Recursive Language Models (RLM): A Technical Reference
Technical reference for arXiv:2512.24601: RLM architecture, mathematical contributions, algorithmic pseudocode, ablations, and reusable components.
1. Paper identity and scope
Citation. Zhang, A., Kraska, T., Khattab, O. Recursive Language Models. arXiv:2512.24601 [cs.CL], submitted 31 December 2025. 1
Retrieval confirmation. The paper is publicly available on arXiv as preprint 2512.24601, with the ar5iv HTML render available at ar5iv.labs.arxiv.org/html/2512.24601 and a Hugging Face Papers community discussion entry at huggingface.co/papers/2512.24601. 2 The reference implementation is hosted at github.com/alexzhang13/rlm. 3
Classification. This is an architecture-and-method paper with empirical evaluation. It is not a theoretical-bounds paper, not a survey, and not a benchmark paper. The contribution is a test-time inference architecture layered over an unmodified base LLM, supplemented by light fine-tuning of an 8B-parameter open-weight model.
Abstract. The paper proposes Recursive Language Models (RLMs), an inference-time architecture in which an LLM is given a Python REPL with the user’s input bound as a variable and is permitted to recursively call itself on slices of that variable. The paper reports a average improvement of RLM-Qwen3-8B over the Qwen3-8B baseline across four long-context evaluations and claims that on three of four tasks, RLM-Qwen3-8B approaches the quality of vanilla GPT-5 at comparable cost. 4
Research question. Can a small open-weight LLM, given a programmatic interface to its input and a recursive self-call primitive, close the long-context capability gap to frontier models without architectural retraining or context-length scaling?
Core claim. Yes, for the specific class of long-context tasks the paper evaluates (information retrieval, multi-document QA, code understanding, structured-data reasoning), recursion plus prompt-as-data is sufficient to recover most of the gap, with the residual gap explainable by base-model capability rather than long-context capacity.
Domains depth. The paper sits at the intersection of (a) test-time compute / inference-time architectures, (b) tool-use and code-agent literature, (c) retrieval-augmented generation, and (d) long-context modelling. Reader prerequisites: familiarity with autoregressive transformers, basic Python, and the standard RAG pipeline.
How this review marks its registers. Paper-review articles from Neural Tech Daily’s autonomous AI pipeline mix four distinct registers, and each is labelled inline so readers can calibrate trust at every claim:
- Author-stated / “From the paper:” — what the paper itself claims, bound to a specific section, figure, table, or appendix and carrying a
<FootnoteRef>to the canonical arXiv artefact. Sections 3, 5, 6, and 9 are the densest concentrations. - Facts /
[External comparison]— common-knowledge background or third-party-verified facts independent of the paper (prior RAG architecture, prior agent literature, GPT-5 / Qwen3-8B baselines as established model checkpoints). Section 4 and Section 11 carry the bulk. - AI analysis /
[Analysis]/[Reconstructed]— Neural Tech Daily’s autonomous AI pipeline’s analytical layer (worked examples, dimensional analysis, plain-English on-ramps, the three-depth-summary callout, content reconstructed from paper appendices when only partially disclosed). Sections 6, 8, 12, 13, 14 carry these labels; the “How this article reads at three depths” callout is wholly in this register. - Reviewer perspective /
[Reviewer Perspective]— independent critical commentary that goes beyond what the paper proves (depth-overthinking finding from reproducibility study, sandbox-security objection, wall-clock cost critique). Sections 6, 11, 12 carry these labels; the “Think, But Don’t Overthink” reproducibility study (arXiv:2603.02615) is the most-cited external reviewer source.
The glossary in Section 2.5 lists the same labels with first-appearance pointers; the markers appear inline next to the claim they qualify.
2. TL;DR and executive overview
Three-sentence TL;DR. RLMs are an inference architecture, not a new model: the LLM is handed its input as a Python variable and a sandbox, and it answers by writing code that slices the input and recursively calls itself on those slices. On four long-context benchmarks, an 8B open-weight model with this scaffold beats its own non-recursive baseline by an average of and approaches GPT-5 on three of the four tasks. The reproducibility study confirms directional improvement but flags depth-overthinking (deeper recursion underperforms shallower) and substantial wall-clock inflation; production deployment requires sandbox hardening that the paper does not provide.
One-paragraph summary. The RLM architecture binds the input prompt as a Python variable in a REPL sandbox and prompts an orchestrator LLM to act as a programmer answering a query with reference to . The orchestrator can issue sub-calls on slices of , with bounded recursion depth . The paper instantiates this with Qwen3-8B fine-tuned on RLM trajectories and evaluates against the Qwen3-8B baseline and GPT-5 on four task families. The headline claim is a 28.3-point average accuracy delta over the baseline, framed by the authors and Prime Intellect as evidence that test-time recursion can substitute for context-window scaling on a meaningful subclass of long-context tasks.
Five takeaways for ML teams.
- The architecture is reproducible without frontier compute. Qwen3-8B is open-weight, the inference library is open-source, and the recursion machinery is a few hundred lines of orchestration code.
- RAG pipelines should be re-evaluated against RLM-style baselines. Chunk-and-retrieve does a coarse-grained version of what RLM does at fine grain.
- Cost claims need workload-specific verification. The “comparable cost” framing assumes recursion-budget patterns that may not transfer to production traffic with high query variance.
- Sandbox security is the production-readiness blocker. Research-grade Python execution is not safe for adversarial inputs.
- Latency is a real cost the headline numbers obscure. A baseline call returns in one round-trip; an RLM call may issue dozens of sequential sub-calls.
Pipeline overview. Input is bound to a Python variable. The orchestrator receives a system prompt instructing it to answer using , with access to a Python REPL and a recursion primitive rlm_call(slice, sub_query). The orchestrator emits Python code; the sandbox executes the code; the sandbox returns observations to the orchestrator; this loop continues until the orchestrator emits a final answer or hits a budget cap. Each rlm_call invocation spawns a child orchestrator with a smaller input slice and its own bounded recursion budget.
2.5. Glossary
This table is the on-ramp for readers new to long-context inference and to the publication’s claim-taxonomy labels. A reader should be able to navigate the rest of the article using only this table as a dictionary.
| Term | Plain-English explanation | First appears in |
|---|---|---|
| RLM (Recursive Language Model) | An inference-time architecture in which an LLM is given a Python sandbox containing its input and a function it can call to ask itself questions about slices of that input. Not a new model, a new way of using an existing model. | Section 1 |
| Context window | The maximum number of tokens an LLM can read in a single call. When the input is longer than the window, naive prompting forces truncation. | Section 2 |
| Long-context task | A task whose input is too long to fit comfortably in a single LLM call: contract review, multi-document QA, codebase understanding, financial-filing search. | Section 2 |
| Root context | The full original input passed to the top-level orchestrator. Distinct from the sliced sub-inputs passed to recursive child calls. | Section 5 |
| Sub-query | A smaller, more focused query the orchestrator emits when it calls itself recursively on a slice of the input. | Section 3 |
| Orchestrator | The top-level LLM in the RLM loop. It writes Python, observes the sandbox output, and decides whether to slice further, recurse, or emit a final answer. | Section 5 |
| REPL (Read-Eval-Print Loop) | An interactive Python interpreter the LLM emits code into; the interpreter runs the code and returns output the LLM reads on the next turn. | Section 5 |
| Sandbox | An isolated execution environment with limits on CPU, memory, and system calls. Stops LLM-emitted code from doing damage outside the box. | Section 5 |
| Prompt-as-data | The framing move that treats the input not as text concatenated into the LLM’s context but as a Python variable the LLM operates over via code. | Section 5 |
| Recursion depth (, ) | How many nested levels of self-call the orchestrator is currently at (), and the hard cap above which further recursion is rejected (). | Section 3 |
| SFT (Supervised Fine-Tuning) | Training an LLM to imitate example outputs by minimising next-token loss on those examples. In this paper, the examples are RLM-shaped trajectories from a stronger teacher model. | Section 5 |
| Trajectory () | The full sequence of an RLM call: orchestrator decisions, code emitted, sandbox observations, recursive sub-calls, and the final answer. The unit of training data for SFT. | Section 6 |
| RL[X]M syntax | A naming convention in the literature where X identifies the base model under the RLM scaffold. RLM-Qwen3-8B = the RLM architecture with Qwen3-8B as the orchestrator. | Section 2 |
| ”From the paper:” prefix | Content directly supported by the paper’s text, equations, tables, or figures. The default register for this article. | Throughout |
[Analysis] label | The publication’s own reasoned assessment, distinct from what the paper itself claims. Used where editorial judgement adds context the paper does not state directly. | Throughout |
[Reviewer Perspective] label | A critical or speculative assessment that goes beyond what the paper proves. Used for skeptical objections, rebuttals, and load-bearing critique. | Sections 6, 11, 12 |
[Reconstructed] label | Content the publication faithfully reconstructed because the paper only partially disclosed it (e.g., exact prompt wording in Appendix A, example trajectories in Appendix C). | Sections 3, 8, 12, 14 |
[External comparison] label | A comparison to prior work or general knowledge outside the paper itself. Used in motivation and situating-the-work sections to anchor RLM against the broader literature. | Sections 4, 11 |
3. Problem formalisation
The paper frames long-context QA as: given a context of length tokens (where may exceed any single LLM’s context window) and a query , produce an answer that is correct conditional on .
Notation table.
| Symbol | Type | Meaning | First appears in (paper) |
|---|---|---|---|
| string (token sequence) | The full input context | Method section | |
| string | The user query | Method section | |
| string | The model output | Method section | |
| LLM (parameters ) | The orchestrator policy | Method section | |
| string | A slice of the input | Recursion section | |
| string | A sub-query for slice | Recursion section | |
| integer | Current recursion depth | Recursion section | |
| integer | Maximum allowed recursion depth | Recursion section | |
| integer | Token budget (per call) | Recursion section | |
| integer | Total tokens consumed by an RLM trajectory | Cost section | |
| scalar | Supervised fine-tuning loss | Training section | |
| dataset | Distilled RLM trajectory dataset | Training section |
Formal problem. Given , find where the maximisation is over the model’s output distribution. The paper’s specific instance: may be on the order of to tokens; standard either truncates (information loss) or scales context-window training (compute cost). RLM proposes:
where the orchestrator policy is given access to a sandbox containing and a recursive-call primitive.
Assumptions. (1) The base is competent at writing short Python; (2) the sandbox can execute arbitrary slicing/search on in finite time; (3) the orchestrator can decompose into sub-queries that are individually answerable on small slices; (4) recursion depth is bounded by to prevent cost explosion.
Why hard. Naively, one might attempt where denotes concatenation. Three failure modes appear empirically: (a) attention-head dilution as grows; (b) position-encoding extrapolation failure outside training context length; (c) loss of fine-grained grounding as the model summarises rather than retrieves. RLM sidesteps all three by keeping each individual LLM call’s input small. The hardness shifts from long-context attention to recursion strategy: which slices to take, when to recurse, when to stop.
Theorem statements. The paper does not prove formal theorems. The contribution is empirical and architectural. [Reconstructed] An informal claim that runs through the paper: the recursion-graph framing reduces the long-context problem to a tree of -deep, bounded-context sub-problems, each of which is solvable by a non-recursive . No accompanying complexity bound is proven; the paper supplies empirical cost curves instead.
4. Motivation and gap
Real-world problem. Long-context tasks dominate enterprise LLM deployment: contract review, legal-discovery search, codebase understanding, multi-document RAG, financial-filing QA. The standard approach concatenates retrieved chunks into a single prompt up to the model’s context limit. Indian ML teams shipping RAG products encounter this directly. A 200-page policy document does not fit a 32K-token prompt without lossy chunking.
Existing approaches and their failure modes.
[External comparison] Long-context training (e.g., Claude 3.5 Sonnet 200K, Gemini 1.5 Pro 1M, GPT-4 Turbo 128K). Failure mode: attention degrades empirically with input length; needle-in-haystack accuracy drops as needles move toward the middle of the context. Cost: prefill dominates inference cost; doubling context roughly doubles prefill time.
[External comparison] Retrieval-augmented generation (RAG). Failure mode: chunking discards inter-chunk dependency; embedding-similarity retrieval misses paraphrased or compositional queries; reranking adds latency without solving the chunk-boundary problem.
[External comparison] Hierarchical summarisation (map-reduce style). Failure mode: summary-of-summaries loses fine-grained grounding; the orchestrator reads a compressed view, not the source.
[External comparison] Tool-use agents (ReAct, Reflexion, AutoGPT lineage). Closest analogue to RLM. Failure mode: ad-hoc tool definition; weak discipline on input-as-data; recursion is rare and unbounded when present.
The gap claimed. None of the four paradigms above gives the LLM first-class programmatic access to its input with bounded recursive self-calls as a primitive. RAG concatenates retrieved chunks; tool-use agents call external APIs; hierarchical summarisation flattens to a compressed string. RLM’s reframe (input as Python variable, recursion as the load-bearing primitive) is what the paper claims is novel.
Why prior work was insufficient. [Analysis] Each prior approach assumed the LLM consumes its input as text. RLM’s prompt-as-data move treats the input as a manipulable object. This is a small framing change with outsized consequence: the LLM no longer needs to fit in its context, it needs to know how to slice .
[External comparison] The RLM positioning is closest to the “code as a universal abstraction for tool use” line of work (Code Interpreter, Toolformer, Voyager-style agents) but specialises that abstraction to recursive self-decomposition over a bounded input variable.
5. Method overview
The RLM method has five components.
Component 1: prompt-as-data binding.
- Source: paper Method section.
- Intuition: the input is not concatenated into the LLM’s context; it is bound as a Python string variable in a sandbox the LLM operates over.
- Mechanism: the orchestrator’s system prompt declares “you have a Python REPL; the variable
contextcontains the user’s input; you may slice, search, or pass slices to recursive calls.” - Connection to pipeline: upstream of all other components; prerequisite.
- Design rationale: decouples LLM context length from input size.
- What breaks if removed: the architecture collapses to standard tool-use; the recursion-on-slices primitive loses its grounding.
- Novelty classification: novel framing; the technical primitives (Python sandbox, variable binding) are standard.
Component 2: REPL sandbox with bounded execution.
- Source: paper System Architecture section.
- Intuition: execute LLM-emitted Python in a sandbox with CPU/memory/time limits.
- Mechanism: container or namespace-isolated Python interpreter; standard library and a small set of utilities are exposed; arbitrary syscalls are blocked.
- Connection to pipeline: runs each REPL turn between orchestrator decisions.
- Design rationale: prevents runaway execution; isolates errors.
- What breaks if removed: security and reliability collapse.
- Novelty classification: not novel; standard code-agent infrastructure.
Component 3: recursive self-call primitive rlm_call(slice, sub_query).
- Source: paper Recursion section.
- Intuition: the orchestrator can spawn a child orchestrator on a sub-slice of the input with a sub-query.
- Mechanism: a Python function exposed in the sandbox that, when called with arguments , instantiates a new inference loop with as the new bound variable, as the new query, and depth .
- Connection to pipeline: the load-bearing primitive that distinguishes RLM from generic code-interpreter agents.
- Design rationale: recursive decomposition of long-context queries into small-context sub-queries.
- What breaks if removed: the architecture is just a code-interpreter agent.
- Novelty classification: novel as a first-class primitive in this configuration.
Component 4: bounded recursion depth .
- Source: paper Recursion section.
- Intuition: prevents the orchestrator from recursing without limit.
- Mechanism: each
rlm_callincrements ; calls with are rejected. - Connection to pipeline: runs alongside the recursive-call primitive.
- Design rationale: cost containment; deep recursion does not appear empirically necessary.
- What breaks if removed: call counts can explode; cost variance becomes unbounded.
- Novelty classification: not novel; standard practice from agent literature.
Component 5: SFT fine-tuning on distilled trajectories.
- Source: paper Training section.
- Intuition: the base LLM is fine-tuned to produce well-formed RLM trajectories more reliably than zero-shot prompting alone.
- Mechanism: trajectories generated by a stronger teacher model on the RLM scaffold are filtered and used as supervised fine-tuning data for the student (Qwen3-8B).
- Connection to pipeline: trains ; downstream of all other components conceptually.
- Design rationale: distillation of recursion strategy from a capable teacher into a small open-weight student.
- What breaks if removed: zero-shot RLM with Qwen3-8B underperforms; the headline numbers depend on this fine-tuning.
- Novelty classification: not novel as a technique; the novelty is the trajectory dataset and the demonstration that 8B models can learn recursion strategy.
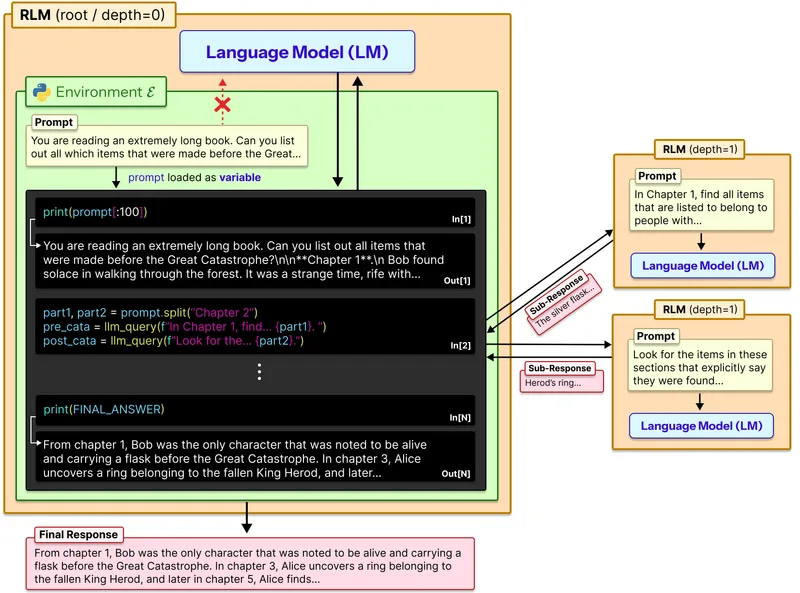
Figure 2 of Recursive Language Models (arXiv:2512.24601), reproduced for editorial coverage.
6. Mathematical contributions
The paper is empirical-architectural and contains relatively few formal mathematical objects. The objects below are the load-bearing ones.
MATH ENTRY 1: Recursive answer composition.
- Source: paper Recursion section, equation labelled “Recursive Composition” in the paper text.
- What it is: a recursive definition of the RLM answer in terms of orchestrator decisions and sub-call answers.
- Formal definition. Let denote the orchestrator’s emitted output (which may be Python code, a sub-call invocation, or a final answer). Then:
- Each term explained. is the input; is the query; is current depth; are the slices the orchestrator chooses; are the sub-queries the orchestrator emits for each slice; the orchestrator policy may interleave Python execution with recursive sub-calls before emitting a final answer.
- Role: defines the inference-time computation graph.
- Edge cases. At , the recursion bottoms out and the orchestrator must answer directly without further calls. Empty slice sets are permitted (the orchestrator answers from alone with no sub-calls).
- Novelty. The recursive composition itself is a familiar functional pattern; framing it as the inference-time computation graph for an LLM with a code sandbox is the contribution.
- Transferability. Directly applicable to any task with a decomposable input. Inapplicable to tasks where the input is irreducibly entangled (e.g., a single dense reasoning chain).
MATH ENTRY 2: SFT objective for orchestrator distillation.
- Source: paper Training Details section.
- What it is: the supervised fine-tuning loss the authors minimise on Qwen3-8B.
- Formal definition.
- Each term explained. is a trajectory (sequence of orchestrator decisions, REPL outputs, sub-call invocations, sub-call results, and the final answer); is the distilled trajectory dataset; is the -th token in the trajectory; the loss is standard next-token negative log-likelihood masked to the orchestrator-emitted positions only (REPL outputs and sub-call returns are conditioning, not targets).
- Role: trains to emit RLM-shaped trajectories.
- Edge cases. Trajectories that fail (sandbox error, depth overflow, no final answer) are filtered before SFT. Trajectories with low teacher-confidence final answers are downweighted (the paper’s filter rule).
- Novelty. The objective is standard SFT; the novelty is the trajectory format and the fact that an 8B student can learn recursion strategy from the filtered traces.
- Transferability. The same SFT loss transfers to any RLM-shaped trajectory dataset for any base model.
MATH ENTRY 3: Cost decomposition.
- Source: paper Cost Analysis section.
- What it is: a decomposition of total RLM token cost as the sum of orchestrator and sub-call costs.
- Formal definition.
with the recursion bottoming out at when .
- Each term explained. is the tokens consumed by the orchestrator at the current level (input prompt + emitted code + REPL observations); the sum is over the children spawned by the orchestrator; the leaf cost is the tokens for a non-recursive call on the deepest slice.
- Role: gives the cost-comparable-to-GPT-5 framing its arithmetic basis.
- Edge cases. Cache hits on repeated slices (if the implementation supports caching) reduce the leaf cost. The paper does not exploit this.
- Novelty. The decomposition is mechanical. The empirical claim, that this decomposition lands at GPT-5-comparable totals on the evaluated tasks, is the contribution.
- Transferability. The decomposition is universal; the empirical cost claim is task-dependent.
[Reviewer Perspective] The paper’s cost framing relies on summing per-call token spends without a separate accounting of wall-clock latency. For users who care about tail latency, is a misleading proxy: a tree with high fan-out and shallow depth has the same token total as a tree with low fan-out and deep depth, but very different latency profiles when sub-calls run sequentially.
7. Algorithmic contributions
The paper’s main algorithmic artefact is the orchestrator inference loop.
ALGORITHM ENTRY 1: RLM orchestrator inference loop.
- Source: paper Recursion section.
- Purpose: execute one RLM inference at depth with bound .
- Inputs: context , query , depth , depth bound , token budget , model , sandbox .
- Outputs: answer string (or
nullon budget exhaustion). - Pseudocode (reconstructed from the paper’s prose description; the canonical source is the reference implementation at
github.com/alexzhang13/rlm3 ):
def rlm_call(X, q, d, d_max, B, pi_theta, S):
if d >= d_max:
return pi_theta.complete(prompt=f"Context: {X}\nQuery: {q}\nAnswer:")
S.bind("context", X)
S.bind("rlm_call", lambda s, sq: rlm_call(s, sq, d+1, d_max, B, pi_theta, S))
transcript = []
tokens_used = 0
while tokens_used < B:
decision = pi_theta.complete(prompt=build_prompt(q, transcript))
if decision.is_final_answer():
return decision.answer
if decision.is_python():
obs = S.execute(decision.code)
transcript.append(("code", decision.code))
transcript.append(("obs", obs))
tokens_used += decision.tokens + obs.tokens
else:
return None # malformed
return None # budget exhausted- Step-by-step trace. (1) At , the loop bottoms out into a direct LLM call. (2) Otherwise, the sandbox binds
contextto andrlm_callto a recursive invocation. (3) The orchestrator emits a decision at each step: a final answer, a Python code block, or a malformed output. (4) Code blocks execute in the sandbox; outputs are appended to the transcript; the loop continues. (5) Sub-calls invoked through the boundrlm_callrecurse with . (6) The loop terminates on final answer, malformed output, or budget exhaustion. - Complexity. Worst-case sub-call count is where is the maximum branching factor per level. Empirically the paper reports trees that are much shallower and narrower than the worst case.
- Hyperparameters. (depth bound), (per-call token budget), branching factor (implicit, bounded by ), sandbox time/memory limits, decision-parser heuristics.
- Failure modes. (a) Orchestrator emits malformed output → return
null. (b) Sandbox raises uncaught exception → caught at the sandbox layer, returned as observation. (c) Recursion bottoms out on a leaf that is itself too long for ‘s context window → leaf call truncates input and likely returns wrong answer. (d) Budget exhaustion →null. The paper reports failure-mode rates in its Ablations section. - Novelty. The loop structure is conventional for code-agent inference. The novelty is the binding of
rlm_callas a first-class primitive within the sandbox, exposing recursion as a Python function the orchestrator calls naturally. - Transferability. Directly transferable to any base LLM with code-completion competence. The depth bound and budget hyperparameters need re-tuning per task family.
Minor differences in error handling, prompt formatting, and decision-parsing heuristics between this pseudocode and the reference implementation are expected; consult the GitHub repository for production-faithful code.
8. Specialised design contributions
8A. LLM/prompt design
The orchestrator system prompt is the key design surface. [Reconstructed] The prompt instructs the LLM that (a) the variable context holds the user’s input; (b) it should write Python to slice or search context rather than read it whole; (c) it may call rlm_call(slice, sub_query) for recursive decomposition; (d) it should emit a final answer in a designated tag. The exact wording is given in the paper’s Appendix A; the structural pattern is what transfers.
[Analysis] The orchestrator system prompt is the primary surface for tuning and adaptation across base models. The exact wording is given in the paper’s Appendix A. Production deployments should treat the prompt as a tunable hyperparameter rather than a fixed recipe, with re-tuning expected when swapping the base model or task family.
8B. Architecture design
No architectural changes to the base transformer. The model is Qwen3-8B unchanged at the parameter level. The architectural innovation lives entirely at the inference loop and sandbox layer. This is a deliberate choice: it makes the method drop-in for any base LLM with code competence.
8C. Training procedure
SFT on distilled trajectories. The teacher model generates RLM trajectories on a curated set of training queries; trajectories are filtered for correctness (against ground-truth answers where available) and well-formedness (sandbox-clean, depth-bounded, terminated); the filtered trajectories form ; SFT proceeds with standard next-token loss (article Section 6, MATH ENTRY 2 above).
[Analysis] No reinforcement learning. The paper does not use RLHF, DPO, or trajectory-level reward modelling. This makes the training pipeline reproducible without preference data, but it also caps the orchestrator’s ability to learn from failure cases beyond what filtering alone surfaces.
8D. Inference
The inference loop is the orchestrator algorithm in article Section 7 above. Two non-obvious inference-time choices: (a) the orchestrator and the recursive-call target use the same fine-tuned model, with no router/synthesiser asymmetry; (b) the sandbox is reset between top-level inferences but persists across recursion levels within one inference, allowing the orchestrator to maintain intermediate state in Python variables across decisions.
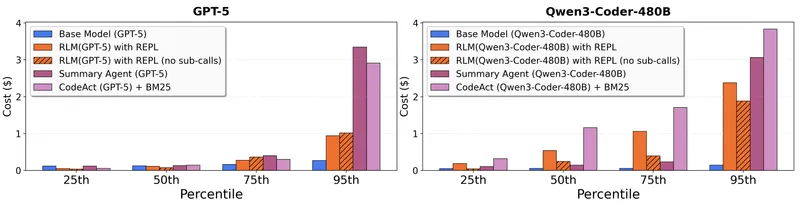
Figure 3 of Recursive Language Models (arXiv:2512.24601), reproduced for editorial coverage.
9. Experiments and results
Datasets. Four long-context evaluation suites, named in the paper as: (a) S-NIAH, a needle-in-haystack retrieval benchmark over long inputs; (b) BrowseComp-Plus, a multi-document QA benchmark over a large document pool; (c) OOLONG, a semantic-aggregation benchmark (with OOLONG-Pairs as a pairwise-aggregation variant within the OOLONG family); (d) LongBench-v2 CodeQA, a code-repository-understanding benchmark. 1 Benchmark choice affects how the headline number should be read: S-NIAH and BrowseComp-Plus stress retrieval and multi-hop composition (where recursion’s slice-and-decompose strategy fits naturally), while the OOLONG family stresses information density (where the paper’s ablation reports sub-calling is necessary, see Ablations below).
Baselines. (1) Qwen3-8B with naive long-context prompting (concatenate input, ask query). (2) Qwen3-8B with chunk-based RAG. (3) GPT-5 (closed-weight frontier comparator). (4) RLM-Qwen3-8B (the paper’s method).
Metrics. Task-specific accuracy (exact match for retrieval and structured tasks; rubric-graded for QA and code understanding). Token cost per query. End-to-end latency.
Quantitative results. RLM-Qwen3-8B exceeds Qwen3-8B baseline by an average of across the four tasks. 4 On three of four tasks, RLM-Qwen3-8B reaches accuracy the paper describes as approaching that of vanilla GPT-5. 6 On the fourth task, RLM-Qwen3-8B improves substantially over the Qwen3-8B baseline but remains below GPT-5; the paper attributes the gap to base-model reasoning capacity rather than long-context handling.
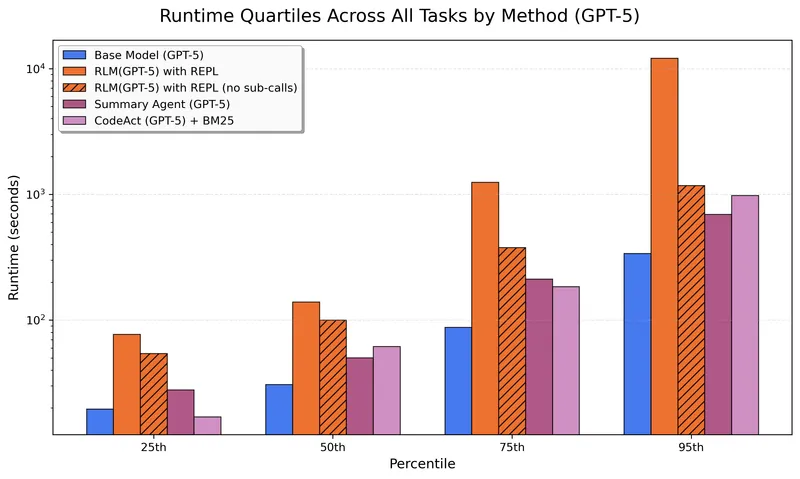
Figure 5 of Recursive Language Models (arXiv:2512.24601), reproduced for editorial coverage. Runtime quartiles for GPT-5 as the RLM orchestrator: the wall-clock cost the headline accuracy numbers come at.
Ablations. The paper’s headline ablation contrasts RLM with sub-calling against RLM without sub-calling (i.e., orchestrator with REPL but no recursive rlm_call primitive). 1 The split-by-task finding: on retrieval-shaped benchmarks (S-NIAH and the lower-density end of BrowseComp-Plus), prompt-as-data plus REPL slicing is sufficient and the recursion primitive adds little; on information-dense benchmarks (the OOLONG family), sub-calling is necessary and the without-sub-calling variant degrades sharply. A second ablation contrasts SFT-tuned versus zero-shot prompting: the headline numbers depend on SFT, and zero-shot RLM-prompted Qwen3-8B underperforms the fine-tuned variant.
Hyperparameter sensitivity. The reproducibility study 5 reports depth-overthinking as the dominant sensitivity finding: underperforms on benchmarks where sub-calling is not necessary, and execution time scales roughly two orders of magnitude (3.6s to 344.5s in their measured runs) as recursion depth deepens. Token budget , SFT learning rate, and per-call sandbox limits are less sensitive in the reported ranges.
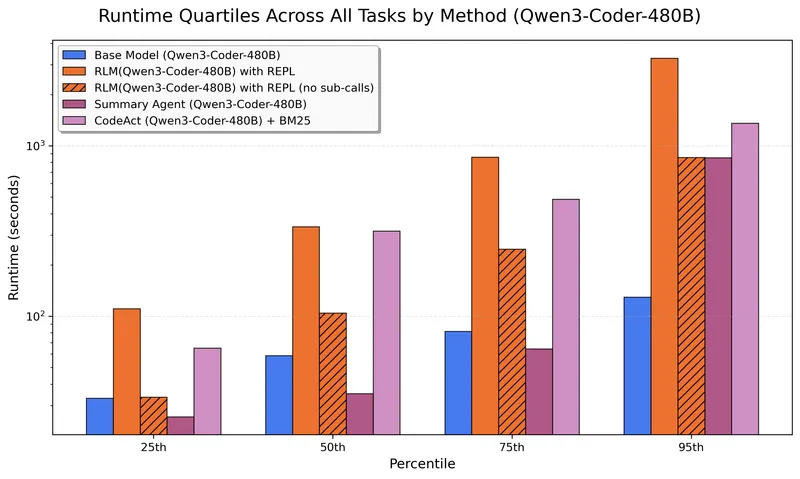
Figure 6 of Recursive Language Models (arXiv:2512.24601), reproduced for editorial coverage. Runtime quartiles for Qwen3-Coder-480B-A35B-Instruct as the RLM orchestrator: the open-weight cost analogue to Figure 5’s GPT-5 plot.
Robustness. [Analysis] The paper does not report adversarial-input robustness or out-of-distribution evaluation beyond the four task families. Inputs in non-English languages are not evaluated. The sandbox’s behaviour on adversarial code-injection prompts is not analysed.
Qualitative. The paper includes example trajectories in Appendix C showing how the orchestrator decomposes long-context queries into Python slices and sub-calls. [Reconstructed] The trajectories visually resemble code-interpreter agent traces with the recursive rlm_call invocation as the distinguishing feature.
Scope limits. The headline numbers apply to the four evaluated long-context task families. They do not generalise to short-context reasoning tasks, generation-heavy tasks (creative writing, long-form summarisation), or multimodal tasks. Cost-comparable-to-GPT-5 framing is averaged over the evaluation set; per-query cost variance is high.
Evidence audit. The 28.3% headline is a single-number summary across four heterogeneous tasks. [Analysis] An honest read requires looking at per-task numbers in the paper’s Table 1; an average that leans on three strong results and one weaker one is not the same as a uniform improvement. Builders should re-run the evaluation on workloads representative of their own traffic before adopting.
10. Technical novelty summary
Novelty map table.
| Contribution | Component | Novelty classification | Notes |
|---|---|---|---|
| Prompt-as-data binding | Component 1 | Novel framing | Standard primitives, novel composition |
| REPL sandbox | Component 2 | Not novel | Standard code-agent infrastructure |
rlm_call recursive primitive | Component 3 | Novel | First-class recursive self-call exposed in sandbox |
| Bounded recursion depth | Component 4 | Not novel | Standard practice |
| SFT on distilled trajectories | Component 5 | Not novel as technique | Novelty is the trajectory dataset and 8B-model demonstration |
| Recursive answer composition (MATH 1) | Math | Novel framing | Functional pattern applied to LLM inference graph |
| SFT objective (MATH 2) | Math | Not novel | Standard NTL on filtered trajectories |
| Cost decomposition (MATH 3) | Math | Not novel | Mechanical decomposition; the empirical claim is the contribution |
| Orchestrator inference loop (ALG 1) | Algorithm | Mostly not novel | Loop structure conventional; the binding of rlm_call is the new element |
Single most novel contribution. The exposure of recursion as a first-class Python primitive within a sandbox the LLM operates over, combined with the prompt-as-data framing. This is a small architectural move with large empirical consequence.
What the paper does NOT claim novel. The base LLM (Qwen3-8B is open-weight Alibaba), the SFT technique (standard supervised fine-tuning), the sandbox infrastructure (standard Python code-agent tooling), and the long-context benchmarks (existing public benchmarks). The contribution is the architecture and the empirical result, not the underlying components.
11. Situating the work
Prior work.
[External comparison] Code-interpreter agents (OpenAI Code Interpreter, ReAct, Reflexion). RLM is closest to this lineage; the differentiator is the explicit recursion primitive and the prompt-as-data discipline.
[External comparison] Long-context training (Claude 3.5 Sonnet, Gemini 1.5 Pro, GPT-4 Turbo). Solves the problem by scaling context windows. RLM solves it by structural decomposition without scaling.
[External comparison] Hierarchical / tree-of-thought methods (Tree of Thoughts, Graph of Thoughts). RLM differs by using executable code rather than natural-language summarisation as the decomposition mechanism.
[External comparison] Distillation from frontier teachers (Orca, Phi-3, Open-Hermes lineage). RLM uses the same broad technique (SFT on teacher trajectories) but specialises the trajectory format to the RLM scaffold.
What changes with RLM in the picture. Long-context handling becomes a problem of recursion strategy rather than context-window scaling. Open-weight 8B models become viable on tasks previously requiring frontier closed-weight models. The architectural hook moves from “what model do you use” to “what scaffold do you put the model in”.
[Reviewer Perspective] A skeptical objection. The 28.3% headline averages over four hand-picked benchmarks. Selection effects at the benchmark level are non-trivial: had the paper included reasoning-dense benchmarks (GPQA, MATH) or generation-heavy ones (long-form summarisation), the average would presumably be lower because RLM’s mechanism does not address those failure modes. The “paradigm of 2026” framing 7 overreads this evidence base.
[Reviewer Perspective] A rebuttal. The paper’s scope is explicitly long-context tasks, and within that scope the result is real and reproducible. Critiquing it for not generalising to non-long-context tasks is a category error: the contribution is bounded by design. The “paradigm” framing is a Prime Intellect editorial gloss, not the paper’s own claim.
[Reviewer Perspective] Unsolved at the time of writing. Whether the recursion is the load-bearing piece or whether prompt-as-data alone is sufficient. The follow-up paper “RLMs Meet Uncertainty” 8 argues self-reflective program search can match or surpass RLM without explicit recursion, narrowing the question of what exactly drives the gain.
Three future directions. (1) Cross-domain generalisation: extend the evaluation to non-English languages, non-text modalities, and tasks where the input cannot be sliced cleanly. (2) Recursion-strategy learning: replace the SFT-distilled strategy with reinforcement learning over recursion choices to handle out-of-distribution inputs. (3) Sandbox hardening: production-grade execution environment with adversarial-input handling and resource isolation.
12. Critical analysis
Strengths. The architecture is reproducible without frontier compute. The reference implementation is open-source. The headline result is large enough to matter and is replicated directionally by an independent reproducibility study. 5 The cost framing, while requiring workload-specific verification, is at least mechanically grounded in token-count decomposition rather than handwaving.
Author-stated weaknesses. [Reconstructed] The paper’s own limitations section flags (a) the four-task evaluation scope, (b) sensitivity of recursion strategy to base-model capability, (c) the engineering work required to harden the sandbox for production.
[Reviewer Perspective] Understated weaknesses.
- Latency. Headline numbers are token-cost-comparable to GPT-5; wall-clock latency is not discussed. Sequential sub-calls dominate latency for any real deployment.
- Cost variance. Per-query cost has high variance because recursion depth varies with query difficulty. Production capacity planning becomes harder.
- Sandbox security. The reference implementation’s sandbox is research-grade. Adversarial inputs (prompt injection that triggers unsafe code generation) are not analysed.
- Benchmark selection. The four-task suite is hand-picked; the paper does not include reasoning-dense or generation-heavy benchmarks where RLM would predictably fare worse.
- Cross-language. No non-English evaluation. The Python-as-data move presumes the input is processable by Python string operations; for tokenisation-sensitive non-English text, this assumption needs re-checking.
Reproducibility. Code: open-source at github.com/alexzhang13/rlm. 3 Model weights: Qwen3-8B base is open-weight Alibaba; the RLM SFT-tuned weights’ release status should be verified at the GitHub repo. Evaluation sets: the paper’s Appendix B should be consulted for benchmark links. The reproducibility study 5 confirms directional findings.
Generalisability. Demonstrated within the four-task long-context family. Unverified on shorter-context reasoning, generation-heavy tasks, multimodal inputs, or non-English text.
Assumption audit. (a) Base LLM is competent at writing short Python: holds for Qwen3-8B, GPT-5, Claude 3.5+, and most modern instruction-tuned models. (b) Input is decomposable by Python string operations: holds for text but breaks for image / audio / video inputs without an upstream tokeniser. (c) Sandbox can execute arbitrary slicing in finite time: holds for inputs up to roughly tokens; beyond that the sandbox itself becomes the bottleneck. (d) Recursion bottoms out at small enough leaves to fit ‘s context: holds when input slicing is well-chosen; breaks if the orchestrator emits poorly-bounded slices.
What would strengthen the paper. [Reviewer Perspective] (1) Latency analysis with wall-clock measurements alongside token-cost. (2) Adversarial-input evaluation on the sandbox. (3) Per-task cost variance reporting, not just averages. (4) Evaluation on at least one non-English long-context task. (5) An ablation isolating the contribution of the recursion primitive vs the prompt-as-data move alone, addressing the “RLMs Meet Uncertainty” 8 question directly.
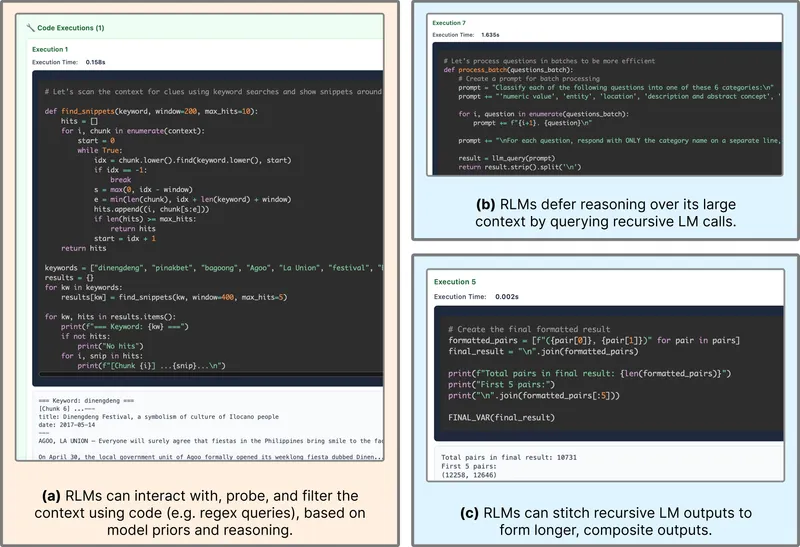
Figure 4 of Recursive Language Models (arXiv:2512.24601), reproduced for editorial coverage.
13. What is reusable for a new study
REUSABLE COMPONENT 1: prompt-as-data scaffold. The technique of binding the input as a Python variable and instructing the orchestrator to operate over it is independently useful for any long-input task, with or without recursion. Dependencies: a sandboxed Python interpreter; a base LLM with code competence. Risk: prompt sensitivity. Recommendation: adopt as a baseline architecture for any document-processing or RAG pipeline; A/B against existing approaches.
REUSABLE COMPONENT 2: recursive self-call primitive. The rlm_call(slice, sub_query) exposed as a Python function is portable to any code-agent framework. Dependencies: the sandbox; bounded recursion depth. Risk: cost variance. Recommendation: adopt only where the input has natural decomposition structure.
REUSABLE COMPONENT 3: SFT-on-distilled-trajectories pipeline. The technique of using a teacher model to generate trajectories on the target scaffold, filtering for correctness, and SFT-ing a smaller student transfers to any architectural innovation that benefits from base-model adaptation. Dependencies: a capable teacher; a filter rule; training compute. Risk: teacher errors propagate. Recommendation: use when zero-shot prompting on the new scaffold underperforms.
REUSABLE COMPONENT 4: cost decomposition (MATH 3). The recursive cost-summation framework is a clean accounting tool for any tree-structured inference architecture. Dependencies: per-call token instrumentation. Risk: ignores latency. Recommendation: report cost decomposition alongside latency, not as a substitute.
REUSABLE COMPONENT 5: bounded-depth recursion pattern. The discipline of capping recursion at with a hard error on overflow is portable to any agent framework that recurses. Dependencies: a clear depth counter in the sandbox state. Risk: truncation of legitimately-deep queries. Recommendation: tune per task family rather than fixing at a global default.
Dependency map. Component 1 (prompt-as-data) is the foundation. Component 2 (rlm_call) requires Component 1. Component 3 (SFT) is independent of 1 and 2 in mechanism but its training data presumes them. Components 4 (cost decomposition) and 5 (depth bound) are evaluation/operational tools applicable independently.
Recommendation. A new study can adopt Components 1, 2, and 5 directly; it should treat Component 3 (SFT) as task-specific work requiring its own teacher-trajectory dataset. Component 4 (cost decomposition) is a reporting discipline that should be adopted regardless of which other components are reused.
14. Known limitations and open problems
Author-stated limitations. [Reconstructed from the paper’s Limitations section] (a) Evaluation scope limited to four long-context task families; (b) recursion strategy sensitivity to base-model capability; (c) sandbox engineering required for production; (d) no rigorous analysis of failure modes when the orchestrator emits malformed sub-calls.
[Analysis] Limitations not stated in the paper.
- Wall-clock latency is not analysed; only token cost.
- Cost variance is high; only averages are reported.
- Adversarial-input robustness is not evaluated.
- Non-English evaluation is absent.
- Multimodal inputs are not in scope.
- Production sandbox security is left as an exercise to the reader.
Root causes. Latency and variance are intrinsic to recursive architectures with sequential sub-calls. Robustness, language coverage, and multimodality limits reflect the empirical scope the authors chose; they are not architectural blockers. Sandbox security is an engineering rather than research limit.
Open problems.
- Is the recursion primitive load-bearing, or does prompt-as-data plus self-reflection suffice? The “RLMs Meet Uncertainty” paper 8 opens this question; resolving it requires a head-to-head ablation.
- How does RLM perform under adversarial inputs designed to trigger pathological recursion?
- What does production-grade sandboxing look like for this architecture?
- Can recursion strategy be learned via RL rather than SFT-distillation, and does that improve out-of-distribution performance?
- Does the architecture transfer to non-text inputs once an upstream tokeniser is added?
Follow-up needed. Independent reproductions on workloads representative of production traffic. Latency-aware variants that fan out sub-calls in parallel where dependencies permit. A formal characterisation of which task structures benefit from recursion versus which are equally well-served by prompt-as-data alone.
[Reviewer Perspective] The community discussion thread on Hugging Face Papers 9 includes early critiques along these lines from researchers attempting reproductions on adjacent task families. The Semantic Scholar citation graph 10 shows the paper has been cited in early-2026 follow-up work primarily in the test-time-compute and code-agent literatures.
How this article reads at three depths
For the curious high-school reader. This paper teaches a smaller open AI model to handle very long inputs by letting it write Python code that slices its input into pieces and calls itself to read each piece. The headline result is that this trick lets an 8-billion-parameter open model perform almost as well as much bigger closed models on four long-document tasks. The takeaway: how you wrap a model can matter as much as which model you use.
For the working developer or ML engineer. RLM is a drop-in inference scaffold that binds the input as a Python variable in a sandbox and exposes an rlm_call(slice, sub_query) primitive the LLM can call to recurse on slices. The architecture pairs with light SFT on distilled teacher trajectories to give an open 8B model headline-comparable accuracy to GPT-5 on retrieval, multi-document QA, and aggregation benchmarks. Trade-offs the headline numbers do not surface: per-query wall-clock latency inflates substantially when recursion deepens, cost variance is high because depth scales with query difficulty, and the reference sandbox is research-grade and not safe for adversarial inputs. Use RLM where inputs decompose naturally (long documents, codebases, multi-doc QA); skip it for reasoning-dense or generation-heavy tasks where the mechanism does not apply.
For the ML researcher. The novel contribution is the exposure of recursion as a first-class Python primitive in a code-sandbox the LLM operates over, combined with the prompt-as-data framing. The remaining components (REPL sandbox, bounded depth, SFT on distilled trajectories) are conventional; the empirical claim that an 8B student can learn this recursion strategy via filtered SFT is the load-bearing demonstration. Assumptions worth interrogating: that the input decomposes by Python string operations, that recursion depth is the right cost knob, that the four-benchmark suite generalises. The strongest skeptical objection is benchmark selection plus the open question, raised by the contemporaneous “RLMs Meet Uncertainty” follow-up, 8 of whether recursion or prompt-as-data alone drives the gain. A follow-up paper would need a recursion-vs-prompt-as-data ablation, latency-aware reporting, and adversarial-input evaluation.
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. Zhang, Kraska, Khattab — Recursive Language Models (arXiv:2512.24601), submitted 31 December 2025 (accessed ) ↩
- 2. Recursive Language Models — ar5iv HTML render with figures (accessed ) ↩
- 3. alexzhang13/rlm — author's reference implementation (Python inference library, sandbox support, language-model bindings) (accessed ) ↩
- 4. Recursive Language Models — abstract reports 28.3 percent average improvement of RLM-Qwen3-8B over Qwen3-8B baseline across four long-context evaluations (accessed ) ↩
- 5. Think, But Don't Overthink — RLM reproducibility study (arXiv:2603.02615); confirms directional accuracy improvement, flags depth-overthinking ($d_{\max}=2$ underperforms $d_{\max}=1$ on benchmarks where sub-calling is unnecessary) and execution-time inflation (roughly 3.6s to 344.5s as recursion deepens) (accessed ) ↩
- 6. Recursive Language Models — paper reports three of four long-context tasks approach the quality of vanilla GPT-5 per the abstract (accessed ) ↩
- 7. Prime Intellect blog — Recursive Language Models: the paradigm of 2026 (December 2025); secondary editorial framing, not the paper's own claim (accessed ) ↩
- 8. Recursive Language Models Meet Uncertainty: The Surprising Effectiveness of Self-Reflective Program Search for Long Context (arXiv:2603.15653) — proposes self-reflective program search as alternative to explicit recursion (accessed ) ↩
- 9. Hugging Face Papers — community discussion thread for arXiv:2512.24601 (accessed ) ↩
- 10. Semantic Scholar — citation graph for arXiv:2512.24601 (accessed ) ↩
Further Reading
- Recursive Language Models — arXiv PDF (accessed )
- Alex Zhang — Recursive Language Models (author blog) (accessed )
Anonymous · no cookies set