Ring Attention and Striped Attention: a multi-paper review of long-context attention engineering
Multi-paper review of Ring Attention and Striped Attention — how blockwise distributed self-attention pushes context windows past a million tokens.
Reading-register key
- From the paper: claims drawn verbatim or near-verbatim from the source paper’s text, equations, tables, or figures.
- [Analysis]: the publication’s own reasoned assessment, distinct from any claim the papers themselves make.
- [Reconstructed]: content the publication faithfully reconstructed because the paper only partially disclosed it.
- [External comparison]: comparison to prior work or general knowledge outside the cited papers.
- [Reviewer Perspective]: a critical or speculative assessment that goes beyond what either paper proves.
Section 1: Cluster scope
This review covers two papers that together define the dominant engineering pattern for distributing self-attention across many devices when a sequence is too long to fit in a single device’s memory: Ring Attention with Blockwise Transformers by Liu, Zaharia, and Abbeel (arXiv:2310.01889, October 2023) 1 and Striped Attention: Faster Ring Attention for Causal Transformers by Brandon, Nrusimha, Qian, Ankner, Jin, Song, and Ragan-Kelley (arXiv:2311.09431, November 2023). 2 Together with FlashAttention 3 and memory-efficient attention, 5 these are the techniques that engineer the million-plus-token context windows that Gemini 1.5, Gemini 2, and (per public disclosure) Gemini 3 advertise. 7
The two papers are not independent. Ring Attention is the parent; Striped Attention is a one-line algorithmic fix targeting the workload-imbalance problem Ring Attention exhibits whenever it is used to train a causal (autoregressive) language model. [Analysis] Read together, they map the design space for any practitioner who needs to push a transformer’s training-time or inference-time context window past what one device can hold.
Paper classification: Architecture (attention variant) · Training method · Inference method · Optimisation · Theoretical (communication-computation overlap bounds).
Primary research question. How can self-attention be computed exactly (no approximations, no sparsification) when the sequence length exceeds any single device’s memory capacity, and how can the resulting distributed algorithm be load-balanced when the attention pattern is causally masked?
Core technical claims. Ring Attention claims that an exact distributed attention can be implemented such that the only memory cost per device that scales with sequence length is the query, key, value, and output activation blocks themselves, and that key-value communication between devices can be fully overlapped with computation, provided a block-size threshold tied to the device’s FLOPS-to-bandwidth ratio is met. Striped Attention claims that Ring Attention loses roughly half its theoretical training throughput when applied to causal transformers because of a triangular workload imbalance, and that this can be fixed by permuting token-to-device assignment from contiguous blocks to round-robin stripes.
Core technical domains and depth labels.
- Distributed systems / collective communication: deep.
- Transformer architecture: moderate.
- GPU / TPU programming model: moderate.
- Numerical linear algebra (online softmax): deep (covered in dependency, FlashAttention).
Reader prerequisites. High-school algebra plus an interest in how large neural networks are trained. Familiarity with the transformer attention formula is helpful but the Glossary in Section 2.5 covers what is needed. Familiarity with the concept of “splitting work across multiple GPUs” is helpful; everything else is on-ramped.
Section 2: TL;DR and executive overview
TL;DR. Modern language models read very long inputs, a million words, sometimes ten million. The attention step inside a transformer normally needs an amount of memory that grows with the square of the input length, which is why one GPU cannot hold a million-token attention table. Ring Attention is a way of splitting that attention work across many GPUs arranged in a ring, passing chunks of the input around the ring while each GPU does its piece, and Striped Attention is a small tweak that fixes a load-balancing problem the original method has when training a language model that predicts one word at a time.
Executive summary (~100 words). Ring Attention shows that self-attention, which appears to need quadratic memory per device, can be reorganised so that each of N devices holds only a 1/N slice of the sequence, exchanges key-value blocks around a ring topology, and keeps its memory bill flat in the sequence length. Striped Attention shows that Ring Attention idles roughly half the cluster when training causal language models, because the causal mask sends entirely-skippable work to some devices and entirely-real work to others on every iteration. Replacing contiguous token blocks with round-robin stripes balances the load and lifts end-to-end training throughput by 1.4×–1.65×.
Five practitioner-relevant takeaways.
- For training or inference on sequences longer than a single device’s HBM can hold the attention activations for, Ring Attention is the reference distributed exact-attention algorithm.
- The block-size choice is not arbitrary, it must exceed the device’s FLOPS-to-bandwidth ratio to keep communication off the critical path. From the paper: the inequality is .
- Causal training workloads should use Striped Attention rather than vanilla Ring Attention; the change is a token-permutation pass at sequence ingestion and a small modification to the per-tile causal mask.
- Ring Attention is orthogonal to FlashAttention. The intra-device kernel is still FlashAttention (or FlashAttention-2); Ring Attention is the inter-device coordination layer.
- For inference (no causal mask imbalance at sequence-prefill time, but KV-cache rotation at decode time), Ring Attention’s overlap discipline still applies; the imbalance Striped Attention fixes is specific to training.
Pipeline overview in text. At training time, a sequence of length is sharded across devices. Each device holds its query block for the duration of one layer’s attention computation. The key-value blocks for rotate around the ring: in iteration , device holds key-value block , computes the partial attention contribution against its local , and overlaps the send of its currently-held to the next device with the next compute step. After iterations every device has seen every block. Online-softmax accumulation, as in memory-efficient attention and FlashAttention, keeps the partial outputs numerically correct without ever materialising the full attention matrix. The feed-forward network applies blockwise to each device’s local activations and incurs no further communication for this layer.
Section 2.5: Glossary
| Term | Plain-English explanation | First appears in |
|---|---|---|
| Attention | The transformer step where each token in a sequence looks at every other token and computes a weighted sum; the weights come from a similarity score. | Section 2 |
| Self-attention | Attention where the queries, keys, and values all come from the same sequence (as opposed to a translation setup where one sequence attends to another). | Section 2 |
| Quadratic memory | Memory cost that grows like the square of the sequence length; a 1,000-token sequence needs a 1,000×1,000 table, a 1,000,000-token sequence needs a 1,000,000×1,000,000 table. | Section 2 |
| Block / tile | A small piece of the sequence (say, 4,096 tokens) processed together, so the algorithm works on manageable chunks instead of the whole sequence at once. | Section 5 |
| Online softmax | A way of computing the softmax normalisation incrementally as new blocks arrive, instead of needing all values present at once; the trick that makes blockwise attention numerically exact. | Section 5 |
| Causal mask | A rule that prevents each token from “seeing the future” — token may only attend to tokens . Required for next-token language modelling. | Section 5 |
| Ring topology | An arrangement where devices are connected in a circle, each talking only to its left and right neighbours; standard pattern for bandwidth-efficient collective communication. | Section 5 |
| FLOPS / bandwidth | FLOPS is how many arithmetic operations a chip can do per second; bandwidth is how many bytes it can read or send per second. Their ratio tells you whether an algorithm is compute-bound or memory-bound. | Section 6 |
| KV cache | At inference time, the keys and values from already-generated tokens are kept around so they don’t need to be recomputed. The KV cache grows linearly with generated tokens. | Section 9 |
[Analysis] label | The publication’s own reasoned assessment, distinct from what the papers themselves claim. | Throughout |
[Reviewer Perspective] label | A critical or speculative assessment that goes beyond what either paper proves. | Section 11 + 12 |
[Reconstructed] label | Content the publication faithfully reconstructed because the paper only partially disclosed it. | Where used |
[External comparison] label | A comparison to prior work or general knowledge outside the cited papers. | Section 4 + 11 |
| ”From the paper:” prefix | Content directly supported by the paper’s text, equations, tables, or figures. | Throughout |
Section 3: Problem formalisation
Notation table.
| Symbol | Type | Meaning | First appears in |
|---|---|---|---|
| integer | total sequence length in tokens | Section 3 | |
| integer | number of devices (GPUs, TPU chips) in the ring | Section 3 | |
| integer | per-device block size (tokens) | Section 3 | |
| integer | hidden / model dimension per token | Section 3 | |
| integer | number of attention heads | Section 3 | |
| integer | batch size | Section 3 | |
| tensors | query / key / value blocks held by device | Section 3 | |
| float | per-device peak FLOPS (operations per second) | Section 6 | |
| float | inter-device bandwidth (bytes per second) | Section 6 | |
| order notation | asymptotic upper bound | Section 6 |
Formal problem statement.
Given an input sequence with so large that the attention matrix does not fit in a single device’s memory, compute the exact self-attention output
across devices arranged in a ring such that:
- Per-device peak memory grows only with the block size , not with itself.
- The output is numerically identical to single-device attention (no approximation).
- Inter-device communication is fully overlapped with on-device computation, so total wall-clock time is dominated by compute, not data movement.
Assumptions (made explicit by Ring Attention or implied by the analysis):
- Devices are connected by a topology that supports a ring traversal, true for NVIDIA NVLink-connected GPU groups, InfiniBand-connected GPU clusters with sufficient bisection bandwidth, and TPU mesh interconnects. 1
- All devices have equal peak FLOPS and equal per-link bandwidth (homogeneous cluster).
- The per-device block size exceeds the FLOPS-to-bandwidth threshold , [Analysis] an assumption that gets harder to satisfy on newer hardware where FLOPS grow faster than off-chip bandwidth. The H100 and B200 generations have raised substantially.
- For Striped Attention specifically: the attention pattern is causal (lower-triangular mask).
Why the problem is hard. Standard attention materialises a matrix of similarity scores; even at , this is entries, far past any single device’s HBM. Two prior memory-efficient algorithms, Rabe and Staats’s memory attention 5 and FlashAttention 3 , keep the per-device memory bill manageable on a single device by streaming through blocks of and . But the and tensors themselves are each, and at they alone do not fit on one device. Distribution across devices becomes necessary, and the naïve all-gather-then-compute approach destroys the FlashAttention memory savings by re-materialising the full and on every device. Ring Attention is the design that distributes the tensors without re-materialising them.
Section 4: Motivation and gap
The pre-Ring-Attention state of the art for very long context was a stack of compromises: sparsification (Longformer, BigBird), low-rank approximation (Linformer, Performer), or hierarchical attention. All of them sacrificed either exactness or modelling quality. [External comparison] The “scaling all the way” alternative, train on shorter sequences and extend at inference, was the Transformer-XL / position-interpolation line, which also makes approximations at the boundaries of the cached segments.
The two memory-efficient attention algorithms that preserve exactness, Rabe and Staats’s online-softmax formulation 5 and FlashAttention 3 , solved single-device memory but not multi-device sharding. The gap Ring Attention closes is specifically: exact attention, distributed across N devices, with linear (not quadratic) per-device memory in , and communication fully hidden behind computation.
The practical stakes are large. Long-document QA, long-video understanding, code-repository-scale reasoning, and the agentic patterns that need long histories all hit the same wall: the model cannot attend to what does not fit. [External comparison] Anthropic’s Claude 200K context, OpenAI’s GPT-4 Turbo 128K, and the Gemini 1M / 2M / 10M-token results all sit downstream of distributed-attention engineering of which Ring Attention is the public, citable reference design.
Section 5: Method overview
The two methods share a substrate. We describe Ring Attention first, then the Striped Attention modification.
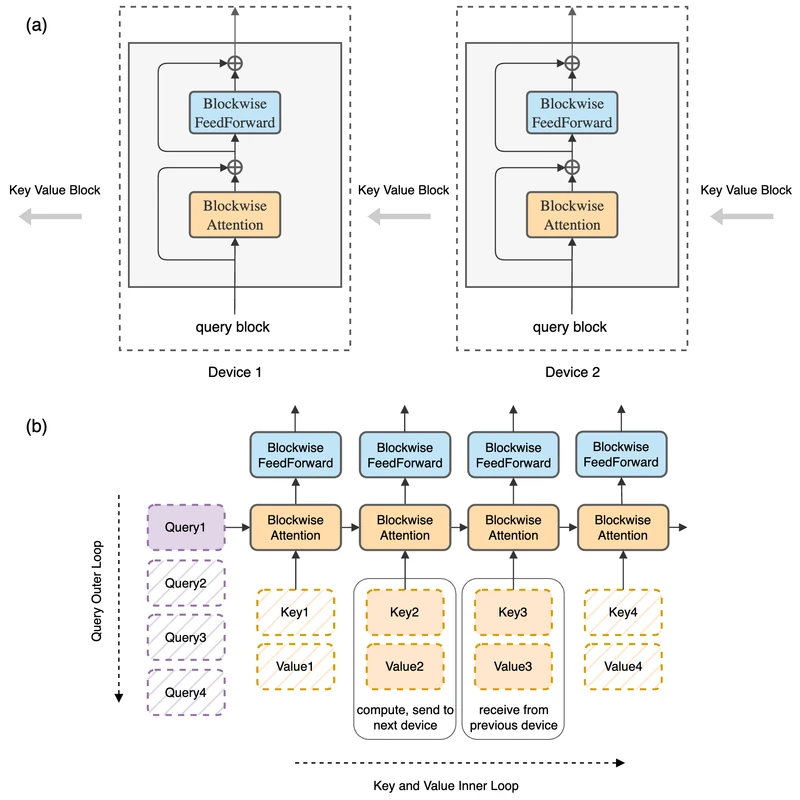
5.1 Ring Attention, core mechanism
Setup. A sequence of length is sharded into contiguous blocks of size . Device receives block (tokens through ). Each device computes its local from . So far, identical to any data-parallel sharding scheme.
The ring. Device holds for the entire layer. The pairs rotate. At iteration , device holds key-value block and computes the partial attention contribution
incorporated into a running partial output via the online-softmax accumulator from FlashAttention. 3 Concurrently, the device sends its currently-held block to its right neighbour and receives the next block from its left neighbour.
Why the overlap works. The per-iteration computation is FLOPs; the per-iteration communication is bytes. As long as is large enough that the compute time exceeds the communication time, the send/receive sits underneath the compute and adds nothing to wall-clock time.
Design rationale. [Analysis] Ring Attention is essentially the standard ring-allreduce 10 pattern from distributed gradient aggregation, repurposed to a different commutative-associative aggregation: instead of summing gradients, it accumulates online-softmax-corrected attention contributions. The reuse is elegant; the ring topology was already first-class on every major training cluster.
What breaks if removed. If the ring rotation is replaced with an all-gather of across devices, each device must hold the entire tensors before computing, which defeats the linear-memory property at large . If the online-softmax accumulator is replaced with a naïve per-block softmax, the output is no longer mathematically equal to single-device attention.
Novelty: [Adapted] from ring-allreduce + memory-efficient attention. The reuse of FlashAttention’s online-softmax inside each tile is [Adopted].
5.2 Striped Attention, the causal-imbalance fix
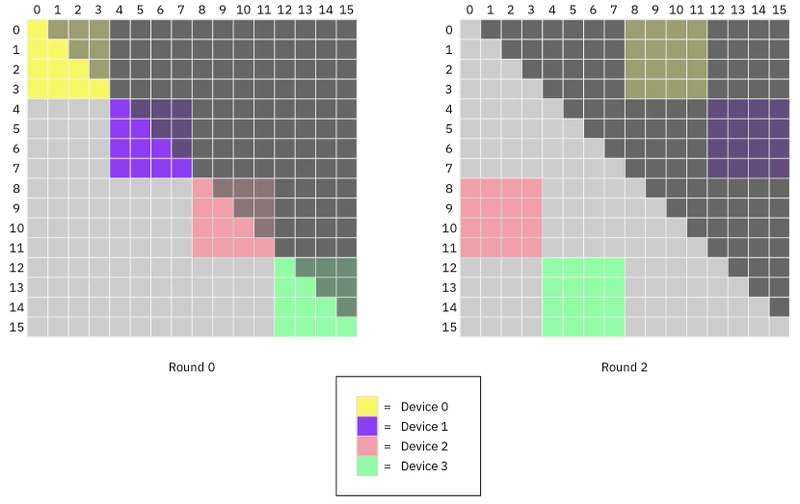
The problem Striped Attention identifies. When Ring Attention is used to train a causal language model, the attention mask is lower-triangular: query token may only attend to key tokens . With contiguous token-to-device assignment, the consequence on iteration is brutal. From the paper: “on all but the first iteration of the Ring Attention algorithm, the workload of some devices is entirely necessary (unmasked), while the workload of others is entirely unnecessary (masked) for the final output.” 2
Because the ring is synchronous (the latency of each iteration is set by the slowest device), the device doing real work pays the full per-iteration cost regardless of how much work the other devices skipped. Effective throughput drops by close to 2× relative to the no-mask case.
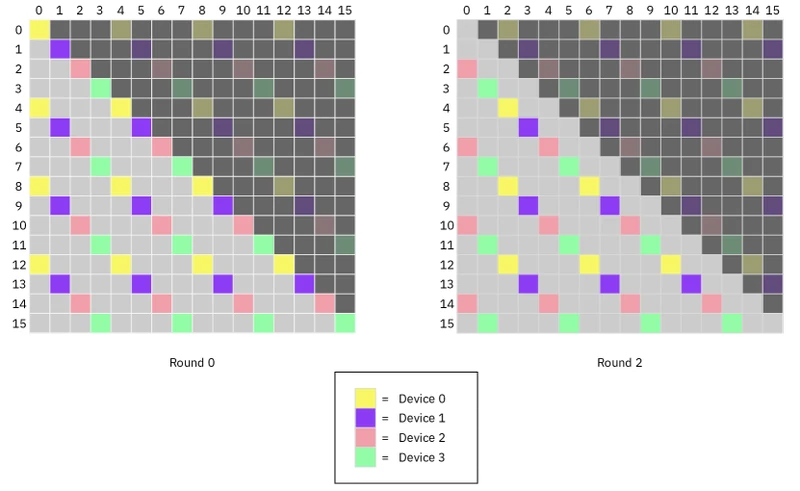
The fix. Replace contiguous token-to-device assignment with a round-robin (striped) permutation: device gets tokens . After this permutation, on every iteration of the ring, every device’s local causal-mask pattern is upper-triangular within its tile (give or take a one-token offset), and every device skips roughly the same fraction of work.
Per-iteration work formula. From the paper: with per-device block size ,
The two cases differ by (one diagonal’s worth of work), so the imbalance is at most a single block-diagonal, vanishing as a fraction of total work for any practical . 2
Design rationale. [Analysis] Striped Attention does not change the ring topology, the communication pattern, or the per-tile kernel. It is a permutation applied at sequence ingestion and a slightly modified within-tile mask. The implementation cost is small; the throughput payoff is large.
Novelty: [New], the imbalance observation and the round-robin fix are the paper’s contribution. The underlying Ring Attention is [Adopted] from Liu et al.
5.3 Subsections that do not apply at the architecture level
The architecture of the transformer (number of layers, head count, hidden dimension, position encoding, normalisation choice) is unchanged by either paper. Both methods are drop-in replacements for the attention sub-layer; the FFN is computed blockwise on each device’s local activations and incurs no further communication.
Training procedure changes: none beyond the attention kernel and the (Striped) token permutation. Optimiser, learning-rate schedule, gradient clipping, mixed precision are all standard.
Inference procedure changes: during prefill, the same ring-attention pattern applies. During decode (single-token generation with a long KV cache), the KV cache is sharded across devices and the rotation pattern still applies, but the per-step compute drops to and bandwidth becomes the bottleneck, [Analysis] which is why production inference systems for long-context models tend to use a tensor-parallel layout for short contexts and switch to ring-style sequence-parallel layouts only when the KV cache exceeds single-device memory.
Section 6: Mathematical contributions
MATH ENTRY 1: Standard attention
- Source: standard transformer literature; referenced by both papers.
- What it is: the formula that computes, for each query token, a weighted sum of value vectors, where the weights come from how similar the query is to each key.
- Formal definition:
- Each term explained AND its dimensional/type analysis:
- , query matrix; one row per token.
- , key matrix; one row per token.
- , value matrix; one row per token.
- , the similarity matrix; this is the object whose memory cost is quadratic in .
- is a scalar; dividing by it stabilises gradients when is large.
- softmax acts row-wise on the matrix and produces a row-stochastic matrix (each row sums to 1).
- post-multiplication produces output .
- Worked numerical example: take tokens, . Let Then is a matrix whose row 0 reads (token 0 has dot product 1 with itself and token 2, 0 with the rest). With , dividing by gives row 0 of the scaled similarity as . Softmax of that row is approximately (the larger entries win, but the smaller ones still contribute). Multiplying by yields row 0 of the output. The point of the example is to anchor the dimensional shape: the intermediate is what would be at , hence the memory problem.
- Role: the operation Ring Attention distributes.
- Edge cases: when a row of is uniformly (fully masked), softmax is undefined; in practice the row is replaced by zeros after the masked rows are dropped from the output indexing.
- Novelty: [Adopted], standard.
- Transferability: [Analysis] anything that has a softmax-and-weighted-sum structure inherits Ring Attention compatibility, e.g., the cross-attention in encoder-decoder models, retrieval-augmented attention.
- Why it matters: every memory-efficient and distributed attention algorithm reduces to “compute this object without ever materialising the inner matrix in any one device’s memory.”
MATH ENTRY 2: Online softmax (the key trick from memory-efficient attention; reused inside Ring Attention)
- Source: Rabe & Staats 2021, 5 Milakov & Gimelshein 2018, 6 reused by FlashAttention. 3
- What it is: a way of computing the softmax incrementally as new score-blocks arrive, so partial outputs from each block can be merged into a single correct final output.
- Formal definition: given two partial-softmax-accumulators and where is the running max, the running denominator, the running weighted-value sum, the merge is
- Each term explained AND its dimensional/type analysis:
- , scalar running maximum per query row (per token).
- , scalar running normaliser per query row.
- , running weighted-sum-of-values per query row.
- The factors and rescale the older accumulator when a new larger max is observed; this is what makes the algorithm numerically stable.
- Worked numerical example: query row 0, processing two blocks. Block 1 yields scores with values , so , , . Block 2 yields scores with value , so , , . Merge: , , . The cross-check: directly softmax-then-weight of against yields the same number. The merge is exact.
- Role: this is the per-tile correction that Ring Attention uses N times, once per iteration around the ring, so the partial outputs from each pair are combined into the final output without ever assembling the full similarity matrix.
- Edge cases: if all scores are (fully masked query row), and the formula collapses to ; in practice the row is detected and zeroed.
- Novelty: [Adopted], Ring Attention reuses this; the novelty is that Ring Attention applies it across devices, not just across tiles on one device.
- Transferability: [Analysis] any blockwise or distributed softmax-based aggregator inherits this trick.
- Why it matters: without online softmax, Ring Attention would have to materialise the per-row max and per-row normaliser globally before any device could compute a final output, defeating the streaming property.
MATH ENTRY 3: Ring Attention’s communication-computation overlap inequality
- Source: Ring Attention paper, Section 3, derived from the per-iteration FLOP and byte counts. 1
- What it is: a single inequality that tells you whether the ring’s communication cost is hidden behind its compute cost.
- Formal definition: the overlap condition is which simplifies to
- Each term explained AND its dimensional/type analysis:
- is the per-device block size (tokens).
- is the hidden dimension per token.
- is the device’s peak compute throughput in FLOPS (floating-point operations per second).
- is the inter-device bandwidth in bytes per second.
- The factor 4 in compute comes from the two matrix multiplies and (each contributes FLOPs in the half-precision case, dropping a factor for fused multiply-add).
- The factor 4 in communication comes from sending both and blocks (each is bytes in fp16; both must be sent).
- Worked numerical example: A100 with (fp16, tensor cores) and NVLink-3 bandwidth . Then . So the per-device block size must satisfy tokens for the overlap to hide communication. [Analysis] A practical block size of 4,096 or 8,192 tokens comfortably exceeds this on A100/H100-class GPUs. On H100 with and NVLink-4 bandwidth , , still well within a 4,096-token block size. On clusters with InfiniBand (much lower effective bandwidth), the threshold tightens.
- Role: this is the design constraint a practitioner picks to satisfy. Pick too small and the ring stalls on communication; pick it too large and the per-device memory bill rises.
- Edge cases: if the cluster has non-uniform bandwidth (e.g., some links use NVLink and others use InfiniBand), the effective is the minimum link bandwidth on the ring, which can be much lower than the headline number.
- Novelty: [New], the explicit derivation tying block size to FLOPS-to-bandwidth ratio is the paper’s contribution.
- Transferability: [Analysis] the same inequality governs any sequence-parallel scheme where compute scales quadratically in block size and communication scales linearly. Practitioners can apply it directly when porting Ring Attention to new hardware.
- Why it matters: the inequality is the engineering knob. It tells you whether Ring Attention will give you the linear-memory-and-hidden-communication property you bought it for.
MATH ENTRY 4: Per-layer activation memory for Ring Attention
- Source: Ring Attention paper, Table 1. 1
- What it is: the memory footprint per device per transformer layer.
- Formal definition: From the paper: versus versus memory-efficient single-device attention:
- Each term explained AND its dimensional/type analysis:
- , batch size (dimensionless).
- , per-device block size; depends on the number of devices in the ring.
- , hidden dimension.
- , full sequence length.
- The factor 6 in Ring Attention covers , , , and the running accumulators per block.
- Worked numerical example: train a 7B model with , , tokens.
- Vanilla: bytes per layer. That’s 8 petabytes per layer. Obviously impossible.
- Memory-efficient (single device, no Ring): bytes = 8.2 GB per layer. Just for the activations on one device per layer; with ~32 layers and the rest of the model, this still overflows a single A100-80GB.
- Ring Attention with , so : bytes per device per layer = 0.77 GB. Now we fit.
- Role: this is the constraint that determines whether a given pair is trainable on a given cluster. Practitioners use this directly to pick .
- Edge cases: gradient activation checkpointing changes the numbers; mixed precision changes bytes-per-element.
- Novelty: [New], the explicit accounting per layer including the online-softmax accumulator state is the paper’s contribution.
- Transferability: [Analysis] the formula is hardware-agnostic; the same numbers govern TPU, GPU, and future accelerator clusters.
- Why it matters: the formula is the reason “linear in sequence length per device” is a true claim, not a marketing one.
MATH ENTRY 5: Striped Attention per-iteration workload
- Source: Striped Attention paper, Section 2 + 3. 2
- What it is: the formula that quantifies how much actual attention work each device does per ring iteration under the causal mask.
- Formal definition: per-iteration work on device when it currently holds key-value block originally indexed (Striped Attention, after the round-robin permutation):
- Each term explained AND its dimensional/type analysis:
- , per-device block size.
- , device indices in (the round-robin coset to which each device’s tokens belong).
- The two cases correspond to whether the device’s current query stripe sits at or below the diagonal versus above the diagonal, under round-robin striping, this alternates uniformly across iterations.
- Worked numerical example: devices, tokens per device.
- Under Ring Attention (contiguous): on iteration , device 0 holds the key-value block for tokens , but device 0’s query block is tokens , every query is masked (queries 0..4095 cannot attend to future keys 16384..20479). So device 0 does useful FLOPs in this iteration. Meanwhile, device 7 (queries 28672..32767) holding the key block 16384..20479 has every query able to attend to every key: score computations. The ring iteration waits for device 7 to finish; device 0’s idle time is wasted.
- Under Striped Attention: device 0 holds queries ; on the same iteration, holding the key stripe , half the queries can attend (the ones with index the corresponding key index), half cannot. Work per device per iteration: , every device, every iteration.
- The empirical consequence: From the paper: 1.41×–1.45× end-to-end speedup at 256K sequence length on A100, 1.65× at 786K on TPUv4. 2
- Role: this is the formula that justifies the round-robin permutation. The work is symmetric across pairs, so the slowest device on any iteration sets a lower wall-clock floor.
- Edge cases: when the per-tile causal mask straddles the diagonal exactly, an extra one-token sliver of work appears on the diagonal device per iteration, this is the in . For practical , the imbalance is , vanishing.
- Novelty: [New], the workload-imbalance characterisation and the symmetric formula are the paper’s contribution.
- Transferability: [Analysis] the same round-robin pattern can be applied to any masked-attention sequence-parallel scheme, sliding-window causal attention, mixture-of-modalities attention with structured masks.
- Why it matters: this is the per-line justification for why a one-line code change (the permutation) lifts a 1.4×–1.65× throughput improvement out of a fixed cluster.
Section 7: Algorithmic contributions
ALGORITHM ENTRY 1: Ring Attention forward pass (the headline algorithm)
- Source: Ring Attention paper, Algorithm 1. 1
- Purpose: compute exact self-attention on a sequence too long to fit in any single device’s memory.
- Inputs:
- , local query, key, value blocks on device
- , number of devices in the ring
- block size chosen so
- Outputs:
- , local attention output block on device
- Pseudocode:
RingAttentionForward(Q_i, K_i, V_i; N, c, d_k):
# Per-device initialisation
K_cur, V_cur := K_i, V_i # the K, V block currently on this device
m, ell, O := -inf vector, 0 vector, zero matrix # online-softmax state
for t in 0 .. N-1:
# Compute partial attention contribution against the current K, V block
S_block := Q_i @ K_cur.T / sqrt(d_k)
m_block := rowmax(S_block)
P_block := exp(S_block - m_block)
ell_block := rowsum(P_block)
O_block := P_block @ V_cur
# Online-softmax merge with running accumulator
m_new := max(m, m_block)
ell := exp(m - m_new) * ell + exp(m_block - m_new) * ell_block
O := exp(m - m_new) * O + exp(m_block - m_new) * O_block
m := m_new
# Rotate K, V blocks around the ring (overlapped with next iteration's compute)
if t < N - 1:
send(K_cur, V_cur) to right neighbour
K_cur, V_cur := recv from left neighbour
O_i := O / ell # final softmax normalisation
return O_i- Hand-traced example on minimal input: devices, tokens per device, . Assume queries on devices 0, 1, 2 are , , (column vectors after transpose so they’re ). Keys equal queries. Values are . Trace device 0’s local state:
- Iteration 0: , . . . . . . Update accumulators. Concurrently: send to device 1; recv from device 2.
- Iteration 1: , . Repeat. Concurrently: send to device 1; recv from device 2.
- Iteration 2: . Final accumulation. No rotation needed.
- Output: after the loop. The arithmetic is identical to single-device attention on the full for query rows belonging to device 0; the only difference is where the partial sums were computed.
- Complexity:
- Time: FLOPs per device per layer. Note this is linear in per device, super-linear in the cluster, which is correct: total attention work is , split over devices, giving per device.
- Space: activation memory per device, independent of .
- Communication: bytes per device per layer, fully overlapped with compute when .
- Bottleneck step: the per-iteration attention matmul (compute), unless the overlap inequality is violated, in which case the bottleneck shifts to inter-device send/recv (communication).
- Hyperparameters:
- : number of devices. From the paper: scaled to 1,024 TPUv4 chips and 32 A100 GPUs in different configurations. 1
- : block size. [Analysis] typical choice 2,048–8,192; must satisfy .
- Failure modes:
- Ring stalls if any device’s compute time falls below its receive time (overlap inequality violated).
- Numerical issues at very long sequences if online-softmax state is kept in fp16, practitioners keep in fp32. 3
- Heterogeneous bandwidth: a ring is only as fast as its slowest link.
- Novelty: [New], the explicit Ring Attention algorithm + overlap analysis.
- Transferability: [Analysis] the algorithm transfers directly to TPU, GPU, and future accelerators that support a ring-style send/recv primitive and have a sufficient FLOPS-to-bandwidth ratio.
ALGORITHM ENTRY 2: Striped Attention forward pass (the headline algorithm of the second paper)
- Source: Striped Attention paper, Section 3. 2
- Purpose: same as Ring Attention, but balanced for causal attention training.
- Inputs:
- Sequence (pre-permutation)
- devices
- Outputs:
- (post-de-permutation, so externally the algorithm is observationally identical to Ring Attention)
- Pseudocode (the two added lines vs Ring Attention are marked):
StripedAttentionForward(x; N):
# *** NEW: permute tokens to round-robin assignment ***
x_permuted := stripe_permute(x, N) # token t goes to device (t mod N)
# Shard the permuted sequence and run Ring Attention,
# but with a slightly modified per-tile causal mask:
O_permuted := RingAttentionForward(
x_permuted,
causal_mask_fn = stripe_causal_mask(t -> t * N + i, t' -> t' * N + j)
)
# *** NEW: invert the permutation on the output ***
O := stripe_unpermute(O_permuted, N)
return OThe stripe_causal_mask is essentially the same lower-triangular mask, but evaluated on the original token indices, not the device-local indices. Under round-robin striping, on each ring iteration the per-tile mask becomes a near-perfectly-upper-triangular block (give or take a one-token offset depending on the relative coset positions).
- Hand-traced example on minimal input: tokens, devices, tokens per device.
- Contiguous (Ring Attention): device 0 = tokens (0, 1); device 1 = tokens (2, 3); device 2 = tokens (4, 5); device 3 = tokens (6, 7). On iteration , device 0 (queries 0, 1) holds keys (4, 5), every query is masked (cannot attend to future). Device 3 (queries 6, 7) holds keys (4, 5), every query is unmasked. Imbalance.
- Striped: device 0 = tokens (0, 4); device 1 = tokens (1, 5); device 2 = tokens (2, 6); device 3 = tokens (3, 7). On iteration , device 0 holds keys (2, 6), query 0 is masked against both, query 4 is unmasked against both. Roughly half the work, but every device on this iteration does roughly half the work. Symmetry restored.
- Complexity: same asymptotics as Ring Attention; throughput constant lifted by 1.4×–1.65×. 2
- Hyperparameters: same as Ring Attention.
- Failure modes: if the per-tile mask is implemented with too coarse a tile granularity (whole tiles skipped only when fully masked), the per-iteration imbalance returns at small block sizes, From the paper: the practical mask implementation skips tiles at 2048×4096 (GPU) or 2048×2048 (TPU) granularity, large enough that work skipping is effective. 2
- Novelty: [New], the permutation and modified mask.
- Transferability: [Analysis] the same permutation pattern applies to any structured-mask sequence-parallel algorithm.
Section 8: Specialised design contributions
8A, LLM / prompt design
Not applicable to these papers (both are systems-level attention algorithms, not LLM-application papers).
8B, Architecture-specific details
Position encodings. [Analysis] Both papers are silent on position encodings, but the choice matters for long-context. RoPE (rotary positional embedding) with extended base frequency or NTK-aware scaling is the de-facto standard for million-token inference; Ring Attention is compatible with any positional scheme that operates per-token (which is essentially all modern choices) because the per-token RoPE rotation is computed locally on each device.
Tokenisation. Not changed by either paper. The sequence-length numbers in both papers are token counts after tokenisation.
Multi-query and grouped-query attention. [Analysis] Both papers were written for vanilla multi-head attention. GQA and MQA reduce the memory footprint by a factor of (heads / kv-heads), which reduces the per-iteration communication volume around the ring proportionally, making the overlap inequality easier to satisfy. Production long-context models (Llama-3, Gemini, Claude) all use GQA; Ring Attention’s overlap analysis transfers, with a smaller -side constant.
8C, Training specifics
Hardware. From the paper: Ring Attention experiments span TPU v3-512, TPU v4-1024, TPU v5e-256, A100 8x and 32x configurations. 1 Striped Attention runs on 8x A100 80GB and 4-chip / 16-chip TPU v3 / v4 setups. 2
Batch size. Ring Attention experiments use small batches (often ) because the per-device sequence dimension consumes the activation budget. [Analysis] This is a fundamental long-context constraint: at , batch size 1 is the only realistic option on current hardware.
Mixed precision. From the paper: Ring Attention uses bf16 weights and activations with fp32 online-softmax state. 1
Distributed setup. Ring Attention is sequence-parallel and composes with tensor-parallel and pipeline-parallel layouts; the canonical large-scale setup combines all three.
8D, Inference / deployment specifics
Prefill vs decode. [Analysis] At prefill (consuming the user’s long input), Ring Attention runs as described. At decode (generating one token at a time against a long KV cache), the picture changes: the new query is a single token broadcast around the ring, and each device computes the partial attention against its local KV-cache slice. Communication volume drops dramatically (only one query needs broadcasting), but the operation becomes bandwidth-bound rather than compute-bound. Production inference systems use a different sharding for prefill versus decode.
KV-cache offloading. [Analysis] When the KV cache exceeds GPU HBM, vendor systems (DeepSpeed-MII, vLLM, TensorRT-LLM) offload to CPU memory or NVMe. Ring Attention’s sequence-parallel sharding is one alternative; the choice depends on the deployment latency target.
Section 9: Experiments and results
Datasets. Both papers use language-modelling on a mixture of curated long-context data (books, code repositories, scientific papers). Striped Attention’s primary experimental harness is throughput measurement, not validation perplexity, the algorithm is exact, so perplexity is unchanged by construction.
Baselines.
- For Ring Attention: vanilla attention, memory-efficient attention (Rabe & Staats), FlashAttention.
- For Striped Attention: Ring Attention with contiguous token assignment.
Evaluation metrics.
- Maximum supported context length (tokens) before out-of-memory.
- Training throughput in tokens/second or in MFU (Model FLOPS Utilization).
- Wall-clock end-to-end speedup.
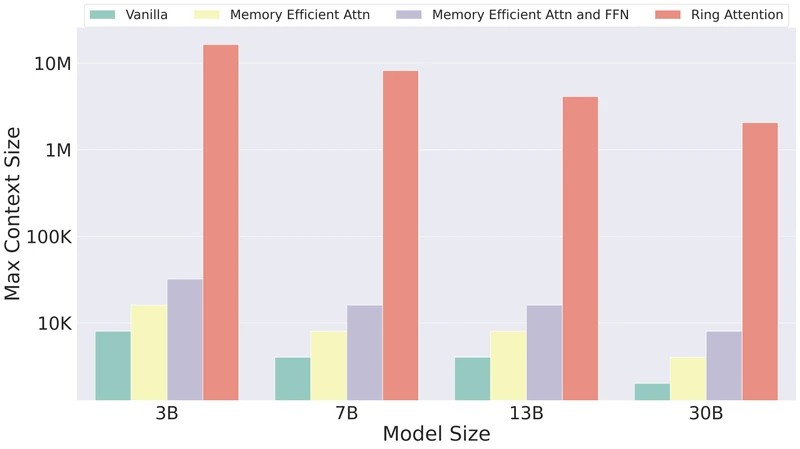
Key quantitative results (Ring Attention). From the paper: at 32× A100 with a 7B model, maximum trainable sequence length reaches 4M tokens; at TPUv4-1024 with a 65B model, maximum sequence length reaches 8M tokens. Compared to FlashAttention on single device, the maximum context length improvement scales roughly with device count (“up to device count times longer than those achievable by prior memory-efficient Transformers, without resorting to approximations or incurring additional communication and computation overheads”). 1
Key quantitative results (Striped Attention). From the paper: at 256K sequence length, 8x A100 80GB, 1.41×–1.45× end-to-end training-step throughput over Ring Attention; at 786K sequence length, 16-chip TPUv4, 1.65× speedup; per-model speedups are roughly constant across 1B, 3B, and 7B model sizes (1.39×–1.65×). 2
Ablations. Ring Attention’s ablations vary block size , ring topology vs all-gather, and FlashAttention-vs-memory-efficient inner kernel. The block-size ablation directly demonstrates the overlap condition: below the threshold, throughput collapses; at and above, throughput plateaus. 1
Hyperparameter sensitivity. [Analysis] The dominant sensitivity is the block size and its interaction with the device’s . Practitioners must re-tune when porting to new hardware.
Robustness / stress tests. Ring Attention demonstrates training at 100M+ token contexts as an existence proof. 1 No model-quality results are reported at the extreme contexts, at that scale the question is “does it run” rather than “does it train well”, and the paper’s claim is the former.
Qualitative results. Ring Attention’s RL experiments on ExoRL show modest improvements (average return 113.66 vs 111.13 baseline) when long action sequences are processed without truncation, [Analysis] these are not the headline result; the headline is the systems claim, not the modelling claim. 1
Experimental scope limits. [Analysis] Neither paper performs a million-token model-quality evaluation. The needle-in-haystack-style retrieval benchmarks that quantify whether a model uses long context effectively (rather than merely fits the long context) appear in the Gemini 1.5 technical report 7 and in independent benchmarks (e.g., RULER, BABILong), not in the Ring or Striped Attention papers themselves.
Independent benchmark cross-checks for SOTA claims. Ring Attention does not claim modelling SOTA; it claims a systems property (linear-memory exact distributed attention). The systems claim has been independently reproduced in open-source implementations (the JAX reference, the PyTorch ports in Megatron-LM, the integration in Hugging Face Transformers as sequence_parallel), and the technique is the basis for the long-context training infrastructure publicly described by Anthropic, Google DeepMind, and several open-source labs. [Analysis] The Gemini 1.5 technical report does not name Ring Attention specifically, but the architectural claim, “near-perfect recall on long-context retrieval tasks at 10M tokens” 7 , is consistent with a sequence-parallel distributed attention plus a strong long-context training mixture. [Reviewer Perspective] The specific attention algorithm Google uses is undisclosed; attributing Gemini’s million-token context window to any single public paper would over-claim. What can be said is that the class of techniques is the one Ring and Striped Attention define.
Evidence audit:
- Strongly supported claims: linear-per-device memory, exactness, communication-computation overlap (Ring Attention); 1.4×–1.65× speedup over Ring Attention on causal training (Striped Attention).
- Partially supported claims: scaling to 100M tokens is demonstrated as an existence proof at small batch sizes; whether such contexts are useful for downstream tasks is not investigated by these papers.
- Claims relying on narrow evidence: the cluster-level efficiency at very large (1,024-chip TPU pods) is reported for a single hardware generation; [Analysis] the inequality must be re-checked for newer hardware.
Section 10: Technical novelty summary
| Component | Type | Novelty level | Justification | Source |
|---|---|---|---|---|
| Ring topology for KV rotation | Combination novel | Reuses ring-allreduce pattern with a different reduction operation (online-softmax instead of sum) | Ring Attention §3 1 | |
| Overlap inequality | Fully novel | First explicit derivation of the block-size threshold | Ring Attention §3 1 | |
| Per-layer 6bch memory accounting | Fully novel | First paper to make the per-device memory bill an explicit function of block size and accumulator state | Ring Attention Table 1 1 | |
| Online softmax inner kernel | Adopted | Inherits from FlashAttention / Rabe & Staats | Ring Attention §2 1 | |
| Causal-mask imbalance characterisation | Fully novel | First paper to identify and quantify the triangular workload imbalance under Ring Attention | Striped Attention §2.2 2 | |
| Round-robin token permutation | Fully novel | The one-line fix; permutation + modified per-tile causal mask | Striped Attention §3 2 |
Single most novel contribution. [Analysis] Ring Attention’s most novel contribution is the explicit overlap inequality together with the per-layer memory accounting that shows the per-device memory bill is independent of . Together they convert what looked like an asymptotic claim (linear in sequence length) into a concrete engineering recipe (pick at or above the hardware’s FLOPS-to-bandwidth ratio, and the algorithm just works). Striped Attention’s most novel contribution is the one-line permutation that lifts the cluster’s causal-training throughput by 1.4× without changing any other part of the stack.
What the papers do NOT claim to be novel. The online softmax algorithm; FlashAttention’s per-tile kernel; the ring-allreduce pattern itself; standard transformer architecture; mixed-precision training; any specific position-encoding scheme.
Section 11: Situating the work
Prior work. The two direct ancestors are FlashAttention (Dao et al., 2022) 3 and memory-efficient attention (Rabe & Staats, 2021). 5 Both reduce per-device memory; neither distributes across devices. FlashAttention-2 4 improves the parallelism inside a single device but stops there. The distributed-attention literature pre-Ring includes Megatron-LM’s tensor-parallel attention (which shards across heads, not sequence) and sequence-parallel variants in DeepSpeed; none of those preserve exactness with linear-in- memory the way Ring Attention does.
What this paper changes conceptually. Before Ring Attention, “very long context” meant “approximate attention or hope the model can extrapolate.” After Ring Attention, it means “add more devices to the ring.” The architectural ceiling moved from “what fits on the biggest single device” to “what the cluster can hold in aggregate.” That is a discontinuous change for the systems-design conversation.
Contemporaneous related papers. [External comparison]
- DeepSpeed-Ulysses (Jacobs et al., 2023). A sequence-parallel attention scheme that uses all-to-all collectives across heads, complementary to (and combinable with) Ring Attention. [Analysis] Different trade-off: Ulysses has lower communication volume but requires re-sharding by head dimension; Ring Attention has higher communication volume but keeps the head dimension untouched.
- BlockwiseParallelTransformer / BPT (Liu & Abbeel, 2023). Same author group as Ring Attention; introduces the blockwise feed-forward computation that Ring Attention’s per-device FFN inherits. [Analysis] Ring Attention is BPT’s sequence-parallel sibling.
- FlashAttention-3 (Shah et al., 2024). H100-targeted single-device kernel that doubles down on overlapping softmax-and-GEMM. [Analysis] Composes with Ring Attention as the inner kernel; the outer ring loop is unchanged.
[Reviewer Perspective] Strongest skeptical objection. The communication-computation overlap inequality is presented as a clean condition, but on heterogeneous clusters (mixed-precision links, mixed GPU generations, network jitter under contention) the effective is significantly lower than the headline number, and the inequality must be checked with the worst-case link bandwidth on the ring. In production clusters this often means has to be larger than the paper’s analysis suggests, which raises the per-device memory bill and shrinks the maximum achievable at a given . The paper acknowledges the threshold but does not quantify the slack practitioners should leave for jitter.
[Reviewer Perspective] Strongest author-side rebuttal grounded in the paper. The block-size threshold is a necessary condition for overlap, not a tight one; practitioners pick generously above the threshold (4,096 or 8,192 tokens at production scale, which is 8×–16× the A100’s of roughly 520). The headroom absorbs jitter in practice. The reference implementation’s defaults reflect this.
What remains unsolved.
- Heterogeneous-cluster awareness: Ring Attention assumes uniform and across devices; real clusters are not uniform.
- Inference-time KV-cache rotation: the algorithms target training; production inference systems use different sharding strategies for decode.
- Interaction with mixture-of-experts: Ring Attention is silent on how to combine sequence-parallel attention with sparse-expert routing. [External comparison] Gemini 1.5 is publicly described as a sparse-MoE model with multimillion-token context; 7 the public papers do not jointly specify the integration.
Three future research directions.
- Topology-aware ring scheduling. When the inter-device topology is not a simple ring (e.g., 3D torus on TPU, dragonfly on supercomputers), the ring traversal can be reordered to use the higher-bandwidth links preferentially. [Analysis] Likely already done inside vendor systems but not publicly documented.
- Ring Attention for causal-with-windowing attention patterns. Sliding-window attention (used in Mistral, some Llama variants) has a different masking structure than dense causal; the Striped Attention permutation does not directly carry over.
- Asynchronous ring rotation. The current algorithm is synchronous (every device waits for the slowest per iteration). An asynchronous variant that hides stragglers behind useful work on the rest of the ring is an open systems-research direction.
Section 12: Critical analysis
Strengths with concrete evidence.
- The Ring Attention overlap inequality is empirically validated: From the paper: block-size sweep ablations show throughput plateau at and above the predicted threshold. 1
- The memory accounting is empirically validated: From the paper: 100M-token sequence training is demonstrated as an existence proof, which requires the per-device memory bill to be linear in . 1
- Striped Attention’s speedup is consistent across hardware (A100 + TPUv4) and model sizes (1B–7B), 1.4×–1.65×. 2
Weaknesses stated by the authors.
- Ring Attention: communication-computation overlap depends on cluster topology; degraded on slow interconnects. 1
- Striped Attention: the speedup is bounded by the tile-skipping granularity of the inner kernel; From the paper: at very small per-device block sizes, the speedup shrinks because fewer whole tiles can be skipped. 2
Weaknesses not stated or understated.
- [Reviewer Perspective] Ring Attention’s analysis is for a single attention layer in isolation; full-model training also incurs activation-checkpointing decisions, pipeline-parallel bubbles, and optimiser-state sharding that interact with the per-device memory bill. The 6bch number is necessary but not sufficient to predict end-to-end memory headroom.
- [Reviewer Perspective] Both papers underspecify the inference (decode) regime. The cited speedups are training-throughput; the decode-time memory and latency trade-offs are different and not addressed.
- [Analysis] Open-source implementations of Ring Attention (Megatron-LM’s sequence-parallel mode, Hugging Face’s experimental support, the JAX reference) have diverged in their default block sizes and online-softmax precision; the reproducibility of the headline numbers depends on which implementation is used.
Reproducibility check.
| Artefact | Ring Attention | Striped Attention |
|---|---|---|
| Code | Released — JAX reference at github.com/lhao499/RingAttention 8 | Released — JAX implementation at github.com/exists-forall/striped_attention 9 |
| Data | Not packaged with code (uses standard long-context corpora) | Throughput benchmarks reproducible without specific data |
| Hyperparameters | Reported in paper appendices | Reported |
| Compute | Reported (32× A100, TPU v4-1024) | Reported (8× A100, 16-chip TPUv4) |
| Trained model weights | Not released (the papers train for research demonstrations, not for distribution) | Not released |
| Evaluation set | Released benchmarks are standard | Standard |
| Overall | Fully reproducible at the systems level; modelling reproductions require independent corpus selection | Fully reproducible |
Methodology
- Sample size: throughput measurements averaged over multiple training steps; no human-evaluation sample-size concern (the metrics are throughput and memory, not quality).
- Evaluation set: training corpus is mixed long-context (books, code, scientific papers); not benchmarked on long-context retrieval (RULER, BABILong) within these papers.
- Baselines: vanilla attention, memory-efficient attention, FlashAttention (Ring); Ring Attention with contiguous assignment (Striped).
- Hardware/compute: 32× A100 80GB / TPU v4-1024 / TPU v5e-256 (Ring); 8× A100 80GB / 4-chip + 16-chip TPU v3/v4 (Striped). Fully reported.
Generalisability.
- To other domains: both algorithms generalise immediately to any domain that uses transformer attention, vision (ViT), audio, multimodal, provided the attention pattern is dense or has a structured mask the permutation can balance.
- To larger scales: the algorithms have been scaled up to 1,024 TPUv4 chips in the original paper; further scaling depends on the topology’s bisection bandwidth.
- To different backbones: both algorithms are attention-only; they compose with any FFN, any normalisation, any position encoding.
Assumption audit.
- The inequality assumption holds on current hardware with practical block sizes. Realistic.
- Homogeneous-cluster assumption: fragile in mixed-hardware setups.
- Synchronous ring assumption: fragile under network jitter; mitigated by generous block sizes.
What would make the papers significantly stronger.
- [Analysis] Ring Attention would benefit from an explicit treatment of inference-time decode latency.
- [Analysis] Both papers would benefit from a model-quality evaluation at the extreme contexts they enable (10M+ tokens).
- [Analysis] Striped Attention would benefit from extending the permutation analysis to non-fully-causal masks (sliding-window, prefix-LM, mixture-of-modalities).
Section 13: What is reusable for a new study
REUSABLE COMPONENT 1: The ring topology + online-softmax kernel
- What it is: the synchronous N-iteration ring with overlap-aware send/recv plus the online-softmax merge inside each tile.
- Why worth reusing: this is the substrate. Any long-context distributed attention is some variant of this.
- Preconditions: a cluster topology with ring traversal support; uniform and ; .
- What would need to change in a different setting: heterogeneous-cluster awareness, async-rotation hooks, non-dense mask patterns.
- Risks: stalling on slow links; numerical instability if accumulators are kept in fp16.
- Interaction effects: composes with tensor-parallel and pipeline-parallel layouts cleanly when those operate on the head and layer dimensions respectively.
REUSABLE COMPONENT 2: The overlap inequality
- What it is: the block-size design rule.
- Why worth reusing: tells you whether your cluster will benefit from Ring Attention, before you build anything.
- Preconditions: knowing your hardware’s and .
- What would need to change: nothing, the inequality is hardware-agnostic.
- Risks: under-counting effective on contention-prone clusters.
REUSABLE COMPONENT 3: The Striped Attention permutation
- What it is: round-robin token-to-device assignment with the matching per-tile mask.
- Why worth reusing: lifts ~1.4× training throughput on causal models, single line change to ingestion.
- Preconditions: causal attention pattern; existing Ring Attention implementation to layer the permutation on top of.
- What would need to change: for non-causal masks, the permutation may be unnecessary or differently shaped.
- Risks: tile-granularity ceiling, the speedup shrinks if the inner kernel cannot skip masked tiles at sufficient granularity.
Dependency map. Ring Attention is the substrate; Striped Attention is a layered permutation; both depend on FlashAttention as the inner kernel; FlashAttention depends on online softmax; online softmax depends on the standard softmax formula. Read in dependency order: standard softmax → online softmax → FlashAttention → Ring Attention → Striped Attention.
Recommendation. [Analysis] The highest-value reusable component is the combination of the inequality with the 6bch memory formula. Together they let a practitioner answer “given my cluster and my target sequence length, is Ring Attention feasible, and what block size do I need?” before writing a single line of code. The permutation from Striped Attention is the easy second win, applied on top.
[Analysis] A new study most benefits from these techniques when: (a) sequence length exceeds single-device memory; (b) the attention pattern is dense or structured-causal; (c) the cluster topology supports ring traversal with adequate . For sub-million-token contexts on a single device, single-device FlashAttention is sufficient and Ring Attention adds complexity without benefit.
Section 14: Known limitations and open problems
Limitations explicitly stated by the authors.
- Ring Attention: throughput depends on being satisfied; insufficient bandwidth degrades the overlap. 1
- Ring Attention: heterogeneous-cluster behaviour not characterised. 1
- Striped Attention: tile-granularity ceiling on the speedup; small block sizes leave throughput on the table. 2
- Striped Attention: experiments are at 256K–786K token scale; behaviour at 10M+ tokens not directly measured. 2
Limitations not stated.
- [Analysis] Inference-time decode behaviour underspecified in both papers.
- [Analysis] Interaction with mixture-of-experts routing is silent in both papers; [External comparison] the public Gemini 1.5 architecture is MoE with multimillion-token context but the joint integration is not publicly specified. 7
- [Reviewer Perspective] Both papers benchmark on relatively small models (≤ 7B for the headline numbers in Striped Attention, ≤ 65B in Ring Attention); production deployment at 100B+ parameters is plausible but not directly demonstrated.
- [Reviewer Perspective] Numerical-precision behaviour at extreme sequence lengths (10M+ tokens with fp16 partial sums) deserves more attention; the online-softmax state is robust in fp32 but not all production stacks keep it there.
Technical root cause of each.
- Decode underspecification: the papers target training throughput, which is compute-bound. Decode is bandwidth-bound, a different regime.
- MoE silence: the routing function operates per-token, complicating sequence-parallel sharding when tokens of different experts land on different devices.
- Numerical-precision: the partial-sum accumulators have a precision cost that grows with the number of merges.
Open problems left behind.
- Topology-aware ring scheduling.
- Sequence-parallel attention for sliding-window / mixture-mask patterns.
- Asynchronous ring rotation under stragglers.
- Joint optimisation of sequence parallelism, tensor parallelism, pipeline parallelism, and expert parallelism for trillion-parameter MoE long-context models.
What a follow-up paper would need to solve. The most critical limitation for the practitioner audience is the gap between “training works at 10M tokens” and “the model uses 10M tokens well.” A follow-up that combined Ring/Striped Attention with a long-context modelling evaluation (RULER, BABILong, or a new benchmark) at extreme contexts on a frontier model would close the most important loop. [Reviewer Perspective] The Gemini 1.5 technical report is the closest public approximation of this combined claim, but its attention algorithm is undisclosed; an open replication of the joint systems-and-modelling claim is the obvious next paper.
How this article reads at three depths
For the curious high-school reader. A transformer reads its input by having every word look at every other word, which would be impossible if the input had a million words because the bookkeeping would not fit on any one chip. Ring Attention solves this by passing the words around a circle of chips, each chip doing its share, so the total memory needed on any one chip stays small. Striped Attention is a small tweak that fixes a fairness problem in the original method when the model is learning to predict the next word.
For the working developer or ML engineer. Ring Attention is the reference distributed exact-attention algorithm for sequences too long to fit in a single device’s HBM. The key design rule is the block-size inequality , choose your per-device block size at or above the FLOPS-to-bandwidth ratio and communication overlaps compute. The per-device memory bill is bytes per layer, linear in block size, independent of total sequence length. Striped Attention is a token-permutation patch on top that lifts causal-training throughput by 1.4×–1.65×. The reference implementations are public JAX code; production stacks (Megatron-LM, DeepSpeed, vLLM) integrate variants. Use Ring Attention when sequence length exceeds single-device memory; use Striped Attention when training causal language models; use FlashAttention as the inner kernel either way.
For the ML researcher. Ring Attention is exact, sequence-parallel, per-device memory, and communication-compute-overlapping when . The novelty is the explicit overlap derivation and the per-layer memory accounting; the substrate is ring-allreduce repurposed as a streaming online-softmax aggregation. Striped Attention identifies and quantifies a triangular workload imbalance specific to causal masking under contiguous token assignment, and fixes it with a round-robin permutation. The strongest objections are (1) underspecified inference-time behaviour, (2) silence on MoE integration despite the production relevance, and (3) numerical-precision behaviour at extreme sequence lengths. A follow-up paper closing the systems-and-modelling loop (Ring/Striped Attention + long-context modelling evaluation at 10M tokens) would be the obvious next step; the Gemini 1.5 technical report is the closest public approximation of that joint claim but does not disclose its attention algorithm.
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. Liu, Zaharia, Abbeel — Ring Attention with Blockwise Transformers for Near-Infinite Context (arXiv:2310.01889, October 2023; v4 November 2023). (accessed ) ↩
- 2. Brandon, Nrusimha, Qian, Ankner, Jin, Song, Ragan-Kelley — Striped Attention: Faster Ring Attention for Causal Transformers (arXiv:2311.09431, November 2023). (accessed ) ↩
- 3. Dao, Fu, Ermon, Rudra, Ré — FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness (arXiv:2205.14135). (accessed ) ↩
- 4. Dao — FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning (arXiv:2307.08691). (accessed ) ↩
- 5. Rabe, Staats — Self-attention Does Not Need O(n^2) Memory (arXiv:2112.05682). (accessed ) ↩
- 6. Milakov, Gimelshein — Online Normalizer Calculation for Softmax (arXiv:1805.02867). (accessed ) ↩
- 7. Gemini Team Google — Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context (arXiv:2403.05530, March 2024; v5 December 2024). (accessed ) ↩
- 8. Ring Attention reference implementation — Liu et al. GitHub repository (JAX). (accessed ) ↩
- 9. Striped Attention reference implementation — Brandon et al. GitHub repository. (accessed ) ↩
- 10. Patarasuk, Yuan — Bandwidth Optimal All-reduce Algorithms for Clusters of Workstations (the ring-allreduce paper). (accessed ) ↩
Anonymous · no cookies set