Vision-Language Model Benchmarks: A Multi-Paper Reference (MMMU, MathVista)
Technical reference on vision-language model benchmarks. Walks MMMU (Yue, CVPR 2024) and MathVista (Lu, ICLR 2024) — what each catches, where leaderboards mislead.
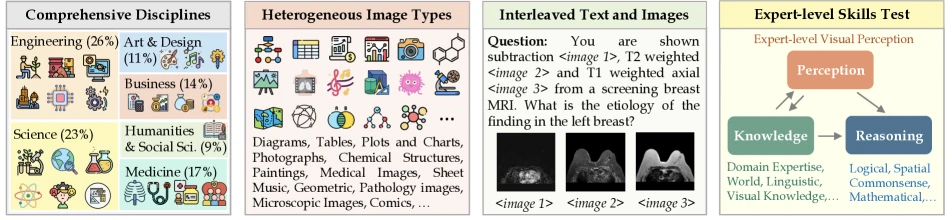
Figure 1 of MMMU (arXiv:2311.16502), reproduced for editorial coverage.
1. Paper identity and scope
Primary citations.
- Yue, X., Ni, Y., Zhang, K., Zheng, T., et al. “MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI.” arXiv:2311.16502, CVPR 2024 Oral 1 .
- Lu, P., Bansal, H., Xia, T., Liu, J., et al. “MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts.” arXiv:2310.02255, ICLR 2024 3 .
Retrieval. This review draws on the arXiv abstract pages 1 3 , the ar5iv HTML renders 2 4 , the MMMU and MathVista project pages 5 6 , and the OpenCompass community leaderboard 7 .
Classification. Evaluation benchmark, vision-language models, expert-level multimodal reasoning. Both papers introduce benchmark datasets rather than new architectures; the contributions are the dataset designs, the annotation methodologies, and the published baselines.
Technical abstract (in the publication’s voice). Vision-language models (VLMs) — GPT-4V, Gemini, Claude with vision, LLaVA-family 8 , and the open-weights tier (InternVL, Qwen-VL, MiniCPM-V) — saturated existing visual question-answering benchmarks rapidly through 2023-2024. The community needed harder benchmarks that distinguished frontier capability from “good enough for VQA”. MMMU (Yue 2024, CVPR Oral) introduces 11.5K college-level multimodal questions spanning six disciplines (Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, Tech & Engineering) and 30 subjects, with heterogeneous image types (charts, diagrams, maps, tables, music sheets, chemical structures, geometry figures). At release, GPT-4V scored 56% and Gemini Ultra 59%, demonstrating substantial headroom against expert-human performance 1 . MathVista (Lu 2024, ICLR) focuses specifically on mathematical reasoning in visual contexts: 6,141 examples drawn from 28 existing multimodal datasets plus three newly-created subsets (IQTest, FunctionQA, PaperQA), spanning figure question answering, geometry problem solving, math word problems, textbook question answering, and visual question answering. At release, GPT-4V scored 49.9%, Bard 34.8%, while human performance was around 60.3% 3 .
Primary research questions.
- (MMMU) How well do frontier VLMs perform on the kind of expert-level multimodal reasoning that human college students routinely handle, and what aspects of multimodal understanding distinguish frontier models from open-tier baselines?
- (MathVista) How accurately do VLMs handle visual-mathematical reasoning specifically — interpreting figures, geometry diagrams, function plots, scientific charts — when the question requires both perception and mathematical inference?
Core technical claims.
- MMMU. A carefully-constructed benchmark of 11.5K college-level multimodal questions across 30 subjects exposes a substantial frontier-VLM gap to expert human performance (~30+ percentage points at release), demonstrating that “broadly competent VLM” is not yet “expert-level reasoning” 1 .
- MathVista. Visual-mathematical reasoning is a distinct capability axis from text-only mathematical reasoning, and frontier VLMs at release exhibited a substantial gap from human performance (49.9% vs 60.3% for GPT-4V) that decomposes into visual perception failures and reasoning failures in approximately equal measure 3 .
Core technical domains.
| Domain | Depth required |
|---|---|
| Vision-language model architecture (CLIP-style + LLM backbone) | Moderate |
| Visual question answering as a task formulation | Moderate |
| Benchmark contamination and held-out evaluation | Deep |
| Image categorisation and annotation pipelines | Moderate |
| Multimodal chain-of-thought | Moderate |
| Multiple-choice vs free-response evaluation | Moderate |
Reader prerequisites. Knowing that a VLM takes both an image and a text prompt and produces a text response, that the standard VQA task asks a question about an image, and that “multimodal” in this context refers to text + image input.
How this review marks its registers.
- Author-stated /
[From the paper]— direct claims from either benchmark paper. - Facts — background facts (VLM architecture, prior benchmark history).
- AI analysis /
[Analysis]— the pipeline’s reasoned synthesis. - Reviewer perspective /
[Reviewer Perspective]— independent commentary, including contamination caveats.
2. TL;DR and executive overview
TL;DR. MMMU and MathVista are the two most-cited 2023-2024 VLM benchmarks that explicitly target capability gaps invisible on older VQA suites. MMMU covers college-level multi-discipline reasoning across 30 subjects; MathVista covers visual mathematical reasoning specifically. Together they form the de-facto “if your VLM can handle these, it’s frontier-grade” pair on the OpenCompass leaderboard and most VLM model cards in 2024-2026.
Executive summary. Pre-2023 VLM evaluation centered on VQAv2 (image-grounded question answering), GQA (compositional reasoning), TextVQA (OCR-heavy), and similar benchmarks. By 2023, frontier VLMs had saturated these — VQAv2 accuracy approached the inter-annotator agreement ceiling. The community needed harder targets. Three responses emerged in late 2023 / early 2024:
- MMMU (CVPR 2024 Oral) 1 — broad-coverage benchmark at college expert level. 11.5K questions, 30 subjects, heterogeneous image types.
- MathVista (ICLR 2024) 3 — depth in mathematical visual reasoning. 6,141 questions across 5 visual-math task types.
- MMBench 10 and MM-Vet 11 — capability-axis benchmarks (perception, knowledge, reasoning) and integrated-capability evaluation.
MMMU and MathVista became the most-cited of these because (a) both were peer-reviewed at top venues (CVPR Oral, ICLR), (b) both included human-performance baselines that gave clear “headroom” numbers, and (c) both released active project sites that maintain leaderboards across the rapidly-evolving model landscape. In 2026, every major VLM release (Claude 3.5 Sonnet, GPT-5o, Gemini 2.5 Pro, Qwen2.5-VL, InternVL3) reports MMMU and MathVista accuracy as part of the standard model-card disclosure 7 .
Five practitioner-relevant takeaways.
- MMMU’s 30-subject structure is the contribution; the absolute scores age fast. [From the paper] MMMU’s value is the axis decomposition — by-subject and by-discipline error rates expose which capabilities a VLM has and lacks. At release, GPT-4V’s worst disciplines were Business and Science; by 2025-2026 these gaps had closed substantially while Health & Medicine remained a relatively-harder axis across models 1 .
- MathVista’s project site maintains a live leaderboard. The MathVista benchmark is actively maintained at mathvista.github.io 6 ; new models report through the official protocol. This is the canonical place to look up current SOTA on visual-mathematical reasoning.
- Contamination is the elephant. [Reviewer Perspective] Both benchmarks have been public since late 2023 / early 2024. Modern VLMs trained on 2024-2025 data have very likely seen problem variants. MMMU-Pro 12 is the 2024 follow-up explicitly designed for contamination resistance; readers should prefer MMMU-Pro scores when published.
- Both benchmarks use multiple-choice as the primary format. [From the paper] This is methodologically clean but can be gamed: a confused model can guess and score 25% baseline; an honest free-response evaluation would expose this floor more clearly. Both papers report multiple-choice plus open-answer subsets to mitigate.
- [Analysis] The benchmarks favour models with strong text reasoning. Both MMMU and MathVista have problems where the image carries auxiliary information and the question’s reasoning is mostly text. Models with strong base-LLM reasoning capability (Claude Sonnet, GPT-5o) outscore models with stronger visual perception but weaker text reasoning on the overall benchmark.
Pipeline overview. Both papers describe a benchmark dataset and an evaluation protocol; neither introduces a new architecture. The evaluation is forward-pass-only at inference time on the released question sets.
2.5. Glossary
| Term | Plain-English explanation | First appears in |
|---|---|---|
| Vision-Language Model (VLM) | A model that takes both an image and text input and produces a text output. GPT-4V, Claude vision, Gemini, LLaVA are VLMs. | Section 1 |
| Visual Question Answering (VQA) | The standard task: given an image and a question about it, produce an answer. | Section 1 |
| Multimodal | Input combining multiple modalities; here, text + image. | Section 1 |
| Multiple-choice evaluation | The model picks one of N predefined answer options; cheap to grade but allows guessing. | Section 2 |
| Free-response evaluation | The model produces an open-ended answer; harder to grade but more honest. | Section 2 |
| Inter-annotator agreement | The rate at which two human annotators agree on the same example; the practical ceiling for benchmark accuracy. | Section 2 |
| Contamination | When the benchmark questions or close paraphrases appear in the model’s training data, inflating measured accuracy. | Section 9 |
| Expert AGI | The aspirational target MMMU was designed to evaluate: AI systems capable of college-expert-level reasoning across disciplines. | Section 1 |
| Chain-of-thought (CoT) for VLMs | Asking the VLM to write reasoning steps before the final answer, often improves accuracy on math/reasoning visual tasks. | Section 4 |
| MMMU-Pro | The 2024 follow-up to MMMU explicitly designed for contamination resistance: filters questions answerable from text alone, augments with vision-only variants. | Section 11 |
| OCR (Optical Character Recognition) | The capability to read text in images. Distinct from understanding the meaning of the text. | Section 5 |
| FQA / GPS / MWP / TQA / VQA | MathVista’s five task categories: Figure QA, Geometry Problem Solving, Math Word Problem, Textbook QA, Visual QA. | Section 5 |
[From the paper] prefix | Default register. | Throughout |
3. Problem formalisation
Notation table.
| Symbol | Type | Meaning | First appears in |
|---|---|---|---|
| Image | A single input image (or a small set in interleaved questions) | Section 3 | |
| Text | Question prompt | Section 3 | |
| Text | Ground-truth answer | Section 3 | |
| Text | Model’s predicted answer | Section 3 | |
| Set | Benchmark question set | Section 3 | |
| Function | Accuracy metric (exact match for multiple-choice; normalized match for free-response) | Section 3 | |
| Scalar | Expert-human baseline accuracy | Section 8 |
Formal problem statement (benchmark evaluation). Given a VLM and benchmark , compute
where is the appropriate equivalence (exact match, normalized text match, or numerical-tolerance match).
Explicit assumption list.
- Closed evaluation set. The benchmark questions are fixed and public; no held-out test set with private answers (MMMU-Pro adds a partial held-out variant).
- No tools, no external retrieval. Standard evaluation forbids the model from looking up answers or using external tools; “VLM solving the question end-to-end” is the unit.
- Single forward pass per question. Standard protocol; self-consistency / best-of-N is not in the standard reported number but appears in many papers as an additional column.
- English-language questions. Both benchmarks are English-only at release; multilingual variants exist as follow-ups.
Why the problem is hard. Designing a benchmark that (a) cannot be solved without visual reasoning, (b) is not contaminated in pretraining data, (c) admits clean evaluation (low inter-annotator disagreement), and (d) covers the relevant capability surface — the four constraints are in tension. MMMU and MathVista make different trade-offs against these constraints.
LLM-based positioning. The benchmarks evaluate VLMs as systems; they treat the model as a black box. Architecture comparisons (encoder-vs-decoder, vision tower choices, projection-layer designs) are out of scope.
4. Motivation and gap
Real-world problem. As VLMs become deployed in education, accessibility, healthcare imaging triage, and document-understanding products, the question “is this VLM good enough for production task X?” requires a benchmark axis that maps to real downstream tasks. VQAv2-style benchmarks systematically overstated deployable capability because the questions were structurally simpler than real downstream queries.
Existing approaches (pre-2023).
- VQAv2 (Goyal 2017) — image-grounded yes/no, what-is-this questions. Saturated by 2022.
- TextVQA (Singh 2019) — OCR-heavy visual QA. Largely solved by 2023.
- OK-VQA (Marino 2019) — questions requiring external knowledge. Solved by knowledge-rich LLMs after CLIP-style alignment.
- MMLU (Hendrycks 2021) 9 — text-only multi-discipline benchmark; the conceptual sibling that MMMU explicitly extends to multimodal.
Gap. A college-expert-level multimodal benchmark covering broad disciplines, where the image is required (not decorative), with substantial headroom against frontier models. MMMU fills this. A visual-mathematical-reasoning benchmark with specific task subcategories and reported human performance. MathVista fills this.
[External comparison] Position vs MMBench / MM-Vet. MMBench 10 (Liu 2024) decomposes capability along 20 axes (perception, reasoning, attribute identification, etc.); MM-Vet 11 (Yu 2024) evaluates integrated capabilities (problems requiring multiple axes simultaneously). MMMU is broader (30 subjects) and more discipline-organised; MathVista is deeper on one capability (visual math). The four benchmarks are complementary rather than substitutes; modern model cards report all four.
5. Method overview — MMMU
[From the paper, Section 3] MMMU’s construction process:
Discipline taxonomy. 30 subjects across 6 disciplines:
- Art & Design (Art, Design, Music, Art History)
- Business (Accounting, Economics, Finance, Manage, Marketing)
- Science (Biology, Chemistry, Geography, Math, Physics)
- Health & Medicine (Basic Medicine, Clinical Medicine, Diagnostics, Pharmacy, Public Health)
- Humanities & Social Science (History, Literature, Sociology, Psychology)
- Tech & Engineering (Agriculture, Architecture, CS, Electronics, Energy, Materials, ME)
Question sourcing. College-textbook questions, college-quiz-bank items, free-response questions converted to multiple-choice via expert review. Total 11,550 questions in the released benchmark.
Image heterogeneity. [From the paper] 30+ image types: photographs, paintings, charts, plots, tables, chemical structures, geometry figures, music sheets, sheet music, maps, medical scans, diagrams.
Annotation pipeline. Each question annotated for: subject, image-type, difficulty (introductory / intermediate / advanced), question-type (single-choice / multi-choice / open-response). Expert annotators (graduate students in the relevant field) verified each.
Evaluation protocol. Multiple-choice with normalised exact-match grading. Models are prompted with the question text + image, optionally including chain-of-thought system prompt. Score: percent correct overall, plus per-discipline and per-subject breakdowns.
[Analysis] The construction pipeline’s clearest contribution is the axis decomposition — the by-subject and by-discipline accuracy breakdown reveals capability shape, not just an overall score.
5b. Method overview — MathVista
[From the paper, Section 3] MathVista’s construction:
Task taxonomy. Five task categories 3 :
- Figure Question Answering (FQA) — interpreting bar charts, line graphs, scatter plots.
- Geometry Problem Solving (GPS) — diagrams requiring angle/area/length computation.
- Math Word Problem (MWP) — text-and-image word problems with a visual component.
- Textbook Question Answering (TQA) — questions drawn from textbook problem sets with figures.
- Visual Question Answering (VQA) — visual reasoning questions with mathematical content.
Source datasets. 28 existing multimodal datasets plus 3 newly-created (IQTest for visual reasoning, FunctionQA for function-plot interpretation, PaperQA for academic figure interpretation). Total 6,141 examples in the released benchmark.
Mathematical reasoning skills. [From the paper] Each example is annotated with the specific mathematical skill it tests: algebraic reasoning, arithmetic, geometry, logical reasoning, numeric commonsense, scientific reasoning, statistical reasoning.
Evaluation protocol. Mix of multiple-choice and free-response. Free-response uses normalised numerical comparison with tolerance. The official evaluation harness (mathvista.github.io) 6 handles the protocol.
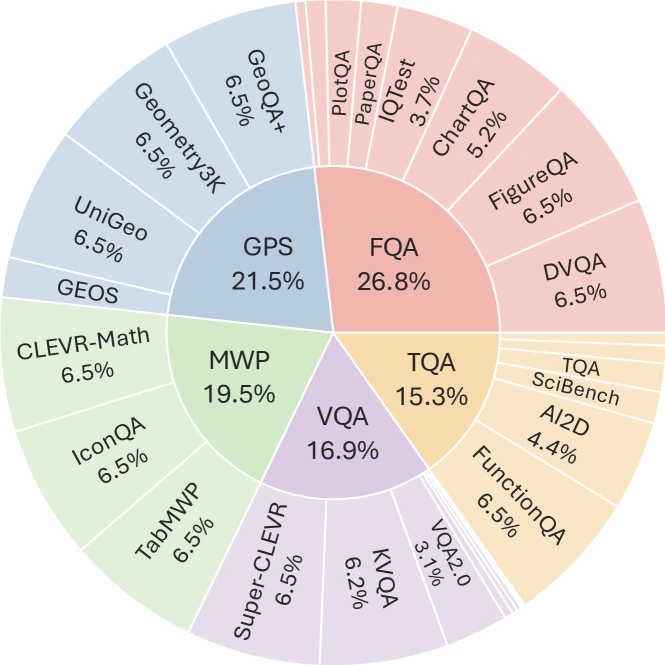
Figure 3 of MathVista (arXiv:2310.02255), reproduced for editorial coverage.
6. Mathematical contributions
MATH ENTRY 1: Accuracy and macro-averaged accuracy.
- Source: Both papers, evaluation protocol sections.
- What it is: the standard metrics; the distinction matters for axis-imbalanced benchmarks.
- Formal definitions.
where the macro version averages over discipline / subject buckets .
-
Each term explained.
- Micro: every example counts equally.
- Macro: every discipline counts equally; small disciplines weigh as much as large.
-
Worked numerical example. Suppose MMMU’s 6 disciplines have 1500, 2000, 2500, 1800, 1750, 2000 questions respectively. A model scores (60, 70, 50, 55, 75, 65) per discipline.
- Micro: weighted by counts. or 63.3%.
- Macro: or 62.5%.
Small per-discipline differences can flip leaderboard ordering between micro and macro. MMMU reports both; community leaderboards usually default to micro.
-
Edge cases. If a discipline has very few questions, macro overweights its accuracy (or inaccuracy). The MMMU paper reports per-discipline counts so macro vs micro comparisons are calibratable.
MATH ENTRY 2: MathVista’s mixed-format evaluation.
- Source: MathVista Section 4.
- What it is: a normalised match metric that accommodates both multiple-choice and free-response.
- Formal definition. For example with format :
with tolerance typically 0.01 (1% relative) for numerical answers.
- Worked numerical example. For a FR-numerical question with , model answer . Difference , relative . Counts as correct. For , relative . Counts as incorrect.
- [Analysis] The tolerance choice () is reasonable for most math problems but problematic for highly-precise numerical questions (where is too loose) and for problems where small rounding shifts matter. MathVista’s per-task subscores should be read in this light.
MATH ENTRY 3: Human-VLM gap as a benchmark-quality indicator.
- Source: Both papers’ Sections 5-6.
- What it is: the headroom metric.
- Formal definition.
where is expert-human accuracy on the benchmark.
- Headroom interpretation. Benchmarks with large positive gap (human > VLM) are useful for differentiating frontier models; benchmarks with gap near zero are saturated and useless for distinguishing frontier from sub-frontier.
- Worked example. MMMU at release: GPT-4V 56%, Gemini Ultra 59%, expert human ~89%. Gap 30 percentage points — substantial headroom. MathVista at release: GPT-4V 49.9%, expert human 60.3%. Gap 10.4 percentage points — moderate headroom. [Analysis] By mid-2026, the MMMU gap has narrowed (frontier VLMs scoring in the high 70s) but not closed; the MathVista gap has narrowed less because the visual-mathematical reasoning axis improved more slowly than the broad-multidiscipline axis.
7. Algorithm trace
[From the paper] Evaluation pipeline trace on a single MMMU question.
Inputs. Question + image from the Science → Physics subject.
Question text: “The figure shows a circuit with three resistors in parallel. Each resistor has resistance R = 10 ohms. What is the equivalent resistance of the parallel combination?” Image: A schematic of three resistors in parallel. Options: (A) 30 ohms, (B) 10 ohms, (C) 3.33 ohms, (D) 0.3 ohms.
Step 1. Format the prompt. Standard MMMU protocol:
You are answering a multimodal multiple-choice question.
[Image]
Question: ...
Options:
A. 30 ohms
B. 10 ohms
C. 3.33 ohms
D. 0.3 ohms
Answer:Step 2. Model forward pass. The VLM processes the image through its vision encoder, encodes the prompt through its text tokeniser, and generates a response.
Step 3. Response parsing. Typical responses are a single letter (“C”) or a full sentence (“The answer is C, 3.33 ohms”). The MMMU evaluator extracts the letter via regex.
Step 4. Grade. Extracted “C” matches ground-truth “C”. Score = 1 for this example.
Step 5. Aggregate. After all 11,550 questions, compute micro accuracy. Decompose by subject: Physics 65%, Chemistry 58%, Biology 71%, Math 52%, Geography 67%. Decompose by image type: schematic 60%, chart 70%, photograph 55%.
[Analysis] What this trace exposes. The benchmark’s value isn’t the overall accuracy number; it’s the decomposition. A model that scores 60% overall but 90% on charts and 30% on chemical structures has a very different capability shape than a model that scores 60% with uniform per-subject accuracy. The decomposition is the actionable signal for downstream use.
8. Results and benchmarks (at release)
[From the paper] MMMU baseline results at release (late 2023 / early 2024) 1 :
| Model | MMMU validation | MMMU test |
|---|---|---|
| Expert human | 88.6% | — |
| Average human | 76.2% | — |
| Gemini Ultra | 59.4% | 59.4% |
| GPT-4V | 56.8% | 55.7% |
| Claude 3 Sonnet | 53.1% | — |
| Open-tier (LLaVA-NeXT-34B) | 51.1% | — |
[From the paper] MathVista baseline results at release 3 :
| Model | MathVista testmini |
|---|---|
| Expert human | 60.3% |
| GPT-4V | 49.9% |
| Bard | 34.8% |
| GPT-4 (text-only, with image caption fallback) | 33.2% |
[Analysis] By mid-2026, the leaderboards have moved substantially. Frontier VLMs (Claude 3.5 Sonnet, GPT-5o, Gemini 2.5 Pro) score in the high 70s on MMMU and the 70s on MathVista, narrowing but not closing the human-expert gap. Open-tier VLMs (Qwen2.5-VL-72B, InternVL3-78B) score in the high 60s to low 70s on MMMU and mid-60s on MathVista. Readers should check the official MMMU and MathVista project pages 5 6 and the OpenCompass leaderboard 7 for current numbers.
9. Ablations and limitations
[From the paper] Stated limitations (MMMU).
- Multi-choice format. The paper acknowledges this allows guessing; reports a 25% random baseline subtraction is sometimes appropriate.
- Coverage gaps. 30 subjects but not exhaustive; some practical-skill axes (creative writing, instruction-following with images) are underrepresented.
- Annotation imperfections. Some questions have ambiguous answers; the paper reports a small fraction (~2-3%) where two answers could be defended.
[From the paper] Stated limitations (MathVista).
- Source heterogeneity. 28 source datasets mean variable annotation quality across subsets.
- The three new subsets (IQTest, FunctionQA, PaperQA) are small relative to the inherited subsets.
- Numerical-tolerance evaluation can mis-grade certain problem types.
[Reviewer Perspective] Independent limitations.
- Contamination. [Reviewer Perspective] Both benchmarks have been public for 18+ months as of mid-2026. Modern frontier VLMs trained on post-2024 data have very likely seen problem variants — and many of the source datasets (textbook questions, exam banks) have been on the open web for years. The 2024-2026 score improvements partly reflect genuine capability growth, partly reflect contamination. MMMU-Pro 12 is the explicit contamination-resistant follow-up; readers comparing models should prefer MMMU-Pro scores when available.
- Image-essential vs image-decorative questions. [From MMMU-Pro paper] 12 A substantial fraction of MMMU questions can be answered with text alone — the image is decorative rather than essential. MMMU-Pro filters these out; differences between MMMU and MMMU-Pro scores reveal a model’s actual visual-reasoning capability vs text-reasoning capability.
- English-only. Multilingual VLM evaluation is underdeveloped in both papers. CMMMU (Chinese MMMU) and other localisations exist as follow-up benchmarks.
- Static benchmarks age. [Reviewer Perspective] The “what does this benchmark measure” framing assumes the question distribution is fixed. As model capabilities change, the same benchmark can shift from “useful differentiator” to “saturated” without changing a single question. MMMU is approaching the saturation regime for frontier models at the time of writing.
10. Reproducibility
| Artefact | Available? | Source |
|---|---|---|
| MMMU dataset | YES | Hugging Face (MMMU/MMMU) |
| MMMU evaluation harness | YES | github.com/MMMU-Benchmark/MMMU |
| MathVista dataset | YES | Hugging Face (AI4Math/MathVista) |
| MathVista evaluation harness | YES | github.com/lupantech/MathVista |
| Expert-human baselines | YES (reported in paper) | — |
| MMMU-Pro contamination-resistant variant | YES | github.com/MMMU-Benchmark/MMMU-Pro 12 |
| Live leaderboards | YES | mmmu-benchmark.github.io 5 , mathvista.github.io 6 , OpenCompass 7 |
[Analysis] Both benchmarks are reproducibility-strong. The evaluation harnesses are actively maintained and the leaderboards accept community submissions. The main caveat is that “reproducing a number from the paper” means “running the same model checkpoint against the same dataset version”; later VLM checkpoints score differently and the comparison is no longer apples-to-apples.
11. Contemporaneous related work
MMMU vs MMBench 10 . MMBench (Liu 2024) decomposes capability along 20 fine-grained axes (Perception, Reasoning, Logic, Attribute Identification, etc.); MMMU decomposes along discipline / subject. Both are valuable; the choice depends on whether the analysis target is “what does this model know” (MMMU) or “what cognitive operations does this model do” (MMBench).
MMMU vs MM-Vet 11 . MM-Vet (Yu 2024) evaluates integrated capabilities — problems requiring multiple cognitive operations in concert (OCR + math, recognition + spatial reasoning). MMMU’s per-subject decomposition is more interpretable; MM-Vet’s integrated-capability decomposition is closer to real-world task complexity.
MathVista vs ScienceQA (Lu 2022) and ChartQA (Masry 2022). ScienceQA covers K-12 science with diagrams; ChartQA is chart-specific. MathVista subsumes both axes with broader coverage of mathematical reasoning specifically.
MMMU-Pro (2024) 12 . The same-authors follow-up to MMMU. Filters questions answerable from text alone, adds vision-only photographed-screenshot variants, expands answer options from 4 to 10 to reduce guessing baseline. The MMMU vs MMMU-Pro score gap is the cleanest published signal for “how much of a VLM’s MMMU score is genuine visual reasoning vs text-only reasoning.”
12. Reviewer perspective
Reviewer perspective on MMMU. [Reviewer Perspective] CVPR 2024 Oral acceptance signals strong reviewer enthusiasm. The benchmark’s lasting contribution is the axis decomposition — by-subject and by-discipline error analysis — which exposed capability shape in a way that aggregate VQAv2 scores could not. The benchmark’s primary weakness is now contamination; the MMMU-Pro follow-up acknowledges and partly addresses this.
Reviewer perspective on MathVista. [Reviewer Perspective] ICLR 2024 acceptance. The benchmark’s lasting contribution is the explicit task taxonomy (FQA, GPS, MWP, TQA, VQA) which makes the visual-math axis more interpretable than competing benchmarks. The mathematical-reasoning-skill annotation layer (algebraic, arithmetic, geometric, logical, statistical) adds a second analysis dimension that is underexploited in most published evaluations.
Reviewer perspective on combined use in 2026. [Analysis] The de-facto VLM evaluation suite in 2026 includes MMMU (or MMMU-Pro), MathVista, MMBench, MM-Vet, and a recall-stress benchmark like RealWorldQA or MM-Vision. Frontier models report all five plus subject-specific extensions (medical-imaging-VQA for healthcare-targeted models, ChartQA for analytics-focused models). MMMU and MathVista anchor the suite.
[Reviewer Perspective] Open methodological questions.
- Contamination measurement. The community lacks a standard contamination-detection protocol for image-text question pairs. Text-based contamination tests (n-gram overlap, perplexity-based detection) don’t transfer cleanly to multimodal data.
- Live-eval vs static benchmarks. Static benchmarks age; live benchmarks (CLAW-Eval, dynamically-generated questions) are early in development but methodologically promising. The right balance between the two is unsettled.
- Multilingual benchmark coverage. CMMMU, JMMMU, and similar localisations exist but the methodology of “translate-and-replace-image-cultural-context” is inconsistent across efforts.
13. Implications
For applied teams. [Analysis] For VLM deployment decisions, the actionable workflow is: (a) decompose the production task into the capability axes MMMU / MathVista / MMBench / MM-Vet expose, (b) look up per-axis scores on the OpenCompass leaderboard for the candidate models, (c) prefer MMMU-Pro scores where available for honest visual-reasoning assessment, (d) run a small sample of the production-task distribution as a sanity check, (e) ignore the aggregate “overall score” — it’s a marketing number.
For the research community. [Analysis] MMMU and MathVista set the standard for “carefully-constructed multidisciplinary VLM benchmark” in 2024-2026. Future benchmark work should target either (a) cleaner contamination resistance (MMMU-Pro-style filtering), (b) deeper per-axis coverage (medical imaging, accessibility-relevant tasks, low-resource-language imagery), or (c) live-eval mechanisms that resist static-benchmark saturation.
For evaluation methodology. [Reviewer Perspective] The community’s standard “report MMMU and MathVista” practice in model cards is reasonable but should be accompanied by MMMU-Pro for contamination resistance and per-subject decomposition for capability shape. Aggregate scores without decomposition obscure exactly the information that downstream users need.
14. Three-depth summary
The 3-line summary for the curious reader. Vision-language models (VLMs) — AI systems that can look at images and answer questions about them — got really good fast between 2022 and 2024, and we needed harder tests to tell the best ones apart. Two tests, MMMU (college-level reasoning across 30 subjects) and MathVista (visual mathematical reasoning), are now the standard way to judge a VLM. They expose specific weaknesses — like medical-imaging interpretation or geometry — that aggregate scores hide.
The 5-line summary for the working developer. MMMU (Yue 2024, CVPR Oral) and MathVista (Lu 2024, ICLR) are the canonical late-2023 / early-2024 VLM benchmarks that distinguish frontier capability from “good-enough VQA.” MMMU covers 11.5K college-level multimodal questions across 30 subjects in 6 disciplines; MathVista covers 6,141 visual-mathematical-reasoning problems across 5 task categories. At release, frontier models scored 56-59% on MMMU and ~50% on MathVista vs expert-human 89% and 60% respectively. By mid-2026 the gaps have narrowed but not closed. For deployment decisions, decompose by subject / task / capability axis rather than the aggregate number; prefer MMMU-Pro over MMMU when contamination resistance matters; treat both benchmarks as one input among MMBench, MM-Vet, and production-task sanity-check evaluations.
The 5-line summary for the ML researcher. MMMU and MathVista define the 2024-2026 standard for “carefully-constructed expert-level multimodal benchmark.” MMMU’s lasting contribution is its 30-subject discipline taxonomy, which makes by-axis error analysis actionable for capability-shape characterisation; the headline aggregate scores age but the decomposition framework survives. MathVista’s lasting contribution is its 5-task visual-math taxonomy with mathematical-reasoning-skill annotations; the methodology supports finer-grained capability claims than competing visual-math benchmarks. Contamination is the dominant emerging limitation; MMMU-Pro 12 is the contamination-resistant follow-up explicitly designed to address text-only-solvable question filtering. Open methodological questions concentrate on contamination measurement protocols, live-eval mechanisms that resist static-benchmark saturation, and multilingual / culturally-localised benchmark methodology. For follow-up work, the most consequential direction is a standard contamination-detection protocol for multimodal data that the community can adopt across new VLM benchmarks.
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. Yue, Ni, Zhang, Zheng et al. (2024). MMMU. CVPR 2024 Oral. (accessed ) ↩
- 2. MMMU — ar5iv HTML render. (accessed ) ↩
- 3. Lu, Bansal, Xia, Liu et al. (2024). MathVista. ICLR 2024. (accessed ) ↩
- 4. MathVista — ar5iv HTML render. (accessed ) ↩
- 5. MMMU project page. (accessed ) ↩
- 6. MathVista project page. (accessed ) ↩
- 7. OpenCompass VLM Leaderboard. (accessed ) ↩
- 8. Liu, Li, Wu, Lee (2024). LLaVA: Visual Instruction Tuning. NeurIPS 2023 Oral. (accessed ) ↩
- 9. Hendrycks et al. (2021). MMLU. (accessed ) ↩
- 10. Liu, Duan, Zhang et al. (2024). MMBench. (accessed ) ↩
- 11. Yu, Yang et al. (2024). MM-Vet. (accessed ) ↩
- 12. Yue, Zheng, Ni, Wang et al. (2024). MMMU-Pro. (accessed ) ↩
Anonymous · no cookies set