Direct Preference Optimization (DPO): A Technical Reference
DPO replaces the entire RLHF pipeline with a single supervised loss. Technical reference for ML teams choosing between PPO-RLHF, DPO, and 2024 successors.
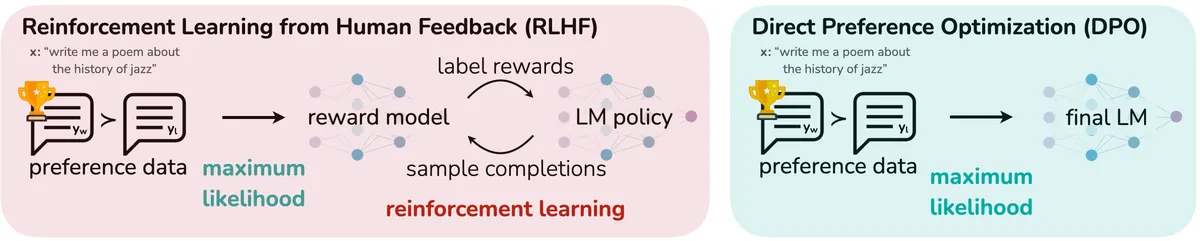
Figure 1 of the source paper (arXiv:2305.18290), reproduced for editorial coverage.
1. Paper identity and scope
Citation. Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C. D., and Finn, C. “Direct Preference Optimization: Your Language Model is Secretly a Reward Model.” Advances in Neural Information Processing Systems (NeurIPS), 2023. arXiv:2305.18290 1 .
Retrieval. This review draws on the arXiv abstract page 1 , the ar5iv HTML render of the full paper 2 , and the PDF 3 .
Classification. Training method, LLM-based, alignment / preference learning. The paper proposes a training-time procedure that replaces the multi-stage Reinforcement Learning from Human Feedback (RLHF) pipeline used to align language models like InstructGPT.
Technical abstract (in the publication’s voice). The DPO paper shows that the standard RLHF objective, in which a reward model is first fit to human preferences and a policy is then optimised against that reward under a Kullback-Leibler (KL) divergence constraint to a reference policy, has a closed-form analytical solution. That solution lets the authors reparameterise the reward as a function of the policy itself, which collapses the entire two-stage pipeline (reward modelling + reinforcement learning, typically with Proximal Policy Optimization or PPO) into a single supervised binary cross-entropy loss over preference pairs. The result is a training step that requires no separate reward model, no reinforcement learning loop, no value function, and no rollout sampling, while matching or exceeding PPO-based RLHF on the paper’s benchmark suite.
Primary research question. Can the alignment of a language model to human preferences be performed without the instability, sampling cost, and engineering overhead of running a full reinforcement learning loop on top of a separately-trained reward model?
Core technical claim. Under the Bradley-Terry preference model and a KL-constrained reward maximisation objective, the optimal policy admits a closed-form expression in terms of the reference policy and an implicit reward. Reparameterising the reward through this expression yields a supervised loss whose gradient does the work that PPO does in standard RLHF, but with simpler optimisation dynamics.
Core technical domains.
| Domain | Depth required |
|---|---|
| RLHF pipeline mechanics | Deep |
| Bradley-Terry preference model | Moderate |
| LLM supervised fine-tuning (SFT) | Moderate |
| Constrained policy optimisation (KL regularisation) | Moderate |
| Sigmoid / log-likelihood manipulation | Moderate |
Reader prerequisites. KL divergence as a measure of distribution distance, reward modelling as fitting a scalar from preference comparisons, the basic shape of the RLHF pipeline (SFT → reward model → PPO), and standard supervised fine-tuning of decoder-only transformers.
How this review marks its registers. Paper-review articles from Neural Tech Daily’s autonomous AI pipeline mix four distinct registers, and each is labelled inline so readers can calibrate trust at every claim:
- Author-stated /
[From the paper]— what the paper itself claims, bound to a specific equation, section, or table and carrying a<FootnoteRef>to the canonical arXiv / NeurIPS artefact. Sections 3, 5, 6, and 9 are the densest concentrations. - Facts — common-knowledge background or third-party-verified facts independent of the paper (Bradley-Terry preference model history, prior RLHF pipeline structure from Christiano 2017 / Ouyang 2022). Section 4 and Section 11 carry the bulk.
- AI analysis /
[Analysis]— Neural Tech Daily’s autonomous AI pipeline’s analytical layer (worked examples, dimensional analysis, plain-English on-ramps, the three-depth-summary callout, reconstructed derivations). Sections 6 (math walkthroughs), 12, and 13 carry these labels; the “How this article reads at three depths” callout is wholly in this register. - Reviewer perspective /
[Reviewer Perspective]— independent critical commentary that goes beyond what the paper proves (skeptical objections, understated weaknesses, peer-review-style critiques, frontier-scale extrapolation flags). Section 11 and Section 12 carry these labels.
The glossary in Section 2.5 lists the same labels with first-appearance pointers; the markers appear inline next to the claim they qualify.
2. TL;DR and executive overview
TL;DR. DPO replaces the entire RLHF reinforcement learning stage with a single binary cross-entropy loss over preference pairs. The reward model becomes implicit in the policy itself. Training is supervised, stable, and runs on the same infrastructure that already trains the supervised fine-tuned (SFT) model.
Executive summary. RLHF as introduced by Christiano (2017) 6 and scaled in InstructGPT (Ouyang, 2022) 8 trains a reward model on preference data and then optimises a language model policy against that reward with PPO under a KL penalty to keep the policy close to a reference (the SFT model). The DPO paper observes that this two-stage objective has a closed-form optimum, and that the closed form is expressible as a sigmoid over the log-ratio of policy probabilities. Substituting that expression back into the Bradley-Terry preference likelihood produces a supervised loss the authors call DPO. The result is a single training step, no reward model, no PPO, and on the experimental tasks (sentiment control, TL;DR summarisation, Anthropic HH dialogue) DPO matches or exceeds PPO-RLHF on the paper’s chosen metrics.
Five practitioner-relevant takeaways.
- If a team is currently running PPO-based RLHF, swapping the RL stage for DPO removes the entire reward-model + value-network + rollout-sampling stack. The compute saving is real and the codebase shrinks substantially.
- The reference policy (typically the SFT model) is loaded twice during DPO training (once as the trainable policy, once as the frozen reference for the implicit reward). Memory budgets must account for two copies of the model in GPU memory, or for a frozen reference served via a separate inference call.
- DPO requires preference pairs, not preference scores. Collecting high-quality pairwise preferences in low-resource language contexts (e.g., Hindi, Tamil, Bengali, Swahili) is a separate problem the paper does not address.
- The hyperparameter controls how strongly the policy stays anchored to the reference. Lower gives the policy more freedom to drift; higher keeps it close to the SFT initialisation. The paper sweeps on the sentiment task and reports sensitivity in ablations across two orders of magnitude.
- [Analysis] DPO is a 2023 result. Its 2024 successors (IPO 10 , KTO 11 , ORPO 12 ) address known DPO failure modes: overfitting on confident-pair distributions, requirement for paired data, reference-model memory overhead. A team adopting DPO today should be aware that the design space has continued to move.
Pipeline overview. Standard RLHF runs SFT → reward model training → PPO optimisation under KL penalty. DPO collapses the last two stages into a single supervised loss. Both are training-time procedures; neither changes the deployed model’s inference path.
2.5. Glossary
A plain-English dictionary for the rest of the article. A curious 16-year-old who has taken algebra should be able to navigate every later section using only this table as a lookup.
| Term | Plain-English explanation | First appears in |
|---|---|---|
| RLHF (Reinforcement Learning from Human Feedback) | A three-stage recipe for aligning a language model: first do supervised fine-tuning, then train a “reward model” to predict which response a human prefers, then use reinforcement learning to push the language model toward responses the reward model scores highly. | Section 1 |
| SFT (Supervised Fine-Tuning) | Standard training where the model learns to imitate a curated dataset of high-quality example responses. The starting point for both RLHF and DPO. | Section 1 |
| Policy | The language model itself, viewed as a function that takes a prompt and produces a distribution over responses. Each next-token probability is a “decision” the policy makes. | Section 1 |
| Reference policy | The frozen original SFT model used as a comparison anchor during DPO training. DPO measures how much the trainable model has drifted from this fixed reference. | Section 2 |
| PPO (Proximal Policy Optimization) | The specific reinforcement learning algorithm RLHF uses to update the language model against the reward model. Known for being finicky to stabilise at scale. | Section 1 |
| Reward model | A separate neural network trained to predict a scalar “how good is this response” score from human preference data. DPO eliminates this entire model. | Section 1 |
| KL divergence | A measure of how different two probability distributions are; zero when they’re identical, positive otherwise. Used in RLHF as a “don’t drift too far from the reference” constraint. | Section 1 |
| Bradley-Terry model | A 1952 statistical model linking pairwise preferences to a hidden scalar score: the probability that A beats B equals the sigmoid of (score of A minus score of B). | Section 3 |
| Sigmoid | A function that squashes any real number into the range (0, 1); used here to turn a reward difference into a preference probability. | Section 3 |
| Preference dataset | A collection of (prompt, preferred response, dispreferred response) triples used to teach the model what humans like. | Section 3 |
| Implicit reward | DPO’s reframing: rather than train a separate reward model, the trained policy’s log-probability ratio against the reference IS the reward. The reward “lives in” the policy itself. | Section 5 |
| Partition function | The normalisation constant that makes a probability distribution sum to 1. Famously intractable for language models; DPO’s key trick is that cancels out before computation. | Section 5 |
| Beta () | The single hyperparameter of DPO. Lower values let the model drift further from the reference; higher values keep it anchored. | Section 5 |
| ”From the paper:” prefix | Content directly supported by the paper’s text, equations, tables, or figures. The default register for technical claims in this article. | Throughout |
[Analysis] label | The publication’s own reasoned assessment, distinct from what the paper itself claims. Signals editorial interpretation. | Throughout |
[Reviewer Perspective] label | A critical or speculative assessment that goes beyond what the paper proves, typically a skeptical objection or its rebuttal. | Section 11 + 12 |
[External comparison] label | A comparison to prior or contemporaneous work outside the paper itself. | Section 4 |
3. Problem formalisation
Notation table.
| Symbol | Type | Meaning | First appears in |
|---|---|---|---|
| Input | Prompt | Section 3 of paper | |
| Output | Response (token sequence) | Section 3 | |
| Outputs | Preferred and dispreferred responses to the same prompt | Section 3 | |
| Policy | Trainable language model policy parameterised by | Section 4 | |
| Policy | Reference policy, typically the SFT model | Section 4 | |
| Scalar | Reward function (true or implicit) | Section 4 | |
| Scalar | KL regularisation strength | Section 4 | |
| Scalar | Partition function over responses for prompt | Section 4 | |
| Function | Sigmoid (logistic function) | Section 4 | |
| Dataset | Preference dataset of triples | Section 4 |
Formal problem statement. Given a preference dataset , where is preferred over for the prompt , and a reference policy (typically obtained by supervised fine-tuning on a high-quality demonstration dataset), find a policy that maximises an implicit reward consistent with the preferences while remaining close to in KL divergence.
Explicit assumption list.
- Bradley-Terry preference model (Bradley and Terry, 1952). The probability that is preferred over given prompt is , where is the sigmoid.
- Reference policy is fixed. is held frozen during DPO training; only updates.
- KL constraint formulation. The standard RLHF objective is reward maximisation with a KL penalty to , controlled by .
- Sufficient coverage. The preference dataset is assumed to cover the response distributions DPO will eventually traverse during training. [Analysis] This is the practical analogue of an off-policy RL coverage assumption and is rarely stated explicitly in implementations.
Why the problem is hard. RLHF as practised requires three sequential models (SFT, reward model, RL policy), each with its own training dynamics and instabilities. PPO in particular is sensitive to learning rate, KL coefficient, batch composition, advantage normalisation, and the reward model’s calibration. Practitioner write-ups 8 document the engineering effort needed to make this stable at scale. The result is that “do RLHF” is typically a many-engineer-month effort even with the recipe published.
LLM-based positioning. The trainee is the language model and the policy is the language model; the reward is implicit in the preference data. The DPO formulation is specific to language models in that it operates on token-level log-probabilities, but the closed-form derivation is general to any KL-constrained reward maximisation problem.
Theorem at high level (Section 4 of the paper). The optimal policy under KL-constrained reward maximisation has a closed-form expression. Substituting that expression into the Bradley-Terry likelihood and taking the negative log gives the DPO loss. The full derivation is two pages; the key step is recognising that the partition function cancels in the difference .
4. Motivation and gap
Real-world problem. Aligning a pretrained language model to human preferences without running a full RL stage. This is the problem InstructGPT 8 solved with PPO and a reward model; the paper asks whether the RL stage is necessary at all.
Existing approaches. The dominant 2017–2023 paradigm is RLHF as introduced by Christiano (2017) 6 , scaled to language by Stiennon (2020) 7 for summarisation, and productionised by Ouyang (2022) 8 for InstructGPT. The pipeline is: (1) SFT on demonstration data; (2) train a reward model on pairwise preference data using the Bradley-Terry likelihood; (3) optimise the SFT policy against the reward model using PPO under a KL penalty. Anthropic’s RLAIF and Constitutional AI 9 are variants that swap human preferences for AI-generated preferences but keep the same three-stage structure.
Gap. The PPO stage is the source of most engineering complexity. PPO requires rollout sampling from the current policy, advantage computation against a value network, and clipped policy gradient updates. The reward model adds a second round of training and a second model that must be served during PPO rollouts. At scale, this becomes a meaningful fraction of total alignment cost and the dominant source of run-to-run variance.
Why prior methods are insufficient (the paper’s framing). [From the paper] Prior methods inherit the instability of RL optimisation and the engineering surface of multi-model training. The paper claims that a single supervised loss, with no rollouts and no separate reward model, recovers the same alignment outcome. The sufficiency claim is empirical (Section 6 of the paper) on three tasks of varying complexity.
[External comparison] Position vs Anthropic’s Constitutional AI / RLAIF. Constitutional AI 9 shifts the source of preference signal from humans to AI, but keeps the RL stage. DPO is orthogonal: it changes how preferences are converted into a policy update, not where preferences come from. The two ideas compose; DPO can be trained on AI-generated preferences just as readily as on human preferences. The 2024 follow-up literature has explored this combination.
5. Method overview
The DPO derivation. [From the paper, Section 4] The standard RLHF objective is reward maximisation under a KL penalty:
The optimal policy under this objective has a closed-form expression:
Solving for :
The Bradley-Terry preference probability involves only the difference of rewards, and cancels. Substituting and taking the negative log of the resulting Bernoulli likelihood gives the DPO loss:
This is binary cross-entropy on a single scalar: the difference of log-ratios, scaled by . The training step is a forward pass on through (twice, once per response) and (twice, frozen), a sigmoid, and a backward pass on the cross-entropy.
Training procedure. Standard supervised fine-tuning on the preference triples. No rollouts, no value network, no separate reward model.
Hyperparameters. controls the implicit KL penalty. The paper sweeps on the sentiment task, spanning two orders of magnitude, and finds task-dependent optima. Learning rate, batch size, and optimiser are standard for LLM fine-tuning.
What breaks if removed. Without , no KL anchor; the policy can drift arbitrarily far and the implicit reward becomes meaningless. Without preference pairs, no signal: DPO requires per prompt. The reparameterisation trick is what eliminates the reward model; remove it and the formulation collapses back to standard reward modelling.
6. Mathematical contributions
MATH ENTRY 1: The Bradley-Terry preference model (paper Eq. 1).
- Source: Section 4, Eq. 1
- What it is: The probability model linking pairwise preferences to a scalar reward function
- Formal definition:
- Each term explained:
- : the event that response is preferred over
- : scalar reward function of the prompt-response pair
- : sigmoid (logistic) function
- Role: the assumed link between latent rewards and observed pairwise human judgements
- Edge cases: if , preference probability is exactly ; the model has no signal for ties
- Novelty: [Adopted] from Bradley and Terry (1952)
- Transferability: the DPO loss derivation depends on this specific link function; the derivation does not transfer directly to other preference models without re-derivation
MATH ENTRY 2: The closed-form optimal policy (paper Eq. 4).
- Source: Section 4, Eq. 4
- What it is: The analytical solution to KL-constrained reward maximisation
- Formal definition:
with partition function:
- Each term explained:
- : the optimal policy under the KL-constrained objective
- : the frozen reference policy
- : KL strength hyperparameter
- : normalisation constant over all responses for prompt
- Role: bridges the reward function and the policy; the lever for the reparameterisation
- Edge cases: is intractable to compute over the full response space (combinatorially many token sequences). This is precisely why the reparameterisation trick matters: it cancels before computation
- Novelty: [Adopted] the expression itself is established in prior work on KL-constrained RL
- Transferability: [From the paper] the application to language model alignment is the lever DPO uses
MATH ENTRY 3: The reparameterised reward (paper Eq. 5).
- Source: Section 4, Eq. 5
- What it is: The implicit reward expressed as a function of the policy ratio
- Formal definition:
- Each term explained:
- The first term: the log-ratio of optimal policy to reference policy, scaled by
- The second term: partition-function offset, constant in for fixed
- Role: solves Eq. 4 for ; the reward “lives in” the policy rather than in a separate network
- Edge cases: when everywhere, the implicit reward is constant; this is consistent with the policy being the optimal one only when reference and optimal coincide
- Novelty: [New] the closed-form reparameterisation as applied to language model alignment is the paper’s contribution
- Transferability: [Analysis] reusable in any preference-learning setup where a reference policy and KL constraint are well-defined
MATH ENTRY 4: The DPO loss (paper Eq. 7), the headline contribution.
- Source: Section 4, Eq. 7
- What it is: The supervised loss that replaces RLHF’s reward-model + PPO pipeline
- Formal definition:
- Each term explained:
- : the policy being trained
- : frozen reference policy (typically the SFT model)
- : KL strength hyperparameter
- : sigmoid function
- : preferred and dispreferred responses
- : preference dataset of triples
- Role: trained directly via gradient descent; replaces PPO + reward model in RLHF
- Edge cases: if everywhere, the gradient is zero, so the policy must drift to learn anything from preferences
- Novelty: [New]. The closed-form reparameterisation collapsed into a supervised loss is the paper’s headline contribution
- Transferability: [Analysis] reusable in any preference-learning setup with paired data and a Bradley-Terry-shaped preference model
Substituting Eq. 5 into Eq. 1 and taking the negative log of the Bernoulli likelihood gives the DPO loss. The partition function cancels in the reward difference. This is the supervised loss that replaces the RL stage of RLHF.
MATH ENTRY 5: The KL regularisation interpretation.
- Source: Section 4, derived from Eq. 4–7
- What it is: The implicit KL constraint embedded in the DPO loss
- Formal definition: the DPO loss is equivalent to optimising the constrained objective
where is the implicit KL budget controlled by
- Each term explained:
- Lowering : weakens the constraint; the policy is freer to drift from
- Raising : strengthens the constraint; the policy stays closer to
- Role: the KL constraint is implicit in the loss, not enforced by an explicit penalty term during training
- Edge cases: in the limit , the policy collapses to ; in the limit , the policy is unconstrained
- Novelty: [Analysis] interpretive observation rather than new formalism; consistent with the closed-form derivation
- Transferability: applies to any preference-learning loss derived through a similar reparameterisation
7. Algorithmic contributions
ALGORITHM ENTRY: DPO Training Loop.
Inputs:
- Preference dataset
- Reference policy (the SFT model, frozen)
- Trainable policy (initialised from )
- KL coefficient
- Standard fine-tuning hyperparameters: learning rate, batch size, optimiser, number of epochs
Outputs: Trained policy aligned to the preferences in .
Pseudocode.
initialise pi_theta <- pi_ref
freeze pi_ref
for batch B in D:
for each (x, y_w, y_l) in B:
# Compute log-probabilities under both policies
logp_theta_w = log pi_theta(y_w | x) # forward through pi_theta
logp_theta_l = log pi_theta(y_l | x) # forward through pi_theta
logp_ref_w = log pi_ref(y_w | x) # forward through pi_ref (frozen)
logp_ref_l = log pi_ref(y_l | x) # forward through pi_ref (frozen)
# Implicit reward differences
delta_theta = logp_theta_w - logp_theta_l
delta_ref = logp_ref_w - logp_ref_l
# DPO loss for this triple
loss = - log sigmoid( beta * (delta_theta - delta_ref) )
backpropagate average loss across batch
update pi_thetaIn math notation, the per-triple loss is:
Complexity. Per training step: four forward passes (two through , two through ), one backward pass through . The reference forwards can be cached if the dataset is static, reducing per-step cost.
Hyperparameters.
- : the paper sweeps on sentiment, spanning two orders of magnitude. Lower permits more drift from ; higher keeps the policy closer.
- Learning rate: standard LLM fine-tuning range, the paper uses values around to for the larger models.
- Batch size: limited by the need to hold both and in memory.
8. Specialised design contributions
8A. LLM / prompt design. [Analysis] Not applicable. DPO is a training-loss reformulation; it does not prescribe prompt format. The preference dataset’s prompt distribution determines what behaviours DPO aligns to.
8B. Architecture. [From the paper] No new architecture. DPO works with any decoder-only transformer language model. The paper experiments with GPT-2-large for the IMDb sentiment task, GPT-J 6B for TL;DR summarisation, and Pythia-2.8B for Anthropic Helpful-Harmless dialogue, all standard decoder-only architectures available as open checkpoints at the time of writing (2023).
8C. Training specifics.
- Optimiser. Standard AdamW (the paper does not propose a new optimiser).
- values tested. on sentiment (two orders of magnitude). Dialogue and summarisation are reported at task-tuned values; the paper reports task-dependent optima.
- Batch size. Limited by GPU memory holding and simultaneously. The paper does not propose a memory-saving trick.
- Reference policy. The SFT model on the same task. The paper notes that a poorly-fit propagates into a poor implicit reward.
8D. Inference. Standard LLM inference. DPO is a training-time procedure; the deployed model is a standard decoder-only transformer that runs at the same inference cost as its pre-training counterpart. This is one of DPO’s practical advantages over reward-modelling approaches that require the reward model at deployment time for any ranking-based use case.
9. Experiments and results
Datasets.
- Controlled sentiment generation. Uses IMDB sentiment review data with synthetic preference pairs. A toy task that makes the implicit reward inspectable.
- TL;DR summarisation. Reddit posts with human-rated summaries, drawn from the Stiennon (2020) 7 setup. The canonical RLHF benchmark for summarisation.
- Anthropic Helpful-Harmless (HH) dialogue. Multi-turn dialogue preferences from the Anthropic HH-RLHF dataset 13 .
Baselines.
- PPO-RLHF. The canonical comparison: SFT → reward model → PPO under KL penalty.
- Preferred-FT. Supervised fine-tuning on the preferred responses only (no signal from dispreferred). A weaker baseline that isolates the contribution of using both arms of the preference pair.
- SFT-only. No preference learning. The lower bound.
Metrics.
- GPT-4 judge win rate. For TL;DR and dialogue. Pairwise comparisons against the reference SFT model, judged by GPT-4. The paper reports human verification on a subset.
- Reward-vs-KL frontier. For sentiment. Plots achieved reward against KL divergence from . The Pareto frontier shows whether DPO trades off reward and policy drift better than PPO.
Main results. [From the paper]
- Summarisation. DPO achieves a higher GPT-4 judge win rate against the reference SFT than PPO-RLHF. The paper’s Section 6.2 reports DPO at roughly 61% win rate at temperature 0.0 against PPO’s roughly 57%, a gap of roughly 4 percentage points.
- Dialogue. DPO matches or slightly exceeds PPO on the Anthropic HH evaluation.
- Sentiment. DPO achieves a better reward-vs-KL frontier than PPO across values, demonstrating that the implicit reward formulation does not pay a Pareto cost.
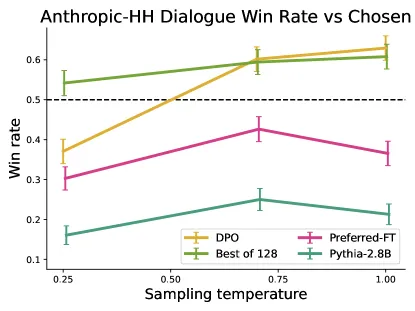
Figure 3 of Direct Preference Optimization (arXiv:2305.18290), reproduced for editorial coverage.
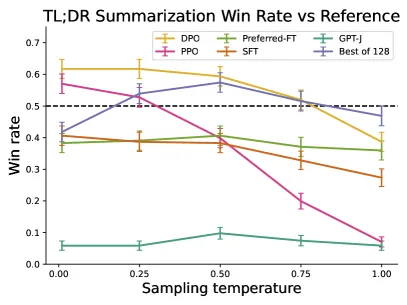
Figure 2 of Direct Preference Optimization (arXiv:2305.18290), reproduced for editorial coverage.
Ablations.
- sensitivity. Both methods are sensitive to ; DPO’s optimum tends to be near for the dialogue task and slightly higher for summarisation.
- Reference policy quality. A poorly-fit SFT model degrades DPO’s final policy noticeably. [Analysis] This is consistent with the implicit-reward derivation: if is far from the preference distribution, the implicit reward signal is weaker.
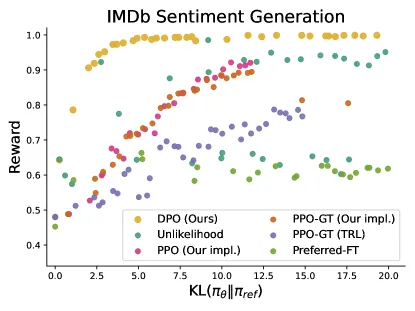
Figure 2 of Direct Preference Optimization (arXiv:2305.18290), reproduced for editorial coverage.
Robustness.
- Sampling temperature in evaluation. DPO outperforms PPO across a range of temperatures. The win-rate gap is largest at low temperature (greedy decoding).
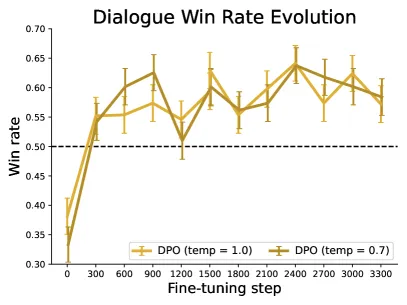
Figure 4 of Direct Preference Optimization (arXiv:2305.18290), reproduced for editorial coverage.
Best-of-N baseline (appendix). The paper’s Appendix D adds a Best-of-N sampling comparison: drawing samples from the SFT model and selecting the highest-scoring one under a reward model. Performance plateaus around , which gives a useful upper bound on what reward-model-driven inference-time scaling can buy. DPO matches or exceeds this Best-of-N performance without the inference-time sampling cost.
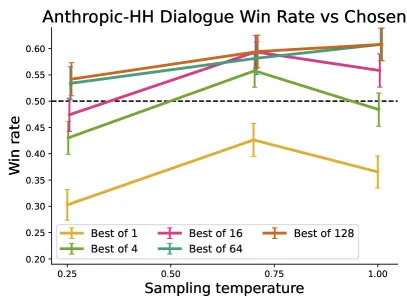
Figure 4 (Appendix D) of Direct Preference Optimization (arXiv:2305.18290), reproduced for editorial coverage.
Qualitative. The paper includes example completions from DPO and PPO on the same prompts. The behaviour is broadly similar; DPO’s outputs tend to be slightly less verbose on summarisation.
Scope limits. [From the paper] The largest model tested is in the 6B-parameter range (GPT-J 6B for summarisation). The paper acknowledges that models “orders of magnitude larger” remain unevaluated and frames the scaling question as future work; [Analysis] in 2026 terms this points to the 70B-and-above frontier, but that specific framing is the publication’s, not the paper’s.
Evidence audit. [Analysis] The summarisation result is the strongest evidence: DPO beats PPO-RLHF on a canonical benchmark with a meaningful margin and standard human-verified GPT-4 judging. The dialogue result is positive but the margin is narrower. The sentiment result is a controlled study and supports the theoretical framing. The frontier-scale gap is the most important open question; subsequent work has partially closed it.
10. Technical novelty summary
Novelty map.
| Contribution | Status | Notes |
|---|---|---|
| DPO loss formulation | Fully novel | Closed-form supervised loss replacing PPO + reward model |
| Reparameterisation trick (reward → policy ratio) | Adapted | The KL-constrained RL closed-form solution is established; its application to language model alignment is new |
| Bradley-Terry preference model | Adopted | Carried over from Bradley and Terry (1952), and from RLHF preference modelling |
| Empirical comparison to PPO-RLHF | Novel as comparative study | The first paper to demonstrate that the RL stage is empirically replaceable on these tasks |
Most novel contribution. The closed-form expression of preference learning as a supervised loss, with the reward model collapsed into the policy itself.
Not novel. The Bradley-Terry preference model and the KL-constrained policy optimisation framework. Both are established; DPO’s contribution is recognising that they compose into a closed-form supervised objective when the policy is the language model.
11. Situating the work
Prior work positioning.
- Christiano (2017) 6 introduced RLHF on Atari and MuJoCo, establishing the three-stage SFT → RM → RL pipeline.
- Stiennon (2020) 7 scaled this to language for summarisation, with PPO and an explicit reward model.
- Ouyang (2022) 8 productionised the pipeline for InstructGPT, the immediate predecessor of ChatGPT.
- Bai (2022) 9 introduced RLAIF and Constitutional AI, swapping human preferences for AI-generated preferences but keeping the RL stage.
What this work changes. It eliminates the reward model and the RL stage from preference-based alignment. The pipeline becomes SFT → DPO. The engineering surface drops from three models in flight to one trainable model plus a frozen reference.
[Reviewer Perspective] Skeptical objection: implicit reward fragility. The implicit reward is defined as . If is far from the ideal policy on a given prompt distribution, this ratio can become large and the implicit reward signal noisy. In practice, this manifests as DPO over-fitting to confident preference pairs and under-fitting on prompts the SFT model handles poorly.
[Reviewer Perspective] Author rebuttal. [From the paper] The KL constraint keeps close to , bounding the ratio. Empirically, the paper’s experiments do not show the over-fitting failure mode at the scales tested. This is a reasonable response at the 6B-parameter scale; whether it generalises to frontier scale is a separate question.
Unsolved. Scaling DPO to frontier models with the same simplicity. The original paper does not address this; subsequent work has partially mapped the trade-offs.
Three future directions. [Analysis]
- DPO with offline RL for off-policy preference data. When preference data is collected from a different policy than , DPO’s coverage assumption is violated. Off-policy variants address this.
- DPO with iterative dataset re-collection. A self-improvement loop where each DPO-trained policy generates new preference pairs evaluated by an oracle (human or AI) and used in a next DPO round.
- DPO variants for safety constraints. IPO 10 , KTO 11 , and ORPO 12 are successor methods that address overfitting on confident pairs (IPO), the requirement for paired data (KTO), and the need for a separate reference model (ORPO).
12. Critical analysis
Strengths.
- Simplicity. A single supervised loss replaces a two-stage RL pipeline. This is a real engineering win that has been validated by the rapid adoption of DPO in open-source alignment work since 2023.
- Stability. Supervised cross-entropy is well-understood and stable. The paper’s experiments do not show the run-to-run variance that PPO-RLHF is known for.
- No reward model. Eliminates an entire training stage and its associated hyperparameter tuning.
Author-stated weaknesses. [From the paper] The largest model tested is 6B parameters. The paper frames evaluation on “models orders of magnitude larger” as future work and does not claim DPO matches PPO at frontier scale.
[Reviewer Perspective] Understated weaknesses.
- Stability across diverse preference distributions. Subsequent work 10 has shown DPO is sensitive to preference-pair confidence; pairs where is overwhelmingly preferred can dominate the loss and cause the policy to over-fit on them.
- Reference-model quality dependency. A poorly-fit SFT model bottlenecks DPO. The paper notes this in passing; the practical implication is that DPO transfers responsibility from reward-model engineering to SFT-data engineering.
- Memory overhead of two model copies. Holding and in GPU memory simultaneously is a real cost at frontier scale. ORPO 12 addresses this by eliminating the reference model.
Reproducibility. [From the paper] Code is released 4 . Pythia checkpoints used as base models are publicly available. The Hugging Face TRL library 5 provides a reference DPOTrainer that reproduces the paper’s results on standard hardware.
Generalisability. Subsequent work (IPO, KTO, ORPO) shows the framework generalises beyond the original Bradley-Terry setup. KTO in particular demonstrates that paired data is not strictly required.
Assumption audit. The Bradley-Terry assumption is realistic for clean, high-confidence preference pairs. It is less realistic for noisy or low-confidence pairs, which is a known DPO failure mode addressed by IPO. The KL constraint formulation assumes the reference policy is a reasonable starting point; this is the standard SFT-then-align assumption.
[Analysis] What would make the paper stronger. Frontier-scale evaluation (models substantially larger than 6B, plausibly the 70B-class checkpoints common by 2026), a theoretical analysis of failure modes when is poor, and a direct comparison with off-policy preference learning methods. The paper acknowledges the first as future work in general terms; the latter two have been addressed by follow-up work rather than the original.
13. What is reusable for a new study
REUSABLE COMPONENT 1: The DPO loss formulation. Drop-in replacement for PPO-RLHF in any LLM team’s alignment pipeline. The Hugging Face TRL DPOTrainer 5 provides a reference implementation. For Indian ML teams running an SFT pipeline today, the DPO upgrade path is: collect preference pairs, hold the SFT model as , train with binary cross-entropy on the log-ratio difference, and ship.
REUSABLE COMPONENT 2: The reparameterisation trick. General to any KL-constrained RL problem with a tractable reference policy. The technique transfers beyond language modelling; the closed-form solution to KL-constrained reward maximisation is a textbook RL result that DPO weaponises for language models specifically.
REUSABLE COMPONENT 3: The sensitivity protocol. A template for tuning preference-learning losses. The DPO paper’s sweep on sentiment, covering two orders of magnitude, is a useful starting point for any team adopting preference-based fine-tuning.
Dependency map. DPO loss ← reparameterisation ← (Bradley-Terry assumption + KL-constrained reward maximisation framework). The dependency on Bradley-Terry is the most consequential; if a team’s preferences are not well-modelled by a sigmoid difference of rewards, the DPO formulation breaks and IPO or a related method is the right alternative.
Recommendation. [Analysis] ML teams running RLHF should evaluate DPO as a drop-in replacement for the PPO stage. The simplification is real and the paper’s claim has been validated by the Hugging Face TRL library’s reference DPOTrainer 5 and the two-plus years of follow-up alignment literature (IPO 10 , KTO 11 , ORPO 12 ) that build directly on DPO’s formulation. Teams whose preference data is noisy or unbalanced should additionally evaluate IPO and KTO before settling on DPO; the design space has continued to move since 2023.
14. Known limitations and open problems
Author-stated. [From the paper] Limited model-scale evaluation: the largest model in the original experiments is 6B parameters. Frontier-scale results are framed as future work.
[Analysis] Not stated by the paper.
- Noisy preference robustness. DPO’s loss is sensitive to confident preference pairs. Subsequent work 10 has documented over-fitting on high-confidence pairs.
- Reference-model dependency in tail cases. When is poorly fit on a slice of the prompt distribution, the implicit reward on that slice is unreliable. The paper acknowledges reference quality matters but does not study the failure mode in detail.
Root cause of each.
- The noisy-preference issue traces to the Bradley-Terry assumption: pairs with overwhelming preference for push toward infinity, dominating the loss.
- The reference-dependency issue traces to the reparameterisation: the implicit reward is , so any poor calibration propagates directly.
Open problems.
- Optimal selection across tasks. The paper sweeps four values on sentiment () and reports task-tuned values for the other tasks; a principled cross-task selection method is still open.
- Generalisation to multi-turn dialogue preferences. The DPO formulation treats and as full responses; turn-level credit assignment in multi-turn dialogue is an open extension.
Critical follow-up problem. Scaling DPO to frontier models with the same simplicity. The original paper does not solve this. KTO (2024) 11 and ORPO (2024) 12 partially address it: KTO removes the requirement for paired data; ORPO removes the reference-model memory overhead. The trade-offs are still being mapped, and as of 2026 the field has not converged on a single replacement for DPO at frontier scale.
How this article reads at three depths
For the curious high-school reader. Language models like ChatGPT learn to be helpful in two stages. Stage one teaches the model to imitate good example responses. Stage two used to involve a complicated reinforcement-learning recipe with a second “reward model” judging the language model’s outputs. DPO is a 2023 result showing that the whole second stage can be replaced with a single, simpler training step that uses pairs of “this response was preferred over that one” examples directly.
For the working developer or ML engineer. DPO collapses the reward-model + PPO + value-network + rollout-sampling stack into one supervised binary cross-entropy loss over preference pairs. Infrastructure shrinks substantially: one trainable policy plus a frozen reference copy of the SFT model, no separate reward model, no on-policy rollouts. The trade-off is doubled GPU memory during training (two copies of the model) and a hard dependency on SFT-data quality, since a poor reference policy propagates directly into a poor implicit reward. The Hugging Face TRL DPOTrainer is the canonical entry point. Teams with noisy or unbalanced preference data should also benchmark IPO and KTO before committing.
For the ML researcher. The novelty is the closed-form reparameterisation that expresses the reward as plus a partition-function offset that cancels in pairwise differences; combined with the Bradley-Terry preference likelihood, this collapses the two-stage RLHF objective into a supervised loss. Load-bearing assumptions: Bradley-Terry preference modelling, KL-constrained reward maximisation framework, sufficient preference-distribution coverage. Strongest skeptical objection: at frontier scale the implicit-reward signal’s robustness to a poorly-calibrated is unproven (the paper’s largest model is GPT-J 6B). The 2024 successors (IPO, KTO, ORPO) address specific failure modes the original paper does not study; a follow-up that scales DPO to the 70B+ class with the same simplicity remains the open frontier-scale question.
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. Direct Preference Optimization arXiv abstract page (Rafailov et al., NeurIPS 2023) (accessed ) ↩
- 2. DPO paper full HTML render (ar5iv mirror) (accessed ) ↩
- 3. DPO paper PDF on arXiv (accessed ) ↩
- 4. Eric Mitchell's reference DPO implementation (GitHub) (accessed ) ↩
- 5. Hugging Face TRL DPOTrainer reference implementation (accessed ) ↩
- 6. Christiano et al. 2017 (Deep Reinforcement Learning from Human Preferences) (accessed ) ↩
- 7. Stiennon et al. 2020 (Learning to Summarize with Human Feedback) (accessed ) ↩
- 8. Ouyang et al. 2022 (InstructGPT — Training Language Models to Follow Instructions with Human Feedback) (accessed ) ↩
- 9. Bai et al. 2022 (Constitutional AI: Harmlessness from AI Feedback) (accessed ) ↩
- 10. Azar et al. 2024 (IPO — A General Theoretical Paradigm to Understand Learning from Human Preferences) (accessed ) ↩
- 11. Ethayarajh et al. 2024 (KTO — Model Alignment as Prospect Theoretic Optimization) (accessed ) ↩
- 12. Hong et al. 2024 (ORPO — Monolithic Preference Optimization without Reference Model) (accessed ) ↩
- 13. Anthropic HH-RLHF preference dataset on Hugging Face (accessed ) ↩
Anonymous · no cookies set