Tree of Thoughts: A Technical Reference on Yao et al. (NeurIPS 2023)
Technical reference on Tree of Thoughts (Yao et al. 2023). Walks through the BFS and DFS variants, Game of 24 and Creative Writing results, and where the claims break.
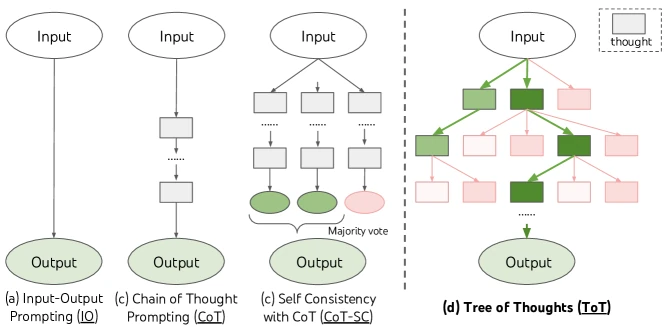
Figure 1 of Tree of Thoughts: Deliberate Problem Solving with Large Language Models (arXiv:2305.10601), reproduced for editorial coverage.
1. Paper identity and scope
Primary citation. Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T. L., Cao, Y., and Narasimhan, K. “Tree of Thoughts: Deliberate Problem Solving with Large Language Models.” NeurIPS 2023; arXiv:2305.10601 1 .
Retrieval. This review draws on the arXiv abstract page 1 , the ar5iv HTML render of the full paper 2 , the arXiv PDF 3 , the NeurIPS 2023 proceedings entry 4 , and the authors’ official implementation repository on GitHub 5 .
Classification. Inference-time procedure; LLM-based; reasoning / search; prompt-design contribution; benchmark-design contribution (Creative Writing and Mini Crosswords as new test-beds for deliberation).
Technical abstract (in the publication’s voice). Tree of Thoughts (ToT) reframes language-model inference as deliberate search over a tree whose nodes are partial reasoning traces called thoughts. Where chain-of-thought 6 emits a single left-to-right sequence and self-consistency 7 samples many such sequences and votes, ToT generates multiple candidate thoughts at each step, asks the same language model to score them, and uses classical breadth-first or depth-first search with that learned heuristic to navigate toward a solution. The paper demonstrates the framework on three tasks: Game of 24, where the GPT-4 chain-of-thought baseline solves 4% of puzzles and ToT solves 74%; a Creative Writing benchmark introduced by the paper where coherency rises from 6.93 to 7.56 on a 1-10 GPT-4-judged scale; and Mini Crosswords, where word-level success rises from a 16% chain-of-thought baseline to 60% under ToT with depth-first search and self-evaluative pruning 1 .
Primary research question. Can a frozen language model solve problems that require search, backtracking, or lookahead by explicitly externalising the search over candidate intermediate steps, rather than relying on a single linear chain of tokens?
Core technical claim. A tree-structured inference procedure with three ingredients, namely (a) a thought decomposition that chunks the problem into discrete reasoning units, (b) a thought generator that proposes candidate next thoughts per state, and (c) a state evaluator that scores each partial state with the same language model, outperforms chain-of-thought and self-consistency on tasks that require non-trivial exploration, at the cost of a 5-100x increase in token consumption per problem 1 .
Core technical domains.
| Domain | Depth required |
|---|---|
| Chain-of-thought prompting | Moderate |
| Self-consistency and majority voting | Moderate |
| Classical search (BFS, DFS, beam search) | Moderate |
| Self-evaluation as a learned heuristic | Deep |
| Prompt engineering and prompt-as-program | Moderate |
| Token-cost accounting at inference time | Surface |
Reader prerequisites. Knowing that an LLM produces a probability distribution over the next token, that chain-of-thought prompting 6 asks the model to write out reasoning before its final answer, and high-school algebra (the worked examples use integers and four-function arithmetic). The Glossary in Section 2.5 covers everything else.
How this review marks its registers. Paper-review articles from Neural Tech Daily’s autonomous AI pipeline mix four distinct registers; each is labelled inline so readers can calibrate trust at every claim:
[From the paper]: what Yao et al. themselves claim, bound to a specific equation, section, table, or figure.[Analysis]: the publication’s own reasoned assessment (worked numerical examples, FLOPs accounting, plain-English on-ramps, three-depth callout).[Reconstructed]: content the publication reconstructs faithfully because the paper only partially discloses it (typically prompt templates or hyperparameter choices buried in appendices).[External comparison]: comparison to named prior or contemporaneous work outside the paper itself.[Reviewer Perspective]: independent critical commentary that goes beyond what the paper proves.
2. TL;DR and executive overview
TL;DR. Tree of Thoughts asks a language model to brainstorm several possible next reasoning steps at every point in a problem, then asks the same model to rate each step, then uses a classical search algorithm (breadth-first or depth-first) to pick which step to expand next. On the puzzle Game of 24, where the player must combine four numbers with plus, minus, times, and divide to reach 24, GPT-4 prompted normally solves about 4 of every 100 puzzles, while GPT-4 wrapped in Tree of Thoughts solves about 74. The cost is roughly 100 times more text generated per puzzle.
Executive summary. The paper formalises four design questions any thought-tree procedure must answer: how to split a problem into thought-sized chunks; how to generate candidate thoughts; how to evaluate a partial state; and which search algorithm to run on top. It instantiates the framework on three tasks chosen to require deliberation rather than fluency, reports large absolute gains over chain-of-thought and self-consistency baselines, and acknowledges that the procedure trades a 5-100x token cost for the accuracy gain. The framework is model-agnostic and was the conceptual ancestor of the test-time-compute 10 and reasoning-trained 11 lines that followed in 2024.
Five practitioner-relevant takeaways.
- Thought decomposition is task-specific and load-bearing. [From the paper] For Game of 24 a thought is one arithmetic operation; for Creative Writing it is a writing plan; for Crosswords it is a single word slot fill. The paper offers no general recipe. Choosing thought granularity is the first thing an implementer must hand-design 1 .
- Self-evaluation is the heuristic. [From the paper] The same frozen LLM that generates candidate thoughts also scores them, either by classification (“sure / maybe / impossible”) or by voting across sampled completions. Without a calibrated self-evaluator, the search axis degenerates to random tree expansion 1 .
- BFS suits shallow, branchy problems; DFS suits deep, constrained ones. [From the paper] Game of 24 (depth 3) uses BFS with beam width . Mini Crosswords (depth 5-10) uses DFS with a value threshold that prunes hopeless branches 1 .
- Cost is 5-100x chain-of-thought. [From the paper] On Game of 24, ToT uses about 5,500 completion tokens per problem and reports a per-case cost of $0.74 against $0.47 for the chain-of-thought best-of-100 baseline at the same GPT-4 pricing 1 .
- [Analysis] The paper is the proof-of-concept; reasoning-trained models are the production answer. ToT showed that wrapping inference in deliberate search recovers behaviour that a single forward pass cannot produce. The 2024 OpenAI o1 line 11 internalised search into the policy weights via reinforcement learning on reasoning traces; ToT today reads as the externalised, transparent ancestor of those reasoning-trained systems.
Pipeline overview. ToT is purely inference-time; no fine-tuning. A single frozen LLM is invoked in three roles (proposer of next thoughts, evaluator of states, and implicitly the deliberation engine) with three different prompts. A search loop in Python orchestrates the calls.
2.5. Glossary
A plain-English dictionary for the rest of the article. A curious 16-year-old who has taken algebra should be able to navigate every later section using only this table as a lookup.
| Term | Plain-English explanation | First appears in |
|---|---|---|
| Token | The unit a language model reads and emits — usually a short fragment of a word like “ing” or “the”. The cost of running an LLM is counted in tokens. | Section 1 |
| Chain-of-thought (CoT) | Asking the LLM to write out its reasoning step by step before giving a final answer. Often improves accuracy on math and logic. | Section 1 |
| Self-consistency | Sample many chain-of-thought answers for the same question, count which final answer appears most often, return that. A 2022 paper by Wang et al. | Section 1 |
| Thought | In this paper, a “thought” is a single intermediate reasoning step — small enough to evaluate, big enough to make progress. For Game of 24 a thought is one arithmetic operation. | Section 3 |
| State | A snapshot of the partial solution so far. Formally written where is the input and are the thoughts taken to reach here. | Section 3 |
| Thought generator | The prompt-and-LLM-call that produces candidate next thoughts given a state. | Section 5 |
| State evaluator | The prompt-and-LLM-call that gives each state a score, so the search can decide which branch to expand. | Section 5 |
| Breadth-first search (BFS) | A classical search algorithm: explore every option at depth 1 before moving to depth 2, and so on. Keeps the top few options at each depth. | Section 5 |
| Depth-first search (DFS) | A classical search algorithm: pick one option and go as deep as possible before backtracking to try another. Good when the tree is deep and branchy. | Section 5 |
| Beam width | In BFS-style search, how many states to keep alive at each depth. Larger explores more but costs more tokens. | Section 7 |
| Backtracking | When a partial solution is judged hopeless, return to a previous decision and try a different branch. Classical search property; missing from plain chain-of-thought. | Section 5 |
| Pass@1 | The probability that a single sampled answer from the LLM is correct. The baseline accuracy if you ask once. | Section 9 |
| Game of 24 | A puzzle in which four integers must be combined with to equal 24. Example: 4, 9, 10, 13 yields . | Section 1 |
[From the paper] prefix | Content directly supported by Yao et al.’s text, equations, tables, or figures. The default register for technical claims in this article. | Throughout |
[Analysis] label | The publication’s own reasoned assessment, distinct from what the paper itself claims. Signals editorial interpretation. | Throughout |
[Reconstructed] label | Content the publication reconstructs faithfully because the paper only partially discloses it (typically appendix-buried prompts). | Section 8 |
[External comparison] label | A comparison to prior or contemporaneous work outside the paper itself. | Sections 4, 11 |
[Reviewer Perspective] label | A critical or speculative assessment that goes beyond what the paper proves. | Sections 11, 12 |
3. Problem formalisation
Notation table.
| Symbol | Type | Meaning | First appears in |
|---|---|---|---|
| Input | Problem statement (e.g., the four numbers “4 9 10 13”) | Section 3 | |
| Symbol sequence | The -th thought; one chunk of intermediate reasoning | Section 3 | |
| State | Partial solution | Section 3 | |
| Function | The frozen language model with parameters | Section 3 | |
| Function | Thought generator — produces candidate next thoughts from state | Section 3 | |
| Function | State evaluator — scores each state in the frontier set | Section 3 | |
| Scalar | Number of candidate thoughts proposed per state | Section 3 | |
| Scalar | Beam width (BFS) — number of states retained per depth | Section 3 | |
| Scalar | Maximum search depth | Section 3 | |
| Scalar | Pruning threshold (DFS) — branches below this score are abandoned | Section 7 |
Formal problem statement. [From the paper, Section 3] Let be a problem instance and a candidate solution. A standard LLM inference returns . Chain-of-thought factors this through a single linear sequence where is the reasoning trace. Tree of Thoughts replaces the single chain with a tree whose nodes are states . The procedure is parameterised by:
- A thought decomposition specifying what counts as a thought (granularity).
- A thought generator producing candidate next thoughts.
- A state evaluator assigning a scalar score to each candidate state.
- A search algorithm (BFS or DFS in the paper) that traverses the tree using as its heuristic.
The objective is to maximise the probability that the leaf state at search termination contains a correct solution to , subject to a total-token-budget constraint that the paper reports but does not optimise over.
Explicit assumption list.
- A useful self-evaluation signal exists. The paper assumes the same LLM that generates thoughts can score them with calibration better than chance. [Analysis] Potentially strong assumption: for tasks where the model cannot tell good reasoning from bad, ToT cannot improve over self-consistency.
- Thought decomposition is hand-designed. Section 3 explicitly leaves decomposition to the practitioner. No automated discovery is offered.
- Search depth is bounded and known. The paper sets per task: 3 for Game of 24, 3 for Creative Writing, 5-10 for Mini Crosswords.
- State is fully captured by the text trajectory. [Analysis] Hidden state (e.g., the model’s own uncertainty over arithmetic) is not part of . This means re-entering the same textual state always yields the same distribution over next thoughts.
Why the problem is hard. Plain left-to-right generation cannot backtrack: once the model commits to a wrong intermediate step it must continue from that step. Self-consistency averages over independent attempts but cannot share information across them. Search over reasoning structurally captures both properties (diversity of candidates and the ability to abandon a bad start), but requires the model to (a) produce useful diversity at each branch point and (b) score states well enough to guide the search.
LLM-based positioning. All three roles (generator, evaluator, deliberation engine) are filled by the same frozen LLM with task-specific prompts. The paper uses GPT-4 throughout the headline experiments; a small ablation with GPT-3.5 is reported as a qualitative check.
4. Motivation and gap
The concrete problem. Some problems require exploration. The paper opens with Game of 24 because it is small enough to study yet structurally requires search: there are 4! orderings of the four numbers and 4 operations between each pair, so the brute-force tree has hundreds of leaves but only one or two reach 24. A model that commits to "" on the first step and discovers the choice was wrong has no way to back up under chain-of-thought; it can only push forward into a dead end.
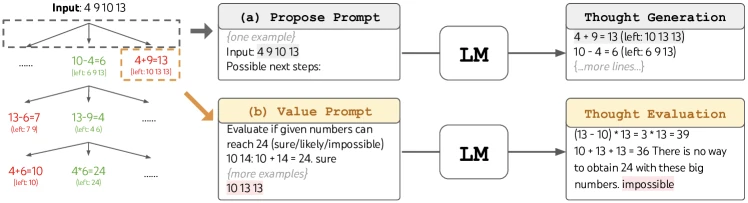
Figure 2 of Tree of Thoughts (arXiv:2305.10601), reproduced for editorial coverage.
Existing approaches and their failure modes. [From the paper, Section 2]
- Chain-of-thought [Wei et al. 2022] 6 elicits step-by-step reasoning but produces a single linear trajectory.
- Self-consistency [Wang et al. 2022] 7 samples many chains and majority-votes the final answer. This helps when the correct answer is the modal answer but not when the model gets a problem wrong most of the time.
- Self-refine [Madaan et al. 2023] 8 and Reflexion [Shinn et al. 2023] 9 iterate the same chain with verbal feedback. [External comparison] Both are contemporaneous with ToT and explore a different axis: sequential refinement rather than parallel branching.
The gap the paper claims to fill. None of the above maintains an explicit set of alternative partial solutions simultaneously, and none can backtrack to an earlier decision point. ToT does both.
Why prior methods were insufficient per the paper. [From the paper] On Game of 24, chain-of-thought with GPT-4 reaches only 4% even with self-consistency over 100 samples reaching 9%, because the model’s mass concentrates on incorrect arithmetic decompositions, and majority-voting them does not recover the small minority of correct ones.
Practical stakes. Any reasoning task with backtracking structure (planning, theorem proving, code synthesis with branching choices, multi-step optimisation) sits in the same regime as Game of 24. [Analysis] ToT is the first inference-time procedure to demonstrate that tree search over thoughts is operationally feasible on a commercial LLM, opening the design space that test-time compute 10 and reasoning-trained models 11 later occupied.
[External comparison] Position in the broader landscape. Contemporaneous with ToT, Hao et al.’s “Reasoning with Language Model is Planning with World Model” (RAP) 12 proposed Monte Carlo Tree Search over LLM-generated states. RAP and ToT independently converged on tree search as the structural answer; ToT’s choice of breadth-first or depth-first plus self-evaluation kept the procedure simpler and cheaper to instantiate.
5. Method overview
The ToT procedure has four components that an implementer must specify per task.
5.1 Thought decomposition
What it is. Choosing what counts as a single “thought”: the unit of reasoning that the generator proposes and the evaluator scores.
Plain-English intuition. A thought should be small enough that the model can plausibly evaluate whether it is good or bad in one look, and large enough that committing to it makes meaningful progress on the problem. For Game of 24 the natural unit is one arithmetic operation that consumes two of the remaining numbers; for Creative Writing it is a one-paragraph plan; for Mini Crosswords it is one word slot filled.
Design rationale. [From the paper, Section 3] If thoughts are too small (one token), evaluation is impossible because no progress has been made; if too large (the whole solution), there is no tree to search.
Classification. [New] formalisation: the paper is the first to make thought granularity an explicit design choice.
5.2 Thought generator
What it is. A prompted LLM call that produces candidate next thoughts from a given state .
Mechanism. [From the paper, Section 3] Two implementations:
- Sample. Independently sample completions from the same prompt at non-zero temperature. Used for Creative Writing where the thought space is open.
- Propose. A single LLM call with a prompt that asks for distinct candidates in one shot. Used for Game of 24 and Crosswords where the thought space is more constrained and asking once is cheaper than separate calls.
Tradeoffs. Sampling produces uncorrelated candidates but costs separate LLM calls; proposing costs one call but the candidates may correlate.
What breaks if removed. Without the tree cannot branch; the procedure collapses to chain-of-thought.
Classification. [Adapted] from standard LLM sampling, repurposed as the branching primitive.
5.3 State evaluator
What it is. A prompted LLM call that scores each state in the current frontier , returning either a scalar value or a class label.
Mechanism. [From the paper, Section 3] Two implementations:
- Value. Score each state independently by asking the model to classify the state as “sure”, “maybe”, or “impossible” with respect to whether the problem can still be solved from this state. The class labels map to numerical values (the paper uses 20, 1, and -1). For robustness the value prompt is sampled three times and the scores averaged.
- Vote. Present all states in to the model at once and ask it to vote which is most promising. Used for Creative Writing where independent value scoring is harder (coherency is comparative, not absolute).
What breaks if removed. Without the search has no heuristic; every branch is equally good and BFS degenerates into exhaustive enumeration up to depth .
Classification. [New]: using the same generative LLM as a learned heuristic for its own search is a novel role assignment.
5.4 Search algorithm
What it is. Either BFS or DFS, parameterised by (beam width) and (max depth).
Mechanism. Covered fully in Section 7.
Design rationale. BFS suits shallow trees where exploring all branches at each depth is feasible. DFS suits deep trees where pruning hopeless branches early is essential.
Classification. [Adopted] directly from classical AI search.
6. Mathematical contributions
The paper’s math is light; ToT is an algorithmic / prompt-engineering contribution rather than a theoretical one. The two formal objects worth a worked treatment are the state evaluator and the per-task value-assignment scheme.
MATH ENTRY 1: State evaluator value assignment (Game of 24)
- Source: [From the paper, Section 4.1 and Figure 2]
- What it is: A function that turns the language model’s three-class classification of a partial state into a numerical heuristic value the search can compare.
- Formal definition:
where is the class label returned by the -th independent sample of the value prompt on state , and maps class to scalar.
-
Each term explained and its dimensional / type analysis:
- is the frozen language model.
- is a partial state, a text trajectory of length tokens.
- is a discrete class label, sampled by a separate LLM call.
- is a hand-coded lookup table; the paper’s chosen values are 20, 1, -1.
- is a scalar in when all three samples agree, or any rational average otherwise.
-
Worked numerical example. Suppose Game of 24 with input “4 9 10 13” and current state after one operation . The value prompt is sampled three times. Sample 1 returns “sure” (the model believes 6, 9, 13 can reach 24, e.g., via ). Sample 2 returns “sure” (same reasoning). Sample 3 returns “maybe” (the model is less confident).
Compare to a state where the model returns “impossible” twice and “maybe” once: . The BFS frontier will retain the first state and discard the second.
-
Role. is the heuristic the search uses to rank states. In BFS it selects the top states per depth; in DFS the value gates whether a branch is expanded or pruned.
-
Edge cases. All three samples returning “impossible” gives , the minimum. The mapping is not a calibrated probability — it is an ordinal heuristic. [Analysis] The choice of is arbitrary; any monotone mapping with similar spread would behave equivalently on the BFS ranking.
-
Novelty.
[Adapted]— the idea of using a model’s own classification as a search heuristic dates to learned heuristics in classical planning; using a prompted frozen LLM in this role is new to ToT. -
Transferability. [Analysis] The 20/1/-1 spread matters only if the search uses cumulative path values (not just per-state); for the frontier-ranking use ToT actually employs, only the relative order matters.
-
Why it matters. Without this scalarisation the search has no comparable scores across branches.
MATH ENTRY 2: Tree size as a function of search parameters
- Source: [Analysis] — the paper reports per-problem token costs in Table 2 without giving the closed-form tree-size formula; this entry reconstructs it.
- What it is: An upper bound on the number of LLM calls a BFS-ToT run can make per problem.
- Formal definition:
where is the beam width retained per depth, is the number of candidate thoughts proposed per state, and the accounts for the three samples of the value prompt per candidate.
-
Each term explained and its dimensional / type analysis:
- : integer beam width (typically 1-5).
- : integer thoughts per state (typically 1-5).
- : integer max depth (3 for Game of 24, up to 10 for Crosswords).
- The term counts the proposal calls per depth; the counts the value calls per depth (each of the retained states is re-evaluated, three samples each).
-
Worked numerical example. Game of 24 uses :
[Analysis] If the average call generates roughly 50 tokens (proposal) or 20 tokens (value), the total completion-token budget per problem is roughly completion tokens. The paper reports about 5,500 completion tokens per Game-of-24 problem 1 , consistent with this estimate plus the proposal-prompt overhead.
-
Role. Sets the cost floor for the procedure.
-
Edge cases. If the search terminates early because a leaf is judged correct, the actual call count is smaller. The bound is tight only when the search exhausts the depth budget.
-
Novelty.
[Analysis]reconstruction. -
Why it matters. Shows where the 5-100x cost multiplier over chain-of-thought comes from and which knob (depth, beam, or proposal width) dominates.
Theorems and proofs. The paper presents no formal theorems. Its claims are empirical.
7. Algorithmic contributions
ALGORITHM ENTRY 1: ToT-BFS (Algorithm 1 in the paper)
- Source: [From the paper, Section 3 Algorithm 1]
- Purpose: Tree-of-Thoughts search using breadth-first exploration with a fixed beam width .
- Inputs:
- : problem instance (text)
- : frozen language model
- : thought generator
- : state evaluator
- : max depth (integer)
- : beam width (integer)
- : candidates per state (integer)
- Outputs: A best-scoring leaf state , or failure.
Pseudocode.
Algorithm 1: ToT-BFS
Input: problem x, LM p_θ, generator G, evaluator V,
depth T, beam width b, branch factor k
Output: best leaf state s*
S_0 ← { [x] } # initial frontier: just the input
for t = 1, ..., T do
# 1. Generate: for each state in current frontier,
# propose k candidate next thoughts
S'_t ← { [s, z] : s ∈ S_{t-1},
z ∈ G(p_θ, s, k) }
# 2. Evaluate: score every candidate state with V
Values ← { (s', V(p_θ, s')) : s' ∈ S'_t }
# 3. Select: keep the top-b candidates by value
S_t ← top-b states from Values
return arg max V over S_TAnnotation per line.
- Initial frontier is the trivial state containing just the input.
- The for-loop runs at most depths; the search can terminate early if a leaf state is judged to contain a solution.
- Generation phase: each of the active states is expanded by candidate next thoughts, yielding a candidate frontier of size .
- Evaluation phase: each candidate is scored.
- Selection phase: only the top candidates survive to the next depth.
Hand-traced example on minimal input. Game of 24 with “4 9 10 13”, , , (smaller than the paper’s for compactness).
-
: .
-
: Generator proposes next thoughts, say:
Candidate frontier: where appends to .
Evaluator scores: (sure / sure / maybe), (maybe / maybe / impossible), (maybe / impossible / maybe).
Top- selection: (state 1 and either of states 2 or 3, with tiebreak to state 2 by index).
-
: Both surviving states expand by . Suppose from (“remaining: 6 9 13”) the generator proposes , , . The first gives “remaining: 4 6”, judged “sure” because . The third gives “remaining: 6 22”, judged “impossible”.
-
: From the surviving “remaining: 4 6” state, the generator proposes . Evaluator: sure.
-
Termination: A leaf is correct. Return that path: , , .
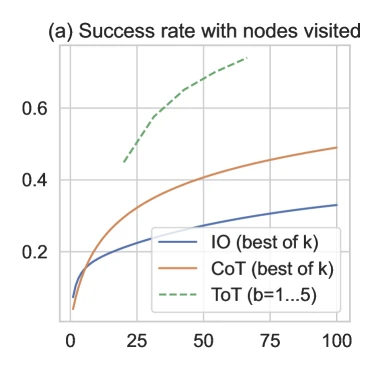
Figure 3 of Tree of Thoughts (arXiv:2305.10601), reproduced for editorial coverage.
Complexity. Time complexity is generation calls plus evaluation calls (each evaluation may itself be three samples). Space is tokens in the active frontier.
Bottleneck. The state-evaluation pass; on Game of 24 it accounts for roughly half of the total calls because each candidate is sampled three times.
Hyperparameters used in the paper. Game of 24: , (proposed in one call as a list), . Creative Writing: , , (one plan-selection step then one paragraph-selection step). Crosswords uses DFS; see ALGORITHM ENTRY 2.
Failure modes. If the evaluator is mis-calibrated (e.g., says “sure” on wrong states), BFS prunes correct branches early and the search returns a confidently wrong answer. [From the paper, Section 5] Yao et al. observe this empirically on a fraction of Game-of-24 failures.
Novelty. [New] as an instantiated procedure on LLM-generated thoughts; [Adopted] as a classical BFS-with-heuristic schema.
Transferability. [Analysis] Reusable wherever (a) thoughts have a natural decomposition, (b) the LLM’s self-evaluation is better than chance, and (c) the tree is shallow enough that stays within the token budget.
ALGORITHM ENTRY 2: ToT-DFS (Algorithm 2 in the paper)
- Source: [From the paper, Section 3 Algorithm 2; instantiated in Section 4.3 Crosswords]
- Purpose: Depth-first variant with a value-threshold pruning rule, suited to deeper trees.
Pseudocode.
Algorithm 2: ToT-DFS
Input: problem x, LM p_θ, generator G, evaluator V,
depth T, branch factor k, value threshold v_th
Output: best terminal state s*, or failure
procedure DFS(s, t):
if t > T:
return s
candidates ← G(p_θ, s, k)
values ← { (c, V(p_θ, [s, c])) : c ∈ candidates }
sort candidates by value, descending
for (c, v) in values:
if v < v_th:
continue # prune
result ← DFS([s, c], t + 1)
if result is a valid solution:
return result
return failure
return DFS([x], 1)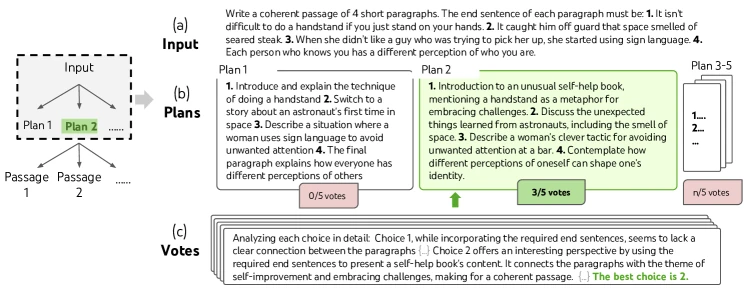
Figure 4 of Tree of Thoughts (arXiv:2305.10601), reproduced for editorial coverage.
Hand-traced example on minimal input. Mini Crossword with two clues active and value threshold on the same 20/1/-1 scale.
- Start , depth 1.
- Generator proposes three candidate first-fills: (value 13.67), (value 0.33), (value -1).
- Sort: .
- Prune because .
- Recurse into , depth 2.
- At depth 2 the generator proposes . Both score (the first fill made the second clue impossible). Both pruned.
- DFS returns failure from this subtree.
- Backtrack to depth 1, recurse into .
- And so on.
Complexity. Worst-case time is if no pruning fires; with pruning the effective branching factor drops sharply. Space is for the recursion stack, strictly less than BFS.
Hyperparameters in the paper. Crosswords: , - (one fill per clue), task-tuned.
Failure modes. Aggressive pruning (high ) abandons correct branches; lenient pruning (low ) blows up the call budget.
Novelty. [Adopted] from classical DFS-with-heuristic; [New] in its use of LLM self-evaluation as the pruning oracle.
Transferability. Suits any deep, constraint-satisfaction-shaped task where most branches are detectably hopeless early (Sudoku-style, theorem prover lemma search, code-generation with hard constraints).
8. Specialised design contributions
Subsection 8A: LLM / prompt design.
The paper’s prompts are the operational core. The propose, value, and vote prompts are reported in Appendix A.
PROMPT ENTRY 1: Game-of-24 propose prompt
- Source: [From the paper, Appendix A]
- Role in pipeline: Thought generator for Game of 24.
- Prompt type: Few-shot with explicit format constraint.
- Components in order: Task definition; few-shot examples of “current numbers → next-step proposal”; the current state; an instruction to list candidate next operations.
- Input schema: Plain text containing the current remaining numbers.
- Output schema: A list of next-step operations, each formatted as ” (remaining: …)”.
- Reconstructed template
[Reconstructed]:
Input: 4 9 10 13
Possible next steps:
10 - 4 = 6 (left: 6 9 13)
4 + 9 = 13 (left: 10 13 13)
... (more)
Input: <CURRENT_STATE>
Possible next steps:- Failure handling. When the generator returns malformed candidates the paper’s reference implementation simply discards them; no retry logic is reported.
- Design rationale. Asking the model to produce all candidates in one call (propose) is far cheaper than independent samples and is feasible because the candidate space is small.
- Complexity. One LLM call per state expansion; output length scales with .
- Novelty.
[New]instantiation;[Adopted]few-shot format.
PROMPT ENTRY 2: Game-of-24 value prompt
- Source: [From the paper, Appendix A]
- Role in pipeline: State evaluator for Game of 24.
- Prompt type: Zero-shot classification with three-class output and lookahead.
- Components in order: Definition of the task; instruction to evaluate whether the remaining numbers can still reach 24; instruction to return one of “sure / likely / impossible” (the paper uses “sure / likely / impossible” in some appendix variants and “sure / maybe / impossible” elsewhere; the GitHub repository 5 uses “sure / likely / impossible”).
- Output schema: A trailing class label on the last line.
- Reconstructed template
[Reconstructed]:
Evaluate if given numbers can reach 24
(sure / likely / impossible).
10 14: 10 + 14 = 24. sure.
11 12: 11 + 12 = 23, 12 - 11 = 1, 11 * 12 = 132, 11 / 12 = 0.91.
impossible.
4 4 10: 4 + 4 + 10 = 18, 4 * 10 - 4 = 36 ... likely.
<REMAINING_NUMBERS>:- Design rationale. The model is invited to do brief arithmetic before classifying, which empirically calibrates the class better than a direct label.
Subsection 8B: Architecture-specific details. Not applicable to this paper. ToT does not modify the LLM.
Subsection 8C: Training specifics. Not applicable to this paper. No fine-tuning; all experiments use GPT-4 frozen as the inference engine, with one ablation using GPT-3.5.
Subsection 8D: Inference / deployment specifics. [From the paper, Section 4 and Table 2] Sampling temperature is set to 0.7 for proposal calls in Game of 24, 1.0 for Creative Writing plan sampling. Maximum tokens per call are bounded per task. The reference Python implementation 5 serialises calls; a production deployment could parallelise within a depth.
9. Experiments and results
Datasets.
- Game of 24. 100 puzzles sourced from
4nums.com(puzzles rated by human-solving rate). - Creative Writing. 100 puzzles introduced by this paper. Each puzzle is four randomly chosen sentences; the task is to write a four-paragraph passage that ends with these four sentences in order.
- Mini Crosswords. 20 puzzles, each a grid with 5 horizontal and 5 vertical clues. Word-level success and letter-level success are both reported.
Baselines.
- Input-output (IO) prompting. Bare prompt, no reasoning.
- Chain-of-Thought (CoT). [Wei et al. 2022] 6 .
- CoT with self-consistency (CoT-SC@100). [Wang et al. 2022] 7 .
- CoT iterative-refine. [From the paper, Section 4.1] An ablation where the model is asked to refine its answer in the same chain.
[Analysis] Conspicuously absent: comparison to Reflexion 9 and Self-Refine 8 , both contemporaneous. The paper acknowledges them in related work but does not run a head-to-head.
Evaluation metrics.
- Game of 24: success rate over 100 puzzles.
- Creative Writing: GPT-4 coherency score on a 1-10 scale, averaged over 100 puzzles, plus human pairwise preference.
- Mini Crosswords: letter-success rate, word-success rate, game-success rate.
Main quantitative results (reproduced from the paper).
| Task | Method | Success / Score |
|---|---|---|
| Game of 24 | IO | 7.3% |
| Game of 24 | CoT | 4.0% |
| Game of 24 | CoT-SC (k=100) | 9.0% |
| Game of 24 | ToT (b=5) | 74% |
| Creative Writing | IO | 6.19 |
| Creative Writing | CoT | 6.93 |
| Creative Writing | ToT | 7.56 |
| Mini Crosswords | IO | 38.7% letter / 14% word |
| Mini Crosswords | CoT | 40.6% letter / 15.6% word |
| Mini Crosswords | ToT (DFS) | 78% letter / 60% word |
Table 2 and Table 3 of Tree of Thoughts (arXiv:2305.10601), reproduced for editorial coverage. The ToT figures are the headline configurations reported in the paper.
Token-cost accounting. [From the paper, Table 2] On Game of 24, CoT uses 1.7k completion tokens per problem on average (best-of-100 self-consistency raises this to roughly 6.7k); ToT uses 5.5k completion tokens per problem at $0.74 per case versus $0.47 for the CoT-SC@100 baseline at GPT-4 pricing as of mid-2023.
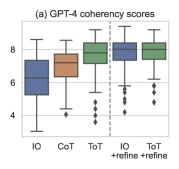
Figure 5 of Tree of Thoughts (arXiv:2305.10601), reproduced for editorial coverage.
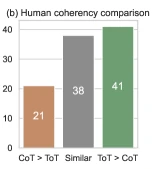
Figure 6 of Tree of Thoughts (arXiv:2305.10601), reproduced for editorial coverage.
Ablations.
- Beam width. [From the paper, Figure 3] Success rises monotonically with from (essentially a single chain with self-evaluation) at 45% to at 74%.
- Value vs vote. Vote ablation for Game of 24 underperforms value classification.
- Single sample of value. Reducing the three-sample average to one sample degrades success by several points; the variance reduction matters.
- Pruning ablation (Crosswords). Removing the value-threshold prune in DFS drives the call budget up by an order of magnitude with marginal accuracy change.
Robustness / stress tests. Not formally reported. [Analysis] No adversarial-prompt evaluation; no out-of-distribution Game-of-24 variants (larger number ranges, different operator sets).
Qualitative results. Figure 2 shows a complete BFS trace on Game of 24 with the value classifications inline. Figure 4 shows the vote-selection step on Creative Writing. Figure 6 illustrates the Crosswords DFS pruning behaviour.
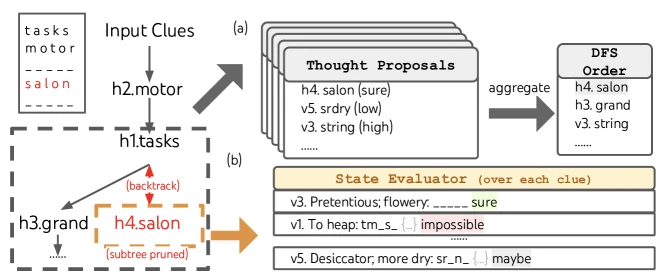
Figure 7 of Tree of Thoughts (arXiv:2305.10601), reproduced for editorial coverage.
Experimental scope limits. Three tasks. All English. All single-turn. GPT-4 only (with one small GPT-3.5 ablation). No public web tasks, no code generation, no agentic tasks, no multimodal inputs.
Independent benchmark cross-checks. [Analysis] The Game-of-24 74% headline number has been reproduced by the official GitHub repository 5 and is widely cited but has not, to the publication’s knowledge as of May 2026, been the subject of a published independent reproducibility study. Subsequent test-time-compute work 10 uses ToT as a comparator rather than re-running it, and o1-style reasoning-trained models 11 achieve Game-of-24-class results without external search at all, so the absolute 74% has been somewhat overtaken by changes in the underlying policy model rather than disproven on its own terms.
Evidence audit.
- Strongly supported. Game-of-24 large absolute gain (4% → 74%), Crosswords letter-level gain (40% → 78%), per-problem token costs.
- Partially supported. Creative Writing 6.93 → 7.56. The absolute scale (1-10 GPT-4-judged) is narrow and the gap is within the noise floor of GPT-4-as-judge.
- Narrowly supported. Generalisation claims beyond the three reported tasks are gestured at but not measured.
10. Technical novelty summary
Novelty map.
| Component | Type | Novelty level | Justification | Source |
|---|---|---|---|---|
| Thought decomposition as explicit design knob | Conceptual | Fully novel | First paper to formalise it as a choice | Section 3 |
| Thought generator as branching primitive | Algorithmic | Combination novel | Sampling exists; using it as tree branching is new framing | Section 3 |
| State evaluator using same LLM | Algorithmic | Combination novel | Self-eval prompts exist; using as search heuristic is new | Section 3 |
| BFS / DFS over thoughts | Procedural | Combination novel | BFS/DFS are classical; combining with prompted LLM is new | Section 3 |
| Three-class “sure / likely / impossible” value scheme | Prompt | Incrementally novel | Concrete instantiation choice | Appendix A |
| Creative Writing benchmark | Dataset | Fully novel | First proposed in this paper | Section 4.2 |
Single most novel contribution. The role-assignment that uses one frozen LLM in three distinct functions (as branching policy, as state-evaluation heuristic, and as the deliberation engine that ultimately produces the answer) wired together by a classical search loop. The framework is the contribution; the per-task instantiations are demonstrations of it.
What the paper does not claim as novel. BFS, DFS, self-consistency, chain-of-thought, GPT-4 itself, the Game of 24 task, the few-shot prompting convention.
11. Situating the work
What prior work did. Wei et al.’s chain-of-thought 6 showed that an LLM’s reasoning could be externalised as a single linear scratchpad. Wang et al.’s self-consistency 7 showed that averaging over many independent chains improves accuracy. Madaan et al.’s Self-Refine 8 and Shinn et al.’s Reflexion 9 showed that sequential refinement using verbal feedback could fix mistakes.
What this paper changes conceptually. It moves from linear scratchpads to branching ones, and from averaging over independent attempts to searching through dependent ones with backtracking. The conceptual contribution is treating LLM inference as decision-time search.
Contemporaneous related work. [External comparison]
- RAP (Hao et al., May 2023) 12 arrived within weeks of ToT with Monte Carlo Tree Search over LLM-generated states. ToT and RAP independently converged on tree search; RAP uses MCTS where ToT uses BFS/DFS. RAP’s framing emphasises the LLM as a world model; ToT’s framing emphasises it as a deliberator.
- Self-Refine (Madaan et al., March 2023) 8 sits on a different axis: sequential refinement of one chain rather than parallel exploration. ToT’s BFS reduces to a generalised Self-Refine when .
[Reviewer Perspective] Strongest skeptical objection. Why is self-evaluation reliable enough to guide search? The same model that picked the wrong reasoning path is asked to judge whether it is wrong. The paper’s empirical answer is “well enough” on Game of 24 and Crosswords, but the calibration of LLM self-evaluation has since become its own research line, with results suggesting model-as-judge bias and over-confidence patterns that ToT’s value prompts would be susceptible to.
[Reviewer Perspective] Strongest author-side rebuttal. The same model is being asked easier questions in the evaluator role than in the generator role. “Is this state hopeless or promising?” is structurally easier than “what is the right next move?”, and the three-sample averaging materially reduces variance. The Game-of-24 ablations bear this out: even when individual value calls are noisy, the search succeeds.
What remains unsolved.
- How to learn the thought decomposition rather than hand-design it.
- Whether the framework scales to deeper, less constrained problems where the branching factor is much larger than .
- Whether reasoning-trained policies make external search redundant: the question the o1 line 11 later answered affirmatively for a large class of tasks.
Three future research directions (each grounded in a specific paper limitation):
- Learned thought decomposition. Section 3 makes thought granularity a hand-designed knob. A natural extension: train a small policy to predict where to chunk a problem, possibly via reinforcement learning with the eventual success as reward.
- Calibrated self-evaluation. Section 4 reveals that the three-sample averaging mitigates but does not eliminate evaluator noise. A future direction: train a separate, smaller verifier model (akin to process reward models in test-time-compute work 10 ) rather than reusing the policy.
- Tree-of-Thoughts as a search target for distillation. [Reviewer Perspective] If a smaller model could learn to imitate the trajectory a ToT-wrapped GPT-4 takes (not just its final answer), the inference cost falls back toward chain-of-thought while preserving accuracy. This is approximately what reasoning-trained models 11 achieve through RL.
12. Critical analysis
Strengths with concrete evidence.
- Large absolute gain on Game of 24 (4% → 74%), reproduced in the official repository 5 .
- A genuinely new framework rather than a parameter tweak: the framework’s design questions (decomposition, generation, evaluation, search) are now standard vocabulary in the reasoning literature.
- Clean ablations isolating beam width, value-vs-vote, sample count, and pruning thresholds.
Weaknesses explicitly stated by the authors. [From the paper, Section 5 limitations]
- Deliberate search may be unnecessary for tasks GPT-4 already excels at.
- Token costs are 5-100x baseline.
- Only three tasks evaluated, all relatively constrained.
- The framework would benefit from fine-tuning the policy on thought-structured data; this is not attempted in the paper.
Weaknesses not stated or understated. [Reviewer Perspective]
- GPT-4 is the only headline model. GPT-3.5 ablations are reported qualitatively. Whether ToT helps for the much smaller open-weight models that 2024-2026 practitioners actually run is not directly answered.
- Self-evaluation calibration is taken for granted. The paper treats the LLM’s value judgments as reliable enough; subsequent work on LLM-as-judge bias (model-self-preference, surface-feature bias) suggests this assumption is fragile in other domains.
- No statistical-significance reporting. Game of 24 is 100 puzzles; the 74% vs 9% gap is large enough to be obviously significant, but Creative Writing’s 7.56 vs 6.93 on 100 puzzles with a 1-10 scale is closer to noise. The paper does not report confidence intervals on the coherency-score comparison.
- External comparison gap. No head-to-head against Self-Refine 8 or Reflexion 9 .
Reproducibility check.
- Code: Released. Princeton-NLP
tree-of-thought-llmrepository 5 . - Data: The 100 Game-of-24 puzzles, the 100 Creative Writing puzzles, and the 20 Mini Crosswords are bundled with the repository.
- Hyperparameters: Fully reported (beam widths, , depth , temperature, value thresholds).
- Compute: API-cost-reported ($0.74 per Game-of-24 problem); no hardware specified because the policy model is GPT-4 via API.
- Trained model weights: Not applicable; no model trained.
- Evaluation set: Released with the code.
- Overall: Fully reproducible against the same GPT-4 API behaviour. The GPT-4 API has changed since 2023, so exact-number reproduction now requires either a pinned snapshot or accepting drift.
Methodology.
- Sample size: 100 puzzles per task for Game of 24 and Creative Writing; 20 puzzles for Mini Crosswords.
- Evaluation set: held-out by construction; sourced from
4nums.comfor Game of 24 and crossword-puzzle archives for Mini Crosswords. Contamination is unlikely for the specific puzzle instances but the task structure is plausibly in GPT-4’s pretraining. - Baselines: IO, CoT, CoT-SC@100, CoT iterative-refine.
- Hardware / compute: not reported as hardware; reported as dollar cost ($0.74 per Game-of-24 problem) and completion-token count (about 5,500 per problem) at mid-2023 GPT-4 pricing.
Generalisability. [Analysis] The framework is structurally general: any task where a useful thought decomposition exists and where a frozen LLM can score states better than chance is a candidate. The empirical evidence is narrower: three small, constrained tasks. Whether ToT extends to long-horizon agentic tasks (web navigation, software engineering on real codebases) is open; the only reasonable answer in May 2026 is “the o1 line 11 internalised what ToT externalised, so the practical question shifted from ‘does ToT scale?’ to ‘is external search worth keeping when the policy is reasoning-trained?’”.
Assumption audit. Of the four assumptions surfaced in Section 3, the load-bearing one is useful self-evaluation. The paper’s evidence is encouraging on math and constraint-satisfaction problems and silent on open-ended ones. Creative Writing’s narrow margin is consistent with a weakening of the self-evaluation signal as the problem becomes less verifiable.
What would make the paper significantly stronger. [Analysis] A fifth task in a different regime (code synthesis, planning), confidence intervals on Creative Writing scores, head-to-heads against Self-Refine and Reflexion, and an ablation isolating self-evaluation calibration from generator diversity.
13. What is reusable for a new study
REUSABLE COMPONENT 1: The four-question framework (decomposition, generation, evaluation, search).
- What it is: A checklist for designing any tree-structured inference procedure.
- Why worth reusing: Forces the implementer to make four design choices explicitly rather than tangling them in a single prompt.
- Preconditions: A task with non-trivial intermediate structure.
- What would need to change: The four answers themselves; only the question structure transfers.
- Risks: Over-engineering the framework on tasks where chain-of-thought is already adequate.
REUSABLE COMPONENT 2: The “sure / likely / impossible” three-class value head.
- What it is: A discrete-class self-evaluation prompt pattern.
- Why worth reusing: Empirically more stable than free-form numeric scoring; the model commits to one of three labels.
- Preconditions: The task has a sensible notion of “is this state still solvable from here?”.
- What would need to change: Possibly the class names per domain (e.g., “promising / unclear / dead-end” for creative tasks).
- Risks: Class boundaries become a hand-tuned knob; the 20 / 1 / -1 spread is arbitrary.
REUSABLE COMPONENT 3: Three-sample value averaging.
- What it is: Sample the value prompt three times and average to reduce variance.
- Why worth reusing: Cheap to add, materially improves search stability.
- Preconditions: The base evaluator is noisy but unbiased.
- What would need to change: Number of samples can be tuned to budget.
- Risks: Three is a heuristic, not a principled choice.
Dependency map. Component 1 (the framework) is the umbrella. Components 2 and 3 are concrete instantiations that plug into the evaluator role of component 1.
Recommendation. [Analysis] The most reusable artefact is the four-question framework; it survives the move from GPT-4 to any future policy because it is not about a specific model. The “sure / likely / impossible” pattern transfers to math, planning, and constraint-satisfaction tasks; transfers weakly to open-ended generation.
What type of new study benefits most. Any study introducing a new prompted reasoning procedure should adopt the four-question framework as its design vocabulary; any study introducing a verifier or process reward model should compare against the three-class value head as a frozen-LLM baseline before claiming improvement from a trained verifier.
14. Known limitations and open problems
Limitations explicitly stated by the authors. [From the paper, Section 5]
- Deliberate search may be unnecessary on tasks GPT-4 already solves with chain-of-thought.
- Token cost is 5-100x baseline.
- Three tasks only.
- Thought decomposition is hand-designed per task.
- Fine-tuning the policy on thought-structured data is left to future work.
Limitations not stated. [Reviewer Perspective]
- Evaluator calibration is the load-bearing assumption. ToT cannot improve over self-consistency on tasks where the LLM cannot tell good states from bad. The paper does not characterise where this assumption fails.
- No comparison against contemporaneous Self-Refine / Reflexion. Both predate ToT by months.
- Headline gains are GPT-4-specific. Whether the procedure transfers to smaller open-weight models in 2024-2026 deployments is not directly answered.
- Reasoning-trained models obsolete the procedure for many tasks. [External comparison] OpenAI’s o1 11 and the open-source distillations that followed achieve Game-of-24-class results in a single forward pass at fractional cost, by training the reasoning behaviour into the policy weights rather than externalising it via search.
Technical root causes.
- Token-cost gap: the explosion in call count combined with the three-sample value-prompt redundancy.
- Hand-designed decomposition: the lack of a learned thought-chunking model.
- Self-evaluation noise: the same model used in two roles correlates its errors.
Open problems.
- Automated thought decomposition.
- Trained verifiers replacing self-evaluation while keeping the framework intact.
- Hybrid policies that use ToT only when the policy’s confidence is low.
What a follow-up paper would need to solve. The most critical limitation is the absence of an automated allocation rule for when to deploy ToT. A follow-up would need (a) a calibrated difficulty estimator predicting whether a problem benefits from search, (b) a learned thought-decomposition module, and (c) a trained verifier replacing the self-evaluation prompt. The 2024 test-time-compute literature 10 took up (a) and (c); (b) remains genuinely open.
How this article reads at three depths
For the curious high-school reader. Tree of Thoughts is a way of asking a language model to “think through” a problem by considering several possible next moves at every step, scoring each move with the same model, and then using a classical search algorithm (the kind taught in introductory computer-science classes) to navigate the tree of possible solutions. On a four-numbers-to-24 puzzle the technique pushes GPT-4 from solving 4 out of 100 puzzles up to 74 out of 100, at the cost of producing about 100 times more text per puzzle.
For the working developer or ML engineer. ToT is a prompt-engineering framework with four parameters: how to chunk the problem into thoughts, how to generate candidate thoughts per state, how to score states with the same LLM, and which search algorithm (BFS or DFS) to run on top. For Game-of-24-style constrained problems the headline configuration is with a three-class value prompt and three-sample averaging; expect to spend roughly 5,500 completion tokens per problem versus 1,700 for chain-of-thought. The framework is most attractive when (a) the policy model is frozen and you cannot RL-train reasoning into it, (b) the task has a natural thought decomposition, and (c) self-evaluation calibration is plausible. If the deployed policy is already reasoning-trained (o1-class), the marginal value of external ToT is small for tasks the policy already handles.
For the ML researcher. The contribution is the role-assignment that uses one frozen LLM as branching policy, state-evaluation heuristic, and deliberation engine, wired together by classical search. The load-bearing assumption is calibrated self-evaluation; the framework’s empirical headroom on Creative Writing is narrow enough to suggest the assumption weakens as task verifiability decreases. The strongest objection is that reasoning-trained policies internalise what ToT externalises, and the strongest extension is the test-time-compute 10 line that replaces self-evaluation with a trained process reward model. A follow-up would need automated thought decomposition, a calibrated difficulty estimator, and a separately-trained verifier; the 2024 literature took up the latter two and left the first genuinely open.
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. Yao, S. et al. "Tree of Thoughts: Deliberate Problem Solving with Large Language Models." arXiv:2305.10601, NeurIPS 2023. (accessed ) ↩
- 2. ar5iv HTML render of arXiv:2305.10601 (used for figure and notation extraction). (accessed ) ↩
- 3. arXiv PDF of Tree of Thoughts (Yao et al. 2023). (accessed ) ↩
- 4. NeurIPS 2023 proceedings entry for Tree of Thoughts. (accessed ) ↩
- 5. Princeton-NLP — official Tree of Thoughts implementation on GitHub (puzzles, prompts, search code). (accessed ) ↩
- 6. Wei, J. et al. "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models." arXiv:2201.11903 (2022). (accessed ) ↩
- 7. Wang, X. et al. "Self-Consistency Improves Chain-of-Thought Reasoning in Language Models." arXiv:2203.11171 (2022). (accessed ) ↩
- 8. Madaan, A. et al. "Self-Refine: Iterative Refinement with Self-Feedback." arXiv:2303.17651 (2023). (accessed ) ↩
- 9. Shinn, N. et al. "Reflexion: Language Agents with Verbal Reinforcement Learning." arXiv:2303.11366 (2023). (accessed ) ↩
- 10. Snell, C., Lee, J., Xu, K., Kumar, A. "Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters." arXiv:2408.03314 (2024). (accessed ) ↩
- 11. OpenAI. "Learning to Reason with LLMs" (o1 announcement, September 2024). (accessed ) ↩
- 12. Hao, S. et al. "Reasoning with Language Model is Planning with World Model." arXiv:2305.14992 (2023). (accessed ) ↩
Anonymous · no cookies set