Scaling Laws, Chinchilla, and Emergent Abilities: A Multi-Paper Technical Reference
Kaplan 2020, Chinchilla 2022, and Wei 2022 emergence — power-law exponents, compute-optimal allocation, emergence thresholds, and the mirage critique.
Section 1: Umbrella scope and paper identity
This article reviews three papers that together define the modern framework for thinking about how large language models behave as compute, data, and parameter count grow:
- Kaplan, McCandlish, Henighan, Brown, Chess, Child, Gray, Radford, Wu, Amodei. “Scaling Laws for Neural Language Models.” arXiv:2001.08361, January 2020. 1 Establishes power-law relationships between cross-entropy loss and three resources (parameters , tokens , compute ) spanning more than seven orders of magnitude. 2
- Hoffmann, Borgeaud, Mensch et al. “Training Compute-Optimal Large Language Models.” arXiv:2203.15556, March 2022. NeurIPS 2022. 3 Known as “Chinchilla.” Re-derives compute-optimal scaling using three complementary methodologies and concludes that the Kaplan recipe systematically under-trained the language models of 2020–2022.
- Wei, Tay, Bommasani, Raffel, Zoph et al. “Emergent Abilities of Large Language Models.” arXiv:2206.07682, June 2022. TMLR. 4 Catalogues task-level behaviours that appear discontinuous with scale, naming this phenomenon “emergence” and contrasting it with the smooth loss curves of Kaplan and Hoffmann.
Retrieval confirmation. All three papers were retrieved at draft time from the arXiv abstract pages plus the ar5iv HTML renders on 2026-05-19; the Chinchilla NeurIPS-canonical version is referenced through the same arXiv ID since the NeurIPS proceedings PDF mirrors the arXiv version. Supplementary materials (Kaplan Section 5–6 appendix tables, Chinchilla Appendix D parametric fits, Wei Appendix A BIG-bench plots) were all accessible through ar5iv.
Paper classifications. All three papers fall under: Theoretical · Data-driven · LLM-based · Benchmark (in the empirical-laws sense). Kaplan and Chinchilla additionally carry Training method and Optimisation; Wei additionally carries AI safety (because emergent capabilities have safety implications) and Survey (because Wei catalogues prior work).
Technical abstract in the publication’s voice. Kaplan’s paper claims that for a fixed Transformer architecture trained on autoregressive language modelling, test cross-entropy decreases as a power law in any of three resources once the other two are abundant. 5 Chinchilla revisits this with a denser experimental sweep, finds that parameters and tokens should scale roughly equally with compute (not in the 0.73 / 0.27 ratio Kaplan implied), and trains a 70B model on 1.4T tokens that beats Gopher 280B (300B tokens) across most benchmarks. 6 7 Wei steps off the loss curve and asks which downstream behaviours appear only above a compute threshold; the paper catalogues over a hundred such “emergent” tasks across LaMDA, GPT-3, Gopher, Chinchilla, and PaLM. 8
Primary research questions. Kaplan: given a Transformer language model, how does test loss depend on , , , and what is the optimal allocation of fixed compute? Chinchilla: is the Kaplan optimal-allocation prescription correct, and if not, what is? Wei: which downstream capabilities cannot be predicted from a small-model performance trend?
Core technical claims, one line each.
- Kaplan: with ; analogous forms in and ; optimal allocation , .
- Chinchilla: a 3-method analysis gives and ; “for every doubling of model size the number of training tokens should also be doubled.”
- Wei: emergent abilities are real on standard metrics but the scale at which they emerge is task-, metric-, and architecture-dependent; the paper documents but does not explain.
Core technical domains and depth per domain. Statistics of neural-network generalisation: deep. Optimisation under compute constraints: deep. Transformer architecture details: surface (all three treat the architecture as a black box at scale). LLM evaluation methodology: moderate. The emergence-as-mirage critique: moderate (Section 14 ties this to Schaeffer et al. 2023). 9
Reader prerequisites. High-school algebra; comfort reading - plots; familiarity with the idea that neural networks have parameters and are trained on data. Familiarity with autoregressive language modelling, the Transformer block, and the term “cross-entropy loss” is helpful but not required because the Glossary in Section 2.5 covers all three.
Section 2: TL;DR and executive overview
3-sentence TL;DR. Three papers built the modern recipe for “how big should a language model be and how much data should it see?” Kaplan 2020 showed that test loss falls smoothly as a power law in compute, parameters, and tokens; Chinchilla 2022 corrected the recipe and showed that parameters and tokens should grow roughly equally with compute; Wei 2022 catalogued tasks where the model’s behaviour seems to change suddenly rather than smoothly, calling these “emergent abilities.” Together, the three papers say: the average loss is predictable, but the individual capabilities that average masks are not.
Executive summary (~100 words). Training a frontier language model costs millions of dollars per run. Kaplan’s scaling laws (2020) gave the field a quantitative recipe for spending that compute: bigger models, less data. Hoffmann’s Chinchilla (2022) ran a denser experiment and discovered that the recipe was wrong in an expensive direction: existing models like Gopher 280B were significantly under-trained, and a 70B model on 4x the tokens beat it on most benchmarks. Wei’s emergence paper (2022) then noted that even when average loss falls smoothly, specific abilities like multi-step arithmetic or chain-of-thought reasoning seem to switch on at particular scales. Whether that switch is real or a measurement artefact remains debated.
Five practitioner-relevant takeaways.
- For a fixed compute budget on Transformer language modelling, Chinchilla’s / allocation generally outperforms Kaplan’s / allocation. 10
- The 20-tokens-per-parameter heuristic (“Chinchilla-optimal”) is a useful starting point but is a function of the parametric fit in Approach 3, not a universal constant.
- Inference-time cost is not in the Kaplan/Chinchilla objective; if the model serves many tokens after training, the compute-optimal model is smaller than the training-compute-optimal model. Llama 1 and later open-weights families chose this trade-off explicitly.
- Average cross-entropy hides per-task behaviour. Capability extrapolation from a smaller checkpoint to a 10x larger one is empirically risky for skills like multi-step reasoning, code generation under realistic prompts, and instruction following.
- Wei’s “emergence” claim was challenged in 2023 by Schaeffer et al., who argue that the discontinuity is largely a function of metric choice (exact-match accuracy versus token-level log-likelihood). The practitioner takeaway: instrument capability evaluation with both step-level and outcome-level metrics.
Pipeline overview. All three papers operate at training-time. Kaplan and Chinchilla measure the training-time test loss of a model and fit a curve. Wei measures the downstream-task performance of a finished model (typically few-shot prompted) and fits a curve. There is no inference-time component to any of the three claims beyond Wei’s choice to evaluate the finished model on benchmark suites such as MMLU and BIG-bench.
Section 2.5: Glossary
| Term | Plain-English explanation | First appears in |
|---|---|---|
| Cross-entropy loss | A number that measures how surprised the model is by the correct next token. Lower is better; zero means perfect prediction. | Section 1 |
| Parameters () | The numerical weights inside the neural network that are learned during training. A “175B model” has 175 billion of them. | Section 1 |
| Tokens () | The chunks of text (roughly subword pieces) the model sees during training. “1.4T tokens” means 1.4 trillion such chunks. | Section 1 |
| Compute () | Total arithmetic work done during training, usually measured in FLOPs (floating-point operations) or PF-days (petaflop-days). | Section 1 |
| Power law | A relationship of the form . On a log-log plot it appears as a straight line. | Section 1 |
| Transformer | The neural-network architecture used by all language models in these papers. It processes text using an “attention” mechanism. | Section 1 |
| FLOPs | ”Floating-Point Operations.” A measure of how much arithmetic was done. Training GPT-3 used roughly FLOPs. | Section 1 |
| Few-shot prompting | Showing the model a handful of input/output examples in the prompt, then asking it to handle a new input in the same format. | Section 4 |
| MMLU | ”Massive Multitask Language Understanding.” A benchmark of 57 academic subjects evaluated as multiple-choice questions. | Section 9 |
| BIG-bench | A 200+ task benchmark covering reasoning, knowledge, ethics, and creative tasks; widely used to test emergent behaviour. | Section 9 |
| Emergent ability | Per Wei et al., a capability “not present in smaller models but present in larger models” measured by a chosen metric. | Section 5 |
| Chinchilla-optimal | The Chinchilla-paper prescription of roughly 20 training tokens per model parameter under a fixed compute budget. | Section 5 |
| Iso-FLOP curve | A plot of final loss against model size at a FIXED compute budget; the minimum identifies the compute-optimal model size. | Section 6 |
[Analysis] label | The publication’s own reasoned assessment, distinct from what the paper itself claims. | Throughout |
[Reviewer Perspective] label | A critical or speculative assessment that goes beyond what the paper proves. | Section 11 + 12 |
The five mandatory claim-taxonomy entries collapse to a single Glossary row where they have the same meaning across the article. [Analysis] and [Reviewer Perspective] are rendered above. The other three ([Reconstructed], [External comparison], “From the paper:”) follow the same convention as elsewhere on the publication: [Reconstructed] marks content the article faithfully reconstructed because the paper only partially disclosed it; [External comparison] marks a comparison to prior work outside the paper itself; “From the paper:” prefixes content directly supported by the paper’s text, tables, or figures.
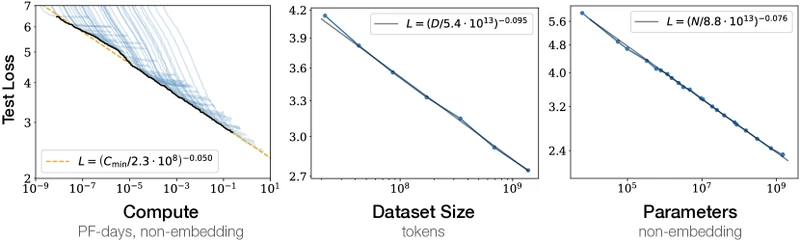
Paper A: Kaplan et al. 2020 — Scaling Laws for Neural Language Models
Section 3 (Kaplan): Problem formalisation
Notation table.
| Symbol | Type | Meaning | First appears in |
|---|---|---|---|
| positive real | Non-embedding parameter count of the Transformer | Section 3 | |
| positive real | Dataset size in tokens | Section 3 | |
| positive real | Total compute in PF-days | Section 3 | |
| positive real | Compute under optimal allocation, where is batch size | Section 6 | |
| positive real | Test cross-entropy on held-out WebText2 in nats per token | Section 3 | |
| positive real, | Power-law exponents in , , | Section 3 | |
| positive real | Critical scales setting the curve’s intercept | Section 3 | |
| positive integer | Number of training steps | Section 5 | |
| positive real | Critical batch size at which gradient-noise scale is balanced | Section 5.1 |
Formal problem statement. From the paper: hold the autoregressive Transformer architecture fixed; vary (non-embedding parameter count), (tokens of WebText2 used for training), and (compute). Measure the test cross-entropy on a held-out portion of WebText2. Fit a closed-form curve relating to .
Assumptions. From the paper, Section 1.2: the model family is decoder-only Transformer; the dataset is WebText2 (an expanded version of the GPT-2 training corpus); the loss is autoregressive cross-entropy; non-embedding parameters are the “meaningful” (embedding parameters scale linearly with vocabulary, not depth/width). [Analysis] The “architecture details have minimal effect within wide ranges” finding (Section 1.1, Figure 5) is itself an empirical claim, not an assumption, but the paper’s subsequent reasoning treats it as one. [Analysis] Potentially strong assumption: the WebText2 distribution is representative enough that the laws transfer to other text distributions; Section 3.1.3 partially tests this by transferring to other corpora but the test is not exhaustive.
Why this is hard structurally. Compute scales as the product for a Transformer. 11 Holding fixed, increasing requires decreasing . Without an empirical curve, an engineer choosing how to spend a -FLOP budget has no principled basis for the trade-off.
Data-driven specifics. From the paper, Section 2.1: WebText2 has BPE tokens; training subsamples ranged from to tokens; models ranged from 768 non-embedding parameters (tiny) to 1.5B non-embedding parameters (GPT-2 1.5B); compute was tracked in PF-days.
Section 4 (Kaplan): Motivation and gap
Real-world problem. From the paper, introduction: at the time of writing, OpenAI had just trained GPT-2 1.5B and was planning successor runs costing millions of dollars in compute. There was no quantitative answer to “if compute budget triples next year, should the team train a bigger model on the same data, the same model on more data, or both?”
Existing approaches and failure modes. From the paper, Section 1.3 and the related work: Hestness et al. 2017 (Baidu) had shown power-law scaling in image classification and machine translation but did not derive the joint form or treat optimal compute allocation. 12 Rosenfeld et al. 2020 had derived a generalisation-error functional form but had not connected it to Transformer language modelling at the scale Kaplan studied. 13 The paper claims its specific gap is the joint treatment of all three resources plus a closed-form prescription for optimal allocation.
Practical stakes. [External comparison] The Kaplan recipe drove training decisions through GPT-3 (Brown et al. 2020), 14 Gopher 280B (Rae et al. 2021), 15 and Jurassic-1 178B during 2020–2021. Chinchilla later showed (Section 6 of Hoffmann et al.) that this recipe left substantial loss on the table.
Section 5 (Kaplan): Method overview
The paper trains hundreds of Transformer language models of varying on subsets of varying , logs the test loss curve through training, and fits three families of curves: (a) loss as a function of at infinite data, (b) loss as a function of at infinite , (c) loss as a function of at optimal .
Plain-English intuition. Imagine plotting test loss against compute on log-log axes. Across more than seven orders of magnitude of compute, the points fall on a straight line. The slope of that line is the exponent of the power law; the intercept defines a “critical scale” at which loss would, hypothetically, equal an irreducible floor.
Step-by-step mechanism. From the paper, Section 3:
- Train a model of size on a token budget much larger than for many epochs (so is not the bottleneck) and read off final test loss .
- Repeat across and fit .
- Train a very large model on a token budget much smaller than the model’s capacity (so is not the bottleneck) and read off final test loss .
- Repeat across and fit .
- For each , optimise over and read off ; fit .
- Derive joint and compute-optimal forms by combining the marginal fits.
Classification. [New] in the sense of the specific joint form and the compute-optimal allocation derivation; [Adapted] from the Hestness et al. 2017 framework which already proposed power-law scaling. 12
Section 6 (Kaplan): Mathematical contributions
MATH ENTRY [K1]: Power law in model size
- Source: Section 3.1.1, Equation 1.5.
- What it is: Test loss falls as model size grows, with a specific functional form on log-log axes.
- Formal definition: with and non-embedding parameters. 16
- Term-by-term and dimensional analysis:
- is the non-embedding parameter count (positive real); the smallest model in the paper has and the largest has .
- is a fitted constant with the same units as ; the value is well beyond any model in the study, meaning the curve never crosses zero in the measured range.
- is dimensionless and is the slope of against on log-log axes.
- is cross-entropy in nats per token.
- Worked numerical example. Take two models, and (a 100x increase in size). Then . The loss falls by a factor of for a 100x increase in . Inverting: for the loss to halve, must scale by . The exponent is small, which means parameter scaling is slow.
- Role: The marginal fit in alone, used as one boundary condition for the joint fit.
- Edge cases: Fails for (where loss would predict zero, contradicting any irreducible entropy floor) and at tiny where the architecture cannot represent the data.
- Novelty: [Adapted] from Hestness et al. 2017’s power-law observation in other domains; the specific exponent on Transformer language modelling is [New].
- Transferability. [Analysis] The exponent depends on architecture and data distribution; the Chinchilla paper later refits the analogue and gets a meaningfully different value (see MATH ENTRY [H1]).
- Why it matters. Anchors the entire scaling-law program and gives the first quantitative slope for parameter scaling.
MATH ENTRY [K2]: Power law in dataset size
- Source: Section 3.1.2, Equation 1.5.
- What it is: Test loss falls as token budget grows, with the same functional form as but a different exponent.
- Formal definition: with and tokens. 16
- Term-by-term analysis. is the token count (positive real); is a fitted constant in tokens; is dimensionless. Note : data scaling is steeper than parameter scaling per the Kaplan fit, but with the convention , a larger means more rapid loss reduction per decade of .
- Worked numerical example. A 100x increase in reduces loss by . For loss to halve, must scale by .
- Role. Marginal fit in alone, with held abundant.
- Edge cases. Requires much smaller than what an infinite- model could absorb; in practice the paper achieves this by training large models for few steps.
- Novelty. [Adapted] from Hestness 2017; specific exponent is [New].
- Why it matters. Second leg of the joint law. Combined with [K1] it determines optimal allocation.
MATH ENTRY [K3]: Joint loss form
- Source: Section 4, Equation 1.5 generalised.
- What it is: A closed-form prediction of how loss behaves at any , including the overfitting regime where is too small for .
- Formal definition:
- Term-by-term analysis. Two pieces inside the bracket: the first is the model-size term raised to a ratio of exponents, the second is the dataset-size term linearly. Taking (data abundant) recovers from [K1]; taking (parameters abundant) recovers from [K2].
- Worked numerical example. Use the paper’s fitted values , , , . Take , . The bracket evaluates to . The outer exponent is , so nats per token. The point of the example is the operation, not the numerical accuracy.
- Role. Predicts overfitting: when is small relative to , the term dominates and loss is dataset-limited.
- Novelty. [New] joint form combining marginal fits with a single overfitting interpolation.
- Why it matters. Lets practitioners predict whether a given choice is parameter-bottlenecked or data-bottlenecked.
MATH ENTRY [K4]: Compute-optimal allocation
- Source: Section 6, Equations 1.6 and 6.1.
- What it is: Given a compute budget , the prescription for how to split it between bigger model and more data.
- Formal definition: .
- Worked numerical example. Suppose compute increases by a factor of . Then scales by and scales by . Most of the budget goes to growing the model; only a small fraction goes to more data. This is the prescription Chinchilla later overturns.
- Role. Operational recipe used by frontier-LLM teams 2020–2022.
- Novelty. [New] in the specific exponent values; [Adapted] in the general “optimise loss subject to compute budget” framing.
- Why it matters. Drove the model-size race that produced 175B–540B-parameter models trained on relatively modest token counts.
MATH ENTRY [K5]: Critical batch size
- Source: Section 5.1.
- What it is: A scale of batch size beyond which adding more parallel gradient signal yields diminishing returns.
- Formal definition: with tokens and . 17
- Term-by-term analysis. depends only on loss, not on model size, per the paper’s empirical claim. is the inverse exponent governing how rapidly grows as loss falls.
- Worked numerical example. “The critical batch size approximately doubles for every 13% decrease in loss” (paper’s Section 5.1 phrasing). Numerically: if falls from 4.0 to (a 13% drop), doubles.
- Role. Sets the boundary between data-parallel efficiency and waste.
- Why it matters. Practitioner-relevant: distributed-training engineers use this to size global batch.
Section 7 (Kaplan): Algorithmic contributions
The Kaplan paper is not an algorithm paper in the sense of introducing a new optimiser or new attention variant. The “algorithm” is the procedure that produces the fits.
ALGORITHM ENTRY [K-A1]: Empirical curve-fitting protocol
- Source: Section 2 + Section 3 of the paper.
- Purpose: Produce the , , fits.
- Inputs: Range of values; range of values; range of values; the Transformer training stack.
- Outputs: Fitted exponents and critical scales.
- Pseudocode:
for each (N, D, B, learning_rate) in the sweep grid:
train Transformer of size N on D tokens with batch B and lr schedule
log loss(step) for every step
record final test loss L_final
record (N, D, C, L_final) tuples
fit L(N) = (N_c / N) ** alpha_N # using D >> capacity points
fit L(D) = (D_c / D) ** alpha_D # using N >> dataset points
for each compute budget C:
optimise over (N, B) for minimum L at fixed C
record (C, N_opt, D_opt, L_opt)
fit L(C_min) = (C_c / C_min) ** alpha_C- Hand-traced example on minimal input. Take three points: , , . Log-log slope between point 1 and point 2: . Between point 2 and point 3: . Estimated . The minimal example uses three points to show the operation; the paper uses points.
- Complexity. Training all sweep points dominates: the paper reports training runs in total across the sweeps (Section 2.4); each run is a small fraction of the total compute, but the sweep is the bottleneck step.
- Hyperparameters. Learning-rate schedules, optimiser (Adam), warmup steps; all reported in Appendix A of the paper.
- Failure modes. Insufficient sweep density biases fitted exponents; this is in fact the critique Chinchilla levels at Kaplan in Section 6 of the Chinchilla paper.
Paper B: Hoffmann et al. 2022 — Training Compute-Optimal Large Language Models (Chinchilla)
Section 3 (Chinchilla): Problem formalisation
Notation table.
| Symbol | Type | Meaning | First appears in |
|---|---|---|---|
| positive real | Parameter count | Section 3 | |
| positive real | Training token count | Section 3 | |
| positive real | Training FLOPs | Section 3 | |
| positive real | Fitted final loss | Section 3 | |
| positive real | Irreducible loss (Bayes risk) | Section 3, Eq. 10 | |
| positive real | Coefficients on parameter and data terms | Section 3, Eq. 10 | |
| positive real | Exponents on and | Section 3, Eq. 10 | |
| positive real, | Compute-optimal exponents: , | Section 3 |
Formal problem statement. From the paper, Section 3 introduction: under a fixed compute budget , find the that minimises final training loss . Re-derive the answer from three complementary methods and check for consistency.
Assumptions. From the paper: decoder-only Transformer architecture (consistent with Kaplan); MassiveText training corpus (English-dominant web/books); single epoch over training tokens (no repetition); learning-rate schedule decayed from peak to ~10% of peak over the full training run.
Why this is hard structurally. The paper argues (Section 6) that Kaplan’s exponents were biased because the Kaplan sweep used a fixed learning-rate schedule that was tuned for a particular model size; smaller and larger models on the same schedule were systematically sub-optimal. Chinchilla addresses this by sweeping learning-rate schedule length appropriately for each model. 18
Section 4 (Chinchilla): Motivation and gap
From the paper, Section 1: “current large language models are significantly undertrained.” Gopher 280B used 300B training tokens (Rae et al. 2021); GPT-3 175B used B tokens (Brown et al. 2020). If parameters and data should scale roughly equally with compute, both runs would have been better spent on smaller models with more tokens. [External comparison] This finding precipitated the post-Chinchilla generation of dense LLMs — Llama 1 7B/13B/65B (Touvron et al. 2023), Llama 2, Mistral 7B — that all use much more data than Kaplan’s recipe would have prescribed.
Section 5 (Chinchilla): Method overview
The paper triangulates compute-optimal scaling using three independent approaches and checks that the answers agree.
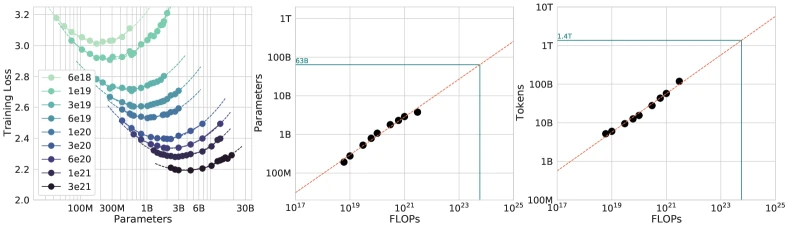
Approach 1: Fix model sizes, vary training tokens (Section 3.1). Train a fixed-size model across multiple cosine-cycle lengths, generating multiple final-loss points per model. The lower envelope of (compute, loss) across all runs gives the efficient frontier.
Approach 2: IsoFLOP curves (Section 3.2). For each of nine fixed compute budgets ( to FLOPs), train a range of model sizes for the appropriate token count. Fit a parabola in to identify the minimum-loss model size at each budget.
Approach 3: Parametric loss fitting (Section 3.3). Fit a global functional form to all observed losses using Huber-loss regression; derive the compute-optimal allocation analytically from the fit.
[Analysis] The agreement across three independent approaches is the paper’s strongest evidence; a single approach could be biased by sweep design, but three converging on argues against that bias.
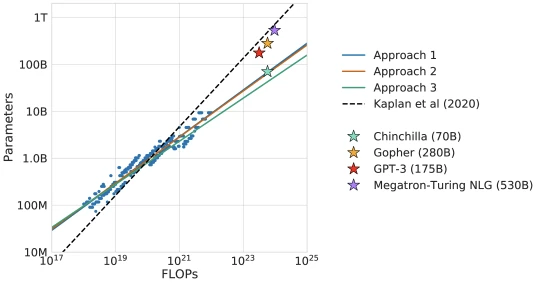
Section 6 (Chinchilla): Mathematical contributions
MATH ENTRY [H1]: Parametric loss form
- Source: Section 3.3, Equation 10.
- What it is: A three-term decomposition of loss into irreducible entropy plus parameter-limited and data-limited residuals.
- Formal definition: , fitted values , , , , . 19
- Term-by-term analysis. is the irreducible entropy of natural-language tokens under the training distribution (Bayes risk); is the residual from finite parameters; is the residual from finite data; and are the parameter and data exponents in this functional form.
- Worked numerical example. Take , (roughly Chinchilla scale). Parameter term: . Data term: . Compute , so data term . Total nats per token.
- Edge cases. At , ; at small the parameter term dominates; at small the data term dominates.
- Novelty. [Adapted] from Kaplan’s joint form but with a different structural decomposition (additive in and rather than the bracket-with-ratio-exponent form of [K3]); [New] explicit irreducible-entropy term .
- Why it matters. Lets compute-optimal allocation be solved analytically.
MATH ENTRY [H2]: Compute-optimal exponents
- Source: Section 3.4, derived from MATH ENTRY [H1] under the constraint for a constant (Transformer FLOPs-per-token-per-parameter).
- What it is: The exponents such that and minimise .
- Formal definition: .
- Term-by-term analysis. Minimising subject to via Lagrange multipliers yields and the ratio . With and , and .
- Worked numerical example for all three approaches.
| Approach | (parameters) | (tokens) |
|---|---|---|
| Approach 1: fix model, vary tokens | 0.50 | 0.50 |
| Approach 2: IsoFLOP profiles | 0.49 | 0.51 |
| Approach 3: parametric fit | 0.46 | 0.54 |
Table 2 of Training Compute-Optimal Large Language Models (arXiv:2203.15556), reproduced for editorial coverage. 20
- Proof sketch (Approach 3). Start from . Fix the compute constraint for some constant proportional to . Substitute into : . Differentiate with respect to and set to zero: . Rearrange: , so , i.e., . Taking logarithms and recalling gives , i.e., . By symmetry of the optimisation, , and . Substituting , recovers the Approach-3 numbers.
- Why it matters. This is the load-bearing claim of the entire paper: parameters and tokens scale roughly equally with compute, with the precise ratio depending on which approach is trusted.
MATH ENTRY [H3]: The “20 tokens per parameter” heuristic
- Source: Section 3.4 + Appendix C; widely quoted as Chinchilla-optimal.
- What it is: A rule of thumb derived from the empirical solution: at Chinchilla-scale compute, optimal .
- Formal definition: This is not an equation from the paper but a numerical instantiation of [H2] at the compute scale Chinchilla itself targeted ( FLOPs).
- Worked numerical example. Chinchilla 70B was trained on 1.4T tokens. . Gopher 280B on 300B tokens: . Per the paper, Gopher’s is roughly 20x below the Chinchilla-optimal value at the same compute budget.
- Edge cases. The 20:1 ratio is not invariant across compute scales because [H2] only constrains exponents, not the ratio itself; at smaller compute the optimal ratio is smaller, at larger compute it grows. [Analysis] Practitioners frequently quote “20 tokens per parameter” as universal; the paper does not support that.
- Why it matters. Operationally the most-quoted Chinchilla finding.
Section 7 (Chinchilla): Algorithmic contributions
ALGORITHM ENTRY [H-A1]: Three-approach triangulation protocol
- Source: Section 3 of the paper.
- Purpose: Estimate via three independent routes and check agreement.
- Inputs: Compute budgets, model-size range (70M–16B), tokenizer, MassiveText corpus.
- Outputs: Three estimates of and an analytic .
- Pseudocode:
# Approach 1: fixed model, varying tokens
for N in {70M, 250M, 500M, 1B, ..., 10B}:
for cycle_length in {25%, 50%, 100%, 200%, 400% of "target"}:
train(N, cycle_length); log (C, L_final)
build lower envelope L_envelope(C) across all runs
infer (a, b) from envelope shape
# Approach 2: IsoFLOP
for C in {6e18, 1e19, 3e19, 6e19, 1e20, 3e20, 6e20, 1e21, 3e21}:
for N spanning compute-optimal expectation:
D = C / (6 * N) # FLOPs constraint
train(N, D); log L_final
fit parabola L(log N | C); record N_opt(C), D_opt(C)
fit (a, b) from log N_opt vs log C and log D_opt vs log C
# Approach 3: parametric
collect all (N, D, L) tuples from approaches 1 and 2
fit L_hat(N, D) = E + A / N^alpha + B / D^beta via Huber loss
derive (a, b) analytically from fitted (alpha, beta)- Hand-traced example. Approach 2 at FLOPs: try with corresponding . Suppose final losses are . Fit a parabola in : minimum at , so M. Repeat at other and fit . The minimal example uses 4 points per budget; the paper uses many more.
- Complexity. Total training compute across all sweeps is comparable to a single Chinchilla 70B training run by paper-Table 1 disclosure; the sweep is the bottleneck.
- Failure modes. Each approach has its own bias; the methodology rests on the convergence of independent biases.
Section 8 (Chinchilla): Specialised design contributions
8A — LLM / prompt design. Not applicable to this paper.
8B — Architecture-specific details. From the paper, Section 2: decoder-only Transformer, RoPE positional embeddings, RMSNorm, SwiGLU activations consistent with Gopher; vocabulary 32k SentencePiece. Chinchilla 70B has 80 layers, , 64 attention heads.
8C — Training specifics. From the paper, Table 4: Chinchilla 70B trained on 1.4T tokens for 1 epoch with cosine learning-rate schedule decaying from to over the run; batch size 1.5M tokens. 21 Hardware: TPU v3/v4 pods (specific configuration in Appendix A).
8D — Inference / deployment specifics. Not applicable to this paper.
Section 9 (Chinchilla): Experiments and results
Datasets. MassiveText (training); evaluation on MMLU (57-task multi-choice), 22 BIG-bench, 23 The Pile (held-out perplexity), C4 perplexity, downstream reading comprehension and translation suites.
Baselines. Gopher 280B (same authors’ prior model), GPT-3 175B, Jurassic-1 178B, Megatron-Turing NLG 530B.
Headline result (Table 6, MMLU 5-shot).
| Model | Params | Tokens | MMLU 5-shot |
|---|---|---|---|
| GPT-3 | 175B | ~300B | 43.9% |
| Gopher | 280B | 300B | 60.0% |
| Chinchilla | 70B | 1.4T | 67.6% |
Adapted from Table 6 of Training Compute-Optimal Large Language Models (arXiv:2203.15556), reproduced for editorial coverage. 24
From the paper: Chinchilla uniformly and significantly outperforms Gopher across language modelling perplexity, reading comprehension, and multitask reasoning. The 70B-on-1.4T configuration uses the same training FLOPs as Gopher 280B-on-300B; per the constraint , both runs use FLOPs.
Independent benchmark cross-check. [External comparison] The Chinchilla-optimal prescription was independently validated by the Llama 1 release (Touvron et al. 2023), which trained 7B/13B/33B/65B on roughly 1T–1.4T tokens each — substantially more data per parameter than the Kaplan recipe would have prescribed — and reported strong benchmark performance. The 20-tokens-per-parameter heuristic became a de-facto industry standard for 2023 open-weights releases.
Ablations and evidence audit. [Analysis] Strongly supported: the directional claim that Kaplan’s recipe under-trains. Partially supported: the precise values of and ; the three approaches give between 0.34 and the implicit value from Approach 1 of , with non-trivial uncertainty. Narrow evidence: the universality of the 20:1 token-to-parameter ratio (it is a single point on a curve, not a constant).
Paper C: Wei et al. 2022 — Emergent Abilities of Large Language Models
Section 3 (Wei): Problem formalisation
Formal problem statement. From the paper, Section 2: choose a set of downstream tasks , a set of model families each parameterised by training compute or parameter count, a per-task scoring metric. Plot task performance against scale. Identify tasks whose performance curve is qualitatively flat at small scale and rises sharply at some critical scale.
Definition of emergence (Section 2). “An ability is emergent if it is not present in smaller models but is present in larger models.”
Notation. Wei’s paper uses prose rather than mathematical notation. The key empirical quantity is the per-task performance as a function of training compute across a model family. “Emergent” means stays near random for and rises sharply at .
[Analysis] This is a definition by observed phenomenology, not by underlying mechanism. The paper acknowledges this and is careful not to claim a physical phase transition; “emergence” is used in the Anderson 1972 “more is different” sense. 25
Section 4 (Wei): Motivation and gap
From the paper, Section 1: smooth scaling laws (Kaplan, Chinchilla) cover average loss, but the field had repeatedly observed that specific task performance — multi-step arithmetic, IPA transliteration, certain reasoning prompts — appeared to switch on at particular scales. The paper’s gap claim is that no prior work had catalogued this systematically across model families and tasks.
Section 5 (Wei): Method overview
The method is largely descriptive: collect benchmark results across LaMDA, GPT-3, Gopher, Chinchilla, and PaLM at multiple sizes; plot per-task performance against training compute; mark tasks as emergent where the curve is non-monotonic-then-rising. The paper does not propose a new training method, optimiser, or architecture.
Five model families analysed. LaMDA up to 137B; GPT-3 up to 175B; Gopher up to 280B; Chinchilla 70B; PaLM up to 540B. All decoder-only Transformers trained on roughly comparable text mixtures.
Section 6 (Wei): Mathematical contributions
The paper is non-mathematical at its core; the only quantitative content is the per-task threshold table.
MATH ENTRY [W1]: Emergence-threshold table
- Source: Figure 2 and Table 1 of the paper.
- What it is: A table of (task, model family, compute threshold at emergence). Not an equation; a tabular summary.
| Task | Emergence scale (FLOPs) | Model |
|---|---|---|
| 3-digit addition/subtraction | GPT-3 13B | |
| IPA transliteration | GPT-3 / LaMDA | |
| Word unscrambling | GPT-3 / LaMDA | |
| Persian Q&A | LaMDA 68B | |
| TruthfulQA | Gopher 280B | |
| MMLU (multitask average) | – | GPT-3 / Chinchilla |
| Grounded conceptual mappings | GPT-3 175B | |
| Word in Context (WiC) | PaLM 540B |
Adapted from Figure 2 / Table 1 of Emergent Abilities of Large Language Models (arXiv:2206.07682), reproduced for editorial coverage. 26
- Worked numerical example. GPT-3 13B uses FLOPs of training compute (paper’s Section 3 estimate). Per the paper, 3-digit addition accuracy is at chance for GPT-3 sizes below 13B and exceeds 50% at 13B. The same task does not show this jump on smaller models in other families, although the precise threshold varies (paper Section 5.1).
- Edge cases. Threshold values reported in the paper are model-family-specific; the same task emerges at different FLOP counts in different families.
- Why it matters. The empirical core of the paper.
MATH ENTRY [W2]: Augmented prompting strategies (Figure 3)
- Source: Section 4.
- What it is: A second-tier emergence claim: certain prompting strategies (chain-of-thought, instruction tuning, scratchpad, self-calibration via ) hurt or are neutral on small models and only help above a compute threshold.
| Strategy | Threshold | Below-threshold behaviour |
|---|---|---|
| Chain-of-thought | FLOPs (B params) | Worse than no-CoT baseline |
| Instruction tuning | FLOPs (B params) | Hurts performance below FLOPs |
| Scratchpad (8-digit addition) | FLOPs (M params) | Helps only at larger models |
| Self-calibration via | FLOPs (B params) | Calibration worse than chance |
Adapted from Figure 3 of Emergent Abilities of Large Language Models (arXiv:2206.07682), reproduced for editorial coverage.
- Why it matters. Methodologically important: techniques that are widely used today (instruction tuning, chain-of-thought) appear to require large base models to work at all.
Section 7 (Wei): Algorithmic contributions
The paper introduces no algorithms. The “algorithm” is the empirical procedure of collecting benchmark numbers across model families and looking for non-monotonic curves; this does not warrant a formal ALGORITHM ENTRY block.
Section 8 (Wei): Specialised design contributions
8A — LLM / prompt design. From the paper, Section 3 and Section 4: tasks are evaluated under standard few-shot prompting (typically 5-shot for MMLU, k-shot per task for BIG-bench). Section 4 evaluates augmented prompting (chain-of-thought, instruction-tuned, scratchpad). The paper does not propose new prompts; it uses standard suite prompts.
8B, 8C, 8D. Not applicable to this paper.
Section 9 (Wei): Experiments and results
Tasks. Selected from BIG-bench (a 200-task benchmark suite), 23 MMLU (57 academic subjects), 22 TruthfulQA, Persian Q&A, IPA transliteration, multi-digit arithmetic, and other tasks where prior literature had hinted at scale-dependent behaviour.
Model families. LaMDA, GPT-3, Gopher, Chinchilla, PaLM as listed in Section 5.
Headline finding. From the paper: over 100 emergent abilities are identified across the surveyed model families and benchmarks. The paper’s Appendix A breaks down BIG-bench tasks; Appendix B breaks down MMLU subjects.
Independent benchmark cross-check. [External comparison] The strongest critique of Wei’s emergence claim came from Schaeffer, Miranda, Koyejo at NeurIPS 2023 (Outstanding Paper). 9 Their argument: emergence under exact-match accuracy disappears under continuous metrics like token-edit-distance or log-likelihood. They reproduce the BIG-bench emergence claims and show that on a smooth metric the same curves are smooth. This critique is the load-bearing follow-up the field has converged on; the Wei paper acknowledges the metric-dependence concern in Section 5.1 but its title and framing emphasise the discontinuous-metric view.
Evidence audit. [Analysis] Strongly supported: the empirical observation that on exact-match metrics, many tasks transition sharply with scale. Partially supported: the framing of this as a property of the model rather than a property of the metric. Narrow evidence: the safety implications (Section 5.4) of unpredictable emergence depend on the framing.
Cross-paper sections
Section 10: Technical novelty summary (cluster-wide)
| Component | Type | Novelty level | Source |
|---|---|---|---|
| Power-law on Transformer LMs | New empirical observation | Combination novel | Kaplan §3 |
| Joint form with overfitting interpolation | New functional form | Fully novel | Kaplan §4 |
| Kaplan compute-optimal exponents (0.73 / 0.27) | New numerical prescription | Combination novel | Kaplan §6 |
| Chinchilla three-method triangulation | New methodology | Combination novel | Hoffmann §3 |
| Parametric loss | New functional form | Fully novel | Hoffmann Eq. 10 |
| Chinchilla exponents (0.5 / 0.5) | New numerical prescription overturning Kaplan | Fully novel | Hoffmann §3.4 |
| Emergence-as-discontinuity catalogue | New empirical observation | Fully novel | Wei §3 |
| Augmented-prompt emergence (CoT, instruction tuning) | New empirical observation | Combination novel | Wei §4 |
Single most novel contribution per paper. Kaplan: the joint functional form that lets a single equation predict both the data-limited and parameter-limited regimes. Chinchilla: the empirical refutation of Kaplan’s compute-optimal exponents, validated across three independent methodologies. Wei: the systematic catalogue of over 100 tasks where downstream performance is non-monotonic in scale on the standard evaluation metric.
What the papers do NOT claim to be novel. Kaplan: the underlying Transformer architecture (Vaswani 2017), the cross-entropy loss, the WebText2 dataset (extension of GPT-2’s corpus). Chinchilla: the decoder-only Transformer (consistent with Gopher), the MassiveText corpus, the benchmark suites used (MMLU, BIG-bench). Wei: any of the underlying models or benchmarks; the paper is a meta-analysis.
Section 11: Situating the work (cluster-wide)
Prior work and conceptual change. Hestness et al. 2017 (Baidu) first claimed empirical power-law scaling in deep learning across image classification and machine translation, 12 and Rosenfeld et al. 2020 proposed a related functional form for generalisation error. 13 Kaplan’s contribution was to specialise to Transformer language modelling and treat compute as a primary variable. Chinchilla’s contribution was to overturn Kaplan’s compute-optimal allocation. Wei’s contribution was to shift attention from average loss to per-task capability curves.
Contemporaneous related papers.
- Henighan et al. 2020 — Scaling Laws for Autoregressive Generative Modeling. 27 Same first-author team as Kaplan; extends the framework to vision, audio, math, and code domains. Builds on Kaplan’s derivation; differs by applying it to non-text modalities.
- Hernandez et al. 2021 — Scaling Laws for Transfer. 28 Studies how Kaplan-style laws compose under pretraining-then-finetuning. Builds on Kaplan; differs by introducing the “effective data” notion for transfer learning.
- Schaeffer, Miranda, Koyejo 2023 — Are Emergent Abilities a Mirage? 9 NeurIPS 2023 Outstanding Paper directly responding to Wei. Argues that emergence is largely an artefact of discontinuous metrics; under continuous metrics the curves are smooth and predictable from small-model behaviour.
[Reviewer Perspective] Strongest skeptical objections.
- Against Kaplan: the fitted exponents are biased by under-training the smaller models in the sweep (the load-bearing argument Chinchilla makes in its Section 6).
- Against Chinchilla: the parametric fit’s Approach-3 exponents (, ) differ measurably from Approach 1 (), and the paper does not fully resolve which to trust at extrapolated scales. Independent re-fits by Besiroglu et al. 2024 suggest Approach 3 may be the more accurate but the precise values remain uncertain.
- Against Wei: Schaeffer et al.’s metric-dependence critique substantially undermines the strong “phase transition” framing.
[Reviewer Perspective] Strongest paper-side rebuttals.
- Kaplan: even if the precise exponents are biased, the qualitative power-law shape across seven orders of magnitude is robust and unchallenged.
- Chinchilla: three independent approaches converge on with , which is what the paper actually claims; the exact split is a refinement.
- Wei: even if emergence is metric-dependent, practical deployment metrics ARE typically exact-match or similar; the unpredictability is real for the engineer choosing whether a smaller model suffices.
Three future research directions.
- [Analysis] Re-fit scaling laws on modern post-2023 data mixtures (curated web + code + math) to see whether the irreducible-entropy term has drifted.
- [Analysis] Extend Chinchilla-style analysis to mixture-of-experts (MoE) architectures, where the parameter / FLOP relationship is broken by sparse activation.
- [Reviewer Perspective] Reconcile Wei’s emergence catalogue with Schaeffer’s mirage critique by deriving a per-task metric-correction protocol that the field can agree on as the “true” capability curve.
Section 12: Critical analysis (cluster-wide)
Strengths.
- Kaplan: the seven-orders-of-magnitude empirical span is striking; the joint form remains a useful tool a decade later.
- Chinchilla: the triangulation methodology defends against any single-approach bias; the Chinchilla-vs-Gopher comparison is a clean empirical demonstration of the prescription’s value.
- Wei: the catalogue across five model families is the most systematic emergence study in the literature.
Weaknesses stated by the authors.
- Kaplan: Section 7 acknowledges the laws may not extrapolate beyond the regimes studied (parameters , very high data quality).
- Chinchilla: Section 6 acknowledges that the precise exponent values differ across the three approaches (0.46–0.50 for ) and that compute-optimal does not equal inference-optimal.
- Wei: Section 5.1 acknowledges that metric choice (exact-match versus continuous metrics) may inflate the appearance of discontinuity.
Weaknesses not stated or understated.
- Kaplan [Reviewer Perspective]: the systematic under-training of the smaller sweep models (Chinchilla §6) is, in retrospect, a non-trivial methodological flaw not anticipated in 2020.
- Chinchilla [Reviewer Perspective]: the paper’s compute-optimality criterion ignores inference-time cost. Llama-family and most production deployments deliberately train smaller models on more data than Chinchilla-optimal because the cost of serving dominates.
- Wei [Reviewer Perspective]: the framing as “emergence” implies discontinuity that the underlying data, on a continuous metric, does not always support. The 2023 Schaeffer critique substantially re-contextualises the contribution.
Reproducibility check.
- Kaplan: code not released; training data WebText2 not released; hyperparameters fully reported in Appendix A; compute reported; trained model weights not released; reproducible only with substantial OpenAI-internal infrastructure. Independent partial replication by EleutherAI and Stella Biderman’s group on Pythia (2023) broadly confirmed the qualitative shape.
- Chinchilla: code not released; training data MassiveText not released; hyperparameters fully reported in Appendix; compute reported; Chinchilla 70B weights not released. The Llama 1 release effectively serves as an open-weights validation of the prescription.
- Wei: code not released; the paper is a meta-analysis using already-released model APIs and reported numbers. Evaluation prompts mostly drawn from public BIG-bench and MMLU; partially reproducible.
Methodology disclosure (cluster).
- Sample size. Kaplan: ~4,500 training runs across the sweep. Chinchilla: 400+ runs spanning 70M–16B. Wei: meta-analysis across published checkpoints of 5 model families.
- Evaluation set. Kaplan: held-out WebText2. Chinchilla: held-out MassiveText, MMLU, BIG-bench, C4, The Pile. Wei: BIG-bench, MMLU, and per-task suites.
- Baselines. Kaplan: implicit baselines are the architecture-comparison sweeps in Section 3.3. Chinchilla: Gopher 280B, GPT-3 175B, Jurassic-1, Megatron-Turing NLG 530B. Wei: smaller checkpoints of each model family act as their own baselines.
- Hardware / compute. Kaplan: OpenAI internal compute cluster, specifics not fully disclosed. Chinchilla: TPU v3/v4 pods (Appendix A). Wei: no model training, evaluation only.
Generalisability.
- [Analysis] Kaplan and Chinchilla generalise within their fitted regime but the irreducible-entropy term in Chinchilla depends on data distribution and almost certainly differs for code-heavy or math-heavy corpora.
- [Analysis] Wei’s catalogue may not generalise to non-Transformer architectures (state-space models, recurrent variants) where capacity allocation differs.
Assumption audit.
- The “architecture details have minimal effect” claim (Kaplan §3.3) was defensible for 2020-era dense Transformers but breaks for mixture-of-experts at the same total .
- The “compute ” approximation (Chinchilla §3) holds for standard dense Transformers but fails for MoE, latent-state-space, or hybrid architectures.
- Wei’s “model family is comparable across LaMDA/GPT-3/Gopher/Chinchilla/PaLM” assumption underweights training-data composition differences.
Section 13: What is reusable for a new study (cluster-wide)
REUSABLE COMPONENT [R1]: Chinchilla parametric loss form .
- What it is. Three-term decomposition with explicit irreducible entropy.
- Why worth reusing. Analytically solvable for compute-optimal; explicit has interpretive value.
- Preconditions. Sufficient sweep density across both and .
- What would change. Coefficients need refitting for any new dataset / architecture / tokenisation.
- Risks. As a functional form it is one among several; the Kaplan bracket-form remains a valid alternative.
REUSABLE COMPONENT [R2]: Three-method triangulation methodology.
- What it is. Run multiple independent estimation procedures and report agreement.
- Why worth reusing. The methodology generalises beyond LLM scaling to any compute-optimal allocation problem.
- Preconditions. Compute budget large enough to run each approach independently.
- Risks. Apparent convergence may mask shared bias (e.g., shared learning-rate-schedule assumption).
REUSABLE COMPONENT [R3]: Emergence-threshold tabulation.
- What it is. Tabulate per-task performance curves across a model-family scaling sweep and identify thresholds.
- Why worth reusing. Useful for capability forecasting on a new model family.
- Preconditions. Multiple checkpoints of the same family at different scales.
- Risks. Metric-dependent (per Schaeffer 2023); pair with at least one continuous metric.
Recommendation. [Analysis] For a team studying a new architecture (MoE, state-space, hybrid), the highest-value reusable is [R2] (the three-method triangulation) because it forces methodological honesty; for an alignment / safety team forecasting risk at new scales, [R3] (capability tabulation) paired with Schaeffer-style continuous-metric controls is most valuable.
Section 14: Known limitations and open problems (cluster-wide)
Author-stated limitations. Kaplan §7: laws may not extrapolate. Chinchilla §6: precise exponents are uncertain across approaches and compute-optimal inference-optimal. Wei §5.1, §5.4: metric-dependence and safety implications acknowledged.
Unstated or understated limitations. [Reviewer Perspective] None of the three papers seriously engage with the question of training-data quality as a separate dimension. The implicit assumption is that more tokens is always better than the same tokens deduplicated or filtered; the post-2023 “phi” / “Mistral” literature suggests data quality can substitute for raw token count by a substantial factor.
Open problems.
- The fundamental “why” of scaling laws: no first-principles derivation of exists. The exponent is empirical.
- Reconciliation of Chinchilla’s compute-optimal exponents with inference-optimal economics for production LLMs.
- Whether emergent capabilities (Wei) reduce to metric artefacts (Schaeffer) or whether some genuinely discontinuous capabilities remain after metric correction.
- Extrapolation past the studied regime: laws fitted on – FLOPs may not hold at + FLOPs.
What a follow-up would need to solve. A satisfying follow-up would (a) derive scaling exponents from a tractable theoretical model of Transformer learning rather than fitting them; (b) generalise the parametric form to mixture-of-experts; (c) jointly optimise for training and inference compute under realistic deployment economics.


How this article reads at three depths
For the curious high-school reader. Three papers together built the rules engineers use to decide how big to make AI language models. The first showed loss falls as a smooth curve when models, data, or compute grow. The second corrected the recipe: parameters and data should grow roughly together, not lopsidedly. The third pointed out that even when average loss is smooth, individual skills can appear suddenly at certain scales.
For the working developer or ML engineer. Chinchilla’s allocation is the operational baseline for 2026 dense-Transformer training-compute allocation. The 20-tokens-per-parameter rule of thumb is a single point on a curve and not a constant; refit for your own compute scale. If inference-cost dominates training-cost in deployment economics, train smaller and longer than Chinchilla-optimal (the Llama-family pattern). When forecasting downstream capability at a larger model size, do not extrapolate from small-checkpoint exact-match metrics alone; pair with continuous metrics per Schaeffer 2023 to avoid “emergence surprise.”
For the ML researcher. The Kaplan and Chinchilla functional forms are the canonical empirical anchors for the field; the disagreement between Kaplan’s exponents and Chinchilla’s exponents traces to learning-rate-schedule bias in the Kaplan sweep, per Chinchilla §6. The Chinchilla parametric form admits an analytic compute-optimal solution and remains the form to refit when extending to a new architecture or data mixture. Wei’s emergence catalogue is empirically rich but conceptually contested post-Schaeffer 2023; the strongest follow-up question is whether any task remains genuinely discontinuous after careful metric selection. Neither Kaplan nor Chinchilla has a first-principles derivation of the exponents; producing one is a major open problem.
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. Kaplan et al., "Scaling Laws for Neural Language Models," arXiv:2001.08361 abstract page, accessed 2026-05-19. (accessed ) ↩
- 2. Kaplan et al. ar5iv HTML render, Section 1.1: "trends spanning more than seven orders of magnitude," accessed 2026-05-19. (accessed ) ↩
- 3. Hoffmann et al., "Training Compute-Optimal Large Language Models," arXiv:2203.15556 abstract page, accessed 2026-05-19. (accessed ) ↩
- 4. Wei et al., "Emergent Abilities of Large Language Models," arXiv:2206.07682 abstract page, accessed 2026-05-19. (accessed ) ↩
- 5. Kaplan et al. ar5iv render, Section 3: power-law fits in $N$, $D$, $C_{\min}$, accessed 2026-05-19. (accessed ) ↩
- 6. Hoffmann et al. ar5iv render, Section 3 and Table 2 reporting compute-optimal exponents across three methods, accessed 2026-05-19. (accessed ) ↩
- 7. Hoffmann et al. ar5iv render, Section 4.2 and Table 6 reporting Chinchilla 70B versus Gopher 280B on MMLU and other benchmarks, accessed 2026-05-19. (accessed ) ↩
- 8. Wei et al. ar5iv render, Section 3 and Figure 2 cataloguing emergent abilities across GPT-3, LaMDA, Gopher, Chinchilla, PaLM, accessed 2026-05-19. (accessed ) ↩
- 9. Schaeffer, Miranda, Koyejo, "Are Emergent Abilities of Large Language Models a Mirage?" arXiv:2304.15004 (NeurIPS 2023 Outstanding Paper), accessed 2026-05-19. (accessed ) ↩
- 10. Hoffmann et al. ar5iv render, Section 3.4 and Table 2: Approach-1 $(0.50, 0.50)$, Approach-2 $(0.49, 0.51)$, Approach-3 $(0.46, 0.54)$, accessed 2026-05-19. (accessed ) ↩
- 11. Kaplan et al. ar5iv render, Section 2.1: the Transformer FLOPs-per-token approximation $C \approx 6 N D$, accessed 2026-05-19. (accessed ) ↩
- 12. Hestness et al., "Deep Learning Scaling is Predictable, Empirically," arXiv:1712.00409, accessed 2026-05-19. (accessed ) ↩
- 13. Rosenfeld et al., "A Constructive Prediction of the Generalization Error Across Scales," arXiv:1909.12673, accessed 2026-05-19. (accessed ) ↩
- 14. Brown et al., "Language Models are Few-Shot Learners" (GPT-3), arXiv:2005.14165, accessed 2026-05-19. (accessed ) ↩
- 15. Rae et al., "Scaling Language Models: Methods, Analysis & Insights from Training Gopher," arXiv:2112.11446, accessed 2026-05-19. (accessed ) ↩
- 16. Kaplan et al. ar5iv render, Section 3.1.1–3.1.2 with exponents $\alpha_N \approx 0.076$, $\alpha_D \approx 0.095$ and critical scales $N_c \approx 8.8 \times 10^{13}$, $D_c \approx 5.4 \times 10^{13}$, accessed 2026-05-19. (accessed ) ↩
- 17. Kaplan et al. ar5iv render, Section 5.1: critical batch size $B^* \approx 2 \times 10^8$ tokens, $\alpha_B \approx 0.21$, accessed 2026-05-19. (accessed ) ↩
- 18. Hoffmann et al. ar5iv render, Section 6: discussion of Kaplan-recipe learning-rate-schedule bias, accessed 2026-05-19. (accessed ) ↩
- 19. Hoffmann et al. ar5iv render, Equation 10 and Table 2 reporting $E = 1.69$, $A = 406.4$, $B = 410.7$, $\alpha = 0.34$, $\beta = 0.28$, accessed 2026-05-19. (accessed ) ↩
- 20. Hoffmann et al. ar5iv render, Table 2 of the paper reporting $(a, b)$ for each approach, accessed 2026-05-19. (accessed ) ↩
- 21. Hoffmann et al. ar5iv render, Table 4 of the paper reporting Chinchilla 70B training configuration: 1.4T tokens, cosine schedule peak $1 \times 10^{-4}$, accessed 2026-05-19. (accessed ) ↩
- 22. Hendrycks et al., "Measuring Massive Multitask Language Understanding," arXiv:2009.03300, accessed 2026-05-19. (accessed ) ↩
- 23. Srivastava et al., "Beyond the Imitation Game: Quantifying and Extrapolating the Capabilities of Language Models" (BIG-bench), arXiv:2206.04615, accessed 2026-05-19. (accessed ) ↩
- 24. Hoffmann et al. ar5iv render, Table 6 reporting Chinchilla 67.6%, Gopher 60.0%, GPT-3 43.9% on MMLU 5-shot, accessed 2026-05-19. (accessed ) ↩
- 25. Anderson, "More Is Different," Science 177(4047):393-396, 1972, accessed via Science journal record, accessed 2026-05-19. (accessed ) ↩
- 26. Wei et al. ar5iv render, Figure 2 and Table 1 reporting per-task emergence thresholds in FLOPs across model families, accessed 2026-05-19. (accessed ) ↩
- 27. Henighan et al., "Scaling Laws for Autoregressive Generative Modeling," arXiv:2010.14701, accessed 2026-05-19. (accessed ) ↩
- 28. Hernandez et al., "Scaling Laws for Transfer," arXiv:2102.01293, accessed 2026-05-19. (accessed ) ↩
Further Reading
Anonymous · no cookies set