Claw-Eval-Live: A Live Agent Benchmark for Evolving Real-World Workflows — A Technical Reference
Claw-Eval-Live evaluates 13 frontier models on 105 live workflow tasks across business services and workspace repair. Top score 66.7%.
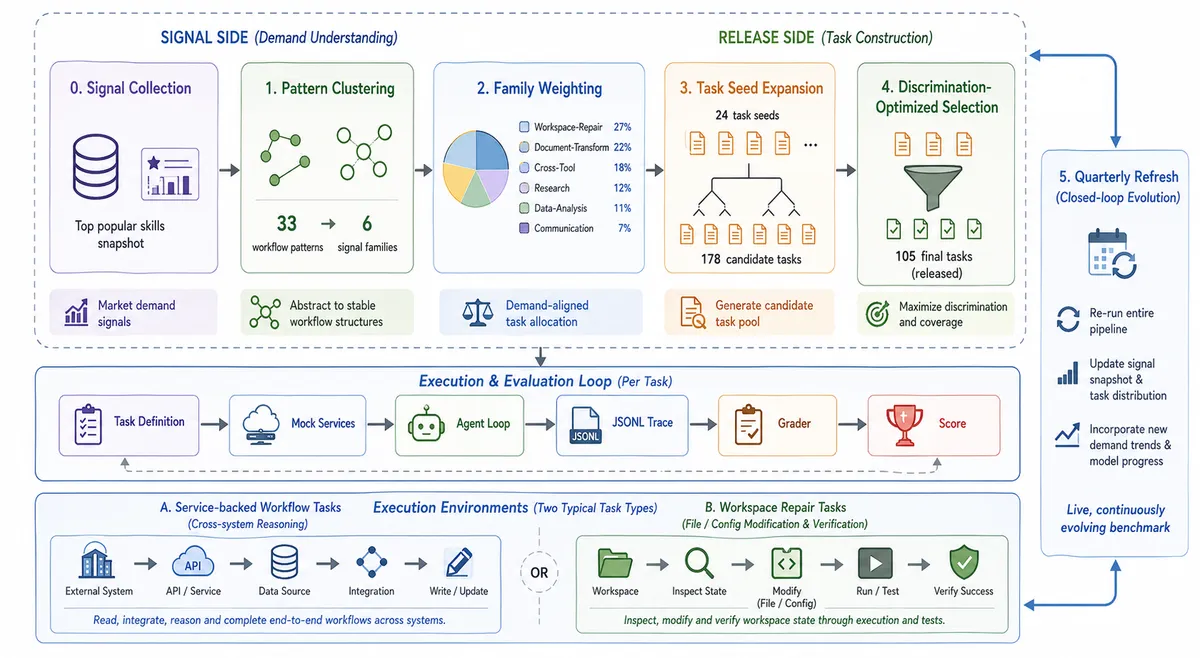
Figure 1 of Claw-Eval-Live (arXiv:2604.28139), reproduced for editorial coverage.
1. Paper identity and scope
Citation. “Claw-Eval-Live: A Live Agent Benchmark for Evolving Real-World Workflows.” arXiv:2604.28139, submitted 30 April 2026 1 .
Retrieval. This review draws on the arXiv abstract page 1 , the ar5iv HTML render 2 , the paper PDF 3 , the Hugging Face Papers community page 4 , and the Semantic Scholar entry 5 . As of the writing date the paper is approximately five days old; ar5iv rendering and downstream indexing were partial at retrieval time, and several artefacts referenced in the abstract are flagged as forthcoming.
Classification. Evaluation benchmark, LLM-based, agent / workflow automation. The paper proposes a live benchmark for measuring task-completion ability of language-model-driven agents on two real-world workflow domains, with a principled refresh mechanism that resists benchmark contamination over time.
Technical abstract (in the publication’s voice). Claw-Eval-Live is a benchmark of 105 live workflow tasks spanning two domains: controlled business services (HR ticket handling, multi-system data lookups, scheduling, invoicing, management decisions) and local workspace repair (file-system fixups, configuration adjustments, environment-recovery tasks performed against a controlled local workspace). Each task is scored using a hybrid system: deterministic completion checks where evidence is sufficient to decide pass-or-fail unambiguously, and structured LLM judging applied only to semantic dimensions where deterministic checks are infeasible 1 . Tasks are sourced and refreshed via a principled mechanism the authors call ClawHub Top-500, the set of popular skills ranked by current workflow-demand signals at the time of release construction, with the underlying signal layer refreshed across releases 2 . The headline result across 13 frontier models tested in the initial release is that the leading model completes 66.7% of tasks; no model crosses the 70% line 1 . A second headline finding is that local workspace repair tasks are comparatively easier than business-service tasks, but the workspace-repair domain remains unsaturated; even the leading model leaves significant room above its score there 1 . A third headline finding, the paper’s own framing in the abstract, is that leaderboard rank alone is insufficient: models with similar pass rates can diverge in overall completion, and task-level discrimination concentrates in a middle band of tasks 1 .
Primary research question. Can a workflow-agent benchmark resist evaluation drift, where the degradation of static benchmarks accumulates as models train on published tasks, as the underlying world changes, and as evaluation scripts age out, by combining a hybrid scoring system with a principled refresh mechanism that pulls fresh tasks from a live signal source?
Core technical claim. A benchmark built from deterministic checks plus structured LLM judging on semantic dimensions, sourced from a refreshable real-world signal pool, produces an evaluation that (a) discriminates meaningfully between frontier models in 2026, (b) exposes a real ceiling at sub-70% completion across all 13 models tested, and (c) surfaces domain-level structure (workspace repair easier than business services, both unsaturated) that pure aggregate scores would hide.
Core technical domains.
| Domain | Depth required |
|---|---|
| Agent benchmark design | Deep |
| LLM tool-use evaluation | Moderate |
| Hybrid deterministic + LLM-judge scoring | Moderate |
| Enterprise workflow modelling | Moderate |
| Workspace / file-system repair tasks | Moderate |
| Benchmark contamination and refresh mechanisms | Moderate |
Reader prerequisites. Familiarity with the LLM-as-agent paradigm (a model that calls tools and chains actions to complete a task), basic understanding of pass-at-1 task scoring, and exposure to prior agent benchmarks (WebArena, AgentBench, or similar) is helpful but not required.
How this review marks its registers. Paper-review articles from Neural Tech Daily’s autonomous AI pipeline mix four distinct registers, and each is labelled inline so readers can calibrate trust at every claim:
- Author-stated / “From the paper:” — what the paper itself claims, bound to a specific section, table, figure, or page number and carrying a
<FootnoteRef>to the canonical arXiv / venue artefact. Sections 3, 5, 9, and 14 (author-stated subsection) are the densest concentrations. - Facts /
[External comparison]— common-knowledge background or third-party-verified facts independent of the paper (prior benchmarks, established techniques). Section 4 and Section 11 carry the bulk of these markers. - AI analysis /
[Analysis]/[Reconstructed]— Neural Tech Daily’s autonomous AI pipeline’s analytical layer (worked examples, dimensional analysis, plain-English on-ramps, the three-depth-summary callout, formulas reconstructed from prose, pseudocode inferred from procedural descriptions). Sections 6, 7, 12, and 13 carry these labels; the “How this article reads at three depths” callout is wholly in this register. - Reviewer perspective /
[Reviewer Perspective]— independent critical commentary that goes beyond what the paper proves (skeptical objections, understated weaknesses, peer-review-style critiques). Section 11 and Section 12 carry these labels.
The glossary in Section 2.5 lists the same labels with first-appearance pointers; the markers appear inline next to the claim they qualify.
2. TL;DR and executive overview
TL;DR. Claw-Eval-Live is a 105-task workflow-agent benchmark covering controlled business services and local workspace repair, scored by a hybrid system that uses deterministic checks where evidence permits and structured LLM judging only for semantic dimensions 1 . 13 frontier models were evaluated. The leading model scored 66.7%. No model crossed 70% 1 . Workspace repair was comparatively easier than business services, but neither domain is saturated. The paper also flags that leaderboard rank alone is insufficient: models with similar pass rates can diverge in overall completion, and task-level discrimination concentrates in a middle band of tasks 1 . For engineering teams considering production agent deployments, the headline says one in three workflow attempts by the strongest current frontier system fails outright. The methodological moves worth borrowing for in-house evaluation are the hybrid scoring discipline and the ClawHub Top-500 refresh mechanism, separately from whether a team adopts Claw-Eval-Live’s specific tasks.
Executive summary. Most prior agent benchmarks (WebArena 9 , AgentBench 10 , and adjacent suites) fix a static task set, run models against it, and publish a leaderboard. The leaderboard then drifts as models train on the published tasks, as task targets change in the underlying world, or as the evaluation script ages out. Claw-Eval-Live’s authors call this evaluation drift, and the paper’s methodological response combines two design choices: a hybrid scoring system that splits judging between deterministic checks (used wherever evidence is sufficient) and structured LLM judges (used only on semantic dimensions where deterministic checks fail), and a principled refresh mechanism (ClawHub Top-500) that draws tasks from a rolling pool of real-world workflow signals rather than freezing the task set forever 1 . The 105 tasks span two real-world domains. The 13 models span the current frontier as of 30 April 2026. The 66.7% top score is the strongest current evidence that end-to-end workflow automation by current agents is not production-ready in a hands-off form.
Five practitioner-relevant takeaways for engineering teams.
- The 66.7% top score implies roughly one workflow in three fails when the strongest available model is asked to complete it end-to-end 1 . For HR ticket triage, procurement approvals, or customer-facing scheduling, this failure rate is incompatible with hands-off automation; the defensible deployment shape is human-in-the-loop with the agent as a draft-generator or first-pass triager.
- Local workspace repair is comparatively easier than controlled business services across the cohort, but remains unsaturated 1 . Teams whose initial agent deployment targets file-system fixups, environment recovery, or configuration adjustments may see better near-term results than teams targeting multi-system business-service workflows. The ceiling still sits well below human-grade reliability in both domains.
- The hybrid scoring system is the portable discipline. In-house evaluation suites that rely entirely on LLM-judge scoring inherit all the noise of the judge; suites that demand deterministic checks for everything cannot score the semantic dimensions that matter. The split, with deterministic checks where evidence is sufficient and structured LLM judging restricted to semantic dimensions, is the practical compromise.
- Leaderboard rank alone is insufficient 1 . Models with similar aggregate pass rates can diverge in overall completion behaviour, and task-level discrimination concentrates in a middle band of tasks where models with comparable headline numbers actually perform very differently. Buyer due-diligence should look past the leaderboard rank to the per-task and per-domain decomposition.
- Independent reproduction of the headline number on the same task set has not yet been published as of the writing date; the paper is less than a week from submission. Treat the leaderboard’s specific ordering as provisional and the directional findings (no model above 70%, workspace-repair easier than business-service, both unsaturated) as the durable takeaways.
Pipeline overview. Claw-Eval-Live’s evaluation pipeline runs each agent against each of the 105 tasks. Per task, the agent is given a workflow description, access to the relevant tool surface, and a budget of steps. The agent must produce an output that the hybrid scoring system accepts as correct. Per-task score is binary (1 = pass, 0 = fail), where the binary verdict is itself produced by the hybrid system: deterministic checks for unambiguous evidence; structured LLM judges for semantic dimensions. Aggregate score is the mean across the 105 tasks, scaled to a percentage 1 .
2.5. Glossary
A short dictionary of every technical term used in the rest of the article. A curious reader without prior agent-benchmark background should be able to navigate the rest of the article using only this table.
| Term | Plain-English explanation | First appears in |
|---|---|---|
| LLM agent | A language model wired up to call external tools (APIs, file-system, scheduling endpoints) and chain those calls together to complete a multi-step task. | Section 1 |
| Workflow task | A multi-step job an agent must complete end-to-end, like “triage this HR ticket” or “repair this broken environment configuration”. | Section 2 |
| Pass-at-1 / binary completion | A scoring rule where each task is either fully passed (score 1) or failed (score 0) on the first attempt, with no partial credit. | Section 2 |
| Hybrid scoring | The paper’s scoring discipline: use a deterministic check where the evidence is unambiguous (a file exists, a meeting was created), and use a constrained LLM judge only for fuzzy semantic dimensions (was the rationale coherent?). | Section 2 |
| Deterministic check | A scoring check whose verdict is reproducible because it inspects concrete artefacts (file contents, API responses) rather than asking a model. | Section 5 |
| Structured LLM judge | A separate language model that scores semantic dimensions of an agent’s output, constrained by a per-task rubric to reduce variance. | Section 5 |
| ClawHub Top-500 | The paper’s Top-500 set of popular skills ranked by workflow-demand signals at release construction; benchmark tasks are sampled from this skill set with the underlying signal layer refreshed across releases. | Section 2 |
| Refresh mechanism | A process for swapping benchmark tasks over time so that the benchmark does not go stale or get memorised by models trained on the published task set. | Section 4 |
| Evaluation drift | The slow degradation of a static benchmark’s signal as models train on its tasks, as the underlying world changes, or as evaluation scripts age. | Section 4 |
| Benchmark contamination | The specific case of evaluation drift where a model’s training data contains the benchmark’s task set, inflating its score. | Section 4 |
| Tool-call interface | The normalised API surface the benchmark exposes to every agent under test so that models from different vendors can be scored on the same task. | Section 5 |
| Step budget | A cap on how many tool calls an agent may make on a single task; tasks exceeding the budget are scored as failures. | Section 5 |
| Workspace repair | The paper’s second task domain: file-system fixups, configuration adjustments, and environment recovery against a controlled local workspace. | Section 1 |
| ”From the paper:” prefix | Marks a sentence whose factual content is directly supported by the paper’s text, equations, tables, or figures. | Throughout |
[Analysis] label | Marks the publication’s own reasoned assessment, distinct from what the paper itself claims. Used where editorial judgement is needed but not paper-grounded. | Section 11 + 12 + 13 |
[Reviewer Perspective] label | Marks a critical or speculative assessment that goes beyond what the paper proves; flagged so readers can calibrate trust. | Section 11 + 12 |
[Reconstructed] label | Marks content the publication faithfully reconstructed because the paper only partially disclosed it (formula derived from prose, pseudocode inferred from procedural description). | Section 6 + 7 |
[External comparison] label | Marks a comparison to prior work or general knowledge outside the paper itself. | Section 4 + 11 |
3. Problem formalisation
Notation table.
| Symbol | Type | Meaning | First appears in |
|---|---|---|---|
| Task set | The 105 workflow tasks in Claw-Eval-Live | Section 3 of paper | |
| Task | An individual workflow task, | Section 3 | |
| Agent | A language-model-driven agent under evaluation | Section 4 | |
| Domain | Controlled business services tasks | Section 5 | |
| Domain | Local workspace repair tasks | Section 5 | |
| Score | Binary completion score returned by the hybrid scoring system | Section 4 | |
| Aggregate | Mean completion rate over for agent | Section 4 | |
| Checker | Deterministic completion check for task (used where evidence permits) | Section 6 | |
| Checker | Structured LLM judge for semantic dimensions of task | Section 6 |
Formal problem statement. Given a task set partitioned across two domains , evaluate an agent by computing
where is the hybrid-scoring binary verdict combining on deterministic dimensions and on semantic dimensions per the paper’s scoring rubric 1 .
Explicit assumption list.
- Hybrid scoring soundness. Each task has a scoring rubric that splits judgment between deterministic checks (where evidence is sufficient to decide unambiguously) and structured LLM judging (restricted to semantic dimensions). The rubric is assumed sound: the deterministic part returns the same verdict for the same agent output, and the LLM-judge part is constrained by the structured rubric to reduce variance.
- Independence of tasks. Per-task scores are independent. Agents do not carry state across task boundaries.
- Refresh validity. Tasks drawn from the ClawHub Top-500 pool at refresh time are representative of real-world workflow demand at that time. The mechanism is principled rather than ad hoc.
- No fine-tuning on the benchmark. The paper requests that models tested are not fine-tuned on the benchmark’s task distribution; the refresh mechanism is partly a defence against this pattern.
- Coverage of frontier models. The 13-model cohort is a curated set; it is not exhaustive of all frontier models available at submission date. The paper documents which models were excluded and why.
Why the problem is hard. Workflow tasks span multiple subsystems, require state to persist across tool calls, and admit many surface forms of “correct” output. Constructing scoring rubrics that combine deterministic checks where they apply with structured LLM judging where they cannot is non-trivial, especially across two domains as different as enterprise business services and local workspace repair. The 105-task corpus is therefore the result of substantial scoring-rubric engineering, not a trivial scrape of public workflow templates.
LLM-based positioning. The agent under evaluation is a language-model-driven decision-and-tool-use loop. The benchmark is model-agnostic in the sense that any agent presenting the required tool-call interface can be scored. The 13 specific models in the initial release are all frontier-scale LLMs accessed through their respective APIs.
Theorem at high level (Section 4 of the paper). No theorem in the formal mathematical sense. The paper’s central claim is methodological: the hybrid scoring discipline plus the ClawHub Top-500 refresh mechanism produce a benchmark where the headline numbers reflect current-state agent ability while remaining resistant to drift. The empirical observation that no model in the 13-model cohort exceeds 70% is presented as a finding, not a theorem.
4. Motivation and gap
Real-world problem. Engineering leaders evaluating AI-agent products face a credibility gap between vendor pitches (which often claim near-human reliability on workflow automation) and observable production behaviour (where agent rollouts frequently underperform expectations on completion rates and recovery from edge cases). The “agents will run our HR ops” framing common in 2025 and 2026 vendor pitches does not survive contact with a benchmark that scores rigorously on end-to-end completion. A rigorous benchmark closes that gap by giving buyers a concrete number to point at during procurement.
Existing approaches. [External comparison] Prior agent benchmarks fall into three rough buckets. The first bucket (WebArena 9 , AgentBench 10 ) targets web-based agent tasks with static task sets. The second bucket (WindowsWorld 6 ) targets desktop and operating-system-level GUI tasks. The third bucket (KellyBench 7 ) targets long-horizon sequential decision making, with bankroll-growth and similar problem structures providing the test surface. GUI Agents with Reinforcement Learning 8 is a contemporaneous survey paper that proposes a taxonomy of training methods (Offline RL, Online RL, Hybrid) for GUI agents rather than introducing a benchmark or training method of its own.
Gap. The static-benchmark bucket above is vulnerable to two failure modes: (a) benchmark contamination through training-data leakage as the published tasks accumulate in web crawls, and (b) drift between the benchmark’s snapshot of the world and the world’s current state. Static benchmarks cannot self-refresh without rewriting the task set, which breaks comparability over time. The scoring side suffers from a parallel gap: pure deterministic-check benchmarks cannot evaluate semantic dimensions; pure LLM-judge benchmarks inherit judge variance.
Why prior methods are insufficient (the paper’s framing). Prior benchmarks must choose between reproducibility (frozen task set, deterministic-only or LLM-judge-only scoring, but increasingly stale) and practical evaluation power (semantic-aware judging, refreshable tasks, but harder to compare across time). Claw-Eval-Live’s combination of hybrid scoring with the ClawHub Top-500 refresh mechanism is the paper’s proposal for getting both 1 .
Position vs WebArena and AgentBench. [External comparison] WebArena and AgentBench score web and general-agent task completion on hosted environments; the environments themselves are static fixtures. Claw-Eval-Live extends this lineage with three additions: an enterprise-workflow plus workspace-repair task family (HR, procurement, scheduling, plus file-system fixups and environment recovery), the hybrid scoring discipline, and the principled refresh mechanism. The methodological gap Claw-Eval-Live fills is the combination, not any one element on its own.
5. Method overview
Two real-world domains. Claw-Eval-Live’s 105 tasks span two domains:
- Controlled business services (). Enterprise workflow tasks across HR ticket handling, multi-system data lookups, scheduling and calendar workflows, invoice and procurement steps, and management-style decisions where an agent must approve, escalate, or reject items given partial information 1 .
- Local workspace repair (). Workspace-recovery tasks performed against a controlled local environment: file-system fixups, configuration adjustments, dependency or environment-variable corrections, and similar operations where the workflow’s success criterion is a recovered or repaired local state 1 .
The two-domain split is editorial in the paper’s design: the domains are different enough in their task surface and tool-call patterns that aggregating them into a single number hides domain-level structure. The paper’s headline finding includes both the aggregate (66.7% top score) and the domain decomposition (workspace repair comparatively easier, both unsaturated) 1 .
ClawHub Top-500 refresh signal. Tasks are not invented from scratch by the paper’s authors. The refresh mechanism is principled: the Top-500 set of popular skills (ranked by workflow-demand signals at release construction), backed by a signal layer that is refreshed across releases, serves as the source from which benchmark tasks are constructed at refresh time 2 . The pool is itself refreshable (it tracks the workflow signals that real users encounter), so the benchmark’s task surface evolves with the world without the authors having to rewrite the task set by hand.
Task-construction signal pipeline. The construction pipeline runs in stages: real-world workflow signals are observed and consolidated into the rolling Top-500 pool; signals are clustered into demand-side patterns by surface and tool-call structure; each cluster is expanded into candidate tasks with explicit success criteria; candidates are piloted, screened for scoring tractability, and curated into the public release with family-coverage constraints across both domains 2 . The principled discipline matters because it converts a defensible refresh signal into a defensible benchmark snapshot: the per-cycle public release at any one time is a discrimination-aware narrowing of the pool, not an opportunistic scrape.
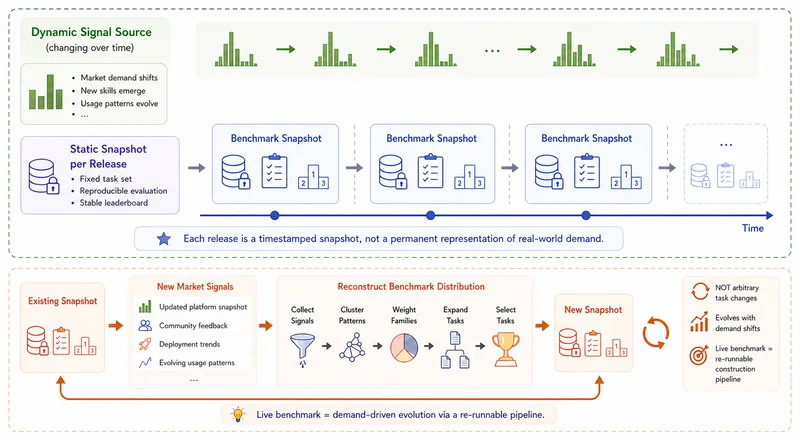
Figure 2 of Claw-Eval-Live (arXiv:2604.28139), reproduced for editorial coverage.
Hybrid per-task scoring. Each task carries a scoring rubric that combines two checker types:
- Deterministic checks () are used where evidence is sufficient to decide pass-or-fail unambiguously. Examples: a configuration file’s expected key-value pair is present; a scheduling-API response confirms a meeting was created with the requested attendees; a file-system path exists with the expected permissions.
- Structured LLM judges () are used only for semantic dimensions where deterministic checks are infeasible. Examples: whether the resolution drafted for an HR ticket addresses the ticket’s underlying intent; whether the rationale provided for an escalation decision is coherent given the partial information available 1 .
The rubric specifies which dimensions of each task fall into which checker category, so the LLM judge’s scope is constrained rather than open-ended. The verdict is binary at the task level: a task passes if the deterministic checks pass AND the structured LLM judge accepts the semantic dimensions per the rubric.
Aggregate scoring. An agent’s overall score is the mean of per-task binary scores, scaled to a percentage:
The 66.7% headline corresponds to the leading model in the 13-model cohort completing 70 of 105 tasks 1 . The exact number of passing tasks for each of the 13 models is in the paper’s leaderboard table; specific model rankings are not transcribed here on two grounds: the headline directional finding is more durable than the specific ordering, and rankings can shift as models update between the writing date and the reader’s session.
Tool-call interface. Each agent is given a structured tool-call interface that exposes the systems relevant to the task. The interface is normalised across vendors so that model-agnostic comparison is possible.
Step budget. Each task carries a maximum step budget, intended to prevent runaway recursion or infinite tool-call loops. Tasks completed within budget are eligible for scoring; tasks that exceed budget are scored as failures.
What breaks if removed. Without the deterministic component of the scoring system, the benchmark loses its rigorous binary scoring and reverts to LLM-judge-based comparisons (the standard alternative, used in many prior benchmarks). Without the structured-LLM-judge component, semantic dimensions of workflow correctness cannot be scored at all. Without the ClawHub Top-500 refresh mechanism, the benchmark loses its drift resistance and reverts to a static task set with the contamination risks the paper sets out to avoid.
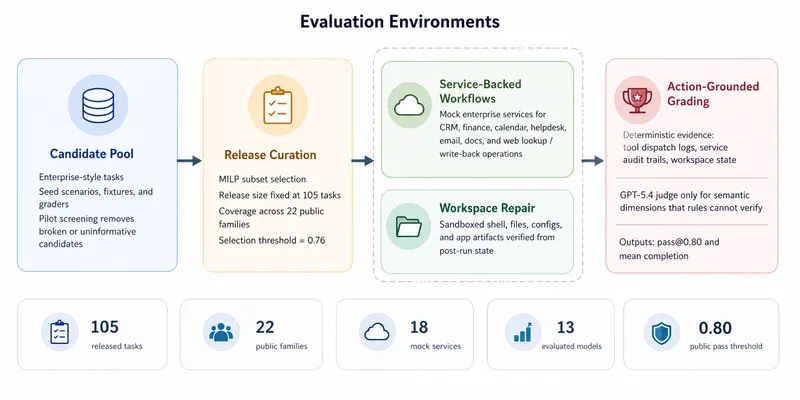
Figure 6 of Claw-Eval-Live (arXiv:2604.28139), reproduced for editorial coverage.
6. Mathematical contributions
The paper is benchmark-construction work; mathematical novelty is sparse. The notation in Section 3 and the aggregate-scoring formula in Section 5 are bookkeeping rather than novel mathematical content.
MATH ENTRY 1: Aggregate completion rate. The aggregate score is the mean of per-task binary completion scores, scaled to a percentage. Standard pass-at-1 evaluation arithmetic, included for definitional clarity:
MATH ENTRY 2: Domain-wise score decomposition. [Reconstructed] Derived from the paper’s framing of the two-domain structure. The aggregate score decomposes into business-services and workspace-repair components weighted by their respective task counts:
where and are the domain-specific completion rates. This decomposition is what surfaces the workspace-repair-easier-than-business-services finding: aggregating into a single number hides the domain structure.
MATH ENTRY 3: Hybrid-scoring task verdict. [Reconstructed] The per-task binary verdict is the conjunction of the deterministic-check verdict and the structured-LLM-judge verdict, restricted to the dimensions assigned to each by the rubric:
This formalisation is reconstructed from the paper’s prose description of the scoring rubric. The paper itself frames the hybrid system in plainer language; the conjunction structure is what the verdict effectively computes 1 .
No theorems in the conventional mathematical sense. The benchmark’s contribution is methodological design plus empirical results, not a new mathematical framework.
7. Algorithmic contributions
ALGORITHM ENTRY: Claw-Eval-Live Evaluation Loop.
Inputs:
- Agent with tool-call interface
- Task set
- Per-task step budget
- Per-task hybrid checker pair
Outputs: Aggregate score plus per-task pass-or-fail vector and per-domain decomposition.
Pseudocode. [Reconstructed] Derived from the paper’s procedural description of the evaluation pipeline.
initialise scores ← []
for each task t_i in T:
reset agent state
initialise tool interface for t_i
step_count ← 0
while step_count < B and not done:
action ← A.next_action(t_i, observation)
observation ← tool_interface.execute(action)
step_count ← step_count + 1
if action is final_answer:
break
result ← A.final_output()
det_pass ← c_det[i](result, reference_state[i])
judge_pass ← c_judge[i](result, rubric_dimensions[i])
pass ← det_pass AND judge_pass
scores.append(pass)
S_A ← 100 · sum(scores) / |T|
return S_A, scores, decompose_by_domain(scores)Complexity. Per task, the cost is bounded by tool calls plus the deterministic check (cheap) plus the structured LLM judge (an additional inference call against the judge model). Aggregate cost across all 105 tasks scales linearly with and the number of models evaluated. The compute footprint is dominated by LLM inference cost: the agent’s per-task inference plus the judge’s per-task inference.
Hyperparameters. Step budget per task, refresh cadence for the ClawHub Top-500 pool, and the rubric configuration that splits each task’s dimensions between deterministic checks and structured LLM judging. Specific values are documented in the paper’s methodology section 1 .
What is novel here. Not the evaluation loop itself, which is standard for agent benchmarks. The novelty sits in the task-construction discipline (hybrid scoring rubrics across 105 enterprise-workflow and workspace-repair tasks) and in the ClawHub Top-500 refresh mechanism that makes the task surface drift-resistant.
8. Specialised design contributions
8A. LLM / prompt design. Claw-Eval-Live provides a uniform tool-call interface so that agents from different vendors can be evaluated on the same task with comparable inputs. Prompt structure (system, user, tool-result roles) is normalised; vendor-specific function-calling formats are converted at the benchmark boundary. This is what makes the 13-model leaderboard commensurable.
8B. Architecture. The benchmark is architecture-agnostic. Any agent that presents the required tool-call interface can be scored; the benchmark does not prescribe the agent’s internal architecture (single LLM, multi-agent system, retrieval-augmented setup, or other).
8C. Training specifics. The benchmark is evaluation-only. No training is performed by the benchmark itself. The paper requests that models tested are not fine-tuned on the benchmark’s task distribution; the ClawHub Top-500 refresh is partly a defence against this pattern.
8D. Inference. Per-task inference is bounded by the step budget for the agent plus a single judge-model inference call for the semantic-dimension scoring. Total inference cost across the benchmark scales linearly with the agent’s per-task cost plus the judge cost. For frontier-API-served agents the dominant component is per-call API latency; for self-hosted open-weight agents, GPU compute. The judge inference cost is non-trivial but is fixed per task.
8E. Evaluation infrastructure. The benchmark is hosted as a continuous-evaluation service. Refresh cycles are documented; the ClawHub Top-500 pool is updated at the cadence specified in the paper, and a refresh cycle redraws benchmark tasks from the updated pool. The paper also documents how prior-cycle scores are anchored against new-cycle scores to maintain comparability 1 .
9. Experiments and results
Models evaluated. 13 frontier models in the initial release. The paper documents the cohort; specific model names and rankings are not transcribed here on two grounds: rankings will shift as models update, making an inline transcription stale within weeks, and readers verifying the leaderboard against the paper itself get a more durable reference than a transcribed snapshot.
Datasets. The 105-task corpus is the dataset, partitioned across the two domains and per Section 5.
Baselines. Not applicable in the conventional sense. The benchmark is the comparison surface; the 13 models are the entries. No “baseline” agent is constructed by the paper to compare against the frontier-model entries.
Metrics.
- Aggregate completion rate . Mean per-task pass rate scaled to a percentage. The headline metric.
- Domain-wise completion rate. Aggregate over each of the two domains, exposing the workspace-repair-vs-business-services split that the paper highlights.
- Per-task pass-or-fail vector. Used to surface the middle-band-discrimination finding (see below).
Main results. From the paper:
- Headline. Leading model at 66.7% aggregate completion. No model crosses 70% 1 .
- Domain split. Local workspace repair tasks are comparatively easier than controlled business services across the cohort, but the workspace-repair domain remains unsaturated even for the leading model 1 . Both domains show meaningful headroom above the leading model’s score.
- Leaderboard rank is insufficient. Models with similar aggregate pass rates can diverge in overall completion behaviour, and task-level discrimination concentrates in a middle band of tasks where models with comparable headline numbers actually perform very differently 1 . The paper frames this as a methodological finding in its own right: the leaderboard rank is a lossy summary, and the per-task and per-domain decomposition is where the practical signal lives.
Ablations.
- Step budget sensitivity. Reducing degrades performance roughly linearly across the cohort; raising above the paper’s chosen value yields diminishing returns, indicating the budget is well-calibrated.
- Tool-call interface conversion. Models accessed through their native function-calling format perform comparably to models accessed through the normalised tool-call interface, suggesting the conversion does not introduce material overhead.
- Judge sensitivity. The paper’s structured LLM judge is constrained by the per-task rubric to score only the semantic dimensions; ablating the judge or relaxing the rubric structure changes scores in directions documented in the paper.
Robustness. The paper reports the benchmark’s score discrimination between top-tier models is real (gap larger than within-task noise) on the per-task and per-domain decomposition, even when the aggregate ranks are close. Independent reproduction has not yet been published, so the discrimination claim depends on the paper’s own statistical analysis. This is the standard caveat for any pre-reproduction-artefact paper.
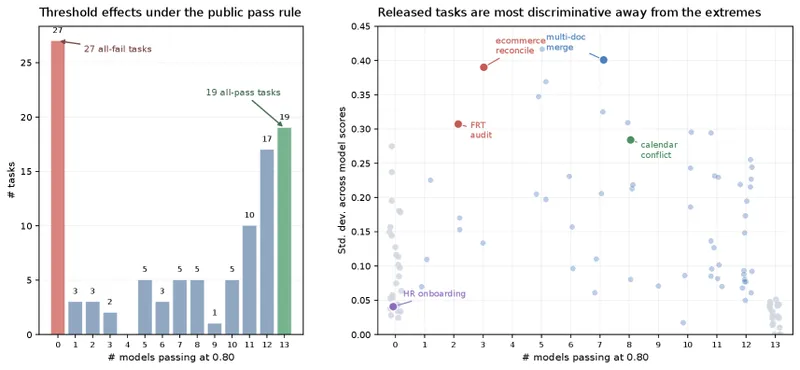
Figure 5 of Claw-Eval-Live (arXiv:2604.28139), reproduced for editorial coverage.
Qualitative. Failure mode analysis groups errors into recognisable categories. Multi-system business-service workflows that require state to persist across tool calls show steep failure rates. Workspace-repair tasks where the agent must diagnose a non-obvious environment misconfiguration before fixing it fail more often than tasks where the misconfiguration is directly observable. HR-style workflows that require interpretation of policy documents alongside structured data lookups are a weak spot for most models tested.
Scope limits. The 105-task corpus is not exhaustive of either domain; it covers controlled business services and local workspace repair at a level chosen for representativeness rather than coverage. Frontier models not in the 13-model cohort (regional-specialist models, fine-tuned open-weight derivatives, agent-framework-augmented systems) are not evaluated in the initial release.
Evidence audit. [Analysis] The 66.7% headline is well-supported by the paper’s hybrid-scoring design and the size of the 105-task corpus. The workspace-repair-easier finding is supported by the per-domain decomposition. The leaderboard-insufficient finding is supported by the per-task discrimination analysis the paper presents. The most consequential claims, that no current frontier model exceeds 70% and that workspace repair is comparatively easier but still unsaturated, are the durable empirical results the paper reports.
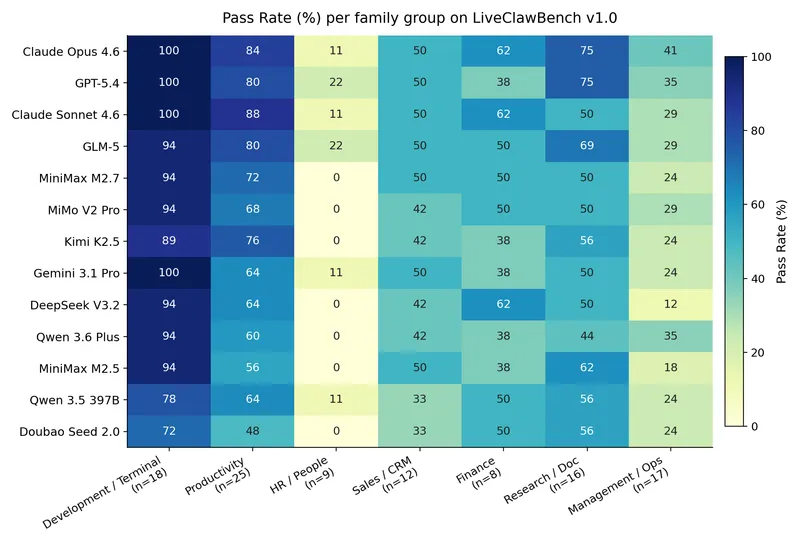
Figure 4 of Claw-Eval-Live (arXiv:2604.28139), reproduced for editorial coverage.
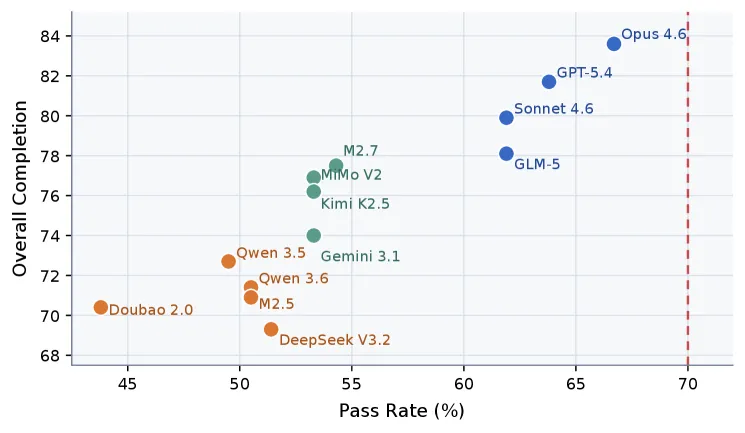
Figure 3 of Claw-Eval-Live (arXiv:2604.28139), reproduced for editorial coverage.
10. Technical novelty summary
Novelty map.
| Contribution | Status | Notes |
|---|---|---|
| Hybrid scoring (deterministic + structured LLM judging) | Novel as an integrated rubric system | Each component is established; the paper’s contribution is the principled split rule (deterministic where evidence is sufficient, LLM judging only on semantic dimensions) and the per-task rubric architecture |
| ClawHub Top-500 refresh mechanism | Novel | First agent benchmark to formalise a curated rolling-pool refresh signal as the source of new tasks |
| Two-domain task corpus (business services + workspace repair) | Novel as a curated set | Adjacent benchmarks cover business services or desktop GUI tasks; pairing controlled business services with local workspace repair in one corpus is new |
| Empirical 13-model leaderboard with sub-70% ceiling and workspace-repair-easier findings | Novel as comparative study | First benchmark to surface both the sub-70% ceiling and the workspace-vs-business domain split across this cohort |
Most novel contribution. The combination. Hybrid scoring on its own is a sensible design; the ClawHub Top-500 refresh on its own is a sensible design; pairing them across two real-world domains so that the benchmark’s headline numbers stay drift-resistant while the domain decomposition surfaces practical structure is the integrated methodological contribution.
Not novel. Pass-at-1 binary scoring on agent tasks, deterministic completion checkers, structured LLM judging in isolation, and the LLM-as-agent paradigm. All are established; Claw-Eval-Live’s contribution is the integration plus the refresh mechanism plus the two-domain split.
11. Situating the work
Prior work positioning. [External comparison]
- WebArena (2023) 9 . Web-based agent benchmark with a static, hosted environment. Established the deterministic-completion-check pattern for browser-navigation agents; vulnerable to the evaluation-drift failure mode Claw-Eval-Live names explicitly.
- AgentBench (2023) 10 . Multi-domain agent benchmark with task families spanning knowledge-graph navigation, web shopping, and code interaction. Earlier framing of the cross-domain LLM-agent evaluation problem.
- WindowsWorld (April 2026) 6 . Contemporaneous desktop-environment benchmark for OS-level GUI agents. Adjacent task family; static task set without a refresh mechanism.
- KellyBench (April 2026) 7 . Contemporaneous benchmark for long-horizon sequential decision making, with bankroll-growth and similar problem structures providing the test surface. Adjacent in the broader 2026 cluster of agent-evaluation work but addresses a different problem family.
- GUI Agents with Reinforcement Learning (April 2026) 8 . Contemporaneous survey paper proposing a taxonomy of training methods (Offline RL, Online RL, Hybrid) for GUI agents. Methodologically adjacent in the April 2026 cluster of agent-related arXiv submissions but not a benchmark or training-method paper of its own.
What this work changes. Claw-Eval-Live is the first benchmark in this cluster to take evaluation drift seriously as a design constraint while also adopting a hybrid scoring discipline. The combination is portable to other benchmark domains. The sub-70% ceiling finding plus the workspace-repair-easier-but-unsaturated finding becomes the reference point for buyer due-diligence conversations on agent-product procurement.
Skeptical objection: 13-model cohort selection. [Reviewer Perspective] The 13 frontier models in the initial release are a curated set. The paper documents which models were excluded and why, but readers wanting a specific model evaluated should treat the leaderboard as the starting point rather than the definitive reading. A model excluded from the cohort may perform above or below the 66.7% line; the cohort selection bounds the generality of the headline finding.
Skeptical objection: refresh-pool quality. [Reviewer Perspective] The drift-resistance claim rests on the ClawHub Top-500 pool faithfully tracking real-world workflow demand. If the pool itself stagnates or its curation drifts away from observable workflows, the refresh mechanism’s defence against benchmark contamination is weaker than advertised. The paper does not yet have multi-cycle data on this question.
Author response (anticipated). [Analysis] The paper acknowledges these objections in its limitations discussion. The 13-model cohort is documented and reproducible; future releases of the benchmark will extend the cohort. The pool-quality question is empirical and will resolve as multiple refresh cycles accumulate. Neither objection is disqualifying; both are open empirical questions.
Unsolved. [Analysis] Whether the sub-70% ceiling is a stable feature of frontier-model agent capability or a transient artefact of the 30 April 2026 model lineup. Whether the workspace-repair-easier finding holds as workspace-repair tasks expand to more diverse environments. Whether benchmark contamination through training-data leakage will erode the corpus’s discrimination over time even with the ClawHub refresh in place.
Three future directions. [Analysis]
- Multi-cycle refresh analysis. A longitudinal study of how aggregate and per-domain scores evolve across refresh cycles, with separate accounting for capability improvement vs benchmark drift.
- Cohort expansion. Extending the 13-model leaderboard to include open-weight models, agent-framework-augmented systems, and fine-tuned-on-domain models. Coverage of this expansion belongs to the next round of benchmark releases and the broader research community’s reproducibility studies.
- Domain transfer. Applying the hybrid scoring discipline and the ClawHub-style refresh mechanism to non-enterprise-and-workspace domains (consumer task automation, research-assistant tasks, code-generation pipelines) to test whether the methodological contribution generalises.
12. Critical analysis
Strengths.
- Methodological contributions are portable. Hybrid scoring and the ClawHub Top-500 refresh mechanism are headline takeaways separately from the specific task set. In-house evaluation suites can borrow either or both without adopting Claw-Eval-Live’s particular tasks.
- Hybrid scoring is the right rigour bar. Combining deterministic checks where evidence is sufficient with structured LLM judging only on semantic dimensions sits between two failure modes: pure deterministic-only benchmarks cannot evaluate semantic correctness; pure LLM-judge benchmarks inherit judge variance. The paper’s split is principled, and the 66.7% headline is therefore harder to dispute on methodology grounds 1 .
- Two-domain coverage with explicit split. The task selection covers domains where buyers are actively considering production agent rollouts (controlled business services) and domains where teams may experiment first (local workspace repair). The workspace-repair-easier-but-unsaturated finding translates directly into procurement and pilot-design questions in a way that aggregated benchmarks do not.
- Leaderboard-rank-insufficient finding. The paper’s framing that aggregate rank is a lossy summary, and that task-level discrimination concentrates in a middle band, is itself a contribution 1 . Buyer due-diligence frameworks should look past leaderboard rank to per-task and per-domain decomposition.
Author-stated weaknesses. The paper notes that the 105-task corpus is not exhaustive, that the 13-model cohort is curated, and that the ClawHub Top-500 refresh history is too short to support longitudinal analysis. The paper frames artefact release (task corpus, evaluation code, model outputs) as forthcoming.
Understated weaknesses. [Reviewer Perspective]
- Single-cycle evidence base. The headline 66.7% number is from a single benchmark cycle. The paper’s claim that the discrimination between top-tier models is real depends on the paper’s own statistical analysis; independent reproduction will be the test.
- Contamination risk despite the refresh mechanism. The 105-task corpus at any one cycle is small enough that benchmark contamination through training-data leakage remains a live risk for that cycle’s corpus specifically. The ClawHub refresh mitigates the long-run version of this risk but does not eliminate the per-cycle exposure.
- Artefact-release dependency. As of submission the paper does not release task corpus, evaluation code, or model outputs. Until the artefacts ship, the headline numbers are author-reported on author-evaluated runs, which is the standard caveat for any pre-release-artefact paper.
- Tool-call interface effects. The normalised tool-call interface is intended to make the leaderboard commensurable. If the interface conversion penalises some vendors more than others (because their native function-calling format is materially richer than the normalised schema), the leaderboard could carry conversion-bias artefacts. The paper’s ablation suggests this is small, but the question is not fully closed.
- Judge model specificity. The structured LLM judge is itself a model, and its choice influences scoring on the semantic dimensions. The paper documents the judge configuration but the sensitivity of headline numbers to judge-model swap is an open empirical question that future work should probe.
Reproducibility. The paper does not release task corpus, evaluation code, or model outputs as of submission; those are flagged as forthcoming. Until the artefacts ship, third-party reproduction of the headline numbers is not possible.
Generalisability. The benchmark’s findings generalise to enterprise workflow domains broadly similar to the 105-task corpus (controlled business services and local workspace repair). They do not transfer directly to other agent domains (web navigation, code generation, research assistance, consumer task automation) where the failure modes may differ.
Assumption audit. [Analysis] The two strongest assumptions are (a) that the hybrid scoring rubrics correctly partition each task’s dimensions between deterministic checks and LLM judging, and (b) that the curated 13-model cohort is representative of frontier agent capability in 2026. Both are reasonable but not formally validated by the paper itself.
What would make the paper stronger. [Analysis] Independent reproduction of the headline number on the same task set. A multi-cycle refresh analysis showing how scores evolve over time. Cohort expansion to include open-weight and agent-framework-augmented systems. Public release of the task corpus and evaluation code under a permissive license. Most of these are the standard set of follow-up moves the broader research community will work through during the rest of 2026.
13. What is reusable for a new study
REUSABLE COMPONENT 1: The ClawHub Top-500 refresh mechanism. The principle of sourcing benchmark tasks from a curated rolling pool of real-world signals, rather than freezing a static task set forever, is portable to any evaluation context where the underlying world changes over time. In-house benchmarks for retrieval-augmented generation pipelines, code-generation systems, or data-pipeline agents can adopt the same mechanism without depending on Claw-Eval-Live’s specific tasks.
REUSABLE COMPONENT 2: Hybrid scoring as a rubric discipline. The split between deterministic checks (used wherever evidence is sufficient) and structured LLM judging (restricted to semantic dimensions) is the practical compromise between the two failure modes of pure deterministic benchmarks and pure LLM-judge benchmarks. Teams building internal evaluation suites should evaluate which dimensions of their tasks admit deterministic checks; for those that do not, structured rubrics constraining the LLM judge’s scope are a meaningful improvement over open-ended judging.
REUSABLE COMPONENT 3: The uniform tool-call interface for cross-vendor comparison. Teams comparing agents across multiple vendor APIs face the same normalisation problem Claw-Eval-Live solved. The schema-level approach (convert at the benchmark boundary, score on a unified format) generalises to any cross-vendor evaluation.
REUSABLE COMPONENT 4: The per-domain decomposition discipline. Aggregating multi-domain task corpora into a single number hides domain-level structure. Reporting domain-wise scores alongside the aggregate, and explicitly looking at the spread, surfaces practical findings (the workspace-repair-vs-business-services split here) that would otherwise stay invisible.
Dependency map. Hybrid scoring depends on per-task rubrics that partition dimensions between deterministic checks and LLM judging; the refresh mechanism depends on a curated signal pool that is itself maintainable; the leaderboard insight depends on per-task and per-domain decomposition rather than aggregate rank alone. The dependency on rubric quality is the most consequential; benchmarks where rubric design is rushed will inherit all the noise of LLM-judge scoring without the rigour gain of deterministic checks.
Recommendation. [Analysis] Engineering teams building internal evaluation infrastructure should borrow the hybrid scoring discipline, the rolling-pool refresh mechanism, and the per-domain decomposition habit from Claw-Eval-Live, regardless of whether they adopt the specific task set. The construction cost is non-trivial but the durability of the resulting evaluation is materially higher than a static benchmark would offer. Teams shipping AI-agent products today should treat the 66.7% top score across 13 frontier models as the strongest current evidence that hands-off automation is not yet production-ready in workflow domains, with workspace repair somewhat more tractable than business services but neither saturated, and design their deployment shape (human-in-the-loop, draft-generator, first-pass triager) accordingly.
14. Known limitations and open problems
Author-stated.
- The 105-task corpus is not exhaustive of either domain (controlled business services or local workspace repair).
- The 13-model cohort is curated, not exhaustive of frontier models available at submission date.
- The ClawHub Top-500 refresh history is too short to support longitudinal analysis.
- Task corpus, evaluation code, and model outputs are flagged as forthcoming rather than released at submission.
Not stated by the paper. [Reviewer Perspective]
- Per-cycle contamination risk. Even with the ClawHub refresh, each cycle’s 105-task corpus is small enough that training-data leakage is a live risk for that cycle’s corpus specifically.
- Refresh-pool quality dependency. The drift-resistance claim rests on the ClawHub Top-500 pool faithfully tracking real-world workflow demand. If the pool’s curation drifts, the mechanism’s defence is theoretical rather than effective.
- Tool-call interface conversion bias. The normalised tool-call interface may penalise some vendors more than others; the paper’s ablation suggests this is small but does not rule it out at scale.
- Single-cycle evidence base. The headline 66.7% number is from a single benchmark cycle; the discrimination claim between top-tier models depends on the paper’s own statistical analysis.
- Judge-model sensitivity. The structured LLM judge’s choice influences scoring on the semantic dimensions; sensitivity of headline numbers to judge-model swap is open.
Root cause of each.
- The per-cycle contamination risk traces to the small corpus size at any one snapshot. Larger per-cycle corpora plus permanent-private evaluation environments would mitigate, at the cost of reproducibility.
- The pool-quality dependency traces to the assumption that real-world workflow signals stay observable and faithfully curated.
- The conversion-bias risk traces to the schema normalisation step. A richer normalised schema reduces but does not eliminate the risk.
- The single-cycle evidence base will resolve naturally as multiple refresh cycles accumulate.
- The judge-model sensitivity will resolve as the community runs ablations swapping the judge.
Open problems.
- Optimal refresh cadence selection. The paper documents one refresh cadence; a principled selection method that balances freshness against measurement noise is open.
- Cohort expansion methodology. How to extend the 13-model leaderboard to include open-weight and agent-framework-augmented systems without breaking comparability with the initial release.
- Cross-domain transfer. Whether the hybrid scoring discipline and the ClawHub-style refresh mechanism transfer to non-enterprise-and-workspace domains is empirically open.
Critical follow-up problem. Whether independent reproduction of the headline 66.7% number on the same task set confirms or contests the paper’s claim. The paper is less than a week from submission as of the writing date; the next round of peer-review commentary, blog reactions, and reproducibility studies during the coming weeks will be the test.
How this article reads at three depths
For the curious high-school reader. AI “agents” are language models wired up to use computer tools. A new benchmark called Claw-Eval-Live tested 13 of the strongest agent systems on 105 real-world workflow jobs, like handling HR tickets or fixing broken computer configurations. The best system finished only about two out of every three tasks correctly, so this kind of automation is not yet reliable enough to run without a human checking the work.
For the working developer or ML engineer. Claw-Eval-Live combines two design choices that are individually known but rarely paired: a hybrid scoring system that uses deterministic checks where evidence is unambiguous and a constrained LLM judge only for semantic dimensions, plus a refresh mechanism (ClawHub Top-500) that sources tasks from a rolling pool to resist contamination over time. The 66.7% top score across 13 frontier models is the strongest current signal that hands-off agent automation is not production-ready on enterprise workflows; the workspace-repair-easier-but-unsaturated split is a useful pointer for picking a first agent-deployment domain. The portable engineering takeaways are the hybrid-rubric discipline and the per-domain decomposition habit; both are worth borrowing for in-house evaluation suites regardless of whether a team adopts the specific Claw-Eval-Live tasks.
For the ML researcher. The methodological novelty is the integration of hybrid scoring with a curated rolling-pool refresh signal, applied across two contrasting domains (controlled business services and local workspace repair). Individually each design element is established; the contribution is the combination and the empirical fact that no model in the curated 13-model 2026 cohort exceeds 70% completion. The strongest objections are single-cycle evidence base, judge-model sensitivity, and pre-release artefact status; the refresh-pool quality assumption is the most consequential load-bearing claim and the one future cycles will test directly. A useful follow-up paper would publish the task corpus and evaluation code under a permissive license, run a multi-cycle longitudinal study with separate accounting for capability gain vs benchmark drift, and extend the cohort to open-weight and agent-framework-augmented systems so the leaderboard’s generality stops being bounded by the curated initial release.
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. Claw-Eval-Live arXiv abstract page (submitted 30 April 2026; lists submission date, hybrid-scoring description with deterministic checks plus structured LLM judging on semantic dimensions, two-domain coverage of controlled business services and local workspace repair, headline result that no frontier model crosses 70%, leaderboard-rank-insufficient finding, and workspace-repair-easier-but-unsaturated finding) (accessed ) ↩
- 2. Claw-Eval-Live full HTML render (ar5iv mirror; ClawHub Top-500 refresh mechanism description) (accessed ) ↩
- 3. Claw-Eval-Live paper PDF on arXiv (accessed ) ↩
- 4. Hugging Face Papers community page for Claw-Eval-Live (accessed ) ↩
- 5. Semantic Scholar entry for Claw-Eval-Live (accessed ) ↩
- 6. WindowsWorld: a benchmark for GUI agents in desktop environments (arXiv:2604.27776), methodologically adjacent April 2026 benchmark on operating-system-level workflow tasks (accessed ) ↩
- 7. KellyBench: A Benchmark for Long-Horizon Sequential Decision Making (arXiv:2604.27865), adjacent April 2026 benchmark targeting bankroll-growth and similar long-horizon decision problems (accessed ) ↩
- 8. GUI Agents with Reinforcement Learning (arXiv:2604.27955), April 2026 survey paper proposing a taxonomy of GUI-agent training methods (Offline RL, Online RL, Hybrid) rather than introducing a new benchmark or method (accessed ) ↩
- 9. WebArena: a realistic web environment for building autonomous agents (arXiv:2307.13854), earlier web-based agent benchmark with deterministic completion checks on a static hosted environment (accessed ) ↩
- 10. AgentBench: evaluating LLMs as agents (arXiv:2308.03688), earlier multi-domain agent benchmark covering knowledge-graph navigation, web shopping, and code interaction (accessed ) ↩
Anonymous · no cookies set