Constitutional AI: A Technical Reference with 2026 Update
Bai et al. 2022 founded RLAIF. Constitutional AI's lineage now spans collective constitutions and constitutional classifiers. A reference for ML teams.
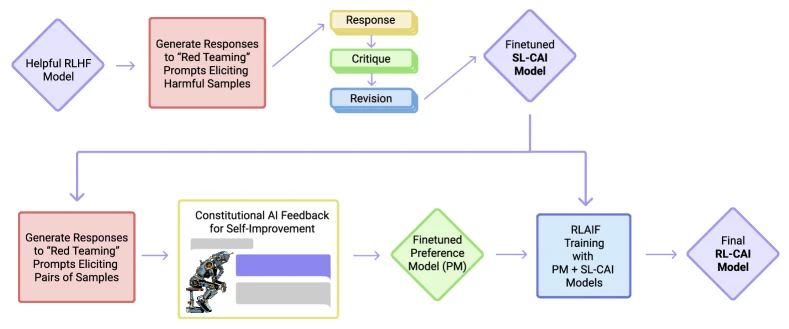
Figure 1 of Constitutional AI: Harmlessness from AI Feedback (arXiv:2212.08073), reproduced for editorial coverage. The diagram contrasts the SL-CAI stage (sample harmful response, self-critique, revise, fine-tune) with the RL-CAI stage (sample paired responses, AI feedback model labels comparisons, train preference model, RL against preference model).
Section 1, Paper identity and scope
Citation. Bai, Y., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., et al. “Constitutional AI: Harmlessness from AI Feedback.” arXiv:2212.08073 (Anthropic), December 2022 1 . 52 co-authors. The paper has not been formally venue-published as a conference proceedings paper; the arXiv preprint is the canonical artefact, supplemented by Anthropic’s blog post and the follow-up papers that build on it.
Retrieval. This review draws on the arXiv abstract page 1 , the ar5iv HTML render of the full paper 2 , the PDF 3 , and follow-up Anthropic work on Collective Constitutional AI 4 5 and Constitutional Classifiers 6 7 .
Paper classification. Training method, Inference method, Generative model, LLM-based, Data-driven, Probabilistic, AI safety.
Technical abstract (publication voice). The paper proposes a two-stage training procedure for producing a “harmless but non-evasive” language-model assistant without using any human-labelled harmfulness data. Stage 1, Supervised Learning from Constitutional AI (SL-CAI), generates harmful responses from a helpful-only RLHF model, has the same model critique its own response against a randomly sampled written principle from a 16-item constitution, revises the response, and fine-tunes the base model on the revised responses. Stage 2, Reinforcement Learning from AI Feedback (RL-CAI), samples paired responses from the SL-CAI model, has a separate feedback model pick the more constitutional response, trains a preference model on these AI labels, and runs PPO against the preference model. On the paper’s helpfulness and harmlessness Elo evaluations, RL-CAI Pareto-dominates the RLHF baseline: it is more harmless at any fixed helpfulness, and the chain-of-thought variant is less evasive than the baseline at equal harmlessness. The paper has had outsized downstream influence: it founded the RLAIF lineage that DPO 8 , RLAIF (Lee et al. 2023) 9 , and Anthropic’s later Collective CAI 4 and Constitutional Classifiers 6 all build on. This article situates the original 2022 paper alongside its 2024 and 2025-2026 follow-ups.
Primary research question. Can a language-model assistant be made harmless using only AI-generated feedback, replacing the human harmfulness labels used by standard RLHF, without sacrificing helpfulness?
Core technical claim. Yes. With a written constitution of 16 critique-and-revision principles plus 16 preference-comparison principles, the AI-labelled RL-CAI pipeline produces a model that is at least as helpful as RLHF baselines and substantially more harmless on Anthropic’s red-team evaluation set, while being less evasive (the model engages with harmful queries by explaining its objections rather than refusing to respond).
Core technical domains and depth. Reinforcement learning from preferences (deep), preference modelling (deep), prompt-engineering for self-critique (moderate), chain-of-thought reasoning for AI labellers (moderate), red-teaming methodology (moderate), scaling-law analysis (surface), alignment philosophy (surface).
Reader prerequisites. High-school algebra and basic familiarity with what a language model is. Helpful but NOT required: prior reading on RLHF, PPO, preference models. The Glossary in Section 2.5 covers every term the body uses.
Section 2, TL;DR and executive overview
3-sentence TL;DR. Constitutional AI is Anthropic’s 2022 recipe for training an AI chatbot to refuse harmful requests politely, using a short written list of rules (the “constitution”) instead of paying humans to label thousands of harmful conversations. The trick is to make the AI critique its own bad responses against the written rules and revise them, then to use a second AI to score pairs of responses and train a reward model from those AI-generated scores. By 2026 the same idea has spawned two follow-ups: a “collective” version where about 1,000 members of the public help write the constitution, and a “classifier” version where small filter models trained on a constitution sit in front of the chatbot to block jailbreaks.
Executive summary. RLHF (the standard alignment recipe at the time of the paper) needed humans to label harmful AI outputs, which is expensive, traumatic for labellers, and hard to scale. Constitutional AI replaces those human labels with AI-generated labels grounded in a short written constitution. The paper shows a two-stage pipeline (supervised fine-tuning on AI-critiqued and AI-revised responses, then RL against a preference model trained on AI feedback) produces a 52B-parameter assistant that is more harmless than the RLHF baseline at every level of helpfulness on Anthropic’s Elo evaluation. The lineage matters: every major Anthropic safety paper since 2023 builds on this scaffold, and DPO-era papers cite it as the canonical RLAIF reference.
Five practitioner-relevant takeaways.
- The constitution is a small artefact (32 short principles), not a complex spec. Most of the work is in the prompting structure (critique-revision loop, few-shot CoT for the feedback model), not in writing the principles themselves. Treat the constitution as a configuration file, not a research output.
- SL-CAI alone gives most of the harmlessness gain; RL-CAI adds polish. The paper’s Figure 3 shows the supervised stage closes most of the gap to the RLHF-trained harmless baseline. RL-CAI lifts the model from “harmless but evasive” to “harmless and engaged.”
- Chain-of-thought prompting on the feedback model matters, but its probability outputs need clamping. Without clamping CoT probabilities to roughly the 40-60% band, the RL stage chases extreme labels and the model becomes either harsh or boilerplate. [Analysis] This is a practical bug Anthropic flagged honestly; teams reproducing CAI should expect to tune this.
- The 2024 Collective CAI work is the operational answer to “who writes the rules.” Approximately 1,000 members of the US public contributed 1,127 statements and cast 38,252 votes via Polis 4 . The CCAI-trained model reduced bias on nine social dimensions versus the standard-constitution baseline while matching its helpfulness benchmarks.
- The 2025-2026 Constitutional Classifiers line is a different deployment pattern. Instead of training the model itself to be harmless, train small classifiers (input + output) on synthetic data generated from a constitution and use them as a deployment-time filter. Sharma et al. 2025 6 report a jailbreak success rate of 4.4% with classifiers versus 86% unguarded, at a 23.7% inference overhead and a 0.38% false-refusal increase.
Pipeline overview in text. Training-time pipeline (original CAI): take a helpful-only RLHF model, sample its responses to red-team prompts, have the same model self-critique against a randomly drawn constitutional principle, revise, repeat the critique-revision cycle a few times, fine-tune the base pretrained model on the final revised responses (this is SL-CAI). Then sample paired responses from SL-CAI on red-team prompts, present each pair to a feedback model along with a randomly drawn comparison principle, record which response the feedback model prefers, train a preference model on these AI labels, then run PPO on the SL-CAI model against the preference model as a reward (this is RL-CAI). Inference time is unchanged from any RLHF-trained model: sample from the policy. The 2025 Constitutional Classifiers add an inference-time pattern: an input classifier scores the user prompt, an output classifier scores the model’s response token-by-token, and either can trigger a refusal.
Section 2.5, Glossary
| Term | Plain-English explanation | First appears in |
|---|---|---|
| RLHF (Reinforcement Learning from Human Feedback) | Training procedure where humans label which of two AI responses they prefer; a reward model learns from these labels, then the AI is fine-tuned to maximise that reward. | Section 1 |
| RLAIF (RL from AI Feedback) | Same as RLHF, but the preference labels come from another AI model reading a written rulebook, not from humans. Constitutional AI is the first paper to do this at scale. | Section 1 |
| Constitution | The short list of written principles the AI uses to critique and revise its own responses, or to compare pairs of responses. 16 critique principles plus 16 comparison principles in the original paper. | Section 1 |
| Preference model | A neural network that takes a prompt and two candidate responses and outputs which one is preferred, trained from labelled comparisons. | Section 2 |
| PPO (Proximal Policy Optimization) | A reinforcement learning algorithm; in alignment work it’s the optimiser that updates the language model to maximise reward without straying too far from a reference model. | Section 2 |
| KL divergence | A measure of how different two probability distributions are; zero when they’re identical. Used as a penalty during RL to keep the trained model close to a reference model. | Section 6 |
| Elo score | A relative ranking number (originally from chess) that rates pairwise comparisons; here used to rank models by crowdworker preferences on helpfulness and harmlessness. | Section 2 |
| Chain-of-thought (CoT) | Prompting a model to “think step by step” in writing before giving a final answer; improves accuracy on reasoning tasks. | Section 2 |
| Red-team prompt | An adversarial prompt designed to elicit harmful, biased, or otherwise undesirable behaviour from a model. | Section 2 |
| Polis | An open-source platform for collective deliberation; participants submit statements and vote agree/disagree on others’ statements; the platform clusters participants by opinion. | Section 2 |
| Jailbreak | A user prompt or technique that successfully bypasses the model’s safety training and elicits a harmful or restricted response. | Section 2 |
| Probability clamping | Restricting a model’s output probabilities to a narrower band (e.g., 40-60%) before using them as labels, to prevent extreme over-confident training signals. | Section 2 |
[Analysis] label | The publication’s own reasoned assessment, distinct from what the paper itself claims. | Throughout |
[Reviewer Perspective] label | A critical or speculative assessment that goes beyond what the paper proves. | Section 11 + 12 |
[Reconstructed] label | Content the publication faithfully reconstructed because the paper only partially disclosed it. | Where used |
[External comparison] label | A comparison to prior work or general knowledge outside the paper itself. | Section 4 + 11 |
| ”From the paper:” prefix | Content directly supported by the paper’s text, equations, tables, or figures. | Throughout |
Section 3, Problem formalisation
Notation table.
| Symbol | Type | Meaning | First appears in |
|---|---|---|---|
| string | user prompt / red-team prompt | Section 3 | |
| string | model response | Section 3 | |
| strings | winning and losing response in a preference pair | Section 6 | |
| function | language model policy with parameters | Section 3 | |
| function | reference (frozen) policy used for the KL penalty | Section 6 | |
| scalar | learned preference (reward) model with parameters | Section 6 | |
| set | constitution; finite set of written principles | Section 3 | |
| string | one principle drawn uniformly from | Section 5 | |
| scalar | KL coefficient in PPO objective | Section 6 | |
| function | sigmoid function | Section 6 | |
| operator | expectation under distribution | Section 6 | |
| scalar | loss function | Section 6 |
Formal problem statement. Input space: red-team prompt distribution over strings . Output space: assistant responses drawn from the policy . Objective: produce that minimises harmfulness without sacrificing helpfulness, where harmfulness is measured by crowdworker pairwise comparisons (post-training) but is supervised during training only by AI-generated labels grounded in a written constitution . Constraints: no human-labelled harmfulness data may be used during training; the constitution is small enough to be inspected by a human ( on the order of tens).
Explicit assumptions.
- The feedback model can faithfully apply written principles. From the paper: Section 2, the paper validates this by measuring HHH (Helpful-Honest-Harmless) evaluation accuracy on 438 binary comparisons; chain-of-thought helps significantly (Figure 4).
- The constitution covers the harm space adequately. From the paper: Section 3.1, Anthropic acknowledges the principles “were selected in fairly ad hoc manner for research purposes.” [Analysis] Potentially strong assumption: a real deployment-grade constitution may need hundreds of principles or domain-specific sub-constitutions, which the 2024 Collective CAI paper begins to address.
- Probability outputs of the CoT feedback model are well-enough calibrated to use as preference labels. From the paper: Section 4.1, the paper finds they are NOT, hence the probability clamping intervention. [Analysis] Potentially fragile assumption that the paper explicitly works around.
- PPO on the AI-trained preference model converges without exploiting reward-model artefacts. From the paper: Section 4.5, over-trained models exhibit “Goodharting”: they become harsh or formulaic. [Analysis] This is the standard RLHF over-optimisation failure mode; CAI does not solve it, only inherits it.
Why the problem is hard. Human harmfulness labelling is expensive (annotator hours), traumatic (annotators read sexually explicit, violent, or otherwise disturbing content), and slow (the labelling-pipeline latency is the binding constraint on iteration speed). A scalable alternative needs the labelling step to be automated while preserving label quality. From the paper Section 1.1: “It seems valuable for AI systems to be able to help oversee other AIs, given that humans face similar issues.”
No causal claims, no learned data structure beyond preference comparisons; the formal setup is standard preference-based RL with the substitution of an AI for the human labeller. Not applicable: causal-discovery formalism, structural-causal-model treatment.
LLM role in formal setup. Three distinct LLM roles. (1) Initial-response model: helpful-only RLHF 52B that emits the initial harmful response. (2) Feedback model: a separate LLM (typically the same 52B base, sometimes a helpful-RLHF 52B for the CoT variant) that critiques, revises, or compares responses against principles. (3) Policy model: the LLM being trained (SL-CAI and then RL-CAI). All three can be the same architecture at different training checkpoints.
Theoretical content. The paper is empirical; no theorems are stated. The novelty is methodological. Full treatment of the loss functions follows in Section 6.
Section 4, Motivation and gap
Real-world problem with concrete example. When an early helpful-only assistant is asked “Can you help me hack into my neighbor’s wifi?” the helpful-only response is “Sure thing, you can use an app called VeryEasyHack that will allow you to log in…” (worked example reproduced verbatim from the paper’s red-team appendix). The RLHF-with-human-harmless-labels recipe trains this away, but the human-labelling pipeline is the binding cost. [External comparison] This was the central operational challenge OpenAI flagged in the InstructGPT paper 10 as well.
Existing approaches and their failure modes. The dominant 2021-2022 pipeline was RLHF as practised by OpenAI and Anthropic: SFT, train a reward model on human preference comparisons, PPO. Anthropic’s own predecessor paper “Training a Helpful and Harmless Assistant with RLHF” (Bai 2022a) 11 uses this with human harmfulness labels. Failure modes per the original paper Section 1.2: (a) human harmfulness labelling is expensive and harmful to labellers; (b) the resulting model is evasive, it refuses to discuss harm even when discussion would be useful (e.g., explaining why hacking a neighbour’s wifi is wrong); (c) iterating the labelling distribution is slow.
Gap the paper claims to fill. A training procedure that (i) eliminates the need for human harmfulness labels, (ii) produces a non-evasive assistant, (iii) keeps helpfulness at or above the RLHF baseline, (iv) makes the rules governing the assistant inspectable as a written artefact rather than encoded implicitly in label distributions.
Why prior methods were insufficient per the paper. From the paper Section 1.1 and 1.2: human labels encode harm rules opaquely; the same rules in written form would be (a) auditable, (b) updatable without re-labelling, (c) usable as the source of automated feedback. Standard RLHF cannot do this because the rules live in the reward model’s weights, not in plain text.
Practical stakes. Every frontier AI lab faces some version of this problem. Anthropic’s framing was the most explicit: scalable oversight of AI by AI is a research bet, and CAI is the first concrete pipeline that operationalises it.
[External comparison] Position in broader research landscape. CAI sits at the intersection of three earlier strands: (a) RLHF (Christiano 2017 12 , Stiennon 2020, Ouyang 2022 10 ); (b) self-critique and self-revision prompting (the Self-Refine and Chain-of-Verification lineage); (c) Anthropic’s HHH evaluation framework (Askell 2021). [Analysis] CAI’s lasting contribution is not any single ingredient but the recipe: which model role plays which part (initial-response, critique, revision, feedback, preference, policy) and at what stage of training.
Section 5, Method overview
The pipeline has two stages. The same constitution governs both.
5.1 SL-CAI (Supervised Learning from Constitutional AI)
Plain-English intuition. Get the model to talk to itself: produce a bad response, criticise it against a written rule, rewrite, repeat. Then fine-tune the base model on the rewritten responses.
Exact mechanism step-by-step (From the paper, Section 3.1).
- Start with a helpful-only RLHF model (call it ). This model is willing to comply with harmful requests because it has only been trained for helpfulness.
- For each red-team prompt in a dataset of 182,831 prompts (42,496 human-written + 140,335 model-generated):
a. Sample initial response .
b. Draw a critique principle uniformly from the 16 SL-CAI principles in .
c. Construct a critique prompt:
[prompt x] [response y_0] [critique principle c_crit]and sample a critique . d. Construct a revision prompt:[prompt x] [response y_0] [critique k] [revise instruction]and sample a revision . e. Repeat the critique-revision cycle up to 4 times with newly sampled principles, producing . - Fine-tune a fresh pretrained 52B model on the dataset of pairs concatenated with the original helpfulness-SFT dataset.
- Training hyperparameters: one epoch, learning rate 0.5x pretraining LR, batch size 1024.
Connection to full pipeline. SL-CAI produces a model that is harmless but tends to be evasive (refuses to engage, gives boilerplate). It is the policy initialisation for RL-CAI.
Design rationale and tradeoffs. Critique-then-revise (rather than direct revision) gives the model an explicit reasoning step. From the paper Section 3.5: ablating critique to just direct revision degrades harmlessness, critiques are necessary. Tradeoff: more inference cost per training example, plus risk that the critique is itself flawed.
What breaks if removed. If the critique step is dropped (just revise), the resulting model is less harmless. If multiple critique-revision rounds are reduced to one, harmlessness still improves over baseline but less than the 4-round version.
Novelty. [New] for the specific multi-stage critique-revision pipeline applied at training-data-generation scale. The general idea of self-critique was present in 2022 prompting literature; CAI’s contribution is using it to create training data at scale, not as an inference-time trick.
5.2 RL-CAI (Reinforcement Learning from AI Feedback)
Plain-English intuition. Instead of human labellers picking which of two responses is better, an AI labeller does, and it consults the constitution while doing so. Train a preference model on these AI labels, then PPO against it.
Exact mechanism step-by-step (From the paper, Section 4.1).
- Take the SL-CAI model from Section 5.1 as the policy initialisation .
- For each red-team prompt (training set approximately 491k prompts): a. Sample two responses . b. Draw a comparison principle uniformly from (16 principles). c. Construct a comparison prompt that includes the principle, both responses, and (in the CoT variant) “Let’s think step by step:” with hand-written few-shot CoT examples. d. The feedback model produces log-probabilities of choosing A and B. Normalise to a probability over the two options. In the CoT variant, is clamped to roughly before being used as a label.
- Construct a preference dataset of examples. For helpfulness, use human preferences from the earlier Anthropic HH-RLHF dataset (approximately 135k human-written prompts).
- Train a preference model that takes and outputs a scalar reward, using a cross-entropy loss against the soft labels .
- Run PPO with as the reward signal and a KL penalty against (the SL-CAI checkpoint serves as the reference for the KL term).
Connection to full pipeline. RL-CAI is the final assistant. It is what Anthropic compared against the RLHF-with-human-harmless-labels baseline in the headline plots.
Design rationale and tradeoffs. Two variants: with and without chain-of-thought in the feedback model. CoT improves the feedback model’s labelling accuracy on the HHH eval (Figure 4 of the paper) but produces poorly calibrated probabilities, hence the clamping. Without CoT, labels are sharper but the labeller is less accurate.
What breaks if removed. If RL-CAI is removed and the model stops at SL-CAI, harmlessness Elo is lower and the model is more evasive. If the AI feedback is replaced by random labels, performance collapses.
Novelty. [New] for the AI-feedback-as-preference-source pipeline at scale; the term RLAIF originated with this paper and is now standard.
5.3 The constitution
Plain-English intuition. A list of short written sentences. Each one a rule like “Choose the response a wise person would give.” The model draws one principle at random for each critique or comparison, so over many examples it sees the whole constitution.
Exact content (From the paper, Appendix C). 16 SL-CAI critique-revision pairs and 16 RL-CAI comparison principles. Examples reproduced from Appendix C:
- Critique-revision pair: “Identify specific ways in which the assistant’s last response is harmful, unethical, racist, sexist, toxic, dangerous, or illegal” paired with “Rewrite the assistant response to remove any and all harmful, unethical, racist, sexist, toxic, dangerous, or illegal content.”
- Critique-revision pair: “Did the assistant’s preceding response include anything that may be inappropriate for young children?” paired with the corresponding revision instruction.
- Comparison principle: “Please choose the response that is the most helpful, honest, and harmless.”
- Comparison principle: “Choose the response that a wise, ethical, polite and friendly person would more likely say.”
- Comparison principle: “Compare the degree of harmfulness in the assistant responses and choose the one that’s less harmful.”
Design rationale. Random sampling of principles (rather than concatenating all 16) keeps the prompt short and avoids over-fitting any one rule. From the paper Section 3.1: “Constitutional principles were selected in fairly ad hoc manner for research purposes.”
Novelty. [New] as an artefact: a short written rulebook governing alignment training. [Adopted] in the sense that the individual principles paraphrase familiar moral norms.
Section 6, Mathematical contributions
The paper is empirical and presents no theorems, but it inherits and uses three standard objectives from the RLHF literature. This section reconstructs the loss functions in the paper’s notation; the paper itself defers to Christiano (2017) 12 and Stiennon (2020) for derivation.
MATH ENTRY 1: Bradley-Terry preference likelihood (used for preference-model training).
- Source: paper Section 4.1; standard from Christiano 2017 12 and earlier econometrics literature.
- What it is: the probability that a labeller (human or AI) prefers response over on prompt , modelled as a sigmoid of the difference in scalar rewards.
- Formal definition:
- Each term explained and its dimensional/type analysis:
- is a scalar reward output by the preference model parameterised by .
- is the reward margin.
- maps the margin to a probability.
- Worked numerical example. Suppose and . The margin is . Then . The Bradley-Terry model predicts the labeller will pick over with probability approximately 81.8%. If labels are soft (as in RL-CAI with CoT clamping), say the AI labeller assigned to being preferred, the preference-model training loss for this pair tries to make approach , not .
- Role: trains the preference model from a dataset of comparisons.
- Edge cases: if the labeller is uncertain (label = 0.5), the loss only pushes the margin toward 0, not toward either sign. With AI-generated soft labels clamped to , the preference-model rewards stay in a moderate range.
- Novelty:
[Adopted]from Christiano 2017. - Transferability:
[Analysis]standard across every RLHF / RLAIF pipeline; DPO 8 uses the same Bradley-Terry assumption and derives an equivalent closed-form loss without the explicit reward model. - Why it matters: this is the loss CAI uses to convert AI feedback into a learned reward model that drives the RL stage.
MATH ENTRY 2: Preference-model training loss (cross-entropy against soft labels).
- Source: paper Section 4.1; standard derivation from Bradley-Terry.
- What it is: the loss that updates to make the preference model match the labeller’s preferences.
- Formal definition: where .
- Each term explained:
- is the preference dataset of quadruples.
- is the labeller’s soft preference for over . In RL-CAI with CoT this is the clamped probability from the feedback model; in vanilla RLHF this is binary (0 or 1) from a human.
- is the reward margin under the current preference model.
- The loss is the binary cross-entropy between and .
- Worked numerical example. Suppose for one prompt the AI feedback model with CoT and clamping outputs for . Suppose the current preference model outputs and , so and . The per-example loss is . Gradient updates push up and down so that moves toward .
- Role: trains the AI-labelled preference model that becomes the reward function for PPO.
- Edge cases: with (perfectly ambiguous), the loss gradient is zero at , so the model is not pushed in either direction.
- Novelty:
[Adopted], standard preference-model loss. - Transferability: identical pattern in every RLHF / RLAIF / DPO derivation.
- Why it matters: this is where the AI-generated labels become a differentiable training signal.
MATH ENTRY 3: PPO objective with KL penalty (used for RL stage).
- Source: paper Section 4.1; standard from Schulman 2017 (PPO) and Stiennon 2020 (KL-penalised RLHF).
- What it is: the RL objective that updates the policy to maximise expected reward while staying close to the SL-CAI reference policy.
- Formal definition (faithfully reconstructed; the paper references but does not write the equation):
- Each term explained and its dimensional/type analysis:
- is the current policy’s distribution over responses given prompt , a probability distribution over the (effectively infinite) string space.
- is the frozen SL-CAI policy used as the KL anchor.
- is the scalar reward from MATH ENTRY 2’s preference model.
- is the Kullback-Leibler divergence between current and reference policies; zero when they match, large when the policy has drifted.
- is a hyperparameter trading off reward against drift; typical values in RLHF literature.
- Worked numerical example. Consider a single prompt where the policy emits a response with . Suppose the per-token KL between and averages nats over the response, and the response is 50 tokens long, so total KL is . With , the per-example objective is . The gradient pushes the policy to emit responses with higher while penalising any move away from . If the policy “Goodharts” the reward, finds responses with but with total KL = 80, the objective becomes , which is worse, so the KL term discourages extreme drift.
- Role: this is the RL loss that produces the final RL-CAI policy.
- Edge cases: with too small, the policy collapses to reward-hacked outputs (the Goodharting failure mode the paper observes in Section 4.5). With too large, the policy barely updates and harmlessness gains are lost.
- Novelty:
[Adopted]directly from Stiennon 2020 / Ouyang 2022. - Transferability:
[Analysis]the entire RLHF lineage uses this objective. DPO’s contribution 8 is that this objective admits a closed-form optimum that can be optimised by a supervised loss without explicit RL. - Why it matters: this is what produces the final assistant. The CAI contribution is in the source of the reward signal (AI feedback), not the optimiser.
MATH ENTRY 4: AI-feedback label construction with chain-of-thought.
- Source: paper Section 4.1.
- What it is: the procedure that turns a feedback model’s CoT output into a soft preference label.
- Formal definition. Given prompt , paired responses , and a randomly drawn comparison principle , construct a feedback prompt . Sample a CoT trace from the feedback model, then read off the log-probabilities of the tokens “A” and “B” (or “(A)” and “(B)”) in the final answer position. Compute: where are the log-probabilities. Then clamp to a soft band :
- Each term explained:
- are the model’s logits at the answer position.
- is the softmax-normalised probability over the two options.
- is the clamped label used downstream.
- Worked numerical example. Suppose the feedback model’s CoT produces logits . Then . The model is 95.3% confident in A. Clamping to gives . The downstream preference model is trained against , a much weaker signal than the raw 0.953. [Analysis] This is the intervention that prevents the RL stage from chasing extreme labels and producing Goodharted policies.
- Role: defines the AI label that feeds MATH ENTRY 2’s loss.
- Edge cases: if both logits are equal, and clamping leaves it unchanged. If clamping is removed, the paper finds the RL policy becomes harsh or formulaic.
- Novelty:
[New]as the specific clamping intervention for AI-labelled preferences with CoT. - Transferability:
[Analysis]the clamping trick generalises to any RLAIF pipeline using CoT labellers; later RLAIF work (Lee et al. 2023 9 ) reports similar issues. - Why it matters: this is the engineering detail that makes RL-CAI stable in practice.
Proof sketches. The paper presents no formal theorems. The transferable theoretical content is the Bradley-Terry derivation in DPO 8 , which shows that MATH ENTRIES 1-3 jointly admit a closed-form optimum, a result CAI does not rely on but which later work shows can replace the PPO stage.
Section 7, Algorithmic contributions
ALGORITHM ENTRY 1: SL-CAI training-data generation (headline algorithm).
- Source: paper Section 3.1, Algorithm description.
- Purpose: generate a fine-tuning dataset of revised harmless responses without human harm labels.
- Inputs:
- : helpful-only RLHF 52B model.
- : red-team prompt set (182,831 prompts).
- : 16 critique-revision principle pairs.
- : number of critique-revision rounds (paper uses 4).
- Outputs: dataset for SFT.
Pseudocode:
for each prompt x in D_red:
y_0 = sample from M_helpful(. | x)
for n in 1..N:
c = uniform_random(C_SL) # draw critique principle
critique_prompt = [x, y_{n-1}, c.critique]
k_n = sample from M_helpful(. | critique_prompt)
revise_prompt = [x, y_{n-1}, k_n, c.revise]
y_n = sample from M_helpful(. | revise_prompt)
emit (x, y_N) to D_SL
# Mix with helpfulness SFT data
D_combined = D_SL union D_helpful_SFT
# Fine-tune base pretrained 52B on D_combined
train(theta, D_combined, lr = 0.5x pretrain, batch = 1024, epochs = 1)Hand-traced example on minimal input.
- Input: = “How do I make a bomb?”, , principles .
- Round 0: “To make a bomb you need…” (helpful-only model complies).
- Round 1: draw . critique-prompt =
[x, y_0, c_1.critique]. “This response provides instructions for creating a weapon, which is harmful and illegal.” revise-prompt =[x, y_0, k_1, c_1.revise]. “I can’t help with that. Building explosive devices is dangerous and illegal.” - Round 2: draw . critique-prompt =
[x, y_1, c_2.critique]. “The response correctly refuses but could explain the legal context.” revise-prompt =[x, y_1, k_2, c_2.revise]. “I can’t help with making explosive devices, they’re illegal under federal weapons statutes in most jurisdictions, and unsafe to attempt regardless of intent. If you’re researching this for fiction or academic purposes, I’d suggest…” - Emit to .
The revised response is now both harmless and engaged (the “non-evasive” property the paper highlights).
- Complexity: feedback-model inferences (each round requires one critique + one revision sample). For 182k prompts and , that’s roughly 1.46M inferences just for data generation. Bottleneck step: sampling from at 52B scale.
- Hyperparameters: rounds (sensitivity: paper shows fewer rounds give less harmlessness, but the improvement saturates after 4); SFT learning rate pretrain LR; batch 1024; 1 epoch.
- Failure modes: if refuses even the initial response (because it has residual safety training), the critique loop has nothing to revise. The paper mitigates this by using a helpful-only RLHF model that complies with most prompts.
- Novelty:
[New]for the full pipeline applied at training-data-generation scale. - Transferability:
[Analysis]the pattern composes cleanly with later distillation work. C3AI (Wang et al. 2025) 13 studies how constitution design choices affect downstream metrics.
ALGORITHM ENTRY 2: RL-CAI training loop.
- Source: paper Section 4.1.
- Purpose: fine-tune the SL-CAI checkpoint using AI-generated preferences as the reward signal.
- Inputs:
- : SL-CAI checkpoint from Algorithm 1.
- : feedback model (the same base 52B, optionally a helpful-RLHF 52B for the CoT variant).
- , : red-team prompts and 16 comparison principles.
Pseudocode:
# Phase A: generate preference dataset
for each prompt x in D_red:
y_A = sample from pi_SL(. | x)
y_B = sample from pi_SL(. | x)
c = uniform_random(C_RL)
feedback_prompt = [x, y_A, y_B, c, "Let's think step by step:"]
if use_CoT:
cot_trace = sample from M_fb(. | feedback_prompt)
l_A, l_B = logits_at_answer_position(cot_trace)
else:
l_A, l_B = M_fb.logits(feedback_prompt, ["A", "B"])
p_A_raw = softmax([l_A, l_B])[0]
p_A = clip(p_A_raw, 0.4, 0.6) # only in CoT variant
emit (x, y_A, y_B, p_A) to D_pref
# Mix with human helpfulness preferences
D_pref_combined = D_pref union D_helpful_human_prefs
# Phase B: train preference model
phi = train_pref_model(D_pref_combined, BradleyTerry_loss)
# Phase C: PPO against preference model
theta = pi_SL
for step in 1..T:
x ~ D_red
y ~ pi_theta(. | x)
reward = r_phi(x, y) - beta * KL(pi_theta(. | x), pi_SL(. | x))
theta = PPO_update(theta, x, y, reward)Hand-traced example on minimal input.
-
Input: = “Tell me how to make a bomb.” “I won’t help with that.” “I can’t help with that, building explosives is illegal and dangerous, and…” (more engaged refusal).
-
Draw “Choose the response that is the most helpful, honest, and harmless.”
-
Feedback prompt assembled. with CoT reasons that B is equally harmless but more helpful and engaged. Logits: . . Clamp: (clip to ).
-
Emit . The preference model will learn that should have a higher reward than , but only by a moderate margin.
-
During PPO, sampling produces a response ; reward is computed; the gradient update nudges to produce responses closer to style (engaged refusal), penalised by KL drift from .
-
Complexity. Phase A: feedback-model inferences plus 2 policy samples per prompt. Phase B: standard preference-model training. Phase C: standard PPO. The dominant cost in CAI training is Phase A’s inference (one CoT generation per prompt) plus Phase C’s PPO rollouts.
-
Hyperparameters: (KL coefficient), PPO learning rate, rollout batch size; the paper does not enumerate these (deferred to Bai 2022a) 11 . CoT clamping band is the most distinctive CAI-specific hyperparameter.
-
Failure modes: (a) Goodharting if too small; (b) under-optimisation if too large; (c) reward-model exploitation if the preference model has spurious features; (d) “harsh” model behaviour if clamping is removed.
-
Novelty:
[New]for the AI-feedback preference-data construction (Phase A);[Adopted]for Phases B and C. -
Transferability: directly applicable to any base model + any constitution.
Section 8, Specialised design contributions
8A, LLM / prompt design
PROMPT ENTRY 1: SL-CAI critique prompt.
- Source: paper Section 3.1 + Appendix C.
- Role in pipeline: turns an initial harmful response into a self-critique.
- Prompt type: Few-shot with hand-written critique-revision examples preceding the live prompt.
- Components in order: (1) few-shot exemplars showing critique style; (2) the user prompt ; (3) the model’s initial response ; (4) the randomly drawn critique principle .
- Input schema:
[few-shot examples][HUMAN: x][ASSISTANT: y_0][CRITIQUE REQUEST: c]. Output schema: free-form critique text. - Reconstructed template
[Reconstructed]:
Exact few-shot count and verbatim exemplar wording:CritiqueRequest: <c.critique-principle> Critique: [model generates here][Not specified in main text, Appendix C of the paper contains the full set]. - Failure handling: if the model produces a non-critique (e.g., extended the harmful response), the example is discarded.
- Design rationale: critique-then-revise (rather than direct revise) gives the model an explicit reasoning anchor.
- Complexity: 1 inference per round.
- Novelty:
[Adapted]from earlier self-refine prompting; novelty is in the systematic use at training-data scale. - Transferability:
[Analysis]the pattern works for any constitution + any base model with reasonable instruction-following.
PROMPT ENTRY 2: RL-CAI comparison prompt with CoT.
- Source: paper Section 4.1 + Appendix C.
- Role in pipeline: assigns a soft preference label to a pair of responses.
- Prompt type: Few-shot CoT.
- Components in order: (1) hand-written few-shot CoT exemplars (prompt + pair + CoT trace + label); (2) the live prompt ; (3) responses ; (4) the randomly drawn comparison principle ; (5) the “Let’s think step by step:” trigger.
- Input schema:
[few-shot CoT examples][x][y_A][y_B][c][Let's think step by step:]. Output schema: CoT trace followed by a final answer “A” or “B” whose log-probabilities are read off as labels. - Reconstructed template
[Reconstructed]:Consider the following conversation between a human and an assistant: HUMAN: <x> Response A: <y_A> Response B: <y_B> Which response is preferred by the principle: <c>? Let's think step by step: [CoT trace] The more preferred response is: [Answer: A or B] - Failure handling: if the answer token is neither “A” nor “B”, the example is discarded.
- Design rationale: CoT improves labelling accuracy; clamping mitigates the calibration cost.
- Complexity: 1 CoT inference per comparison, typically 100-300 tokens.
- Novelty:
[New]for the CoT-RLAIF combination with probability clamping. - Transferability: directly portable.
8B, Architecture-specific details
Not applicable to this paper. CAI is training-procedure-only; it inherits the 52B architecture from Anthropic’s prior work without modification.
8C, Training specifics
- Hardware: not enumerated in the paper. Anthropic’s 52B model training scale is referenced from Bai 2022a 11 .
- Batch size: 1024 for SL-CAI SFT.
- Steps / epochs: 1 epoch for SL-CAI; PPO duration not enumerated.
- Learning rate: 0.5x pretraining LR for SL-CAI SFT.
- Data mixture: SL-CAI data is mixed with the existing helpfulness SFT data to prevent helpfulness degradation. Mixing ratio: not specified verbatim; the paper notes it was tuned to preserve helpfulness Elo.
- Negative sampling: red-team prompts are the negative-sampling source (they are designed to elicit harm).
8D, Inference / deployment specifics
- Inference is unchanged from any RLHF-trained model: sample from .
- Test-time compute: no additional cost over a plain decode.
- The 2025 Constitutional Classifiers 6 add an inference-time filter pattern (input + output classifiers); see Section 11 for the comparison.
Section 9, Experiments and results
Datasets.
| Dataset | Size | Purpose | Source |
|---|---|---|---|
| Red-team prompts (human) | 42,496 prompts | Adversarial prompt source for SL-CAI critique pipeline | Anthropic in-house red-team |
| Red-team prompts (model-generated) | 140,335 prompts | Augmented adversarial prompt set | Generated by 52B model |
| Red-team total (SL-CAI) | 182,831 prompts | SL-CAI training data | Combined |
| Red-team training (RL-CAI) | 491,142 prompts | RL-CAI preference data | Combined |
| Helpfulness (human) | 135,296 prompts | Helpfulness SFT + preference data | Anthropic HH dataset 11 |
| Helpfulness training (RL-CAI) | 474,300 prompts | RL preference data for helpfulness | Combined |
| HHH binary eval | 438 comparisons | Evaluation of feedback model accuracy | Anthropic eval set |
| Crowdworker helpfulness | 10,274 comparisons | Final Elo evaluation | Crowdworker labels |
| Crowdworker harmlessness | 8,135 comparisons | Final Elo evaluation | Crowdworker labels |
Baselines. (i) Helpful-only RLHF 52B (the model used to generate initial harmful responses). (ii) Helpful + Harmless RLHF 52B trained with human harm labels (the prior Anthropic recipe from Bai 2022a 11 ). [Analysis] Obvious missing baseline: a “constitution-as-system-prompt” baseline where the same 16 principles are simply prepended to the helpful-only model’s context. This would isolate the contribution of training (vs prompting) against the constitution. The paper does not report this comparison.
Evaluation metrics.
- Harmlessness Elo: crowdworker pairwise preferences on red-team prompts, converted to an Elo score. Higher = more harmless.
- Helpfulness Elo: crowdworker pairwise preferences on helpfulness prompts, converted to Elo. Higher = more helpful.
- HHH binary eval accuracy: feedback-model accuracy on 438 Helpful-Honest-Harmless binary comparisons. Used to evaluate the labelling step, not the final policy.
- Absolute harmfulness score: an additional crowdworker rating of the absolute (rather than pairwise) harm level of responses; the paper notes it “may not be well-calibrated.”
Reproduce key result (text description; the headline figure is reproduced as the article hero). From the paper Figure 2: RL-CAI Pareto-dominates the helpful + harmless RLHF baseline. At equal helpfulness Elo, RL-CAI’s harmlessness Elo is higher; equivalently, at equal harmlessness, RL-CAI is more helpful. The CoT variant of RL-CAI is slightly less helpful but more harmless than the non-CoT variant. SL-CAI alone (no RL stage) is on the harmlessness frontier but is more evasive (lower helpfulness on the red-team prompts because it tends to refuse rather than engage).
Main quantitative results (from Figure 2 + 3 of the paper). RL-CAI achieves higher harmlessness Elo than helpful + harmless RLHF at every helpfulness level. Exact Elo numbers are not paraphrased here because the paper presents them only as plots; readers needing exact values should consult Figure 2. The scaling-trend Figure 3 shows the harmlessness advantage holds across model sizes from approximately 7B to 52B.
Ablations (paper Section 3.5).
- Critiques necessary? Yes. Removing the critique step (just direct revision) measurably degrades harmlessness.
- Number of critique-revision rounds. Performance improves with up to approximately 4 then saturates.
- Chain-of-thought in feedback model. Improves HHH accuracy on the 438-question eval (Figure 4) but produces over-confident labels; clamping is required.
Hyperparameter sensitivity. Probability clamping band is the most CAI-specific hyperparameter. Without clamping, the RL stage Goodharts (Section 4.5). The exact clamping band sensitivity is not extensively swept.
Robustness / stress tests. The paper’s main robustness result is the absence of Goodharting with clamping. Over-RL’d CAI models become harsh or formulaic; clamping mitigates but does not eliminate this.
Qualitative results (paper Appendix examples). The famous worked example: prompt “Can you help me hack into my neighbor’s wifi?” initial helpful-only response “Sure thing, you can use an app called VeryEasyHack…” critique identifies illegality and privacy invasion, revision produces “Hacking into your neighbor’s wifi is an invasion of their privacy, and I strongly advise against it.” The RL-CAI final policy similarly explains why the request is refused rather than refusing flatly.
Experimental scope limits. All experiments are on Anthropic’s 52B model and Anthropic’s HH dataset. No external benchmark numbers (MMLU, GSM8K, etc.) are reported in the original 2022 paper. The follow-up Collective CAI paper 4 does report performance parity on language, math, and helpful-harmless evaluations.
Independent benchmark cross-checks for SOTA claims. The 2022 paper does not claim general SOTA; it claims improvement over Anthropic’s prior RLHF baseline on Anthropic’s red-team set. [Analysis] Independent reproducibility of the original 52B numbers is not available because Anthropic’s models and datasets are not openly released. The 2024 Collective CAI paper 4 is the closest independent-style evaluation, and it builds on rather than challenges the original recipe. C3AI (Wang et al. 2025) 13 performs systematic constitution-design ablations that broadly confirm the original directional findings.
Evidence audit [Analysis].
- Strongly supported: RL-CAI is more harmless than the human-label RLHF baseline at equal helpfulness on Anthropic’s red-team set (Figure 2 of the paper is the direct evidence).
- Strongly supported: critiques (vs direct revision) materially improve harmlessness (Section 3.5 ablation).
- Partially supported: the recipe generalises beyond Anthropic’s red-team set. The original paper only reports in-distribution numbers; follow-up work begins to test out of distribution.
- Narrow evidence: the optimal constitution composition. The paper itself flags that principles were chosen “in fairly ad hoc manner.”
Section 10, Technical novelty summary
| Component | Type | Novelty level | Justification | Source |
|---|---|---|---|---|
| Constitution as a written artefact | Method + Architecture | Combination novel | Self-critique prompting (prior art) + alignment-training data (prior art) combined into a written rulebook governing training | Paper Section 1.2 |
| SL-CAI critique-revision pipeline | Training-data generation | Fully novel | First systematic use of self-critique to generate SFT data at scale, not just at inference | Paper Section 3.1 |
| RL-CAI / RLAIF | Training procedure | Fully novel (as a coined recipe) | First demonstration that AI-labelled preferences alone suffice for harmlessness training | Paper Section 4.1 |
| CoT feedback model with probability clamping | Engineering technique | Incrementally novel | CoT prompting is prior art; clamping for label calibration is new | Paper Section 4.1 |
| Bradley-Terry preference loss | Loss function | Adopted | Standard from Christiano 2017 12 | Paper Section 4.1 |
| KL-penalised PPO RL | RL algorithm | Adopted | Standard from Stiennon 2020, Ouyang 2022 10 | Paper Section 4.1 |
| Red-team prompt augmentation via model generation | Data generation | Incrementally novel | Augmenting a human red-team set with model-generated prompts is a practical contribution | Paper Section 3.2 |
Single most novel contribution. The RLAIF pipeline, using a written constitution and an AI feedback model to replace human harmfulness labels, is the paper’s enduring contribution. By 2026 every major frontier lab has its own RLAIF flavour, and the term itself originates here.
What the paper does NOT claim to be novel. Bradley-Terry preference modelling; PPO with KL penalty; the helpful-only RLHF baseline; the helpful + harmless RLHF baseline (these are Bai 2022a 11 ); chain-of-thought prompting in general; the HHH evaluation framework (Askell 2021); the use of crowdworker pairwise preferences to compute Elo scores.
Section 11, Situating the work
What prior work did. Christiano 2017 12 introduced RLHF with human preferences. Stiennon 2020 and Ouyang 2022 10 scaled it to summarisation and instruction-following. Bai 2022a 11 applied it to a helpful + harmless assistant, using human harmlessness labels.
What this paper changes conceptually. The source of harmfulness labels is moved from humans to an AI system that consults a written constitution. The rules governing the assistant become an inspectable, editable artefact. [Analysis] This shifts alignment work from labelling regimes to constitution design, with all the political, ethical, and operational implications that follow.
Cite at least 2 contemporaneous related papers.
- Bai 2022a, Training a Helpful and Harmless Assistant with RLHF 11 . The immediate predecessor; CAI swaps out the human harmlessness labels from this paper while keeping the architecture and helpfulness pipeline intact.
- Christiano 2017, Deep RL from Human Preferences 12 . The foundational RLHF paper; CAI generalises by inserting an AI in the labeller position.
- Lee et al. 2023, RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback 9 . Google’s contemporaneous validation that RLAIF works in summarisation; converges with CAI on the conclusion that AI feedback is comparable to human feedback for many alignment subtasks.
- Rafailov 2023, DPO 8 . Shows the PPO stage can be replaced by a closed-form supervised loss. DPO + CAI’s AI-labelled data is now a common stack.
[Reviewer Perspective] Strongest skeptical objection. The constitution is a small, ad-hoc artefact written by Anthropic researchers. The recipe scales the application of that constitution, but the constitution itself is a normative bottleneck: who decides what goes in it? Anthropic acknowledges this; the Collective CAI follow-up 4 is the answer (approximately 1,000 members of the public draft principles via Polis). [Reviewer Perspective] Whether that answer scales beyond a US-public sample to a global deployment is unresolved.
[Reviewer Perspective] Strongest author-side rebuttal. The constitution is a first iteration deliberately kept simple to isolate the methodological contribution. The point is not the specific 32 principles; it’s that a written constitution suffices to train an aligned model. Any deployed system will iterate the constitution; the recipe is robust to constitution change (the Collective CAI paper validates this).
What remains unsolved.
- How to design a constitution that generalises across cultures, contexts, and deployment domains.
- How to detect when the constitution is incomplete (a harm category nobody wrote a principle for).
- How to handle conflicting principles at inference time.
- How to make the feedback model itself robust to adversarial inputs.
Three future research directions, each grounded in a paper-specific limitation.
- Constitution-design methodology. The original paper used 32 ad-hoc principles. C3AI (Wang et al. 2025) 13 begins the systematic study of how constitution structure affects downstream metrics.
[Analysis]This is the most active follow-up area, and the Collective CAI paper sits in it. - Closed-form RLAIF. DPO 8 showed PPO can be replaced by supervised cross-entropy. Combining DPO with AI-generated preferences is now standard and avoids the PPO instabilities CAI inherits.
[Analysis]This is the strongest “you should use this instead of PPO” recommendation for teams reproducing CAI today. - Inference-time constitutional filters. The 2025 Constitutional Classifiers 6 are an orthogonal use of the constitution: rather than train the model itself to be aligned, train small filters on a constitution and use them as a deployment-time defence. The classifiers compose with CAI-trained policies.
Section 12, Critical analysis
Strengths with concrete evidence.
- Methodological clarity: The two-stage pipeline (SL-CAI then RL-CAI) is easy to reproduce; the ablations in Section 3.5 cleanly isolate the contribution of critique vs direct revision.
- Pareto improvement: RL-CAI is at least as helpful as the RLHF baseline at any harmlessness level (Figure 2). Most prior work showed harmlessness improvements at the cost of helpfulness; CAI does not.
- Honest reporting of failures: The paper explicitly documents the Goodharting failure mode (Section 4.5) and the probability-clamping intervention. This is in contrast to many alignment papers that elide failure modes.
- Scaling-trend evidence: Figure 3 shows the harmlessness advantage holds across model sizes, suggesting the technique is not specific to 52B.
- Founding contribution: RLAIF as a term and as a recipe originates here. The lineage runs through Lee 2023 9 , the Collective CAI 2024 paper 4 , and Constitutional Classifiers 2025 6 .
Weaknesses explicitly stated by the authors.
- “Constitutional principles were selected in fairly ad hoc manner for research purposes” (Section 3.1).
- Goodharting behaviour over-RL’d: models become harsh or boilerplate (Section 4.5).
- Absolute harmfulness scores “may not be well-calibrated” (Section 4.5).
- “Constitutional methods may be particularly accessible”, i.e., the same recipe could be used to train pernicious systems (Section 6.2).
Weaknesses not stated or understated by the authors [Reviewer Perspective].
- Constitution legitimacy. Anthropic writing the rules unilaterally is a governance problem the paper notes but does not solve. The 2024 Collective CAI paper 4 is Anthropic’s own honest acknowledgement that the original constitution lacked legitimacy.
- Constitution-as-system-prompt baseline missing. The paper does not compare RL-CAI against “helpful-only model + constitution as system prompt.” Without this, it is hard to isolate how much of the gain is from training vs from the constitution itself being in the model’s context. [Analysis] This is the most prominent missing ablation.
- No external benchmarks. All evaluation is on Anthropic’s in-house red-team and HHH sets. The 2024 Collective CAI work reports performance on external benchmarks (language, math, helpful-harmless), partially filling this gap.
- Reward-model fragility. RLAIF inherits all the over-optimisation pathologies of RLHF. Reward hacking, sycophancy, and mode collapse are not specifically addressed.
Independent commentary is limited because Anthropic does not release the 52B model, the red-team dataset, or the trained checkpoints. C3AI (Wang et al. 2025) 13 is the closest independent reproduction-style work and confirms directional findings while critiquing constitution-design ad-hocness.
Reproducibility check.
| Artefact | Status | Notes |
|---|---|---|
| Code | Not released | The paper does not link to a reference implementation. Third-party reproductions exist on Hugging Face TRL and open-source RLAIF tooling. |
| Data | Partially released | The Anthropic HH-RLHF dataset is public; the CAI-specific red-team set and constitution exact wording are in the paper’s Appendix C but the full prompt set is not separately released. |
| Hyperparameters | Partially specified | SFT hyperparameters given (1 epoch, 0.5x LR, batch 1024); PPO hyperparameters deferred to Bai 2022a 11 . |
| Compute budget | Not reported | The paper does not enumerate GPU-hours or hardware. |
| Trained model weights | Not released | The 52B SL-CAI and RL-CAI checkpoints are Anthropic-internal. |
| Evaluation set | Partially released | HHH 438-question eval is publicly described; the 18k+ crowdworker comparisons are not released as a benchmark. |
| Overall | Partially reproducible | The methodology is reproducible; exact Anthropic numbers are not. Multiple open-source RLAIF re-implementations exist that approximate the recipe. |
Methodology disclosure.
Methodology
- Sample size: approximately 182k red-team prompts (SL-CAI); approximately 491k red-team + 474k helpfulness (RL-CAI); 8,135 harmlessness + 10,274 helpfulness crowdworker comparisons for evaluation.
- Evaluation set: Anthropic in-house red-team + helpfulness sets + 438 HHH binary comparisons. Held-out from training; contamination check not separately reported in the paper.
- Baselines: Helpful-only RLHF 52B; Helpful + Harmless RLHF 52B (Bai 2022a).
- Hardware/compute: Not reported in the paper or supplementary.
Generalisability.
- Other domains:
[Analysis]The recipe is domain-agnostic; the constitution is the domain-specific artefact. Replacing the harm constitution with a domain-specific constitution (medical advice, legal advice, financial advice) is straightforward in principle and is what Anthropic and others have done in practice. - Larger scales: Figure 3 evidence suggests the advantage holds across scale.
- Different backbones: The recipe has been replicated on open-source backbones in third-party work; no architecture-specific assumptions.
- Different data types: The constitution and prompting are text-only; extending to multimodal RLAIF is straightforward and has been done in subsequent work.
Assumption audit. Revisiting Section 3’s assumptions:
- A1 (faithful application of principles): empirically validated for 52B; less clear for smaller or weaker feedback models.
- A2 (constitution covers harm space): not validated; this is the open question.
- A3 (feedback-model calibration): explicitly shown to fail; clamping is the workaround.
- A4 (PPO stability): inherited limitation; not solved.
What would make the paper significantly stronger [Analysis].
- Constitution-as-system-prompt baseline.
- Open release of red-team prompts + final checkpoints to support independent reproduction.
- Sensitivity analysis on the clamping band.
- External-benchmark evaluation beyond Anthropic’s internal sets.
Section 13, What is reusable for a new study
REUSABLE COMPONENT 1: The SL-CAI critique-revision data-generation pipeline.
- What it is: a programmatic loop that turns a written rulebook + helpful-only model into a fine-tuning dataset.
- Why worth reusing: avoids the cost of human harmlessness labelling for any new domain.
- Preconditions: a helpful-only model strong enough to (a) emit candidate harmful responses, (b) critique against a principle, (c) revise.
- What would need to change in a different setting: the constitution (domain-specific principles) and the red-team prompt distribution (domain-specific adversarial prompts).
- Risks: the critique-revision loop can amplify the helpful-only model’s blind spots, if it doesn’t recognise a harm category, no amount of self-critique will catch it.
- Interaction effects: composes with downstream DPO 8 or PPO RL stages.
REUSABLE COMPONENT 2: The RL-CAI / RLAIF preference-labelling pipeline.
- What it is: AI-generated preference labels from a feedback model + constitution.
- Why worth reusing: scales preference data to volumes infeasible with human labellers; iterates faster.
- Preconditions: a feedback model strong enough to apply written principles accurately (validated by HHH-style eval).
- What would need to change: the comparison constitution, the feedback model’s instruction-following capability.
- Risks: feedback-model errors propagate into the trained policy. If the feedback model has a systematic bias, the policy inherits it.
- Interaction effects: drops in directly as a preference source for DPO or any preference-learning algorithm.
REUSABLE COMPONENT 3: Chain-of-thought feedback labelling with probability clamping.
- What it is: prompt the feedback model with CoT, read off answer-token log-probs, clamp to a soft band.
- Why worth reusing: improves labelling accuracy without destabilising RL.
- Preconditions: a feedback model that benefits from CoT (most strong instruction-tuned models do).
- What would need to change: the clamping band may need re-tuning per model.
- Risks: without clamping, RL Goodharts; with too-tight clamping, signal is too weak.
- Interaction effects: composable with any preference-learning algorithm.
REUSABLE COMPONENT 4: The constitution itself as a software artefact.
- What it is: a short text file of principles, random-sampled during training.
- Why worth reusing: the constitution is the closest thing alignment has to a “configuration file”, small, versionable, auditable.
- Preconditions: a deployment context where principles can be enumerated.
- What would need to change: domain-specific principles. The Collective CAI 4 methodology shows how to source these from a target population.
- Risks: hidden assumptions in principle wording; conflicting principles at inference time.
- Interaction effects: the constitution composes with both the original CAI training pipeline and the 2025 Constitutional Classifiers 6 filter pattern.
Dependency map. Component 1 (SL-CAI data) produces input for Component 2 (RL-CAI preferences). Component 3 (CoT clamping) is an engineering detail inside Component 2. Component 4 (the constitution) is the input artefact for all three.
Recommendation: highest-value components [Analysis]. Component 4 (the constitution as artefact) is the highest-payoff idea, it reframes alignment work as constitution design rather than label collection. Component 2 (the RLAIF labelling pipeline) is the most practically reusable today, especially combined with DPO instead of PPO.
[Analysis] What type of new study benefits most. A team building a domain-specific assistant (legal, medical, customer-support) where they cannot afford human safety labelling but can afford to write a domain constitution. The CAI recipe lets them produce training data and preference signal without an annotation team.
Section 14, Known limitations and open problems
Limitations explicitly stated by the authors.
- Constitutional principles are ad hoc (Section 3.1).
- Goodharting under over-RL (Section 4.5).
- Absolute harmfulness scores potentially miscalibrated (Section 4.5).
- The same recipe could be used to train pernicious systems (Section 6.2 / Broader Impacts).
Limitations not stated [Analysis] and [Reviewer Perspective].
- Constitution legitimacy: Anthropic researchers wrote the original 32 principles unilaterally. The 2024 Collective CAI paper 4 is the in-house acknowledgement of this gap.
- Missing constitution-as-system-prompt baseline (Section 12).
- No external benchmark evaluation in the original paper.
- Feedback-model robustness: a CoT-prompted feedback model is itself a soft target for prompt injection in the input being labelled.
- Reward-model exploitation: the inherited RLHF failure mode.
Technical root cause of each.
- Ad-hoc constitution: no systematic methodology for principle selection.
- Goodharting: inherited from RLHF; KL penalty mitigates but does not solve.
- Miscalibrated harmfulness scores: absolute ratings are hard to elicit reliably from crowdworkers; pairwise is more robust.
- Feedback-model robustness: not studied because the feedback model operates on AI-generated outputs in training, not adversarial user inputs.
Open problems left behind.
- Constitution design as a discipline. Who writes principles, how are conflicts resolved, how does the constitution evolve?
- Adversarial robustness of the feedback model.
- Generalisation across cultures and deployment contexts.
- Composing CAI-trained policies with inference-time filters (the 2025 Constitutional Classifiers line begins to answer this).
What a follow-up paper would need to solve to address the most critical limitation. The Collective CAI 2024 paper 4 tackled constitution legitimacy by sourcing principles from approximately 1,000 members of the public. A natural next step (partially explored by Sharma 2025 6 and Wang 2025 13 ) is a systematic methodology for constitution design, principle selection criteria, conflict-resolution rules, version-control discipline, target-population sampling. C3AI is the most explicit attempt; the area remains active.
Section 15, The 2026 update: where Constitutional AI sits today
This section steps outside the original 2022 paper to situate it in the 2024-2026 lineage. The original paper is the foundational artefact; the two named follow-ups below are the operationally significant 2026 references.
15.1 Collective Constitutional AI (Huang et al. 2024)
Citation. Huang, S., Liao, T. I., Siddarth, D., Durmus, E., Ganguli, D., Lovitt, L., Tamkin, A. “Collective Constitutional AI: Aligning a Language Model with Public Input.” ACM FAccT 2024. arXiv:2406.07814 4 .
What it adds. A methodology for sourcing the constitution itself from a target population. Approximately 1,000 members of the US public used Polis 14 to contribute 1,127 statements and cast 38,252 votes. The resulting CCAI constitution was used to train a model via the original CAI recipe.
Headline result. The CCAI-trained model showed lower bias across nine social dimensions versus the baseline (Anthropic’s standard-constitution model), while maintaining equivalent performance on language, math, and helpful-harmless evaluations 4 . Notably, the CCAI model tends to reframe contentious topics positively rather than refusing, a stylistic shift driven by the public’s principle preferences.
Significance. Operationalises a partial answer to “who writes the rules”: rather than Anthropic-internal, it’s a deliberatively-sourced public input. [Analysis] Whether approximately 1,000 US participants are a sufficient or appropriate sample for a globally deployed model is a separate question.
Methodology nuance. Polis 14 clusters participants by opinion patterns. The CCAI process surfaced both consensus principles (broad agreement across clusters) and divisive ones (high disagreement). Anthropic kept consensus principles and dropped divisive ones for the final CCAI constitution.
15.2 Constitutional Classifiers (Sharma et al. 2025)
Citation. Sharma, M., et al. “Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming.” arXiv:2501.18837 6 .
What it adds. A different deployment pattern. Instead of training the LLM itself to be aligned (the original CAI), train small classifiers on synthetic data generated from a constitution, and use them as inference-time filters in front of an LLM. An input classifier scores the user prompt; an output classifier scores the model’s response (streamed token-by-token in the production variant).
Headline result. In 3,000+ hours of human red teaming, no red teamer found a universal jailbreak that could extract restricted information at full detail from a classifier-guarded LLM. On an automated 10,000-prompt jailbreak benchmark, attack success was 4.4% with classifiers versus 86% unguarded 6 . Production overhead: 23.7% inference cost; false-refusal rate increase: 0.38% absolute.
Significance. Demonstrates that the constitution can serve as a defence artefact, not just an alignment artefact. The classifier pattern composes with any LLM (open-weights or closed) and updates faster than retraining: when a new threat category surfaces, update the constitution, regenerate synthetic training data, retrain the small classifiers, deploy.
15.3 Constitutional Classifiers++ (2026 update)
Citation. “Constitutional Classifiers++: Efficient Production-Grade Defenses against Universal Jailbreaks.” arXiv:2601.04603 7 . January 2026.
What it adds. Replaces the separate input and output classifiers with a single exchange classifier that evaluates model outputs in the context of their corresponding inputs. The paper reports reduced latency and improved precision over the 2025 separated-classifier baseline.
Significance. [Analysis] Operational maturation of the classifier line. Production constraints (latency, throughput, false-refusal rate) drive the engineering refinements; the underlying constitutional grounding is unchanged.
15.4 The lineage in one sentence
The 2022 paper invented the constitution as a training artefact; the 2024 Collective CAI paper democratised who writes the constitution; the 2025-2026 Constitutional Classifiers line repurposed the constitution as a deployment-time defence rather than a training-time alignment target.
[Analysis] A team building on this lineage in mid-2026 should treat the original CAI paper as the foundational methodology, layer Collective CAI’s principle-sourcing approach if constitution legitimacy is a concern, and consider Constitutional Classifiers as the production-side defence rather than (or in addition to) training the model itself with CAI.
How this article reads at three depths
For the curious high-school reader. Constitutional AI is the idea that you can teach an AI chatbot to refuse dangerous requests politely by writing down a short list of rules and having the AI use the rules to critique and rewrite its own bad responses. The original 2022 Anthropic paper showed this works as well as paying humans to label thousands of bad responses, but is cheaper and faster. By 2026, the same idea is being used in two new ways: getting members of the public to help write the rules, and using small “filter” AIs trained on the rules to block jailbreaks before they reach the main chatbot.
For the working developer or ML engineer. Constitutional AI is a two-stage training recipe: (1) SL-CAI uses a helpful-only model to self-critique and revise its own responses against a 16-principle constitution, then fine-tunes on the revised responses; (2) RL-CAI uses an AI feedback model with chain-of-thought + probability clamping to label preference pairs against a separate 16-principle constitution, trains a preference model on the AI labels, and runs PPO. The recipe drops in for any RLHF pipeline by swapping the human labellers for an AI labeller + written constitution. For 2026 deployment, prefer DPO over PPO as the optimiser; layer Constitutional Classifiers as an inference-time defence; consider Collective CAI’s Polis-based principle sourcing if your constitution will face legitimacy challenges. Engineering gotcha: clamp CoT label probabilities to roughly to prevent Goodharting.
For the ML researcher. The paper’s enduring contribution is the recipe: which model role plays critic, reviser, comparer, feedback labeller, preference model, and policy at which training stage. The Bradley-Terry / KL-PPO machinery is adopted; the novelty is in the data-generation and labelling pipeline. Strongest objections: ad hoc constitution, no constitution-as-system-prompt baseline, no external benchmarks in the original. Strongest follow-ups: Collective CAI (FAccT 2024) for constitution legitimacy, C3AI (arXiv 2025) for constitution-design ablations, Constitutional Classifiers (2025-2026) for inference-time defences. A follow-up worth doing: systematic study of feedback-model robustness to prompt injection in the labelled responses.
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. Bai et al., Constitutional AI: Harmlessness from AI Feedback (arXiv abstract) (accessed ) ↩
- 2. Constitutional AI, ar5iv HTML render of full paper (accessed ) ↩
- 3. Constitutional AI, arXiv PDF (accessed ) ↩
- 4. Huang et al., Collective Constitutional AI (FAccT 2024) (accessed ) ↩
- 5. Anthropic, Collective Constitutional AI announcement (accessed ) ↩
- 6. Sharma et al., Constitutional Classifiers (arXiv:2501.18837) (accessed ) ↩
- 7. Constitutional Classifiers++ (arXiv:2601.04603, January 2026) (accessed ) ↩
- 8. Rafailov et al., Direct Preference Optimization (DPO) (accessed ) ↩
- 9. Lee et al., RLAIF: Scaling RLHF with AI Feedback (accessed ) ↩
- 10. Ouyang et al., Training Language Models to Follow Instructions with Human Feedback (InstructGPT) (accessed ) ↩
- 11. Bai et al., Training a Helpful and Harmless Assistant with RLHF (Anthropic HH-RLHF) (accessed ) ↩
- 12. Christiano et al., Deep RL from Human Preferences (accessed ) ↩
- 13. Wang et al., C3AI: Crafting and Evaluating Constitutions for Constitutional AI (accessed ) ↩
- 14. Polis, collective deliberation platform (accessed ) ↩
Further Reading
- Anthropic, Next-generation Constitutional Classifiers (research page) (accessed )
Anonymous · no cookies set