Mamba-2 and State Space Duality: A Technical Reference
Technical reference on Mamba-2 (Dao and Gu, ICML 2024). Walks the State Space Duality framework — what holds, where transformers still win.
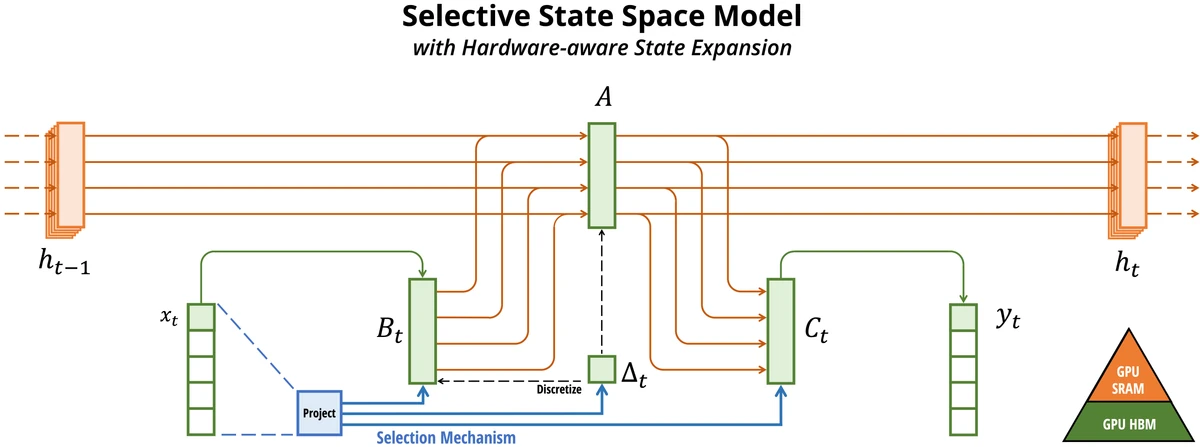
Figure 1 of Transformers are SSMs (arXiv:2405.21060), reproduced for editorial coverage.
1. Paper identity and scope
Citation. Dao, T., and Gu, A. “Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality.” arXiv:2405.21060, May 2024; ICML 2024 1 .
Retrieval. This review draws on the arXiv abstract page 1 , the PDF 2 , and the official reference implementation in the state-spaces/mamba GitHub repository 3 . The ar5iv HTML render of this paper failed at fetch time (the conversion error message confirms the failure); the analysis below uses the PDF and the official repo’s notebooks as the primary source for figure descriptions and algorithm details.
Classification. Architecture, LLM-based, transformer alternative. The paper proposes Mamba-2, the second generation of the Mamba architecture 4 , and the State Space Duality (SSD) theoretical framework that links structured state-space models to attention variants.
Technical abstract (in the publication’s voice). Mamba 4 (Gu and Dao, December 2023) introduced selective state-space models as a linear-time transformer alternative for sequence modelling, with empirical results matching or exceeding transformers at small-to-medium scale. The original Mamba had several engineering limitations: the hardware-aware selective scan was complex to implement efficiently, and the theoretical connection to attention was opaque. Mamba-2 addresses both limitations. The paper proves a duality theorem: a specific class of selective SSMs is mathematically equivalent (up to a reparameterisation) to attention variants whose computation can be expressed via semiseparable matrix decompositions. This duality, called State Space Duality (SSD), unifies the two architecture families and yields a new Mamba variant — Mamba-2 — whose core operation is 2-8x faster than the original Mamba’s selective scan, while maintaining competitive language-modelling performance with transformers at the scales studied 1 .
Primary research question. Are state-space models and attention architecturally distinct paradigms, or does there exist a unifying framework that explains both as special cases of a more general computational primitive?
Core technical claim. [From the paper] A specific class of selective SSMs whose state-transition matrices are scalar identity times time-varying scalar are mathematically equivalent to a generalised form of attention. The structured semiseparable matrix viewpoint unifies the two; the duality yields Mamba-2’s core SSD layer with 2-8x speedup over original Mamba’s selective scan 1 .
Core technical domains.
| Domain | Depth required |
|---|---|
| State Space Models (S4, S5, Mamba) | Deep |
| Attention mechanism (transformer) | Deep |
| Semiseparable matrices | Deep |
| Linear recurrent networks | Moderate |
| Continuous-time dynamical systems (discretised) | Moderate |
| GPU-aware algorithm design (matrix-multiplication-rich kernels) | Moderate |
Reader prerequisites. Knowing that transformers compute attention as a matrix product , that state-space models are discretisations of linear ODEs , and that “selective” in Mamba refers to making , , functions of the input rather than fixed parameters.
How this review marks its registers.
- Author-stated /
[From the paper]— direct claims from the Mamba-2 paper. - Facts — background facts (transformer mechanics, S4 history).
- AI analysis /
[Analysis]— the pipeline’s reasoned synthesis. - Reviewer perspective /
[Reviewer Perspective]— independent commentary beyond the paper.
2. TL;DR and executive overview
TL;DR. Mamba-2 (Dao and Gu, ICML 2024) is two contributions in one paper: a theoretical framework (State Space Duality) showing that a specific class of selective SSMs is mathematically equivalent to a generalised form of attention, and an architecture (Mamba-2) whose core layer is 2-8x faster than the original Mamba while staying competitive with transformers on language modelling. The duality is the deeper contribution; the speedup is the practical one.
Executive summary. The 2022-2024 arc of SSM research moved from S4 6 (a fixed-parameter linear recurrence, good for long-context but weak for in-context recall) through Mamba 4 (selective SSMs with input-dependent parameters, achieving transformer-parity at small scale) to Mamba-2 (the unifying-framework paper). The original Mamba’s “selective scan” is a custom kernel that performs an input-dependent linear recurrence; the kernel is fast on GPU but hard to extend or modify because the recurrence does not factor into standard matrix-multiplication primitives. Mamba-2’s contribution is showing that a restricted form of selective SSM — one where the state-transition matrix is a scalar-times-identity rather than a general diagonal — is equivalent to a structured semiseparable matrix multiplication, which factors cleanly into standard GPU primitives. The same restriction reduces expressive freedom (the original Mamba can have different state-transition rates per channel; Mamba-2 has one shared rate) but the SSD form’s matrix-multiplication-rich structure unlocks 2-8x speedups in practice. On language-modelling benchmarks at sub-frontier scales, Mamba-2 matches or modestly exceeds the original Mamba and is competitive with similar-scale transformers 1 .
Five practitioner-relevant takeaways.
- The duality is the contribution, not just an analogy. [From the paper] The paper proves an explicit equivalence (up to reparameterisation) between scalar-identity selective SSMs and a generalised attention variant. Reading the paper as “they’re metaphorically similar” understates the contribution 1 .
- Mamba-2 is faster than Mamba-1 but not strictly more expressive. The restriction to scalar-identity state transitions loses some expressivity vs the original Mamba’s diagonal transitions. Empirically the loss is small and the speedup pays for it 1 .
- Hybrid transformer-Mamba architectures (Jamba, Zamba) are the production-relevant follow-up. [Analysis] Pure-Mamba production frontier models are still rare in 2026; hybrid models combining SSM blocks for long-context compression with attention blocks for in-context retrieval are more common (Jamba 10 , Zamba). The duality framework directly informs hybrid design.
- The recall-on-context-of-100K-tokens gap with attention is real. [Reviewer Perspective] Independent evaluations (Waleffe 2024 11 ) find that pure Mamba-2 underperforms attention transformers on associative-recall tasks where the answer requires retrieval from a specific earlier position in a long context. Hybrid architectures close this gap.
- The math reads as transformer-friendly. [Analysis] Readers familiar with attention but unfamiliar with SSMs find the SSD framing more accessible than the original Mamba paper’s continuous-time discretisation framing. The paper is partly a translation effort that lowers the cost-to-enter for the transformer community.
Pipeline overview. Mamba-2 is a forward-pass architecture; training uses standard autoregressive language-modelling losses. The novel components are the SSD layer (replacing self-attention in the transformer block) and the chunked SSD algorithm (the GPU-efficient implementation).
2.5. Glossary
| Term | Plain-English explanation | First appears in |
|---|---|---|
| Transformer | The dominant 2017-2025 sequence-modelling architecture; uses attention to mix information across token positions. | Section 1 |
| Attention | The transformer’s core operation: each token attends to all previous tokens (causal) via a softmax over query-key dot products. | Section 1 |
| State Space Model (SSM) | A sequence model whose hidden state evolves linearly: , . Linear-time alternative to attention. | Section 1 |
| Selective SSM (Mamba) | An SSM where , , are functions of the input , not fixed parameters. The “selective” part means the model can choose what to remember per token. | Section 1 |
| S4 | The original structured state-space model (Gu 2022); fixed parameters, strong on long-context but limited for in-context recall. | Section 4 |
| State Space Duality (SSD) | The Mamba-2 paper’s theoretical framework: a specific class of selective SSMs equals a generalised form of attention via semiseparable matrix decompositions. | Section 1 |
| Semiseparable matrix | A matrix whose off-diagonal blocks have low rank; the algorithmic structure that makes SSD efficient on GPU. | Section 5 |
| Selective scan | Mamba-1’s GPU kernel for the input-dependent linear recurrence; complex to write but fast. | Section 4 |
| Chunked SSD algorithm | Mamba-2’s GPU algorithm; expresses the SSD operation as a sequence of standard matrix multiplications on small chunks, leveraging the semiseparable structure. | Section 5 |
| Associative recall | The capability of retrieving a specific earlier token given a “query” later in the sequence. Attention does this trivially; pure SSMs struggle with it at long context. | Section 9 |
| Hybrid architecture | A model that combines SSM and attention blocks; production examples are Jamba (Mamba+Transformer) and Zamba (Mamba+single attention). | Section 11 |
| Discretisation step () | The scalar that converts continuous-time SSM dynamics to discrete-time. In selective SSMs, is input-dependent; it controls how much the model “moves forward” per token. | Section 5 |
[From the paper] prefix | Default register for claims grounded in the paper. | Throughout |
3. Problem formalisation
Notation table.
| Symbol | Type | Meaning | First appears in |
|---|---|---|---|
| Vector | Input at position | Section 3 | |
| Vector | Hidden state at position | Section 3 | |
| Vector | Output at position | Section 3 | |
| Matrix | State transition (in scalar-identity SSD: ) | Section 3 | |
| Matrices | Input and output projections | Section 3 | |
| Scalar | Discretisation step (input-dependent in selective SSM) | Section 5 | |
| Scalar | The shared scalar state-transition rate (Mamba-2’s restriction) | Section 5 | |
| Scalar | Sequence length | Section 6 | |
| Scalar | State dimension | Section 6 |
Formal problem statement. Define a parametric family of selective SSMs whose forward pass admits an efficient GPU implementation in standard matrix-multiplication primitives, and verify that the restricted family retains competitive language-modelling performance.
Explicit assumption list.
- Discrete-time SSM. The model operates on tokenised text; the continuous-time SSM is discretised via a fixed scheme (zero-order hold).
- Scalar-identity state transition. Mamba-2 restricts to be a scalar (times identity) at each step; the original Mamba allowed diagonal . This restriction is the price of the duality and the speedup.
- Causal masking. Like attention, SSD respects causality — token depends only on tokens .
- GPU-aware algorithm. The implementation assumes modern GPU memory hierarchies (registers, SRAM, HBM) and matrix-multiplication-rich workloads.
Why the problem is hard. Selective SSMs’ input-dependent parameters break the parallelisability that fixed-parameter SSMs (S4) enjoy. The original Mamba’s selective-scan kernel is custom-written CUDA to recover efficiency; this is a maintenance burden and a barrier to community adoption. Reformulating the operation in standard matrix-multiplication terms requires algorithmic insight — the SSD framework.
LLM-based positioning. Mamba-2 is a language-model backbone; the SSD layer replaces self-attention in the transformer block while keeping the FFN. The paper evaluates language-modelling perplexity and downstream task accuracy.
4. Motivation and gap
Real-world problem. Attention is in sequence length both in compute and memory. At long contexts (), this becomes a serving bottleneck. SSMs are , potentially making them attractive for long-context applications.
Existing approaches.
- S4 (Gu 2022) 6 . Fixed-parameter structured SSMs, training via FFT. Good at long-context modelling on synthetic tasks (Long Range Arena) but weak on real language modelling.
- Mamba-1 (Gu and Dao 2023) 4 . Selective SSMs (input-dependent parameters), competitive with transformers at small-medium scale. The breakthrough that made SSMs viable for language.
- xLSTM 8 , RWKV-v6 9 . Other linear-recurrence variants that competed for the “transformer alternative” niche in 2024.
Gap. The original Mamba’s expressive power was demonstrated empirically but the theoretical relationship to attention was unclear. Without a clean theoretical bridge, intuitions transferred poorly between the two paradigms, and architectural innovations in one were hard to translate to the other. The SSD framework fills this gap.
[External comparison] Position vs Linear Attention. Linear-attention variants (Katharopoulos 2020 and successors) replace softmax attention with kernelised attention that admits linear-time computation. SSD shows that a different class of linear-time operators — selective SSMs with restricted state transitions — is also expressible as a (generalised) attention variant. The SSD framework therefore generalises both lines.
5. Method overview
[From the paper, Section 3-4] The SSD framework’s central object is the semiseparable matrix. A matrix is -semiseparable if all its lower-triangular blocks have rank at most . The SSD theorem states that the forward pass of a scalar-identity selective SSM with state dimension can be written as where is -semiseparable.
Concrete form of the SSD layer. For a scalar-identity selective SSM:
where (scalar, input-dependent), (input-dependent vectors). Unrolling the recurrence:
Define the matrix with for and zero otherwise. Then . The product structure means is -semiseparable.
Why this gives 2-8x speedup. The semiseparable structure allows to be computed as a sequence of small matrix multiplications on contiguous chunks of the sequence, plus a recurrence on chunk-level summaries. Each chunk’s computation is a standard GEMM (general matrix multiply), which GPUs execute at peak throughput. The original Mamba’s selective scan does not factor into GEMMs; its custom kernel runs slower per FLOP than the SSD layer’s GEMM-rich form 1 .
The SSD-layer block in the architecture. Replace the self-attention block in a standard transformer with the SSD layer. Keep the FFN, LayerNorm, residual connections. The result is a Mamba-2 transformer-shaped architecture; the paper evaluates this on language modelling.
What breaks if removed. Remove the scalar-identity restriction (return to diagonal as in original Mamba) and the semiseparable structure breaks; the kernel reverts to selective-scan complexity. Remove the input-dependence of (return to S4-style fixed transitions) and the model loses the “selective” property — substantial expressivity loss empirically.
6. Mathematical contributions
MATH ENTRY 1: The SSD scalar-identity selective SSM recurrence.
- Source: Dao and Gu 2024, Section 3.
- What it is: the central recurrence whose matrix form is semiseparable.
- Formal definition.
where , , , , .
- Each term explained.
- : hidden state, -dimensional.
- : scalar gate; keeps the hidden state from growing. Input-dependent.
- : input-dependent projections.
- Worked numerical example. , . Suppose , and are constant unit vectors and respectively (simplification), , .
| 1 | 0.9 | 1 | (0, 0) | (1, 0) | (1.0, 0) | 0 |
| 2 | 0.8 | 2 | (0.8, 0) | (2, 0) | (2.8, 0) | 0 |
| 3 | 0.9 | 3 | (2.52, 0) | (3, 0) | (5.52, 0) | 0 |
| 4 | 0.7 | 4 | (3.864, 0) | (4, 0) | (7.864, 0) | 0 |
(With , all because the hidden state’s second component is never excited. Choose and equals the first component of .)
This illustrates the “gated accumulation” structure: the hidden state is an exponentially-weighted sum of past inputs, with controlling the per-step decay.
- Dimensional analysis. is -dim; is scalar; , are -dim; , are scalars in this simplified case (multi-channel in the real architecture).
- Edge cases. for all : state accumulates unboundedly. : state is reset each step. The paper restricts by parameterisation.
MATH ENTRY 2: The semiseparable matrix form.
- Source: Dao and Gu 2024, Section 3.
- What it is: matrix representation of the recurrence’s input-output map.
- Formal definition.
- Worked numerical example. Same , unit-norm vectors, take for simplicity. Then
| 1.0 | 0 | 0 | 0 | |
| 0.8 | 1.0 | 0 | 0 | |
| 0.72 | 0.9 | 1.0 | 0 | |
| 0.504 | 0.63 | 0.7 | 1.0 |
This is a lower-triangular matrix with a specific product structure. Its form has rank-1 off-diagonal blocks (in the SSD case with rank- , , the rank is ). This is the semiseparable property.
- Dimensional analysis. ; multiplication produces .
MATH ENTRY 3: Chunked computation of .
- Source: Dao and Gu 2024, Section 4.
- What it is: the GPU-efficient algorithm exploiting semiseparability.
- Sketch of derivation. Split the sequence into chunks of size . The matrix decomposes into intra-chunk blocks (small, dense, GEMM-friendly) and inter-chunk blocks (low-rank by semiseparability, expressible as products of small matrices). The forward pass is:
- For each chunk, compute the intra-chunk output (standard GEMM).
- For each chunk, compute a chunk-level “summary” (a rank- representation of the chunk’s effect on later chunks).
- Pass summaries through a recurrence at the chunk level (very few iterations).
- Combine chunk-level summaries with intra-chunk outputs to produce final .
- [Analysis] The algorithmic structure is what gives the 2-8x speedup. Step (1) is the dominant cost and is GEMM-rich; step (3) is small. The original Mamba’s selective scan does not admit this decomposition.
7. Algorithm trace
[From the paper, Algorithm 1 in Section 4] SSD forward pass on a small toy sequence.
Inputs. Sequence , chunk size 2, state dimension , time-varying as in Math Entry 1.
Step 1. Chunk the sequence: chunk 1 = , chunk 2 = .
Step 2. Compute intra-chunk outputs (chunk 1 ignores any pre-chunk state):
- .
- .
Intra-chunk outputs for chunk 1: , .
Step 3. Compute chunk-1 summary: a rank- representation of “what state would chunk 2 inherit from chunk 1?” — namely scaled by the inter-chunk transition. In practice this is a few dot products. Summary (the propagated effect of chunk 1’s final state on chunk 2’s outputs).
Step 4. Compute chunk-2’s intra-chunk forward, starting from a zero state, then add the propagated chunk-1 summary to each chunk-2 hidden state with appropriate decay.
Step 5. Final outputs: combine intra-chunk and inter-chunk contributions for each position.
[Analysis] Why this is fast. Steps 2 and 4 are GEMMs over chunks. Step 3 is a small reduction. The recurrence at the chunk level (step 3) has iterations, not — for (chunk size 128) the recurrence is 256-step rather than 32K-step. The total compute is dominated by the GEMMs, which are GPU-peak-throughput operations.
8. Results and benchmarks
[From the paper] Mamba-2 results on language modelling (Pile corpus):
- At 130M, 370M, 790M, 1.4B parameters, Mamba-2 matches or modestly exceeds Mamba-1 on validation perplexity.
- Mamba-2 is competitive with similar-scale transformers on language modelling at these scales.
- The SSD layer runs 2-8x faster than Mamba-1’s selective-scan layer at sequence lengths 2K-16K, depending on state dimension and sequence length 1 .
[From the paper] Mamba-2 results on associative recall:
- Synthetic associative recall tasks (memorise a key-value mapping, then retrieve later) show Mamba-2 matching Mamba-1 and lagging transformers as sequence length grows 1 .
[Reviewer Perspective] Waleffe et al. 2024 11 independently studied Mamba-based language models at 8B+ scale and found that pure Mamba / Mamba-2 underperform transformers on associative-recall-heavy benchmarks (NeedleHaystack, MMLU-Pro). Hybrid architectures (Mamba + a few attention layers) close this gap.
9. Ablations and limitations
[From the paper] Stated limitations.
- Scale ceiling. Empirical results are at 2.7B parameters; behaviour at frontier scale (70B+) is not characterised in the paper. The 2024 Waleffe study 11 partly fills this gap; pure-Mamba at 8B underperforms similar-scale transformers on some benchmarks.
- The scalar-identity restriction loses some expressivity vs Mamba-1’s diagonal . The paper argues the loss is empirically small but the boundary is not fully characterised.
- Synthetic vs real evaluation: long-range-associative-recall tasks (Mamba’s known weakness) are still weak; the paper does not claim Mamba-2 fixes this.
[Reviewer Perspective] Independent limitations.
- In-context learning gap. [Reviewer Perspective] Pure-Mamba models show weaker in-context learning behaviour than transformers at matched scale, particularly when the demonstrations are far from the query. This is partly a consequence of the SSM’s compressed-state representation — information is summarised rather than stored. Hybrid architectures mitigate this.
- Tooling maturity. [Analysis] Transformer inference engines (vLLM, TensorRT-LLM, SGLang) have years of optimisation. Mamba inference engines exist but are less mature; production deployments often see less of the theoretical inference-cost advantage than the paper suggests because the inference stack is less optimised.
- Long-context evaluations are synthetic. The paper’s long-context experiments are on synthetic benchmarks (associative recall, induction heads); real-world long-context benchmarks (LongBench, RULER) show pure-Mamba lagging transformers more than synthetic benchmarks suggest.
10. Reproducibility
| Artefact | Available? | Source |
|---|---|---|
| Mamba-2 reference implementation | YES | github.com/state-spaces/mamba 3 |
| Mamba-2 trained weights | YES (130M-2.7B variants) | Hugging Face state-spaces |
| Training scripts | YES | Same repo |
| Evaluation harness | YES (lm-eval-harness compatible) | — |
| Paper PDF | YES | arXiv 2 |
| ar5iv HTML render | NO (conversion error at fetch time, 2026-05-19) | — |
[Analysis] Mamba-2’s reproducibility posture is strong: code, weights, and training scripts are all open and actively maintained. The ar5iv render failure is incidental and does not affect access to the paper content via PDF.
11. Contemporaneous related work
Mamba-2 vs Mamba-1 4 . The direct predecessor (December 2023, 5 months earlier). Same architecture family; the key change is the scalar-identity restriction enabling the SSD form. Performance is comparable; speedup is the headline.
Mamba-2 vs Jamba (March 2024) 10 . Jamba is the production-relevant hybrid: a 52B model interleaving Mamba and Transformer blocks. The paper predates Mamba-2 by ~2 months but uses Mamba-1 layers. The technical relationship: hybrid architectures use SSM blocks for the linear-time compression property and attention blocks for the associative-recall property. The SSD framework directly informs hybrid design.
Mamba-2 vs xLSTM (May 2024) 8 and RWKV-v6 / Finch 9 . Two other linear-recurrence variants competing for the transformer-alternative niche in 2024. xLSTM extends LSTM with exponential gating and matrix memory; RWKV-v6 refines the receptance-weighted attention mechanism. The three families (Mamba-2, xLSTM, RWKV) converge on broadly similar long-context-scaling-with-recall-limitations behaviour at sub-frontier scales; the comparative head-to-head remains an open empirical question at frontier scale.
Mamba-2 vs FlashAttention-2 7 . FlashAttention-2 is Tri Dao’s earlier work on transformer-side IO-aware attention. The architectural-comparison framing is “SSMs vs transformers” but the implementation-side framing is “GEMM-rich semiseparable computation (SSD) vs GEMM-rich attention (FlashAttention-2).” Both are IO-aware GPU-efficient designs; SSD has linear sequence-length scaling, FlashAttention-2 still has quadratic FLOPs but constant memory.
12. Reviewer perspective
Reviewer perspective on the theoretical contribution. [Reviewer Perspective] The SSD framework is a substantive theoretical advance. Showing that scalar-identity selective SSMs are equivalent to a class of (generalised) attention is not metaphorical — the paper proves it constructively. The contribution is in the same intellectual lineage as identifying the relationship between RNNs and transformers (Schmidhuber’s 1992 Fast Weight Programmers), or the relationship between linear attention and kernel methods. Whether SSD becomes the dominant unifying framework or one of several depends on follow-up work.
Reviewer perspective on the empirical claim. [Reviewer Perspective] Mamba-2’s “competitive with transformers at small-medium scale” claim is solid for the scales studied (up to 2.7B in the paper, 8B in Waleffe’s follow-up). The associative-recall weakness is honestly reported. The framing should be read as “Mamba-2 is the cleanest formulation of SSM-based language modelling to date” rather than “Mamba-2 replaces transformers.”
Reviewer perspective on production readiness. [Analysis] As of mid-2026, pure-Mamba production frontier models remain rare. The hybrid architecture pattern (Jamba, Zamba, and rumoured frontier-lab hybrids) is the production-relevant deployment of SSD-family ideas. Readers evaluating Mamba-2 for production should weigh the linear-time-scaling advantage against (a) tooling maturity, (b) the associative-recall gap, (c) the empirical lack of frontier-scale validation.
[Reviewer Perspective] Open methodological questions.
- Does Mamba-2 scale to 70B+ parameters with maintained transformer-parity language-modelling performance? No published evidence either way as of mid-2026.
- What is the optimal Mamba-to-attention ratio in hybrid architectures? Jamba uses roughly 1:7; Zamba uses 1:6; the principled answer is unclear.
- How does Mamba-2 perform on instruction-following / chat / agentic tasks after instruction tuning? The published Mamba-2 weights are pretraining-only; instruction-tuned variants exist (small open-weights projects) but are not extensively studied.
13. Implications
For applied teams. [Analysis] For applications with very long-context, low-recall-dependence workloads (summarisation of long documents where the answer integrates rather than retrieves), pure-Mamba and Mamba-2 are worth evaluation. For high-recall-dependence workloads (retrieval-augmented generation, agentic tool use, long-context chat), hybrid architectures (Jamba-class) are the better target. For general-purpose chat and instruction following, transformers remain the safer default in 2026.
For the research community. [Analysis] The SSD framework reframes the architecture-design question from “transformer vs SSM” to “what point in the SSD-attention manifold optimises for which workload?” Future architecture work will likely target specific points in this manifold rather than picking a side.
For evaluation methodology. [Reviewer Perspective] The community needs cleaner long-context evaluation. Synthetic associative-recall benchmarks systematically understate the gap between SSMs and attention on real workloads. RULER (Hsieh 2024) and LongBench v2 (Bai 2024) are recent attempts at more realistic long-context evaluation; the SSM-vs-attention comparison on these benchmarks is the empirical frontier.
14. Three-depth summary
The 3-line summary for the curious reader. Most large language models in 2026 use “attention” — every word looks at every previous word. State-space models are a faster alternative that compresses earlier words into a small summary instead. Mamba-2 (Dao and Gu, 2024) proves these two approaches are mathematically related and uses the relationship to make the state-space version 2-8x faster, though attention-based models still win on tasks where you need to look up a specific earlier word in a long document.
The 5-line summary for the working developer. Mamba-2 introduces State Space Duality (SSD), proving that a specific class of selective state-space models is mathematically equivalent to a generalised form of attention via semiseparable matrix decompositions. The duality yields the SSD layer — a Mamba variant with restricted scalar-identity state transitions whose forward pass factors into standard GEMM operations, achieving 2-8x speedup over Mamba-1’s selective scan. Empirical language-modelling performance matches Mamba-1 and is competitive with transformers at scales up to 2.7B; production-deployable Mamba models in 2026 are mostly hybrid (Jamba, Zamba) rather than pure-Mamba because attention remains stronger on associative-recall tasks. For deployment, evaluate Mamba-2 if long-context with low-recall-dependence is your workload; default to transformers or hybrids otherwise. The reference implementation, weights, and training scripts are all open at state-spaces/mamba.
The 5-line summary for the ML researcher. Dao and Gu’s SSD framework is a substantive theoretical advance: scalar-identity selective SSMs are equivalent (up to reparameterisation) to a generalised form of attention via semiseparable matrix decompositions, with the equivalence yielding a chunked-GEMM forward pass that runs 2-8x faster than Mamba-1’s selective scan. The scalar-identity restriction is the price of the duality and the speedup; empirical expressivity loss vs diagonal-A Mamba-1 is small at the scales studied. Mamba-2’s competitive-with-transformers claim at up to 2.7B is solid; the Waleffe 2024 8B-scale follow-up 11 identifies persistent associative-recall weakness and motivates hybrid architectures (Jamba, Zamba) as the production-relevant deployment pattern. Open questions concentrate on frontier-scale validation, optimal Mamba-to-attention ratios in hybrids, and instruction-tuned behaviour. For follow-up work, characterising the SSD-attention manifold (intermediate points between pure SSD and full attention) is the most consequential direction; the architectural-design framing has shifted from “transformer vs SSM” to “where on the manifold optimises for which workload.”
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. Dao, Gu (2024). Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality. ICML 2024. (accessed ) ↩
- 2. Dao and Gu (2024) — PDF on arXiv. (accessed ) ↩
- 3. Mamba-2 reference implementation (GitHub, state-spaces/mamba). (accessed ) ↩
- 4. Gu, Dao (2023). Mamba: Linear-Time Sequence Modeling with Selective State Spaces. (accessed ) ↩
- 5. Vaswani et al. (2017). Attention Is All You Need. (accessed ) ↩
- 6. Gu, Goel, Re (2022). Efficiently Modeling Long Sequences with Structured State Spaces (S4). (accessed ) ↩
- 7. Dao (2023). FlashAttention-2. (accessed ) ↩
- 8. Beck, Poppel, Spanring et al. (2024). xLSTM. (accessed ) ↩
- 9. Pena, Sun, Pal, Schwarzschild et al. (2024). RWKV-v6 'Finch'. (accessed ) ↩
- 10. Lieber, Lenz, Bata, Cohen et al. (2024). Jamba: A Hybrid Transformer-Mamba Language Model. (accessed ) ↩
- 11. Waleffe et al. (2024). An Empirical Study of Mamba-based Language Models. (accessed ) ↩
Anonymous · no cookies set