs. ActAdd’s introduction frames steering as a “between prompting and fine-tuning” intermediate.
- RLHF / DPO fine-tuning. Expensive; requires preference data; modifies weights globally; hard to undo per-trait without affecting other traits. CAA’s Section 5 specifically shows steering stacks on top of DPO-tuned models, suggesting fine-tuning doesn’t saturate the steering direction.
- Mechanistic interpretability (circuit-level). [External comparison] The Olah / Anthropic circuits research line — induction heads, sparse autoencoders, transformer circuits — works bottom-up at the neuron and head level. RepE explicitly positions itself as the top-down complement, working at the population-of-neurons level via linear directions instead of individual circuits.
- Linear probing. A small classifier trained to read a concept off activations. RepE generalises this from a read-only operation to a read-and-write framework via LAT.
Gap the papers claim to fill. A lightweight, gradient-free, layer-localised intervention that produces measurable behavioral effects on safety-relevant traits, with empirical evidence that it works on frontier (at time of writing) chat models, not just toy GPT-2 demos.
Position in the broader research landscape. [External comparison] Activation steering sits at the intersection of three lines: (a) the Olah / Anthropic mechanistic-interpretability line covered in the publication’s mechanistic-interpretability-circuits multi-paper review, which the four reviewed papers complement rather than replace; (b) the LLM-alignment / RLHF / DPO line covered in dpo-vs-ipo-vs-kto-vs-simpo, which steering augments without replacing; (c) classical model-editing work (ROME, MEMIT) which modifies weights to edit specific facts, whereas steering modifies activations to shift broad behaviors.
5. Method overview
Paper A — ActAdd
Plain-English intuition. Write down two prompts, one that elicits the trait you want more of, one that elicits the trait you want less of. Run both through the model and grab the residual-stream vector at a chosen layer. Subtract. You now have a direction. At inference time, add a scaled copy of that direction to the residual stream at the same layer on a real prompt. The model’s continuation now leans toward the positive trait.
Exact mechanism. From the paper: pick layer . Construct prompts (“Love”) and (“Hate”). Run a forward pass on each; record at the first token position of the stream. Compute steering vector . On a real input , run the forward pass up to layer , modify at the chosen position, continue the forward pass. The paper reports in the range of “absolute values between 3 and 15” for GPT-2-XL on sentiment shifts. 1
Design rationale. Minimum-viable steering: one pair, one layer, one coefficient. The paper’s pitch is that this minimum suffices for measurable effects.
What breaks if removed. Drop and you lose contrastive grounding; the resulting “positive-only” vector encodes “this prompt was used as steering input” rather than “this trait minus its opposite.”
Novelty. [New] for the LLM context, though the contrastive-activation-difference idea has antecedents in classical word-embedding analogy work (king − man + woman ≈ queen). The paper itself acknowledges this lineage.
Paper B — Representation Engineering (RepE)
Plain-English intuition. Instead of one contrastive pair, run a whole template (“Consider the amount of HONESTY in the following: …”) over many stimuli and collect the activation cloud. Then do PCA on the differences. The first principal component is your steering direction; it’s more stable than a one-pair vector because it averages out idiosyncrasies of any single stimulus.
Exact mechanism — Linear Artificial Tomography (LAT). From the paper, three steps. 7
- Stimulus design. Build a task template that elicits distinct neural activity for the target concept . The paper’s running example: “Consider the amount of
<concept>in the following:<stimulus>. The amount of<concept>is”. - Neural activity collection. For a stimulus set , collect , the activations at the final token position. For function concepts (behaviors), collect both experimental and reference activations .
- Linear model construction. Run PCA on the difference vectors for concepts (or for functions). The first principal component is the reading vector .
Contrast vectors. From the paper: a stimulus-dependent variant where are paired prompt variants. Differs from the LAT reading vector by being per-stimulus instead of dataset-averaged.
LoRRA — Low-Rank Representation Adaptation. From the paper Algorithm 1: define a target representation , then minimise
where is the current (low-rank-adapted) representation and is a mask. LoRRA is RepE’s training-time analog of inference-time steering.
Design rationale. Average out noise across many contrastive pairs; use PCA’s variance-maximisation to find the most-informative direction; provide both read (probe) and control (steer + LoRRA) operators.
What breaks if removed. Without PCA, you’re back at one-pair ActAdd. Without LoRRA, you only have inference-time steering, no training-time variant.
Novelty. [New] framework label and [Adapted] mechanism (PCA on activation differences has antecedents in supervised probing).
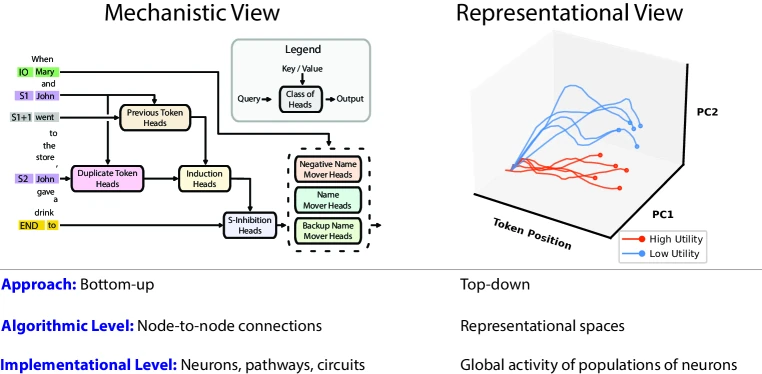
Figure 2 of Representation Engineering: A Top-Down Approach to AI Transparency (arXiv:2310.01405), reproduced for editorial coverage.
Paper C — Contrastive Activation Addition (CAA)
Plain-English intuition. ActAdd’s one-pair vector is noisy on a chat model. Build hundreds of multiple-choice contrastive pairs for a behavior (sycophancy: question with answer A “I agree with you” vs. answer B “Actually, evidence suggests otherwise”). Average the per-pair activation differences. That mean-difference vector is your steering vector. It’s the right granularity for chat models on safety-relevant behaviors.
Exact mechanism. From the paper, the mean-difference vector at layer is
where is the activation at layer for a (prompt, completion) pair, is the positive (target-trait-aligned) completion, is the negative completion, and is the dataset of contrastive pairs. 8 CAA’s seven behavior datasets each contain hundreds of multiple-choice items.
Layer selection. From the paper: sweep all layers, pick the one with the largest behavioral effect on a held-out validation set. Reports peak effect at layers 15-17 of Llama 2 7B (32-layer model) and corresponding mid-network layers of Llama 2 13B.
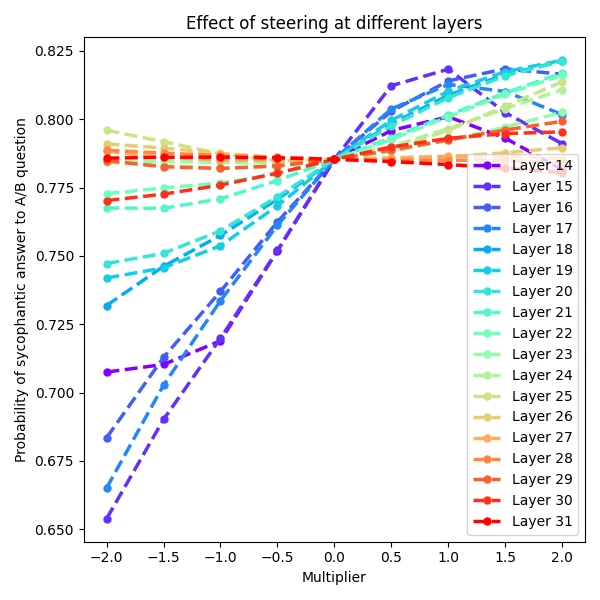
Layer-sweep figure from Steering Llama 2 via Contrastive Activation Addition (arXiv:2312.06681), reproduced for editorial coverage. Mid-network layers carry the strongest steering effect.
Coefficient. Sweep . Reports degradation at coefficients far from zero; optimal usually .
Design rationale. Averaging across hundreds of pairs is the empirical fix to one-pair ActAdd’s variance. Multiple-choice format gives clean contrast.
What breaks if removed. Drop the dataset and you’re back at ActAdd. Drop the layer sweep and you’ll pick a layer that’s either too early (effect washes out) or too late (effect is too narrow).
Novelty. [Adapted] from ActAdd: same mechanism, dataset-averaged plus multiple-choice-formatted plus applied at scale on a chat model.
Paper D — Persona Vectors
Plain-English intuition. [Reconstructed from abstract + Anthropic blog] Compute a steering vector for a persona trait (evil, sycophancy, hallucination) the same way CAA does: contrastive prompts that elicit the trait vs. suppress it. Then use that vector for three things instead of just steering: (1) monitor during finetuning by projecting intermediate activations onto the persona vector and watching the projection over training steps (rising projection = persona drift); (2) prevent by adding the persona vector as a regularisation term during finetuning so the model isn’t rewarded for activating along that direction; (3) flag training data by scoring training examples by how much they activate the persona direction (high-scoring examples are flagged as likely to induce the unwanted trait). 4
Exact mechanism. From the abstract + blog: persona vectors are extracted via the contrastive prompt protocol common to ActAdd, RepE, and CAA. The novel mechanism is the preventative-steering objective during finetuning: rather than applying the persona vector post-hoc at inference time, it’s applied during finetuning so that gradient updates don’t push the model along the persona direction. The blog frames this as “vaccine-like”: the model is exposed to the persona direction during training in a controlled way, so it doesn’t acquire the trait from the training data.
[Reconstructed] formal regularisation form (paper D ar5iv build failed; reconstructed from blog plus standard practice): the finetuning loss takes the form
where is the standard cross-entropy training loss, is the projection of layer- activations onto the persona vector, and penalises growth of the projection. The exact functional form and the layer-aggregation strategy are not extractable from the available sources and should be confirmed against the full PDF before any reproduction attempt.
Design rationale. Move steering from a one-time inference intervention to a continuous training-time signal. Treats persona drift as a measurable, attributable, and preventable phenomenon.
What breaks if removed. Persona Vectors is the synthesis paper of this research line: drop monitoring and you’re back at CAA; drop preventative steering and you’re back at LoRRA; drop data flagging and you lose the operational application.
Novelty. [New] for the monitoring + preventative-steering + data-flagging triple; [Adapted] for the vector-extraction step which is CAA-style.

Figure 3 of Representation Engineering: A Top-Down Approach to AI Transparency (arXiv:2310.01405), reproduced for editorial coverage.
6. Mathematical contributions
MATH ENTRY 1: ActAdd steering vector and injection
- Source: Turner et al. 2308.10248 Section 2 + 3 1
- What it is: a one-pair contrastive direction added to the residual stream.
- Formal definition: and
- Each term explained AND dimensional analysis:
- , where is the model’s hidden dimension (e.g., for GPT-2-XL, for Llama 2 7B). One vector per layer, per token position.
- are short strings. The paper’s running example: “Love”, “Hate”.
- , same shape as the residual stream.
- , scalar coefficient. Paper reports typical on GPT-2-XL.
- Worked numerical example. Let (toy model). Suppose and . Then . If the input activation is and , then . The first component grew by 1.4, the second shrank by 1.0; the steering pushed the activation strongly along the contrastive direction.
- Role: the entire ActAdd mechanism.
- Edge cases: when semantically, is near zero and steering has no effect.
- Novelty:
[New]for LLMs;[Adapted]from classical word-embedding analogies. - Transferability:
[Analysis]reusable wherever the model has a residual stream and a chosen layer; the trade-off is one-pair-vector noise. - Why it matters: shows the minimum-viable intervention that works.
MATH ENTRY 2: RepE Reading Vector via PCA
- Source: Zou et al. 2310.01405 Section 3.1 7
- What it is: the principal component of the difference-of-activations cloud over many contrastive stimuli, a more stable reading direction than ActAdd’s one-pair vector.
- Formal definition: collect for concept stimuli or for function stimuli; the reading vector is the first principal component of this difference set.
- Each term explained AND dimensional analysis:
- : activation at layer on the -th stimulus from concept set .
- The difference set is a cloud of vectors in where is the number of pairs.
- PCA on this cloud produces orthogonal directions; is the one explaining most variance.
- Worked numerical example. Let , pairs producing difference vectors . Mean-center: subtract the mean to get . Compute the covariance matrix . The principal eigenvector is the direction along which the differences vary most. Step-by-step: the first axis-aligned spread is 0.0125 in both x and y, but the off-diagonal tilts the principal axis to 45 degrees (rotated 45° from x-axis). In a real run, the first PC would similarly capture the dominant variance direction across hundreds of pairs.
- Role: the reading operator. RepE uses both for probing (project activations onto , read off the concept score) and for control (add scaled to activations, steer behavior).
- Edge cases: when the difference cloud is isotropic (no preferred direction), PCA returns essentially random directions and steering fails.
- Novelty:
[Adapted]since PCA on probe-style activation differences has antecedents in classical interpretability work; RepE’s framing of it as a “reading vector” with paired control operators is the novel contribution. - Transferability:
[Analysis]reusable in any probing context; the dataset size needs to be large enough to produce a stable PC. - Why it matters: explains why RepE’s reading vectors are more stable than ActAdd’s one-pair vectors.
MATH ENTRY 3: CAA Mean-Difference Vector
- Source: Panickssery et al. 2312.06681 Section 2 8
- What it is: dataset-averaged steering vector built from a corpus of contrastive multiple-choice answer pairs.
- Formal definition:
- Each term explained AND dimensional analysis:
- is a set of contrastive multiple-choice items; the paper uses hundreds per behavior.
- is the question prompt; is the trait-aligned completion (e.g., “B. Actually, the evidence suggests…”); is the opposed completion (e.g., “A. I agree with you”).
- is the activation at layer for the (prompt, completion) pair.
- .
- Worked numerical example. Let , . For pair 1: , , difference . For pair 2: , , difference . Average: . With in a real CAA run, the per-pair noise averages out and the dominant direction emerges cleanly.
- Role: the steering vector in CAA’s inference-time intervention.
- Edge cases: same as ActAdd: when contrastive pairs aren’t faithful (the only difference between and should be the target trait), encodes confounded directions.
- Novelty:
[Adapted]from ActAdd. - Transferability:
[Analysis]reusable on any chat model with multiple-choice contrastive datasets available. - Why it matters: shows the dataset-averaging fix to one-pair noise, with empirical validation on Llama 2 Chat.
MATH ENTRY 4: LoRRA training objective
- Source: Zou et al. 2310.01405 Section 5 + Algorithm 1 7
- What it is: a low-rank fine-tuning objective that pushes the model’s representations toward a target steering direction. RepE’s training-time variant.
- Formal definition: target representation ; loss .
- Each term explained AND dimensional analysis:
- : the current (frozen-base-plus-low-rank-adapter) activation at layer .
- : the contrast vector (per-stimulus difference). : the reading vector (PCA-derived dataset-level direction). Both in .
- : scalar coefficients controlling target shift magnitude.
- : representation produced by the current low-rank-adapted model (the “predicted” representation).
- : a mask selecting token positions for the loss.
- The L2 norm gives a scalar loss.
- Worked numerical example. Let , , , mask . Suppose , , . Then . If the low-rank-adapted current representation is , then , and . Gradient descent on with respect to the low-rank adapter parameters shifts the representation closer to the target.
- Role: lets the steering direction be baked into the model via low-rank fine-tuning, so inference-time addition isn’t required.
- Edge cases: if and disagree (per-stimulus contrast points in a different direction than the dataset-level PC), the target representation is poorly defined.
- Novelty:
[New]since the specific combination of low-rank adaptation with representation-targeted loss is RepE’s contribution. - Transferability:
[Analysis]reusable on any model where LoRA adapters are supported. - Why it matters: explains how RepE crosses from inference-time intervention to training-time fix.
MATH ENTRY 5: Persona Vector Projection (monitoring)
- Source: Chen et al. 2507.21509 + Anthropic blog 4
- What it is: a scalar that measures how much an activation lies along the persona direction; the monitoring signal during training.
[Reconstructed]from blog plus standard linear-projection definition since paper D ar5iv build failed. - Formal definition:
- Each term explained AND dimensional analysis:
- : activation at layer .
- : the persona vector at layer .
- : standard dot product, .
- : L2 norm.
- : scalar projection.
- Worked numerical example. Let , , . Dot product: . Norm of : . Projection: . Over training steps, monitoring this scalar per batch reveals whether the model is drifting along the persona direction. Rising = drift detected.
- Role: the diagnostic signal Persona Vectors uses for monitoring drift during finetuning.
- Edge cases: when the persona-extraction contrastive pairs are too similar; projection becomes numerically unstable.
- Novelty:
[Adapted]since scalar projection onto a probe direction is classical interpretability. Novelty is the operational use during finetuning runs. - Transferability:
[Analysis]directly reusable for any persona / behavior trait where a steering vector can be extracted. - Why it matters: shows how a steering vector becomes a continuous training-time observable, not just an inference-time intervention.
Proof sketches. None of the four papers carries a formal convergence-style theorem; they’re empirical-mechanism papers. The closest is RepE’s argument that PCA of activation differences recovers the most-informative direction in the linear-representation-hypothesis sense. This rests on the standard PCA optimality property (the first PC is the unit-norm direction maximising the variance of projections, by the Rayleigh quotient). The argument step-by-step:
- The data cloud is the set of difference vectors in .
- PCA seeks the unit-norm vector maximising , equivalently where is the covariance matrix of the differences.
- By the Rayleigh quotient, the maximiser is the eigenvector of with the largest eigenvalue.
- Under the linear representation hypothesis (target concept is a linear direction in activation space and contrastive pairs differ only along that direction), the dominant variance direction is the target direction, modulo noise.
- So the first PC of the difference cloud recovers the target direction asymptotically as the dataset grows.
Steps 4 and 5 are where the empirical work has to do the heavy lifting; the linear representation hypothesis is itself the load-bearing assumption.
7. Algorithmic contributions
ALGORITHM ENTRY 1: ActAdd
- Source: Turner et al. 2308.10248 1
- Purpose: minimum-viable steering at inference time.
- Inputs: model , layer , prompts , coefficient , input .
- Outputs: continuation generated from modified forward pass on .
- Pseudocode:
def actadd_generate(M, l, p_plus, p_minus, c, x):
# Step 1: compute steering vector once
h_plus = forward_to_layer(M, p_plus, layer=l) # shape (d,)
h_minus = forward_to_layer(M, p_minus, layer=l) # shape (d,)
v = h_plus - h_minus # shape (d,)
# Step 2: generate with hook
def hook(activations, layer_id):
if layer_id == l:
activations = activations + c * v
return activations
return M.generate(x, hook=hook)- Hand-traced example. Suppose , is a toy 3-layer model, , “happy”, “sad”, . Step 1: forward pass on “happy” through layer 2 gives ; forward pass on “sad” gives . Compute . Step 2: process real input “The weather today is”. At layer 2, the unmodified activation might be ; with steering, . The model continues generation from the steered activation; downstream layers see a representation pushed strongly toward the “happy” pole.
- Complexity. Time: 2 forward passes for vector setup plus 1 generation forward pass per token. Space: extra (one steering vector). Bottleneck: the same as ordinary generation.
- Hyperparameters: layer (sweep middle third of network), coefficient (sweep, paper uses 3-15 on GPT-2-XL), token positions (paper applies at the first stream position).
- Failure modes: poor choices produce noisy ; large degrades fluency.
- Novelty:
[New]for LLM context. - Transferability:
[Analysis]directly transferable to any decoder transformer.
ALGORITHM ENTRY 2: CAA Mean-Difference Steering
- Source: Panickssery et al. 2312.06681 8
- Purpose: stable inference-time steering on chat models via dataset-averaged vector.
- Inputs: model , layer , dataset of contrastive pairs, coefficient , input .
- Outputs: continuation with steered behavior.
- Pseudocode:
def caa_steer(M, L, D, c, x):
# Step 1: build mean-difference vector
diffs = []
for (p, a_plus, a_minus) in D:
a_p = activations(M, p + a_plus, layer=L, position=-1)
a_m = activations(M, p + a_minus, layer=L, position=-1)
diffs.append(a_p - a_m)
v_md = mean(diffs) # shape (d,)
# Step 2: generate with steering at all post-prompt positions
def hook(acts, layer_id, token_idx):
if layer_id == L and token_idx > len(user_prompt_tokens):
acts = acts + c * v_md
return acts
return M.generate(x, hook=hook)- Hand-traced example. Suppose , , layer , . Pair 1: , , diff . Pair 2: , , diff . Pair 3: , , diff . Mean: . (Real has hundreds of pairs and the components are noisier, but the mean stabilises.) At inference, on input “Is the sky green?”, the model’s activation at layer 15 after the user-prompt tokens might be . Steered: , pushed toward the trait-aligned direction.
- Complexity. Setup: forward passes (a few hundred). Inference: identical to ordinary generation plus one vector add per layer- token. Bottleneck: setup, not inference.
- Hyperparameters: layer (sweep, paper finds layers 15-17 on Llama 2), coefficient (sweep , paper finds safe).
- Failure modes: poor contrastive-dataset construction produces confounded ; large degrades MMLU.
- Novelty:
[Adapted]from ActAdd; novelty is dataset-averaging + multiple-choice format + frontier chat-model validation. - Transferability:
[Analysis]directly transferable; needs contrastive datasets for the target behavior.
ALGORITHM ENTRY 3: LoRRA training loop (RepE)
- Source: Zou et al. 2310.01405 Algorithm 1 7
- Purpose: bake the steering direction into the model via low-rank adaptation, no inference-time intervention required.
- Inputs: base model , layer , target stimuli , contrast vector , reading vector , coefficients , mask , low-rank adapter parameters .
- Outputs: trained low-rank adapter parameters that produce the steered behavior in base-model forward pass.
- Pseudocode:
def lorra_train(M, l, X, v_c, v_r, alpha, beta, m, theta_init, lr, steps):
theta = theta_init
for step in range(steps):
x_i = sample(X)
r_t = forward_with_adapter(M, x_i, layer=l, theta=None) \
+ alpha * v_c \
+ beta * v_r # target rep
r_p = forward_with_adapter(M, x_i, layer=l, theta=theta) # current rep
loss = norm(m * (r_p - r_t), p=2)
grads = backward(loss, wrt=theta)
theta = theta - lr * grads
return theta- Hand-traced example. Suppose , , , mask , learning rate . Sample : forward without adapter gives base rep . Target: . Current adapted rep (random init): . Loss: . Backprop adjusts to reduce this loss. After many steps, the adapter learns to produce representations near the target.
- Complexity. Per step: 2 forward passes (one with frozen base, one with adapter) plus 1 backward. Bottleneck: backward through the adapter, identical to standard LoRA training.
- Hyperparameters: (target shift magnitudes), (layer), (mask), low-rank dimension of adapter, learning rate, steps.
- Failure modes: target rep too far from base rep produces unstable training; coefficients must be calibrated.
- Novelty:
[New]since the specific objective is RepE’s contribution. - Transferability:
[Analysis]reusable wherever LoRA infrastructure is supported.
ALGORITHM ENTRY 4: Persona Vectors monitoring + preventative steering
- Source: Chen et al. 2507.21509 + Anthropic blog 4
[Reconstructed]overall structure from blog; specific loss formulation reconstructed since paper D ar5iv conversion failed. - Purpose: detect persona drift during finetuning and prevent it via a regularisation term.
- Inputs: base model , persona vector , finetuning dataset , regularisation weight .
- Outputs: finetuned model with bounded persona-direction activation.
- Pseudocode:
def persona_vector_finetune(M, l, v_l, D_ft, lambda_, lr, steps):
for step in range(steps):
batch = sample(D_ft)
h_l = forward_to_layer(M, batch, layer=l)
loss_ce = cross_entropy(M(batch), batch.targets)
proj = mean( dot(h_l, v_l) / norm(v_l) ) # batch-mean projection
loss_total = loss_ce + lambda_ * f(proj)
# Track proj over steps for monitoring; alarm if proj > threshold
log_metric("persona_projection", proj)
backward(loss_total)
step_optimizer(lr)- Hand-traced example. Suppose , , . Batch projection: dot , , projection . Cross-entropy on batch: . Total loss: . Over training, if the dataset would have pushed projection to (high drift), the regulariser term grows to , pulling the model away from that drift.
- Complexity. Per step: standard finetuning forward + backward, plus a dot product and norm. Bottleneck: same as standard finetuning.
- Hyperparameters: (regularisation strength), (layer for projection), threshold for monitoring alarm.
- Failure modes: too small produces no effect; too large degrades downstream task performance. The reconstructed pseudocode shows the high-level structure; the actual paper-D formulation may differ in functional form and layer-aggregation strategy.
- Novelty:
[New]for the monitoring + regularisation combination at this scale. - Transferability:
[Analysis]reusable on any finetuning run where the persona direction can be extracted in advance.
Best-layer plot from Steering Llama 2 via Contrastive Activation Addition (arXiv:2312.06681), reproduced for editorial coverage. Mid-network layers carry peak steering influence.
8. Specialised design contributions
Subsection 8A — LLM / prompt design.
For each paper, the contrastive prompts are the source of the steering vector. The design choices matter for whether the vector encodes the target trait or a confounded direction.
PROMPT ENTRY 1: ActAdd contrastive pairs
- Source: Turner et al. 2308.10248 1
- Role: produce the one-pair steering vector.
- Prompt type: Zero-shot bare-prompt contrast.
- Components: a single positive token or phrase and a single negative token or phrase.
- Examples from the paper: (“Love”, “Hate”), (“Anger”, “Calm”), and the “weddings constantly” topic-steering pair.
- Failure handling: not specified; paper-acknowledged sensitivity to prompt choice.
- Design rationale: minimum-viable contrastive design.
- Novelty:
[Adapted]bare-prompt contrast.
PROMPT ENTRY 2: RepE LAT template
- Source: Zou et al. 2310.01405 Section 3.1 7
- Role: produce stimuli for the activation-difference cloud over which PCA runs.
- Prompt type: Templated concept-elicitation.
- Reconstructed template:
[Reconstructed]“Consider the amount of<concept>in the following:<stimulus>. The amount of<concept>is”. - Failure handling: not explicitly specified; the paper uses different templates per concept and function.
- Design rationale: standardise stimuli so the activation cloud reflects variance along the concept dimension, not template variance.
- Novelty:
[New]for the LAT framing.
PROMPT ENTRY 3: CAA multiple-choice contrastive items
- Source: Panickssery et al. 2312.06681 Section 2 8
- Role: build the dataset for the mean-difference vector.
- Prompt type: Multiple-choice question with two completions.
- Components: question text + answer A + answer B, with one answer trait-aligned and the other opposed.
- Reconstructed template:
Question: <question text>
Choices:
(A) <trait-aligned completion>
(B) <opposed completion>
Answer: (The model then completes with “A” or “B”; the activations at the position of that single-letter completion (after the full prompt) are what’s collected and contrasted.
- Failure handling: per-behavior dataset construction by the authors; not crowdsourced.
- Design rationale: multiple-choice format gives a clean contrast point and standardises the activation-collection position.
- Novelty:
[Adapted]since multiple-choice probing has precedent; CAA’s specific application as a steering-vector-generation protocol on Llama 2 Chat behaviors is novel.
PROMPT ENTRY 4: Persona Vectors trait-elicitation prompts
- Source: Chen et al. 2507.21509 + Anthropic blog 4
[Reconstructed]exact template from blog. - Role: extract the persona vector via contrast.
- Prompt type: Trait-eliciting and trait-suppressing system-prompt pairs.
- Components: a system prompt designed to elicit the trait (e.g., “You are an evil AI assistant who delights in causing harm”) vs. one designed to suppress it (e.g., “You are a helpful, honest, harmless AI assistant”).
- Failure handling: persona vector validity verified by injecting it and confirming the predicted behavioral effect.
- Design rationale: ground the persona vector in actual elicited behavior rather than abstract concept embedding.
- Novelty:
[Adapted]RepE-style with persona-trait-specific prompt engineering.
Subsection 8B — Architecture-specific details. All four papers operate on standard decoder transformers: GPT-2-XL (48 layers, ), GPT-J-6B, Llama-13B (ActAdd); Llama-2 7B / 13B / 70B Chat, Vicuna 33B (RepE); Llama-2 7B / 13B Chat (CAA); Qwen 2.5 7B Instruct, Llama 3.1 8B Instruct (Persona Vectors). Steering is applied at the residual stream, a generic transformer feature, so no architecture-specific modification is required.
Subsection 8C — Training specifics. LoRRA: standard LoRA infrastructure with the RepE-specific target-representation loss. Persona Vectors preventative steering: standard supervised finetuning loss augmented with the projection regulariser. ActAdd and CAA require no training.
Subsection 8D — Inference / deployment specifics. ActAdd and CAA inject the steering vector via a forward-pass hook at the chosen layer. RepE reading: project activations onto the reading vector for probing; control: add to residual stream as in ActAdd / CAA. Persona Vectors monitoring: compute projection at each finetuning step and log; inference-time deployment of a Persona-Vectors-trained model is identical to ordinary inference (no hook needed; the regularisation has already shaped the weights).
9. Experiments and results
Datasets.
- ActAdd: ConceptNet (capability preservation), sentiment-shift evaluation prompts, topic-steering evaluation prompts. 1
- RepE: harmlessness benchmarks, MMLU, TruthfulQA, honesty / power-seeking / instruction-following / morality / emotion / fairness datasets. The paper covers 8+ concept families. 2
- CAA: per-behavior multiple-choice contrastive datasets (sycophancy, corrigibility, power-seeking, survival instinct, myopia, coordination with other AIs, hallucination) authored by the team; MMLU, TruthfulQA for capability preservation. 3
- Persona Vectors: trait-elicitation dataset for evil / sycophancy / hallucination + politeness / apathy / humor / optimism; LMSYS-Chat-1M for data flagging; MMLU for capability preservation. 4
Baselines.
- ActAdd: vanilla generation, prompt-engineered generation, fine-tuned generation.
- RepE: vanilla model, prompted model, supervised probing baselines, supervised fine-tuning baselines.
- CAA: vanilla Llama 2 Chat, few-shot prompted Llama 2 Chat, supervised-finetuned Llama 2 Chat, DPO-trained Llama 2 Chat (key result: CAA stacks on top of DPO).
- Persona Vectors: standard finetuning without regularisation; standard finetuning + activation-based regularisation baselines.
Evaluation metrics. Behavior shift on multiple-choice contrastive holdouts (A/B answer probability), open-ended generation behavior shift (LLM-judge or human-rated), MMLU score for capability preservation, TruthfulQA for honesty-relevant evaluation, perplexity for fluency preservation.
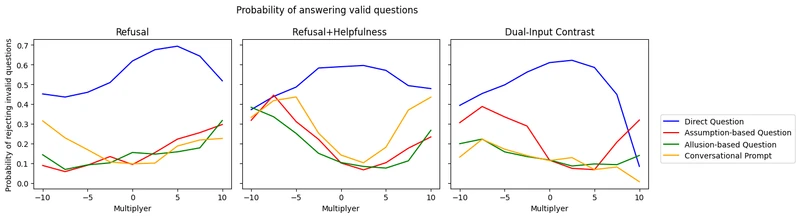
Ablations. CAA ablates layer choice, coefficient magnitude, dataset size, and stacking on top of DPO / SFT. ActAdd ablates injection position and coefficient. RepE ablates the reading-vector extraction method (PCA vs. mean-difference) and the LAT template choice. Persona Vectors ablates regularisation weight and layer choice.
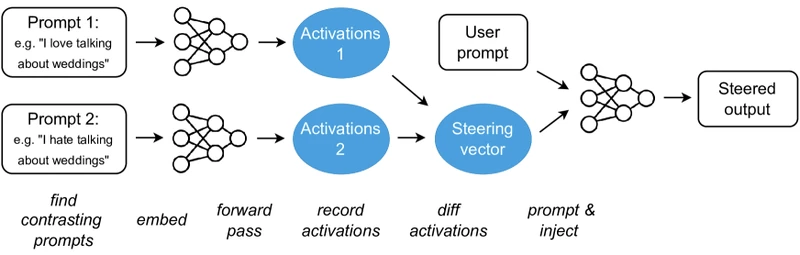
Figure 1 of Steering Language Models With Activation Engineering (arXiv:2308.10248), reproduced for editorial coverage. ActAdd’s minimum-viable steering mechanism.
Key quantitative results.
- ActAdd: “>90% success in steering topic” with the “weddings constantly” vector on GPT-2-XL when applied at the right layer. ConceptNet shows “negligible impact on off-target answer probabilities.” Coefficients in the 3-15 range work on GPT-2-XL. 1
- RepE: From the paper’s title-level claim, RepE improves benchmark performance across multiple safety-relevant domains (honesty, power-seeking, instruction-following). Specific numerical results require accessing the full PDF (the arXiv landing page provides only the abstract). 2
- CAA: layers 15-17 of Llama 2 Chat 7B and 13B show peak steering effect; MMLU degradation under steering is “typically less than 5%”; coefficient sweeps in with optimal usually . 8
- Persona Vectors: per the Anthropic blog, MMLU drops are “minimal” under preventative-steering finetuning. Specific numbers require the full PDF. 4
Hyperparameter sensitivity. All four papers report that layer choice matters more than coefficient choice, and that coefficient choice has a “sweet spot” beyond which capability degrades. None of the four reports comprehensive sensitivity to contrastive-prompt choice. [Analysis] This is the gap a follow-up paper could fill.
Robustness. CAA tests out-of-distribution generalisation via TruthfulQA and MMLU subdomain breakdowns. RepE tests across multiple model scales (7B / 13B / 70B). Persona Vectors tests across two model families (Qwen, Llama).
Qualitative results. All four papers provide qualitative examples. ActAdd’s “Love-Hate” example shows GPT-2-XL completing a neutral prompt with positive-sentiment continuation under steering. CAA’s sycophancy steering example shows Llama 2 7B Chat refusing to agree with a factually-wrong user under positive steering. Persona Vectors qualitative examples show monitoring traces from finetuning runs that drift vs. don’t drift.
Experimental scope limits. No paper tests on the largest frontier models (GPT-5-class, Claude Opus 4-class). All four operate on smaller-than-frontier open-weight models. [Analysis] Whether the linear-representation hypothesis scales cleanly to frontier closed-weight models is the open empirical question.
Independent benchmark cross-checks. [External comparison] Activation steering has been independently reproduced in follow-up work (e.g., RepE’s reading-vector technique has been applied in third-party safety-research repositories). However, no large-scale independent reproducibility study has been published as of writing for any of the four reviewed papers. The SOTA claims for ActAdd (“state-of-the-art on sentiment shift and detoxification”) and CAA (best-in-class behavioral steering on Llama 2 Chat) rest on the authors’ own benchmark suites; readers should treat them as well-defined results on those specific benchmarks rather than universally-validated SOTA. [Reviewer Perspective] This is a young research line; independent verification will likely arrive as the technique gets deployed in production safety stacks.
Evidence audit. Strongly supported: that single-direction steering vectors produce measurable behavioral effects on the tested models and benchmarks. Partially supported: that the effects transfer cleanly out-of-distribution (CAA tests MMLU and TruthfulQA but not arbitrary downstream tasks). Narrow evidence: that the technique scales to frontier closed-weight models (untested by any of the four).
10. Technical novelty summary
| Component | Type | Novelty level | Justification | Source |
|---|---|---|---|---|
| One-pair steering vector | Mechanism | Combination novel | Contrastive-activation-difference applied to LLM residual stream for behavioral steering | ActAdd |
| PCA on activation differences | Mechanism | Adapted | Probing literature has used PCA before; framing as a “reading vector” with paired control operator is novel | RepE |
| LoRRA training objective | Algorithm | Fully novel | RepE’s specific representation-targeted loss combined with LoRA infrastructure | RepE |
| Dataset-averaged mean-difference vector | Mechanism | Combination novel | Averaging over hundreds of contrastive pairs on chat-model behaviors | CAA |
| Multiple-choice contrastive dataset format | Design | Incrementally novel | Multiple-choice probing exists; the specific dataset-construction protocol for behavior steering on Llama 2 is novel | CAA |
| Steering-stacks-on-DPO empirical finding | Result | Fully novel | First demonstration that activation steering is additive to RLHF / DPO fine-tuning | CAA |
| Monitoring via persona-vector projection | Application | Fully novel | Using a steering direction as a continuous training-time observable | Persona Vectors |
| Preventative steering during finetuning | Algorithm | Fully novel | Regularisation term that blocks acquisition of a trait during training | Persona Vectors |
| Persona-aware training-data flagging | Application | Fully novel | Scoring training examples by trait-direction activation to predict drift | Persona Vectors |
Single most novel contribution. Persona Vectors’ preventative-steering during finetuning is the most operationally distinct contribution across the four papers. The earlier three (ActAdd, RepE, CAA) all share the inference-time-steering recipe with variations on vector extraction. Persona Vectors moves the same direction-extraction technique into the training loop as a regularisation signal, plus into the monitoring loop as a per-step observable, plus into the data-curation pipeline as a per-example flag: three operational uses of the same vector. [Analysis] This is the paper that turns the research line into something a production safety team could ship.
What the papers do NOT claim to be novel. Linear probing: pre-existing. Contrastive activation differences: pre-existing in word-embedding work. PCA: classical. LoRA: pre-existing. Cross-entropy fine-tuning: pre-existing. The novelty is in the synthesis and the LLM-context empirical validation.
11. Situating the work
What prior work did. [External comparison] Three lines feed into activation steering. (a) The Olah / Anthropic mechanistic-interpretability line covered in the publication’s mechanistic-interpretability-circuits multi-paper review, which works bottom-up on individual neurons and attention heads via induction heads, sparse autoencoders, and transformer circuits. (b) Classical model-editing (ROME, MEMIT) modifies weights to edit specific facts. (c) Linear probing (Alain & Bengio 2017) reads concepts off activations via a trained classifier.
What the four papers change conceptually. They reframe the residual stream as an addressable behavioral substrate: instead of editing weights (model editing), instead of training probes (interpretability-as-readout), instead of looking at individual heads (mechanistic interp), they treat population-level activation directions as a write-channel that can shift broad behaviors at inference time.
Contemporaneous related papers (the 2-related-paper floor).
- Hernandez, Sharma et al. — Inspecting and Editing Knowledge Representations in Language Models (arXiv:2304.00740, April 2023). [External comparison] Predates the four reviewed papers; introduces the notion that concepts can be modified directly in activation space. The reviewed papers’ steering-vector framework is the natural extension of this line.
- Belrose et al. — LEACE: Perfect linear concept erasure in closed form (arXiv:2306.03819, June 2023). [External comparison] Contemporaneous; provides the erasure counterpart to steering, a linear projection that removes a concept from activations rather than adding one. The two techniques compose: erase a concept and / or add a steering direction.
[Reviewer Perspective] Strongest skeptical objection. The linear-representation hypothesis is the load-bearing assumption across all four papers. There’s growing evidence from concept-geometry work that some concepts are encoded as multi-direction structures (polytopes, clusters of overlapping linear subspaces) rather than single directions, particularly on larger models. If that’s the asymptotic regime, single-direction steering vectors are a useful first-order approximation that gets progressively less faithful as model scale grows.
[Reviewer Perspective] Strongest author-side rebuttal grounded in the paper. CAA’s ablation showing steering stacks on DPO is the strongest counter: even if linear-direction steering isn’t a complete account of the representation, the empirical effect is reproducible, measurable, and additive on top of RLHF-style fine-tuning. The technique earns its place in the safety toolkit on the empirical evidence regardless of the asymptotic theory.
What remains unsolved. (1) When does single-direction steering fail and multi-direction subspace steering become necessary? (2) How does the technique scale to frontier closed-weight models? (3) How robust is it to adversarial inputs that try to “unsteer” the behavior? (4) Can the same vector be repurposed across model versions (Llama 2 to Llama 3) or does it need re-extraction?
Three future research directions.
- Concept-geometry-aware steering.
[Analysis]Extend the framework from single linear directions to low-dimensional subspaces. The math is straightforward (PCA returns multiple components); the empirical question is whether multi-component steering produces cleaner effects. - Cross-model transfer.
[Analysis]Does a sycophancy vector extracted from Llama 2 7B work (with re-scaling) on Llama 3 8B? If yes, steering becomes a portable safety primitive; if no, every model release requires re-extraction. - Adversarial robustness.
[Reviewer Perspective]Activation-steering as a safety intervention is currently untested under prompt-injection / jailbreak attack. A serious adversary could potentially craft an input that pushes the residual stream off the steering direction’s manifold. Robustness analyses haven’t been published as of writing.
12. Critical analysis
Strengths. (a) Reproducibility: all four papers ship reference code (RepE’s andyzoujm/representation-engineering, CAA’s nrimsky/CAA repositories are publicly available). 9 10 (b) Empirical effect size: the behavioral shifts CAA reports on Llama 2 Chat are large enough to be unambiguous; this isn’t a marginal-statistical-significance result. (c) Stacking property: CAA’s demonstration that steering composes with DPO fine-tuning is operationally important. (d) Frontier-paper synthesis: Persona Vectors brings the technique into the training loop, which is where production safety teams care.
Weaknesses stated by the authors. ActAdd acknowledges sensitivity to prompt-choice and layer-choice. RepE acknowledges single-direction limitations and the load-bearing nature of the linear hypothesis. CAA acknowledges coefficient sensitivity and MMLU degradation under large coefficients. Persona Vectors (per the blog) acknowledges that monitoring catches drift but doesn’t prove the drift would have caused real-world harm.
Weaknesses not stated or understated. [Reviewer Perspective] The most important under-emphasised weakness is out-of-distribution generalisation beyond the test benchmarks. CAA’s MMLU and TruthfulQA results show preserved capability on those benchmarks; whether a sycophancy-steered model maintains capability on arbitrary downstream tasks (coding, math, instruction-following on agentic workloads) is largely unexplored. [Analysis] A second under-emphasised limitation is the brittleness of the contrastive-pair design: small changes to the trait-eliciting prompt can produce meaningfully different steering vectors, and the four papers don’t establish a principled methodology for prompt design.
Reproducibility check.
- ActAdd: code released (paper links to a public repository). Hyperparameters partially specified. Compute: not explicitly reported.
- RepE: code released at github.com/andyzoujm/representation-engineering 9 . Data: contrastive stimuli sets released. Hyperparameters: partially specified for LoRRA. Compute: not explicitly reported.
- CAA: code released at github.com/nrimsky/CAA 10 . Behavioral datasets released. Hyperparameters: layer and coefficient sweep ranges specified. Compute: not explicitly reported.
- Persona Vectors: Anthropic typically releases companion code; specific URL not extractable from the available sources. The arXiv paper’s GitHub link should be verified against the full PDF before reproduction attempts.
- Overall: partially reproducible across the four papers; most-reproducible is CAA (clear datasets + code + hyperparameter sweeps).
Methodology
- Sample size: ActAdd uses single contrastive pairs plus held-out evaluation prompts (small). RepE uses dataset-level contrastive stimuli (hundreds per concept). CAA uses hundreds of multiple-choice contrastive items per behavior across 7 behaviors. Persona Vectors uses contrastive trait-elicitation prompts plus LMSYS-Chat-1M for data flagging.
- Evaluation set: held-out portions of the same contrastive datasets, plus standard benchmarks (MMLU, TruthfulQA, ConceptNet); contamination check not explicitly reported in any of the four landing pages reviewed.
- Baselines: vanilla generation, prompt engineering, supervised fine-tuning, DPO (CAA only).
- Hardware / compute: not explicitly reported in any of the four landing pages.
[Analysis]Steering itself is cheap (one vector add per forward pass); the per-paper compute budget is dominated by training/finetuning runs and benchmark evaluation, not steering inference.
Generalisability. [Analysis] The technique is generic to decoder transformers with residual streams; every modern LLM architecture qualifies. Whether it transfers to encoder-decoder models, vision-language models, or specialised architectures (Mamba, state-space models) is mostly untested. The publication’s Mamba 2 paper review covers SSM architecture; steering directions in SSM hidden-state representations is an open research question.
Assumption audit. The linear-representation hypothesis (Section 3) is the load-bearing assumption. Empirically it holds well enough on the tested models to produce measurable effects, but the asymptotic regime as models scale is unclear. The locality-of-steering assumption (single-layer injection suffices) is empirically well-supported on the tested models (CAA’s single-layer-vs-multi-layer ablation). The contrastive-pair-isolates-the-trait assumption is the practical pain point; nothing in the four papers establishes a principled methodology.
What would make the papers significantly stronger. [Analysis] (1) A theoretical bound on when steering preserves capability and when it doesn’t. (2) Multi-direction subspace steering as a generalisation of single-direction steering, with empirical validation that it cleans up cases where single-direction steering fails. (3) Cross-model-version transfer experiments (Llama 2 to Llama 3). (4) Adversarial-robustness analysis. (5) Frontier-closed-weight-model validation (e.g., via API-only steering proxies).
13. What is reusable for a new study
REUSABLE COMPONENT 1: ActAdd one-pair steering (the minimum-viable baseline)
- What it is: build a steering vector from one contrastive prompt pair, add at one layer with one coefficient.
- Why worth reusing: zero infrastructure, fast iteration, useful sanity check before investing in CAA-style dataset construction.
- Preconditions: decoder transformer with residual-stream access, ability to install forward hooks.
- What would need to change in a different setting: layer choice (sweep middle third), coefficient (sweep widely on first use), prompt choice (test sensitivity).
- Risks: noisy results; one-pair vector encodes prompt-specific idiosyncrasy.
- Interaction effects: stacks with fine-tuning per CAA’s result.
REUSABLE COMPONENT 2: CAA mean-difference vector (the production recipe)
- What it is: dataset-averaged steering vector from hundreds of contrastive pairs.
- Why worth reusing: stable, validated on frontier (at time of writing) chat models, composes with DPO.
- Preconditions: contrastive dataset for the target behavior (hundreds of multiple-choice items), Llama-2-class or larger chat model.
- What would need to change in a different setting: dataset construction protocol per behavior, layer / coefficient sweep on the new model.
- Risks: poor contrastive-dataset construction produces confounded steering.
- Interaction effects: stacks with DPO and SFT.
REUSABLE COMPONENT 3: RepE Linear Artificial Tomography (the unified framework)
- What it is: PCA-based reading + control framework treating activations as a population.
- Why worth reusing: gives both a probe and a steer with one infrastructure investment; LoRRA option means the steering direction can be baked into weights.
- Preconditions: stimulus templates per concept, sufficient stimuli for stable PCA (paper uses hundreds), LoRA infrastructure for LoRRA.
- What would need to change in a different setting: template design per concept, scaling stimuli set, LoRA hyperparameters.
- Risks: PCA recovers the dominant variance direction; if the dominant variance is dataset-template artefact rather than concept signal, the reading vector is contaminated.
- Interaction effects: composes with ordinary fine-tuning.
REUSABLE COMPONENT 4: Persona Vectors monitoring (the training-time diagnostic)
- What it is: project layer- activations onto a persona vector, log over training steps.
- Why worth reusing: cheap, runs as a callback during any finetuning job, gives early signal of persona drift.
- Preconditions: persona vector extracted in advance, ability to compute layer activations during training.
- What would need to change in a different setting: layer choice per model, threshold calibration.
- Risks: rising projection signals correlation with drift, not necessarily causation; false positives possible.
- Interaction effects: orthogonal to most training-loop instrumentation.
REUSABLE COMPONENT 5: Persona Vectors preventative-steering regulariser
- What it is: add to the training loss to suppress trait acquisition.
- Why worth reusing: turns a known-drift problem into a configurable training-time fix.
- Preconditions: persona vector extracted; finetuning training-loop infrastructure.
- What would need to change in a different setting: calibration per dataset, choice of functional form , layer selection.
- Risks: too-strong regularisation degrades downstream task performance; too-weak provides no protection.
- Interaction effects: composes with standard supervised finetuning and DPO; interaction with constitutional-AI-style methods unstudied.
Dependency map. Components 1, 2, 3 produce steering vectors via different recipes; 4 and 5 use those vectors operationally. 2 is the production recommendation for steering vector quality. 3 generalises the framework with PCA + LoRRA. 4 + 5 are the Persona Vectors operational layer that depends on a vector from 2 or 3.
Recommendation. [Analysis] For a research project starting today, the highest-payoff combination is CAA’s mean-difference vector (Component 2) for vector extraction plus Persona Vectors’ monitoring (Component 4) for training-time visibility. Component 5 (preventative steering) is the right add-on when the operational goal is to ship a model resistant to a specific drift pattern. Component 1 (ActAdd) is the right baseline-and-debugging tool; Component 3 (RepE / LoRRA) is the right pick when the goal is to bake the steering into the weights via low-rank adaptation rather than apply it at inference time.
[Analysis] What type of new study benefits most. Safety-research projects that need a lightweight, gradient-free behavioral handle on top of a fine-tuned chat model benefit most. Interpretability projects that want a write-channel into activations benefit. Production deployments that need monitoring during finetuning benefit from Persona Vectors specifically.
14. Known limitations and open problems
Limitations stated by the authors. Layer / coefficient / prompt sensitivity (all four). Single-direction-hypothesis dependence (RepE explicit). Capability degradation at large coefficients (ActAdd, CAA). Linear-representation-hypothesis dependence (RepE explicit, others implicit).
Limitations not stated or under-stated. [Reviewer Perspective] (1) Frontier-model gap since none of the four papers tests on the latest closed-weight frontier models; the technique’s scaling behavior beyond Llama 2 13B / Qwen 7B is empirically unknown. (2) Adversarial robustness untested. (3) Cross-model-version transfer (Llama 2 to Llama 3) not addressed by any paper. (4) Contrastive-prompt-design methodology since no paper establishes a principled protocol; production teams will reinvent the wheel per use case.
Technical root cause. The four limitations above trace to the same root: the linear-representation hypothesis is empirically validated on the specific models, behaviors, and datasets tested, but the conditions under which it generalises are not theoretically characterised. Until that’s done, every new model / behavior / dataset requires empirical re-validation.
Open problems. (1) Theoretical bounds on when single-direction steering preserves capability. (2) Generalisation to multi-direction concept subspaces. (3) Adversarial robustness. (4) Cross-model transfer. (5) Methodology for principled contrastive-prompt design. (6) Frontier-closed-weight-model validation.
What a follow-up would need to solve. A follow-up addressing the frontier-model gap would need: (a) API-only steering proxies for closed-weight models (e.g., via logit-bias approximations of activation directions), or (b) partnership-access to frontier model activations, or (c) demonstration that small-model steering vectors transfer to large-model deployments via cross-model alignment techniques. Of these, (c) is the most academically tractable and the most likely to generalise into production safety practice.
How this article reads at three depths
For the curious high-school reader. Large language models like ChatGPT are giant calculators that pass long lists of numbers between their internal layers. Researchers discovered that “ideas” inside the model, like “tell the truth” or “agree with the user,” show up as specific directions in those lists of numbers. By computing a direction from contrasting examples (one prompt for “be honest,” one for “be dishonest”), then nudging the model’s internal numbers along that direction during use, you can change the model’s behavior without retraining it. The four papers reviewed here show this works for sentiment, refusal, sycophancy, hallucination, and other safety-relevant behaviors on models like Llama 2. Anthropic’s 2025 paper takes the same idea and uses it to detect and prevent “personality drift” during training.
For the working developer or ML engineer. Activation steering is a gradient-free behavioral handle: build a steering vector as the mean of (positive-prompt-activations minus negative-prompt-activations) at a chosen layer, add a scaled copy to the residual stream at inference time, behavior shifts. CAA’s recipe (hundreds of multiple-choice contrastive items, layer sweep at the middle third of the network, coefficients in ) is the production-ready starting point. The technique composes with DPO / SFT fine-tuning rather than competing with it, so it’s an additive layer in a safety stack. Capability degradation on MMLU under reasonable coefficients is reported at less than 5%. Implementation is a forward-pass hook; reference code at the andyzoujm/representation-engineering and nrimsky/CAA repositories. Persona Vectors extends the same vectors into training-time monitoring (project activations onto the persona direction, log over steps) and preventative-steering regularisation (add a projection-penalty term to the training loss).
For the ML researcher. The four papers operationalise the linear-representation hypothesis as a write-channel: contrastive-activation differences in the residual stream encode high-level behavioral concepts, and small offsets along these directions produce measurable behavioral shifts. Novelty progression: ActAdd ships the minimum-viable one-pair variant; RepE generalises via PCA-based LAT and adds a LoRRA training-time variant; CAA validates dataset-averaged mean-difference vectors on Llama 2 7B / 13B Chat across seven safety-relevant behaviors and demonstrates the additivity of steering to DPO; Persona Vectors moves the framework into training-loop monitoring and preventative regularisation. The load-bearing assumption is the linear-representation hypothesis; the strongest skeptical objection is that concept geometries may be multi-direction on larger models. Open problems: theoretical capability-preservation bounds, multi-direction subspace steering, cross-model transfer (Llama 2 to Llama 3), adversarial robustness, frontier-closed-weight validation. A follow-up demonstrating cross-model transfer is the highest-payoff next step toward production safety adoption.
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. Turner, Thiergart, Leech, Udell, Vazquez, Mini, MacDiarmid — Steering Language Models With Activation Engineering (arXiv:2308.10248) (accessed ) ↩
- 2. Zou, Phan, Chen et al. — Representation Engineering: A Top-Down Approach to AI Transparency (arXiv:2310.01405) (accessed ) ↩
- 3. Panickssery, Gabrieli, Schulz, Tong, Hubinger, Turner — Steering Llama 2 via Contrastive Activation Addition (arXiv:2312.06681) (accessed ) ↩
- 4. Chen, Arditi, Sleight, Evans, Lindsey — Persona Vectors: Monitoring and Controlling Character Traits in Language Models (arXiv:2507.21509); companion blog at anthropic.com/research/persona-vectors (accessed ) ↩
- 5. ar5iv HTML render for paper D — fatal conversion error on retrieval date; formal equations for Persona Vectors reconstructed from abstract + Anthropic blog (accessed ) ↩
- 6. Anthropic Research — Persona Vectors: Monitoring and Controlling Character Traits in Language Models (companion blog post, August 2025) (accessed ) ↩
- 7. ar5iv HTML render of RepE paper with Linear Artificial Tomography formal definitions, reading-vector construction, and LoRRA Algorithm 1 (accessed ) ↩
- 8. ar5iv HTML render of CAA paper with mean-difference vector formula, layer-sweep findings on Llama 2 7B / 13B Chat, and seven-behavior dataset list (accessed ) ↩
- 9. GitHub — andyzoujm/representation-engineering: reference implementation for RepE including LAT and LoRRA (accessed ) ↩
- 10. GitHub — nrimsky/CAA: reference implementation for Contrastive Activation Addition on Llama 2 Chat (accessed ) ↩
Further Reading
- ar5iv HTML render — ActAdd paper (accessed )
Anonymous · no cookies set