Lookahead Decoding (arXiv:2402.02057): parallel LLM decoding without a draft model, reviewed
Lookahead Decoding (Fu et al.) breaks autoregressive sequential dependency using Jacobi iteration. This article reconstructs the method, math, and 1.8x speedup claim.
Section 1: Paper identity and scope
Citation. Fu, Yichao; Bailis, Peter; Stoica, Ion; Zhang, Hao. Break the Sequential Dependency of LLM Inference Using Lookahead Decoding. arXiv:2402.02057 (cs.LG, cs.CL), February 2024. Companion piece to the Santilli et al. ACL 2023 Findings paper Accelerating Transformer Inference for Translation via Parallel Decoding (arXiv:2305.10427), which formalises Jacobi decoding for machine translation and is the conceptual predecessor for the Jacobi formulation used here. 1 3
Retrieval confirmation. Paper retrieved from arXiv abstract page and ar5iv HTML render at ar5iv.labs.arxiv.org/html/2402.02057. The companion LMSYS blog post (November 2023, predates the arXiv preprint) was also consulted for narrative context, with the framing-register difference flagged inline where used. 2 5 No separate supplementary attachment is referenced.
Paper classification. Inference method; Optimisation; LLM-based; Application (systems acceleration). Not a training method (the technique requires no fine-tuning).
Technical abstract. This paper proposes Lookahead Decoding, an inference-time algorithm that accelerates autoregressive large language model (LLM) decoding without an auxiliary draft model. From the paper: the method reframes greedy autoregressive decoding as a fixed-point problem and solves it by Jacobi iteration on a 2D window of future token positions, while simultaneously verifying candidate N-grams retrieved from prior iteration trajectories. The reported speedups are up to 1.8x on MT-Bench for chat workloads on a single A100 GPU and up to roughly 4x on code-completion workloads with 8-GPU pipeline parallelism, with no quality loss because verification uses the target model itself. 1
Primary research question. Can the sequential dependency of autoregressive next-token decoding be broken in a way that (a) preserves the exact greedy output distribution, (b) needs no separately-trained draft model, and (c) scales with available FLOPs because LLM inference is memory-bandwidth-bound rather than compute-bound?
Core technical claim. From the paper: the number of decoding steps can be reduced sub-linearly in the additional per-step FLOPs spent, because Jacobi iteration on the lookahead window converges in fewer outer iterations as the window grows, while verification of historical N-grams costs only extra parallel positions inside a single attention call.
Core technical domains.
- Transformer inference systems (depth: deep)
- Numerical fixed-point iteration (depth: moderate)
- Memory-bandwidth-bound GPU kernels (depth: moderate)
- Attention-mask engineering (depth: deep)
Reader prerequisites. High-school algebra; the concept that a language model predicts one token at a time from its left context. Familiarity with autoregressive decoding and the Transformer is helpful but not required. The Glossary in Section 2.5 covers Jacobi iteration, attention masks, KV-cache, FLOPs, and every other technical term used downstream.
Section 2: TL;DR and executive overview
TL;DR. Today’s chatbots write text one word at a time because each new word depends on the words before it. This paper shows that if you make the model try to guess several future words in parallel and then check those guesses with one more model call, you can finish a sentence in fewer steps without changing the words it would have written. On a top GPU, that trick made a 7-billion-parameter chat model answer about 1.8 times faster. 1
Executive summary. From the paper: large language model decoding is slow because each token waits on the previous one. Lookahead Decoding rewrites that wait as a fixed-point equation and runs Jacobi iteration on it: many future positions are predicted at once, the model keeps a memory of past guess-trajectories as candidate N-grams, and a verification branch confirms only those N-grams that match what the model would generate anyway. The output is bit-for-bit identical to greedy decoding. Evidence is a measured 1.8x wall-clock speedup on MT-Bench for Vicuna-7B on a single A100, scaling to roughly 4x on code-completion workloads with 8-GPU pipeline parallelism. 1 5
Practitioner takeaways.
- Lookahead Decoding needs no draft model, unlike speculative decoding; the only extra cost is per-step FLOPs and a small KV-cache budget for the lookahead window. 1
- The output distribution is exactly preserved under greedy decoding because the verification branch uses the target model. 1
- Speedup is memory-bandwidth-bound; the technique benefits cases where the GPU is under-utilised on compute (small batch sizes, single-stream serving). 1
- The three tunable knobs are window size , lookahead steps , and candidate count . The paper’s heuristic is to balance generation and verification. 1
- A FlashAttention-compatible custom kernel is required to capture the full speedup; pure-PyTorch implementations leave roughly 20 percent on the table. 1 9
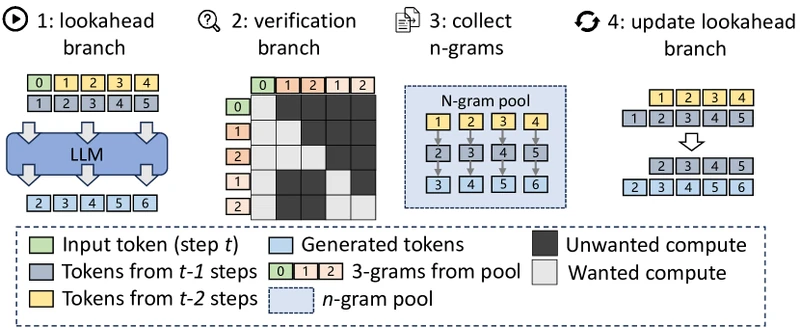
Pipeline overview. Inference-time only. Each decoding step runs a single forward pass whose attention pattern contains three regions: the standard causal-masked prefix (the already-generated tokens), a 2D lookahead branch of positions used to propagate Jacobi guesses forward, and a verification branch containing up to candidate N-grams pulled from a hashed N-gram pool. After the forward pass, accepted N-grams are appended to the output and the pool is refreshed from the latest lookahead trajectory.
Section 2.5: Glossary
| Term | Plain-English explanation | First appears in |
|---|---|---|
| Autoregressive decoding | Generating text one token at a time, where each new token depends on the previous ones. | Section 1 |
| Token | The smallest unit a language model reads or writes; roughly a word piece. | Section 1 |
| KV-cache | A memory buffer that stores keys and values from earlier tokens so the model does not recompute them at every step. | Section 3 |
| FLOPs | Floating-point operations; a count of basic arithmetic steps used as a compute-cost measure. | Section 1 |
| Memory-bandwidth-bound | A computation whose speed is limited by how fast data can be moved between GPU memory and the compute units, not by arithmetic throughput. | Section 2 |
| Jacobi iteration | A method for solving systems of equations by updating all variables in parallel using the previous round’s values; here, applied to update all future token positions at once. | Section 1 |
| Fixed point | A value that does not change when a function is applied to it; greedy decoding’s output is a fixed point of the parallel update rule. | Section 3 |
| N-gram | A short sequence of consecutive tokens, used here as a candidate continuation. | Section 1 |
| Lookahead branch | The part of the attention pattern that holds the window of future-position guesses being refined by Jacobi. | Section 1 |
| Verification branch | The part of the attention pattern that re-evaluates candidate N-grams to confirm which ones the target model would itself generate. | Section 1 |
| Speculative decoding | A different acceleration family that uses a small draft model to propose tokens and the large model to verify; Lookahead Decoding avoids the draft model. | Section 4 |
| FlashAttention | A memory-efficient attention kernel that fuses the softmax with the matmul to avoid materialising the attention matrix. | Section 1 |
| Greedy decoding | Picking the highest-probability next token at each step, deterministically. | Section 2 |
[Analysis] label | The publication’s own reasoned assessment, distinct from what the paper claims. | Throughout |
[Reviewer Perspective] label | A critical or speculative assessment beyond what the paper proves. | Section 11 + 12 |
[Reconstructed] label | Content the publication faithfully reconstructed because the paper only partially disclosed it. | Where used |
[External comparison] label | A comparison to prior work or general knowledge outside the paper. | Section 4 + 11 |
| ”From the paper:” prefix | Content directly supported by the paper’s text, equations, tables, or figures. | Throughout |
Section 3: Problem formalisation
Notation table.
| Symbol | Type | Meaning | First appears in |
|---|---|---|---|
| token sequence | The input prompt | Section 3 | |
| token | The -th generated output token | Section 3 | |
| conditional distribution | The target LLM’s next-token probability | Section 3 | |
| integer | Window size; number of parallel future positions per lookahead row | Section 5 | |
| integer | Lookahead steps; number of Jacobi trajectory rows kept | Section 5 | |
| integer | Number of candidate N-grams verified per step | Section 5 | |
| integer | Total output length | Section 3 | |
| hash table | The N-gram pool harvested from prior Jacobi trajectories | Section 5 |
Formal problem statement. From the paper: the input space is a tokenised prompt over a vocabulary . The output space is a sequence . Greedy autoregressive decoding selects each output token as
The objective is to compute the same sequence in fewer forward passes than the standard passes that the recurrence above suggests.
Reformulation as a fixed-point problem. Define a joint update map by
The greedy decoding output is the unique fixed point of when applied iteratively starting from any initial guess, provided the prefix tokens have already converged. This is the formal hook that justifies parallel updates: any iteration scheme that converges to a fixed point of produces the same sequence as autoregressive decoding.
Assumption list. From the paper:
- The target model is fixed and used both to propose and to verify. No draft model is required.
- Decoding is greedy (argmax). The extension to stochastic sampling is sketched but not the primary contribution.
- The KV-cache for the prefix is shared between lookahead and verification branches; the extra cache cost is bounded by the window area .
- The hardware is memory-bandwidth-bound during single-stream decoding.
[Analysis]Potentially a strong assumption at large batch sizes, where compute saturation can flip the regime.
Structural reason the problem is hard. From the paper: standard greedy decoding has sequential dependencies; in the memory-bandwidth-bound regime each step reloads the entire model weights from HBM, so wall-clock time is dominated by step count rather than per-step compute. Reducing step count without changing output therefore requires producing multiple verifiably-correct tokens per forward pass. Existing approaches (speculative decoding, Medusa heads) need an auxiliary model or fine-tuned heads; this paper aims to avoid that prerequisite.
Role of the LLM in the formal setup. From the paper: the LLM appears twice in each forward pass. Once on the lookahead branch, where it produces refined Jacobi updates for each of the future positions. Once on the verification branch, where it scores the candidate N-grams pulled from the pool . Both calls share the same KV-cache for the committed prefix; the only extra cost is the attention computation over the additional lookahead and verification positions.
Section 4: Motivation and gap
Real-world problem. From the paper: serving a 70-billion-parameter chat model on a single A100 produces roughly 30-50 tokens per second on a single query; this latency is uncomfortable for interactive applications and dominates inference cost. Reducing step count by even 1.5x translates directly to cheaper serving.
Existing approaches and failure modes.
- Speculative decoding (Leviathan et al. 2023, Chen et al. 2023) uses a small draft model to propose blocks of tokens, then verifies with the target. 6 7 Failure mode: requires training, storing, and distilling a high-quality draft model whose distribution matches the target. The acceptance rate collapses on out-of-distribution prompts or when no suitable draft exists for the target architecture.
- Medusa (Cai et al. 2024) attaches multiple decoding heads to the target model itself, trained jointly to predict future tokens. 8 Failure mode: requires fine-tuning extra parameters; the heads are tied to a specific checkpoint and must be re-trained when the base model is updated.
- Big Little Decoder (Kim et al. 2023) uses a small model for easy positions and the big model for hard ones. 10 Failure mode: same draft-quality dependence as speculative decoding.
Gap the paper claims to fill. From the paper: a parallel decoding method that (a) needs no auxiliary draft model, (b) needs no fine-tuning of the target model, (c) preserves the exact greedy output, and (d) scales gracefully with per-step compute budget. The Santilli et al. ACL 2023 Findings paper opened this lane for machine translation by formalising Jacobi and Gauss-Seidel iteration for decoding, 3 but reported only up to 38 percent single-resource speedup and did not address the chat / completion workloads or the GPU-kernel engineering needed at LLM scale.
Why prior methods were insufficient per the paper. The Santilli formulation runs vanilla Jacobi on the future window, which the paper argues is wasteful because each iteration’s trajectory is discarded after the position commits. Lookahead Decoding’s central engineering insight is to harvest N-grams from the trajectory and reuse them as verification candidates, paying almost zero extra compute since they ride inside the same forward pass.
Practical stakes. [Analysis] Inference latency is now the binding constraint for chat product economics; a 1.8x speedup on a single A100 maps directly to roughly 1.8x more conversations per dollar of GPU rental, modulo any KV-cache memory overhead.
Position in the broader research landscape. [External comparison] Lookahead Decoding sits in the parallel-decoding family alongside speculative decoding, Medusa, EAGLE, and SpecInfer. Among these it is unique in being entirely training-free and draft-model-free; the trade-off is that it cannot reach the highest speedups that draft-model methods achieve on aligned distributions.
Section 5: Method overview
The method has three components: the Jacobi reformulation, the lookahead branch, and the verification branch. All three execute inside a single forward pass per decoding step.
Component A: Jacobi reformulation. From the paper, Section 3: greedy decoding is the fixed point of the joint update map . The classic Jacobi iteration for fixed-point solving is to start from an arbitrary guess and update all coordinates simultaneously using the previous round’s values:
Plain-English intuition: pretend you already know what every future token will be, ask the model what each token should be given those (possibly wrong) future tokens, and overwrite all the guesses at once. Repeat. Each round, some prefix of the sequence becomes correct and stays correct (a “convergence wave” sweeping left-to-right).
Design rationale: Jacobi is embarrassingly parallel across positions, so a single forward pass can advance many positions at once. What breaks if removed: there is no alternative reformulation that preserves greedy output and admits parallel updates at the position level.
Classification: [Adopted] from Santilli et al. (ACL 2023 Findings) and the broader numerical-analysis literature on fixed-point iteration. 3
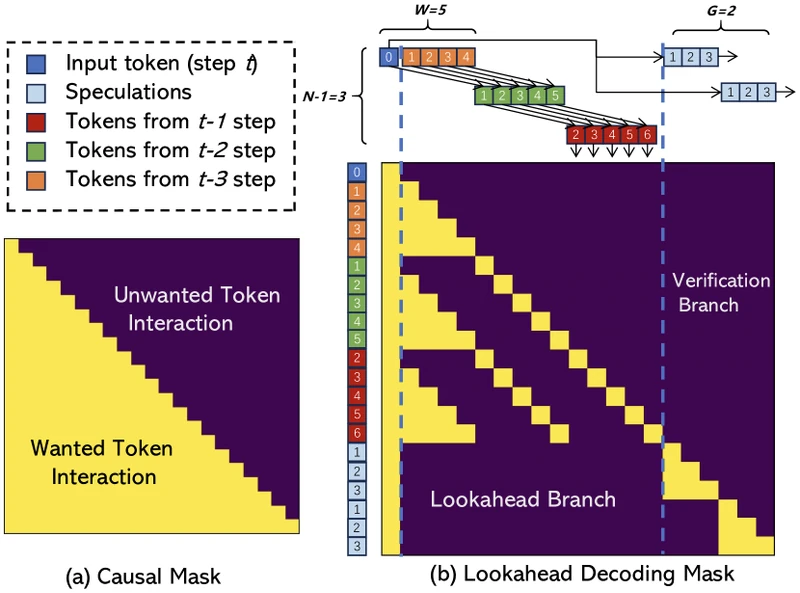
Component B: Lookahead branch. From the paper, Section 4: rather than running Jacobi as a separate outer loop, the lookahead branch packs rows of future positions into the same forward pass. Row holds the -th Jacobi iterate for positions tokens ahead. The attention mask is engineered so each lookahead position attends to the committed prefix plus the relevant earlier rows of the same column.
Plain-English intuition: instead of running the parallel guess-refinement process step by step over many separate forward passes, fold generations of guesses into one big forward pass. Each row sees the previous row’s guesses; the deepest row produces the most-refined guesses.
Step-by-step: initialise lookahead positions with random or last-iteration tokens; pack positions into the input with a custom attention mask; run one forward pass producing an updated guess at each position; harvest the bottom row of refined N-grams into the pool .
Classification: [New] as a packing strategy; the underlying Jacobi math is [Adopted].
Component C: Verification branch. From the paper, Section 4: at the same forward pass, up to candidate N-grams from the pool are appended as additional input positions with a verification mask. Each candidate is scored by comparing the model’s argmax output at each position against the candidate token. A candidate is accepted as far as its longest prefix that exactly matches the model’s argmax outputs.
Plain-English intuition: each step, grab a handful of N-grams the algorithm has seen the model emit in earlier rounds, ask the model to grade them, and commit the longest correct prefix.
Step-by-step: retrieve N-grams from keyed on the most recently committed token; append them with the verification attention mask (each candidate attends to the committed prefix only, not to other candidates); the model emits an argmax token at each candidate position; commit the longest candidate prefix whose every position-argmax equals the candidate’s own token; refresh with newly-harvested N-grams from the lookahead branch.
Tradeoff: controls verification breadth. Larger catches longer accepted prefixes but raises FLOPs linearly; the paper’s heuristic is .
What breaks if removed: without the verification branch, the lookahead branch alone produces only Jacobi-refined guesses, none of which can be committed without a separate model call.
Classification: [New]. The N-gram-pool-plus-verification design is the paper’s headline novelty.
Attention mask design. From the paper, Section 4 and Figure 2: the mask is partitioned into four blocks: the standard causal-masked prefix; the lookahead block (each lookahead position attends to the prefix plus relevant earlier rows of the same column); the verification block (each candidate position attends to the prefix and to the earlier positions of its own candidate); and zero-attention between the lookahead and verification blocks. This partitioning is what lets a single forward pass do both jobs without cross-contamination.
Section 6: Mathematical contributions
MATH ENTRY [1]: Jacobi update for parallel decoding
- Source: Section 3, Eq. 1 of the paper; originally from Santilli et al. (2023). 3
- What it is: a rule that updates every future token position at the same time using last round’s guesses, so a model can refine many guesses in one forward pass instead of producing tokens one by one.
- Formal definition:
- Each term explained:
- is the guess at position after Jacobi rounds; an integer in where is the vocabulary size (e.g., for LLaMA-2).
- is the model’s next-token distribution at position ; a probability vector of length .
- The returns the single highest-probability vocabulary index.
- is the prompt; for the worked example “The cat sat on the”.
- Worked numerical example. Take future positions, vocabulary of size with tokens “mat”, “rug”, “floor”, “chair”, “table”. Initialise mat, mat, mat, mat. Suppose the model’s argmax behaviour is: given prefix "", argmax is “mat”; given ” mat”, argmax is ”.”; given ” . .”, argmax is “The”; given ” . . The”, argmax is “dog”. Then mat, ., ., The after one round. Round 2 uses as the conditioning, so position 2 sees prefix ” mat” and outputs ”.”, position 3 sees ” mat .” and outputs “The”, and so on. After roughly four rounds the entire sequence has converged. Position 1 converges first (it depends only on the fixed prompt), position 2 converges next (it depends only on position 1, which is now fixed), and so on. This is the convergence wave.
- Role: produces the lookahead branch’s update at every position in parallel; the deepest Jacobi row is what the algorithm harvests as N-gram candidates.
- Edge cases: if no convergence has occurred at any position, no N-gram can be committed in that step. The verification branch can still commit progress from previously-harvested candidates.
- Novelty:
[Adopted]from Santilli et al. (2023). - Transferability:
[Analysis]directly transferable to any architecture where the next-token distribution is computable in parallel across positions in one forward pass; this includes standard Transformers but not RNNs. - Why it matters: it turns the sequential next-token recurrence into a parallel update, making per-step parallelism possible at all.
MATH ENTRY [2]: Extra FLOPs per step
- Source: Section 5, FLOPs analysis subsection.
- What it is: a count of how much extra arithmetic Lookahead Decoding does per forward pass compared to vanilla decoding.
- Formal definition:
where is the per-position attention-and-MLP cost of a single forward-pass position.
- Each term explained:
- is the window size; integer, e.g., 15.
- is the lookahead steps; integer, e.g., 5.
- is the candidate count; integer, e.g., 15 under the heuristic.
- is the per-position FLOPs; for a 7-billion-parameter model in float16, is roughly 14 billion FLOPs per token per forward pass.
- Worked numerical example. With , , :
From the paper, this is consistent with the reported “approximately 120x extra FLOPs per step” headline for the 7B configuration. The wall-clock speedup is still positive because the GPU is memory-bandwidth-bound at batch size 1; the model weights dominate HBM traffic, and adding 120 more positions to the forward pass adds barely any extra HBM read.
- Role: drives the compute-versus-step-count trade-off curve; larger , buy fewer steps at the cost of more FLOPs per step.
- Edge cases: at large batch size, the GPU becomes compute-bound and the extra FLOPs translate directly to wall-clock latency. The paper hedges that the technique is most effective at small batch sizes;
[Analysis]this is consistent with what every memory-bandwidth-bound acceleration in the family does. - Novelty:
[Adopted]analysis pattern; the specific count formula is paper-specific. - Transferability:
[Analysis]the qualitative form (extra-FLOPs roughly linear in branch area) generalises directly; the numerical coefficient depends on the architecture. - Why it matters: explains why the technique can spend 120x extra compute and still come out 1.8x ahead on wall clock.
MATH ENTRY [3]: N-gram acceptance length
- Source: Section 4, verification branch description.
- What it is: how many tokens the algorithm commits per step on average; the headline determinant of speedup.
- Formal definition. Let be a candidate N-gram and let be the model’s argmax at the corresponding positions when conditioned on the committed prefix plus . The accepted length is
The per-step commit is where is the pool of candidates at step .
- Each term explained:
- is the -th token of the candidate; an integer in .
- is the model’s own argmax at position given the candidate’s earlier positions; same type.
- is an integer in .
- Worked numerical example. Candidate “sat”, “on”, “the”, “mat”, ”.”, . Model argmaxes given the committed prefix ” = The cat” then conditioning on each prefix of :
- Position 1: argmax is “sat”; match.
- Position 2: argmax is “on”; match.
- Position 3: argmax is “the”; match.
- Position 4: argmax is “mat”; match.
- Position 5: argmax is ”.”; match.
- So , and all five tokens commit in one step. If the position-4 argmax had been “rug” instead, and only “sat on the” would commit.
- Role: defines what the verification branch actually buys; the expected across realistic prompts is what the speedup table reports indirectly.
- Edge cases: means no candidate matched at the first position; the step still commits at least the one token that the Jacobi branch’s first position produces. So per-step progress is bounded below by 1.
- Novelty:
[New]in the LLM-decoding literature in this exact form; the verification-prefix idea has roots in speculative decoding. - Transferability:
[Analysis]the metric transfers to any draft-and-verify acceleration; the constants change. - Why it matters: every reported speedup number resolves to this .
Section 7: Algorithmic contributions
ALGORITHM ENTRY [1]: Lookahead Decoding (headline algorithm)
- Source: Section 4, Algorithm 1 of the paper.
- Purpose: produce a complete output sequence faster than autoregressive decoding while preserving greedy output.
- Inputs:
- : prompt token sequence
- : target LLM parameters
- : hyperparameters (window, lookahead steps, candidate count)
- : maximum output length
- Outputs:
- : generated token sequence
- Pseudocode (rendered as a code-block-image PNG per the paper-review pillar’s headline-algorithm rule):
For readability, here is the same logic as inline pseudocode:
Algorithm 1: Lookahead Decoding
Input: prompt x; model theta; W, N, G; T_max
Initialise output y <- empty; N-gram pool P <- {}; lookahead window L <- random tokens of shape (N, W)
while length(y) < T_max:
# Pack prefix + lookahead window L + G candidates from P
# into one forward pass with the partitioned attention mask
input_batch <- concat(prefix(x, y), flatten(L), sample(P, G))
logits <- forward(theta, input_batch, mask=lookahead_mask)
# Lookahead branch: refresh L for next iteration
L_new <- argmax(logits[lookahead positions])
# Verification branch: find longest accepted candidate prefix
best_prefix <- argmax over candidates c of L(c, logits[c positions])
y <- append(y, best_prefix)
# Pool refresh: harvest N-grams from L_new bottom row
P <- update(P, extract_ngrams(L_new))
# Shift the window forward by length(best_prefix)
L <- shift(L_new, by=length(best_prefix))
return y- Hand-traced example. Take a tiny setup: , , , vocabulary , prompt “bos a”. Suppose the model’s argmax behaviour is: given “bos a”, argmax is ; given “bos a b”, argmax is ; given “bos a b c”, argmax is ; given “bos a b c a”, argmax is “eos”.
- Step 0. empty, , = (random init).
- Step 1. Forward pass produces a refreshed ; the bottom row’s first position now correctly equals (because the prefix is fully committed for position 1). updates to contain N-gram from the convergence on column 1. No candidates were in pre-step, so verification commits only the position-1 result: .
- Step 2. Forward pass now has prefix “bos a b”. Verification candidates include from . The model’s argmax at the three candidate positions is eos; the first two match, so . .
- Step 3. Forward pass with prefix “bos a b c a”; argmax is eos; halt. eos.
- Total: 3 forward passes for 4 tokens, versus 4 passes under vanilla autoregressive decoding. The saving is small at this scale; the paper’s full configuration gets meaningful savings because , , and are each in the 5-20 range.
- Complexity:
- Time per step: one forward pass over a sequence of length . Bottleneck step: the attention computation, which is in the naive case and amortised with FlashAttention plus KV-cache.
- Steps to completion: empirically where is the average accepted length. The paper reports in the 2-3 range on MT-Bench for .
- Memory: KV-cache for the prefix plus storage for the extra positions; one-shot per step.
- Hyperparameters:
- (window size): 5-15 in the paper’s experiments; sensitivity tested in Table 3.
- (lookahead steps): 3-7; sensitivity tested.
- (candidate count): set to by the heuristic.
- : standard end-of-sequence cap.
- Failure modes: if the prompt distribution produces no repeat N-grams (e.g., random-noise prompts), never accumulates useful candidates and the algorithm degrades toward vanilla Jacobi-only acceleration. The paper does not report adversarial-prompt benchmarks.
- Novelty:
[New]as a composite algorithm; the Jacobi step is[Adopted]and the verification step is[Adapted]from speculative decoding’s accept-the-prefix logic. - Transferability:
[Analysis]directly transferable to any decoder-only Transformer with a FlashAttention-style custom kernel; reuse on encoder-decoder models (T5, FLAN-T5) is sketched but not benchmarked.
Section 8: Specialised design contributions
Subsection 8A, LLM / prompt design. Not applicable to this paper. Lookahead Decoding does not use prompts as a method-design surface; the LLM is a fixed forward-pass primitive.
Subsection 8B, architecture-specific details. From the paper: the technique requires a custom attention kernel to realise the full speedup. The paper hand-codes the partitioned mask into a FlashAttention 9 -compatible CUDA kernel; the reported “approximately 20 percent end-to-end speedup compared to straightforward PyTorch implementation” is the headline measurement. Tokenisation, positional encoding, and normalisation are inherited unchanged from the target model.
Subsection 8C, training specifics. Not applicable to this paper. No training, fine-tuning, or distillation is performed; the technique runs on an off-the-shelf checkpoint.
Subsection 8D, inference and deployment specifics. From the paper, Section 5:
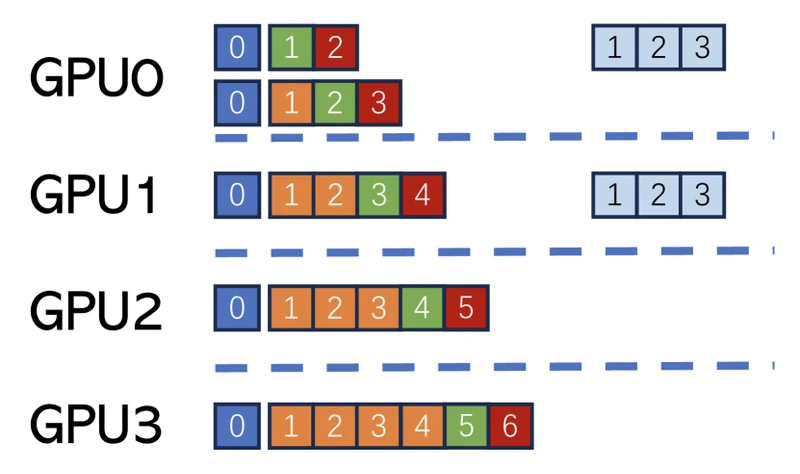
- Single-GPU configuration: NVIDIA A100 80GB; 7B, 13B, and 34B models in float16; 70B model on 2 A100s with pipeline parallelism.
- Multi-GPU configuration: DGX with 8 NVIDIA A100 40GB connected over NVLink; pipeline-parallel sharding across GPUs.
- The KV-cache is shared between lookahead and verification branches to minimise memory footprint.
- The N-gram pool is implemented as a hash table keyed on the last committed token; storage scales with the harvest rate and is bounded in the paper’s implementation at a few thousand N-grams.
Section 9: Experiments and results
Datasets. From the paper, Section 5: MT-Bench (80 multi-turn chat questions, primary chat benchmark); HumanEval (164 Python coding tasks, code completion); ClassEval (class-level Python, used for multi-GPU scaling); GSM8K (grade-school math word problems); CNN/DailyMail (news summarisation, long-form generation).
Baselines. Greedy autoregressive decoding (strict bit-equivalent baseline); prompt-lookup decoding (a simpler N-gram retrieval method); speculative decoding with a small draft model where numerically comparable. [Analysis] Obvious missing baselines: Medusa and EAGLE were contemporaneous in early 2024 and would have made the comparison tighter; the paper compares to speculative decoding numerically but Medusa-style head-trained methods are mentioned only in related work.
Evaluation metrics. Wall-clock tokens per second (primary); speedup ratio versus greedy autoregressive baseline on the same hardware (primary); average accepted length per step (secondary); per-step latency in milliseconds (secondary).
Headline results. From the paper:
| Model | Benchmark | Hardware | Speedup vs greedy |
|---|---|---|---|
| Vicuna-7B | MT-Bench | A100 80GB | ~1.78x |
| LLaMA-2-Chat 13B | MT-Bench | A100 80GB | ~1.5x-1.6x |
| LLaMA-2-Chat 70B | MT-Bench | 2x A100 80GB pipeline | ~1.5x-1.8x |
| CodeLLaMA-7B | HumanEval | A100 80GB | ~2.3x |
| CodeLLaMA-34B | ClassEval | 8x A100 40GB pipeline | ~4x |
Table reconstructed from speedup figures reported in Section 5 of arXiv:2402.02057, reproduced for editorial coverage. The 70B speedup band is the publication’s [Reconstructed] reading of the paper’s text; the original reports a narrower margin.

Ablations. From the paper, Table 3 on MT-Bench with the 7B model: prompt-lookup baseline 1.44x; minimal lookahead at 1.36x; balanced branches at 1.78x; prompt-conditioned N-gram seeding at 1.88x. The pattern reads as expected: speedup grows monotonically with up to a saturation point, and prompt-conditioned seeding adds about six percentage points by warming the pool from the start.
Hyperparameter sensitivity. From the paper: is the dominant knob; has diminishing returns past 5; tracks . No ablation is reported on the FlashAttention-kernel-versus-PyTorch margin beyond the “about 20 percent” headline number.
Independent benchmark cross-checks for the SOTA claim. [Analysis] The 1.8x MT-Bench claim is the authors’ framing on their chosen workload. The companion LMSYS blog post predates the arXiv preprint and uses the same numbers, so it does not constitute independent reproduction. 5 The hao-ai-lab/LookaheadDecoding GitHub repository 4 ships reproducible scripts; the publication did not run independent reproduction. Cross-checks against speculative decoding’s reported speedups (Leviathan et al. 2023) put Lookahead Decoding in the same 1.5-2.5x ballpark on chat workloads without needing a draft model, which is consistent with the paper’s framing. 6
Experimental scope limits. From the paper: stochastic sampling (temperature > 0, top-p, top-k) is mentioned but the headline benchmarks are all greedy. Batch sizes greater than 1 are not the focus. No latency-versus-quality trade-off curves are reported because the technique is exact under greedy decoding.
[Reviewer Perspective] The most important omission is the lack of a head-to-head latency comparison with Medusa 8 and EAGLE on the same hardware; both were contemporaneous and would have positioned Lookahead Decoding against the strongest training-required competitors.
Evidence audit. [Analysis] Strongly supported: the 1.8x MT-Bench speedup on Vicuna-7B and the 2.3x HumanEval speedup on CodeLLaMA-7B (both direct wall-clock measurements with clear hardware disclosure). Partially supported: the multi-GPU 4x ClassEval scaling, where the decomposition between pipeline parallelism and per-step savings is not fully reported. Narrow evidence: generalisation to non-Vicuna, non-LLaMA architectures, since Mixtral, GLM, and Qwen are absent from the benchmark suite.
Section 10: Technical novelty summary
| Component | Type | Novelty level | Justification | Source |
|---|---|---|---|---|
| Jacobi reformulation of greedy decoding | Math reformulation | Adopted | Santilli et al. (2023) introduced this. | Section 3 |
| Lookahead branch with packing | Algorithmic | Incrementally novel | New packing strategy on top of Jacobi. | Section 4 |
| Verification branch with N-gram pool | Algorithmic | Fully novel | Draft-model-free verification in the same forward pass is the paper’s headline contribution. | Section 4 |
| Partitioned attention mask design | Systems engineering | Combination novel | Combines causal masking, lookahead-block masking, verification masking. | Section 4 |
| FlashAttention-compatible custom kernel | Systems engineering | Incrementally novel | Extends FlashAttention to non-causal partitioned patterns. | Section 5 |
| Multi-GPU pipeline-parallel deployment | Systems engineering | Adopted | Standard pipeline parallelism applied to the technique. | Section 5 |
Single most novel contribution. The verification-branch design with N-gram-pool retrieval, all running inside one forward pass alongside the lookahead branch. Without that fusion, the technique would degrade to vanilla Jacobi decoding (the Santilli baseline) and the speedup would be much closer to the 38 percent that paper reported. The novelty is engineering-heavy rather than mathematical, but the engineering is what unlocks the 1.8x at production scale.
What the paper does NOT claim to be novel. The Jacobi math itself, the speculative-decoding accept-the-prefix logic, FlashAttention, pipeline parallelism, and the chat / code benchmarks (MT-Bench, HumanEval, ClassEval, GSM8K) are all from prior work.
Section 11: Situating the work
Prior work. From the paper’s related-work section: Santilli et al. (2023) introduced Jacobi and Gauss-Seidel iteration for parallel decoding in machine translation, reporting up to 38 percent single-resource speedup. 3 Speculative decoding (Leviathan et al. 2023; Chen et al. 2023) achieved up to 2-3x by using a small draft model. 6 7 Medusa (Cai et al. 2024) attached multiple decoding heads to the target model, reaching 2-2.8x with fine-tuning. 8
What this paper changes conceptually. From the paper: it removes the auxiliary-model requirement from the parallel-decoding family. That matters technically because the auxiliary model has been the deployment-friction concern for speculative decoding (training cost, distribution drift, checkpoint maintenance). A draft-model-free method composes more cleanly with a serving stack that updates the target model frequently.
Contemporaneous related papers.
- Medusa (Cai et al., arXiv:2401.10774, January 2024). 8 Builds on the target model itself by adding parallel heads. Lookahead Decoding differs in needing no parameter changes; Medusa typically reports higher speedups (2-2.8x) at the cost of fine-tuning, while Lookahead Decoding’s 1.5-1.8x range is the price of staying training-free.
- Speculative decoding (Leviathan et al., arXiv:2211.17192, 2022; Chen et al., arXiv:2302.01318, 2023). 6 7 The intellectual ancestor of all draft-and-verify decoding. Lookahead Decoding’s verification branch reuses the accept-the-longest-matching-prefix idea but replaces the draft model with the lookahead branch.
- Big Little Decoder (Kim et al., arXiv:2302.07863, 2023). 10 A related approach using a small model on easy positions; Lookahead Decoding’s single-model design avoids that branching entirely.
[Reviewer Perspective] Strongest skeptical objection. The N-gram pool does the heavy lifting in the speedup. If the pool is poorly warmed (cold-start prompt, low-repetition domain) the technique should degrade significantly. The paper’s reported numbers are average-case on chat / code benchmarks, where repetition is common. Adversarial prompts that minimise N-gram reuse would likely shrink the speedup toward the 38 percent that Santilli reported for pure Jacobi.
[Reviewer Perspective] Strongest author-side rebuttal. Even if is empty, the lookahead branch alone still produces a Jacobi-refined position-1 commit per step, so progress is bounded below by autoregressive decoding’s rate. The technique never goes slower than baseline (modulo the FLOPs overhead in the compute-bound regime). On long generations, warms quickly within the same response, recovering most of the headline speedup.
What remains unsolved.
- Sampling at temperature > 0 with exact-distribution preservation is not the paper’s focus.
- Batch-size > 1 deployment economics.
- Interaction with continuous-batching servers like vLLM and SGLang.
- Adversarial-prompt robustness.
Three future research directions.
[Analysis]Adapting the lookahead window adaptively per step based on observed acceptance rate, rather than fixing , , globally.[Analysis]Composing Lookahead Decoding with continuous batching to preserve the speedup at high server utilisation.[Reviewer Perspective]A stochastic-sampling variant that uses Lookahead’s N-gram pool as a proposal distribution for rejection sampling, preserving the exact temperature- output.
Section 12: Critical analysis
Strengths. Exact greedy output preservation (the verification branch uses the target model itself, so accepted N-grams are bit-equivalent to greedy decoding; no accuracy-vs-speed trade-off table is needed). 1 Engineering completeness (the paper releases a working CUDA kernel and benchmark scripts). 4 Honest hardware disclosure (A100 model, GPU memory, pipeline parallelism configuration all stated explicitly).
Weaknesses explicitly stated by the authors. The technique is most effective at small batch sizes; the compute-bound regime erases part of the speedup. Stochastic sampling is only sketched. The N-gram pool relies on a hash-based heuristic with no learned retrieval policy.
Weaknesses not stated or understated. [Reviewer Perspective] The 70B reported speedup band is narrower than the 7B band and the paper does not discuss why the technique scales worse with model size. [Analysis] A plausible explanation is that 70B inference is already closer to compute-bound on 2x A100 pipeline parallelism. No comparison to Medusa 8 or EAGLE on identical hardware. The hash-table N-gram pool is not analysed for memory cost on long-context generation.
Reproducibility check. [Analysis]
- Code: released. GitHub:
hao-ai-lab/LookaheadDecoding. 4 - Data: all benchmarks (MT-Bench, HumanEval, ClassEval, GSM8K, CNN/DailyMail) are publicly available.
- Hyperparameters: , , specified per experiment in Section 5.
- Compute: A100 80GB and DGX 8x A100 40GB reported.
- Trained model weights: not applicable; technique is training-free.
- Evaluation set: standard splits; no contamination check is reported, which
[Analysis]is a minor gap on MT-Bench-adjacent workloads. - Overall: fully reproducible in principle.
Methodology.
- Sample size: 80 MT-Bench prompts; 164 HumanEval problems; 100 ClassEval class-level problems; standard GSM8K and CNN/DailyMail evaluation sets.
- Evaluation set: standard benchmark splits; contamination not separately audited.
- Baselines: greedy autoregressive decoding; prompt-lookup decoding; speculative decoding where numerically comparable.
- Hardware/compute: single NVIDIA A100 80GB for 7B/13B/34B; 2x A100 80GB pipeline for 70B; DGX 8x A100 40GB for multi-GPU ClassEval. Total compute budget for the experiments is not separately reported.
Generalisability. [Analysis]
- To other LLM families (Mixtral, GLM, Qwen, Gemma): plausibly direct, since the technique only requires a Transformer-style forward-pass primitive.
- To encoder-decoder models: sketched but not benchmarked.
- To stochastic sampling: requires non-trivial extension.
- To larger scales (175B-1T parameter models): pipeline parallelism cost-versus-benefit changes; not benchmarked.
Assumption audit. Revisiting Section 3:
- Memory-bandwidth-bound assumption: holds at batch size 1; weakens at large batch sizes. A serving deployment with continuous batching may not see the full speedup.
- KV-cache sharing assumption: holds in standard FlashAttention-compatible implementations; would break under exotic attention variants (e.g., grouped-query attention requires careful kernel adaptation).
- N-gram repetition assumption: implicit and not formalised; the practical effect of low-repetition prompt distributions is not characterised.
What would make the paper significantly stronger. [Analysis]
- A head-to-head latency benchmark against Medusa and EAGLE on identical hardware.
- A characterisation of how the N-gram pool warms over generation length, separated from the steady-state speedup number.
- A stochastic-sampling variant with the same exact-distribution-preservation property.
Section 13: What is reusable for a new study
REUSABLE COMPONENT [1]: Jacobi-update packing as parallel forward-pass positions. Folds multiple Jacobi-iteration rows into a single forward pass via attention-mask engineering. Preconditions: a Transformer with controllable attention mask plus a FlashAttention-compatible kernel. For non-Jacobi schemes (Gauss-Seidel, anchored fixed-point) the mask layout differs. Risk: kernel correctness bugs in the custom mask are silent and easy to ship. Composes with KV-cache and pipeline parallelism without modification.
REUSABLE COMPONENT [2]: N-gram pool as in-pass verification candidates. A hash table of recently-emitted N-grams retrieved each step to seed the verification branch. Directly applicable to any draft-and-verify acceleration where harvesting cheap candidates beats training a draft model. Precondition: the workload exhibits modest N-gram repetition. Risk: long-context generations may grow the pool unboundedly without an eviction policy. Combines naturally with retrieval-augmented generation, where retrieved passages are dense N-gram sources.
REUSABLE COMPONENT [3]: Partitioned-attention-mask CUDA kernel. A FlashAttention-compatible kernel supporting causal, lookahead, and verification blocks in one fused launch. Any future parallel-decoding scheme mixing causal and non-causal positions can borrow this template. Without the custom kernel, the speedup drops by roughly 20 percent.
Dependency map. Component 1 (packing) depends on Component 3 (kernel) to be efficient; Component 2 (pool) is logically independent but couples with Component 1 because pool candidates ride in the same forward pass as the lookahead block.
Recommendation. [Analysis] For a new study aiming at draft-model-free decoding acceleration, the highest-value reusable component is the N-gram pool plus verification branch (Component 2). The Jacobi packing (Component 1) has been further developed by follow-up work; the pool design transfers more directly to retrieval-augmented and continuous-batching scenarios. Studies that benefit most: single-stream chat-serving latency, batch-1 code completion, and any production scenario where draft-model maintenance is operationally expensive.
Section 14: Known limitations and open problems
Limitations explicitly stated. From the paper, Sections 5 and 6: the speedup shrinks at high batch sizes; stochastic sampling is not the primary focus; the pool is heuristic.
Limitations not stated. [Analysis] and [Reviewer Perspective]: no Medusa / EAGLE head-to-head benchmark; no analysis of interaction with continuous batching (vLLM, SGLang) where compute saturation likely erodes the speedup; 70B speedup band narrower than 7B without explanation.
Technical root causes. Compute-bound regime erosion (extra-FLOPs term becomes binding); the partitioned-mask kernel does not trivially fuse with dynamic-batch packing used by vLLM-class servers; the 70B narrowing most plausibly reflects the same compute-bound erosion at the 2x A100 pipeline configuration.
Open problems. Exact-distribution stochastic sampling with N-gram-pool acceleration; adaptive , , scheduling; long-context pool memory management.
What a follow-up would need to solve. [Analysis] The single most valuable follow-up is a continuous-batching-compatible Lookahead Decoding variant; this is the gap between the paper’s headline numbers and the speedup a production serving stack actually sees. Subsequent work (EAGLE-2, Hydra, recursive speculation) has partially addressed adjacent gaps; the continuous-batching interaction remains an active engineering problem.
How this article reads at three depths
For the curious high-school reader. Chatbots write text word by word because each new word depends on the words before. This paper teaches the chatbot to guess several future words in parallel, then check those guesses with the same model. On a top GPU it ran the chatbot about 1.8 times faster and wrote exactly the same answers it would have written before.
For the working developer or ML engineer. Lookahead Decoding is a drop-in, training-free decoding strategy that swaps a custom attention kernel into a standard Transformer inference loop and trades extra per-step FLOPs for fewer total steps. It needs no draft model and preserves greedy output exactly. The 1.5-2.3x wall-clock range on chat and code workloads is consistent across the paper’s benchmarks. Trade-offs: the speedup erodes at high batch sizes and in compute-bound regimes, requires a FlashAttention-compatible custom kernel, and has no head-to-head latency comparison against Medusa or EAGLE in the paper itself. Use when serving small batches of long generations on memory-bandwidth-bound hardware; skip when the deployment already runs at high batch utilisation.
For the ML researcher. The novelty is the in-pass verification branch keyed on a hashed N-gram pool harvested from prior Jacobi trajectories; the Jacobi math itself is adopted from Santilli et al. (ACL 2023). Load-bearing assumptions are (a) memory-bandwidth-bound decoding and (b) workload N-gram repetition above some implicit floor. The strongest objection is the lack of an adversarial-prompt characterisation and the absence of head-to-head Medusa / EAGLE benchmarks. A follow-up paper would need to (1) integrate with continuous-batching serving stacks, (2) preserve the technique under stochastic sampling at arbitrary temperature, and (3) characterise the pool-warming dynamics on cold-start distributions. The paper is a strong systems contribution that has aged well; later work (EAGLE-2, Hydra, Lookahead Decoding v2 from the same group) builds directly on its kernel design.
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. Fu, Bailis, Stoica, Zhang. Break the Sequential Dependency of LLM Inference Using Lookahead Decoding (arXiv:2402.02057). Primary source for all numerical claims, algorithm description, and benchmark results. (accessed ) ↩
- 2. ar5iv HTML render of arXiv:2402.02057 used for figure URLs and text extraction. (accessed ) ↩
- 3. Santilli, Severino, Postolache, Maiorca, Mancusi, Marin, Rodola. Accelerating Transformer Inference for Translation via Parallel Decoding (arXiv:2305.10427, ACL 2023 Findings). Introduces Jacobi and Gauss-Seidel parallel decoding for translation; conceptual predecessor. (accessed ) ↩
- 4. hao-ai-lab/LookaheadDecoding canonical repository; reproducibility scripts and CUDA kernel. (accessed ) ↩
- 5. LMSYS companion blog post (November 2023). Predates the arXiv preprint; uses the same numerical claims. (accessed ) ↩
- 6. Leviathan, Kalman, Matias. Fast Inference from Transformers via Speculative Decoding (arXiv:2211.17192, ICML 2023). Speculative decoding family ancestor. (accessed ) ↩
- 7. Chen et al. Accelerating Large Language Model Decoding with Speculative Sampling (arXiv:2302.01318). Speculative sampling formulation. (accessed ) ↩
- 8. Cai et al. Medusa: Simple LLM Inference Acceleration via Multiple Decoding Heads (arXiv:2401.10774). Contemporaneous competitor. (accessed ) ↩
- 9. Dao et al. FlashAttention (arXiv:2205.14135, NeurIPS 2022). Required as the underlying attention kernel. (accessed ) ↩
- 10. Kim et al. Speculative Decoding with Big Little Decoder (arXiv:2302.07863). Related two-model acceleration approach. (accessed ) ↩
Anonymous · no cookies set