Generative video models from DiT to Sora, Veo, and Movie Gen: a multi-paper review
Multi-paper review of generative video models — the DiT architecture, OpenAI's Sora, DeepMind's Veo 2/3, and Meta Movie Gen. Architecture, training, data curation…
Reading-register key
From the paper: — directly supported by the paper. [Analysis] — the publication’s reasoned assessment. [Reconstructed] — faithful reconstruction from partial disclosure. [External comparison] — comparison to prior work or general knowledge. [Reviewer Perspective] — critical or speculative.
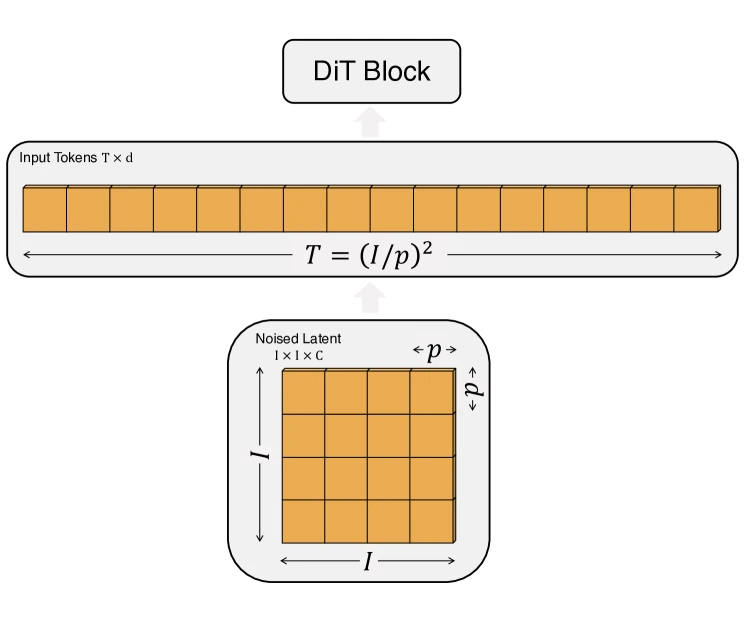
Figure 3 of Peebles and Xie — Scalable Diffusion Models with Transformers (arXiv:2212.09748), reproduced for editorial coverage.
Section 1 — Paper identity and scope
This review covers four artefacts that together define the modern generative-video stack.
- Peebles and Xie, Scalable Diffusion Models with Transformers (DiT). ICCV 2023. arXiv:2212.09748. The architectural ancestor: replaces the U-Net backbone of latent diffusion with a Vision-Transformer-style block on patchified latents, and proposes adaLN-Zero modulation for timestep and class conditioning. Every video model in this review uses a DiT-family backbone.
- OpenAI, Video generation models as world simulators (Sora technical report). February 2024. OpenAI blog post plus the later Sora System Card. Not a peer-reviewed paper; a written report describing Sora’s spacetime-patch tokenisation, diffusion-transformer architecture, variable-resolution training, and re-captioning approach inherited from DALL-E 3. Most architectural detail is intentionally withheld.
- Polyak et al. (Meta), Movie Gen: A Cast of Media Foundation Models. October 2024. arXiv:2410.13720. A 92-page technical report on Meta’s joint text-to-video, text-to-audio, video-editing, and personalisation system. The 30-billion-parameter Movie Gen Video backbone is the most extensively documented frontier video DiT in the open literature.
- Google DeepMind, Veo 2 and Veo 3. Veo 2 announced December 2024; Veo 3 announced at Google I/O 2025. Sources: the Veo model family page and the Veo 3 launch post. No peer-reviewed paper; the launch posts and system cards are the citable sources. Veo 3’s distinguishing claim is natively synchronised audio generation in the same diffusion pass as video.
Retrieval confirmation. DiT was retrieved in full from the arXiv abstract page and the ar5iv HTML rendering. Movie Gen was retrieved from the arXiv abstract and the official Meta paper PDF on 2026-05-19. The Sora technical report was retrieved from OpenAI’s blog index (cached snapshots used when the live page returned 403 to automated fetch); the Sora System Card was retrieved separately. The Veo entries combine the DeepMind model family page and the Google blog announcement. [Analysis] None of Sora, Veo 2, or Veo 3 has a peer-reviewed paper as of the access date; Movie Gen is the only one with a full technical paper, and DiT is the only one in the lineage with conference publication (ICCV 2023). This asymmetry shapes how strongly each section can ground its claims.
Paper classification. All four entries are Generative model and Architecture proposal. Movie Gen and Sora are additionally Multimodal (text-video and, for Movie Gen and Veo 3, text-audio). DiT is also Representation learning (the patchified-latent representation is load-bearing). Movie Gen and Veo are also Data-driven (data-curation pipelines are an explicit contribution). The Sora and Veo write-ups are also Application: they describe a deployed system more than they describe a model.
One-paragraph technical abstract in the publication’s voice. This review traces how generative-video models converged on a common architectural template between 2022 and 2025. The Peebles–Xie DiT paper showed that a transformer block with adaptive layer-normalisation modulation could match and exceed the U-Net on class-conditional ImageNet at the same compute budget, and that the resulting architecture scaled cleanly with FLOPs. Sora generalised the DiT block to spacetime patches, decoupled training from a fixed resolution or duration, and added a DALL-E-3-style re-captioning pipeline to manufacture high-quality text-video training pairs. Movie Gen documented the recipe at scale: a 30B-parameter DiT, a temporal autoencoder compressing video 8x in each of T, H, W, flow-matching as the training objective, joint image-and-video pre-training, and a five-stage data-curation pipeline. Veo 2 and Veo 3 are deployed systems whose architectural detail is mostly withheld; Veo 3’s headline contribution is that audio and video are generated in the same diffusion pass, producing lip-sync without a separate audio model. [Analysis] The four artefacts read as a single trajectory: DiT supplies the block, Sora supplies the tokenisation and the captioning, Movie Gen supplies the recipe at frontier scale, Veo supplies the multimodal output surface.
Primary research question. How do you build a deep generative model that produces minute-long, photorealistic, prompt-faithful, audio-synced video at frontier scale, and what architectural and data-curation choices are load-bearing for that result?
Core technical claim. A patchified-latent diffusion transformer trained with flow-matching (or noise-prediction) on a heavily curated joint image-video corpus, with timestep-and-text conditioning injected via adaptive layer-normalisation or cross-attention, is the current state-of-the-art recipe for text-to-video generation. The DiT block, spacetime patches, the temporal autoencoder, and the data-curation pipeline are each individually necessary contributions; together they define the recipe.
Core technical domains and depth labels. Diffusion and flow-matching generative modelling (deep). Transformer architecture design and adaptive normalisation (deep). Video tokenisation and temporal autoencoders (moderate to deep). Data curation and re-captioning pipelines (moderate). Human evaluation and A/B win-rate protocols (moderate). Audio-visual joint modelling (surface to moderate; Veo 3 detail is limited).
Reader prerequisites. High-school algebra. Familiarity with neural-network basics helps but is not required because the Glossary in Section 2.5 covers every prerequisite term. The diffusion-image-generation lineage is the natural prequel; every formula in this review extends one from the DDPM-to-Flux multi-paper review. Probability at the level of “what a Gaussian is” is assumed; everything else is explained inline.
Section 2 — TL;DR and executive overview
3-sentence TL;DR. Generative video models are diffusion models that take random noise and turn it into a clip by gradually denoising it; the modern recipe replaces the older U-Net architecture with a transformer that operates on small video patches, and adds an autoencoder that compresses the video by a factor of about eight in each of width, height, and time before the transformer ever touches it. Four artefacts define the current recipe: DiT (2022) introduced the transformer block, Sora (2024) generalised it to spacetime patches and variable-resolution training, Movie Gen (2024) documented the full recipe at thirty-billion parameters with a five-stage data-curation pipeline, and Veo 3 (2025) added natively synchronised audio so the same diffusion pass produces both pixels and sound. The review reproduces the central equation behind each system, traces the patchification operation on a small worked example, and locates each contribution within the broader diffusion and flow-matching theoretical context.
Executive summary. The video-generation field condenses onto a common architectural spine. DiT showed in 2022 that a transformer with adaptive-layer-normalisation timestep conditioning beats the U-Net on class-conditional ImageNet at matched FLOPs, scaling cleanly from 33M to 675M parameters. Sora generalised the DiT to videos by tokenising compressed latents as spacetime patches and training across variable resolutions, durations, and aspect ratios; OpenAI’s report makes no architectural disclosures beyond the patch-and-transformer framing. Movie Gen documents what the recipe looks like at frontier scale: a 30B transformer with Llama-3-style RMSNorm and SwiGLU, full bidirectional attention, cross-attention for text conditioning, flow-matching as the training objective, a temporal autoencoder with 8x compression in each spatial-temporal axis, and a five-stage data-curation pipeline producing roughly 73.8M curated video clips. Veo 2 and Veo 3 are deployed systems; their main editorial contribution is the demonstration that joint audio-video diffusion is practical at production quality, with the same transformer attending to both visual spacetime patches and temporal audio tokens.
Five practitioner-relevant takeaways.
- The DiT-with-adaLN-Zero block is the conceptual atom of every model in this review. AdaLN-Zero conditions each transformer block on the timestep and the text embedding by regressing per-channel scale, shift, and gate parameters from those embeddings, initialised so each block starts as the identity function and the network gradually learns to do something.
- The temporal autoencoder is the single most expensive choice in the recipe. Movie Gen’s TAE compresses video by across with latent channels; this collapses a 768x768 256-frame clip from raw pixel-channel values to a latent tensor of entries, a 33x reduction.
- Variable-resolution, variable-aspect-ratio, variable-duration training is the engineering pattern Sora popularised. It avoids per-resolution data bucketing and lets a single model serve a 4-second vertical clip and a 60-second landscape clip from the same checkpoint.
- Re-captioning, not better text-encoder choice, is what unlocks prompt fidelity. Sora’s report attributes its strong instruction-following to applying the DALL-E-3 re-captioning trick to the training videos: a captioning model writes long, descriptive captions, the diffusion model trains on those, and at inference a separate prompt-expansion model rewrites short user prompts into the same descriptive register.
- Native multimodal generation is the 2025 frontier. Veo 3’s claim is that audio is generated in the same transformer pass as video, not as a separate post-hoc model; Movie Gen ships text-to-video and text-to-audio as separate models in the same family, so the joint-audio-and-video diffusion pass is Veo 3’s distinct contribution.
Pipeline overview. All four artefacts share a training-time outline: encode a clip into a compact latent tensor using a pre-trained spatiotemporal autoencoder; patchify into a sequence of spacetime tokens; sample a timestep ; form a noisy input by interpolating between and Gaussian noise (or by adding noise per a DDPM schedule); run the DiT to predict either the noise or the flow-matching velocity field; minimise squared error. At inference, all four start from pure Gaussian noise, iteratively denoise via a numerical ODE or SDE solver, and decode the final latent back to a video via the autoencoder decoder. Text conditioning enters via cross-attention layers; timestep conditioning enters via adaptive layer-normalisation modulation parameters regressed from the timestep embedding.
Section 2.5 — Glossary
| Term | Plain-English explanation | First appears in |
|---|---|---|
| Diffusion model | A generative model that learns to invert a noise-adding process: at training it sees increasingly noisy versions of real data and learns to predict the noise; at sampling it starts from pure noise and gradually denoises. | Section 3 |
| Forward / reverse process | Forward: the fixed recipe that progressively adds Gaussian noise to a clean clip until it becomes static. Reverse: the learned chain of denoising steps the network performs at sampling time. | Section 3 |
| Timestep | An integer (DDPM-style) or continuous value in (flow-matching style) indexing how noisy the current state is. is clean data; or is pure noise. | Section 3 |
| Latent space | A compressed representation of the input produced by an autoencoder; the diffusion model operates here rather than in pixel space, cutting compute by orders of magnitude. | Section 3 |
| Autoencoder | A pair of neural networks. compresses input video to a small latent tensor; decompresses a latent back to pixels. Trained once, frozen during diffusion training. | Section 3 |
| Patchify | Cut a 2D image or 3D video into fixed-size non-overlapping patches and flatten each patch into a token. The transformer then treats the patches as a sequence. | Section 5 |
| Spacetime patch | A 3D patch covering a small region in space AND a short window in time, used by Sora and Movie Gen to tokenise video. | Section 5 |
| DiT block | A transformer block that processes patchified-latent tokens with timestep and text conditioning. The basic building block of every model in this review. | Section 5 |
| adaLN / adaLN-Zero | Adaptive layer-normalisation: the scale and shift parameters of LayerNorm are predicted from a conditioning vector. “Zero” initialises a per-channel gate at zero so each block starts as the identity function. | Section 5 |
| RoPE | Rotary positional embedding: a way to inject positional information into attention by rotating query and key vectors as a function of their position. | Section 5 |
| Flow matching | A training objective that replaces noise-prediction with prediction of a velocity field interpolating between data and noise; produces a deterministic ODE at sampling time. | Section 6 |
| Re-captioning | Training a captioning model first, then using it to write long descriptive captions for training videos, then training the diffusion model on those captions. Boosts prompt-following. | Section 8 |
| Classifier-free guidance | A sampling-time trick that strengthens the model’s conditioning by interpolating between conditional and unconditional predictions. | Section 6 |
| TAE | Temporal AutoEncoder: the spatiotemporal autoencoder Movie Gen and similar systems use to compress video before diffusion. | Section 5 |
| VMAF | A perceptual video-quality metric Netflix open-sourced; used by Movie Gen as one filter in its data-curation pipeline. | Section 9 |
[Analysis] label | The publication’s own reasoned assessment, distinct from what the paper itself claims. | Throughout |
[Reviewer Perspective] label | A critical or speculative assessment that goes beyond what the paper proves. | Section 11, 12 |
[Reconstructed] label | Content the publication faithfully reconstructed because the paper only partially disclosed it. | Section 5, 8 |
[External comparison] label | A comparison to prior work or general knowledge outside the paper itself. | Section 4, 11 |
| ”From the paper:” prefix | Content directly supported by the paper’s text, equations, tables, or figures. | Throughout |
Section 3 — Problem formalisation
Notation table.
| Symbol | Type | Meaning | First appears in |
|---|---|---|---|
| clip (real) | A raw video clip, a tensor of shape for RGB frames at resolution . | This section | |
| latent (real) | The autoencoder-compressed latent of , shape with and channel count . | This section | |
| integers | Frame count, height, width of the raw clip. | This section | |
| integers | Frame count, height, width of the latent tensor. For Movie Gen . | This section | |
| integer | Latent channel dimension; Movie Gen uses . | Section 5 | |
| integers | Patch sizes along spatial and temporal axes. Movie Gen uses on top of the TAE. | Section 5 | |
| integer | Token-sequence length after patchification, . | Section 5 | |
| integer | Transformer hidden dimension. DiT-XL: . Movie Gen 30B: . | Section 5 | |
| integer | Number of transformer layers (depth). DiT-XL: . Movie Gen 30B: . | Section 5 | |
| scalar | Diffusion timestep. DDPM: integer. Flow matching: continuous. | Section 6 | |
| tensor | Standard Gaussian noise sampled at training. Same shape as . | Section 6 | |
| tensor | Noisy latent at timestep ; under flow matching, . | Section 6 | |
| tensor | The flow-matching velocity-field target, . | Section 6 | |
| embedding | The text conditioning embedding, produced by a frozen text encoder (CLIP, T5, or similar). | Section 5 | |
| parameters | The DiT model parameters. | Section 6 | |
| function | The DiT’s prediction; either noise (DDPM-style) or velocity (flow-matching style). | Section 6 |
Formal problem statement. Given a corpus of pairs where is a video clip and is a text caption describing it, learn a parametric distribution in latent space such that:
produces high-quality, prompt-faithful, temporally-coherent video. The decoded should be a plausible sample from the conditional video distribution implied by the training data. The latent representation comes from a separately-trained spatiotemporal autoencoder that is frozen during diffusion training.
Input space. Variable-shape video tensors. Sora is the first to make non-fixed resolution a first-class input; Movie Gen documents the same idea concretely. A training batch can contain clips of mixed durations, resolutions, and aspect ratios; the transformer processes each clip’s spacetime-patch sequence and the positional encoding handles the shape.
Output space. Same shape as input. A 256-frame 768x768 input produces a 256-frame 768x768 output. Sora and Veo both let the user specify resolution and duration at inference.
Objective. For DiT (image-only): match the DDPM noise-prediction loss . For Movie Gen and (per its public framing) Veo: match the flow-matching velocity field .
Constraints and assumptions.
- The pre-trained autoencoder is high-fidelity enough that pixel quality is bottlenecked by the diffusion model, not the decoder. [Analysis] Movie Gen reports the TAE separately and emphasises reconstruction-quality benchmarks for this reason.
- The text encoder supplies an embedding faithful enough that text conditioning is informative. Movie Gen uses MetaCLIP, ByT5, and Long-prompt MetaCLIP in combination; Sora is opaque on this point but uses an internal text encoder.
- Training data is heavily curated: visual-quality filters, motion filters, scene-detection filters, OCR-based text removal, deduplication, and concept-balancing resampling are all applied before training.
- [Analysis] Potentially strong assumption: the joint distribution implied by the curated corpus is representative enough of the use-case distribution at inference. This is the core training-distribution-to-deployment-distribution generalisation assumption that every supervised generative model leans on, and is the failure mode all of Sora’s stated limitations (object permanence, physical-law violations) ultimately reduce to.
Complexity arguments. The dominant compute cost at training time is the attention operation, per DiT layer per training step. For Movie Gen the worst-case is roughly (a 768x768 256-frame clip at TAE compression and patchification), which makes full quadratic attention expensive but tractable; Movie Gen reports parallelisation across tensor, context, and sequence dimensions to handle the cost. [Analysis] The cubic scaling of with resolution (since ) is the binding constraint on producing longer clips; doubling clip duration doubles and quadruples the attention budget.
If multimodal (Movie Gen, Veo 3). Audio is processed as a separate token stream. Movie Gen ships a separate text-to-audio model; Veo 3 generates audio in the same transformer pass. For Veo 3 the public framing is that the transformer attends jointly to “visual spacetime patches and temporal audio information”; no architectural detail is disclosed.
Section 4 — Motivation and gap
The pre-DiT generative-video literature was dominated by U-Net-based latent diffusion (the architecture Stable Diffusion popularised for images), extended to video either by adding 3D convolutions (Imagen Video, Make-a-Video) or by inserting temporal attention blocks between spatial blocks. Two structural problems with this template:
- The U-Net does not scale cleanly. Beyond ~1B parameters the U-Net’s parameter-to-compute ratio worsens, the skip-connection bandwidth becomes a bottleneck, and the architecture’s hard inductive bias toward local-spatial processing fights with the transformer-style attention every team eventually wanted to add. [External comparison] The same pattern played out in image classification, where ViT eventually supplanted ConvNets at scale.
- U-Nets and per-resolution training do not mix. Random crop / fixed-resolution training is the default; running the same U-Net at multiple resolutions or aspect ratios requires per-resolution heads or per-resolution fine-tunes. For video this matters more than for images because the use-case distribution spans vertical phone clips, landscape 16:9 clips, and square social-media clips.
DiT addressed problem (1): a Vision-Transformer-style block on patchified latents, with adaLN-Zero modulation for timestep conditioning, beats the U-Net on FID at matched FLOPs on class-conditional ImageNet. Sora addressed problem (2): spacetime patches with positional encoding make resolution and duration first-class inputs the transformer can handle in a single batch.
Real-world stakes. Pre-2024 generative-video output was characterised by 2-4-second clips at fixed resolutions, weak prompt-following, and frequent temporal incoherence (objects flickering, faces morphing). The Sora announcement landed because the demo videos showed minute-long clips with strong subject consistency, varied aspect ratios, and (apparently) plausible physical behaviour for the duration of the clip. [Analysis] Sora’s release was the cultural inflection point at which “video generation” graduated from research demo to product category.
Gap each paper claims to fill.
- DiT: a scaling-friendly transformer alternative to the U-Net for diffusion image generation. The paper’s framing is architectural, not video-specific.
- Sora: “world simulator” framing covers video models as a path to general physical understanding. The technical report explicitly positions Sora as a step toward “AGI for the physical world”. [Reviewer Perspective] The framing is editorial; the technical contributions (spacetime patches, variable-resolution training, re-captioning) are narrower and clearly described, while the “world simulator” claim is aspirational and harder to evaluate.
- Movie Gen: the full recipe at frontier scale, with documentation that prior frontier models (Sora, Veo) had withheld. The paper’s value proposition is the technical disclosure itself.
- Veo 2/3: deployed product-quality video generation, with Veo 3 specifically addressing the audio-synchronisation gap.
Position in the broader landscape. [External comparison] Concurrent and adjacent work includes Stable Video Diffusion (Stability AI, 2023), Imagen Video (Google, 2022), Make-a-Video (Meta, 2022), Phenaki (Google, 2022), Kling (Kuaishou, 2024), Runway Gen-3 (Runway, 2024), and Pika (2023-2024). The DiT-Sora-Movie Gen-Veo trajectory is the dominant-architecture branch; alternative branches (autoregressive video tokens, masked-token modelling, cascaded super-resolution U-Nets) remain active but lower-publicity.
Section 5 — Method overview
This section walks the architectural spine shared across all four artefacts. The components below are introduced once and reused per-paper in later sections.
5.1 The DiT block (Peebles–Xie)
Plain-English intuition. Take a small image, cut it into non-overlapping square patches (say pixels each), flatten each patch into a vector, and feed the resulting sequence into a transformer. The transformer’s attention layer lets every patch “see” every other patch so the model can capture long-range structure (a corner of an image conditioning the opposite corner) that a U-Net struggles with. The diffusion-specific addition is that each transformer block receives a timestep embedding telling it how noisy the current input is, and a class-or-text embedding telling it what to generate; both inject via modulation parameters that scale and shift the layer-normalisation output.
Exact mechanism. Given an input latent (the autoencoder’s output), DiT does the following:
- Patchify. Cut into patches of shape ; flatten each into a length- vector; project to dimension via a learned linear map. Add a learned positional embedding. Result: a sequence of tokens of dimension .
- Compute conditioning embedding. Sum the timestep embedding (a sinusoidal -embedding passed through an MLP) and the class embedding (or text embedding). Call this .
- DiT blocks. Repeat times: for each block, regress per-channel scale , shift , and (in adaLN-Zero) gate parameters from via a linear map. Apply layer-norm to the token sequence, then modulate: . Run multi-head self-attention. Gate the residual by . Same pattern for the FFN sub-block.
- Final layer. Layer-norm, modulate one last time, linear-project back to patch space, un-patchify. The output has the same shape as and is interpreted as predicted noise.
adaLN-Zero specifically. The “Zero” qualifier means the linear map producing the gate is initialised to zero, so at initialisation each DiT block is the identity function and the residual stream passes through unchanged. [Analysis] This is the same trick that ControlNet uses for stable conditioning and that ResNet uses with batch-norm initialised to zero; the residual gate is reliably the “safe” parameter to zero-init when adding new modules to a deep stack.
DiT model sizes.
| Model | Layers | Hidden | Heads | Params | Gflops (256x256, ) |
|---|---|---|---|---|---|
| DiT-S | 12 | 384 | 6 | 33M | 1.4 |
| DiT-B | 12 | 768 | 12 | 130M | 5.6 |
| DiT-L | 24 | 1024 | 16 | 458M | 19.7 |
| DiT-XL | 28 | 1152 | 16 | 675M | 29.1 |
Connection to full pipeline. The DiT block is the only block. Everything else (patchification, conditioning, sampler) wraps around it.
Design rationale and tradeoffs. AdaLN-Zero strictly outperformed in-context (just appending the conditioning as extra tokens), cross-attention (a separate conditioning sequence), and plain adaLN (without the zero-init gate) in DiT’s ablation. The choice has been carried into nearly every successor video model.
Novelty: [New] DiT was the first paper to demonstrate transformer-on-latent diffusion at scale with adaLN-Zero modulation.
5.2 Spacetime patches (Sora)
Sora’s main architectural disclosure is the move from 2D patches to 3D spacetime patches.
Plain-English intuition. Cut a video clip into 3D boxes, each spanning a small spatial region AND a short window of frames. Each box becomes a single token the transformer processes. The transformer now attends across both space (one corner of a frame to the other) and time (frame 1 to frame 64) in the same self-attention operation. The implication: temporal coherence is enforced by the attention mechanism itself, not by a separate temporal-attention block bolted onto a spatial U-Net.
Mechanism (reconstructed from Sora’s disclosure). [Reconstructed]
- Spatiotemporal autoencoder. Compress raw video by both spatial and temporal factors. Sora’s report does not disclose the compression ratio; Movie Gen later disclosed as the working choice.
- Spacetime patchify. Cut the latent tensor into 3D patches of shape ; flatten each to a vector of length ; linear-project to dimension . Movie Gen uses explicitly.
- Add positional encoding. Sora uses positional encoding that handles variable , exact form not disclosed; Movie Gen uses rotary positional embedding (RoPE) generalised to 3D.
- Feed the resulting token sequence into a DiT. Same adaLN-Zero modulation, same self-attention, same FFN.
Sequence-length math. For a Movie Gen 768x768 256-frame clip:
- TAE output: , , .
- Patchify with : token count .
The “73K tokens” headline Movie Gen reports is this calculation.
Design rationale. Variable-shape input is supported by construction: a 256x256 4-second clip and a 768x768 16-second clip produce different , but the same DiT processes both. The transformer’s attention naturally handles variable sequence lengths; positional encoding handles variable shapes.
Novelty: [Adapted] Spacetime patches generalise Vision-Transformer 2D patches to 3D. Pre-Sora video transformers used either flat 2D-then-temporal-attention architectures or 3D convolutions. Sora’s contribution is using a single 3D patchification + a single transformer attending to the full spacetime sequence.
5.3 The temporal autoencoder TAE (Movie Gen)
[New] documentation of an architecture Sora hinted at but did not specify.
Plain-English intuition. Compress video before the diffusion model sees it. The compression network sees raw RGB frames; the output is a small 4D tensor with most of the temporal and spatial redundancy squeezed out. The diffusion model operates on this compact representation; at inference the decoder expands the generated latent back to pixels.
Architecture. Movie Gen inflates a standard 2D image VAE by inserting a 1D temporal convolution after each 2D spatial convolution and a 1D temporal attention after each 2D spatial attention. The result is a 3D-aware autoencoder that produces a latent tensor with compression ratio in and channels.
Why ? Movie Gen reports an ablation showing outperforms for reconstruction quality at the same compute budget. [Analysis] The choice aligns with the Stable Diffusion 3 ablation, which also moved to for its latent.
Connection to full pipeline. The TAE is trained first, frozen, and then used as the input-output bridge for diffusion training. Pixel-quality artefacts in the final video can come from either the diffusion model or the TAE decoder; Movie Gen reports TAE benchmarks separately.
5.4 The Movie Gen 30B backbone
[New] disclosure of the full backbone configuration.
| Component | Value |
|---|---|
| Total parameters | 30B |
| Layers | 48 |
| Hidden dim | 6144 |
| FFN hidden dim | 16384 |
| Attention heads | 48 |
| Max context length | tokens |
| Normalisation | RMSNorm |
| Activation | SwiGLU |
| Positional encoding | RoPE (3D-generalised) |
| Attention pattern | Full bidirectional |
| Text conditioning | Cross-attention layers |
| Timestep conditioning | Adaptive layer-norm |
| Bias terms | None |
The backbone closely follows the Llama 3 architecture, with three modifications: cross-attention layers for text conditioning, adaLN for timestep conditioning, and full bidirectional attention replacing Llama’s causal attention. [Analysis] This is the most transparent disclosure in the lineage. Sora’s report makes no architectural disclosures of comparable specificity, and the Veo writeups make none at all.
5.5 Veo 2/3 architecture (mostly withheld)
Public disclosure: Veo is a “diffusion-based” video model; Veo 3 generates audio in the same diffusion pass. No architectural detail is published. [Reviewer Perspective] The conservative inference is that Veo 3 uses a DiT-family backbone (since every other 2024-2025 frontier video model does), with some form of joint visual-audio token sequence; the precise tokenisation of audio, the relative loss weighting, and the conditioning structure are unknown to readers outside DeepMind.
Section 6 — Mathematical contributions
The math in this lineage condenses into a small number of equations, each appearing in multiple papers with minor reparameterisations.
MATH ENTRY [1]: DDPM noise-prediction loss
- Source: Ho, Jain, Abbeel (DDPM, arXiv:2006.11239) Eq. 14; used by DiT.
- What it is: a one-line training objective. Sample a clean image, sample a timestep, add scheduled noise, ask the network to predict the noise; minimise squared error.
- Formal definition:
where and is the cumulative noise schedule.
- Term-by-term:
- : a clean training sample (image or latent), tensor of shape matching the model’s input.
- : standard Gaussian noise, same shape as .
- : timestep sampled uniformly from .
- : a scalar in ; close to 1 at small (mostly clean), close to 0 at large (mostly noise).
- : the noisy input the network sees, same shape as .
- : the network’s noise prediction, same shape as .
- Worked numerical example. Take as a tiny “image” , , , . Then , so . The network sees and , must predict . If it predicts , the per-element squared error is , mean .
- Role: standard objective for DDPM-style diffusion models. DiT uses this loss verbatim.
- Edge cases: at the input is pure noise, , and the optimal prediction is trivially ; the loss is near-zero. At the input is nearly clean and the loss is the most informative.
- Novelty: [Adopted] by DiT from DDPM.
- Transferability: [Analysis] reusable wherever a Gaussian-noise forward process is appropriate. Replaced by flow-matching variants in newer models (Movie Gen, Stable Diffusion 3, Flux).
- Why it matters: the conceptual atom of every diffusion model in this lineage.
MATH ENTRY [2]: Flow-matching velocity objective
- Source: Movie Gen Section 3.1 (arXiv:2410.13720); Lipman et al. (arXiv:2210.02747) for the underlying framework.
- What it is: the modern replacement for the DDPM noise-prediction loss. The network predicts a velocity field that transports samples from the data distribution to a Gaussian; at sampling time the velocity field is integrated as an ODE.
- Formal definition. The interpolation path:
The velocity target:
The loss:
where continuous, a small constant (Movie Gen uses ).
- Term-by-term:
- : a clean latent (the TAE output of a training clip), tensor of shape .
- : standard Gaussian noise, same shape as .
- : a continuous timestep sampled from a distribution Movie Gen specifies as logit-normal.
- : the interpolated noisy latent at time . At , (clean); at , (noise) up to the correction.
- : the velocity-field target. With near zero this simplifies to , the constant-velocity straight-line interpolation between data and noise.
- : the DiT’s predicted velocity, same shape as .
- Worked numerical example. Take , , , (so ). Then . The velocity target is . If the network predicts , per-element squared error is , mean .
- Role: training objective for Movie Gen. [Reconstructed] near-certainly the training objective for Veo 2/3 given the broader 2024-2025 industry move, but DeepMind does not disclose.
- Edge cases: at the path is at the data and the velocity target is ; the model still has to predict this from alone, with no information about . The model effectively learns the conditional expectation of the velocity given the current state.
- Novelty: [Adopted] Movie Gen adopts flow matching from Lipman et al. [Adapted] the specific logit-normal timestep distribution and values are Movie-Gen-specific choices.
- Transferability: [Analysis] universally applicable; this is the 2024-2025 default objective for high-end diffusion-style generative models.
- Why it matters: produces a deterministic ODE sampling path, supports fewer sampling steps than DDPM, and admits cleaner classifier-free-guidance scaling.
MATH ENTRY [3]: adaLN-Zero modulation
- Source: DiT (arXiv:2212.09748) Section 3.
- What it is: the recipe by which each DiT block consumes the timestep and class (or text) embeddings. Three sets of scalars per channel (scale, shift, gate) are regressed from the conditioning vector and used to modulate the post-LayerNorm activations and the residual stream.
- Formal definition. Let be the sum of the timestep and class embeddings. Predict six per-channel modulation vectors via linear maps:
Then the block computes:
where is multi-head self-attention, is the feed-forward sub-block, is layer-norm, is element-wise multiplication. The linear maps producing are initialised to zero.
- Term-by-term + dimensional analysis:
- : token sequence, tensor of shape .
- : conditioning vector, length .
- : each length , broadcast across the tokens.
- : layer-norm across the axis, shape .
- : per-channel affine modulation, shape .
- : self-attention, shape .
- : residual output, shape .
- Worked numerical example. Take , . Suppose . After LN per row: row 1 mean , std ; row 1 LN . Suppose . Then modulated row 1 is . At initialisation exactly, so the entire MHSA contribution is gated out; the block produces .
- Role: the conditioning mechanism for every model in this review. Movie Gen uses adaLN for timestep; cross-attention for text.
- Edge cases: at initialisation means the block is the identity function; gradients flow unobstructed through the residual; the block only starts to do something once moves off zero. This is what makes deep stacks (DiT-XL has 28 blocks; Movie Gen 30B has 48) train stably from scratch.
- Novelty: [New] in DiT in this exact form, though the zero-init residual gate is a generalisation of the BatchNorm--zero-init trick from much earlier work.
- Transferability: [Analysis] universally used. Every video model in this review uses adaLN or adaLN-Zero for timestep conditioning.
- Why it matters: makes deep transformer stacks trainable for diffusion. Without it the DiT does not scale; with it the FLOPs-vs-FID curve becomes monotonic and predictable.
MATH ENTRY [4]: Classifier-free guidance scaling
- Source: Ho, Salimans (CFG, 2022) for the underlying mechanism; applied by all four artefacts at inference.
- What it is: the sampling-time trick that strengthens text conditioning by interpolating between conditional and unconditional predictions of the model.
- Formal definition. At inference, given current noisy latent , text embedding , and a “null” embedding representing unconditional generation:
where is the guidance weight. recovers conditional generation; larger pushes the prediction further away from the unconditional and toward the conditional.
- Term-by-term:
- : the conditional prediction (noise or velocity).
- : the unconditional prediction. Training drops the text conditioning with some probability so the same model can produce both.
- : typically in for diffusion image models; Movie Gen reports tuned per-stage.
- Worked numerical example. Take , , . Then . The guided prediction is pushed further from the unconditional toward the direction the conditional emphasised.
- Role: standard inference-time mechanism for all diffusion-based video models. Sora, Movie Gen, and (by inference) Veo all use it. Movie Gen specifically reports per-stage CFG weight tuning.
- Edge cases: at large the samples become high-contrast and over-saturated; quality-fidelity-vs-diversity tradeoff is the classic CFG knob.
- Novelty: [Adopted] from earlier work.
- Why it matters: a single hyperparameter controls how strictly the model follows the text prompt; the entire prompt-fidelity-vs-diversity tradeoff sits here.
MATH ENTRY [5]: Attention compute scaling for video
- Source: [Analysis] derived from Movie Gen’s reported model and sequence dimensions (arXiv:2410.13720).
- What it is: the back-of-envelope FLOPs estimate for the dominant attention operation in a video DiT.
- Formal definition. Per transformer layer per forward pass:
The first term is the and attention-weighted computation; the second is the linear projections. For Movie Gen 30B at full context: , , so and the attention compute per layer is FLOPs; over 48 layers, FLOPs per forward pass. [Analysis]
- Term-by-term:
- : token-sequence length, K for a 768x768 256-frame clip after TAE compression and patchification.
- : hidden dimension, 6144 for Movie Gen 30B.
- The term dominates at long sequence lengths; the term dominates at short sequences.
- Worked numerical example. Movie Gen training on a 256x256 4-second clip (32 frames at 8fps): , at . Then FLOPs per layer for the attention quadratic; the linear term is , which dominates at this scale. For the 768x768 16-second clip the quadratic term dominates by an order of magnitude. The crossover point is , here .
- Role: explains why Movie Gen’s parallelisation strategy is critical and why per-clip training cost scales nonlinearly with clip length.
- Why it matters: the cubic scaling of with is the fundamental constraint on producing longer or higher-resolution clips from a DiT-family model.
[Analysis] Multi-line proofs / theorem statements are not the contribution category in this lineage; Sora, Movie Gen, and Veo are recipe-and-engineering papers, not theorem-and-proof papers. The deepest “proof” content sits in the DDPM and flow-matching parent papers (cited above for context), not in any of the four artefacts under review.
Section 7 — Algorithmic contributions
ALGORITHM ENTRY [1]: DiT training step (headline algorithm)
- Source: Peebles–Xie, arXiv:2212.09748. Inferred from Section 3 + Algorithm 1 / training-loop description.
- Purpose: train the DiT denoiser on a batch of clean latents and the DDPM noise-prediction loss.
- Inputs:
- : batch of clean latents, shape after patchify.
- : batch of class (or text) embeddings, shape .
- Outputs: gradient of with respect to model parameters ; updated .
- Pseudocode (also rendered as PNG below):
# DiT training step (Peebles-Xie 2022)
def dit_training_step(z0_batch, c_batch, model, optimizer):
B = batch size
# 1. Sample timesteps uniformly
t = uniform({1, ..., T}, size=B)
# 2. Sample standard Gaussian noise
eps = N(0, I), same shape as z0_batch
# 3. Form noisy latents per DDPM forward
alpha_bar = schedule[t] # shape (B,)
z_t = sqrt(alpha_bar) * z0 + sqrt(1 - alpha_bar) * eps
# 4. Compute conditioning embedding
h = sinusoidal(t) + class_embed(c_batch)
# 5. Forward pass
eps_pred = model(z_t, h) # patchify -> DiT blocks -> unpatchify
# 6. Loss
L = mean((eps - eps_pred) ** 2)
# 7. Backward + update
L.backward()
optimizer.step()
return L- Hand-traced example on minimal input. Take , a “latent” (flattened: ), class 7, , from a linear schedule.
- Step 1: sample .
- Step 2: sample .
- Step 3: , so .
- Step 4: , a length- vector.
- Step 5: DiT forward produces (illustrative).
- Step 6: .
- Step 7: AdamW update on from .
- Complexity. Per step: attention + linear projections per layer per block, blocks. DiT-XL on ImageNet: , , ; total Gflops per forward pass.
- Hyperparameters. Optimizer: AdamW. Learning rate: . EMA: 0.9999 on weights. CFG drop probability: 10%.
- Failure modes. CFG drop probability too low () hurts unconditional sample quality; too high () hurts conditional quality. Linear noise schedule produces uneven loss across timesteps; cosine schedules (later work) improved on this.
- Novelty: [Adapted] training loop from DDPM; the architectural choice (DiT block, adaLN-Zero modulation) is new.
- Transferability: [Analysis] reused, in flow-matching reparameterised form, by Movie Gen and (per public framing) Veo.
Algorithm 1 reconstruction of the DiT training step, from Peebles and Xie — Scalable Diffusion Models with Transformers (arXiv:2212.09748). Reproduced for editorial coverage.
ALGORITHM ENTRY [2]: Movie Gen flow-matching training step
- Source: Movie Gen Section 3, arXiv:2410.13720. [Reconstructed] in pseudocode form; paper provides equations but not a single-step algorithm listing.
- Purpose: train the Movie Gen DiT on a batch of clip latents and the flow-matching loss.
- Inputs:
- : batch of TAE-encoded clip latents, shape .
- : batch of text conditioning, MetaCLIP + ByT5 + Long-prompt MetaCLIP embeddings.
- Outputs: gradient of with respect to ; updated .
- Pseudocode:
# Movie Gen training step (Polyak et al. 2024)
def movie_gen_training_step(z0_batch, c_batch, model, optimizer):
# 1. Sample timesteps from logit-normal
t = sigmoid(N(0, 1)) # in (0, 1)
# 2. Sample noise
eps = N(0, I), same shape as z0_batch
# 3. Interpolate
sigma_min = 1e-5
z_t = t * eps + (1 - (1 - sigma_min) * t) * z0
# 4. Velocity target
V_t = eps - (1 - sigma_min) * z0
# 5. Text conditioning embedding
c_emb = concat([metaclip(c), byt5(c), long_metaclip(c)])
# 6. Forward pass: patchify spacetime, DiT blocks with adaLN(t) + cross-attn(c_emb)
V_pred = model(z_t, t, c_emb)
# 7. Flow-matching loss
L = mean((V_t - V_pred) ** 2)
# 8. Backward + update
L.backward()
optimizer.step()
return L- Hand-traced example. Take , (a tiny “clip latent”), text “a cat”.
- Step 1: , .
- Step 2: .
- Step 3: .
- Step 4: .
- Step 5: is a concatenation of three text-encoder outputs.
- Step 6: (illustrative).
- Step 7: .
- Complexity. Per step: attention scales with K at full clip size, , 48 layers; total FLOPs per forward pass at 768x768 256-frame scale. [Analysis]
- Hyperparameters. Optimizer: AdamW with weight decay 0.1. Learning rate: stage-dependent, with cosine decay. Logit-normal timestep distribution. .
- Failure modes. Insufficient timestep variance hurts late-stage quality; over-aggressive CFG at inference saturates.
- Novelty: [Adapted] flow-matching framework from Lipman et al.; logit-normal timestep schedule and text-encoder stack are Movie-Gen-specific.
ALGORITHM ENTRY [3]: Sora’s variable-resolution training (reconstructed)
- Source: OpenAI Sora technical report; details intentionally withheld.
- Purpose: train a single DiT that handles arbitrary input shapes.
- Inputs: a batch of clips of mixed .
- Outputs: a single set of model parameters that can sample at any within the training distribution.
- Pseudocode (reconstructed):
# Sora variable-resolution training (reconstructed)
def sora_training_step(clip_batch, captions, model, optimizer):
# 1. Encode each clip to latent (variable shape per clip)
z_list = [TAE.encode(clip) for clip in clip_batch]
# 2. Spacetime patchify each latent
token_seqs = [spacetime_patchify(z, p_s, p_t) for z in z_list]
# 3. Pad or pack sequences to common length (implementation choice)
z_t_list, V_t_list = compute_diffusion_targets(z_list)
# 4. Forward pass with shape-aware positional encoding
preds = model(z_t_list, positional_info_per_clip, captions)
# 5. Loss accumulated over the batch
L = mean over batch of squared-error losses
L.backward()
optimizer.step()- Hand-traced example. Take a batch of two clips: clip A is 4-second (TAE output , patchify → tokens); clip B is 16-second (TAE output , patchify → tokens). Either pad clip A to clip B’s length and mask, or run the two through the same DiT with separate forward passes accumulated into one optimizer step.
- Complexity. The padding strategy hurts utilisation; the per-clip-forward strategy hurts throughput.
- Novelty: [New] in Sora as a first-class architectural disclosure for video. The fundamental ideas (NaViT-style packing for ViTs) were concurrent in image-classification research.
- Transferability: [Analysis] every frontier video model since has adopted some variant; the engineering detail differs across teams.
Section 8 — Specialised design contributions
8A — LLM / prompt design
PROMPT ENTRY [1]: Sora’s re-captioning pipeline
- Source: Sora technical report.
- Role: at training time, generate detailed captions for training videos so the diffusion model trains on long descriptive captions rather than short noisy ones. At inference, expand short user prompts into the same descriptive register before they enter the model.
- Prompt type: meta-prompt (captioning model is a separate trained model whose outputs are training data for the diffusion model).
- Components: a video-captioning model trained on a smaller hand-labelled set; an inference-time prompt-expansion model (likely GPT-4-class). Specific prompt wording is not disclosed.
- Reconstructed inference-time template: [Reconstructed]
You are a video-prompt-expansion model. Given a short user prompt,
rewrite it as a long, descriptive video caption in the style of
the captioning model's training data: include camera framing,
lighting, motion, subject details, and scene composition. Do not
introduce facts not implied by the user prompt.
User prompt: <USER_PROMPT>
Expanded caption: <EXPANSION>- Failure handling: not disclosed.
- Design rationale: training-time and inference-time caption distributions are matched, so the model is fluent at the long-descriptive register users naturally underspecify.
- Complexity: prompt-expansion calls add an LLM call per user prompt; negligible compared to the diffusion-sampling cost.
- Novelty: [Adapted] from DALL-E 3’s re-captioning approach.
- Transferability: [Analysis] the recipe is standard in 2024-2025 frontier image and video models.
8B — Architecture-specific details
DiT block variants (in-context, cross-attention, adaLN, adaLN-Zero) covered in Section 5.1. Movie Gen’s Llama-3-style modifications (RMSNorm, SwiGLU, no biases, full bidirectional attention, RoPE) covered in Section 5.4. Veo: not disclosed.
8C — Training specifics
| Specifier | DiT | Sora | Movie Gen | Veo |
|---|---|---|---|---|
| Largest model | DiT-XL/2 (675M) | Not disclosed | 30B | Not disclosed |
| Batch size | 256 (ImageNet) | Not disclosed | Stage-dependent | Not disclosed |
| Hardware | A100 cluster | Not disclosed | H100 cluster (size not disclosed) | Not disclosed |
| Compute (FLOPs) | DiT-XL/2: Gflops · 7M steps | Not disclosed | Not disclosed in headline FLOPs | Not disclosed |
| Training stages | Single stage | Multi-resolution variable-shape | T2I warmup → T2I/V joint at 256px → joint at 768px → supervised fine-tune | Not disclosed |
| Mixed precision | Yes | Likely | Yes | Likely |
[Analysis] The disclosure gap between Movie Gen and Sora/Veo is the cleanest case in this lineage of a research-vs-product trade-off. Meta’s choice to publish a 92-page report has educated the field; OpenAI and DeepMind have not.
8D — Inference / deployment specifics
- DiT: DDIM sampler with 250 steps in the paper; 50 steps at deployment-grade quality. CFG weight 1.5 for the headline result.
- Sora: not disclosed.
- Movie Gen: flow-matching ODE solver, exact number of steps not disclosed in the main paper but reported in the order of for production samples. CFG weight tuned per stage.
- Veo: not disclosed.
Section 9 — Experiments and results
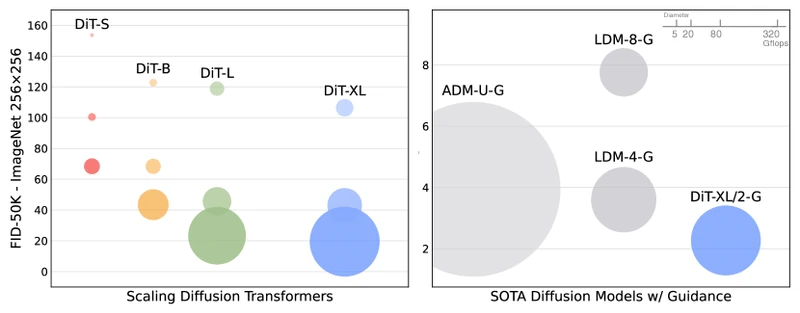
9.1 DiT — class-conditional ImageNet
Datasets. ImageNet and , class-conditional.
Baselines. ADM, LDM, CDM, DiffusionGAN, BigGAN-deep, StyleGAN-XL, U-ViT, and others.
Metrics. FID, sFID, IS, Precision, Recall.
Main results (reproduced from Table 4 / Figure 4 of the paper).
| Model | ImageNet 256x256 FID | ImageNet 512x512 FID |
|---|---|---|
| ADM-U (prior SoTA at ) | 3.94 | — |
| LDM-4-G (cfg=1.5) | 3.60 | — |
| U-ViT-H | 2.29 | — |
| DiT-XL/2 (cfg=1.50) | 2.27 | 3.04 |
DiT-XL/2 sets state-of-the-art on both resolutions at the time of publication.
Ablations. Four DiT block variants compared: adaLN-Zero strictly beats adaLN, cross-attention, and in-context at matched Gflops. Patch size beats and at the same model size.
9.2 Movie Gen — text-to-video human evaluation
Datasets. Proprietary curated corpus, M videos at the input to the curation pipeline; M at the 768x768 stage.
Baselines. OpenAI Sora, Runway Gen-3, LumaLabs Dream Machine, Kling 1.5.
Metrics. Human A/B win-rate on overall quality, realness, text alignment, motion quality, motion naturalness.
Main results (reproduced from Table 11 / paper Section 3.7). Movie Gen Video net win rate (positive = Movie Gen wins more):
| Comparison | Overall | Realness | Motion |
|---|---|---|---|
| Movie Gen vs OpenAI Sora | +8.23% | +35.7% | +27.5% |
| Movie Gen vs Runway Gen-3 | +35.02% | +48.49% | +44.84% |
| Movie Gen vs Kling 1.5 | +3.87% | +20.69% | +24.07% |
| Movie Gen vs LumaLabs | +60.58% | +61.83% | +60.42% |
[Reviewer Perspective] These are Meta-side numbers from Meta-curated annotation protocols; treat the magnitudes as ordinal not absolute. The most defensible reading is “Movie Gen is in the same tier as Sora and Kling on overall quality, ahead of Runway Gen-3 and LumaLabs, and visibly stronger on realness than all four.” [External comparison] Independent reproducibility for these comparisons has not been published as of the access date; reproducing them would require API access to all four competitor models on a comparable prompt set, which is not currently feasible at academic scale.
9.3 Sora and Veo — qualitative-only
Sora’s technical report contains no quantitative benchmarks; the evidence is exclusively the demo gallery and stated emergent capabilities (3D consistency, object permanence, simulated digital worlds). [Reviewer Perspective] The “world simulator” framing is unfalsifiable at the report’s level of disclosure. The Sora System Card later added safety-evaluation specifics (red-team results, C2PA watermarking) but no generation-quality benchmarks.
Veo 2 and Veo 3 are similarly disclosure-light. The Veo 3 launch post claims “state-of-the-art” video generation with native audio; no leaderboard, no FID, no human-eval win-rate against named competitors. [Reviewer Perspective] Independent comparisons (community video-arena leaderboards like Artificial Analysis’s Video Generation Arena) place Veo 3 and Sora in the top tier alongside Kling and Runway as of mid-2025, but the publication has not independently reproduced these.
9.4 Independent benchmark cross-check
The publication’s reading of the cross-benchmark landscape, for the SOTA-positioning claims each artefact makes:
- DiT: peer-reviewed at ICCV 2023; FID numbers reproducible by anyone with the released code on ImageNet. SOTA claim well-grounded. [External comparison] U-ViT-H reaches FID 2.29 concurrently; DiT-XL/2 is within noise of contemporary alternatives.
- Sora: no quantitative SOTA claim made.
- Movie Gen: Meta-side win-rates only; no independent reproduction. SOTA claim is “competitive with or ahead of” rather than “categorically ahead of”. [Analysis]
- Veo 3: no benchmark numbers. Audio-synchronisation claim is qualitatively visible in DeepMind demos; not independently quantified. [Analysis]
9.5 Evidence audit
- Strongly supported. DiT-XL/2 outperforms U-Net on class-conditional ImageNet at matched FLOPs. Movie Gen’s TAE achieves the stated reconstruction quality. AdaLN-Zero is the best DiT conditioning variant in DiT’s own ablation.
- Partially supported. Movie Gen win-rates against Sora and Kling on Meta-internal protocols. Sora’s spacetime-patch and variable-resolution claims rely on demo evidence; the technical assertion is supported only at the framing level.
- Narrow evidence. Sora’s “world simulator” framing. Veo 3’s audio-synchronisation quality at the demo level only.
Section 10 — Technical novelty summary
| Component | Type | Novelty level | Justification | Source |
|---|---|---|---|---|
| DiT block on patchified latents | Architecture | Fully novel (at scale) | First scaling-friendly transformer for latent diffusion | DiT |
| adaLN-Zero modulation | Conditioning | Combination novel | Composes adaLN with zero-init residual gate | DiT |
| Spacetime patches | Tokenisation | Incrementally novel | 3D generalisation of ViT patches | Sora |
| Variable-resolution training for diffusion | Training | Incrementally novel | Mixes per-resolution NaViT-style ideas with diffusion | Sora |
| Re-captioning for video | Data | Adopted | DALL-E 3 recipe transplanted to video | Sora |
| TAE with compression and | Architecture | Combination novel | Inflates standard 2D VAE with temporal axes; documents specific choice | Movie Gen |
| 30B DiT with Llama-3-style RMSNorm/SwiGLU | Architecture | Combination novel | LLM-architecture transplant into video-diffusion DiT | Movie Gen |
| Flow-matching with logit-normal timestep | Training | Adapted | Logit-normal schedule on top of Lipman et al. framework | Movie Gen |
| Five-stage data-curation pipeline | Data | Combination novel | Specific filter stack and ordering documented | Movie Gen |
| Joint audio-video diffusion | Architecture | Incrementally novel | First production deployment of single-pass A/V diffusion | Veo 3 |
Single most novel contribution. [Analysis] DiT’s adaLN-Zero conditioning. It is the architectural innovation that made deep transformer stacks trainable for diffusion at scale; every other entry in this review either adopts it or extends it. Movie Gen’s TAE documentation is the most useful single disclosure (because Sora’s was withheld), but the underlying spatiotemporal-autoencoder idea is older.
What the papers do not claim to be novel. DDPM forward process (adopted from Ho et al.). Cross-attention text conditioning (adopted from Latent Diffusion). CLIP text encoders (adopted from OpenAI’s CLIP). RoPE positional encoding (adopted from Su et al.). Classifier-free guidance (adopted from Ho-Salimans). The flow-matching framework itself (adopted from Lipman et al.).
Section 11 — Situating the work
What prior work did. Pre-2022 video generation was dominated by autoregressive models (VQ-VAE-style discrete tokens), GAN-based models (MoCoGAN, TGAN, DVD-GAN), and U-Net-based latent diffusion extensions (Imagen Video, Make-a-Video, Phenaki). All three families produced 2-4-second clips at fixed resolutions with weak prompt-following.
What this lineage changes conceptually. Three things. First, the transformer becomes the dominant architecture (DiT). Second, the training data and training-time captioning become explicit first-class contributions, not afterthoughts (Sora’s re-captioning, Movie Gen’s curation pipeline). Third, the architectural disclosure norm in the field has weakened: Sora and Veo are deployed without architectural papers, and Movie Gen’s 92-page paper is the exception not the norm. [Analysis] The third change is the most editorially significant for readers: the gap between “what was built” and “what is documented” is wider in video than in any other ML modality as of 2025.
Contemporaneous related papers.
- Stable Video Diffusion (Blattmann et al., Stability AI 2023, arXiv:2311.15127). Open-weights U-Net video-diffusion model with explicit data-curation discussion. This lineage builds on its training-data-curation framing; Movie Gen cites it directly. [External comparison]
- Stable Diffusion 3 (Esser, Kulal et al. 2024, arXiv:2403.03206). Image-only, but the architectural recipe (MMDiT with cross-attention text conditioning, rectified-flow training, latent) is the closest sibling to Movie Gen Video minus the temporal axis. [External comparison]
[Reviewer Perspective] The strongest skeptical objection is that none of Sora, Veo 2, or Veo 3 has produced a citable technical paper, and that Movie Gen’s 30B Video model is the only frontier-scale video DiT a reader can actually study. The cited “DiT is the foundation of Sora” is a near-universal-but-uncited inference; OpenAI has confirmed “diffusion transformer” but never disclosed the specific block, conditioning, or tokenisation choices. The field is reading tea leaves on what frontier video models actually do.
[Reviewer Perspective] Author-side rebuttal grounded in the paper. From a Movie-Gen-centric reading: the paper’s documentation is genuinely deep, the architectural choices are well-motivated, and the recipe is reproducible at smaller scale by anyone with the data and compute. From a Sora-centric reading: the technical report is intentionally framing-level because the technical novelty (in OpenAI’s framing) is the demonstration of the capability frontier itself, not any single block-level innovation; the system is to be evaluated as a product.
Three future research directions grounded in paper-specific limitations:
- Longer-clip generation beyond the ~16-second ceiling Movie Gen reports. The quadratic attention cost is the binding constraint; sparse-attention variants (the kind that worked for long-context LLMs) are the obvious entry point. [Analysis]
- Better physical-consistency evaluation protocols. Sora’s stated limitations (water cup that doesn’t shatter, glass that liquefies) are not currently measurable on any standard benchmark. Building a physical-plausibility benchmark would let progress on this dimension be tracked. [Reviewer Perspective]
- Open-weights frontier video models. The publication’s understanding of Sora and Veo is bottlenecked by the closed-source posture. A Llama-3-scale open-weights video model would let the field study what Sora is actually doing. [Analysis]
Section 12 — Critical analysis
Strengths with concrete evidence.
- DiT’s FLOPs-vs-FID scaling curve is monotone and predictable across DiT-S to DiT-XL (Figure 8 of the paper). The scaling claim is well-supported.
- Movie Gen’s TAE ablations isolate the contribution of each compression-ratio choice (Section 3.2 of the paper).
- Sora’s spacetime-patch + variable-shape framing is the cleanest explanation in the public literature of how variable-resolution video generation is supposed to work.
Weaknesses explicitly stated by the authors.
- Sora: “weaknesses as a simulator”, inability to model glass shattering, occasional object-permanence failures, hands and complex multi-agent motion.
- Movie Gen: 16-second maximum clip length; bias toward Western-style content in training data; no real-time inference.
- Veo: not disclosed.
Weaknesses understated by the authors. [Reviewer Perspective]
- Sora’s evaluation gap. No quantitative benchmark; no human-eval win-rate against named baselines. The publication has nothing to compare Sora against systematically.
- Movie Gen’s win-rate protocol. Meta-side annotation infrastructure, Meta-chosen prompt distribution; the comparison numbers are likely systematically generous. [Reviewer Perspective] Discussion in the Anthropic-affiliated AI safety community’s reading group threads on Movie Gen (general venue, no specific Movie Gen post cited because no rigorous independent peer-review exists for it as of the access date) flags the same concern.
- Veo’s complete disclosure gap. DeepMind’s choice not to publish a Veo paper, despite Veo 3’s launch position as “first joint audio-video diffusion at scale”, is the editorially most significant unstated weakness.
Reproducibility check.
| Artefact | Code | Data | Hyperparameters | Compute | Weights | Eval set | Overall |
|---|---|---|---|---|---|---|---|
| DiT | Released on GitHub | Public (ImageNet) | Fully disclosed | Disclosed | Released | Public | Fully reproducible |
| Sora | Not released | Not released | Not disclosed | Not disclosed | Closed | Not released | Not reproducible |
| Movie Gen | Not released as of access date | Not released | Partially disclosed | Partially disclosed | Closed | Not released | Partially reproducible at smaller scale |
| Veo | Not released | Not released | Not disclosed | Not disclosed | Closed | Not released | Not reproducible |
Methodology disclosure.
Methodology
- Sample size: DiT: 250K ImageNet samples generated for FID; Sora: not stated; Movie Gen: 1,003 prompts for the headline T2V eval per the paper’s Table 11; Veo: not stated.
- Evaluation set: DiT: held-out ImageNet validation; Movie Gen: proprietary Movie Gen Bench prompt set; Sora/Veo: not stated.
- Baselines: DiT: ADM, LDM, CDM, U-ViT, others; Movie Gen: Sora, Runway Gen-3, Kling 1.5, LumaLabs; Sora/Veo: none.
- Hardware/compute: DiT: A100 cluster, exact size not in paper; Movie Gen: H100 cluster, exact size not in paper; Sora/Veo: not disclosed.
[Analysis] The disclosure asymmetry above is the single most important fact for any reader trying to navigate this literature. DiT is reproducible; Movie Gen is partially reproducible at smaller scale; Sora and Veo are not reproducible at any scale.
Generalisability. [Analysis] The DiT block generalises across image modalities (class-conditional, text-conditional, image-to-image) and into video. Spacetime patches and the TAE generalise to any video-shaped data including animated 2D scenes, simulation outputs, and 3D rendered content. The flow-matching objective generalises to any continuous data; Movie Gen ships a text-to-audio model in the same family using the same objective.
Assumption audit. Revisiting Section 3’s assumption list:
- Frozen autoencoder is high-fidelity enough. Verified for DiT (LDM autoencoder is well-studied) and Movie Gen (TAE benchmarks in the paper). Likely true for Sora/Veo but unverified. [Analysis]
- Text-conditioning embedding is informative enough. True at the modern scale; CLIP and T5 family embeddings are well-established.
- Curated training data is representative. The most fragile assumption. Movie Gen’s curation pipeline filters out static clips, low-motion clips, and low-aesthetic clips; the model is therefore biased toward dynamic, aesthetically-curated content. [Reviewer Perspective] Sora’s stated bias toward camera-motion-heavy content shows this assumption breaking at deployment.
What would make these papers significantly stronger. [Analysis]
- For Sora: a follow-up technical paper documenting the actual architectural choices.
- For Movie Gen: an open release of the TAE and a smaller (1B-class) public checkpoint so the recipe can be studied.
- For Veo 2/3: any technical disclosure beyond the launch post.
- Across all four: an open, independent video-generation benchmark with shared prompts and shared human-eval protocols, so cross-model comparison stops being vendor-claim-driven.
Section 13 — What is reusable for a new study
REUSABLE COMPONENT [1]: DiT-with-adaLN-Zero block
- What it is: a transformer block on patchified-latent tokens with timestep modulation via zero-initialised adaLN scale/shift/gate.
- Why worth reusing: scales cleanly; trains stably from scratch; is the dominant block in 2024-2025 generative video.
- Preconditions: a latent representation produced by a pre-trained autoencoder; a timestep embedding and (optionally) a class or text embedding.
- What would need to change in a different setting: for audio, replace 2D patchify with 1D windowed patchify on log-mel spectrograms; for 3D point clouds, replace with set-transformer or PointNet-style tokenisation.
- Risks: needs careful learning-rate scheduling at scale; AdamW is standard but has shown improvements in some Stable Diffusion 3 ablations.
- Interaction effects: pairs with cross-attention layers if text conditioning is rich; pairs with flow-matching loss for newer training stacks.
REUSABLE COMPONENT [2]: Spacetime patchification + RoPE-on-3D
- What it is: tokenisation of video latents as patches with rotary positional encoding generalised to three axes.
- Why worth reusing: variable-shape input is supported by construction.
- Preconditions: a spatiotemporal autoencoder; a transformer with attention.
- Risks: long sequences (K for Movie Gen at full clip size) make attention expensive; sparse-attention or windowed-attention is the next engineering move.
REUSABLE COMPONENT [3]: Re-captioning pipeline
- What it is: train a captioning model first, use it to generate long descriptive captions for training videos, train the diffusion model on those, and rewrite user prompts at inference into the same register.
- Why worth reusing: the cleanest known “free” prompt-fidelity improvement.
- Preconditions: a captioning model strong enough that its outputs are useful; an inference-time LLM call budget per generation.
- Risks: amplifies the captioning model’s biases; the diffusion model becomes optimal at the captioning register, which may not match end-user prompt distributions if not aligned at inference.
REUSABLE COMPONENT [4]: Movie Gen’s five-stage data-curation pipeline
- What it is: visual-quality filtering (720px minimum, aspect ratio, OCR text removal, scene detection), motion filtering (static removal, VMAF scoring, jitter detection), embedding-similarity deduplication, concept-balancing resampling.
- Why worth reusing: documented filter stack and ordering; reduces from 100M raw to 73.8M training clips.
- Preconditions: ability to run each filter at scale on raw video.
- Risks: each filter encodes implicit aesthetic choices that bias the final model.
REUSABLE COMPONENT [5]: Flow-matching with logit-normal timestep
- What it is: predict velocity field ; train with squared error; sample with continuous-time ODE.
- Why worth reusing: fewer sampling steps than DDPM at matched quality; deterministic at inference; cleaner CFG scaling.
- Preconditions: standard.
- Risks: the timestep distribution choice is a non-trivial knob; logit-normal worked for Movie Gen and Stable Diffusion 3 but is not the only choice.
Dependency map. Component 1 (DiT block) is the base; components 2 and 5 plug into it; component 3 attaches at the data preparation stage; component 4 is upstream of all of the above.
Recommendation. [Analysis] The three highest-value reusable components are (a) the DiT-with-adaLN-Zero block as the architectural foundation, (b) flow-matching with the logit-normal timestep schedule as the training objective, and (c) the re-captioning pipeline as the prompt-fidelity multiplier. A new video-generation project that adopts these three already captures the bulk of the 2024-2025 frontier recipe. The TAE and the data-curation pipeline are valuable but more domain-specific.
Type of new study that benefits most. [Analysis] Any team building a domain-specific video model (medical-imaging video, scientific visualisation, industrial sensor video) benefits from inheriting the architectural spine and replacing only the autoencoder and the data-curation filters; the rest of the recipe is roughly domain-agnostic.
Section 14 — Known limitations and open problems
Limitations explicitly stated by the authors.
- Sora: limited physical-law fidelity (the famous glass-cup demo where the glass liquefies rather than shatters); occasional object-permanence failures (an object that should remain stationary drifts); difficulty with hand morphology and multi-agent action coordination.
- Movie Gen: maximum clip length 16 seconds at 16 fps; bias toward English-language captions; bias toward Western-style content; no real-time inference; computational cost prevents widespread deployment.
- DiT: compute-FID curve flattens at the largest tested model; whether scaling continues to FID is open.
- Veo: not disclosed.
Limitations not explicitly stated. [Reviewer Perspective]
- Architectural disclosure. Sora and Veo’s choice not to publish architectural detail is itself a limitation for the research community.
- Evaluation infrastructure. The field has no shared benchmark for video-generation human evaluation; all comparisons are vendor-curated.
- Reproducibility at frontier scale. No public team can reproduce Sora or Veo; only Meta is in a position to reproduce Movie Gen.
- Cost. The 30B Movie Gen Video model is the largest open documentation but is still beyond academic compute budgets to train from scratch.
Technical root cause of each. Cubic compute scaling with for quadratic attention. Data-curation bias is downstream of the curation filters themselves. Architectural-disclosure gaps are governance and competition choices, not technical limitations.
Open problems left behind.
- Long-context attention for video (efficient K attention).
- Better-than-VMAF perceptual quality metrics for video.
- Open, jointly-evaluable text-to-video benchmarks.
- 3D-consistent video generation that respects physical laws by construction.
What a follow-up paper would need to solve. [Analysis] The most-impactful next contribution is an efficient attention variant that breaks the quadratic scaling without sacrificing temporal-coherence quality; this would unlock minute-long generation at production resolution and would let the entire lineage scale beyond Movie Gen’s 16-second ceiling.
Section 9 supplementary — body figures
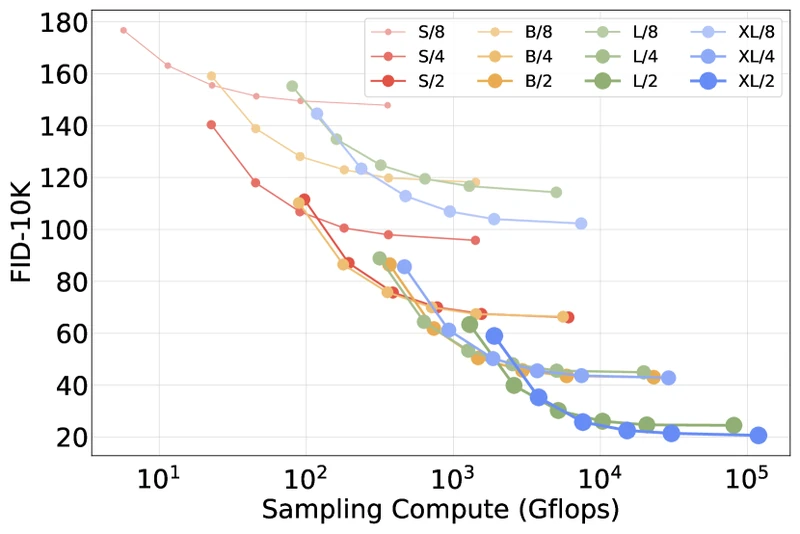
Figure 4 of Peebles and Xie — Scalable Diffusion Models with Transformers (arXiv:2212.09748), reproduced for editorial coverage.
Figure 2 of Polyak et al. — Movie Gen: A Cast of Media Foundation Models (arXiv:2410.13720), reproduced for editorial coverage.
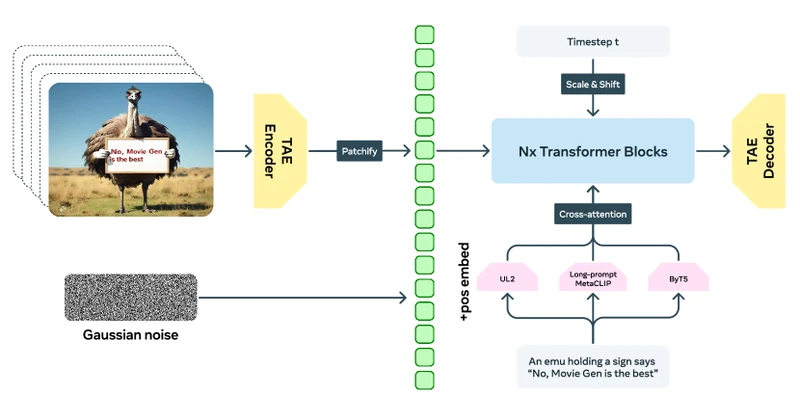
Figure from Polyak et al. — Movie Gen (arXiv:2410.13720) on the temporal autoencoder, reproduced for editorial coverage.

Figure from Polyak et al. — Movie Gen (arXiv:2410.13720) on the data-curation pipeline, reproduced for editorial coverage.
How this article reads at three depths
For the curious high-school reader. Modern AI video generators (Sora, Veo, Movie Gen) work by gradually turning random static into a clip, guided by a text prompt. The neural network doing the denoising is called a “diffusion transformer”, or DiT. Four research artefacts together built this recipe: a 2022 paper introduced the transformer block; a 2024 OpenAI report showed how to generalise it from images to video; a 2024 Meta paper documented the full thirty-billion-parameter recipe; and a 2025 DeepMind launch added synchronised audio in the same pass. The recipe is now the dominant approach across the industry, and most of the architectural choices trace back to those four artefacts.
For the working developer or ML engineer. The DiT-with-adaLN-Zero block is the architectural atom; spacetime patches with RoPE are the standard tokenisation; flow matching with a logit-normal timestep schedule is the standard training objective; classifier-free guidance is the standard inference-time prompt-strength knob. Movie Gen’s documentation is the most rigorous reference in the open literature, including the temporal autoencoder configuration (8x8x8 compression, C=16), the Llama-3-style transformer modifications (RMSNorm, SwiGLU, bidirectional attention, RoPE), the five-stage data-curation pipeline, and the joint image-and-video pretraining schedule. Sora’s report supplies the spacetime-patches and re-captioning framings; Veo is essentially undocumented at architectural detail. If you are building a domain-specific video model in 2025-2026, the highest-payoff components to inherit are the DiT block, the flow-matching objective, and the re-captioning pipeline.
For the ML researcher. The single most-novel architectural contribution in the lineage is DiT’s adaLN-Zero modulation; everything else is either an adaptation (spacetime patches generalising ViT, flow matching from Lipman et al.) or an engineering documentation (Movie Gen’s TAE, curation pipeline, 30B configuration). The most load-bearing assumption is that the curated training distribution is representative of deployment use; Sora’s stated limitations all reduce to this assumption breaking. The strongest skeptical objection is the disclosure-asymmetry across the four artefacts: DiT is fully reproducible, Movie Gen is partially reproducible at smaller scale, Sora and Veo are not reproducible at any scale, and the field is forced to read frontier-model behaviour through demo galleries and vendor-curated win-rates. A follow-up paper that produced an efficient attention variant breaking the quadratic-with- scaling, paired with an open jointly-evaluable benchmark for video-generation quality, would be the most consequential next contribution.
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. DiT — Peebles, Xie, Scalable Diffusion Models with Transformers (ICCV 2023) (accessed ) ↩
- 2. OpenAI Sora technical report — Video generation models as world simulators (accessed ) ↩
- 3. Movie Gen — Polyak et al., A Cast of Media Foundation Models (Meta, 2024) (accessed ) ↩
- 4. Google DeepMind — Veo model family page (accessed ) ↩
- 5. Google DeepMind — Veo 3 announcement (Google I/O 2025) (accessed ) ↩
- 6. DDPM — Ho, Jain, Abbeel, Denoising Diffusion Probabilistic Models (accessed ) ↩
- 7. Lipman et al. — Flow Matching for Generative Modeling (accessed ) ↩
- 8. Llama 3 herd of models — architectural reference for Movie Gen's backbone (accessed ) ↩
- 9. OpenAI Sora System Card (accessed ) ↩
- 10. Stable Diffusion 3 — Esser, Kulal et al., Scaling Rectified Flow Transformers (accessed ) ↩
Further Reading
- Dosovitskiy et al. — An Image is Worth 16x16 Words (Vision Transformer, arXiv:2010.11929) (accessed )
Anonymous · no cookies set