What Is RLHF and Why Is It Being Replaced?
RLHF turned GPT-3 into ChatGPT by aligning models to human preferences. By 2026, simpler methods like DPO have largely replaced it for new alignment work.
The short answer
RLHF, or Reinforcement Learning from Human Feedback, is the alignment pipeline that turned a raw language model into a usable chat assistant. It is the technique behind the jump from GPT-3 to ChatGPT. The recipe has three stages: fit a reward model on human preference data, then optimise the language model against that reward using reinforcement learning, with a constraint that keeps the model from straying too far from its starting point. 1
It works. It is also unstable, expensive, and hard to engineer correctly. By 2024, simpler alternatives had emerged. Direct Preference Optimization (DPO) collapses the reward-model and reinforcement-learning stages into one supervised loss. 2 KTO and ORPO refine it further. For dev teams running alignment workloads in 2026, the practical answer is: use DPO or its successors for new work, and understand RLHF mainly to read older papers and assess vendor claims about how their models were aligned.
What RLHF actually is
The name describes the structure. Reinforcement learning is the optimisation method. Human feedback is the training signal. Plug both together and you get a pipeline with three stages.
Stage one is supervised fine-tuning, usually called SFT. Take a pretrained base model and fine-tune it on a dataset of high-quality demonstrations. For a chat model, the demonstrations are human-written examples of the kind of response the model should produce. After SFT, the model speaks roughly the right register, but it has no notion of which of two reasonable responses a person would actually prefer.
Stage two is reward model training. Show the SFT model a prompt. Sample two or more candidate responses from it. Ask a human labeller which response they prefer. Repeat thousands of times. Train a separate model (the reward model) to predict, given a prompt and a response, the score a human would assign. The reward model is the cheap proxy you will use in the next stage instead of asking a human at every step. 3
Stage three is reinforcement learning. Use the reward model as the reward signal and optimise the SFT model with a policy-gradient algorithm. The standard choice in the InstructGPT paper and most production pipelines that followed is Proximal Policy Optimization, or PPO. A KL-divergence penalty against the original SFT model is added to the objective, which keeps the policy from drifting into reward-hacking outputs that score well on the reward model but read as gibberish. 4
The diagram below shows the three stages and the data flow.
That is the entire pipeline. The InstructGPT paper from OpenAI in 2022 was the first widely-read demonstration that this recipe could turn GPT-3 into a model that followed instructions, and the result became the basis of ChatGPT later that year. 4
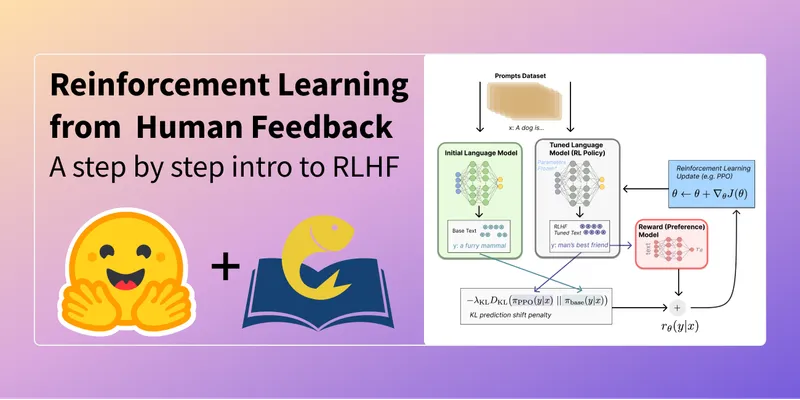
Image: Hugging Face — Illustrating Reinforcement Learning from Human Feedback (RLHF), used for editorial coverage of the three-stage RLHF pipeline.
Why it works
Three reasons.
The first is that preference data is cheap to collect compared to demonstration data. Asking a labeller “is response A better than response B?” is faster and more reliable than asking them to write a perfect response from scratch. People disagree about how to write a good answer; they agree more readily about which of two answers is worse.
The second is that the reward model plus reinforcement learning combination is general. Once you have a reward signal (a function from prompt and response to a number), reinforcement learning gives you a way to optimise any model against that signal. The same machinery works for helpfulness, harmlessness, factuality, or any other axis a labeller can rank.
The third is that the KL penalty keeps the model honest. Without it, the model learns to game the reward model by producing outputs that score high on the proxy but are useless or pathological. With it, the policy stays close to the SFT distribution while shifting toward higher-reward regions. This is why RLHF in production looks like a small adjustment to the SFT model rather than a wholesale rewrite of its behaviour.
Why it doesn’t scale
The same paper that made RLHF famous also made its problems famous, and a wave of follow-up work in 2023 and 2024 set out to fix them.
PPO is unstable. Reinforcement learning at language-model scale is finicky. Hyperparameters need tuning per-model, the loss curves are noisy, and small changes to the reward model or the KL coefficient can produce qualitatively different policies. Teams running RLHF report that getting a clean run is a craft skill, not a checklist.
The reward model is its own infrastructure. Stage two requires training and serving a separate neural network roughly the size of the policy. That doubles the GPU memory budget during stage three, because both models have to run in parallel: the policy generates samples and the reward model scores them.
Sampling cost is real. Stage three is on-policy: every gradient step requires fresh samples from the current policy, scored by the reward model. A single RLHF run on a moderately-sized model can take days of compute and require careful checkpointing to recover from instability.
Engineering overhead is high. A working RLHF pipeline has three training stages, two model artefacts, a preference-data collection workflow, and a reward-model evaluation harness. Production teams running RLHF report the pipeline can absorb more engineering time than the model itself.
By 2023, researchers were asking whether all of this was necessary. The answer turned out to be no.
What replaces it
Direct Preference Optimization (DPO), introduced by Rafailov and co-authors at Stanford in May 2023, is the headline alternative. 2 The trick is mathematical. The DPO paper shows that if you assume the reward model has the form implied by the standard RLHF objective, you can rearrange the equations so that the reinforcement-learning stage and the reward-model stage collapse into a single supervised loss on the preference data. There is no separate reward model. There is no PPO loop. The aligned model is fit directly from preference pairs using a standard cross-entropy-like objective.
The practical impact is large. A DPO run is a fine-tune. It uses standard supervised-learning infrastructure, takes a fraction of the compute of a comparable PPO run, and produces results that the original DPO paper reports as matching or improving on PPO-based RLHF on the benchmarks the authors tested. 2 DPO has since become a common baseline for new alignment work, and the Hugging Face TRL library ships a first-party DPOTrainer alongside the SFTTrainer used in supervised fine-tuning.
KTO (Kahneman-Tversky Optimization) is a 2024 refinement that drops the requirement for paired preferences. KTO trains on a stream of (prompt, response, desirable-or-not) labels, drawing on the prospect-theory idea that humans evaluate outcomes as gains or losses against a reference point. 5 Where DPO needs A-vs-B comparisons, KTO works with thumbs-up / thumbs-down data, which is closer to what production logs actually contain.
ORPO (Odds Ratio Preference Optimization) goes one step further. It folds the SFT stage and the preference-optimisation stage into a single training objective, removing the need for a separate supervised fine-tune before the alignment step. For teams starting from a strong base model, ORPO can compress the alignment pipeline into one fine-tuning job.
IPO (Identity Preference Optimization) is a closely-related variant that addresses a specific failure mode of DPO under noisy or weakly-separated preferences. It is not a wholesale alternative; it is a tighter loss function for the same setup.
The common thread across these methods is the same insight DPO started with: most of the engineering work in classical RLHF was a consequence of the reinforcement-learning framing, not a consequence of the alignment problem itself. Once you do the algebra carefully, the three-stage pipeline collapses into a one- or two-stage supervised problem, and the engineering complexity falls with it.
What this means for Indian developers in 2026
Three practical takeaways.
If you are starting a new alignment project today, the default choice is DPO or one of its successors. The compute budget is smaller, the engineering surface narrows, and the ecosystem around DPO (Hugging Face’s TRL library, Axolotl, Unsloth) is mature enough that a team running alignment on a single H100 box at E2E Networks or Yotta can ship a credible run in days rather than weeks.
If you are reading older papers (the InstructGPT paper, the Anthropic Constitutional AI paper, the early Llama 2 fine-tuning report), the RLHF vocabulary is the lingua franca and you need to understand it to follow the methodology. The same is true for vendor claims. When a model card says “aligned with RLHF,” it is describing a specific recipe, not a generic alignment story, and the recipe’s strengths and weaknesses come along with it.
If you are evaluating a vendor’s aligned model for production use, the alignment method matters less than the preference data and the evaluation set. A well-curated DPO model on clean preferences will outperform a sloppy PPO-RLHF model on noisy preferences, and vice versa. The method is a force multiplier on the data, not a substitute for it.
Honest caveats
The RLHF-to-DPO shift is the dominant trend, not the only one. Some research labs continue to use PPO-based RLHF for production model training where they have already absorbed the engineering cost and the pipeline is part of their internal moat. Reinforcement learning with verifiable rewards (the technique behind reasoning models like OpenAI’s o-series and DeepSeek’s R-line) is a separate development that uses RL but with rule-based rewards rather than learned preference rewards, and it does not fit cleanly into either the RLHF or the DPO frame.
Benchmarks comparing DPO and RLHF are also less settled than the headline framing suggests. The original DPO paper reported matching or improving on PPO-based RLHF across the benchmarks tested; subsequent comparison work — including Xu et al. 2024, “Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study” (arXiv:2404.10719) — has found that PPO-based RLHF retains an edge on some out-of-distribution behaviours and that DPO can be more sensitive to preference-data quality. Treat the “DPO replaces RLHF” framing as accurate for most new builder work and as approximate for frontier research.
The vocabulary in this article reflects the canonical 2022-to-2024 framing. The field moves fast, and by the time the next cohort of alignment methods lands, some of the names here will be historical references rather than current practice. The underlying idea (that aligning a model to human preferences is mostly a data problem dressed up as an optimisation problem) is more durable than any specific method.
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. Hugging Face blog — Illustrating Reinforcement Learning from Human Feedback; canonical accessible explainer of the three-stage SFT → reward-model → PPO pipeline (accessed ) ↩
- 2. Rafailov et al. — Direct Preference Optimization: Your Language Model is Secretly a Reward Model (arXiv:2305.18290, May 2023); shows the RLHF objective can be reduced to a single supervised loss on preference pairs (accessed ) ↩
- 3. Christiano et al. — Deep Reinforcement Learning from Human Preferences (arXiv:1706.03741, 2017); foundational paper introducing the reward-model-from-preferences idea that RLHF later built on (accessed ) ↩
- 4. Ouyang et al. — Training Language Models to Follow Instructions with Human Feedback (InstructGPT, arXiv:2203.02155, March 2022); the OpenAI paper that demonstrated RLHF on GPT-3 and became the basis of ChatGPT, with PPO as the policy-gradient method and a KL penalty against the SFT reference (accessed ) ↩
- 5. Ethayarajh et al. — KTO: Model Alignment as Prospect Theoretic Optimization (arXiv:2402.01306, February 2024); proposes a loss inspired by Kahneman-Tversky prospect theory that works on unpaired thumbs-up/thumbs-down data (accessed ) ↩
Anonymous · no cookies set