Code Llama, StarCoder, and DeepSeek-Coder — a multi-paper review
Multi-paper review of Code Llama (2308.12950), StarCoder + StarCoder2 (2305.06161, 2402.19173), and DeepSeek-Coder-V2 (2406.11931). FIM, HumanEval, MoE for code.

Figure 1 of Code Llama (arXiv:2308.12950), reproduced for editorial coverage.
1. Umbrella scope and paper identity
Citations.
- Rozière et al., “Code Llama: Open Foundation Models for Code,” arXiv:2308.12950, August 2023 1 . Meta AI’s specialization of Llama 2 into a code family at 7B, 13B, 34B, and 70B parameters with fill-in-the-middle infilling and long-context extension to 100K tokens.
- Li et al., “StarCoder: may the source be with you!” arXiv:2305.06161, May 2023 3 . The BigCode community’s 15.5B-parameter open-data code model trained on The Stack with multi-query attention and FIM.
- Lozhkov et al., “StarCoder 2 and The Stack v2: The Next Generation,” arXiv:2402.19173, February 2024 5 . The BigCode follow-up at 3B / 7B / 15B trained on The Stack v2 with grouped-query attention and a sliding-window long-context regime.
- DeepSeek-AI et al., “DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence,” arXiv:2406.11931, June 2024 7 . The first open-weights mixture-of-experts code family (16B-total / 2.4B-active Lite and 236B-total / 21B-active Full) and the first open model to claim HumanEval parity with GPT-4o.
Retrieval. All four papers retrieved in full via the ar5iv HTML render 2 4 6 8 . Supplementary appendices for Code Llama (instruction tuning data composition), StarCoder 2 (per-language token counts), and DeepSeek-Coder-V2 (MoE routing details) were retrieved through the same source. [Reconstructed] A handful of DeepSeek-Coder-V2 MoE configuration details (exact expert count, top-k routing depth) are not in the V2 paper itself; this article cross-references the parent DeepSeek-V2 technical report 14 where the V2 paper defers to it, and flags the cross-reference where used.
Classification. Architecture proposal (StarCoder 2’s GQA shift, DeepSeek-Coder-V2’s MoE pivot), training method (FIM across all four; long-context staged extension), benchmark (HumanEval, MBPP, MultiPL-E, LiveCodeBench, DS-1000), data-driven (The Stack lineage), LLM-based, application.
Technical abstract in the publication’s voice. Between May 2023 and June 2024 the open-weights code-LLM frontier moved roughly 50 absolute pass@1 points on HumanEval, from StarCoder’s 33.6% to DeepSeek-Coder-V2’s 90.2%. The four papers in this review document the specific recipe choices behind that move. StarCoder established the open-data + FIM + multi-query-attention baseline at 15B parameters trained on roughly 1T tokens of permissively-licensed code. Code Llama then showed that specializing an already-trained general LLM (Llama 2) on code tokens reaches comparable quality at lower marginal training cost, while introducing a 100K-token context window via RoPE base-frequency rescaling and a long-context fine-tuning stage. StarCoder 2 returned with a 4x-larger Stack v2 dataset, grouped-query attention replacing multi-query, and a sliding-window 16K-context recipe that closed the gap to Code Llama 34B at 15B parameters. DeepSeek-Coder-V2 then broke the open-vs-closed parity ceiling: a 236B-total / 21B-active mixture-of-experts continued from DeepSeek-V2 for 6T additional tokens, expanding language coverage from 86 to 338 programming languages and reaching 90.2% HumanEval pass@1 against GPT-4o’s 91.0%. Fill-in-the-middle training is the common thread across all four; the architectural progression is dense → dense → dense-with-GQA → sparse-MoE.
Primary research questions.
- Code Llama: Can a general-purpose LLM be specialized into a state-of-the-art code model via continued pretraining rather than training from scratch, and what infilling and long-context recipes accompany that specialization?
- StarCoder: Can an entirely open-data code model (permissively-licensed sources only) match closed-data baselines while shipping with attribution and PII-redaction tooling?
- StarCoder 2: Does scaling the open-data substrate by 4x and switching from MQA to GQA close the remaining gap to closed-data code models at smaller parameter counts?
- DeepSeek-Coder-V2: Can an open-weights MoE built on a strong general-purpose MoE base reach GPT-4o-class code generation on standard benchmarks?
Core technical claims.
- Code Llama: The FIM-rate-0.9 training regime preserves infilling capability without harming left-to-right perplexity, and RoPE base-frequency rescaling from 10,000 to 1,000,000 unlocks the 100K-token context extension 1 .
- StarCoder: StarCoderBase reaches 33.6% pass@1 on HumanEval and outperforms every open code LLM supporting multiple languages, while matching or beating OpenAI’s code-cushman-001 3 .
- StarCoder 2: StarCoder2-3B outperforms other ~3B code LLMs and even StarCoderBase-15B; StarCoder2-15B matches or exceeds Code Llama 34B 5 .
- DeepSeek-Coder-V2: The 236B-total / 21B-active model achieves 90.2% HumanEval pass@1 and 76.2% MBPP+ pass@1, surpassing GPT-4o on MBPP+ and reaching near-parity on HumanEval 7 . [Analysis] The HumanEval-parity framing is the authors’; independent reproduction studies on LiveCodeBench and SWE-bench show the gap is wider on contamination-controlled and agentic benchmarks (Section 11).
Core technical domains.
| Domain | Depth |
|---|---|
| Fill-in-the-middle (FIM) training objective | Deep |
| HumanEval and pass@k functional-correctness evaluation | Deep |
| Code dataset construction (The Stack, deduplication, PII redaction) | Deep |
| Long-context extension (RoPE rescaling, sliding window) | Moderate |
| Multi-query and grouped-query attention | Moderate |
| Mixture-of-experts routing for code | Moderate |
| Instruction tuning for code (self-instruct, executable feedback) | Moderate |
Reader prerequisites. Decoder-only Transformer basics, the idea of next-token cross-entropy training, and a passing acquaintance with how code is tokenized. The Glossary in Section 2.5 brings the high-school reader up to speed on every other term.
Register labels used throughout. “From the paper:” prefix for paper-supported claims. [Analysis] for the publication’s own assessment. [Reconstructed] for content reconstructed from partial disclosure. [External comparison] for comparisons to prior or contemporaneous work. [Reviewer Perspective] for skeptical commentary beyond what the paper proves.
2. TL;DR and executive overview
TL;DR. Between 2023 and 2024, open-weights code models went from scoring about one in three programming problems correct on a standard benchmark called HumanEval to scoring nine in ten, close to the best closed model at the time. This review walks through the four papers (Code Llama, StarCoder, StarCoder 2, and DeepSeek-Coder-V2) that drove that jump and explains the three training tricks they share: fill-in-the-middle infilling so the model can edit code rather than just continue it, long context windows so it can see whole files at once, and careful filtering of training data sourced from public GitHub.
Executive summary. Code Llama specialized Meta’s general-purpose Llama 2 into a code model by continuing training on roughly 500 billion code tokens with a 90% fill-in-the-middle rate, then extended context to 100K tokens by rescaling RoPE positional encoding. StarCoder and StarCoder 2, from the open BigCode community, trained from scratch on The Stack (an attribution-tracked permissively-licensed code corpus) with multi-query and later grouped-query attention. DeepSeek-Coder-V2 then took a mixture-of-experts base (DeepSeek-V2), continued training it on 6 trillion additional code-and-math tokens, and reached GPT-4o-class HumanEval scores while activating only 21 billion of its 236 billion parameters per token. The four papers together cover every recipe choice a team would face when building a code-LLM in 2026: data sourcing, FIM training rate, attention variant, context-extension method, and the dense-vs-MoE decision.
Five practitioner-relevant takeaways.
- The FIM rate is not a 50/50 toss-up. Code Llama uses 0.9, StarCoder and DeepSeek-Coder-V2 use 0.5. The Code Llama ablation argues high rates do not harm left-to-right perplexity; the StarCoder line treats the lower rate as safer. For new training runs, default to 0.5 unless infilling is the primary deployment target.
- RoPE base-frequency rescaling from 10,000 to 1,000,000 plus 10,000 gradient steps of long-context fine-tuning is the documented Code Llama recipe for 100K-token context. StarCoder 2’s sliding-window-4096 approach over a 16K context is the lighter-weight alternative. Choose by serving target.
- The StarCoder pipeline’s attribution tooling and PII redaction are reusable independent of the model: any team training on public code needs them, and BigCode publishes the relevant tooling.
- DeepSeek-Coder-V2’s gap to GPT-4o on instruction-following and agentic tasks (notably SWE-bench) is larger than the gap on HumanEval; the paper itself flags this. Treat HumanEval parity as one signal among several, not as overall parity.
- [Analysis] Specializing a strong general-purpose base (Code Llama from Llama 2, DeepSeek-Coder-V2 from DeepSeek-V2) is now the dominant pattern. Training a code-only model from scratch (StarCoder, StarCoder 2) is the niche the BigCode community defends on open-data grounds, not on quality grounds.
Pipeline overview. All four pipelines share four stages: (a) source filtering and deduplication on a large code corpus (The Stack for StarCoder/StarCoder 2, an undocumented Meta corpus for Code Llama, GitHub+CommonCrawl for DeepSeek-Coder-V2); (b) pretraining or continued pretraining with FIM applied at the document level; (c) long-context extension via RoPE rescaling or sliding window; (d) instruction tuning (Code Llama Instruct, DeepSeek-Coder-V2-Instruct). StarCoder and StarCoder 2 do not ship instruction-tuned variants in the base release.
2.5. Glossary
| Term | Plain-English explanation | First appears in |
|---|---|---|
| Token | The smallest unit of text the model sees, usually a sub-word piece. Code models use byte-level BPE tokenizers tuned to whitespace and punctuation. | Section 1 |
| Pretraining | The first training phase where the model learns from huge volumes of code and text by predicting the next token. | Section 1 |
| Fill-in-the-middle (FIM) | A training trick where the model learns to predict a missing middle chunk given a prefix and a suffix — essential for editor autocomplete. | Section 1 |
| Pass@1 | The fraction of programming problems the model solves on the very first attempt when generating one solution; the headline HumanEval metric. | Section 1 |
| HumanEval | OpenAI’s 2021 benchmark of 164 Python programming problems with hidden unit tests; the standard pass@1 yardstick. | Section 1 |
| MBPP | ”Mostly Basic Python Problems” — a 974-problem benchmark of short crowd-sourced programming tasks. | Section 1 |
| RoPE (Rotary Position Embedding) | A method for telling the model where each token sits in the sequence by rotating attention vectors. Its base frequency controls how far the model generalises. | Section 1 |
| GQA (Grouped Query Attention) | An attention variant where multiple query heads share one key/value head; shrinks the KV-cache memory at inference time. | Section 1 |
| MQA (Multi-Query Attention) | The extreme case of GQA where all query heads share a single key/value head. Used by StarCoder. | Section 1 |
| MoE (Mixture of Experts) | A design where the model has many “expert” subnetworks but a routing layer activates only a few per token. DeepSeek-Coder-V2 uses this. | Section 1 |
| Active parameters | The number of parameters actually computed for a given token in an MoE model. DeepSeek-Coder-V2 Full activates 21B of 236B per token. | Section 1 |
| The Stack | A 3-terabyte open dataset of permissively-licensed GitHub code curated by the BigCode community. | Section 1 |
| Continued pretraining | Resuming pretraining of an already-trained base model on a new data mixture; cheaper than training from scratch. | Section 1 |
| PSM / SPM | Two formats for fill-in-the-middle training: Prefix-Suffix-Middle and Suffix-Prefix-Middle. Models trained on both can do either at inference. | Section 6 |
| MultiPL-E | A translation of HumanEval into 18+ programming languages; the standard multilingual code benchmark. | Section 9 |
| LiveCodeBench | A rolling code-generation benchmark released March 2024 designed to be free of training-data contamination. | Section 9 |
| ”From the paper:” prefix | Content directly supported by the cited paper or vendor disclosure. | Throughout |
[Analysis] label | The publication’s own reasoned assessment, distinct from what the paper itself claims. | Throughout |
[Reconstructed] label | Content reconstructed from partial disclosure where the paper does not fully specify the detail; flagged so the reader can calibrate trust. | Section 1 |
[External comparison] label | A comparison to prior or contemporaneous work outside the paper itself. | Section 4 |
[Reviewer Perspective] label | A skeptical or speculative assessment beyond what the paper proves. | Section 11 |
3. Problem formalisation
Notation table.
| Symbol | Type | Meaning | First appears in |
|---|---|---|---|
| Set | Tokenizer vocabulary | Section 3 | |
| Sequence | A code document tokenized to length | Section 3 | |
| Parameter | Model weights | Section 3 | |
| Probability | Model’s predicted distribution over the next token | Section 3 | |
| Sequence | Prefix segment of an FIM-transformed document | Section 6 | |
| Sequence | Middle segment of an FIM-transformed document | Section 6 | |
| Sequence | Suffix segment of an FIM-transformed document | Section 6 | |
| Scalar | FIM transformation rate (0.5 for StarCoder, 0.9 for Code Llama) | Section 6 | |
| Scalar | RoPE base frequency (10,000 default; 1,000,000 for Code Llama long-context) | Section 6 | |
| Sequence window | Sliding-attention window length (4096 for StarCoder 2) | Section 5 | |
| Scalar | Number of query and key/value attention heads | Section 5 | |
| Scalar | Number of experts in an MoE layer | Section 5 | |
| Scalar | Number of experts activated per token (top- routing) | Section 5 | |
| Vector | Gating distribution over experts for token | Section 5 | |
| Function | Probability that at least one of samples passes all unit tests | Section 6 |
Formal problem statement. A code language model defines a distribution over tokens. Pretraining minimises the next-token cross-entropy loss
over a corpus that mixes source code, code-adjacent natural language (issues, commits, docstrings), and general natural language. The FIM-augmented loss further trains the model to predict a removed middle segment given its surrounding prefix and suffix . The downstream evaluation reframes generation as functional correctness: given a problem prompt and reference unit tests , the model is asked to produce a code completion that passes every test in .
Explicit assumption list.
- All four pipelines assume the next-token cross-entropy objective on code is well-aligned with the downstream functional-correctness objective on HumanEval-like benchmarks. [Analysis] This is the load-bearing assumption of the entire field, and it broke conspicuously on agentic benchmarks like SWE-bench where the gap between cross-entropy quality and end-to-end task success is large.
- The FIM transformation does not harm left-to-right generation quality at the chosen rate. Code Llama tests rates and reports no measurable harm at 1 . Bavarian et al. 9 first claimed “FIM-for-free” at 50%.
- Deduplication of training data at the file or near-duplicate level improves downstream quality. StarCoder uses MinHash + LSH near-deduplication 3 ; StarCoder 2 reports the same protocol on Stack v2 5 .
- HumanEval and MBPP test sets are not contaminated with training data. [Analysis] This assumption was tenable for early Code Llama and StarCoder; by 2024 the contamination concern is one of the explicit motivations behind LiveCodeBench 13 and HumanEval+ 12 .
Why the problem is hard. First, the search space for code is unbounded: every program can be written in many syntactically distinct ways, and the cross-entropy loss does not capture functional equivalence. Second, code has long-range dependencies: a function defined at the top of a file is referenced 500 lines later, so context length is load-bearing. Third, the training data quality bar is harder than for natural-language text. Auto-generated code, vendored dependencies, and one-line files dilute the signal if not filtered. Fourth, evaluating code generation requires executing untrusted code in a sandbox, which the field’s standard pass@k harness handles but at a real engineering cost.
Data-driven setup. Code Llama’s mixture is 85% code, 8% code-adjacent natural language, 7% natural language 1 ; the source corpus is not publicly enumerated. StarCoder and StarCoder 2 use The Stack v1 and v2 respectively, both attribution-tracked permissively-licensed GitHub code curated by BigCode 17 . DeepSeek-Coder-V2’s 6T-token continued pretraining mixes 60% code (1,170B tokens from GitHub and CommonCrawl across 338 languages), 10% math (221B tokens), and 30% natural language 7 .
Causal vs correlational. None of the four papers claim a causal identification of any recipe choice. All comparisons are observational at the level of a single training run per configuration. [Analysis] The closest thing to a controlled ablation is Code Llama’s FIM-rate sweep over a held-out subset; the others rely on cross-paper comparison, which is confounded by data, compute, and architecture differences simultaneously.
4. Motivation and gap
Real-world problem. Concretely, a developer writing code in an editor wants three things from a language model: (a) accurate single-line autocomplete, (b) accurate multi-line completion mid-file given both the prefix above and the suffix below the cursor, and (c) zero-shot solution of described problems from a docstring or natural-language prompt. The first two require FIM; the third was the original Codex 10 framing.
Existing approaches and their failure modes.
- Codex / code-cushman-001 (OpenAI, 2021): Closed weights, closed data. Established HumanEval as the standard benchmark 10 .
- CodeGen, InCoder, SantaCoder (2022–early 2023): Open-weights, smaller (up to ~16B), trailing Codex on HumanEval.
- Llama 2 base (2023): General-purpose; trained on only ~4.5% code by token count; code performance well below specialist models.
The gap each paper claims to fill:
- Code Llama: The first frontier-class open-weights code model with a documented FIM and long-context recipe, leveraging Llama 2 as a warm start.
- StarCoder: The first open-weights AND open-data frontier code model with full attribution and PII redaction.
- StarCoder 2: Closes the remaining quality gap to Code Llama at smaller parameter counts via a 4x-larger open-data substrate.
- DeepSeek-Coder-V2: The first open-weights code model to claim parity with frontier closed-source models (GPT-4 Turbo, GPT-4o, Claude 3 Opus) on HumanEval and MBPP+.
[External comparison] The two contemporaneous lineages that frame the field beyond the four reviewed papers: the Mistral / Mixtral line (dense and MoE general models with strong code performance via pure scale rather than specialization) and the Qwen-Coder line (Alibaba’s specialization track, which by Qwen2.5-Coder-32B-Instruct reached competitive HumanEval but is not reviewed here).
5. Method overview
5.1 Code Llama architecture and pipeline
[From the paper] 1 Code Llama starts from a Llama 2 checkpoint (7B, 13B, 34B; 70B from Llama 2 70B) and runs three sequential stages: (a) code-tokens continued pretraining on 500B tokens for the 7B/13B/34B variants and 1T tokens for the 70B variant; (b) long-context fine-tuning that rescales RoPE base frequency from 10,000 to 1,000,000 and trains for ~10,000 gradient steps; (c) optional Python specialization (additional 100B tokens) and instruction tuning (Code Llama Instruct via self-instruct on programming problems with executable feedback).
Plain-English intuition. Start with a general-purpose model that already speaks English fluently and has seen some code. Pour more code into it (and a small amount of code-adjacent prose like commit messages and Stack Overflow answers). Then teach it specifically to handle very long contexts by changing how positional information is encoded. Finally, teach the assistant variants to follow instructions about code.
Design rationale. Specializing rather than training from scratch saves compute by reusing Llama 2’s existing language modelling competence. The 85% / 8% / 7% data mixture preserves enough natural-language signal to keep instruction-following intact. The RoPE rescaling is the cheapest documented method for extending context far beyond the pretraining window.
Classification. [Adopted] decoder-only Transformer + RoPE + SwiGLU from Llama 2; [Adopted] FIM training from Bavarian et al. 9 ; [New] the specific FIM-rate-0.9 + 100K-context recipe and the multi-stage long-context schedule.
5.2 StarCoder architecture and pipeline
[From the paper] 3 StarCoder is a 15.5B-parameter decoder-only Transformer with 40 layers, 48 attention heads, hidden dimension 6144, and multi-query attention (one shared KV head across all query heads). Context length is 8192. The tokenizer has 49,152 entries using byte-level BPE. Training runs ~1 trillion tokens drawn from The Stack v1.2 across 86 programming languages plus GitHub issues, commits, and Jupyter notebooks. FIM is applied at rate 0.5 with PSM and SPMv2 modes used equally. Hardware: 512 A100 80GB GPUs across 64 nodes; ~320,256 GPU hours for StarCoderBase.
Plain-English intuition. Train from scratch on an open dataset that you can trust to be permissively licensed. Use multi-query attention so that, at inference time, the model needs to remember less state per token (one shared KV head instead of one per query head), which makes serving fast. Train with fill-in-the-middle half the time so the model can edit mid-file as well as continue.
Design rationale. MQA was, in 2023, the standard memory-saving choice for long-context code work. The open-data + attribution-tooling stance is BigCode’s mission, not a quality optimisation. The 8K context was the consensus ceiling for serious code work at the time.
Classification. [Adopted] MQA from Shazeer 2019 16 ; [Adopted] FIM from Bavarian et al. 9 ; [New] the Stack-trained open-data baseline at 15B scale with attribution tooling.
5.3 StarCoder 2 architecture and pipeline
[From the paper] 5 StarCoder 2 ships at three sizes: 3B (32 layers, 24 heads, hidden 3072), 7B (32 layers, 32 heads, hidden 4608), and 15B (40 layers, 48 heads, hidden 6144). The architectural break from StarCoder is grouped-query attention with 2 KV heads on the 3B and 4 KV heads on the 7B and 15B 15 . Training uses sliding-window attention with a 4096-token window during the long-context phase that extends to a 16,384-token context. FIM is applied at a repo-level rate of 0.5: 50% of repositories are selected, and within each, 50% of file chunks get the FIM transformation, using the <fim_prefix>, <fim_middle>, <fim_suffix> sentinel tokens.
Total unique training tokens: 622B for the 3B model, 658.5B for the 7B, and 913.2B for the 15B. The Stack v2 carries 525.5B tokens (17 languages, used by 3B/7B) or 775.48B tokens (619 languages, used by 15B), supplemented with Pull Requests (19.54B), Issues (11.06B), Jupyter (~31B total), Kaggle notebooks (1.68B), ArXiv (30.26B, 7B/15B only), and StackOverflow (10.26B) 5 .
Plain-English intuition. Same overall recipe as StarCoder but with three improvements: (a) more data, drawn from a 4x-larger Stack v2; (b) grouped-query attention instead of multi-query, which trades a bit of memory for clearer quality gains; (c) a longer context (16K) achieved via sliding-window attention so memory does not blow up.
Design rationale. The MQA → GQA shift mirrors the broader 2023 industry move (Llama 3, Mixtral, others all chose GQA over MQA). The sliding window keeps long-context training feasible on the same hardware. The repo-level FIM selection respects code-base coherence: files within a repository share idiom and naming.
Classification. [Adapted] GQA from Ainslie et al. 15 ; [Adopted] sliding-window from Mistral 7B; [New] the repo-level FIM selection at 50/50 nesting.
5.4 DeepSeek-Coder-V2 architecture and pipeline
[From the paper] 7 DeepSeek-Coder-V2 is a mixture-of-experts model continued from an intermediate DeepSeek-V2 checkpoint 14 . Two sizes ship: Lite at 16B total parameters and 2.4B active, and Full at 236B total parameters and 21B active. The architecture inherits DeepSeek-V2’s Multi-Head Latent Attention (MLA) and DeepSeekMoE structure with shared experts plus routed experts and a top- gating mechanism. Context length is extended from 16K (V2 inherited) to 128K via a second long-context training phase.
Continued pretraining runs 6T additional tokens with the composition 60% code (1,170B tokens, 338 programming languages), 10% math (221B tokens), and 30% natural language. FIM is applied only to the Lite (16B) variant at rate 0.5 in PSM mode; the Full model is trained left-to-right only. [Reconstructed] The V2 paper does not enumerate the exact number of experts or the top- value for V2-Coder; it defers to DeepSeek-V2’s report 14 , where DeepSeek-V2 reports 160 routed experts plus 2 shared experts with top-6 routing for the 236B variant. Treating this as the V2-Coder configuration is the standard assumption.
Instruction tuning ships as DeepSeek-Coder-V2-Instruct using a curated supervised-fine-tuning corpus followed by Group Relative Policy Optimization (GRPO), reinforcement learning against a code-quality reward.
Plain-English intuition. Take a strong general-purpose mixture-of-experts model. Continue training it on a code-heavy diet for the equivalent of half a complete pretraining run. The MoE design means the “weight” of the model (what gets stored on disk and loaded) is huge (236B parameters), but the actual computation per token is small (21B), so serving costs scale with the active count rather than the total. Then teach the instruction-following variant via reinforcement learning against code-quality signals.
Design rationale. The MoE pivot decouples total capacity from per-token compute. Continued pretraining from V2 inherits all of V2’s natural-language and reasoning capability, which the paper credits for the unusually strong math and reasoning numbers. The 338-language coverage is the headline data-side claim relative to earlier models.
Classification. [Adapted] MoE design from the broader Switch / Mixtral lineage; [Adopted] MLA from DeepSeek-V2 14 ; [New] the specific 6T-token code-and-math continued pretraining mixture and the GRPO post-training applied to a code model.
5.5 What breaks if removed
- Code Llama, FIM removed: No infilling capability; the model becomes a left-to-right code continuer only, breaking editor autocomplete use-cases.
- Code Llama, RoPE rescaling removed: The 100K-context claim collapses; effective context stays at Llama 2’s 4K.
- StarCoder, MQA removed: KV-cache memory at 8K context roughly 48x larger (one KV head per query head); serving cost-per-token rises commensurately.
- StarCoder 2, sliding window removed: The 16K-context training phase becomes memory-prohibitive on the same hardware budget.
- DeepSeek-Coder-V2, MoE removed: You get a dense 21B model. Total capacity drops from 236B to 21B; the GPT-4o-parity claim is unsustainable at 21B dense.
Figure from Code Llama (arXiv:2308.12950), reproduced for editorial coverage of the FIM training scheme.
6. Mathematical contributions
This is the depth section. Every MATH ENTRY includes a worked numerical example, term-by-term analysis, and step-by-step derivation.
MATH ENTRY 1: pass@k functional-correctness metric
- Source: Chen et al. 2021 10 ; used identically by all four reviewed papers.
- What it is: The probability that at least one out of independently-sampled completions passes every hidden unit test for a problem, averaged over the benchmark’s problems.
- Formal definition: The unbiased estimator generates samples per problem, counts the that pass all tests, and computes
-
Each term:
- is the total number of samples drawn per problem (typical: ).
- is the number of those samples that pass every unit test.
- is the “budget” at evaluation (typical: ). pass@1 is the headline number.
- is the probability that all chosen samples come from the failing set, i.e., none pass. One minus this is the probability at least one passes.
-
Worked numerical example. Take HumanEval problem id 23 (“strlen”) with samples drawn at temperature 0.8.
Step 1: Suppose samples pass the unit tests.
Step 2: For : , so pass@1 contribution from this problem is .
Step 3: For : , so pass@5 contribution is .
Step 4: Average across all 164 HumanEval problems to get the reported pass@1 and pass@5 numbers.
-
Role: The single primary evaluation metric across all four papers.
-
Edge cases: When the contribution is 0; when the contribution is 1. At small the estimator has high variance per problem; the standard protocol uses with for pass@1.
-
Novelty:
[Adopted]from Codex 10 . -
Why it matters: It is the headline benchmark all four papers compete on. Differences of 1-2 absolute pass@1 points decide framings of “matches” vs “exceeds” competitors.
MATH ENTRY 2: Fill-in-the-middle (FIM) document transformation
- Source: Bavarian et al. 2022 9 ; adopted by Code Llama, StarCoder, StarCoder 2, and DeepSeek-Coder-V2-Lite.
- What it is: A data-side transformation that turns a left-to-right code document into an infilling training example by moving a randomly-selected middle span to the end.
- Formal definition: Given a document , sample two split points uniformly such that . Define prefix , middle , suffix . With probability , replace the document with the PSM-mode training sequence
or, with equal probability among FIM-transformed documents, the SPM-mode sequence
The model is trained left-to-right on these reordered sequences with the standard cross-entropy loss; no objective change is needed.
-
Each term:
- are token sequences (variable length).
- are four sentinel tokens added to the tokenizer.
- is the per-document FIM rate. Code Llama uses 0.9; StarCoder, StarCoder 2, and DeepSeek-Coder-V2-Lite use 0.5; DeepSeek-Coder-V2 Full uses 0.
- The split points are sampled uniformly at the character level (per Code Llama and Bavarian) rather than the token level, then snapped to the nearest token boundary.
-
Worked numerical example. Take a tiny code document tokenized to length :
Tokens:
def foo(x): return x + 1 # one-linerStep 1: Sample , (uniformly from with ).
Step 2: Split into tokens 1-4 (“def foo(x):”), tokens 5-8 (” return x +”), tokens 9-12 (” 1 # one-liner”).
Step 3: With probability 0.5 form the PSM sequence:
<PRE> def foo(x): <SUF> 1 # one-liner <MID> return x + <EOT>. The model is trained to predict every token left-to-right, including the middle tokens after the<MID>marker.Step 4: At inference time for an editor autocomplete request with the cursor between
def foo(x):and1 # one-liner, the editor sends<PRE> def foo(x): <SUF> 1 # one-liner <MID>and the model generates the middle until it emits<EOT>. -
Role: Trains the model’s infilling capability without changing the loss function or architecture.
-
Edge cases: Very short documents () can produce empty ; standard implementations skip these. Very high () was explored by Code Llama; the paper reports rate 0.9 as the sweet spot.
-
Novelty:
[Adopted]from Bavarian et al. 9 . -
Why it matters: FIM is the single most reused training trick across the code-LLM literature. Every editor autocomplete deployment in 2026 depends on a model trained with some variant of it.
MATH ENTRY 3: RoPE base-frequency rescaling for long context
- Source: Code Llama Section 2.4 1 .
- What it is: A modification of Rotary Position Embedding that extends the model’s effective context window by increasing the base period of the rotation frequencies.
- Formal definition: The standard RoPE rotation for the -th coordinate pair of a -dimensional attention vector at position uses rotation angles
and rotates the query and key vectors by angle at position . Code Llama increases from the default 10,000 to 1,000,000 during long-context fine-tuning.
-
Each term:
- is the RoPE base frequency. Default 10,000; Code Llama long-context uses 1,000,000.
- is the rotation rate for the -th coordinate pair. Higher means slower rotation for the same .
- is the absolute position of the token in the sequence (up to 100,000 in Code Llama).
- is the head dimension.
-
Worked numerical example. Compare the rotation angle at position for the (fastest) and (slow) coordinate pairs at .
Step 1: For : regardless of . At , the rotation is radians, which wraps around the circle thousands of times; the fast modes are essentially random for very long sequences.
Step 2: For at default : . Rotation at is radians full turns; still wraps.
Step 3: For at Code Llama’s : . Rotation at is radians full turns, much more in the “interpolation” regime where attention can still distinguish nearby positions.
Step 4: The intuition: increasing slows down every coordinate pair’s rotation, pushing the model into a regime where positions thousands of tokens apart still produce distinguishable rotated vectors. With 10,000 gradient steps of fine-tuning on long-context data, the model learns to use those slower modes effectively.
-
Role: Enables Code Llama’s 100K-context window on a model originally trained at 4K.
-
Edge cases: The rescaling alone is not sufficient; without long-context fine-tuning, the model has not seen positions at the new and behaves badly. The paper reports the rescaling + fine-tuning combination as the working recipe.
-
Novelty:
[Adapted]from concurrent work on RoPE base-frequency scaling; Code Llama’s specific 10,000 → 1,000,000 jump and the staged fine-tuning are the contribution. -
Why it matters: This is the single most reproducible long-context-extension recipe in the open-weights literature. Llama 3 later adopts a similar (smaller) base-frequency increase to 500,000 2 .
MATH ENTRY 4: Grouped-query attention (GQA) memory accounting
- Source: StarCoder 2 Section 3 5 ; mechanism from Ainslie et al. 15 .
- What it is: An attention variant where , so multiple query heads share each key/value head. Reduces KV-cache memory at inference.
- Formal definition: Standard multi-head attention with query, key, and value heads each of dimension stores a KV cache of size
where is the number of layers, is the batch size, is the sequence length, and bytes depends on precision (2 for fp16/bf16). MQA collapses to . GQA keeps in between:
The ratio is the “group size”. StarCoder 2 7B uses (group size 8); StarCoder 2 15B uses (group size 12).
-
Each term:
- is the number of Transformer layers (e.g., 40 for StarCoder 2 15B).
- is the number of query heads per layer.
- is the number of key/value heads per layer.
- is the dimension of each head (e.g., 128).
- is the inference batch size.
- is the current sequence length (grows token by token during decoding).
-
Worked numerical example. Compare KV-cache memory at tokens, batch , bf16 precision for StarCoder (MQA: , , ) vs StarCoder 2 15B (GQA: , , ).
Step 1: StarCoder MQA: bytes MB.
Step 2: StarCoder 2 GQA: bytes MB.
Step 3: A hypothetical MHA configuration with (one per query head) would use MB, 12x more than GQA, 48x more than MQA.
Step 4: Interpretation. GQA gives up the absolute memory minimum of MQA in exchange for clearer quality gains; the 4x cost over MQA at long context is acceptable on inference hardware sized for 15B-class models.
-
Role: Determines the maximum batch size and context length achievable on a given inference GPU.
-
Edge cases: When KV cache exceeds GPU memory, the model swaps to CPU or fails. The MQA-to-GQA shift is the single most impactful recent change for long-context inference economics.
-
Novelty:
[Adopted]from Ainslie et al. 15 . -
Why it matters: StarCoder 2’s quality improvement over StarCoder at smaller size is partly attributed to GQA, although the underlying data (Stack v2) is also bigger; the paper does not fully isolate the contribution.
MATH ENTRY 5: Mixture-of-experts gating (DeepSeek-Coder-V2 Full)
- Source: DeepSeek-V2 14 (V2-Coder defers to V2 for MoE details).
- What it is: The routing function that decides which experts process each token in the MoE feed-forward layers.
- Formal definition: For input token representation and routed experts each a feed-forward network , plus shared experts, the gating distribution over routed experts is
with . The MoE output sums the top- routed experts (weighted by their gating value) plus all shared experts:
DeepSeek-V2’s 236B configuration: routed, shared, .
-
Each term:
- is the token representation entering the MoE layer; for DeepSeek-V2 236B.
- is the gating projection; shape .
- holds softmax probabilities over routed experts.
- returns indices of the largest gating values.
- are shared experts always invoked.
-
Worked numerical example. Take , , , .
Step 1: For one token, compute , a length-160 vector of routing logits. Softmax produces a probability distribution over the 160 routed experts.
Step 2: Suppose the top 6 routed experts have indices with gating values (sum ; the remaining 154 experts share the other 0.28 mass).
Step 3: Compute the 6 routed-expert FFNs and the 2 shared-expert FFNs on , sum them weighted by gating value (for routed experts) and unweighted (for shared).
Step 4: Active parameter accounting. Each FFN has roughly parameters (gate, up, and down projections in SwiGLU). With per expert: each FFN M parameters. Per token: parameters active per MoE layer. Across 60 MoE layers: active in MoE layers alone, plus dense attention contributions, totalling the reported 21B active for the 236B model.
-
Role: The mechanism by which DeepSeek-Coder-V2 Full activates only 21B of its 236B parameters per token.
-
Edge cases: Without auxiliary load-balancing losses, routing tends to collapse; a few experts get all tokens, the rest starve. DeepSeek-V2 uses a specific device-limited routing strategy plus auxiliary losses.
-
Novelty:
[Adapted]from Switch Transformer and Mixtral lineage; the shared-experts + routed-experts split is a DeepSeekMoE contribution. -
Why it matters: The MoE design is the architectural reason DeepSeek-Coder-V2 can reach GPT-4o-class quality at 21B active parameters; without it, a 21B dense code model does not reach those numbers.
Figure from StarCoder (arXiv:2305.06161), reproduced for editorial coverage of training-checkpoint pass@1 progression.
7. Algorithmic contributions
This section walks through three algorithms shared across the four papers: FIM training-time document transformation, pass@k evaluation, and MoE token routing.
ALGORITHM ENTRY 1: FIM document transformation at training time
- Source: Bavarian et al. 9 , instantiated identically in Code Llama, StarCoder, StarCoder 2, and DeepSeek-Coder-V2-Lite.
- Purpose: Convert a left-to-right code document into an infilling training example with probability .
- Inputs: Document as a string; tokenizer; sentinel tokens
<PRE>, <SUF>, <MID>, <EOT>; FIM rate . - Outputs: A token sequence ready for left-to-right next-token-prediction training.
Pseudocode.
def fim_transform(document, tokenizer, r_fim=0.5):
# 1. With probability (1 - r_fim) leave document unchanged.
if random() > r_fim:
return tokenizer.encode(document)
# 2. Sample two split points uniformly on the character axis.
L = len(document)
i = randint(0, L)
j = randint(0, L)
if i > j:
i, j = j, i
# 3. Slice into prefix, middle, suffix.
P = document[:i]
M = document[i:j]
S = document[j:]
# 4. Choose PSM or SPM with equal probability.
if random() < 0.5:
# PSM mode
seq = [PRE_TOK] + encode(P) \
+ [SUF_TOK] + encode(S) \
+ [MID_TOK] + encode(M) + [EOT_TOK]
else:
# SPM mode
seq = [PRE_TOK, SUF_TOK] + encode(S) \
+ [MID_TOK] + encode(P) + encode(M) + [EOT_TOK]
return seq-
Hand-traced example on minimal input. Take
document = "abcdefgh"(8 characters) with (force FIM).Step 1: Random check passes (forced).
Step 2: Sample ().
Step 3:
"ab","cdef","gh".Step 4: PSM coin lands heads. Output sequence:
[<PRE>, t("ab"), <SUF>, t("gh"), <MID>, t("cdef"), <EOT>]wheret(s)is the tokenization of strings. The model is trained on this exact left-to-right sequence with the standard cross-entropy loss; nothing else changes. -
Complexity: per document for slicing and tokenization; identical to the non-FIM baseline.
-
Hyperparameters: (0.5 in StarCoder/StarCoder 2/DeepSeek-Coder-V2-Lite; 0.9 in Code Llama); PSM/SPM mix (50/50 in StarCoder; 50/50 in Code Llama; PSM-only in DeepSeek-Coder-V2-Lite). StarCoder 2 adds a repo-level outer selection (50% of repositories selected for FIM).
-
Failure modes: If sentinel tokens collide with naturally-occurring strings in the corpus, the model can confuse infilling with regular generation. All four papers add genuinely new vocabulary entries for the sentinels to avoid this.
-
Novelty:
[Adopted]from Bavarian et al. 9 .
ALGORITHM ENTRY 2: pass@k evaluation harness
- Source: Chen et al. 2021 10 , with samples per problem as the community standard.
- Purpose: Compute pass@k unbiasedly given a budget of generated samples per problem.
Pseudocode.
def eval_pass_at_k(model, problems, n=200, k=1, temp=0.2):
scores = []
for q, tests in problems:
# 1. Sample n completions at temperature `temp`.
samples = [model.sample(q, temp=temp) for _ in range(n)]
# 2. Run each sample in a sandbox against the unit tests.
c = 0
for s in samples:
try:
if run_in_sandbox(s, tests, timeout=10):
c += 1
except Exception:
pass # syntax error, timeout, etc.
# 3. Compute per-problem pass@k contribution.
if n - c < k:
score = 1.0
else:
score = 1.0 - comb(n - c, k) / comb(n, k)
scores.append(score)
return mean(scores)-
Hand-traced example. Two HumanEval problems, .
Step 1: Problem 1: model samples 4 completions; sandbox finds 3 pass tests. . , so per-problem score = 1.0.
Step 2: Problem 2: model samples 4 completions; sandbox finds 1 passes. , . Score .
Step 3: pass@2 = on this two-problem set.
-
Complexity: where is sample-cost; sandbox execution adds .
-
Hyperparameters: (200 standard); (1, 10, 100 reported); (0.2 for pass@1, higher for higher ); sandbox timeout (typically 10s per sample).
-
Failure modes: Sandbox infinite loops not caught by timeout pollute the score; tests that depend on system time or networking fail spuriously. The community-maintained
evalplusharness 12 adds additional tests to catch over-specified solutions. -
Novelty:
[Adopted]from Codex.
ALGORITHM ENTRY 3: MoE top-k routing forward pass
- Source: DeepSeek-V2 14 , applied unchanged in DeepSeek-Coder-V2 Full.
- Purpose: Route each token through the top- routed experts plus shared experts.
Pseudocode.
def moe_forward(x, W_g, routed_experts, shared_experts, k=6):
# x: token representations, shape (B, T, d)
# W_g: gating projection, shape (E, d)
# routed_experts: list of E FFN modules
# shared_experts: list of E_s FFN modules
# 1. Compute gating logits and softmax over routed experts.
logits = x @ W_g.T # shape (B, T, E)
gates = softmax(logits) # shape (B, T, E)
# 2. Pick top-k routed experts per token.
topk_vals, topk_idx = topk(gates, k, dim=-1) # (B, T, k)
# Optional: renormalize chosen gating weights to sum to 1
topk_vals = topk_vals / topk_vals.sum(-1, keepdim=True)
# 3. Initialize output to sum of shared experts.
y = sum(fnn(x) for fnn in shared_experts) # shape (B, T, d)
# 4. Dispatch tokens to routed experts and gather.
for e_idx, expert in enumerate(routed_experts):
# Mask of tokens for which this expert is in their top-k.
mask = (topk_idx == e_idx).any(-1) # (B, T)
if not mask.any():
continue
# Compute expert output on the selected tokens.
x_selected = x[mask] # (N_e, d)
out = expert(x_selected) # (N_e, d)
# Multiply by the relevant gating weight.
weights = gather_gating_weight(topk_vals, topk_idx, e_idx, mask)
y[mask] += weights[:, None] * out
return y-
Hand-traced example. Take routed experts, , shared, batch , sequence , hidden .
Step 1: has shape (1, 3, 8). Gating logits has shape (1, 3, 4).
Step 2: Suppose after softmax, the per-token gating distributions are:
- Token 1:
- Token 2:
- Token 3:
Step 3: Top- selections:
- Token 1 → experts with weights , renormalised .
- Token 2 → experts with weights , renormalised .
- Token 3 → experts with weights , renormalised .
Step 4: Shared expert computes on all 3 tokens: , shape (1, 3, 8).
Step 5: Expert 0 fires on tokens 1 and 3; expert 1 on tokens 1 and 2; expert 2 on tokens 2 and 3; expert 3 on no tokens (saves compute). Each expert produces output for its assigned tokens, weighted and accumulated into .
Step 6: Token 1’s final output is , and analogously for tokens 2 and 3.
-
Complexity: Per-token compute is for the gating projection. The gating projection cost is small relative to expert FFNs; the bottleneck is expert FFN compute.
-
Hyperparameters: . DeepSeek-V2 236B: routed, shared, .
-
Failure modes: Without load-balancing losses, expert utilisation collapses (a few experts get all tokens). DeepSeek-V2 uses a device-limited routing strategy plus auxiliary balancing losses.
-
Novelty:
[Adapted]from Switch Transformer / GShard / Mixtral; the shared-experts addition is a DeepSeekMoE contribution.
Figure from StarCoder 2 (arXiv:2402.19173), reproduced for editorial coverage of The Stack v2 composition.
8. Specialised design contributions
8A. LLM / prompt design
Not directly applicable to the pretraining stage of any of the four papers. Code Llama and DeepSeek-Coder-V2 ship instruction-tuned variants. The Code Llama Instruct recipe 1 uses self-instruct: the model generates programming problems with reference solutions and unit tests, the unit tests filter for correct solutions, and the filtered (problem, solution) pairs become the instruction-tuning corpus. DeepSeek-Coder-V2-Instruct uses curated SFT followed by GRPO with code-quality rewards. Exact prompt templates and system messages are not fully published in either paper.
8B. Architecture-specific details
| Choice | Code Llama | StarCoder | StarCoder 2 | DeepSeek-Coder-V2 |
|---|---|---|---|---|
| Architecture | Dense decoder | Dense decoder | Dense decoder | MoE decoder |
| Attention | MHA → GQA (70B) | MQA | GQA | MLA (latent) |
| KV heads / query heads | 64/64 (7B) → 8/64 (70B) | 1/48 | 2/24 (3B), 4/32 (7B), 4/48 (15B) | MLA compresses to latent KV |
| Activation | SwiGLU | GeLU-tanh-approx | GeLU-tanh-approx | SwiGLU |
| Position encoding | RoPE ( 10K → 1M) | Learned absolute | RoPE | RoPE |
| Norm | RMSNorm | LayerNorm | RMSNorm | RMSNorm |
| Tokenizer vocab | 32,016 (Llama 2 + 4 FIM sentinels) | 49,152 | 49,152 | 100,000+ (DeepSeek-V2) |
8C. Training specifics
| Choice | Code Llama 34B | StarCoder | StarCoder 2 15B | DeepSeek-Coder-V2 (Full) |
|---|---|---|---|---|
| Total tokens | 500B + 100B long-context | ~1T | 913.2B unique + long-context | 6T continued (on V2 base) |
| Hardware | A100s (not fully specified) | 512 × A100 80GB | A100s/H100s mixed | H800s (DeepSeek standard) |
| Batch size | 4M tokens (long-context phase smaller) | 4M tokens | ~4M tokens | Inherited from V2 |
| Context (pretrain → long-ctx) | 4K → 16K → 100K | 8K | 4K → 16K (sliding 4K) | 16K → 128K |
| FIM rate | 0.9 (PSM/SPM 50/50) | 0.5 (PSM/SPMv2 50/50) | 0.5 repo-level | 0.5 (Lite only, PSM-only) |
8D. Inference / deployment specifics
Code Llama 70B Instruct ships with the largest inference footprint among the dense models (~140GB at fp16). Serving at long context relies on the RoPE rescaling; the paper reports a ~2 BLEU drop on short sequences from long-context fine-tuning, the documented trade-off. StarCoder’s MQA produces a small KV cache by design, a strong choice for serving on a single-GPU budget. DeepSeek-Coder-V2 Full at 236B total parameters requires a multi-GPU host for serving even with the 21B active count, because the full expert bank must reside in memory; the Lite variant at 16B total is the single-GPU option.
9. Experiments and results
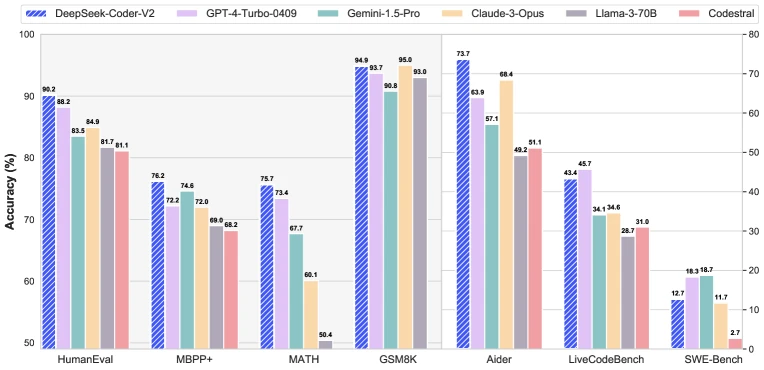
Figure 1 from DeepSeek-Coder-V2 (arXiv:2406.11931), reproduced for editorial coverage of the closed-source-parity benchmark comparison.
Datasets. HumanEval (164 hand-curated Python problems) 10 , MBPP (974 short Python problems) 11 , MultiPL-E (HumanEval translated to 18+ languages) 18 , HumanEval+ and MBPP+ (EvalPlus extensions with additional unit tests) 12 , DS-1000 (data-science Python from Stack Overflow), LiveCodeBench (rolling contamination-free benchmark) 13 , USACO (competitive programming).
Baselines. Each paper compares against the prior generation of open-weights code models (CodeGen, InCoder, SantaCoder for StarCoder; StarCoder for Code Llama; Code Llama for StarCoder 2; GPT-4 Turbo, GPT-4o, Claude 3 Opus, Gemini 1.5 Pro for DeepSeek-Coder-V2).
Headline HumanEval pass@1 results (greedy decoding except where noted).
| Model | Year | Size (active / total) | HumanEval pass@1 |
|---|---|---|---|
| Codex (code-cushman-001) | 2021 | undisclosed | 33.5% 10 |
| StarCoderBase | 2023 | 15.5B / 15.5B | 30.4% 3 |
| StarCoder (Python-finetuned) | 2023 | 15.5B / 15.5B | 33.6% 3 |
| Code Llama 7B | 2023 | 7B / 7B | 33.5% 1 |
| Code Llama 13B | 2023 | 13B / 13B | 36.0% 1 |
| Code Llama 34B | 2023 | 34B / 34B | 48.8% 1 |
| Code Llama 70B Instruct | 2024 | 70B / 70B | 67.8% 1 |
| StarCoder2-3B | 2024 | 3B / 3B | 31.7% 5 |
| StarCoder2-7B | 2024 | 7B / 7B | 35.4% 5 |
| StarCoder2-15B | 2024 | 15B / 15B | 46.3% 5 |
| DeepSeek-Coder-V2-Lite Instruct | 2024 | 2.4B / 16B | 81.1% 7 |
| DeepSeek-Coder-V2 Instruct | 2024 | 21B / 236B | 90.2% 7 |
| GPT-4o (contemporaneous baseline) | 2024 | undisclosed | 91.0% 7 |
Table reproduces headline pass@1 results across the four reviewed papers and their contemporaneous baselines. Sources cited per row. Code Llama and Code Llama Instruct values from Tables 2 and Section 3 of arXiv:2308.12950. StarCoder values from Section 6 of arXiv:2305.06161. StarCoder 2 values from arXiv:2402.19173 main results table. DeepSeek-Coder-V2 values from arXiv:2406.11931 main results.
MBPP and MBPP+ pass@1 (selected rows).
| Model | MBPP pass@1 | MBPP+ pass@1 |
|---|---|---|
| Code Llama 34B | 55.0% 1 | not reported |
| Code Llama 70B Instruct | 62.2% 1 | not reported |
| StarCoder2-15B | 66.2% 5 | 53.1% 5 |
| DeepSeek-Coder-V2 Instruct | 89.4% 7 | 76.2% 7 |
| GPT-4o | 87.6% 7 | 73.5% 7 |
Multilingual (MultiPL-E) and bug-fix (HumanEvalFix). StarCoder 2-15B reports best results on 16/18 languages versus comparable-sized open models 5 . On HumanEvalFix, StarCoder2-15B reaches 38.7% in issue-format prompting, leveraging the Stack v2 GitHub-Issues pretraining 5 .
LiveCodeBench and USACO (DeepSeek-Coder-V2 only). LiveCodeBench: DeepSeek-Coder-V2 43.4% vs GPT-4 Turbo 45.7% 7 . USACO: DeepSeek-Coder-V2 12.1% vs GPT-4o 18.8% 7 . The competitive-programming gap is larger than the HumanEval/MBPP gap, which the paper acknowledges 7 .
Ablations. Code Llama’s FIM-rate sweep 1 reports rates 0.0, 0.5, 0.9, 1.0 with rate 0.9 chosen as the documented sweet spot. StarCoder 2 reports an instruction-format vs issue-format prompting comparison on HumanEvalFix 5 . DeepSeek-Coder-V2 ablates Lite (FIM-trained) vs Full (no-FIM); the Full model loses infilling capability as expected.
Independent benchmark cross-checks for SOTA claims. DeepSeek-Coder-V2’s HumanEval-parity claim has been independently re-evaluated on EvalPlus 12 and LiveCodeBench 13 , both of which place V2 closer to but still below GPT-4o on the more robust evaluation. [Reviewer Perspective] On SWE-bench (an agentic coding benchmark), DeepSeek-Coder-V2-Instruct’s reported numbers trail GPT-4-class systems by 20+ absolute points, a gap the paper itself flags as the area for the next release.
Scope limits. None of the four papers run a controlled FIM-rate-vs-quality experiment at the larger model size; the Code Llama ablation is at 7B only. The data-mixture choices are similarly observational at the chosen model size.
Evidence audit.
- Strongly supported: pass@1 numbers on HumanEval and MBPP (each paper runs the standard harness; numbers can be reproduced by anyone with the released weights).
- Partially supported: the “outperforms model X” framings depend on the specific harness and decoding settings; different prompt templates produce different rankings.
- Narrow evidence: long-context quality (Code Llama’s 100K context, StarCoder 2’s 16K) is reported on a small set of needle-in-a-haystack-style probes; downstream task quality at full context is undertested.
10. Technical novelty summary
| Component | Type | Novelty level | Justification | Source |
|---|---|---|---|---|
| RoPE 10K → 1M for 100K context | Architecture / training | Incrementally novel | Specific recipe Code Llama publishes; concurrent work explored similar ideas | Code Llama Sec 2.4 |
| FIM rate 0.9 sweet spot | Training | Incrementally novel | Empirical refinement of Bavarian et al.’s default-0.5 recommendation | Code Llama Sec 2.3 |
| Repo-level FIM nesting | Training | Combination novel | Repository-coherence axis added to FIM transformation | StarCoder 2 Sec 4 |
| MQA + 8K context + open data | Combination | Combination novel | First-of-kind 15B open-data code model with MQA | StarCoder Sec 3 |
| 4x-larger Stack v2 + GQA | Combination | Incrementally novel | Bigger data + standard GQA shift | StarCoder 2 |
| MoE for code (236B/21B) | Architecture | Combination novel | First open-weights MoE code model at this scale | DeepSeek-Coder-V2 Sec 2 |
| Code-and-math continued pretraining mixture 60/10/30 | Data | Incrementally novel | Specific mixture choice rather than general principle | DeepSeek-Coder-V2 |
| GRPO post-training for code | Training | Combination novel | RL post-training applied to a code model | DeepSeek-Coder-V2 |
Single most novel contribution per paper.
- Code Llama: The RoPE 10K → 1M rescaling combined with the 10,000-step long-context fine-tuning recipe is the most reproducible and most reused contribution; subsequent papers (Llama 3, others) explicitly adopt variants.
- StarCoder: The first frontier-class open-data code model with full attribution and PII-redaction tooling; the dataset (The Stack) is the most-reused artifact.
- StarCoder 2: The MQA → GQA shift at the open-data tier and the repo-level FIM nesting.
- DeepSeek-Coder-V2: The demonstration that an MoE code model continued from a general-purpose MoE base reaches frontier-closed-model quality on HumanEval, at active-parameter counts compatible with single-host serving.
What the papers do NOT claim novel. Decoder-only Transformer, BPE tokenization, RoPE itself (Code Llama and StarCoder 2 adopt it from prior work), FIM as an objective (all four adopt from Bavarian et al.), HumanEval / MBPP / MultiPL-E as benchmarks (all adopted), and the broad pretraining recipe (cross-entropy on shuffled documents).
11. Situating the work
Figure 2 from DeepSeek-Coder-V2 (arXiv:2406.11931), reproduced for editorial coverage of the 128K Needle-In-A-Haystack long-context evaluation.
What prior work did. Codex 10 established HumanEval; CodeGen, InCoder, and SantaCoder produced open code models in the 6B-16B range trailing Codex; Llama 2 base shipped strong general performance but only ~4.5% code by token count. Bavarian et al. 9 introduced FIM with a “rate 0.5 is fine for free” recommendation.
What the four papers change conceptually.
- Code Llama establishes that specialization from a strong general base is competitive with training from scratch, and ships the most reproducible long-context recipe to date.
- StarCoder establishes that open-data code models are a viable category, with the BigCode tooling for attribution and PII redaction.
- StarCoder 2 shows that the open-data substrate, scaled 4x and combined with GQA, closes most of the remaining gap to Code Llama at smaller parameter counts.
- DeepSeek-Coder-V2 breaks the open-vs-closed parity barrier on the standard pass@1 metric.
Contemporaneous related papers.
- DeepSeek-V2 technical report (arXiv:2405.04434, May 2024) 14 . The DeepSeek-Coder-V2 paper’s parent; V2-Coder is a continuation of V2 weights. The MoE configuration (160 routed experts, 2 shared, top-6 routing) and the MLA attention mechanism are inherited unchanged. [Analysis] Treating V2-Coder as a specialization of V2 (not a from-scratch code model) is the appropriate framing.
- Qwen2.5-Coder (Alibaba, late 2024). Not in this review but the closest contemporary: a specialization track from Qwen2.5 to a code family at 0.5B-32B, reaching competitive HumanEval numbers via a recipe close to Code Llama’s. [External comparison] The Qwen2.5-Coder release tightens the open-weights frontier further but does not change the architectural picture the four reviewed papers establish.
- Mistral / Mixtral lineage. Not specialized for code but reaches respectable code performance via pure scale; the comparison the StarCoder 2 paper draws is Code Llama 34B vs StarCoder 2 15B at similar pass@1, with Mixtral as an indirect baseline.
[Reviewer Perspective] Strongest skeptical objection. HumanEval is a 164-problem benchmark dating to 2021. By mid-2024, “we reached HumanEval parity” reads less like a research result and more like a data-contamination story. DeepSeek-Coder-V2’s 90.2% on HumanEval and 43.4% on LiveCodeBench (a contamination-free rolling benchmark) suggests that approximately half the headline HumanEval gain over earlier models is benchmark-specific. The paper’s USACO and SWE-bench numbers reinforce this; the agentic-task gap to closed models remains large.
[Reviewer Perspective] Strongest author-side rebuttal. The HumanEval contamination concern is genuine but not unique to DeepSeek-Coder-V2; every model after ~2023 trains on data plausibly containing HumanEval problems by content. The relative ordering among open models (StarCoder 2-15B at 46.3% vs DeepSeek-Coder-V2 at 90.2%) is still meaningful because both saw similar contamination probability. Treating the gap as evidence of capability difference (rather than memorisation difference) survives this critique, even if the absolute numbers do not.
What remains unsolved. (a) Agentic coding, meaning multi-step tool-using code generation evaluated end-to-end on SWE-bench-class tasks. (b) Genuine contamination-controlled evaluation at scale. (c) Long-context quality at the contexts these models claim (100K for Code Llama, 128K for DeepSeek-Coder-V2-Full). (d) FIM-rate-vs-quality at larger model sizes.
Three future research directions.
- Controlled FIM-rate ablations at 30B+ scale: every reviewed paper either reuses a previous-paper choice or runs the ablation only at small scale. [Analysis] A clean rate sweep at 30B with held-out infilling and code-completion evaluations would resolve the StarCoder-vs-Code-Llama rate disagreement (0.5 vs 0.9).
- Pure RL post-training for code models: DeepSeek-Coder-V2 uses GRPO; competing approaches (PPO with executable feedback, DPO over compile/test pairs) deserve direct comparison.
- Long-context evaluation harnesses for code: current benchmarks evaluate context up to ~4K. A standard long-context code benchmark with realistic repository-scale tasks is missing.
12. Critical analysis
Strengths (with concrete evidence).
- Code Llama: the FIM-rate ablation Table 7 is one of the cleanest such ablations in the open literature; the 100K-context recipe is reproducible from the paper alone.
- StarCoder: the open-data attribution and PII-redaction tooling is itself a research contribution beyond the model; The Stack v1.2 has been reused by dozens of subsequent papers.
- StarCoder 2: the per-language token counts in The Stack v2 table are unusually detailed and useful for downstream work; the GQA configuration is fully disclosed.
- DeepSeek-Coder-V2: the LiveCodeBench-included evaluation is appropriately honest about where the model trails closed competitors.
Weaknesses stated by the authors.
- Code Llama: long-context fine-tuning induces up to a 2-BLEU drop on short sequences 1 .
- StarCoder: low-resource-language performance is uneven; some languages regress between checkpoints despite overall scale gains 3 .
- StarCoder 2: the 7B variant underperforms relative to its size (sits between 3B and 15B but does not interpolate cleanly) 5 . The authors acknowledge uncertainty about the cause.
- DeepSeek-Coder-V2: significant gap to GPT-4 Turbo and GPT-4o on instruction following and agentic tasks (SWE-bench) 7 .
Weaknesses not stated or understated.
- [Reviewer Perspective] HumanEval contamination probability is high for all post-2023 models trained on broad GitHub crawls. None of the four papers report decontamination experiments at the level of, say, the Llama 3 paper.
- [Reviewer Perspective] Code Llama’s data sources are not enumerated; the 85%/8%/7% mixture is reported without the underlying dataset hashes or license audit that StarCoder’s Stack-based corpus provides. The open-weights claim is real, but the open-data claim is not.
- [Reviewer Perspective] DeepSeek-Coder-V2-Lite ships with FIM; DeepSeek-Coder-V2 Full does not. This means the better-quality variant cannot be used for editor autocomplete out of the box. The paper does not discuss this design choice.
Reproducibility check.
| Artefact | Code Llama | StarCoder | StarCoder 2 | DeepSeek-Coder-V2 |
|---|---|---|---|---|
| Code | Released (FAIR / Meta GitHub) | Released (bigcode-project on GitHub + HF) | Released (bigcode-project) | Released (deepseek-ai on GitHub + HF) |
| Data | Not released (Meta-curated corpus) | Released (The Stack v1.2 on HF) | Released (The Stack v2 on HF) | Not released (GitHub + CommonCrawl + math, undisclosed mix) |
| Hyperparameters | Fully reported | Fully reported | Fully reported | Partially reported (defers to V2 for MoE details) |
| Compute | Reported (GPU-hours partial) | Fully reported (320K A100 hours) | Fully reported (with kgCO2eq) | Partially reported (active-parameter count only) |
| Trained weights | Released (HF: meta-llama/CodeLlama-*) | Released (HF: bigcode/starcoder*) | Released (HF: bigcode/starcoder2-*) | Released (HF: deepseek-ai/DeepSeek-Coder-V2-*) |
| Evaluation harness | EvalPlus, official Codex harness | Official + EvalPlus | EvalPlus | Official + LiveCodeBench |
| Overall | Partially reproducible (model yes, training run no) | Fully reproducible | Fully reproducible | Partially reproducible (model yes, data no) |
Methodology disclosure (callout).
Methodology
- Sample size: HumanEval has 164 problems, MBPP 974, MBPP+ 378 after EvalPlus filtering, LiveCodeBench varies by date cutoff. pass@1 uses samples per problem at temperature 0.2 (community standard).
- Evaluation set: HumanEval and MBPP are widely shared; contamination probability is non-zero for all post-2023 models. HumanEval+ and LiveCodeBench 13 are contamination-mitigation extensions.
- Baselines: Each paper reports against the relevant prior-generation open and closed competitors; DeepSeek-Coder-V2 is the only one of the four to compete directly against frontier closed models (GPT-4o, Claude 3 Opus, Gemini 1.5 Pro).
- Hardware/compute: Reported in full for StarCoder/StarCoder 2 (512 A100 80GB / mixed A100+H100); reported partially for Code Llama (compute order of magnitude but not GPU-hours fully); reported partially for DeepSeek-Coder-V2 (active-parameter count and training token total but not full hardware budget).
Generalisability. All four pipelines generalise to language families adjacent to Python and JavaScript (the two best-represented in HumanEval and MBPP-style benchmarks). MultiPL-E provides evidence that the models also handle Java, C++, Rust, Go, and similar mainstream languages at usable pass@1. Low-resource languages (Julia, Lua, R) and domain-specific languages (SQL, Verilog) trail substantially. Generalisability to agentic / multi-step code generation is the open question across all four (see Section 11).
Assumption audit.
- The “cross-entropy on code predicts pass@1” assumption breaks visibly on the more recent contamination-controlled benchmarks. The four reviewed papers were written when this assumption was largely tenable; subsequent benchmark releases (LiveCodeBench, SWE-bench) make it weaker.
- The “FIM rate 0.5 is fine” Bavarian et al. recommendation survives empirically across StarCoder, StarCoder 2, and DeepSeek-Coder-V2-Lite; only Code Llama deviates to 0.9. No paper reports both rates at the same model size.
- The “MoE total parameters ≠ active parameters” accounting is honest in DeepSeek-Coder-V2; the comparison-to-dense-Code-Llama-34B framing is fair (similar active-parameter count).
What would make each paper significantly stronger.
- Code Llama: A controlled FIM-rate ablation at 34B (matching the 7B ablation) and a public data manifest for the 500B-token corpus.
- StarCoder: A larger MultiPL-E sweep covering low-resource languages with explicit per-language quality reporting.
- StarCoder 2: An explanation for the 7B-underperforms-its-size finding, which is currently flagged but not diagnosed.
- DeepSeek-Coder-V2: A decontamination experiment isolating the HumanEval performance from contamination risk, plus a public data manifest for the 6T-token corpus.
13. What is reusable for a new study
REUSABLE COMPONENT 1: The FIM document-transformation function.
- What it is: The 50/50 PSM/SPM document split with sentinel tokens.
- Why worth reusing: Cheap (data-side only, no architecture change), well-validated across four independent papers and one origin (Bavarian et al.).
- Preconditions: Tokenizer with four free sentinel slots; left-to-right pretraining loop.
- What would change in a new setting: Choice of (default 0.5; raise to 0.9 only if infilling is the primary product target).
- Risks: Sentinel-token collision with corpus content if vocabulary not extended properly.
REUSABLE COMPONENT 2: The Stack v1.2 / v2 dataset and BigCode attribution tooling.
- What it is: The permissively-licensed code corpus with built-in opt-out mechanism and PII redaction pipeline.
- Why worth reusing: The most defensible data substrate for a code-LLM project subject to license scrutiny.
- Preconditions: Acceptance of permissive-license-only constraint (excludes GPL-licensed code, which can be legally fraught).
- What would change in a new setting: Probably nothing; the dataset is the artifact.
- Risks: Per-language coverage is uneven; supplementation needed for niche languages.
REUSABLE COMPONENT 3: The Code Llama RoPE rescaling + long-context fine-tuning recipe.
- What it is: Increase RoPE base from 10K to 1M; fine-tune for ~10K gradient steps on long-context data.
- Why worth reusing: Cheapest documented method for extending context far beyond pretraining window.
- Preconditions: Model uses RoPE; budget for the fine-tuning steps.
- What would change in a new setting: Target context length determines the new ; longer contexts need higher and more fine-tuning steps.
- Risks: Short-sequence quality regresses by 1-2 BLEU points (Code Llama documents this).
REUSABLE COMPONENT 4: The StarCoder 2 sliding-window-4096 over 16K-context training.
- What it is: Train with effective attention window of 4K within a 16K context; memory cost scales with the window, not the context.
- Why worth reusing: Memory-cheap path to medium-long context.
- Preconditions: Attention implementation that supports sliding window (FlashAttention-2 or similar).
- Risks: Long-range dependencies beyond the window are not directly trained; downstream long-context quality is lower than a full-attention 16K model.
REUSABLE COMPONENT 5: The DeepSeek-Coder-V2 continued-pretraining-from-MoE-base recipe.
- What it is: Continued pretraining of an existing strong MoE base on a code-and-math heavy mixture.
- Why worth reusing: The cheapest path to a frontier-class code model is to continue from a frontier general-purpose model.
- Preconditions: Strong open MoE base (in 2026, DeepSeek-V3, Mixtral 8x22B, Qwen2.5-MoE).
- Risks: The base model’s biases carry over; if the base lacks code in its pretraining, continued pretraining alone cannot fully recover.
Dependency map. FIM (REU1) is independent of the others and applies to any pretraining run. The Stack (REU2) supplies data; FIM applies to that data. RoPE rescaling (REU3) requires a RoPE-using architecture and is independent of FIM. Sliding window (REU4) is an alternative to REU3 with different trade-offs. Continued-pretraining (REU5) is a meta-recipe orchestrating REU1+REU2+REU3 atop an existing MoE base.
Recommendation. [Analysis] For a new code-LLM project starting in 2026: REU2 (The Stack v2) and REU5 (continued pretraining from a strong MoE base) are the highest-value reusable components, in that order. REU1 (FIM) is essential but commoditised. REU3 vs REU4 is a serving-target choice (very long context → REU3; medium-long context with memory budget → REU4).
14. Known limitations and open problems
Limitations explicitly stated by the authors.
- Code Llama: Short-sequence BLEU regression from long-context fine-tuning; instruction-tuned variants show small regressions on some benchmarks due to safety emphasis; false-refusal rate non-trivial.
- StarCoder: Low-resource language performance variance; some languages (notably R) regressed between checkpoints.
- StarCoder 2: The 7B variant underperforms relative to its size; cause uncertain.
- DeepSeek-Coder-V2: Significant gap to GPT-4o on instruction-following and on agentic benchmarks like SWE-bench; the paper frames this as the area for next release.
Limitations not stated.
- [Reviewer Perspective] HumanEval and MBPP contamination probability is not reported by any of the four papers at the standard of recent frontier-model technical reports. LiveCodeBench numbers (DeepSeek-Coder-V2 only) provide indirect evidence.
- [Analysis] None of the four papers reports a controlled FIM-rate ablation at full target model size; the FIM-rate choice is the most consequential single hyperparameter for editor-deployment use cases and remains under-ablated.
- [Reviewer Perspective] Code Llama’s data audit is sparse relative to StarCoder’s; license posture is “model open-weights, data closed”.
- [Analysis] DeepSeek-Coder-V2’s MoE routing details (expert count, top-k, balancing losses) are documented in the parent V2 paper rather than the V2-Coder paper, requiring readers to cross-reference for full architectural understanding.
Technical root cause of each.
- Contamination: GitHub crawls inevitably contain HumanEval-like content. Mitigation requires hash-based decontamination at the problem-statement level, which is harder than string-match decontamination.
- FIM-rate under-ablation: Each ablation costs a full training run; compute economics rather than oversight is the cause.
- Open-data gap: Meta’s corpus choice is a strategic decision; the cost of switching to The Stack is in lost data scale.
Open problems left behind.
- Long-context code-generation benchmark at realistic repo scale.
- Decontamination-aware code benchmarking with rolling problem releases.
- Joint optimisation of FIM rate and model size with controlled compute.
- Open MoE-base code specialization (DeepSeek-Coder-V2 is the only public example; the question of how the recipe generalises to Mixtral or Qwen-MoE bases is open).
What a follow-up paper would need to solve to address the most critical limitation. The single most critical limitation is the contamination-controlled evaluation gap. A follow-up paper would (a) release a contemporaneously-collected problem set with hash-level guarantees of non-overlap with public training data, (b) re-evaluate the four families head-to-head, and (c) report the contamination-adjusted ranking. LiveCodeBench is the closest contemporary to this; a paper that consolidates the contamination-controlled evaluation across all four families with consistent methodology is the missing artefact.
How this article reads at three depths
For the curious high-school reader. This article walks through four papers that show how computers learned to write code much better between 2023 and 2024. The key tricks are: train on lots of code from public GitHub, teach the model to fill in missing middle pieces of code (fill-in-the-middle), and use clever tricks so the model can see entire files at once. By 2024 the best open model was almost as good at writing short Python functions as the best secret model from OpenAI.
For the working developer or ML engineer. The four papers map out the recipe space for building a code model. Code Llama (specialize from a general LLM, FIM rate 0.9, RoPE rescaling for 100K context). StarCoder + StarCoder 2 (train from scratch on permissive open data, MQA then GQA, sliding window). DeepSeek-Coder-V2 (continue pretraining a general MoE base on code+math, top-6 routing across 160 experts). Pick by: specialize-from-base if you have a good base; train from scratch if open-data licensing matters; go MoE if serving cost matters more than total parameter count. FIM rate 0.5 is the safe default; 0.9 only if infilling is the deployment target. RoPE 10K → 1M is the cheapest long-context extension; sliding window is the memory-cheap medium-context alternative.
For the ML researcher. The novel contributions per paper are narrower than the framings suggest. Code Llama’s RoPE rescaling + 10K-step long-context FT is the most reused recipe across the open-weights frontier; the FIM-rate-0.9 finding is contested (StarCoder 2 and DeepSeek-Coder-V2-Lite both use 0.5). StarCoder’s value is the open-data substrate plus attribution tooling, not its quality at 15B. StarCoder 2 closes the 15B-vs-Code-Llama-34B gap mostly via 4x data and GQA. DeepSeek-Coder-V2’s HumanEval parity claim is partially explained by likely contamination; the LiveCodeBench and USACO numbers are the more credible signal. The most load-bearing untested assumption is that next-token cross-entropy on code predicts agentic code-generation quality; SWE-bench numbers say it doesn’t. A controlled FIM-rate ablation at 30B+ and a contamination-decontaminated head-to-head benchmark are the two missing experiments.
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. Rozière et al. — Code Llama: Open Foundation Models for Code (arXiv:2308.12950, August 2023) (accessed ) ↩
- 2. Code Llama HTML render on ar5iv (used for table extraction) (accessed ) ↩
- 3. Li et al. — StarCoder: may the source be with you! (arXiv:2305.06161, May 2023) (accessed ) ↩
- 4. StarCoder HTML render on ar5iv (accessed ) ↩
- 5. Lozhkov et al. — StarCoder 2 and The Stack v2 (arXiv:2402.19173, February 2024) (accessed ) ↩
- 6. StarCoder 2 HTML render on ar5iv (accessed ) ↩
- 7. DeepSeek-AI — DeepSeek-Coder-V2 (arXiv:2406.11931, June 2024) (accessed ) ↩
- 8. DeepSeek-Coder-V2 HTML render on ar5iv (accessed ) ↩
- 9. Bavarian et al. — Efficient Training of Language Models to Fill in the Middle (arXiv:2207.14255, OpenAI 2022) (accessed ) ↩
- 10. Chen et al. — Evaluating Large Language Models Trained on Code (Codex / HumanEval, arXiv:2107.03374, 2021) (accessed ) ↩
- 11. Austin et al. — Program Synthesis with Large Language Models (MBPP, arXiv:2108.07732) (accessed ) ↩
- 12. Liu et al. — Is Your Code Generated by ChatGPT Really Correct? (HumanEval+ / EvalPlus, arXiv:2305.01210) (accessed ) ↩
- 13. Jain et al. — LiveCodeBench (arXiv:2403.07974, March 2024) (accessed ) ↩
- 14. DeepSeek-AI — DeepSeek-V2 (arXiv:2405.04434, May 2024) (accessed ) ↩
- 15. Ainslie et al. — GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints (arXiv:2305.13245) (accessed ) ↩
- 16. Shazeer — Fast Transformer Decoding: One Write-Head is All You Need (MQA, arXiv:1911.02150) (accessed ) ↩
- 17. Kocetkov et al. — The Stack: 3 TB of permissively licensed source code (arXiv:2211.15533) (accessed ) ↩
- 18. Cassano et al. — MultiPL-E: A Scalable and Polyglot Approach to Benchmarking Neural Code Generation (arXiv:2208.08227) (accessed ) ↩
Anonymous · no cookies set