AgentFlow (ICLR 2026 Oral): a trainable agent framework, reviewed in plain English
AgentFlow (arXiv:2510.05592) trains a planner with on-policy RL across a four-module agent. We summarise what it claims, where the evidence holds, and where it doesn't.
1. Decision in 100 words
AgentFlow is a four-module agent system (planner, executor, verifier, generator) where only the planner is trained, using a new on-policy reinforcement-learning recipe called Flow-GRPO. 1 The paper reports that a 7B-scale AgentFlow delivers average accuracy gains of 14.9% on search, 14.0% on agentic, 14.5% on mathematical, and 4.1% on scientific tasks, with the abstract framing this as “even surpassing larger proprietary models like GPT-4o” on the evaluated suite. 1 If you already have GPU budget for a multi-day training run and are stuck on the ceiling of prompt-engineered agents like AutoGen, the paper is worth reading carefully. If you don’t, the prompt-only baselines remain the right starting point.
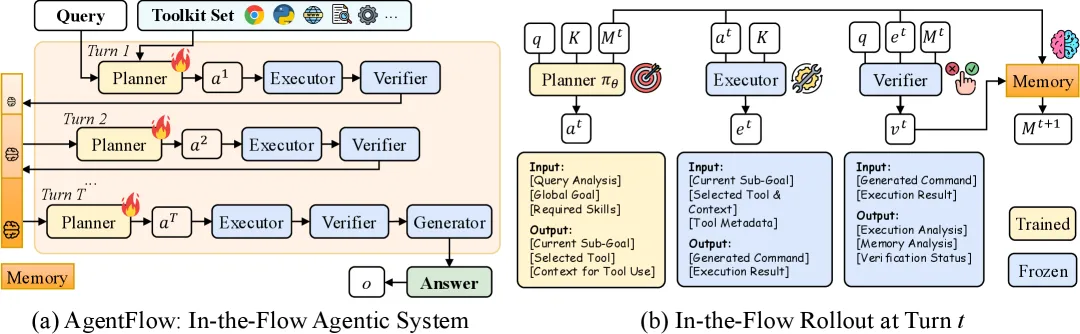
Figure 2 of In-the-Flow Agentic System Optimization (arXiv:2510.05592), reproduced for editorial coverage.
2. Background: the trainable-agent vs prompt-only debate
By early 2026 the open-source agent stack has split into two camps. One camp ships training-free frameworks where the agent’s behaviour is encoded in prompts: AutoGen runs multi-agent conversations through structured roles, 2 LangGraph orchestrates state-machine workflows over any LLM, ReAct interleaves reasoning and tool calls in a single prompt template, 3 and Smolagents wraps the same idea in code-first action surfaces. None of these update model weights. The model you start with is the model you ship.
The other camp updates weights. Toolformer was the early signal: a language model that taught itself to call APIs through self-supervised fine-tuning. 4 Outcome-driven reinforcement learning (DeepSeek-R1-style training, Search-R1, ToRL) extended that idea by training a single monolithic policy that interleaves chain-of-thought and tool calls under one trajectory-level reward. The trade-off is real: the prompt-only camp has zero training cost but caps at the base model’s reasoning ceiling; the trained camp pays GPU-hours upfront but can push past that ceiling.
AgentFlow’s pitch sits in a third position. Instead of training one giant policy that does everything, it factors the work across four specialised modules and trains only the one in charge of high-level planning, leaving the others as frozen open-weight LLMs. 1 The bet is that this split is both cheaper to train and stronger at long-horizon, sparse-reward tasks where credit assignment across many tool calls is hard.
3. What AgentFlow actually claims
The paper makes three load-bearing claims, all stated in the abstract. 1
First, prevailing tool-augmented approaches “train a single, monolithic policy that interleaves thoughts and tool calls under full context.” That, the paper argues, “scales poorly with long horizons and diverse tools and generalizes weakly to new scenarios.” 1
Second, AgentFlow proposes a four-module agent (planner, executor, verifier, generator) coordinated through an evolving memory, with the planner trained “directly inside the multi-turn loop.” 1 The training method is Flow-based Group Refined Policy Optimization (Flow-GRPO), which “tackles long-horizon, sparse-reward credit assignment by converting multi-turn optimization into a sequence of tractable single-turn policy updates.” 1
Third, on ten benchmarks across four task categories, a 7B AgentFlow outperforms the best same-scale baselines by 14.9% on search, 14.0% on agentic tasks, 14.5% on math, and 4.1% on science, “even surpassing larger proprietary models like GPT-4o” in places. 1
Each of these is a paper claim. We separate paper claims from third-party framing in §12.
4. The four-module architecture
The architecture is a clean factoring. The planner is a trainable policy that “formulates a sub-goal, selects an appropriate tool , and retrieves relevant context from memory” at each turn. 1 The executor “invokes the chosen tool with context, yielding an execution observation.” 1 The verifier “evaluates whether execution is valid and whether the accumulated memory is sufficient to solve the query.” 1 The generator “produces the final solution , conditioned on the query and the accumulated memory.” 1
Holding the four modules together is an evolving memory , “a deterministic, structured record of the reasoning process, enabling transparent state tracking” and updated as at each turn. 1 The toolset is fixed at five entries: a base generator (a Qwen2.5-7B-Instruct that answers when no external tool is needed), a Python coder, Google Search, Wikipedia Search, and a Web Search summariser. 1
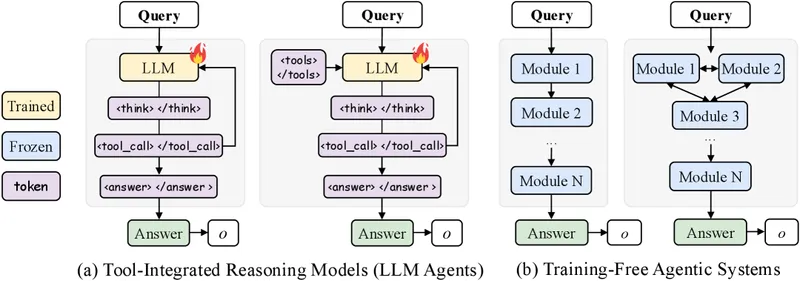
Figure 3 of arXiv:2510.05592, reproduced for editorial coverage.
The narrowness of the toolset matters. Five tools, four of which are search-shaped, plus one Python REPL, is a much smaller surface than what a general-assistant benchmark like GAIA expects. The paper’s tool-use claims need to be read against this scope, not against the broader “agent that can do anything” framing that some secondary coverage uses.
5. Flow-GRPO: how the planner is trained
Flow-GRPO is the paper’s method contribution. The intuition is straightforward once the jargon is unpacked.
Reinforcement learning (RL) means training a policy by sampling actions from it, observing rewards, and updating the parameters to make rewarded actions more likely. On-policy RL means the trajectories used for updates come from the current version of the policy, not from a fixed dataset. Sparse reward means feedback only arrives at the end of a long sequence; you find out whether the answer was right after every tool call has happened, not after each one.
The classical approach to sparse-reward credit assignment in long sequences is Proximal Policy Optimization (PPO) and its modern variant Group Relative Policy Optimization (GRPO). Flow-GRPO adapts the latter to the multi-turn agent setting in two specific ways. 1
The first move is to “broadcast a single, verifiable trajectory-level outcome to every turn.” Concretely, every action in a rollout receives the same global reward, which is the binary correctness of the final answer: . 1 This sidesteps the “which step deserves credit” question by giving the same credit to all of them.
The second move is the group-normalised advantage. The advantage at step in trajectory is the trajectory’s reward, recentred and rescaled against the mean and standard deviation of the rewards across the rollout group:
The PPO ratio that drives the update is the standard one, taken over the planner’s tokens for that turn:
The paper proves a result it labels Theorem B.1: under the on-policy state distribution, maximising the expected token-level local objective at each turn is “mathematically equivalent” to maximising the multi-turn trajectory objective. 5 The theorem is the formal justification for why decomposing a multi-turn problem into single-turn updates does not drift away from the long-horizon goal. We have not seen an independent verification of the proof, so it should be read as the paper’s own claim.
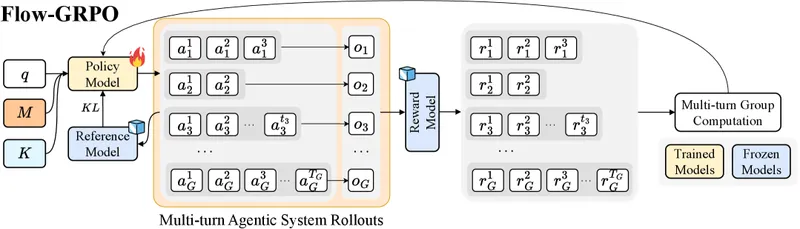
Figure 4 of arXiv:2510.05592, reproduced for editorial coverage.
What’s not trained matters as much. Only , the planner, has its weights updated. The verifier and generator are both frozen Qwen2.5-7B-Instruct instances; the executor is the deterministic tool-call layer; the memory is a non-parametric structured record. 1 If you want to upgrade the verifier or generator, you swap in a different open-weight model and retrain the planner. There is no joint optimisation across modules.
6. The headline result, reproduced
These are the paper’s reported numbers, taken from Section 4.2 and Tables 1 and 2 of the arXiv HTML render. 1 All AgentFlow rows use a 7B-scale planner; all baseline rows use the same 7B Qwen2.5 backbone unless otherwise marked.
| Task category | AgentFlow | Best 7B baseline | Gap |
|---|---|---|---|
| Search (Bamboogle, 2Wiki, HotpotQA, Musique avg) | 57.3% | AutoGen 42.4% | +14.9pp |
| GAIA (agentic) | 33.1% | Search-R1 19.1% | +14.0pp |
| AIME24 (math) | 40.0% | ToRL 20.0% | +20.0pp |
| AMC23 (math) | 61.5% | SimpleRL 60.0% | +1.5pp |
| GameOf24 (math) | 53.0% | SimpleRL 33.0% | +20.0pp |
| MedQA (science) | 80.0% | ToRL 76.5% | +3.5pp |
Tables 1–2 of In-the-Flow Agentic System Optimization (arXiv:2510.05592), reproduced for editorial coverage.
The training-strategy ablation in Table 3 (Section 4.4) is the most informative single result for a builder thinking about doing this themselves. 1
| Training strategy on the planner | Average accuracy | Delta vs frozen Qwen-7B |
|---|---|---|
| Frozen Qwen-7B-Instruct (no training) | 46.2% | baseline |
| Frozen GPT-4o (stronger LLM, no training) | 52.0% | +5.8pp |
| Offline supervised fine-tuning (SFT) on planner | 27.2% | −19.0pp |
| Flow-GRPO (this paper) | 63.4% | +17.2pp |
Table 3 of arXiv:2510.05592, reproduced for editorial coverage.
The line that should make any team pause is the SFT row. Naively fine-tuning the planner on supervised tool-use traces collapses performance by 19 percentage points below the untrained baseline. The paper’s preferred reading is that the on-policy multi-turn signal is doing real work; an alternative reading is that SFT is being run with insufficient care. Either way, “we’ll just SFT a planner on tool-call traces” is not a free shortcut.
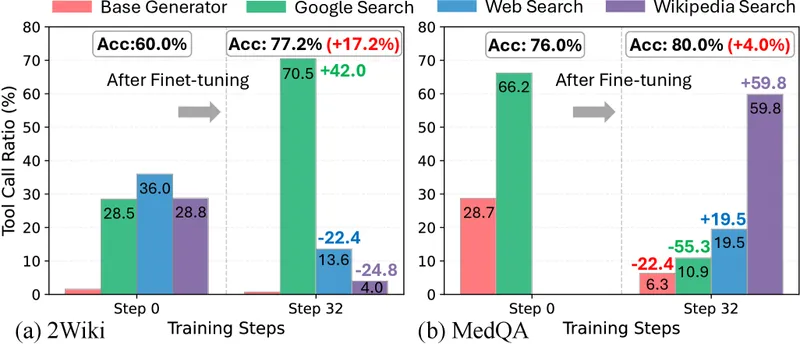
Figure 5 of arXiv:2510.05592, reproduced for editorial coverage.
A useful secondary finding: the trained planner learns domain-appropriate tool selection on its own. On 2Wiki (broad knowledge), Google Search usage rises by roughly 42 percentage points after Flow-GRPO; on MedQA (medical domain), Google Search usage falls from 66.2% pre-training to 10.9% post-training, while Wikipedia Search usage rises from 0% to 59.8%. 1 Tool-calling error rate falls by up to 28.4% on GAIA after training. These are not the kind of behaviours that prompt engineering reliably produces.
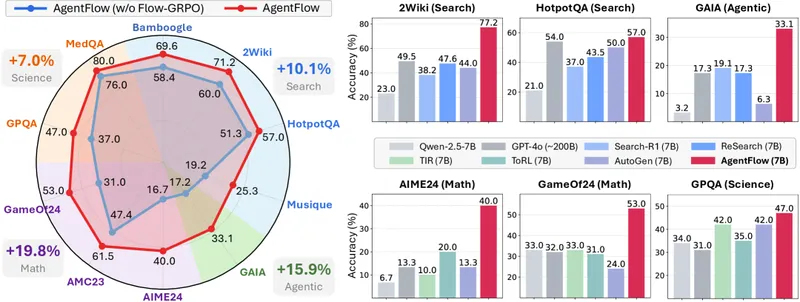
Figure 1 of arXiv:2510.05592, reproduced for editorial coverage.
7. Methodology disclosure
Phase 9C asks every paper-review article to surface four methodology inputs. Three are answered by the paper; one is not.
Sample size. Training data combines the Search-R1 corpus and DeepMath-103K, totalling 182,190 paired Q-A examples per the DeepWiki summary of the public repo. 6 The validation set during training is AIME24, a 30-problem high-difficulty math set. Batch size is 32 with 8 rollouts per sample. 1
Evaluation set. Ten benchmarks across four categories: four search-intensive (Bamboogle, 2Wiki, HotpotQA, Musique), one agentic (GAIA), three math (AIME24, AMC23, GameOf24), two science (GPQA, MedQA). 1 AIME24 sits in both training-time validation and final evaluation, which the paper does not flag. The DeepMath-103K training corpus is not audited for AIME24 contamination in the paper itself; given that AIME problems are public and frequently scraped into math corpora, this is a methodology hedge a careful reader should hold in mind.
Baselines. Five categories: open-source frozen LLMs (Qwen2.5-7B-Instruct), proprietary LLMs (GPT-4o), reasoning-RL models (DeepSeek-R1-style), tool-integrated systems (ToRL, Search-R1, SimpleRL), and a single training-free agentic system (AutoGen). 1 Notably absent: LangGraph, ReAct in canonical form, Reflexion, Smolagents. AutoGen is the only training-free agentic baseline. A reader inclined toward prompt-engineered alternatives should know that the comparison cohort tilts toward trained baselines.
Hardware and compute. Training runs on 8 × NVIDIA A100 GPUs, with effective parallelism of 256 trajectories per training step (32 batch × 8 rollouts). 1 Training horizon is capped at 3 turns per rollout to “accelerate the training speed”; 1 evaluation runs at up to 10. Total wall-clock time and aggregate GPU-hours are not disclosed in Section 4.1 or Section 4.5. A team budgeting a replication run cannot extract the cost from the paper directly. Industry pricing for A100 cluster rentals would put the order of magnitude in the low five figures of US dollars per training run, but that is an inference, not a paper claim.
Figure 8 of arXiv:2510.05592, reproduced for editorial coverage.
8. Limitations: the paper’s own and independent
The paper contains no standalone Limitations section. The closest paper-internal framing lives in the Conclusion’s future-work clause, which lists “extending in-the-flow optimization to other modules, incorporating more fine-grained reward signals, and scaling the framework to tackle more complex, open-ended tasks.” 1 A buried sentence in Section 4.1 acknowledges that the training horizon is capped at three turns purely to speed training up. 1 Phase 9C asks paper-review articles to flag this kind of structural absence, so it is flagged here: the paper does not separately treat its own limitations.
The strongest external critique surfaced in third-party coverage is a Medium analysis by Dixon (huguosuo) that surfaces three concerns the paper itself does not. 7 Dixon argues that only the planner learns while the other components remain static, which leaves potential joint-training optimisation on the table. Dixon also flags that on-policy multi-turn rollouts are compute-intensive in a way the paper’s hardware disclosure does not fully quantify, and that relying on single outcome rewards may miss fine-grained learning signals for subtask-level optimisation.
Three additional limitations surface from an independent read of the paper.
The training horizon mismatch ( during training, up to 10 at evaluation) is not validated as a controlled study. The reader cannot tell whether the planner generalises across the gap or whether evaluation longer trajectories simply fail more slowly.
The 7B AgentFlow outperforms a frozen GPT-4o on parts of the suite, but the comparison is being made between a model trained on this distribution and a frontier model with no opportunity to be tuned on it. This is a standard apples-to-oranges shape that newer frontier-vs-trained-small comparisons all share. Not unique to AgentFlow, but worth naming.
The benchmarks are picked from the same conceptual neighbourhood as the training data. Search-R1 and DeepMath are training corpora; HotpotQA, 2Wiki, AIME24 are evaluations. A claim of “general planning improvement” is stronger than the evidence supports; “improvement on the search-and-math distribution Flow-GRPO was trained against” is what the numbers actually show.
9. Reproducibility check
The release surface is unusually complete by ICLR standards.
| Artefact | Released | Source |
|---|---|---|
| Code (training + evaluation) | Yes, MIT licensed | github.com/lupantech/AgentFlow 8 |
| 7B trained planner weights | Yes | huggingface.co/AgentFlow/agentflow-planner-7b 9 |
| 3B trained planner weights | Yes | huggingface.co/AgentFlow/agentflow-planner-3b |
| Base model | Yes (external) | Qwen2.5-7B-Instruct |
| Training data | Yes (external) | Search-R1 + DeepMath-103K |
| Evaluation suites | Yes (external) | All ten public benchmarks |
| Demo space | Yes | huggingface.co/spaces/AgentFlow/agentflow |
| Trajectory visualizer | Yes | agentflow.stanford.edu |
The gap is on the methodology side rather than the artefact side. The Hugging Face model card for the 7B planner does not surface compute disclosure, training-data list, or limitations; it is thin enough that a builder reading only the model card gets a misleadingly minimal picture. The paper’s Section 4.1 is the canonical source. Total wall-clock training time is the one piece of information a builder needs that neither surface provides.
10. Related work
ReAct is the canonical training-free baseline. 3 It interleaves chain-of-thought reasoning and tool calls in a single prompt-only loop with no weight updates. AgentFlow’s framing in the abstract, that monolithic single-policy approaches “scale poorly with long horizons,” is the implicit critique of the ReAct lineage. 1 A reader choosing between them is choosing between zero training cost and prompt-engineering ceiling (ReAct) versus an on-policy training run and a higher per-task ceiling (AgentFlow).
Toolformer is the trainable-tool predecessor. 4 It demonstrated that a language model could teach itself API use through self-supervised fine-tuning, but it trained one monolithic policy: the same approach AgentFlow’s abstract critiques. AgentFlow extends Toolformer’s spirit (training is part of the answer) while disagreeing with its method (one monolithic policy is the wrong granularity).
AutoGen is the production-orchestration counterpoint and the only training-free agentic framework included as a baseline in AgentFlow’s own evaluation. 2 AutoGen plus a frozen 7B Qwen2.5-Instruct scores 42.4% on AgentFlow’s search suite versus AgentFlow’s 57.3%. 1 Two readings of that gap exist. The paper’s reading is that the trained planner is doing real work. An alternative reading is that AutoGen with frontier-LLM backbones (GPT-5, Claude Sonnet 4.5), a configuration not run in the paper, would close most of the gap, because most of AutoGen’s ceiling is bounded by the underlying model. We do not have data either way; we flag the asymmetry.
A cluster of contemporaneous work pushes related ideas. AFlow (ICLR 2025) reframes agent-workflow generation as Monte Carlo Tree Search over code workflows, a different optimisation paradigm for the same underlying problem of “how do we make multi-step agents better.” 10 Reflexion uses verbal reinforcement (memory of past mistakes) instead of weight updates, hitting the same sparse-reward credit-assignment problem from the opposite direction. 11 Together with AgentFlow, these papers map the design space: train weights, search workflows, or accumulate verbal memory. AgentFlow takes the first option.
11. Independent benchmark cross-check
The paper’s headline numbers are the authors’ own evaluations. We checked two public agent benchmarks for independent reproductions.
The Princeton HAL GAIA leaderboard, the most-cited public agent leaderboard at time of writing, lists 32 entries. 12 The top entry is HAL Generalist Agent + Claude Sonnet 4.5 at 74.55%; the runner-up is the same agent in a “high” configuration at 70.91%. AgentFlow does not appear in any of the 32 entries. 12
The Hugging Face GAIA Space leaderboard shows 600+ public submissions, with the top entries (openJiuwen-deepagent and OPS-Agentic-Search) sitting at 92.36% on multi-frontier-LLM composite stacks. 13 AgentFlow is absent from this leaderboard as well. 13
This is the Phase 9C standard 3 hedge in plain language: independent reproducibility on GAIA has not been published as of 2026-05-09. The paper’s 33.1% figure is the authors’ result against same-scale 7B baselines. The 70-92% range on the public leaderboards is a different comparison: frontier-LLM-backed agents at much larger total capability, and a 7B AgentFlow is not directly comparable to that ceiling. The right reading of the paper’s GAIA number is “AgentFlow is the strongest 7B agent in this paper’s cohort,” not “AgentFlow approaches GAIA SOTA.”
We did not find an entry for arXiv:2510.05592 on Papers With Code at fetch time; the URL redirected to a generic trending page. Independent benchmark indexing has not surfaced.
12. The community reception
We separate three layers of community framing from the paper itself.
The Lambda Labs ICLR 2026 blog calls AgentFlow one of twelve papers worth reading at the conference, summarising the method as: “Rather than optimizing the whole trajectory at once, Flow-GRPO breaks it into single-turn updates and propagates a verifiable trajectory-level signal back to each step. With this approach, a 7B AgentFlow model beats GPT-4o on search, math, and science reasoning.” 14 Lambda is one of the author affiliations, so this is a release-narrative source, not an independent assessment. The “Top 1.1%” Oral framing in the same post is consistent with the iclr.cc virtual page confirmation of Oral status. 15
Researcher commentary on X.com surfaced in WebSearch results during dossier preparation. A launch post from Pan Lu (the senior author) and a follow-up commentary from Rohan Paul are both visible by URL, but a direct fetch returned an authentication gate at fetch time. These posts are confirmed to exist; full thread context is not surfaced here, so this article does not quote from them. The OpenReview thread at openreview.net/forum?id=Mf5AleTUVK is public, the paper is licensed CC BY 4.0, and the page surfaces title, abstract, author list, and the explicit “ICLR 2026 Oral” acceptance designation; reviewer scores and weakness comments are not surfaced to unauthenticated visitors at fetch time.
The Medium analysis by Dixon (referenced in §8) is the most substantive independent critique surfaced in third-party coverage. 7 MarkTechPost and AIBase coverage surfaced in the same search are press-release rewraps with no independent evaluation; neither is cited here for analysis.
A consistent pattern across all secondary coverage surveyed: the +14% headline gains get repeated without the methodological caveats from §7. The paper’s own framing in the abstract is more careful than the secondary coverage suggests, and the secondary coverage is more enthusiastic than the paper’s data warrants. The paper version is canonical.
13. What this means for builders
The decision tree breaks down by team shape and ceiling.
A team running a prompt-engineered agent on AutoGen, LangGraph, or Smolagents that is hitting a quality ceiling on long-horizon, sparse-reward tasks has a real reason to read AgentFlow carefully. The +14.9% search and +14.0% GAIA gaps over training-free baselines at the same model scale are the sharpest evidence for the trained-planner thesis in the paper. A team in this position should run the public 7B planner against their own task suite before considering a from-scratch training run.
A team without GPU budget for a multi-day on-policy training run should stick with prompt-engineered baselines for now. Smolagents on a self-hosted Qwen 3 or Llama 3 backbone, or AutoGen on a frontier API, gets you 80% of the way at near-zero training cost. The crossover where training pays back is roughly: enough sustained inference traffic that the per-query difference between a frontier-API-backed AutoGen and a 7B-self-hosted AgentFlow planner amortises a five-figure training run. Most teams are not at that crossover yet.
A team thinking about doing the obvious thing, supervised fine-tuning a planner on tool-use traces, should read the −19pp SFT result in §6 carefully. The paper’s strongest internal warning is that the naive shortcut is worse than no training at all on this evaluation suite. If the on-policy infrastructure is too expensive, the right alternative is staying with frozen baselines, not switching to SFT.
A team that does try the public AgentFlow checkpoint should check three specific things on its own task distribution. First, does the planner’s domain-appropriate tool selection (Wikipedia for medical, Google for broad-knowledge) transfer to the team’s own domain mix? Second, does the training-time horizon constrain performance on tasks that genuinely need 6-10 turns? Third, does the binary outcome reward generalise to tasks where partial credit matters?
14. Open questions for follow-up papers
Four directions are unresolved.
The frozen-modules question. AgentFlow trains only the planner. Joint training of planner and verifier, or planner and generator, is the natural next study. Whether it pays off (richer credit signal) or breaks (training instability across coupled modules) is open.
The reward-design question. Single binary outcome rewards work in the paper’s evaluation but plausibly miss fine-grained learning signals. Process-reward models, step-level verifier scores, and partial-credit graders are the obvious next-step alternatives.
The contamination question. Whether DeepMath-103K’s overlap with AIME24 is doing measurable work in the headline AIME24 number is testable with held-out splits. The paper does not run that test.
The orchestration question. AgentFlow is a research framework, not a production library. A LangGraph or AutoGen integration that exposes AgentFlow’s trained planner as a drop-in node would be the cleanest path from paper to deployment, and we have not seen one yet.
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. Li et al., *In-the-Flow Agentic System Optimization for Effective Planning and Tool Use*, arXiv:2510.05592v1, 7 October 2025 — abstract, sections 3.1, 3.2, 4.1, 4.2, 4.3, 4.4, and Conclusion (ar5iv HTML render). (accessed ) ↩
- 2. Microsoft AutoGen v0.7 documentation — multi-agent conversational orchestration framework cited as the training-free baseline in AgentFlow's evaluation. (accessed ) ↩
- 3. Yao, Zhao, Yu, Du, Shafran, Narasimhan, Cao — *ReAct: Synergizing Reasoning and Acting in Language Models*, arXiv:2210.03629, 6 October 2022 (ICLR 2023). (accessed ) ↩
- 4. Schick, Dwivedi-Yu, Dessì, Raileanu, Lomeli, Zettlemoyer, Cancedda, Scialom — *Toolformer: Language Models Can Teach Themselves to Use Tools*, arXiv:2302.04761, 9 February 2023. (accessed ) ↩
- 5. Hugging Face Papers community page for arXiv:2510.05592 — structured extraction of Theorem B.1 statement (paper's own claim; independent verification not surfaced). (accessed ) ↩
- 6. DeepWiki auto-generated repository summary of lupantech/AgentFlow — training data sample count (182,190) and validation set (AIME24, 30 problems). (accessed ) ↩
- 7. Dixon (huguosuo), Medium analysis of *In-the-Flow Agentic System Optimization* — independent critique on frozen non-planner modules, compute-intensive on-policy rollouts, and single-outcome-reward simplicity. (accessed ) ↩
- 8. lupantech/AgentFlow — canonical code repository, MIT licensed; Python 92.7% / Shell 7.3%; full source for training and benchmark scripts. (accessed ) ↩
- 9. AgentFlow planner 7B trained checkpoint on Hugging Face — last updated 12 October 2025; thin model card with no compute disclosure. (accessed ) ↩
- 10. Zhang et al. — *AFlow: Automating Agentic Workflow Generation*, arXiv:2410.10762, ICLR 2025; reformulates workflow optimization as MCTS over code-representation search. (accessed ) ↩
- 11. Shinn, Cassano, Berman, Gopinath, Narasimhan, Yao — *Reflexion: Language Agents with Verbal Reinforcement Learning*, arXiv:2303.11366, 20 March 2023. (accessed ) ↩
- 12. Princeton HAL GAIA leaderboard — 32 listed entries as of fetch; AgentFlow not present; top entry HAL Generalist Agent + Claude Sonnet 4.5 at 74.55%. (accessed ) ↩
- 13. Hugging Face GAIA Space leaderboard — 600+ public submissions; AgentFlow not present in visible entries; top composite-stack agent at 92.36% average. (accessed ) ↩
- 14. Lambda Labs ICLR 2026 blog — release-narrative source; co-author affiliation conflict noted; useful for "Top 1.1%" Oral framing. (accessed ) ↩
- 15. ICLR 2026 Oral session page for AgentFlow — paper 10009932; Oral session Friday 24 April 2026, 6:54-7:04 AM PDT, Amphitheater. (accessed ) ↩
Further Reading
- Li et al. — In-the-Flow Agentic System Optimization for Effective Planning and Tool Use (arXiv:2510.05592 abstract) (accessed )
- Stanford AgentFlow project page (accessed )
- OpenReview forum thread (review surface non-public as of fetch) (accessed )
Anonymous · no cookies set