Mechanistic interpretability: induction heads, transformer circuits, and scaling monosemanticity — a multi-paper review
Plain-English walkthrough of induction heads, transformer circuits, and Anthropic's 2024 scaling-monosemanticity work — what's known, what's open.
Reading-register key
- From the paper: claims drawn verbatim or near-verbatim from the source paper’s text, equations, tables, or figures.
- [Analysis]: the publication’s own reasoned assessment, distinct from any claim the paper itself makes.
- [Reconstructed]: content faithfully reconstructed because the source page partially disclosed it; flagged where used.
- [External comparison]: comparison to prior or contemporary work outside the three reviewed papers.
- [Reviewer Perspective]: a critical or speculative assessment that goes beyond what any of the three papers proves.
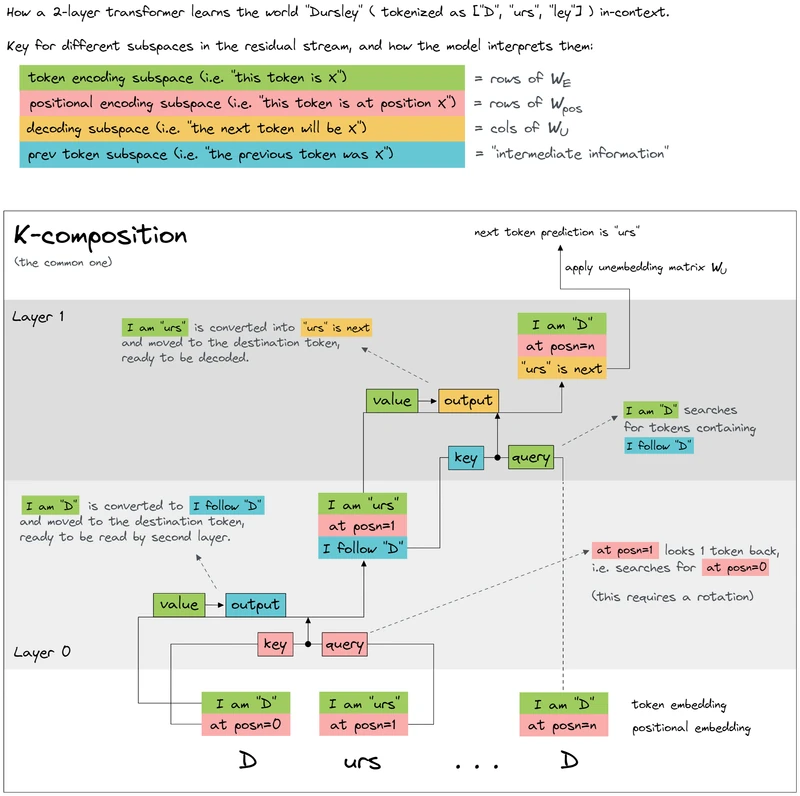
Diagram of the two-head induction-circuit mechanism, from LessWrong’s Induction heads — illustrated explainer of the 2022 Olsson et al. paper, used for editorial reference.
Section 1: Cluster scope
This review covers three foundational mechanistic-interpretability reports from Anthropic’s Transformer Circuits Thread: the 2021 A Mathematical Framework for Transformer Circuits (Elhage, Nanda, Olsson et al.), 1 the 2022 In-context Learning and Induction Heads (Olsson, Elhage, Nanda et al.), 2 and the 2024 Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet (Templeton, Conerly, Marcus et al.). 3 Together they trace a single research arc: from a low-level mathematical decomposition of attention-only transformers, to an empirically-grounded mechanism for in-context learning, to a scalable feature-extraction technique that surfaces interpretable directions inside a production-scale frontier model.
The three papers are linked, not independent. The 2021 framework supplies the algebraic language — residual stream, QK and OV circuits, head composition — that the 2022 paper uses to describe induction heads. The 2024 paper inherits the goal (decompose what a transformer is doing) and shifts the substrate (sparse autoencoders applied to mid-layer activations of a state-of-the-art model). [Analysis] Reading them as a cluster, rather than three isolated reports, is the only way to follow the field’s shift from algebra-of-attention to dictionary-learning-of-features.
Cluster classification: representation learning · theoretical · interpretability · AI safety · LLM-based. Single-domain depth label: deep on each paper’s central contribution.
Reader prerequisites. High-school algebra plus the willingness to read a few matrix products. Familiarity with transformers helps but the Glossary in Section 2.5 covers every term that goes beyond high-school math. The Section 6 MATH ENTRIES and the Section 7 ALGORITHM ENTRIES are written so that a curious 16-year-old can follow the worked numerical examples even without prior neural-network experience, while a working ML researcher can use the same entries as a faithful technical reference.
Section 2: TL;DR for the cluster
Anthropic’s interpretability team set out to understand what individual components inside a transformer are computing. In 2021 they built a mathematical framework that lets you decompose a transformer with no MLP layers into “circuits” — small, named subgraphs that perform a specific function. 1 In 2022 they used that framework to identify a particular two-head circuit, the induction head, that completes patterns of the form [A][B] ... [A] → [B], and they presented six lines of evidence — discussed in Section 5 — that induction heads are a (or the) mechanism behind a transformer’s ability to learn from examples placed in its prompt. 2 In 2024 they pivoted from attention-circuits to features inside the residual stream: by training a sparse autoencoder on Claude 3 Sonnet’s middle-layer activations, they extracted up to 34 million interpretable feature directions, including features that fire for the Golden Gate Bridge, for code errors, and for safety-relevant abstractions like deception and sycophancy. 3
Practitioner takeaways.
- Residual-stream framing is a useful mental model even for engineers. Treating attention and MLP outputs as “writes” to a shared linear bus clarifies why ablating one head can change a model in ways that look downstream-correlated.
- Induction heads are reproducible in toy attention-only transformers and surface a co-emergence pattern (a “bump” in the training loss curve) that practitioners can use as a coarse interpretability probe.
- Sparse autoencoders are the current scalable tool for finding semantically-named features in production-scale models. The 2024 paper demonstrates the technique on Claude 3 Sonnet at 34M feature scale.
- Feature steering (“Golden Gate Claude”) shows the features are causal, not just correlational — clamping a feature changes the model’s behaviour in the direction the feature’s name predicts.
- Interpretability is not solved. The 2024 paper itself flags that 34M features are a small fraction of all the features a model of Sonnet’s size plausibly uses, and many features remain hard to label.
Pipeline overview in text. All three papers analyse trained models post-hoc; none retrain. The 2021 paper analyses small attention-only transformers it trained for the purpose. The 2022 paper analyses a sweep of model sizes from small attention-only models up to 13B parameters. The 2024 paper analyses Claude 3 Sonnet as released by Anthropic in March 2024, with the SAE trained separately on activations harvested from a forward pass.
Section 2.5: Glossary
| Term | Plain-English explanation | First appears in |
|---|---|---|
| Residual stream | A linear “bus” running through the transformer that every attention and MLP layer reads from and writes to by addition. Think of it as a stack of slots one per token. | Section 3 |
| Attention head | A single attention operation. A layer contains several heads working in parallel. Each head decides which earlier tokens to look at and writes a vector back into the residual stream. | Section 3 |
| QK circuit | The pair of matrices that decide which earlier token each token pays attention to. “Q” stands for query, “K” for key. | Section 3 |
| OV circuit | The pair of matrices that decide what the head writes back into the residual stream once it has chosen what to attend to. “O” stands for output, “V” for value. | Section 3 |
| Induction head | A two-layer attention circuit that completes patterns of the form [A][B] ... [A] → [B] by looking back to where the current token previously appeared and copying the token that followed it. | Section 5 |
| Previous-token head | A layer-1 attention head whose only job is to copy each token’s identity into the next position of the residual stream, so that the next layer can match against it. | Section 5 |
| K-composition | A particular way two attention heads compose: head 2’s keys are produced by reading directly from head 1’s output, rather than from the original embedding. | Section 5 |
| Phase change | A sudden bend in the training loss curve where many properties of the model shift at the same time. The induction-heads paper documents an in-context-learning phase change. | Section 5 |
| In-context learning | The ability of a language model to use earlier tokens in its prompt as informal “training examples” for the rest of the prompt, without any weight update. | Section 5 |
| Sparse autoencoder (SAE) | A neural network that learns to reconstruct its input from a sparse intermediate representation, used here to turn a dense activation vector into a list of a few active interpretable features. | Section 6 |
| Monosemantic feature | A feature direction that responds to a single human-recognisable concept, as opposed to a polysemantic feature that fires for several unrelated concepts. | Section 6 |
| Feature ablation / clamping | Forcing a feature’s activation to a fixed (often elevated) value during a forward pass, to test what causal effect the feature has on the output. | Section 6 |
[Analysis] label | The publication’s own reasoned assessment, distinct from what the paper itself claims. | Throughout |
[Reviewer Perspective] label | A critical or speculative assessment that goes beyond what the paper proves. | Sections 11 and 12 |
[Reconstructed] label | Content the publication faithfully reconstructed because the source page only partially disclosed it. | Where used |
[External comparison] label | A comparison to prior or contemporary work outside the three reviewed papers. | Sections 4 and 11 |
| ”From the paper:” prefix | Content directly supported by one of the three papers’ text, equations, tables, or figures. | Throughout |
Section 3: Problem formalisation (cluster-wide)
Notation. All three papers use the same residual-stream conventions, traceable to the 2021 framework.
| Symbol | Type | Meaning | First appears in |
|---|---|---|---|
| vector in | the residual-stream state at token position | Section 3 | |
| integer | sequence length | Section 3 | |
| integer | residual-stream dimension; typical values 512, 768, 4096 | Section 3 | |
| matrices | per-head query, key, value, output projections | Section 5 | |
| matrix | the QK circuit, a single low-rank bilinear form on residual vectors | Section 5 | |
| matrix | the OV circuit, a single low-rank linear map | Section 5 | |
| integer | head index | Section 5 | |
| scalar in | attention weight from token to token for head | Section 5 | |
| non-negative scalar | activation of SAE feature on a given residual vector | Section 6 | |
| integer | number of features in the SAE; 1M / 4M / 34M in the 2024 paper | Section 6 | |
| scalar | sparse-autoencoder training loss (reconstruction MSE plus L1 penalty) | Section 6 |
Formal problem statement (cluster level). Given a trained transformer language model , characterise the internal computation that produces its outputs in terms of named, low-rank substructures of the weight matrices (papers 1 and 2) and in terms of named, sparse activation directions inside the residual stream (paper 3), in a way that (a) is mechanistic enough to support causal interventions and (b) generalises across model scales.
Assumptions, by paper.
- 2021 framework: attention-only transformers (no MLP layers), so the entire network is a composition of linear operations gated by softmax-attention. [Analysis] This is the strongest assumption in the cluster; relaxing it is the central open problem the 2024 paper effectively addresses by switching substrates.
- 2022 induction-heads: the framework’s algebra applies to small attention-only models without modification, and applies approximately to larger models with MLP layers (the paper presents correlational rather than causal evidence at scale). From the paper: for small attention-only models the evidence is strong and causal; for larger models with MLPs the evidence is correlational.
- 2024 Scaling Monosemanticity: sparse-autoencoder dictionary learning, as established on a one-layer transformer in the 2023 Towards Monosemanticity paper, 5 generalises to mid-layer residual-stream activations of a production-scale model.
Complexity arguments. A transformer with layers and heads per layer admits named attention heads plus MLP blocks. The 2021 framework reduces a single head to two named circuits ( and ), each of rank at most , where is typically or . The combinatorial space of composed circuits (head-on-head compositions across layers) grows like at a minimum; the induction-heads paper picks out exactly one of these compositions and argues it dominates a specific behaviour. The 2024 paper sidesteps the combinatorial blow-up by working directly with the residual-stream activations as a vector space and learning a dictionary on top.
Why the problem is hard. Standard mechanistic interpretability faces three hard subproblems: (1) superposition — a single residual-stream direction can encode multiple features, and a single feature can be spread across many directions; (2) polysemanticity — individual neurons fire for unrelated concepts; (3) scale — a frontier model has billions of parameters and tens of millions of plausible features. The 2021 framework attacks (1) and (2) by working with weight matrices instead of neurons; the 2024 paper attacks all three by learning an over-complete sparse dictionary that has more features than the residual stream has dimensions.
Section 4: Motivation and gap
The motivating real-world question across all three papers is the same: what is a language model actually computing? The user-facing answer (“it predicts the next token”) names the loss function but not the algorithm. [Analysis] Without an internal account, AI-safety claims about deception, sycophancy, or jailbreak resistance reduce to behavioural testing, which is necessary but not sufficient.
Existing approaches and gaps the papers address.
- Pre-2021 mechanistic interpretability focused on vision models, culminating in the Distill Circuits Thread on InceptionV1. 10 [External comparison] The vision-circuits programme established the conceptual moves — find a neuron, characterise it, find how it composes — but those moves did not transfer cleanly to attention because attention has no spatial structure analogous to a conv kernel. The 2021 framework fills that gap.
- Probing and feature-attribution methods (saliency maps, integrated gradients, linear probes) can show that a representation contains some concept, but they do not say how that representation was constructed by upstream layers. The 2022 paper goes further: it identifies a specific construction, the induction head, and runs interventions on it.
- Dictionary learning for interpretability was demonstrated at toy scale by Anthropic’s 2023 Towards Monosemanticity paper on a one-layer transformer. 5 The 2024 paper’s gap-closing contribution is scaling that recipe to a production model — a step Anthropic itself flagged as the open question after the 2023 report.
Practical stakes. Mechanistic interpretability is one of the load-bearing planks of AI safety research; if interpretability fails to scale, alignment research loses its ability to make claims about why a model behaves a certain way rather than that it does. The 2024 paper makes this explicit, framing the SAE method as a “step towards practical interpretability tools for AI safety.” 7
[External comparison] Concurrent work from OpenAI on sparse autoencoders 3 reaches similar conclusions about feature quality on GPT-4 scale activations. The two efforts use different architectural choices (TopK vs L1 sparsity) but converge on the same conclusion: SAEs scale.
Schematic of the scaled-dot-product attention mechanism (Wikipedia Commons), used for reference on the QK / OV decomposition described in Paper 1.
Section 5: Method overview — Paper 1 (Mathematical Framework, 2021)
Plain-English intuition. A transformer is harder to read directly because each layer mixes information across many positions and many feature dimensions. The 2021 framework rewrites the transformer as a sum of paths through the network, where each path goes through specific heads. A single attention head, viewed this way, splits into two independent calculations: one that decides which earlier token to look at (the QK circuit), and one that decides what to write once it has decided where to look (the OV circuit).
Exact mechanism.
- The residual stream is a sequence of vectors . The token embedding writes the initial .
- Each attention layer reads from the residual stream, runs parallel heads, and adds each head’s output back into the residual stream.
- For head in layer , the head computes (i) attention weights and (ii) output , then adds the output into .
- The 2021 framework collapses into a single bilinear form and into a single linear map . This makes each head a pair of low-rank matrices, independent of the others up to what they read from the shared residual stream.
- Multi-layer composition is then a sum over paths through the residual stream. Composition between heads is decomposed into three named flavours: Q-composition (later head’s queries depend on earlier head’s output), K-composition (later head’s keys depend on earlier head’s output), and V-composition (later head’s values depend on earlier head’s output). From the paper: induction heads use K-composition with previous-token heads.
Design rationale. The decomposition is exact, not approximate, for attention-only transformers. It is the algebraic language the 2022 paper then uses to name induction heads precisely.
What breaks if removed. Without the residual-stream-as-bus framing, head composition has to be re-derived for each pair of heads. The framework’s contribution is making composition generic, not bespoke. Classification: [New] — the residual-stream-as-linear-bus view is the paper’s signature contribution; the underlying linear algebra was known but had not been organised this way before.
Section 5 (cont.): Method overview — Paper 2 (Induction Heads, 2022)
Plain-English intuition. An induction head completes a pattern. If the prompt has earlier said “Alice loves Paris” and now says “Alice loves”, the induction head looks back to where “Alice loves” appeared before and copies the next token (“Paris”). It does so via a two-head circuit: a layer-1 previous-token head writes each token’s identity into the next slot of the residual stream; a layer-2 induction head then matches the current token against those written-forward identities to find a copy of “where this token last appeared” and attends one position to the right of that match, copying the token there.
Exact mechanism.
- Token at position in layer 1 is the current token .
- The previous-token head copies ‘s identity into the residual stream at position (the slot for the next token, ).
- In layer 2, the induction head computes its query at position (the current position, which also contains ). Its keys at each position read the previous-token-head writing, which contains .
- The query at position therefore matches the key at position , attending to position — i.e., the position holding .
- The OV circuit at position writes the token ‘s value back into the residual stream at position , so becomes the model’s predicted next token.
The mechanism only requires that the layer-2 head’s project from a subspace of the residual stream that the layer-1 head writes into. K-composition score, measured as the fraction of the layer-2 key matrix that aligns with the layer-1 output subspace, is typically 0.2–0.3 in the small models the paper studies.
Six lines of evidence (the paper’s central empirical contribution). From the paper, induction heads are the proposed mechanism for the majority of in-context learning in transformers. The six lines of evidence the paper presents are: (1) macroscopic co-occurrence — induction heads form at the same training step as a measurable jump in in-context-learning ability; (2) macroscopic co-perturbation — when the architecture is changed in a way that delays induction-head formation, the in-context-learning jump shifts to match; (3) direct ablation in small attention-only models — knocking out induction heads abolishes the in-context-learning ability; (4) specific small models — for explicit two-layer attention-only models, the authors trace the induction head end-to-end; (5) mechanistic plausibility — the algorithm the head implements would, if executed by a deliberate engineer, produce in-context learning; (6) continuity with larger models — induction-head-like attention patterns are observed in models up to 13B parameters, though only correlationally.
Phase change. Across model sizes, the paper identifies a narrow training-step window where the in-context-learning loss curve bends sharply — a visible bump rather than a smooth decrease. Induction heads appear in the same window. This is the empirical anchor for the paper’s headline claim. Classification: [New] for the induction-head concept and the six-evidence argument; [Adopted] for the underlying head-composition vocabulary, which comes from the 2021 framework.
Section 5 (cont.): Method overview — Paper 3 (Scaling Monosemanticity, 2024)
Plain-English intuition. Instead of trying to read individual attention heads at frontier scale, the 2024 paper trains a separate small network — a sparse autoencoder — to re-express the residual stream as a sparse sum of named features. The SAE has more features than the residual stream has dimensions (i.e., it is over-complete), but only a few features are allowed to be active on any given activation. The hope, borne out empirically in the paper, is that the active features will line up with human-recognisable concepts.
Exact mechanism.
- Choose a single layer of Claude 3 Sonnet — the 2024 paper uses a middle layer of the residual stream.
- Sample residual-stream activations from a forward pass of the model on training data.
- Train an SAE with encoder and decoder , minimising .
- After training, each column of is a feature direction in the residual stream; each component of is the feature’s activation.
- Interpret features by inspecting the inputs that maximally activate them, then verify the interpretation by clamping the feature high or low at inference time and observing the change in output.
Scale. The paper trains SAEs at three sizes: 1M, 4M, and 34M features. From the paper, “the features are highly abstract, multilingual, multimodal, and generalize between concrete and abstract references.” Notable features documented include the Golden Gate Bridge, code errors, and safety-relevant abstractions; the publicly-deployed “Golden Gate Claude” demo clamped the Golden Gate feature high and the model’s output shifted toward the topic regardless of prompt. 9
Design rationale. SAEs target superposition: the hypothesis that the residual stream packs many more features than its dimension allows, by relying on the sparsity of which features are simultaneously active. An over-complete sparse dictionary is the natural inverse of this packing. Classification: [Adapted] — SAEs and dictionary learning come from the broader interpretability literature, and the 2024 paper credits the 2023 Towards Monosemanticity predecessor for the recipe at toy scale.
Full Transformer architecture schematic (Wikipedia Commons), used for reference on the residual-stream-as-bus framing introduced in Paper 1.
Section 6: Mathematical contributions
MATH ENTRY 1: Residual-stream decomposition (Paper 1).
- Source: 2021 framework, Section “The Residual Stream as a Communication Channel.”
- What it is: a way of writing the transformer’s output as a sum of contributions from each layer, where each layer just adds to a shared vector.
- Formal definition: for a transformer with layers and per-layer output , the residual stream at depth is , and the final output before unembedding is .
- Each term explained:
- is the initial token embedding plus positional encoding, a vector in .
- is the output of layer ‘s attention block (or MLP block), also in .
- The sum is a vector sum: each layer “writes” its contribution by addition.
- Worked numerical example. Take and . Say . Layer 1’s attention output is , so . Layer 2’s output is , so . The unembedding then dots with each row of the unembedding matrix to produce logits over the vocabulary. The point is that every layer’s contribution is still visible in — nothing is overwritten.
- Role: lets the framework write any output dimension as a sum of contributions, one per layer or even one per head.
- Edge cases: the additive structure is exact only when residual connections are pure addition (no LayerNorm), which holds approximately for the small models in the framework.
- Novelty: [New] framing; the algebra was known.
- Transferability: [Analysis] generalises to any architecture with additive residual connections.
- Why it matters: the additive decomposition is what makes circuit-level interpretability possible at all.
MATH ENTRY 2: QK and OV circuits (Paper 1).
- Source: 2021 framework, Section “Attention Heads as Independent Circuits.”
- What it is: a way of rewriting a single attention head as two low-rank matrices, one for “where to look” and one for “what to write.”
- Formal definition: where is a matrix of rank at most ; the head’s contribution to the residual stream is where , also rank-.
- Each term explained and dimensional analysis:
- is a matrix of token-position residual vectors.
- , so but its rank is bounded by .
- with rows summing to 1 (a probability distribution over attended positions).
- and , so , again rank .
- Worked numerical example. Set , , . Take as the rank-2 outer product of and , so has a 1 at row 1 column 3 and zeros elsewhere. For and , (a strong attention score from position 1 to position 3). Now suppose writes the value at position 3 into the residual at position 1 by identity in a two-dimensional subspace, with the value vector being . Then position 1 receives as its head output — exactly what an OV-write would do if it were copying position 3’s identity. Notice how QK chose where, OV chose what, and the two are independent matrices.
- Role: the algebraic foundation for naming circuits like the induction head.
- Edge cases: at finite , both circuits are inexact; the framework treats them as exact within the rank- subspace and lossy outside it.
- Novelty: [New] as a named pair; the underlying products were standard.
- Transferability: [Analysis] applies unchanged to multi-query attention and grouped-query attention with appropriate reindexing.
- Why it matters: separating where from what is the move that makes higher-level circuit composition tractable.
MATH ENTRY 3: Induction-head composition (Paper 2).
- Source: 2022 paper, Section “How Induction Heads Work.”
- What it is: a formal characterisation of the two-head circuit that implements pattern completion.
- Formal definition: an induction head is a pair of attention heads in different layers such that (i) ‘s OV circuit shifts token identity by one position (the previous-token head property), and (ii) ‘s K-composition score with is non-trivial — that is, ‘s projects significantly from the subspace ‘s writes into.
- Each term explained:
- is the key matrix of the layer-2 induction head.
- The “K-composition score” is the Frobenius-norm fraction of that lies inside . Empirically 0.2–0.3 in small attention-only models. [Reconstructed] — the precise scalar definition follows from the 2021 framework’s composition-measure construction; the 2022 paper cites the framework rather than restating it inline.
- Worked numerical example. Take . Suppose writes only into the last two coordinates of the residual stream (i.e., its image is the subspace spanned by and ). For the induction head , suppose has columns and (it reads exactly from the subspace writes into) — its K-composition score with is then close to 1, an idealised induction head. If instead had columns and (it reads only from the subspace does not write into), the K-composition score would be 0 and the induction circuit would be broken. The 0.2–0.3 empirical scores live between these extremes.
- Role: gives a measurable, falsifiable definition of the induction-head construction.
- Edge cases: the score is informative only when does write the previous-token signal in the first place; previous-token heads have to be identified separately.
- Novelty: [New] as a named construction; the composition measure is [Adopted] from the 2021 framework.
- Why it matters: the K-composition score is the falsifiability bridge — without it the induction-head story would be untestable.
MATH ENTRY 4: Sparse-autoencoder objective (Paper 3).
- Source: 2024 Scaling Monosemanticity, methodology section.
- What it is: the loss that trains the SAE to reconstruct residual-stream activations from a sparse code.
- Formal definition: where , , and is the sparsity penalty.
- Each term explained:
- is a sampled residual-stream activation; e.g., is typically several thousand for a Sonnet-class model.
- is the encoder; is the sparse code.
- is the decoder, whose columns are the feature directions.
- controls the trade-off between reconstruction fidelity and sparsity.
- Worked numerical example. Take , , . Suppose . Suppose the encoder fires only on features 2 and 5, with , so . Suppose the decoder reconstructs , so . Total loss is on this example — sparsity-dominated, as expected when is set to push the encoder toward few active features. The encoder will adjust to lower one of the two active feature activations if the reconstruction loss permits.
- Role: defines what “features” the 2024 paper recovers; varying between 1M, 4M, and 34M gives the paper’s scaling sweep.
- Edge cases: with too high, features collapse to zero and reconstruction fails; with too low, features become dense and lose interpretability. The 2024 paper documents the sweep used to land on production values.
- Novelty: [Adapted] from classical dictionary learning and the 2023 Towards Monosemanticity recipe; the 2024 paper’s contribution is the scale, not the loss.
- Why it matters: the L1 penalty is the only thing pushing the autoencoder toward monosemanticity; without it the autoencoder would just learn an arbitrary basis.
MATH ENTRY 5: Feature-clamping intervention (Paper 3).
- Source: 2024 paper, “Feature steering” and “Influence on behavior” sections.
- What it is: the causal-intervention operator that turns a feature interpretation into a falsifiable claim.
- Formal definition: at inference time, replace with a fixed value in the SAE’s intermediate code, then compute where is with the -th coordinate replaced. Add as a perturbation to the original residual-stream activation in the model’s forward pass, propagate to the output.
- Worked numerical example. Reuse the Math Entry 4 setting: . Clamp feature 5 to , well above its natural maximum. Then , and the change in reconstructed residual is . Adding to the original residual-stream activation pushes the model’s downstream output in the direction the feature represents. In the Golden Gate Claude demo, the analogous clamp on the Golden Gate Bridge feature caused the model to mention the bridge in nearly any context.
- Role: the falsifiability mechanism for SAE feature interpretations — a feature labelled “Golden Gate Bridge” should, when clamped high, make the model produce text about the Golden Gate Bridge.
- Edge cases: clamping too aggressively can push the activation out of the model’s normal operating regime and produce gibberish; the paper documents the operating range.
- Novelty: [Adapted] from classical activation-patching interventions, applied to SAE features.
- Why it matters: without intervention, an SAE feature is correlational; with intervention, it becomes causally tied to a behaviour.
Section 7: Algorithmic contributions
ALGORITHM ENTRY 1: Induction-head detection (Paper 2).
- Source: 2022 paper, methodology section and Appendix.
- Purpose: given a trained transformer, find the attention heads that behave as induction heads.
- Inputs: a trained transformer ; a corpus of repeated-token sequences for testing (the paper uses synthetic sequences with a deliberate repeating segment).
- Outputs: a list of (layer, head) pairs flagged as induction heads, with an “induction score” per head.
- Pseudocode (faithful reconstruction of the standard induction-score protocol — [Reconstructed] where the exact constant offsets are paper-internal):
for each (layer L, head H) in transformer pi:
induction_score[L, H] = 0
for each test sequence s with repeated subsequence:
positions = indices where the repeat begins
attention = forward(pi, s).attentions[L, H]
for t in positions:
# the induction head should attend ~1 step after
# where the current token previously appeared
target = previous_occurrence(s, t) + 1
induction_score[L, H] += attention[t, target]
induction_score[L, H] /= number_of_positions
return {(L, H) : induction_score[L, H] > tau}- Hand-traced example. Take a 2-layer attention-only transformer; test sequence is
[X, Y, Z, X, Y, ?]where?is the position the model predicts. Suppose layer-1 head 0 is a previous-token head (writes token identity from into slot ). For layer-2 head 1 we compute attention from position 5 (current token afterX, Y) back to position 2 (the priorYslot, which now containsZ-shifted). If attention[5, 2] is near 1, the induction score for (layer 2, head 1) on this sequence is close to 1. Averaged over many test sequences, an induction head will score near 1; a non-induction head will score near . - Complexity: for test sequences of length . Bottleneck step: the forward pass.
- Hyperparameters: (threshold), (test corpus size), (sequence length). Sensitivity: the paper finds the head population is bimodal — induction heads score visibly above the rest — so the threshold choice is robust.
- Failure modes: in larger MLP-bearing models, the induction-like behaviour can be distributed across multiple heads and a single threshold becomes harder to set.
- Novelty: [New] as a packaged detection procedure; the underlying attention-introspection moves are [Adopted] from prior interpretability work.
- Transferability: [Analysis] reusable for any decoder-only transformer; encoder-decoder variants need re-derivation.
ALGORITHM ENTRY 2: SAE training loop (Paper 3).
- Source: 2024 paper, methodology and training-details sections.
- Purpose: train a sparse autoencoder on residual-stream activations of a frozen Claude 3 Sonnet.
- Inputs: a frozen Claude 3 Sonnet ; a chosen middle layer ; a corpus of training texts; hyperparameters (sparsity penalty), (feature count), learning rate , batch size.
- Outputs: trained encoder and decoder such that the SAE reconstructs activations of layer with low MSE while keeping small.
- Pseudocode (faithful reconstruction):
freeze pi
sample N activations:
for each text in corpus:
x_batch = forward(pi, text).residual_stream[layer = l_star]
store x_batch
initialize W_e, b_e, W_d, b_d (typically W_d columns unit-norm)
for epoch in epochs:
for x in stored activations:
f = ReLU(W_e @ x + b_e)
x_hat = W_d @ f + b_d
L_recon = ||x - x_hat||_2^2
L_sparsity = lambda * ||f||_1
L = L_recon + L_sparsity
backprop on L; update W_e, b_e, W_d, b_d
renormalize W_d columns to unit norm # standard SAE trick- Hand-traced example. Take , , batch size 2, . Initial random, random unit-norm columns. First batch: . , say it gives . , say it gives . . . Total loss 0.77. Backprop pushes in directions that lower MSE without inflating . After many steps, becomes sparse and tracks closely on most inputs.
- Complexity: dominated by the forward passes of Claude 3 Sonnet to harvest activations; SAE training itself is cheap relative to LM training. The 2024 paper does not publish full hardware budgets but flags compute as substantial. 7
- Hyperparameters: , , learning rate, batch size, unit-norm renormalisation of columns (a standard SAE stability trick).
- Failure modes: dead latents (features that never activate post-training); the paper documents mitigations but flags this as an open issue.
- Novelty: [Adapted] from the 2023 Towards Monosemanticity recipe and broader dictionary-learning literature; the 2024 contribution is that it scales, not that it is a new objective.
- Transferability: [Analysis] applies to any decoder-only LM whose residual-stream activations can be harvested.
Section 8: Specialised design contributions
Subsection 8A — LLM / prompt design. Not applicable to this paper cluster. The 2024 paper uses Claude 3 Sonnet as the substrate for SAE training but does not introduce new prompts as a contribution.
Subsection 8B — Architecture-specific details. From the paper: the 2024 SAE attaches to a middle layer of the residual stream rather than an early or late layer; the choice trades off feature concreteness (later layers) against feature primitiveness (earlier layers). The 2022 paper studies decoder-only transformers with both attention-only and attention-plus-MLP variants. The 2021 framework is restricted to attention-only architectures.
Subsection 8C — Training specifics. Paper 1: small attention-only transformers trained for the purpose, exact hyperparameters in the paper’s appendix. Paper 2: sweep of model sizes up to 13B parameters; standard decoder-only autoregressive language-modelling loss. Paper 3: Claude 3 Sonnet, released March 2024, used as a frozen backbone; SAE trained on harvested activations with the loss in MATH ENTRY 4. From the paper, the SAEs are trained at three sizes: 1M, 4M, and 34M features.
Subsection 8D — Inference / deployment specifics. Paper 3’s “feature steering” is an inference-time operation (MATH ENTRY 5); the public Golden Gate Claude demo was a deployed variant that clamped the Golden Gate feature. The 2024 paper does not promise that SAE features generalise to fine-tuned variants of Sonnet; that remains an open generalisation question.
Section 9: Experiments and results
Datasets. Paper 1: synthetic next-token sequences for the attention-only models it trains. Paper 2: a curated corpus including The Pile and the paper’s repeated-token diagnostic sequences; the in-context-learning measurement uses the loss decrease from the 50th to 500th token of a sequence as the operational definition of ICL. Paper 3: a large internal text corpus used to harvest activations from Claude 3 Sonnet.
Baselines. Paper 2 baselines its causal claims internally — induction heads are knocked out and the ICL measurement re-run on the same model. There is no external SOTA-style benchmark; the paper’s claim is mechanistic, not headline-number-driven. Paper 3 has no direct prior baseline at Sonnet scale; the 2023 Towards Monosemanticity one-layer transformer is the closest comparator and serves as a sanity check that the recipe scales.
Evaluation metrics. Paper 1 introduces algebraic-decomposition metrics: composition measures (Q, K, V) measured as Frobenius-norm fractions. Paper 2’s headline metric is the per-token in-context-learning loss decrease, plus the induction score from Algorithm 1. Paper 3 uses (a) reconstruction MSE, (b) the L1-norm-weighted sparsity, (c) qualitative interpretability of top-activating examples per feature, and (d) downstream behavioural change under feature clamping.
Main quantitative results.
- Paper 1: heads with high K-composition scores between layers exist in the small attention-only models analysed; the framework identifies which heads compose.
- Paper 2: the in-context-learning phase change coincides with induction-head emergence across all studied model sizes; ablation of induction heads in small attention-only models abolishes the in-context-learning ability.
- Paper 3: 34M features extracted from Claude 3 Sonnet’s mid-layer activations; selected features include Golden Gate Bridge, code error, deception-related, and sycophancy-related directions; feature clamping causally shifts model output.
Independent benchmark cross-checks for SOTA claims. None of the three papers makes a head-to-head SOTA claim against a competing method. The 2024 paper is best read as a capabilities demonstration of the SAE methodology rather than a benchmark win. [External comparison] Concurrent SAE work from OpenAI 3 reaches similar conclusions on GPT-4 scale activations; the two efforts use different sparsity penalties (L1 vs TopK) but agree on the headline that SAEs surface monosemantic features at scale.
Ablations. Paper 1 ablates head composition by zeroing entries; Paper 2 ablates entire induction heads. Paper 3 does not ablate the SAE itself (the SAE is the analysis tool), but it ablates features in the backbone model via clamping (MATH ENTRY 5).
Hyperparameter sensitivity. Paper 3 reports sensitivity to and to ; lower yields denser, less interpretable features; higher yields more concept-specific features but with diminishing returns past 34M at the Sonnet scale studied.
Qualitative results. Paper 2 traces specific induction-head circuits in small attention-only models end-to-end. Paper 3 publishes example “feature cards” showing top-activating dataset examples for selected features and the model’s response under feature clamping. The Golden Gate Claude demo is the public-facing qualitative result. 9
Evidence audit.
- Strongly supported. Paper 1’s algebraic decomposition for attention-only transformers; Paper 2’s claim about induction-head emergence in small attention-only models; Paper 3’s claim that SAE features at 34M scale include interpretable directions.
- Partially supported. Paper 2’s extension of the induction-head story to larger MLP-bearing models, which is correlational rather than causal; from the paper, this gap is acknowledged.
- Reliant on narrow evidence. The fraction of all in-context learning that is mediated by induction heads (rather than other mechanisms) is supported strongly only in small attention-only models. [Reviewer Perspective] The headline framing — induction heads as the mechanism for in-context learning — is suggestive, not proven, at scale.
Section 10: Technical novelty summary
| Component | Type | Novelty level | Justification | Source |
|---|---|---|---|---|
| Residual-stream-as-bus framing | Algebra | Combination novel | Re-organises known matrix products to make composition tractable | Paper 1, Section “Residual Stream” |
| QK / OV circuit naming | Algebra | Fully novel as a named pair | Per the 2021 framework | Paper 1 |
| Composition measures (Q, K, V) | Metric | Fully novel | Per the 2021 framework | Paper 1 |
| Induction-head concept | Mechanism | Fully novel | Per the 2022 paper | Paper 2 |
| Six-evidence argument | Experimental design | Combination novel | Standard ablation + emergence-curve techniques combined into a multi-pronged argument | Paper 2 |
| Phase-change observation for ICL | Empirical | Fully novel as a documented phenomenon | Per the 2022 paper | Paper 2 |
| SAE at Sonnet scale | Engineering | Incrementally novel | Recipe from 2023 Towards Monosemanticity; scale and selection of features are new | Paper 3 |
| Feature steering on production models | Intervention | Combination novel | Activation patching applied to SAE features at scale | Paper 3 |
Single most novel contribution. [Analysis] The induction-head identification (Paper 2) is the cluster’s most novel contribution in the strict sense — it is the first time a specific named circuit was tied causally to a high-level emergent behaviour (in-context learning) inside a transformer. Paper 1 supplies the language; Paper 3 supplies the scale; Paper 2 supplies the mechanism that earned the cluster its place in the canon.
What the papers do NOT claim to be novel. Sparse autoencoders (Paper 3, [Adopted] from 2023 predecessor); the underlying matrix algebra (Paper 1, [Adopted] from standard transformer notation); standard activation-patching (Paper 3, [Adopted]).
Section 11: Situating the work
Prior work. Mechanistic interpretability before 2021 was anchored on vision models via the Distill Circuits Thread. 10 Linear probing and attention-pattern visualisations existed for language models but did not yield mechanistic accounts. The three papers reframe the field around (a) named circuits as the unit of analysis and (b) sparse features as the unit of representation.
What this cluster changes conceptually. Pre-2021, “what is this attention head doing?” was answered by inspecting its attention patterns. Post-2021, the answer involves which subspace of the residual stream the head reads from and writes to, and which other heads compose with it. Post-2024, attention-head-level analysis is supplemented by SAE-feature-level analysis on the residual stream itself, which dodges the attention-pattern interpretation difficulty entirely on the way to a different unit of explanation.
Contemporaneous related papers.
- Toy Models of Superposition (Elhage et al., Anthropic, 2022) 11 — establishes the superposition hypothesis that motivates SAEs. The 2024 paper builds on it directly; the relationship is parent-child.
- Scaling and Evaluating Sparse Autoencoders (Gao et al., OpenAI, 2024) 3 — concurrent SAE work on GPT-4 scale activations using TopK sparsity. [External comparison] The Anthropic and OpenAI SAE recipes differ in the sparsity penalty (L1 vs TopK) but agree on the headline that SAEs scale to frontier models.
- Locating and Editing Factual Associations in GPT (Meng et al., 2022) — adjacent mechanistic-interpretability strand that uses causal mediation analysis rather than circuit decomposition. The two strands are complementary; the 2024 paper’s intervention recipe shares conceptual DNA.
[Reviewer Perspective] Strongest skeptical objection. The induction-head story is causal only in attention-only toy models. In production-scale models with MLPs, the evidence is correlational — induction-head-like patterns appear alongside in-context learning, but ablating them at scale has not been demonstrated to abolish ICL the way it does in toy models. A skeptic can reasonably hold the position that induction heads are one mechanism but not necessarily the mechanism at frontier scale.
[Reviewer Perspective] Strongest author-side rebuttal. The cluster’s response, implicit across all three papers, is that mechanistic interpretability proceeds by examples-of-things-found rather than by coverage-of-all-things. Finding even one named circuit that explains a behaviour is a contribution; the existence of additional mechanisms does not invalidate the named one. Paper 3’s SAE feature catalogue is best read in this spirit — a sample of an enormous feature library, not a claim to enumerate it.
What remains unsolved. The fraction of model computation that can be mechanistically explained at any given scale; whether SAE feature catalogues at different layers can be composed back into a circuit-level account; whether features generalise across fine-tuned variants of the same base model.
Three future research directions.
- MLP-block decomposition at the same algebraic depth as the 2021 framework. The framework’s elegance breaks at MLP layers; a successor framework would need to handle elementwise non-linearity gainfully. [Analysis]
- Cross-layer circuit composition over SAE features. The 2024 paper studies one layer; the open question is whether feature catalogues from adjacent layers compose into named circuits. [Analysis]
- Feature-level safety auditing. Given a feature labelled “deception” or “sycophancy”, the open practical question is whether feature-level monitoring is robust to adversarial inputs that activate the feature without surface-level signal. [Reviewer Perspective]
Section 12: Critical analysis
Strengths. Paper 1’s algebraic decomposition is genuinely tight — it is exact for attention-only transformers, not approximate. Paper 2’s six-evidence argument is the most carefully constructed empirical argument in the cluster; even readers who reject the headline framing can verify the underlying observations (phase change, K-composition score, ablation effect in toy models). Paper 3’s scale demonstration is the headline result that moved the field; SAE feature catalogues at the 34M scale are now standard reference material for downstream interpretability work.
Weaknesses explicitly stated by the authors.
- Paper 2: the evidence is causal only in small attention-only models; in larger MLP-bearing models it is correlational.
- Paper 3: the 34M features extracted are a small fraction of the total features the residual stream plausibly carries; many features remain hard to label; dead latents are an open issue.
Weaknesses not stated or understated. [Reviewer Perspective]
- Selection bias in feature reporting. Paper 3’s feature catalogue showcases interpretable features; the proportion of features that are not interpretable is harder to read off the paper. Independent commentary on LessWrong and substack writeups has flagged this as a presentational concern. 8
- Layer-choice sensitivity. Paper 3 studies one middle layer; whether the feature catalogue would look meaningfully different at adjacent layers is not directly addressed in the body.
- The induction-head story does not exclude alternative explanations of in-context learning at scale. The cluster’s framing — induction heads as the mechanism behind ICL — is suggestive but the paper itself uses more cautious wording; secondary coverage sometimes loses the hedge.
Reproducibility check.
- Code. Paper 2’s analysis code was partially released via the TransformerLens community library; Paper 3’s training code was not released as of the paper’s publication. 6
- Data. Synthetic test corpora from Paper 2 are reconstructible. Claude 3 Sonnet activations from Paper 3 are not publicly available.
- Hyperparameters. Papers 1 and 2 publish hyperparameters in their appendices; Paper 3 publishes the broad recipe and key choices but not every training-run hyperparameter.
- Compute. Paper 3 acknowledges substantial compute; precise hardware budget not reported. 7
- Trained model weights / SAE checkpoints. The 2024 SAE checkpoints were not publicly released alongside the paper.
- Overall. Partially reproducible — the methodological recipe is documented end-to-end, but reproducing the 2024 results requires Sonnet access and substantial compute. The 2021 and 2022 results are reproducible by an interested researcher with modest compute.
Methodology.
- Sample size: paper 2 evaluates across model sizes from to parameters with a held-out evaluation corpus. Paper 3 trains on millions of activations harvested from Sonnet forward passes; exact training-set size not reported.
- Evaluation set: paper 2’s ICL measurement uses held-out next-token loss curves; paper 3’s feature evaluation is qualitative (top-activating examples) plus causal (clamping).
- Baselines: paper 2 internal-ablation baselines only; paper 3 the 2023 one-layer SAE as a recipe predecessor.
- Hardware/compute: not reported in the cluster at the level needed for a precise replication estimate.
Generalisability. Paper 1’s framework generalises to any attention-only transformer architecture and approximately to MLP-bearing ones. Paper 2’s induction-head story has been replicated by external researchers on additional model families. Paper 3’s SAE recipe has been replicated by OpenAI on GPT-4 and by community projects on open-weight models, with similar qualitative findings.
Assumption audit. Revisiting the Section 3 assumptions: the attention-only assumption (Paper 1) is the most fragile and is the central limitation that motivates Paper 3’s substrate change. The single-layer SAE-attach assumption (Paper 3) is a pragmatic choice, not a methodological necessity; multi-layer SAE catalogues are an active research direction. The induction-head-mediates-ICL hypothesis (Paper 2) is well-supported at small scale and suggestive at large.
What would make the cluster significantly stronger. [Analysis] Causal evidence that induction-head ablation at frontier scale abolishes the ICL phase-change behaviour, rather than just correlational co-occurrence; release of SAE checkpoints alongside the 2024 paper to enable third-party replication; an MLP-block decomposition framework matching the elegance of the 2021 attention framework.
Section 13: What is reusable for a new study
REUSABLE COMPONENT 1: Composition-measure metric (from Paper 1).
- What it is: the Frobenius-norm fraction of a later head’s // that aligns with an earlier head’s image.
- Why worth reusing: a single scalar that captures whether one head reads from another head’s output; falsifiability bridge for any circuit hypothesis.
- Preconditions: access to model weights; the attention-only-derivation assumption is most precise but the metric is still informative with MLPs.
- What would need to change in a different setting: rescaling for very large models; the metric was tuned on small models.
- Risks: false positives in models where many heads incidentally write into overlapping subspaces.
REUSABLE COMPONENT 2: Induction-score detection (from Paper 2).
- What it is: a per-head score for “is this an induction head?” computed on synthetic repeated-token sequences.
- Why worth reusing: a coarse interpretability probe usable on any decoder-only transformer.
- Preconditions: a generation of synthetic test sequences with controlled repetition.
- What would need to change: thresholds may need re-tuning across architectures.
- Risks: in larger MLP-bearing models, induction-like behaviour can be distributed.
REUSABLE COMPONENT 3: SAE-on-residual-stream recipe (from Paper 3).
- What it is: train a sparse autoencoder on harvested mid-layer residual-stream activations, then interpret features by top-activating examples and validate by clamping.
- Why worth reusing: state-of-the-art technique for feature-level interpretability on any decoder-only LM as of 2024–2026.
- Preconditions: substantial compute; access to a chosen layer’s activations on a large corpus; tooling for activation harvesting.
- What would need to change: layer choice and feature count are model-dependent; sparsity penalty schedule must be re-tuned.
- Risks: dead latents; selection bias in reporting “good” features; the recipe is the easy part, interpreting the millions of recovered features is the hard part.
Dependency map in text form. Component 1 is a precondition for Component 2 in spirit (you need composition measures to even pose the induction-head hypothesis precisely), though Component 2 can be deployed standalone. Component 3 is largely independent of 1 and 2 — it works on a different substrate.
Recommendation. [Analysis] For a new mechanistic-interpretability study on a frontier model, the highest-value combination is (a) Component 3 to surface a feature catalogue, then (b) Component 1’s composition measures to look for circuits between SAE features at adjacent layers. This is roughly the research direction the field has moved into post-2024.
[Analysis] What type of new study benefits most. Safety-flavoured interpretability studies (find a feature that fires on deceptive outputs; show clamping it suppresses the behaviour; show feature persists across fine-tunes) are the highest-payoff downstream application of the cluster.
Section 14: Known limitations and open problems
Limitations explicitly stated by the authors.
- Paper 2: causal evidence only at small attention-only scale; correlational at MLP-bearing scale.
- Paper 3: 34M features are a small fraction of plausible total; many features remain hard to label; dead latents; layer-choice not exhaustively studied.
Limitations not stated.
- [Analysis] The cluster does not provide a recipe for combining attention-circuit-level and SAE-feature-level explanations into a unified account; this is a structural gap rather than an oversight.
- [Reviewer Perspective] Public-facing demonstrations (Golden Gate Claude) emphasise dramatic interventions; the typical feature’s behaviour under clamping has not been characterised statistically across the catalogue.
Technical root cause. The cluster’s substrate split — algebra-of-attention in 2021/2022, feature-dictionaries in 2024 — is the price of the substrate change. The algebra framework is exact but breaks at MLP layers; the SAE framework scales but loses the named-circuit-level structure of the algebra approach.
Open problems.
- Causal evidence for the induction-head-ICL link at frontier scale.
- MLP-block decomposition matching the 2021 framework’s elegance.
- Cross-layer composition of SAE features.
- Feature-catalogue completeness and selection-bias measurement.
- Generalisation of features across fine-tuned model variants.
What a follow-up paper would need to solve. The most critical limitation is the combination problem: stitching the algebra-of-attention story (Papers 1–2) and the feature-dictionary story (Paper 3) into one account. A follow-up that delivered cross-layer SAE-feature circuits with composition measures attached would close the cluster’s central structural gap.
How this article reads at three depths
For the curious high-school reader. A language model like Claude is a stack of matrix operations, and these three papers from Anthropic ask: what is each part of the stack actually doing? The first paper invents a clear way to describe attention. The second paper uses that description to identify a specific two-step machine inside the model — the induction head — that lets the model learn from examples in its prompt. The third paper scales the question up to a frontier model and finds millions of “features” inside, including one that fires for the Golden Gate Bridge. Together, the three papers are the closest the field has come to actually seeing what is inside a language model’s head.
For the working developer or ML engineer. Treat the residual-stream-as-bus framing as a reusable mental model — it tracks what every attention block contributes to the final logit and clarifies why some ablations cascade. Induction-score detection is a near-zero-cost interpretability probe on any decoder-only transformer; running it before any deeper mechanistic work helps narrow the head population that matters. SAEs are the right tool when the question is “what concepts does this model represent?” rather than “which heads run this behaviour”; expect substantial compute for the activation-harvest step and substantial human time for the feature-labelling step. Feature clamping is the falsifiability move that turns correlation into causation; do not trust a feature interpretation that has not been validated by clamping. The cluster is the canonical reading list before any serious interpretability work; later papers assume its vocabulary.
For the ML researcher. The 2021 framework’s algebra of QK / OV circuits and composition measures is the field’s de facto notation for attention-circuit analysis; the 2022 paper is the canonical existence proof of a named circuit tied causally to an emergent capability at toy scale; the 2024 paper is the existence proof that dictionary learning on the residual stream surfaces interpretable features at frontier scale. The cluster’s load-bearing assumption is the attention-only restriction in the 2021 framework, which the 2024 paper effectively side-steps by switching substrates rather than extending the algebra. The strongest objection is that the induction-head-as-ICL-mechanism story is causal only at toy scale; the cluster’s framing acknowledges this but secondary coverage sometimes does not. A follow-up paper closing the gap — cross-layer SAE-feature circuits with composition measures and causal interventions at frontier scale — is the natural next step the field is converging toward.
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. Elhage, Nanda, Olsson et al., *A Mathematical Framework for Transformer Circuits*, transformer-circuits.pub, December 2021. (accessed ) ↩
- 2. Olsson, Elhage, Nanda et al., *In-context Learning and Induction Heads*, transformer-circuits.pub, September 2022; arXiv:2209.11895. (accessed ) ↩
- 3. Templeton, Conerly, Marcus et al., *Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet*, transformer-circuits.pub, May 2024. OpenAI's concurrent SAE work, *Scaling and Evaluating Sparse Autoencoders* (Gao et al., 2024, arXiv:2406.04093), reaches similar conclusions on GPT-4 scale activations. (accessed ) ↩
- 5. Bricken, Templeton et al., *Towards Monosemanticity: Decomposing Language Models With Dictionary Learning*, transformer-circuits.pub, October 2023 — the toy-scale predecessor of the 2024 paper. (accessed ) ↩
- 6. TransformerLens — community-maintained library that implements the analyses used in the 2022 induction-heads paper and many follow-on works. (accessed ) ↩
- 7. Anthropic, *The engineering challenges of scaling interpretability* — companion piece flagging compute and engineering cost of the 2024 effort. (accessed ) ↩
- 8. LessWrong, *A "Scaling Monosemanticity" Explainer* — community commentary flagging presentational and selection-bias concerns in the 2024 paper. (accessed ) ↩
- 9. Anthropic, *Mapping the Mind of a Large Language Model* — public-facing companion to the 2024 paper, including the Golden Gate Claude demonstration. (accessed ) ↩
- 10. Olah et al., *Circuits Thread* on Distill — the predecessor mechanistic-interpretability research line on vision models that motivates the transformer-circuits programme. (accessed ) ↩
- 11. Elhage et al., *Toy Models of Superposition*, transformer-circuits.pub, 2022 — the superposition hypothesis that motivates SAE-based interpretability. (accessed ) ↩
Further Reading
- arXiv preprint of induction-heads paper (2209.11895) (accessed )
- Transformer Circuits Thread — landing page (accessed )
- Quanta Magazine — Researchers Glimpse How AI Gets So Good at Language Processing (induction-heads coverage) (accessed )
Anonymous · no cookies set