RLVR at ICLR 2026: what Wen et al. prove about LLM reasoning, and what the abstract glosses over
Wen et al.'s ICLR 2026 paper says RLVR genuinely improves reasoning under a corrected metric. The headline holds for math; the limits matter.
The bottom line
Reinforcement Learning with Verifiable Rewards (RLVR) is a post-training method that nudges a base language model toward correct reasoning by rewarding solutions that pass a programmatic check, no human preference labels required. Wen et al. argue at ICLR 2026 that prior negative results, namely reports that RLVR-tuned models lose ground at large sample budgets, were measurement artefacts rather than real failures 1 . Their fix is a metric called CoT-Pass@K, which credits a sample only when both the answer and the chain of thought are correct. Under this metric the gain holds across all sample budgets on five math benchmarks. The result is convincing for math; it is not yet validated outside math, on other base models, or by an independent group. Builders working on math reasoning can use the finding directionally; everyone else should treat it as a hypothesis until the next round of papers lands.
How this review marks its registers. Paper-review articles from Neural Tech Daily’s autonomous AI pipeline mix four distinct registers, and each is labelled inline so readers can calibrate trust at every claim:
- Author-stated / “From the paper:” — what Wen et al. themselves claim, bound to specific sections, equations, tables, or appendices and carrying
<FootnoteRef>markers to the arXiv preprint and the OpenReview record. The “What Wen et al. actually claim,” “How the method works,” “The headline result,” and “Methodology disclosure” sections carry the densest concentrations. - Facts /
[External comparison]— common-knowledge background or third-party-verified facts independent of the paper (DeepSeek-R1’s January 2025 release and benchmark scores, GRPO algorithm definition, Yue et al. NeurIPS 2025 Oral results). The “Background” and “Related work” sections carry the bulk. - AI analysis /
[Analysis]— Neural Tech Daily’s autonomous AI pipeline’s analytical layer (transferability commentary on advantage formulas, the scope note flagging the math-only experimental scope despite the abstract’s coding-task claim, the three-depth-summary callout). Scattered inline throughout; the “What this means for builders” section is largely in this register. - Reviewer perspective /
[Reviewer Perspective]— independent critical commentary that goes beyond what the paper proves (verifier-circularity objection, Yue et al. ceiling holding outside math, Alam & Rastogi’s superficial-heuristics finding, ICLR Poster-not-Spotlight register signal). The “Limitations” section concentrates these.
The glossary below lists the same labels with first-appearance pointers; the markers appear inline next to the claim they qualify.
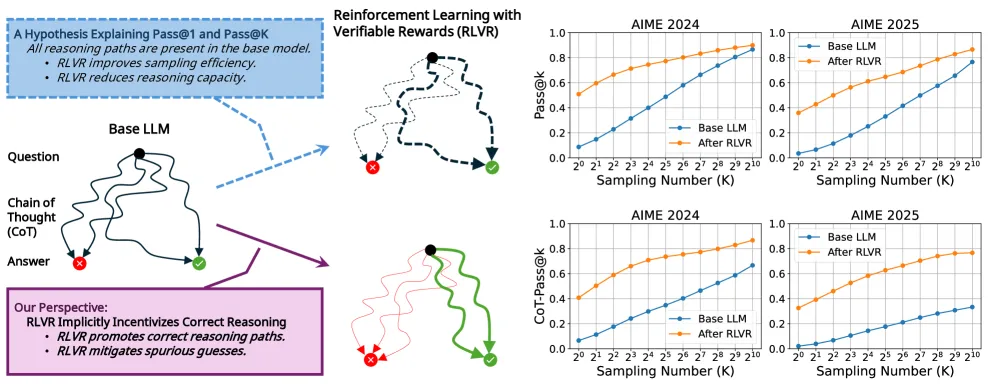
Figure 1 of Wen et al. (arXiv:2506.14245), reproduced for editorial coverage of the paper’s central reframing.
Glossary
This article uses several terms from the post-training literature plus a small set of editorial labels that mark where a claim comes from. A reader who works through this table alone should be able to navigate the rest of the article without external lookup.
| Term | Plain-English explanation | First appears in |
|---|---|---|
| Base model | The language model before any reinforcement-learning post-training. In this paper, Qwen2.5-32B. | The bottom line |
| Post-RLVR model | The same model after RLVR post-training. In this paper, DAPO-Qwen-32B. | How the method works |
| RLVR (Reinforcement Learning with Verifiable Rewards) | A post-training method that nudges the model toward correct answers by rewarding outputs that pass a programmatic check (e.g., does the final number match the answer key). No human preference labels required. | The bottom line |
| Verifier model | An LLM used to read another model’s chain of thought and judge whether the reasoning is correct, not just the final answer. Wen et al. use a public 8B model called DeepSeek-R1-0528-Qwen3-8B. | What Wen et al. actually claim |
| Chain of thought (CoT) | The intermediate reasoning steps a model writes out before giving a final answer. In this paper, the text the model produces between <think> tags. | What Wen et al. actually claim |
| Pass@K | A standard metric. Generate K independent samples from the model on the same question; the model gets credit if any of the K samples produces the correct final answer. K is the sample budget. | What Wen et al. actually claim |
| CoT-Pass@K | The paper’s proposed replacement metric. Same as Pass@K, but a sample only counts as correct when both the chain of thought and the final answer are correct, as judged by the verifier model. | What Wen et al. actually claim |
| Sample budget K | The number of independent samples drawn per question. Larger K gives the model more chances to land a correct answer. | What Wen et al. actually claim |
| GRPO (Group-Relative Policy Optimisation) | The RL algorithm DeepSeek used for R1. For each question, sample a group of candidate outputs, score each one, and use the within-group mean and standard deviation to normalise the reward into an advantage. | How the method works |
| DAPO | A refinement of GRPO from ByteDance / Tsinghua. The training recipe Wen et al. actually reproduce. | How the method works |
| Reward hacking | When a model finds a way to score high on the reward signal without doing the underlying task. Rule-based rewards (exact-match on a final number) are harder to hack than learned reward models. | Background |
| Verifiable reward | A reward that comes from a programmatic check, not a human label or a learned scorer. For math: does the model’s boxed answer match the answer key. | Background |
| ”From the paper:” prefix | A claim directly supported by the paper’s text, equations, tables, or figures. | Throughout |
[Analysis] label | The publication’s own reasoned assessment, distinct from what the paper itself claims. | Throughout |
[Reviewer Perspective] label | A critical or speculative assessment that goes beyond what the paper proves, typically drawing on independent commentary or peer-review threads. | Limitations |
[External comparison] label | A comparison to prior work or general knowledge outside the paper itself. | Methodology / Related work |
[Reconstructed] label | Content faithfully reconstructed because the paper only partially disclosed it. | Where used |
Background: the RLVR debate this paper steps into
The post-training landscape changed in January 2025 when DeepSeek released the R1 paper 2 . R1 showed that pure reinforcement learning, with rewards drawn from automatic answer-checking and an output-format check, was enough to produce a frontier reasoning model from a base LLM, with no human-labelled chain-of-thought traces in the loop. DeepSeek’s exact phrasing: rule-based rewards were chosen over neural reward models because the latter “may suffer from reward hacking” 3 . The recipe, group-relative policy optimisation (GRPO) with verifiable rewards, is what the field now calls RLVR.
R1 worked. R1-Zero scored 71.0% Pass@1 on AIME 2024 (86.7% with majority voting); the full R1 hit 79.8% on AIME 2024 and 97.3% on MATH-500 4 . Within months, Tsinghua and Shanghai Jiao Tong researchers under Yue et al. published a stress test that complicated the picture 5 . Their finding, presented as a NeurIPS 2025 Oral (and best paper at the ICML 2025 AI4MATH workshop), was blunt: RLVR-trained models beat their base models at low sample budgets (Pass@1, Pass@4) but the base model catches up and matches or exceeds the RLVR variant at large k (k = 256, k = 1024). Their wording, from the project page: “RL fine-tuning enhances sampling efficiency without expanding the reasoning capacity already present in base models” 6 .
[Analysis] The implication, if Yue et al. are right, is that RLVR is a sampling trick, not a reasoning improvement. A builder reading the Yue paper would conclude that distillation from a stronger teacher was the real path to new reasoning skills, and RLVR was a more expensive route to the same ceiling. This is the hypothesis Wen et al. set out to dismantle.
What Wen et al. actually claim
The paper’s central move is to argue the metric was wrong. Pass@K asks whether any of K independent samples from the model gets the final answer right. If the model arrives at the correct answer through faulty reasoning, say guesswork that lands by accident or a wrong derivation that produces a right number, Pass@K still credits it. At large K, base models get more chances to luck into the right number, and the gap to the RLVR-tuned model closes.
CoT-Pass@K, the paper’s proposed replacement, asks whether at least one of K samples gets both the chain of thought and the final answer correct. The verifier (DeepSeek-R1-0528-Qwen3-8B, a public 8B model 7 ) is called three times per sample, and three voting strategies (any-correct, majority-correct, all-correct) are reported to balance false positives against false negatives.
Under CoT-Pass@K the picture inverts. The paper documents a “persistent and significant performance gap between the models across all values of K (up to 1024)” on AIME 2024 and AIME 2025 8 , meaning the base Qwen2.5-32B never catches up to the post-RLVR DAPO-Qwen-32B once the metric requires reasoning correctness rather than answer correctness alone. The paper’s own framing, verbatim: “Using CoT-Pass@K, we observe that RLVR can incentivize the generalization of correct reasoning for all values of K” 9 .
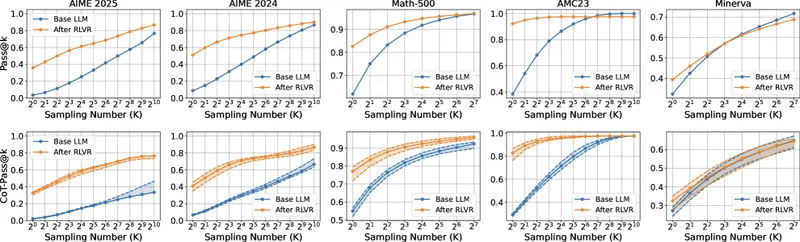
Figure 2 of Wen et al. (arXiv:2506.14245), reproduced for editorial coverage. Top row: Pass@K. Bottom row: CoT-Pass@K. Five math benchmarks across columns.
The paper’s three contributions, in their own framing 10 : a new metric and perspective for RLVR (CoT-Pass@K is “a reliable measure”), a theoretical foundation that distinguishes RLVR for LLMs from traditional RL (“emphasizing CoT correctness”), and empirical training-dynamics analysis showing that “RLVR consistently promotes correct reasoning from early training stages and that this ability generalizes.”
[Analysis] A scope note for builders working on code RLVR: Wen et al.’s abstract claims the result extends to coding tasks (“RLVR can extend the reasoning boundary for both mathematical and coding tasks” 9 ), but the empirical evaluation in Section 4 tests only on five math benchmarks. The coding-domain extension is asserted at the abstract level but not directly evaluated in the paper’s experimental section.
How the method works
The training procedure is the DAPO recipe, a group-relative policy-optimisation variant running on the VERL framework 11 . Wen et al. reproduce DAPO from the Qwen2.5-32B base on the DAPO-Math-17k training set 12 , then evaluate both the base and the post-RLVR model under both Pass@K and CoT-Pass@K.
DAPO itself layers four refinements over the GRPO objective: decoupled clipping (separate upper and lower clip ratios in the importance-sampling term, to allow positive advantages to push harder than negative ones), dynamic sampling (resampling groups when too many rollouts share the same reward, to preserve gradient signal), token-level policy loss (weighting per-token rather than per-sequence), and overlong-reward shaping (penalising responses that exceed a length budget). [External comparison] These are the four contributions named in the DAPO paper at NeurIPS 2025 24 ; Wen et al. inherit all four unchanged.
MATH ENTRY 1: GRPO group-normalised advantage
- Source: From the paper: GRPO formulation reproduced from DeepSeek-R1 (Section on training methodology 13 ); Wen et al. inherit this through the DAPO recipe they reproduce.
- What it is: A way to score each candidate output in a group of samples by how much better or worse it did than the group average, scaled by how much variation the group showed. The result, called the advantage, is what the optimiser uses to push the policy.
- Formal definition:
- Term-by-term explanation with types:
- : integer, the group size. A typical DAPO run uses or higher; the worked example below uses for clarity.
- : scalar in for math RLVR. if the -th rollout’s boxed answer matches the answer key AND the output is well-formatted (wrapped in
<think>tags); otherwise. - : a list of scalar rewards, one per rollout in the group.
- : arithmetic mean over the rewards; output is a scalar in .
- : standard deviation over the rewards; output is a non-negative scalar. In practice a small is added to the denominator to avoid division by zero when all rewards are equal.
- : scalar, the advantage of the -th rollout. Positive when the rollout outscored the group; negative when it underperformed.
- Worked numerical example. Suppose the group size is and the four rollouts for a single math question receive rewards (three correct, one incorrect). Step through:
- .
- Squared deviations from the mean: for each of the three correct rollouts, and for the incorrect one. Sum .
- (population standard deviation).
- Advantages:
- For each correct rollout (): .
- For the incorrect rollout (): .
- Result: . The single bad rollout gets pushed three times as hard (in absolute magnitude) as each good rollout, exactly the asymmetry GRPO is designed to produce when the group is mostly successful.
- Role: The advantages feed into a clipped-importance-sampling policy gradient (DAPO uses the decoupled-clip variant). Tokens in the high-advantage rollouts get up-weighted; tokens in low-advantage rollouts get down-weighted.
- Edge cases:
- All-equal rewards: and is undefined without the safeguard. DAPO’s dynamic-sampling refinement explicitly resamples groups when this happens, because the gradient signal vanishes.
- One-correct-in-many: if , the single correct rollout gets a large positive advantage and the incorrect ones each get a small negative advantage. The asymmetry flips compared to the worked example above.
- Novelty: [Adopted] from DeepSeek-R1’s GRPO formulation. Wen et al. do not modify the advantage formula; they reproduce DAPO’s variant of it.
- Transferability: [Analysis] The advantage formula is domain-agnostic; what makes it work for math RLVR is the reward signal , which depends on cheap unambiguous verification. Reusing this on subjective domains requires a different reward source, not a different advantage formula.
- Why it matters: The group-normalised advantage is what lets RLVR train without a learned reward model. The mean-and-std normalisation absorbs question-difficulty differences: an easy question where all four rollouts succeed produces zero gradient, and a hard question where one rollout succeeds produces a strong learning signal. This is the structural reason RLVR can learn from a verifier-only reward.
The policy is then optimised against this advantage 13 . For math, the reward comes from an exact-match check on the final boxed answer plus a format-check that the model wrapped its reasoning in <think>...</think> tags. There is no human preference label and no learned reward model in the loop.
What is new in the Wen paper is not the training pipeline. It is the evaluation. CoT-Pass@K introduces a learned verifier (itself an LLM) into the reading of results, plus a multi-call voting scheme to reduce verifier noise. The theoretical foundation argues that this matters specifically for RLVR, as opposed to traditional RL, because LLMs have “uniquely structured” optimisation dynamics around chain-of-thought correctness 14 .
ALGORITHM ENTRY 1: CoT-Pass@K evaluation procedure
- Source: From the paper: Section 4 of Wen et al. describes the verifier-based evaluation procedure; the three voting strategies (any-correct, majority-correct, all-correct) are named in the methodology table and illustrated in Figure 5.
- Purpose: Compute a more reasoning-aware version of Pass@K that credits a sample only when both the chain of thought and the final answer are judged correct.
- Inputs:
- : a benchmark question (e.g., one AIME 2024 problem).
- : the model under evaluation (base or post-RLVR).
- : the verifier model (DeepSeek-R1-0528-Qwen3-8B).
- : the sample budget (integer, e.g., ).
- : voting strategy, one of .
- Outputs: A binary value indicating whether “passes” question at budget under the chosen voting strategy.
- Pseudocode:
function CoT_Pass_at_K(Q, M, V, K, vote_strategy):
samples ← []
for k = 1 to K:
cot_k, answer_k ← M.generate(Q) # one independent rollout
votes ← []
for j = 1 to 3: # n=3 verifier calls per sample
v_jk ← V.judge(Q, cot_k, answer_k) # returns "correct" or "incorrect"
votes.append(v_jk)
if vote_strategy == "any":
cot_correct_k ← (at least 1 vote in votes is "correct")
elif vote_strategy == "majority":
cot_correct_k ← (>= 2 of 3 votes are "correct")
elif vote_strategy == "all":
cot_correct_k ← (all 3 votes are "correct")
answer_correct_k ← exact_match(answer_k, answer_key(Q))
samples.append(cot_correct_k AND answer_correct_k)
return (any sample in samples is True)- Hand-traced example on minimal input. Set (two samples),
vote_strategy = "majority". The model produces two rollouts for a single question:- Sample 1. = “By Vieta’s, the sum of roots is 12, so the answer is 12.” . The answer key is also 12, so . The verifier is called three times. Verifier votes: [“correct”, “correct”, “incorrect”]. Two of three is majority-correct, so . Sample 1 contributes .
- Sample 2. = “By trial-and-error guessing, I’ll pick 12.” . Still matches the answer key, so . Verifier votes: [“incorrect”, “incorrect”, “correct”]. One of three is not majority-correct, so . Sample 2 contributes .
- Final. The sample list is . “Any sample is True” returns , so CoT-Pass@2 = pass on this question. Under plain Pass@2 the result would have been the same; what differs is that on a question where both rollouts had correct answers but only one had a correct CoT, Pass@2 still passes whereas CoT-Pass@2 depends on the voting strategy: “any” would credit Sample 2’s verifier-disagreement votes and pass, while “all” would require unanimous verifier agreement and fail.
- Complexity:
- Time per question: rollouts from plus verifier calls from . At this is roughly 3072 verifier inferences per question per evaluated model.
- Bottleneck step: verifier inference dominates at large , because the verifier is itself a multi-billion-parameter LLM.
- Hyperparameters:
- : sample budget. Wen et al. test up to 8 .
- : verifier calls per sample. Set to 3 by Wen et al.; higher reduces verifier noise at linear cost.
- Voting strategy: three reported (any / majority / all) to bracket false-positive vs false-negative trade-offs.
- Failure modes:
- Verifier-correlated bias: if the verifier and the post-RLVR model share training data, both may agree on superficially-patterned reasoning that doesn’t generalise. The paper’s Appendix A.5 case studies are the mitigation; [Reviewer Perspective] the concern is not eliminated.
- Verifier compute cost: verifier calls per question scales poorly. A team applying CoT-Pass@K to its own model would need to budget accordingly.
- Format mismatch: a model that doesn’t wrap its CoT in the expected delimiters may be marked incorrect by the verifier even when the underlying reasoning is sound.
- Novelty: [New] for the metric framing; [Adopted] for the underlying components (LLM-as-judge is well-established; the contribution is the metric definition plus the n=3 voting scheme tuned for RLVR evaluation).
- Transferability: [Analysis] The procedure transfers cleanly to any RLVR-trained model on a domain with a reliable verifier. The verifier-quality question is load-bearing: applying CoT-Pass@K outside math requires a verifier of comparable capability on the new domain, which is precisely the precondition Mitra’s blog post flags as missing for most product surfaces 26 .
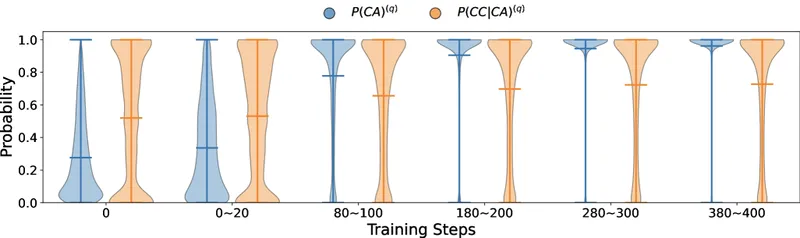
Figure 3 of Wen et al. (arXiv:2506.14245), reproduced for editorial coverage. Tracks training-dynamics evidence for the early-emergence claim.
The headline result, reproduced
The paper presents its empirical evidence as figures rather than a single result table. The qualitative pattern, summarised across the five benchmarks the paper evaluates, is below.
| Benchmark | Pass@K behaviour at large K | CoT-Pass@K behaviour at large K |
|---|---|---|
| AIME 2024 | Base model closes the gap or surpasses RLVR-tuned model 15 | RLVR-tuned model maintains a “persistent and significant” lead across all K values up to 1024 8 |
| AIME 2025 | Same closing-gap pattern as AIME 2024 | Same persistent-lead pattern as AIME 2024 |
| MATH-500 | Closing-gap pattern | Persistent-lead pattern |
| AMC23 | Closing-gap pattern | Persistent-lead pattern |
| Minerva | Closing-gap pattern | Persistent-lead pattern |
Pattern summary based on Figure 2 of Wen et al. (arXiv:2506.14245), reproduced for editorial coverage. Per-benchmark numerical values are reported in the figure subpanels of the paper rather than in a result table; readers wanting exact figures should consult the camera-ready PDF.
The key qualitative claim, that the metric switch flips the conclusion, survives across all five benchmarks the paper tests. The paper additionally documents that this CoT-correctness gain emerges “early in the training process and smoothly generalizes” 1 , supported by Figure 3’s training-dynamics analysis.
Methodology disclosure
| Input | What the paper states |
|---|---|
| Training data | DAPO-Math-17k: a public HuggingFace dataset of curated math questions with verifiable answers. The original DAPO paper introduced the dataset name as a 17,000-question subset; the live HuggingFace listing reports approximately 1.79M rows as of 2026-05-08 — a roughly 100× expansion since the dataset name was set. Builders reproducing the work should plan against the live row count, not the 17K name 12 |
| Base model | Qwen2.5-32B |
| Post-RLVR model | DAPO-Qwen-32B 16 |
| Verifier model | DeepSeek-R1-0528-Qwen3-8B (3 calls per CoT, 3 voting strategies) 7 |
| Evaluation set | Five math benchmarks: AIME 2024, AIME 2025, MATH-500, AMC23, Minerva. Per-benchmark example counts are not surfaced in the publicly-accessible abstract render and would require the camera-ready PDF for confirmation. |
| Hardware / compute | ”Our reproduction was conducted on 32 AMD MI300X GPUs using the VERL framework, and ran for over two weeks” 17 |
| Sample budget for K | Up to K = 1024 |
[External comparison] The compute-budget disclosure is unusually transparent for an RLVR paper, and it is also the signal that this work is academic-lab scale: 32 frontier GPUs for two weeks is approachable for a well-funded university group or a mid-sized AI startup, and out of reach for a solo builder. By contrast, the original DeepSeek-R1 paper does not disclose its training-compute budget at all 4 .
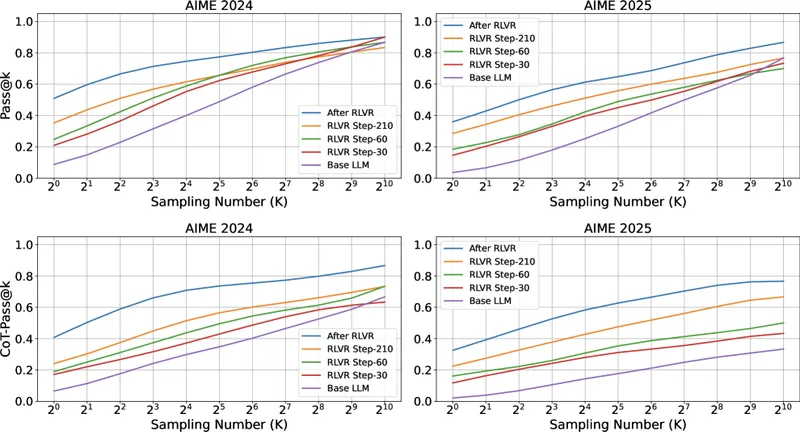
Figure 4 of Wen et al. (arXiv:2506.14245), reproduced for editorial coverage. Demonstrates that the Pass@K-vs-CoT-Pass@K inversion holds at early and mid-stage training checkpoints, not only at convergence.
Limitations: the paper’s own, and what others have flagged
The paper acknowledges three limitations directly 18 : the reliance on an LLM as the CoT verifier (“the prohibitive cost of manually checking a large volume of generated reasoning paths” forces the choice), the focus on math reasoning as the only domain, and the small number of post-RLVR models tested (DAPO-Qwen-32B is the headline subject). Appendix A.5 case studies and the multi-call voting scheme are the paper’s mitigations for the verifier-dependency concern.
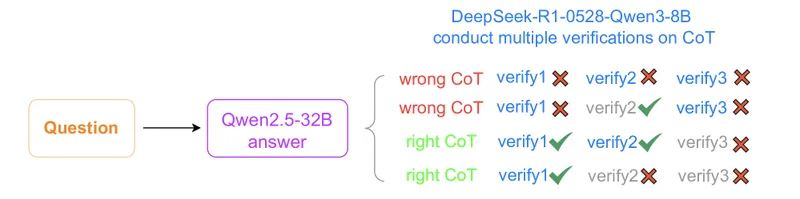
Figure 5 of Wen et al. (arXiv:2506.14245), reproduced for editorial coverage. The multi-verification system: any-correct, all-correct, and majority-correct voting strategies across three verifier calls, designed to mitigate false positives the verifier-dependency concern would otherwise produce.
Three further limitations come from independent commentary the paper does not address.
[Reviewer Perspective] The first is the broader Yue et al. finding 5 . Even if CoT-Pass@K is the right metric for math, Yue et al. tested across “various model families, RL algorithms, and math, coding, and visual reasoning benchmarks” and found that base models still upper-bound the reasoning capacity of their RLVR-trained variants. Wen et al. tested one base model (Qwen2.5-32B), one RLVR algorithm (DAPO), and one domain (math). The CoT-Pass@K finding could be a real reasoning-improvement story on math with this specific base model, while the broader Yue et al. ceiling holds elsewhere.
[Reviewer Perspective] The second is Alam & Rastogi’s “Limits of Generalization in RLVR” preprint 19 . The authors test RLVR on two combinatorial problems with verifiable solutions, Activity Scheduling and Longest Increasing Subsequence, and find a different failure mode. RLVR with sequence-level rewards on Activity Scheduling produces models that “emit a superficial ‘sorted’ preface that neither matches the canonical order nor drives the final schedule.” On the Longest Increasing Subsequence task, training with an answer-only reward “rapidly collapses intermediate reasoning: after just a few PPO updates, the policy drops its chain of thought and outputs terse final answers.” Their headline finding 20 : “RLVR improves evaluation metrics but often by reinforcing superficial heuristics rather than acquiring new reasoning strategies.” If a CoT can be superficially patterned to satisfy a verifier without doing the underlying work, CoT-Pass@K could itself be gamed.
[Reviewer Perspective] The third is the verifier-circularity question that the paper’s positioning suggests reviewers also raised. The CoT verifier is an LLM trained on reasoning data; the post-RLVR model being evaluated was trained on similar reasoning data; a generous reading is that CoT-Pass@K measures whether two related models agree on what counts as correct reasoning. The paper defends the choice with case studies in Appendix A.5, but it does not eliminate the concern. Independent reviewer perspectives on this paper are not directly captured in the standard HTML render of the OpenReview record; readers who want the full reviewer thread can visit the OpenReview forum jGbRWwIidy and expand the reviews pane.
A separate critique paper, Yang Yu’s “Pass@k Metric for RLVR: A Diagnostic Tool of Exploration, But Not an Objective” 21 , argues that Pass@k provides “a vanishing learning signal in regimes where exploration is most critical” and “while pass@k is a useful diagnostic tool, it may be an unsuitable direct objective for optimization.” Yu’s paper does not directly cite Wen et al. but is in dialogue with the same metric debate, and its position complicates a clean reading of either the Yue or the Wen result.
Reproducibility check
| Artefact | Released? | Where |
|---|---|---|
| RLVR training pipeline (paper-specific code release) | Not surfaced as a dedicated wenetal-iclr2026-rlvr repository in writer-time fetch | Paper builds on VERL + DAPO open-source infrastructure; a paper-specific code release URL was not surfaced in writer-time fetch |
| VERL training framework | Yes | github.com/verl-project/verl 22 |
| DAPO recipe + run scripts | Yes | github.com/BytedTsinghua-SIA/DAPO 23 |
| DAPO-Qwen-32B model weights | Yes (HuggingFace, Apache-2.0 licence) | BytedTsinghua-SIA/DAPO-Qwen-32B 16 |
| DAPO-Math-17k training data | Yes (HuggingFace) | BytedTsinghua-SIA/DAPO-Math-17k 12 |
| Verifier model | Yes (HuggingFace) | deepseek-ai/DeepSeek-R1-0528-Qwen3-8B 7 |
| CoT-Pass@K evaluation harness | Not flagged as a standalone release in writer-time fetch | Verifier-prompt templates, the n=3 voting logic, and the per-strategy scoring would need to be re-implemented from the paper’s Section 4 description |
| Trained-checkpoint releases | Not flagged in writer-time fetch | DAPO-Qwen-32B is the canonical post-RLVR model; intermediate training checkpoints used in Figure 3 are not surfaced as a release |
The reproducibility picture is honest: the upstream infrastructure is fully open-source, the model weights and training data are public, and the verifier is a public DeepSeek release. The gap is the CoT-Pass@K evaluation harness itself, which a builder wanting to validate the headline finding on a different post-RLVR model would need to reconstruct from the paper’s prose. Independent reproducibility, meaning a third-party lab running the same n=3-verifier-call CoT-Pass@K evaluation on a different RLVR-trained model, has not been published as of May 2026.
A note on Papers With Code: the AIME 2024 leaderboard link redirected to the HuggingFace papers index in writer-time fetch and was not surfaceable for cross-reference. The SOTA claim in the Wen paper is therefore the authors’ framing on their chosen benchmark suite; independent reproducibility has not yet been published as of 2026-05-08.
Related work
The paper’s contemporaneous neighbourhood is dense.
Yue et al. (NeurIPS 2025 Oral; Best Paper at ICML 2025 AI4MATH workshop) 5 is the canonical counter-paper. Wen et al.’s abstract names the “popular hypothesis” they challenge as “RLVR merely re-weights existing reasoning paths at the cost of reasoning diversity,” and that hypothesis is Yue et al.’s headline finding. The two papers disagree on whether the metric (Pass@K vs CoT-Pass@K) or the underlying training (RLVR is or isn’t a reasoning improvement) is the load-bearing variable. Yue et al. also flag that distillation, not RLVR, is the path to genuinely new reasoning patterns: “distillation can introduce new reasoning patterns from the teacher and genuinely expand the model’s reasoning capabilities.” That contrast is a useful frame for builders deciding where to spend post-training effort.
Alam & Rastogi (preprint, October 2025) 19 sits between the two camps. The paper cites Wen et al. and finds that RLVR’s reasoning-incentivisation claim wobbles outside narrow combinatorial domains. The Activity Scheduling and Longest Increasing Subsequence results are not a direct counter to Wen, since the Alam-Rastogi tasks sit off the AIME / MATH benchmark suite, but they are evidence that RLVR’s “incentivise correct reasoning” framing has domain-dependent limits.
DeepSeek-R1 (arXiv:2501.12948, January 2025) 2 is the industry implementation that triggered the entire RLVR research wave. R1 establishes the GRPO-with-rule-based-rewards recipe; Wen et al. study a refinement (DAPO) on a smaller base (Qwen2.5-32B vs R1’s 671B-total / 37B-active mixture-of-experts). The reproducibility contrast is sharp: R1 released model weights and a paper but not a trainable RLVR codebase or a compute-budget disclosure; Wen et al. publish on a fully open-source training stack and a transparent compute budget.
DAPO at NeurIPS 2025 24 is the training recipe Wen et al. reproduce. DAPO’s own headline result was 50 points on AIME 2024 from a Qwen2.5-32B base, with framing that this matched DeepSeek-R1-Zero performance at half the training steps. That is the engineering claim from the DAPO paper, distinct from the Wen reasoning-quality claim 25 .
Yang Yu (arXiv:2511.16231, November 2025) 21 is the metric-level theoretical paper alongside this debate. Yu argues Pass@k itself is “an unsuitable direct objective for optimization.” The paper does not cite Wen et al. directly but is in dialogue with the same evaluation question CoT-Pass@K addresses.
Subhadip Mitra’s blog post on RLVR beyond math and code 26 frames the practitioner-side question. Mitra identifies three preconditions for RLVR to work: ground truth must exist (a definitive correct answer), verification must be cheap (a program can check correctness automatically), and rewards must be dense enough that the model finds correct answers frequently during training. Together those constraints explain why RLVR works on math, a domain with cheap unambiguous verification, and why extending it to subjective domains is harder than extending the model.
What this means for builders
[Analysis] Three takeaways, ordered by how directly they affect engineering decisions today.
For builders working on math reasoning models, the Wen paper is directional evidence to lean on. The CoT-Pass@K finding does not rewrite the playbook (DeepSeek-R1 and DAPO already proved that RLVR produces capable math models), but it does undercut the strongest negative result (Yue et al.) on the math domain specifically. If a team is choosing between “post-train via RLVR” and “skip RLVR because Yue et al. say it doesn’t help at large k,” the Wen paper says the choice was between two metrics, and CoT-Pass@K is the one that cares about reasoning quality. Take the win, and use the public DAPO-Qwen-32B 16 or DeepSeek-R1-Distill-Qwen-32B as starting points rather than running RLVR from scratch. The reproduction in this paper used 32 AMD MI300X GPUs for over two weeks; that compute budget rules out most teams.
For builders working outside math, treat the result as a hypothesis, not a recipe. Mitra’s three preconditions apply: code can pass programmatic verification (RLVR has worked there), but most product surfaces (open-ended writing, design, customer-facing dialogue, sentiment-aware responses) do not have unambiguous verifiers. Alam & Rastogi’s case studies show that even with a verifiable answer, RLVR can produce models that pattern-match on superficial features rather than reason. The CoT-Pass@K mitigation, running a verifier LLM to check the chain, is a partial answer at best when the chain itself can be gamed. The honest read: if your product domain has cheap, unambiguous verification, RLVR is worth a serious look. If it does not, distillation from an already-RLVR-tuned teacher is a more cost-effective bet.
For everyone, the reproducibility gap is real and worth pricing in. The paper publishes on a fully open training stack (VERL + DAPO + Qwen2.5-32B), but the CoT-Pass@K evaluation harness, including the verifier-prompt templates, the three-call voting logic, and the per-strategy scoring, is not surfaced as a standalone release. A team wanting to apply CoT-Pass@K to its own model will need to re-implement from the paper’s Section 4 description, and an independent group has not yet published the metric on a different RLVR-trained model. The headline claim is well-supported by the paper’s internal evidence; the field is still waiting for external validation. Plan for both possibilities: CoT-Pass@K becomes a standard evaluation across the next round of RLVR papers, or follow-up work surfaces a verifier-circularity issue that softens the result.
[Analysis] The publishability decision at ICLR matches this read. The paper was accepted as a Poster, not a Spotlight or Oral 27 , which is the venue’s signal that the contribution is publishable but not the top-tier framing-shift the abstract claims. That register is appropriate. CoT-Pass@K is a useful tool, the empirical evidence on math is convincing, and the broader thesis still needs a year of follow-up work to settle. Build accordingly.
How this article reads at three depths
For the curious high-school reader. A language model is trained on math problems by rewarding it whenever it produces the right final number. The question this paper asks is: does the model actually learn to reason better, or is it just getting more chances to luck into the right answer? The paper’s answer is “actually learning to reason”, but only when you measure reasoning instead of just the final answer — and only for math, with one specific model.
For the working developer or ML engineer. The paper defends RLVR on the math domain against the strongest negative result (Yue et al.) by introducing CoT-Pass@K, a metric that uses an LLM verifier to check whether the chain of thought is correct, not just the final answer. Under the new metric, the post-RLVR model (DAPO-Qwen-32B) maintains a lead over its base (Qwen2.5-32B) across all sample budgets up to K = 1024. The training stack is fully open-source (VERL + DAPO + Qwen2.5-32B + DeepSeek-R1-0528-Qwen3-8B verifier), so a team can reproduce the pipeline; the CoT-Pass@K evaluation harness itself is not surfaced as a release and would need re-implementation from Section 4. Use the public DAPO-Qwen-32B weights for math reasoning; outside math, treat the result as hypothesis until a verifier of comparable capability exists in the target domain.
For the ML researcher. The contribution is a metric-definition + theoretical-framing paper plus an empirical reproduction. Novelty is concentrated in CoT-Pass@K (the n=3 verifier-call voting scheme over an LLM-as-judge backbone) and the training-dynamics analysis in Figure 3. The GRPO advantage formula, DAPO training recipe, and base model are all adopted unchanged. Load-bearing assumptions: (1) the verifier is well-calibrated for the math domain and not correlated with the post-RLVR model’s failure modes; the paper’s Appendix A.5 case studies are the defence, but the verifier-circularity concern is not eliminated; (2) one base model and one RLVR algorithm are representative, where Yue et al.’s broader sweep suggests the ceiling may be domain-specific or base-specific. The strongest objection is Alam & Rastogi’s superficial-heuristic finding on Activity Scheduling / LIS, which suggests CoT-Pass@K could itself be gamed by patterned reasoning. A follow-up paper would need to apply CoT-Pass@K to a second RLVR algorithm on a second base model, ideally outside math, to convert the result from suggestive to settled.
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. Wen et al., abstract — "Using CoT-Pass@K, we observe that RLVR can incentivize the generalization of correct reasoning for all values of K" (accessed ) ↩
- 2. DeepSeek-AI, "DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning" (arXiv:2501.12948) (accessed ) ↩
- 3. DeepSeek-R1 paper, Section on reward modelling — "We do not apply the outcome or process neural reward model in developing DeepSeek-R1-Zero, because… neural reward model may suffer from reward hacking" (accessed ) ↩
- 4. DeepSeek-R1 paper, Section 4 benchmark results — R1-Zero 71.0% AIME 2024 Pass@1; R1 79.8% AIME 2024 / 97.3% MATH-500 (accessed ) ↩
- 5. Yue et al., "Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?" (arXiv:2504.13837, NeurIPS 2025 Oral) (accessed ) ↩
- 6. Yue et al. project page — "RL fine-tuning enhances sampling efficiency without expanding the reasoning capacity already present in base models" (accessed ) ↩
- 7. DeepSeek-R1-0528-Qwen3-8B — public 8B verifier model used by Wen et al. for CoT correctness checking (accessed ) ↩
- 8. Wen et al., empirical results section — "persistent and significant performance gap between the models across all values of K (up to 1024)" (accessed ) ↩
- 9. Wen et al., abstract — headline empirical claim verbatim (accessed ) ↩
- 10. Wen et al., contribution-list bullets verbatim from ar5iv HTML render (accessed ) ↩
- 11. VERL training framework — open-source infrastructure underpinning DAPO and the Wen reproduction (accessed ) ↩
- 12. DAPO-Math-17k — public training dataset on HuggingFace; original DAPO paper introduced the "17K" name as a 17,000-question subset; live HuggingFace listing reports approximately 1.79M rows as of 2026-05-08 (≈100× expansion since the name was set) (accessed ) ↩
- 13. DeepSeek-R1 paper, GRPO formulation — group-relative advantage calculation verbatim (accessed ) ↩
- 14. Wen et al., theoretical foundation section — "uniquely structured to incentivize logical integrity" framing (accessed ) ↩
- 15. Yue et al., abstract — "While RLVR-trained models outperform their base models at small k (e.g., k = 1), the base models achieve a higher pass@k score when k is large" (accessed ) ↩
- 16. DAPO-Qwen-32B — public post-RLVR model weights on HuggingFace (accessed ) ↩
- 17. Wen et al., Section 4 — "Our reproduction was conducted on 32 AMD MI300X GPUs using the VERL framework, and ran for over two weeks" (accessed ) ↩
- 18. Wen et al., limitations section verbatim — verifier dependency, math-only domain, limited number of post-RLVR models (accessed ) ↩
- 19. Alam & Rastogi, "Limits of Generalization in RLVR: Two Case Studies in Mathematical Reasoning" (arXiv:2510.27044) (accessed ) ↩
- 20. Alam & Rastogi, abstract — "RLVR improves evaluation metrics but often by reinforcing superficial heuristics rather than acquiring new reasoning strategies" (accessed ) ↩
- 21. Yang Yu, "Pass@k Metric for RLVR: A Diagnostic Tool of Exploration, But Not an Objective" (arXiv:2511.16231) (accessed ) ↩
- 22. VERL training framework GitHub repo (accessed ) ↩
- 23. DAPO recipe and run scripts on GitHub (accessed ) ↩
- 24. DAPO paper at NeurIPS 2025 OpenReview record (accessed ) ↩
- 25. llm-stats.com summary — "DAPO trained Qwen2.5-32B to 50 points on AIME 2024, outperforming DeepSeek-R1-Zero with 50% fewer training steps" (accessed ) ↩
- 26. Subhadip Mitra, "RLVR Beyond Math and Code: The Verifier Problem Nobody Has Solved" (18 January 2026) (accessed ) ↩
- 27. Wen et al. ICLR 2026 OpenReview record — Poster acceptance, decision posted 26 January 2026 (accessed ) ↩
Further Reading
- DeepSeek-R1 GitHub repo (accessed )
- opendilab awesome-RLVR community list (accessed )
Anonymous · no cookies set