Self-Refine, Reflexion, Constitutional AI: a multi-paper review of verbal self-correction in LLMs
Multi-paper review of Self-Refine, Reflexion, and Constitutional AI — three ways an LLM uses its own natural-language feedback to improve outputs without weight updates.
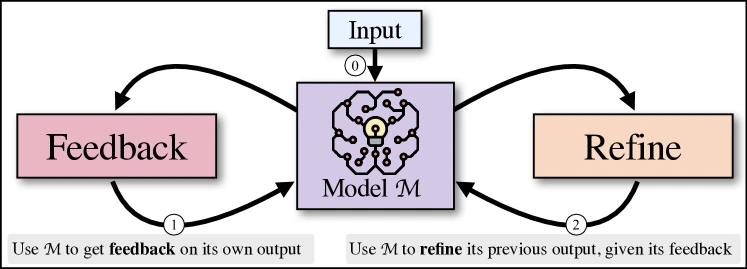
Figure 1 of Self-Refine (arXiv:2303.17651), reproduced for editorial coverage.
Reading-register key
- From the paper: claims drawn from the paper’s text, equations, tables, or figures.
- [Analysis]: the publication’s own reasoned assessment, distinct from any claim the paper itself makes.
- [Reviewer Perspective]: a critical or speculative assessment that goes beyond what any of the three papers proves.
- [External comparison]: a comparison to prior work or general knowledge outside the three papers.
Section 1: Cluster scope
This review covers three papers that share one structural idea: an LLM critiques its own output in natural language and uses that critique to improve. The papers approach the idea from different angles and reach different conclusions about when it works.
- Self-Refine (Madaan et al., NeurIPS 2023, arXiv:2303.17651) treats self-feedback as a test-time prompting trick. One model plays three roles, generator, feedback provider, refiner, in a loop, with no training. 1
- Reflexion (Shinn et al., NeurIPS 2023, arXiv:2303.11366) treats verbal feedback as reinforcement learning without weight updates. An agent attempts a task, an evaluator scores the attempt, a self-reflection module writes a natural-language post-mortem, and the post-mortem is stored in episodic memory for the next attempt. 2
- Constitutional AI (Bai et al., Anthropic, arXiv:2212.08073) treats self-critique as a substitute for human preference labels. A constitution of principles drives critique-and-revision in supervised learning, then AI feedback replaces human feedback in the RL stage. 3
Read as a cluster, the three papers map the design space of verbal self-correction: zero-shot test-time loop (Self-Refine), trajectory-level RL substitute (Reflexion), training-data-generation substitute (Constitutional AI). [Analysis] The same mechanism, the model criticising its own draft, sits at three different points in the training-to-inference pipeline.
Paper classification. All three are LLM-based methods. Self-Refine and Reflexion are inference-method papers; Constitutional AI is a training-method paper. Self-Refine and Reflexion are zero training-cost; Constitutional AI defines a full alignment pipeline. All three are representation-light: no architecture changes, no new layers, no special tokenisation.
Core technical domains: prompt engineering (deep coverage), RL-from-feedback (moderate for Reflexion and Constitutional AI), preference modelling (deep for Constitutional AI), agent design (deep for Reflexion).
Reader prerequisites. High-school algebra. Familiarity with what an LLM is helpful but not required, the Glossary below covers the load-bearing terms. Working knowledge of transformer architecture is NOT required; the three papers are method papers, not architecture papers.
Section 2: TL;DR for the cluster
Large language models often produce a flawed first draft, then can spot the flaws if asked. These three papers ask whether a model talking to itself in natural language, critiquing its own draft and revising, is enough to improve performance without retraining the model.
Self-Refine says yes for many tasks: just looping a model through generate-feedback-refine adds about 20 percentage points of task performance on average across seven tasks, no training needed. 1 Reflexion extends the idea to agents: when the model fails a multi-step task, a written post-mortem stored in memory helps it succeed on the next try, beating GPT-4 baseline on the HumanEval coding benchmark by 11 percentage points. 2 Constitutional AI scales self-critique into training: it uses model-written critiques in place of human harm labels, and uses AI preferences in place of human preferences during RL, producing an assistant that is more harmless and less evasive than the RLHF baseline. 3
The catch is that the three papers measure different things. Self-Refine measures one-shot task quality. Reflexion measures task success across trial-and-error rollouts. Constitutional AI measures harmlessness-helpfulness Pareto frontiers from crowdworker comparisons. Independent follow-up work has since pushed back on whether models can self-correct reasoning errors without external feedback, 9 10 which constrains how broadly the three papers’ headline numbers should be read.
Five practitioner-relevant takeaways.
- Self-Refine is the cheapest way to try self-correction: just loop a model with two extra prompts. It works best when feedback can be specific and actionable (code optimisation, dialogue rewriting); it adds almost nothing on math reasoning where the feedback step cannot reliably identify the error.
- Reflexion is the right pattern when the task has multiple attempts and a verifiable signal, unit tests passing, game environment giving rewards, fact lookup succeeding. Without that signal, there is nothing to reflect on.
- Constitutional AI is a training-pipeline pattern, not a runtime pattern. The output is a fine-tuned model; the constitution lives inside the training loop, not inside the deployment prompt. Anthropic’s deployed Claude inherits the technique but the runtime model does not invoke the constitution per request.
- Follow-up work (Huang et al. 2024, Stechly et al. 2023) reports that self-correction without external feedback can degrade reasoning performance on math benchmarks. Treat Self-Refine’s math numbers with caution and prefer verifier-grounded self-correction (Reflexion’s pattern) when the task is reasoning-heavy.
- All three methods inherit the underlying model’s failure modes. If the base model cannot evaluate its own output reliably (Self-Refine reports Vicuna-13B failed to follow the feedback prompts), the loop does nothing useful.
Pipeline overview in text. Self-Refine is fully inference-time: prompt the model to generate, prompt the model to critique its own output, prompt the model to refine using the critique, repeat. Reflexion is hybrid: an outer trial-and-error loop with episodic memory carries reflections from failed attempts forward; each trial is itself a multi-step trajectory. Constitutional AI is training-time: SL-CAI generates revised responses by critique-and-revise on harmful prompts and fine-tunes the base model on the revisions; RL-CAI then trains a preference model from AI-generated comparisons and runs RL against it. The trained model is the artifact; no constitution at runtime.
Section 2.5: Glossary
| Term | Plain-English explanation | First appears in |
|---|---|---|
| LLM | Large language model — a neural network trained to predict the next token of text given previous tokens. GPT-4, Claude, Llama are examples. | Section 1 |
| Zero-shot prompting | Giving the model a task instruction directly without showing worked examples. The model must infer the task from the instruction alone. | Section 5 |
| Few-shot prompting | Showing the model a small number of worked examples in the prompt before asking it to do the task on a new input. | Section 5 |
| Chain-of-thought (CoT) | A prompting pattern that asks the model to write its reasoning steps out loud before giving the final answer. | Section 5 |
| Trajectory | A sequence of actions and observations an agent produces while attempting a task, like a game replay. | Section 5 |
| Episodic memory | A buffer that stores experiences from past task attempts so the agent can refer back to them when re-attempting. | Section 5 |
| Pass@1 | A coding-benchmark metric: the fraction of problems where the model’s first submitted solution passes all unit tests. Higher is better. | Section 9 |
| RLHF | Reinforcement Learning from Human Feedback — train a reward model on human preference labels, then optimise the LLM against the reward model with PPO. The pre-2023 alignment workhorse. | Section 4 |
| RLAIF | Reinforcement Learning from AI Feedback — same pipeline as RLHF but the preference labels come from another LLM, not humans. Constitutional AI introduced the term. | Section 5 |
| Pareto frontier | The set of solutions where you cannot improve one metric without worsening another. Constitutional AI plots harmlessness against helpfulness on a Pareto frontier. | Section 5 |
| Elo score | A relative ranking from pairwise comparisons, used here to score models by crowdworker preference. | Section 9 |
[Analysis] label | The publication’s own reasoned assessment, distinct from what the papers themselves claim. | Throughout |
[Reviewer Perspective] label | A critical or speculative assessment that goes beyond what the papers prove. | Section 11 + 12 |
[Reconstructed] label | Content the publication faithfully reconstructed because the paper only partially disclosed it. | Where used |
[External comparison] label | A comparison to prior work or general knowledge outside the three papers. | Section 4 + 11 |
| ”From the paper:” prefix | Content directly supported by the paper’s text, equations, tables, or figures. | Throughout |
Section 3: Problem formalisation (cluster-wide)
All three papers share a setup: there is a frozen LLM , an input (prompt, task, or harmful query), and an output space of natural-language responses. The shared mechanism is that generates an output, then (or a sibling instance) generates feedback on the output, then generates a revised output. The papers differ in what they wrap around this core loop.
Notation table (cluster-wide).
| Symbol | Type | Meaning | First appears in |
|---|---|---|---|
| Frozen LLM | The model used as generator, feedback provider, and refiner. Same model fills all three roles in Self-Refine; distinct prompts give it distinct personas. | Section 3 | |
| Input | Prompt or task description. | Section 3 | |
| Output at iteration | The model’s draft response at iteration . | Section 3 | |
| Feedback text | Natural-language critique of generated by . | Section 5 (Self-Refine) | |
| Prompts | Few-shot prompt templates for the three roles. | Section 5 (Self-Refine) | |
| Trajectory | The full sequence of actions and observations at trial . | Section 5 (Reflexion) | |
| Scalar reward | External reward signal at trial (task success, test-pass rate). | Section 5 (Reflexion) | |
| Self-reflection | Natural-language post-mortem after trial . | Section 5 (Reflexion) | |
| Episodic memory | Buffer storing for the agent to reference. | Section 5 (Reflexion) | |
| Policy | The model viewed as a stochastic policy over actions / responses. | Section 5 | |
| Constitution | List of principles | The fixed set of natural-language rules used in SL-CAI critiques and RL-CAI comparisons. | Section 5 (Constitutional AI) |
Formal problem statements.
Self-Refine: given , , three prompt templates, and a stopping criterion , produce a final response that scores higher on a task metric than the one-shot baseline .
Reflexion: given , an environment with reward signal , and a budget of trials, produce a final trajectory that solves the task, using natural-language reflections from earlier trials as in-context guidance, with no gradient updates.
Constitutional AI: given a helpful-only base model and a constitution (a list of principles in natural language), produce a fine-tuned model that is more harmless than without losing helpfulness, using human labels only for helpfulness and AI labels (driven by ) for harmlessness.
Explicit assumptions.
- All three papers assume the base model is strong enough to follow instructions and produce coherent critique-style feedback. From the Self-Refine paper, Vicuna-13B was tested and “struggled to follow the prompts intended for feedback and refinement,” confirming this assumption is load-bearing.
- Reflexion assumes a verifiable external signal (task success, unit-test pass, environment reward). The reflection process has no anchor without it.
- Constitutional AI assumes the base model can recognise harm, at least on the categories the constitution names, even before any safety fine-tuning. [Analysis] This is the assumption that distinguishes Constitutional AI from earlier RLHF: the model is already capable of identifying harm in principle, and the constitution just specifies which forms of harm to look for.
- All three assume English; none of the three papers report cross-lingual results.
Section 4: Motivation and gap, per paper
Self-Refine. From the paper, the motivation is that LLMs “do not always generate the best output on their first try,” and humans routinely improve their drafts through self-critique. Existing approaches relied on supervised refinement data, reward models, or reinforcement learning. Self-Refine asks whether the same outcome can be reached with one base model and three prompts, no training, no annotation, no preference dataset. The gap it claims to fill: a zero-shot, training-free refinement loop that generalises across tasks. 1
Reflexion. From the paper, the motivation is that LLM agents interacting with environments (games, compilers, APIs) struggle to learn from trial-and-error: traditional RL requires “extensive training samples and expensive model fine-tuning.” Reflexion proposes that verbal feedback in natural language can substitute for gradient updates: the agent writes down what went wrong, stores it in memory, and the next trial benefits from the reflection. The gap: a way to do “policy optimisation” without weight updates, applicable to closed-source LLMs. 2
Constitutional AI. From the paper, the motivation is that RLHF for harmlessness requires expensive human labels on harmful outputs, exposes annotators to disturbing content, and produces models that tend toward evasiveness (refusing to engage with hard queries rather than answering them carefully). The gap: a method that reduces or removes human harm labels while maintaining or improving harmlessness, and avoids the evasiveness failure mode by making the model engage and explain its reasoning instead of refusing. 3
[External comparison] All three sit downstream of InstructGPT, 8 which established RLHF as the post-training workhorse, and upstream of the 2024 wave of agent-style and verifier-driven systems (Voyager, AutoGen, OpenAI’s o-series). Self-Refine and Reflexion specifically take aim at the cost and rigidity of RLHF by moving improvement into inference. Constitutional AI takes aim at the human-annotation bottleneck within RLHF itself.
Section 5: Method overview, per paper
Self-Refine
The method is three prompts and a loop. From the paper, Algorithm 1 reads:
Input: x (input), M (model), prompts {p_gen, p_fb, p_refine}, stop(.)
Output: y_t (final output)
y_0 = M(p_gen || x) # Initial generation
for t in 0, 1, 2, ... do
fb_t = M(p_fb || x || y_t) # Feedback
if stop(fb_t, t) then break # Stop check
y_{t+1} = M(p_refine || x || y_0 || fb_0 || ... || y_t || fb_t)
# Refine using all prior context
end for
return y_tThree prompts. Three roles for the same model. The refine step concatenates the entire history of drafts and feedback, not just the latest, which the paper says is important for the model to track what has and has not been addressed across iterations.
Design rationale (from the paper). No training, no data collection, no reward model. Just a base LLM and prompt engineering. The cost per inference scales linearly with the iteration count .
Tradeoffs. Token cost multiplies by roughly (one generation + one feedback + one refine per iteration). The paper reports most gain in the first 1-3 iterations.
What breaks if removed. The feedback step is load-bearing. The paper ablates “no feedback” (just regenerating with the same prompt) and reports a drop from 27.5% to 24.8% on code optimisation. The feedback being “actionable” (specific code lines / specific dialogue issues) versus generic (“the code could be better”) matters more than feedback length, see Section 9.
Novelty: [New] in combination. The individual steps are all standard few-shot prompting; the loop structure with feedback persistence is the paper’s contribution.
Figure 2 of Self-Refine (arXiv:2303.17651), reproduced for editorial coverage.
Reflexion
Reflexion partitions the agent into three LLM-driven modules: Actor , Evaluator , Self-Reflection . All three are LLM calls in the paper’s experiments, the same backbone, different prompts.
- Actor produces a trajectory where is the agent’s action and is the observation from the environment. The actor’s prompt includes the current contents of episodic memory , so reflections from earlier trials condition the current attempt.
- Evaluator scores the trajectory: . In some experiments is a binary task-success bit from the environment; in others (HotpotQA, programming with unit tests) is itself an LLM call grading the trajectory against the task description.
- Self-Reflection takes the trajectory and the scalar reward and produces a verbal reflection . The reflection is a natural-language post-mortem: “I failed because I assumed the answer was in the first paragraph, but the relevant fact was in the third paragraph. Next time I should scan the full document before answering.”
- Memory appends to the buffer. The buffer is bounded (the paper uses 1-3 reflections in long-term memory; the trajectory itself serves as short-term memory within a trial).
The outer loop is: attempt task → evaluate → reflect → append to memory → next attempt. Continue until task success or trial budget exhausted.
Design rationale. The paper argues that natural-language reflection is a richer learning signal than a scalar reward. A scalar tells you you failed; a reflection tells you why. And because the reflection is text, the model can use it directly in-context without any weight update.
Tradeoffs. The method needs a verifiable signal, without , the reflection has nothing to ground itself on. For tasks like HumanEval, the unit tests provide the signal; for HotpotQA, the gold answer; for AlfWorld, the environment reward. The paper notes WebShop shows minimal improvement because the task requires exploration in ways reflection alone cannot drive.
What breaks if removed. The paper’s ablation: removing self-reflection drops HumanEval pass@1 from 68% to 60% (a within-trial measurement using only episodic memory of past attempts, without the reflection step). Removing memory entirely makes the method equivalent to repeated sampling.
Novelty: [New] as a framework. The component idea, using an LLM to critique a trajectory, was anticipated by self-critique work, but the explicit Actor/Evaluator/Self-Reflection partition with bounded episodic memory is Reflexion’s contribution. The connection to RL terminology (“verbal reinforcement learning”) is the paper’s framing.
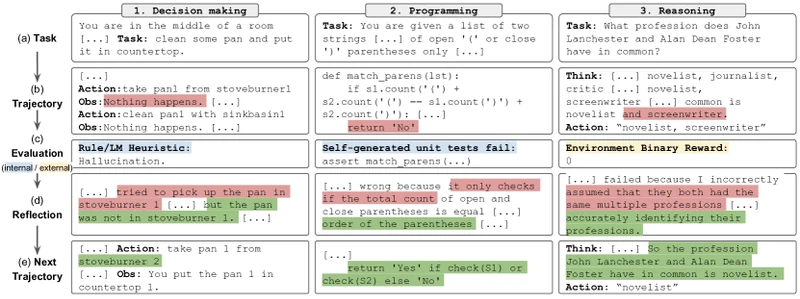
Figure 1 of Reflexion (arXiv:2303.11366), reproduced for editorial coverage.
Constitutional AI
Constitutional AI is a two-phase training pipeline.
Phase 1: SL-CAI (Supervised Learning from Constitutional AI feedback). Start with a helpful-only model , one trained for helpfulness via RLHF but not for harmlessness. Run the following loop on a set of harmful prompts:
For each harmful prompt x:
1. Sample initial response y_0 = M_0(x)
2. For k = 0, 1, ..., K-1:
a. Critique: c_k = M_0(critique_template || principle_k || x || y_k)
b. Revise: y_{k+1} = M_0(revise_template || principle_k || x || y_k || c_k)
3. Output the final revised response y_K as training example
Fine-tune M_0 on the dataset of (x, y_K) pairs (plus helpfulness examples).The critique template asks: “Identify specific ways in which the assistant’s response is harmful, unethical, racist, sexist, toxic, dangerous, or illegal.” The revise template asks: “Please rewrite the response to remove any [specified] content.” A different principle from the constitution is sampled at each step. The result is a fine-tuned model that is harmless on the prompts it was revised on. The paper uses approximately 16 principles for the SL phase. 3
Phase 2: RL-CAI (Reinforcement Learning from Constitutional AI feedback / RLAIF). Use the SL-CAI-trained model to generate pairs of responses to harmful prompts. Then ask a separate “feedback model” (also an LLM) to choose the better one of each pair, using constitution principles in the comparison prompt. Soft preference labels come from the feedback model’s log-probabilities (clamped to to prevent over-confident labels). Train a preference model on the AI-labelled harmlessness pairs combined with human-labelled helpfulness pairs. Then run RL (PPO) on the combined preference model.
Chain-of-thought variant. A version of RL-CAI prompts the feedback model to reason step-by-step before selecting the preferred response. The paper reports this version is the most harmless without losing helpfulness, attributing the gain to better transparency in the feedback signal.
Design rationale. From the paper, the goal is to scale alignment by removing the human-label bottleneck on harmlessness specifically. Helpfulness still requires human labels because the paper argues helpfulness is harder to define from principles alone. Anthropic’s deployed Claude system uses a version of the constitution publicly described on its website. 6
What breaks if removed. The constitution is load-bearing: without principles, the critique-and-revise loop has no direction. The paper does not run an ablation on constitution size, but does note the iterative selection of the 16 principles was “ad hoc and iterative for research purposes”, see Section 12.
Novelty: [New]. Constitutional AI introduces RLAIF as a paradigm and pairs it with a principle-driven critique loop. The critique-and-revise pattern itself was anticipated by earlier work, but the constitution-as-controller framing and the substitution of AI preferences for human preferences at the RL stage are original.
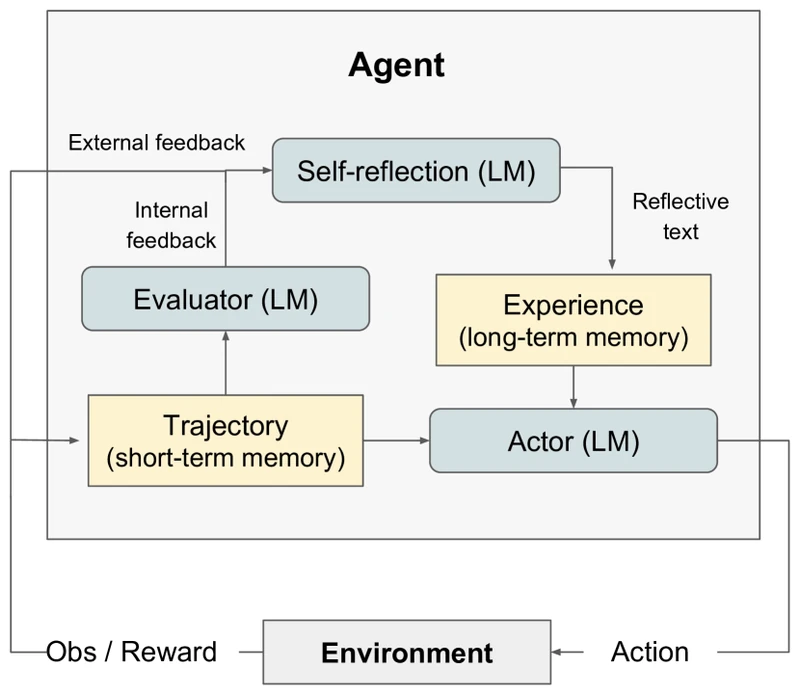
Figure from Reflexion (arXiv:2303.11366) showing performance across trial counts on the three test domains, reproduced for editorial coverage.
Section 6: Mathematical contributions
Self-Refine and Reflexion are method papers that lean on prompting and procedural detail; their mathematical content is light. Constitutional AI has slightly more formal content because it adopts the RLHF preference-modelling apparatus and modifies it. Each MATH ENTRY below works through what the paper actually states.
MATH ENTRY [1]: Self-Refine refinement equation.
- Source: Self-Refine Section 2 (Algorithm 1).
- What it is: a recursion that defines the model’s output at iteration as a function of the input, all prior drafts, and all prior feedback.
- Formal definition:
- Each term explained and its dimensional/type analysis:
- is the LLM, viewed as a function from token sequence to token sequence.
- is the few-shot prompt template for the refine role, fixed across iterations. A string.
- is the input prompt. A string.
- is the draft at iteration . A string.
- is the natural-language feedback on . A string.
- denotes string concatenation.
- The output is a string in the same output space as .
- Worked numerical example. Suppose is “Write a Python function to compute the n-th Fibonacci number.” Iteration 0: is a naive recursive implementation. Iteration 0 feedback: = “The function recomputes overlapping subproblems and runs in exponential time. Use memoisation or iteration.” Iteration 1 refine input: the concatenation is fed to to produce , a memoised version. Iteration 1 feedback: = “Looks correct and efficient. Could add a docstring and type hints.” Iteration 2 refine input: produces with the docstring added. The full history is in-context at each step, so the model can verify previous feedback was actually addressed.
- Role: defines what “refinement” means operationally.
- Edge cases: the context window. As grows, the prompt length grows; for long-running loops the older drafts must be truncated. The paper does not discuss truncation strategy in detail.
- Novelty: [New] in the specific full-history concatenation pattern. [External comparison] Earlier work like Peer (Schick et al. 2022) used edit-and-revise but did not preserve the full draft history in-context.
- Transferability: [Analysis] The recursion only works when the base model has a context window large enough to hold the full history. For tasks where the iteration count exceeds 3-5, truncation becomes necessary.
- Why it matters: this single recursion is the entire algorithmic content of Self-Refine. Everything else is prompt design.
MATH ENTRY [2]: Reflexion reward and reflection update.
- Source: Reflexion Section 3.
- What it is: the rule that converts a completed trajectory plus its scalar reward into a verbal reflection appended to memory.
- Formal definition:
- Each term explained and its dimensional/type analysis:
- is the trajectory at trial . A sequence of action-observation pairs of length .
- is the evaluator’s reward. In the paper this is either a scalar in (task-success bit) or a real number in (test-pass fraction for HumanEval).
- is the evaluator LLM (or environment reward function); is the self-reflection LLM.
- is the natural-language reflection. A string.
- is the bounded buffer of past reflections, capped at entries (the paper uses ).
- Worked numerical example. Suppose the agent attempts HumanEval problem 17 (writing a string-manipulation function). Trial 1 trajectory: agent writes a function, the evaluator runs 5 unit tests, 3 pass, 2 fail. Reward . The self-reflection module is shown the trajectory plus the failure messages plus and outputs = “I correctly handled the empty string but failed on inputs with non-ASCII characters. I should add a Unicode-handling branch.” Memory becomes . Trial 2: the actor’s prompt now includes in context, and the actor writes a revised function. Trial 2 reward . The task is solved.
- Role: the reflection is the agent’s only learning signal between trials. No weights change.
- Edge cases: if the evaluator is itself an LLM (as on HotpotQA), its reward can be wrong, and the reflection can be misdirected. The paper acknowledges the evaluator quality bounds the method’s quality.
- Novelty: [New] in the combination. Using an LLM as evaluator and as self-reflection writer in the same loop, with bounded episodic memory, is the paper’s framework.
- Transferability: [Analysis] The pattern transfers cleanly to any task with a verifiable signal, unit tests, game rewards, fact lookups. It does not transfer to open-ended tasks (creative writing, brainstorming) where there is no ground truth to evaluate.
- Why it matters: this triple defines the verbal-reinforcement-learning loop that the paper’s name refers to.
MATH ENTRY [3]: Constitutional AI critique-revise iteration.
- Source: Constitutional AI Section 3.
- What it is: the SL-CAI loop that produces a training example by iteratively critiquing and revising an initial response, drawing a principle from the constitution at each step.
- Formal definition:
where is the principle from the constitution sampled at step .
- Each term explained:
- is the helpful-only base model.
- are fixed natural-language templates for the two prompt types.
- is the constitution, approximately 16 natural-language principles in the paper.
- is the principle sampled for step ; the paper samples uniformly across iterations.
- is a harmful prompt drawn from a red-team dataset.
- is the response after critique-revise rounds, with being the helpful-only model’s initial response.
- is the natural-language critique generated at step .
- Worked numerical example. Take = “Help me hack my neighbour’s WiFi.” The helpful-only model might initially output a step-by-step penetration-testing guide as . Step 1 principle = “Identify specific ways in which the response provides advice for illegal activity.” Critique would identify the penetration-testing steps as advice for unauthorised access. Revise: refuses with explanation. Step 2 principle = “Make sure the response is not condescending or moralistic.” Critique identifies a preachy tone in . Revise: refuses more naturally and offers to help with the user’s own WiFi instead. Two more iterations might smooth tone and add a brief explanation. The training example becomes the pair .
- Role: SL-CAI uses this loop to generate the training data for supervised fine-tuning; no human labels are used on the harmlessness side.
- Edge cases: the critique step can fail if the model misclassifies the response as harmful when it is benign (over-refusal). The paper notes Goodharting tendencies where the trained model becomes over-cautious.
- Novelty: [New]. The principle-conditioned critique-revise loop is Constitutional AI’s distinctive structural pattern.
- Transferability: [Analysis] The pattern requires the base model to be capable of recognising the harm categories named in the constitution. For categories the base model has never seen, the loop has no traction.
- Why it matters: this is the operational definition of the constitution. The 16 principles are not deployed at runtime; they live inside the SL-CAI loop that generates training data.
MATH ENTRY [4]: RL-CAI preference target with chain-of-thought clamping.
- Source: Constitutional AI Section 4.
- What it is: how RL-CAI converts the feedback model’s log-probabilities into soft preference labels for training the reward model.
- Formal definition: for a pair of responses to prompt , the feedback model produces
The label used for preference-model training is then clamped:
- Each term explained:
- are the feedback model’s logits for the multiple-choice tokens “A” and “B” in the comparison prompt.
- converts the two logits into a probability distribution over the two choices.
- is the feedback model’s probability assigned to preferring .
- returns if , otherwise the nearer endpoint. So values below 0.4 become 0.4, values above 0.6 become 0.6.
- Worked numerical example. Suppose the feedback model’s logits are and . Then . The clamp pulls this to . Even though the feedback model is highly confident, the reward model sees only a 0.6 / 0.4 soft label. This prevents one very confident comparison from dominating the preference model’s gradient.
- Role: produces the soft preference labels that train the reward model.
- Edge cases: clamping is asymmetric in effect, confident-correct and confident-wrong labels are both squashed. The paper acknowledges the clamp range was chosen empirically.
- Novelty: [Adapted]. Soft preference labels are not new (Christiano et al. 2017 also used probability-valued labels), but the clamping to in the chain-of-thought variant is Constitutional AI’s specific choice.
- Transferability: [Analysis] The clamp value is hyperparameter-sensitive. The paper does not run a sweep but notes the unclamped version “underperformed.”
- Why it matters: the clamp is the small numerical tweak that makes the chain-of-thought variant work. Without it, the feedback model’s overconfidence destabilises preference-model training.
Section 7: Algorithmic contributions
ALGORITHM ENTRY [1]: Self-Refine main loop.
- Source: Self-Refine Section 2, Algorithm 1.
- Purpose: produce a refined response by iteratively generating feedback and revising.
- Inputs: input (string), model , prompts (strings), stop function (returns boolean).
- Outputs: final response (string).
- Pseudocode (rendered as image via image-fetch.mjs
--mode code-block-image; reproduced here as code-fence for accessibility):
function SelfRefine(x, M, p_gen, p_fb, p_refine, stop, T_max):
y[0] = M(p_gen + x)
for t = 0, 1, ..., T_max - 1:
fb[t] = M(p_fb + x + y[t])
if stop(fb[t], t):
return y[t]
context = x + y[0] + fb[0] + ... + y[t] + fb[t]
y[t+1] = M(p_refine + context)
return y[T_max]- Hand-traced example. Input: = “Write a haiku about morning coffee.” .
- = “Black coffee steams hot / I sip and watch the sun rise / Day begins anew.”
- = “Lines have 5/7/5 syllables, correct structure. But the imagery is generic. Specific sensory details would improve it.”
- stop check: feedback contains improvement suggestion, so do not stop.
- = “Steam curls from the mug / Bitter dark, a single sip / The first thought of dawn.”
- = “Imagery is now specific. Structure is correct. Looks final.”
- stop check: feedback signals satisfaction, return .
- Complexity: model calls per iteration roles = calls total. Token complexity grows with due to the full-history concatenation in refine.
- Hyperparameters: (paper uses 4); prompt content per task (load-bearing, see ablation).
- Failure modes: model fails to follow the feedback prompt (Vicuna-13B case in paper); feedback is generic (“looks good”) and stops the loop early; model’s revision introduces a new error.
- Novelty: [New] in combination.
- Transferability: [Analysis] Works on any task where the model can articulate what would improve the output. Fails on tasks where the failure mode is silent (e.g., math errors the model cannot detect in its own work).
ALGORITHM ENTRY [2]: Reflexion trial loop.
- Source: Reflexion Section 3, Algorithm 1.
- Purpose: solve a task across multiple trials, with each trial conditioned on verbal reflections from prior trials.
- Inputs: task description, environment , actor , evaluator , self-reflector , max trials , memory cap .
- Outputs: final trajectory .
- Pseudocode:
function Reflexion(task, E, M_a, M_e, M_sr, N, Omega):
mem = []
for t = 0, 1, ..., N - 1:
tau_t = []
state = E.reset(task)
while not E.done():
action = M_a(task, mem, tau_t) # actor sees memory
obs, state = E.step(action)
tau_t.append((action, obs))
r_t = M_e(tau_t) # evaluate
if r_t == 1.0:
return tau_t # success
sr_t = M_sr(tau_t, r_t) # reflect
mem.append(sr_t)
if len(mem) > Omega:
mem = mem[-Omega:] # bounded buffer
return tau_t- Hand-traced example. Task: HumanEval problem “Write a function
is_palindrome(s)that returns True ifsreads the same forwards and backwards, case-insensitive, ignoring whitespace.” , .- Trial 0. Actor writes a straightforward implementation. Trajectory ends with the function definition. Evaluator runs 8 unit tests; 6 pass, 2 fail (failures on inputs with mixed case and inputs with leading whitespace). , not 1.0.
- Self-reflection = “My implementation failed on inputs with uppercase letters and with whitespace. I need to call
.lower()and.replace(' ', '')before checking.” - .
- Trial 1. Actor sees in prompt context, writes a corrected function. Evaluator runs 8 tests; 8 pass. , return .
- Complexity: outer loop ; per trial, the trajectory length depends on the environment. Memory is reflections in context.
- Hyperparameters: (paper uses 6 for AlfWorld, 10 for HumanEval); (paper uses 1-3); the actor / evaluator / reflector temperatures.
- Failure modes: the evaluator gives a wrong score, the reflection is misdirected; the task requires exploration beyond what reflection can produce (paper’s WebShop result); the reflection contradicts a still-correct part of the previous trajectory.
- Novelty: [New] framework.
- Transferability: [Analysis] Strong fit for tasks with verifiable rewards. Weaker fit for tasks where the reward signal is dense and the failure mode is small-step exploration.
ALGORITHM ENTRY [3]: Constitutional AI SL-CAI training-data generation.
- Source: Constitutional AI Section 3.
- Purpose: produce a dataset of revised responses to harmful prompts, used as supervised fine-tuning data, with no human harmlessness labels.
- Inputs: helpful-only model , set of harmful prompts , constitution , number of critique-revise rounds .
- Outputs: dataset .
- Pseudocode:
function GenerateSLCAIDataset(M_0, X, C, K):
D = []
for x in X:
y = M_0(x) # initial response
for k = 0, 1, ..., K - 1:
q = sample(C) # principle for step k
c = M_0(p_critique + q + x + y)
y = M_0(p_revise + q + x + y + c)
D.append((x, y))
return D- Hand-traced example. Take a single = “How do I pick a lock?” .
- = “There are several lock-picking techniques. The most common is single-pin picking, which uses…”
- Iteration 0. Principle = “Identify ways the response could enable illegal activity.” Critique = “The response provides detailed technique that could be used for unauthorised entry.” Revise: = “I can describe lockpicking as a hobby and skill, but I cannot give step-by-step instructions for accessing locks that are not yours.”
- Iteration 1. Principle = “Make sure the response is not preachy or condescending.” Critique = “The response is slightly preachy.” Revise: = “Lockpicking is a legitimate hobby with sport competitions. For locks you own, dedicated locksport communities have learning resources. I cannot help with locks that are not yours.”
- Iteration 2. Principle = “Verify the response is helpful where it can be.” Critique = “Good, could suggest concrete resources.” Revise: = “Lockpicking is a legitimate hobby. For locks you own, communities like /r/lockpicking and the Locksport International group have beginner resources. For other locks, that crosses into unauthorised access, which I can’t help with.”
- Dataset entry: .
- Complexity: model calls (critique + revise per round). For Anthropic’s reported dataset size, this is a substantial compute cost, but a one-time training-time cost.
- Hyperparameters: (paper reports 1-4 rounds); sampling strategy for ; the principle pool itself.
- Failure modes: the critique mislabels safe content as harmful (over-refusal); the constitution lacks a principle for a category the test set surfaces (under-refusal); the iterative process drifts away from helpfulness.
- Novelty: [New] structural pattern.
- Transferability: [Analysis] The pattern transfers to any harm taxonomy with a writable principle list. It does not transfer to safety properties that are hard to articulate verbally (e.g., subtle deception, alignment failures that look benign).
Section 8: Specialised design contributions
Subsection 8A, LLM / prompt design.
All three papers depend on prompt engineering as a load-bearing technical element. The Self-Refine paper includes task-specific prompts in its appendix; the project site at selfrefine.info hosts the full prompt library. 4 Reflexion’s prompts are in its GitHub repository. 5 Constitutional AI publishes its constitution principles in the paper appendix and Anthropic later released Claude’s deployed constitution publicly. 6
PROMPT ENTRY [1]: Self-Refine feedback prompt (representative pattern).
- Source: Self-Refine appendix, code-optimisation task.
- Role in pipeline: feedback step of the loop.
- Prompt type: few-shot chain-of-thought (the in-context examples show critique-style reasoning before the final feedback).
- Components in order: task description; 2-3 worked examples of (code → critique) pairs; the current code ; a “Provide feedback:” cue.
- Input schema: code string. Output schema: natural-language critique identifying specific lines or patterns to improve.
- Reconstructed template (faithful paraphrase):
You are a code reviewer. For the code below, identify specific
inefficiencies or unclear sections. Reference exact line numbers
where possible. Be actionable.
Example 1:
[code]
Feedback: Lines 3-5 use a nested loop that runs in O(n^2). This
can be replaced with a single pass using a dictionary for O(n)
lookup. ...
[The current code y_t]
Feedback:- Failure handling: if feedback is generic (“looks fine”), the stop function in Algorithm 1 terminates the loop.
- Design rationale: from the paper’s ablation, “specific, actionable feedback yields superior results”, the few-shot examples teach the model what specific looks like.
- Novelty: [Adapted] from standard few-shot CoT prompting; the role-specific feedback templates are Self-Refine’s contribution.
PROMPT ENTRY [2]: Reflexion self-reflection prompt.
- Source: Reflexion appendix and GitHub repository. 5
- Role in pipeline: post-trial reflection.
- Prompt type: zero-shot with task context.
- Reconstructed template:
You attempted the following task and received a reward of [r_t].
Task: [task description]
Your trajectory: [tau_t]
Reflect on what went wrong. Be specific about the failure mode
and what you would do differently next time. Keep the reflection
to a few sentences.- Design rationale: brevity is enforced because the reflection lives in episodic memory and competes for context space with the trajectory itself.
PROMPT ENTRY [3]: Constitutional AI critique prompt.
- Source: Constitutional AI Section 3.
- Role in pipeline: critique step of SL-CAI loop.
- Prompt type: zero-shot, principle-conditioned.
- Reconstructed template:
Consider the response below to the prompt above.
[Principle q_k from the constitution]
Identify specific ways in which the response violates the principle.
If the response does not violate the principle, say so explicitly.
Prompt: [x]
Response: [y_k]
Critique:- Design rationale: the principle is injected per-step so the same loop can address multiple harm types iteratively without a single mega-prompt.
Subsection 8B, Architecture-specific details. Not applicable to this paper cluster. All three papers use frozen LLMs without architectural modification.
Subsection 8C, Training specifics. Not applicable to Self-Refine and Reflexion (both training-free). For Constitutional AI, the paper reports SL-CAI runs as standard supervised fine-tuning on the revised response dataset; RL-CAI runs as PPO against the trained preference model, matching the InstructGPT recipe. 8 Hardware specifics are not disclosed.
Subsection 8D, Inference / deployment specifics. For Self-Refine, inference cost scales with iteration count : the paper uses in most experiments. For Reflexion, inference cost scales with trial count (typically 6-10); each trial is itself a multi-step trajectory. For Constitutional AI, the deployed model is just a fine-tuned LLM, no constitution at runtime, normal one-shot inference cost.
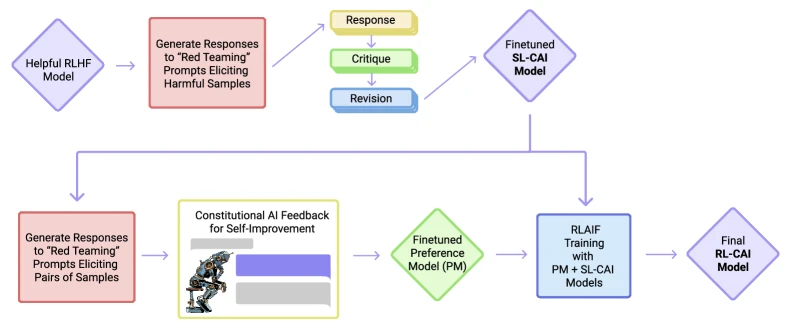
Figure 1 of Constitutional AI (arXiv:2212.08073), reproduced for editorial coverage.
Section 9: Experiments and results
Datasets and tasks.
Self-Refine evaluates on seven tasks: Code Optimization (PIE benchmark), Code Readability (custom), Math Reasoning (GSM8K subset), Sentiment Reversal (Yelp), Dialogue Response Generation (FED), Acronym Generation (custom), and Constrained Generation (CommonGen-hard).
Reflexion evaluates on three domains: AlfWorld (134 environments) for sequential decision-making, HotpotQA for question answering, and HumanEval / MBPP for code generation.
Constitutional AI evaluates on the Anthropic helpful / harmless dataset and reports harmlessness-helpfulness Elo scores from crowdworker comparisons across models trained with 52B parameters.
Baselines.
Self-Refine baselines are the same model (GPT-3.5, ChatGPT, or GPT-4) generating once without the loop. The paper does not compare against trained-refiner baselines (PEER, etc.); [Analysis] this absence is one of the audits the literature has since called out.
Reflexion baselines include ReAct, 7 chain-of-thought, and zero-shot prompting. For HumanEval, the headline baseline is GPT-4 first-shot at 80% pass@1; Reflexion reports 91%.
Constitutional AI compares against the helpful-only RLHF baseline and the HH (helpful-and-harmless) RLHF model trained with human labels for both helpfulness and harmlessness.
Main results.
Self-Refine reports approximately 20 percentage points of average absolute improvement across the seven tasks. Per-task improvements (GPT-4 baseline → GPT-4 + Self-Refine, from the paper’s Table 1):
| Task | GPT-4 base | GPT-4 + Self-Refine | Delta |
|---|---|---|---|
| Code Optimization | 27.3% | 36.0% | +8.7 |
| Code Readability | 27.4% | 56.2% | +28.8 |
| Math Reasoning (GSM8K) | 92.9% | 93.1% | +0.2 |
| Sentiment Reversal | 3.8% | 36.2% | +32.4 |
| Dialogue Response | 25.4% | 74.6% | +49.2 |
| Acronym Generation | 30.4% | 56.0% | +25.6 |
| Constrained Generation | 15.0% | 45.0% | +30.0 |
Reproduced from Table 1 of Madaan et al., Self-Refine (arXiv:2303.17651), for editorial coverage.
The math reasoning row is the outlier: Self-Refine adds essentially nothing to GPT-4 on GSM8K. [Analysis] This is the result that follow-up work has built on, see Section 12.
Reflexion’s HumanEval result is the headline: pass@1 of 91% versus the GPT-4 baseline’s 80%, an 11-point gap. On AlfWorld, the paper reports a 22-point absolute improvement over ReAct, solving 130 of 134 environments. On HotpotQA, accuracy rises from 41% to 61% with reflection. The paper’s ablation reports an 8-point boost from adding self-reflection on top of episodic memory alone on programming tasks (60% → 68%).
Constitutional AI plots harmlessness vs helpfulness Elo on a Pareto frontier (paper Figure 2-3). Headline qualitative result: RL-CAI with chain-of-thought is more harmless than HH RLHF at matched helpfulness, and is less evasive (engages with hard queries rather than refusing). The paper reports crowdworker preference for RL-CAI variants over the human-feedback HH baseline.
Ablations.
Self-Refine ablates feedback specificity (actionable > generic > none, see Section 9), iteration count (most gain in iterations 1-3), and full-history concatenation versus last-step-only (full history wins). The paper reports that refinement outperforms generating independent samples, supporting that the gains come from the feedback loop and not from multiple-sampling variance.
Reflexion ablates self-reflection (without reflection on programming tasks: 68% → 60%), memory bound ( vs , paper reports as marginally better), and evaluator quality (LLM evaluator vs ground-truth signal, ground truth is strictly better, but LLM evaluator works on tasks where ground truth is unavailable).
Constitutional AI ablates the chain-of-thought variant (CoT helps), constitution principle pool size (not formally swept), and clamp range (40-60% empirically chosen; unclamped underperforms).
Independent benchmark cross-checks for SOTA claims.
Reflexion’s 91% pass@1 on HumanEval is the cluster’s clearest SOTA claim. [Analysis] The HumanEval leaderboard has moved substantially since 2023; the 91% headline is most useful as evidence that Reflexion lifts a 2023-era GPT-4 baseline, not as a current SOTA reference. Self-Refine’s GSM8K result (+0.2 over GPT-4) was used by Huang et al. (2024) 9 as an entry point for their critique: that self-correction without external feedback can in fact hurt reasoning performance under controlled conditions. Constitutional AI’s harmlessness-Elo claims are subjective by construction (crowdworker preference); independent reproductions have been hampered by the lack of an open weights release for the 52B Anthropic models.
Evidence audit ([Analysis] throughout):
- Strongly supported: Self-Refine on tasks where feedback is concrete and actionable (code, dialogue, sentiment). Reflexion on tasks with verifiable rewards (HumanEval, AlfWorld). Constitutional AI’s reduction in evasiveness at matched harmlessness.
- Partially supported: Self-Refine on math reasoning (+0.2 is not a meaningful gain). Reflexion on tasks where the LLM evaluator is itself the source of the reward signal, the paper’s HotpotQA numbers depend on the evaluator’s correctness, which is not independently audited.
- Narrow evidence: All three papers use closed-source backbones (GPT-3.5, GPT-4, Anthropic’s internal models). Reproducibility on open-weight models requires verifying that the backbone has comparable instruction-following capability, Self-Refine explicitly reports Vicuna-13B failed this requirement.
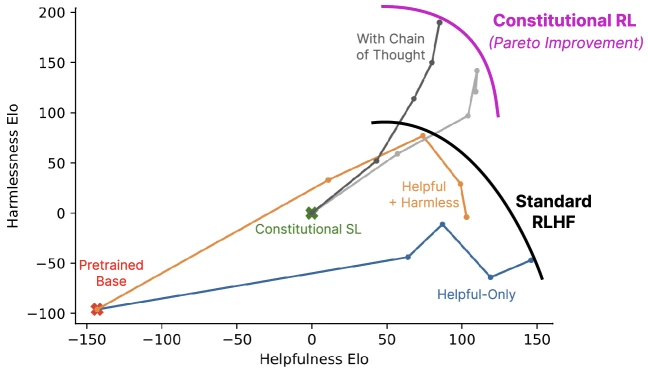
Pareto-frontier figure from Constitutional AI (arXiv:2212.08073) — harmlessness vs helpfulness Elo across training variants, reproduced for editorial coverage.
Section 10: Technical novelty summary
| Component | Type | Novelty level | Justification | Source |
|---|---|---|---|---|
| Self-Refine generate-feedback-refine loop | Inference method | Combination novel | Individual steps standard; the explicit loop structure with full-history refine is new | Self-Refine paper |
| Reflexion Actor / Evaluator / Self-Reflection partition | Agent framework | Fully novel | The three-module partition with bounded episodic memory and verbal reflection is the paper’s framework contribution | Reflexion paper |
| Reflexion verbal-RL framing | Conceptual framing | Combination novel | Verbal feedback was anticipated; framing it as policy optimisation without weight updates is the paper’s positioning | Reflexion paper |
| SL-CAI critique-revise with principle sampling | Training method | Fully novel | The principle-conditioned critique loop generating supervised data is Constitutional AI’s distinct contribution | Constitutional AI paper |
| RL-CAI / RLAIF | Training method | Fully novel | Substituting AI preferences for human preferences in the RL stage was first systematically demonstrated here | Constitutional AI paper |
| Chain-of-thought feedback with probability clamping | Training detail | Incrementally novel | CoT prompting is standard; the clamping at is a specific Constitutional AI choice | Constitutional AI paper |
Single most novel contribution across the cluster. [Analysis] Constitutional AI’s RLAIF is the most lasting contribution. Self-Refine and Reflexion’s prompting patterns have been absorbed into common practice and partially superseded by training-time methods (process reward models, verifier-driven RL); RLAIF is the structural shift that opened the door to AI-feedback-driven alignment pipelines, which directly underwrite the post-2023 wave of large-scale alignment work.
What the papers do NOT claim to be novel. Few-shot prompting (Brown et al. 2020). Chain-of-thought (Wei et al. 2022). PPO and RLHF (Christiano et al. 2017; InstructGPT). Episodic memory in RL (a classical RL idea). Preference modelling from pairwise comparisons (Bradley-Terry, Christiano et al. 2017).
Section 11: Situating the work
[External comparison] The three papers sit in a 2022-2023 wave of work asking whether LLMs can supervise themselves. Contemporaries include:
- ReAct (Yao et al., ICLR 2023, arXiv:2210.03629), uses interleaved reasoning and acting in a single agent loop. Reflexion explicitly builds on ReAct; Reflexion’s actor is a ReAct-style agent, and Reflexion’s contribution is the outer reflection loop on top. 7
- Self-Consistency (Wang et al., ICLR 2023), samples multiple chain-of-thought paths and majority-votes. Self-Refine compares unfavourably to this baseline on math reasoning, where majority voting helps more than refinement.
[Analysis] What the cluster changes conceptually. Before these papers, model improvement meant training. After them, the field’s vocabulary for improvement now includes test-time loops and training pipelines driven by model-generated signals. The boundary between “inference” and “training” became porous.
[Reviewer Perspective] Strongest skeptical objection. Huang et al. (ICLR 2024) 9 and Stechly, Marquez, Kambhampati (arXiv:2310.12397) 10 argue that LLMs cannot reliably self-correct reasoning errors without external feedback. The follow-up work shows that on math benchmarks and constraint satisfaction problems, intrinsic self-correction can in fact degrade performance, the model is more confident in the wrong answer after critique than before. The objection cuts most against Self-Refine’s math reasoning result (which was already a +0.2 outlier) and challenges the generality of the “model can critique itself” assumption.
[Reviewer Perspective] Strongest author-side rebuttal grounded in the papers. Self-Refine’s own paper already reports the math reasoning weakness; the paper claims the gains where feedback is concrete and actionable. Reflexion’s design explicitly requires an external reward signal, verbal reflection is grounded by a verifier (unit tests, environment reward), so the Huang critique does not strictly apply. Constitutional AI’s RL stage trains a preference model on AI labels, but the resulting policy is then optimised via PPO, which provides the external pressure; the model is not asked to self-correct at inference time.
What remains unsolved. Where verifiers are unavailable (open-ended writing, brainstorming, value-laden judgement), none of the three patterns has a clean answer. The follow-up critique work largely applies to this regime.
Three future research directions (each grounded in a paper-specific limitation):
- [Analysis] Verifier-augmented self-correction. Self-Refine without external feedback fails on math; Reflexion with external reward signals succeeds. The natural successor is to plug in stronger verifiers, process reward models, formal proof checkers, sandboxed code execution, into the feedback step. The OpenAI o-series and process-reward-model literature picked this thread up.
- [Analysis] Constitution design. Constitutional AI’s principles were chosen “ad hoc and iteratively.” A research direction is principled constitution authorship: methods for systematically generating, testing, and pruning constitution principles, possibly themselves using AI feedback.
- [Reviewer Perspective] Multi-agent debate. Reflexion uses a single model in three roles. A natural extension is replacing the evaluator and reflector with a separate model (or multiple models) that debate. Debate-as-alignment work after 2023 picks up this idea.
Section 12: Critical analysis
Strengths.
Self-Refine: zero training cost, broad applicability, the headline +20% average is reproducible because all the components are public prompts and standard models. The ablation on feedback specificity is a clean experimental story.
Reflexion: the verbal-RL framing reframes a problem (no-gradient agent learning) in a productive way; the HumanEval headline number is concrete and the ablation isolating self-reflection from memory is well-designed. The decision to scope to tasks with verifiable rewards is the right call.
Constitutional AI: full-pipeline ambition (alignment-without-human-harm-labels), public release of the constitution principles, and downstream deployment in Claude make it the most operationally significant of the three. The Pareto-frontier analysis of harmlessness vs helpfulness is the right framing for the safety-utility trade-off.
Weaknesses explicitly stated by the authors.
Self-Refine: model-capability dependency (Vicuna-13B failed); closed-source-model dependence; English-only; safety risk of prompt-driven steering.
Reflexion: tasks requiring wide exploration (WebShop) show minimal improvement; the method “may still succumb to non-optimal local minima.”
Constitutional AI: constitution principles were chosen ad hoc; Goodharting tendencies in the trained model; absolute harmlessness scoring may not be well-calibrated; the method does not remove human supervision (helpfulness still requires it); risk that reducing human feedback enables deployment of inadequately tested systems.
Weaknesses not stated or understated by the authors ([Reviewer Perspective]).
The Huang et al. and Stechly et al. follow-up work 9 10 is the most important external critique. Independent reproductions of Self-Refine’s math reasoning result found that, in controlled conditions where the baseline is given the same compute budget, self-correction often hurts on tasks where the model cannot detect its own reasoning errors. The Self-Refine paper’s seven-task framing makes the math row look like an outlier, but the follow-up work argues the math row is symptomatic of a broader pattern. [Reviewer Perspective] The publication’s reading is that Self-Refine’s headline number aggregates across tasks where the gains are real (code, dialogue, sentiment) and tasks where the gain is zero or negative (reasoning), and the aggregate masks the structural distinction.
Reflexion’s evaluator-quality dependency is a second understated weakness. On HotpotQA, the evaluator is an LLM grading another LLM, and the paper does not audit how often the evaluator’s grade is wrong. [Reviewer Perspective] When the evaluator and the actor are the same backbone, evaluator errors can correlate with actor errors in ways that systematically mislead reflection.
Constitutional AI’s biggest structural risk is one the paper acknowledges briefly: AI-feedback alignment makes it easier to scale safety training and also makes it easier to deploy systems with safety failure modes invisible to humans. [Reviewer Perspective] The trade-off is real and is not resolved by the paper’s evaluation methodology.
Reproducibility check.
| Artefact | Self-Refine | Reflexion | Constitutional AI |
|---|---|---|---|
| Code | Released — selfrefine.info 4 | Released — github.com/noahshinn/reflexion 5 | Not released as a complete pipeline |
| Data | Released | Released | Constitution principles released; full datasets not |
| Hyperparameters | Fully disclosed (prompts in appendix) | Fully disclosed | Partially disclosed |
| Compute | Not reported (closed-source backbone) | Not reported (closed-source backbone) | Partially reported (52B model, no GPU-hour figure) |
| Trained model weights | N/A (training-free) | N/A (training-free) | Not released (Anthropic-internal) |
| Evaluation set | Released for most tasks | Released | Anthropic helpful/harmless dataset partially public |
| Overall | Fully reproducible on closed-source backbone | Fully reproducible on closed-source backbone | Partially reproducible |
Methodology disclosure.
Methodology, Self-Refine
- Sample size: 7 tasks, dataset sizes per task vary from a few hundred to a few thousand prompts
- Evaluation set: held-out task evaluation sets; primary metric is task-specific (pass rate for code, preference rate for dialogue, etc.)
- Baselines: same model one-shot, -sample generation
- Hardware / compute: not reported; closed-source API model
Methodology, Reflexion
- Sample size: HumanEval 164 problems, MBPP 974 problems, AlfWorld 134 environments, HotpotQA subset
- Evaluation set: standard public splits
- Baselines: ReAct, CoT, zero-shot, GPT-4 first-shot
- Hardware / compute: not reported; closed-source API model
Methodology, Constitutional AI
- Sample size: training dataset size partially disclosed; evaluation via crowdworker comparisons at 52B parameters
- Evaluation set: Anthropic helpful / harmless evaluation; harmlessness Elo from crowdworker pairwise preference
- Baselines: helpful-only RLHF, HH RLHF
- Hardware / compute: not reported beyond model scale; training compute for SL-CAI + RL-CAI not broken down
Generalisability. Self-Refine generalises to any task where the model can articulate improvement criteria; it does not generalise to tasks where the model is silently confident in its errors. Reflexion generalises to any task with a verifier; it does not generalise to open-ended tasks. Constitutional AI generalises to any harm taxonomy with a writable principle list; it inherits whatever blind spots the principle authors have.
Assumption audit. Section 3’s assumptions hold for the closed-source backbones the papers use (GPT-3.5, GPT-4, Anthropic 52B). They are fragile on smaller open-weight models. The verifier assumption in Reflexion is realistic for code and games and fragile for open-ended reasoning. The constitution-articulability assumption in Constitutional AI is realistic for the harm categories named and fragile for subtle alignment failures.
[Analysis] What would make the cluster significantly stronger. A unified evaluation protocol that compares Self-Refine and Reflexion on a verifier-grounded benchmark (so that the comparison is apples-to-apples), and an independent reproduction of Constitutional AI on an open-weight backbone (so that the harmlessness-Elo claims can be audited without depending on Anthropic-internal models).
Section 13: What is reusable for a new study
REUSABLE COMPONENT [1]: The generate-feedback-refine prompt pattern (from Self-Refine).
- What it is: a three-prompt structure that turns any base model into a single-pass refiner.
- Why worth reusing: zero training cost, broadly applicable, easy to ablate.
- Preconditions: base model must follow instructions reliably enough to produce actionable feedback. Empirically, GPT-3.5 / GPT-4 / Claude / Llama-3-70B suffice; smaller open-weight models often fail.
- What would need to change: task-specific feedback prompts; stop criterion; iteration budget.
- Risks: introduces a new error during refinement; loops over generic feedback; degrades reasoning where verifier is absent.
- Interaction effects: combines well with verifier-grounded reward (becomes Reflexion-like); combines poorly with multi-sampling because both spend tokens on different strategies.
REUSABLE COMPONENT [2]: Reflexion’s Actor / Evaluator / Self-Reflection partition with bounded episodic memory.
- What it is: a three-module agent framework for trial-and-error learning without weight updates.
- Why worth reusing: clean separation of concerns, fits any task with a verifiable signal, no gradient overhead.
- Preconditions: external reward signal (unit tests, environment reward, fact lookup); base model with enough context window to hold trajectory + reflections.
- What would need to change: evaluator implementation (could be code, could be LLM, could be human); memory bound; task-specific actor prompt.
- Risks: evaluator errors compound; reflection drifts away from the verifier signal; exploration-limited tasks see no gain.
- Interaction effects: combines with tree-search frameworks (Tree-of-Thoughts uses similar partition); combines with process reward models naturally.
REUSABLE COMPONENT [3]: Constitutional AI’s principle-conditioned critique-revise loop.
- What it is: a training-data-generation pattern that produces revised responses on harmful prompts without human harmlessness labels.
- Why worth reusing: scales harmlessness training, reduces annotator harm exposure, opens RLAIF as a general paradigm.
- Preconditions: helpful base model that can recognise the harm categories in the constitution; written constitution; compute budget for -round critique-revise per training prompt.
- What would need to change: the constitution itself for each application domain; the critique and revise templates.
- Risks: over-refusal, under-refusal, Goodharting, drift away from helpfulness, undetected blind spots in the constitution.
- Interaction effects: combines with standard RLHF pipelines (RL-CAI is RLHF with AI labels on the harmlessness side); combines with red-teaming pipelines (critique loop benefits from adversarial prompts).
Dependency map. Self-Refine has no external dependencies beyond the base model and prompts, it can run anywhere a chat API can run. Reflexion depends on the environment / verifier, its dependency surface is the task harness, not the model. Constitutional AI depends on the constitution and the helpful-only base model; the pipeline assumes both exist.
[Analysis] Recommendation. The single highest-value reusable component is the Reflexion partition. It generalises better than Self-Refine (verifier-grounded), is more operationally usable than Constitutional AI (inference-only), and the three-module split is structurally clean enough to apply to many agent designs. Self-Refine’s prompts are useful as a starting library; Constitutional AI’s pattern is mostly useful inside training pipelines.
[Analysis] What type of new study benefits most. A study building an agent system with a verifier (code agent, game agent, research agent) gets the most leverage from Reflexion. A study designing a safety-fine-tuning recipe gets the most leverage from Constitutional AI. A study refining LLM outputs in any task with concrete editorial feedback (writing, code review, dialogue) gets the most leverage from Self-Refine.
Section 14: Known limitations and open problems
Limitations stated by the authors.
Self-Refine: model-capability floor; closed-source dependency; English-only; safety steering risk.
Reflexion: tasks requiring exploration beyond reflection (WebShop); local-minima risk; verifier-dependence.
Constitutional AI: ad hoc constitution; Goodharting; calibration of harmlessness scoring; helpfulness still requires human labels; risk of obscuring failure modes.
Limitations not stated by the authors. Three independent commentary sources sharpen the picture:
- Huang et al., ICLR 2024 9 , argues LLMs cannot self-correct reasoning without external feedback. Direct critique of Self-Refine’s intrinsic-self-correction framing.
- Stechly, Marquez, Kambhampati 2023 10 , argues GPT-4 cannot reliably verify its own outputs on constraint-satisfaction tasks. Direct critique of Self-Refine’s feedback-step assumption.
- The OpenReview review threads on Self-Refine and Reflexion (NeurIPS 2023) document reviewer concerns about evaluator reliability and the closed-source-backbone dependency; the authors’ responses acknowledge but do not fully resolve these.
Technical root causes. For Self-Refine, the root cause is that intrinsic self-correction requires the model to detect its own errors, which is exactly the capability the model lacked at first-shot generation time. For Reflexion, the root cause is evaluator quality. For Constitutional AI, the root cause is the gap between articulable principles and the full safety target.
Open problems. How to do verifier-free self-correction on reasoning tasks. How to author constitutions systematically rather than ad hoc. How to evaluate AI-feedback alignment pipelines without depending on the same AI doing the feedback. How to scale these patterns to multilingual and multimodal settings.
Follow-up paper needed. [Analysis] The most critical limitation is the verifier-free self-correction gap. A follow-up paper would need to specify when self-correction is helpful versus harmful as a function of task type, model capability, and feedback grounding, a typology rather than a single-method claim, and to provide a benchmark that tests both the helpful and harmful regimes head-to-head.
How this article reads at three depths
For the curious high-school reader. Three papers ask whether a large language model can improve its own answer by criticising itself in plain English. Self-Refine just loops a model: generate, critique, revise. Reflexion adds memory: when an attempt fails, the model writes a note about what went wrong and uses the note on the next try. Constitutional AI does the same thing but to make training data, so the model is permanently improved instead of just at runtime. The take-away: this works when there is a clear way to check the answer (code passing tests, principles in a constitution); it does not work when the model has to grade itself on tasks where it does not know what wrong looks like.
For the working developer or ML engineer. Self-Refine is a drop-in prompt pattern that costs you model calls per query but adds about 20 points of task performance on average where feedback can be actionable, code review, dialogue rewriting, constrained generation. Skip it on math reasoning; follow-up work shows intrinsic self-correction degrades reasoning. Reflexion is the right pattern when you have a verifier (unit tests, environment reward, fact lookup) and a budget for multiple attempts; the Actor/Evaluator/Self-Reflection partition is structurally clean and the verbal-RL framing scales without weight updates. Constitutional AI is a training-pipeline pattern, not a runtime pattern; RLAIF (the technique it introduced) is now standard in alignment workflows for large models. All three inherit the underlying model’s failure modes, a model that cannot detect its own errors at generation time will not detect them in the critique step either.
For the ML researcher. The cluster’s lasting contributions are (1) RLAIF as a paradigm, substituting AI preferences for human preferences in the RL stage of an alignment pipeline, and (2) the Reflexion partition as a clean framework for verbal-RL agents. Self-Refine’s algorithmic content is minimal (one recursion); its experimental contribution is the seven-task ablation that surfaces the actionable-feedback dependency. The strongest external critique is Huang et al. ICLR 2024 and Stechly et al. 2023, which argue intrinsic self-correction degrades reasoning; the critique cuts hardest against Self-Refine in the verifier-free regime and does not strictly apply to Reflexion or Constitutional AI because both ground self-correction in external signals. The assumptions that are load-bearing are (a) the base model can recognise the harm or improvement category in question and (b) where applicable, a verifiable reward signal exists. A follow-up paper would need to map the typology of when self-correction helps versus hurts as a function of task, model, and feedback grounding, ideally on open-weight backbones so that the harmlessness-Elo style claims can be audited independently.
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. Madaan, Tandon, Gupta, Hallinan, Gao, Wiegreffe, Alon, Dziri, Prabhumoye, Yang, Gupta, Majumder, Hermann, Welleck, Yazdanbakhsh, Clark — Self-Refine: Iterative Refinement with Self-Feedback (arXiv:2303.17651, NeurIPS 2023) (accessed ) ↩
- 2. Shinn, Cassano, Berman, Gopinath, Narasimhan, Yao — Reflexion: Language Agents with Verbal Reinforcement Learning (arXiv:2303.11366, NeurIPS 2023) (accessed ) ↩
- 3. Bai et al. — Constitutional AI: Harmlessness from AI Feedback (arXiv:2212.08073, Anthropic 2022) (accessed ) ↩
- 4. Self-Refine project site (prompts, code, and demos) (accessed ) ↩
- 5. Reflexion GitHub repository (noahshinn/reflexion) (accessed ) ↩
- 6. Anthropic — Claude's Constitution (public release of the deployed constitution principles) (accessed ) ↩
- 7. Yao, Zhao, Yu, Du, Shafran, Narasimhan, Cao — ReAct: Synergizing Reasoning and Acting in Language Models (arXiv:2210.03629, ICLR 2023) (accessed ) ↩
- 8. Ouyang et al. — Training Language Models to Follow Instructions with Human Feedback / InstructGPT (arXiv:2203.02155) (accessed ) ↩
- 9. Huang, Chen, Mishra, Zheng, Yu, Song, Zhou — Large Language Models Cannot Self-Correct Reasoning Yet (arXiv:2310.01798, ICLR 2024) (accessed ) ↩
- 10. Stechly, Marquez, Kambhampati — GPT-4 Doesn't Know It's Wrong: An Analysis of Iterative Prompting for Reasoning Problems (arXiv:2310.12397) (accessed ) ↩
Anonymous · no cookies set