LLM watermarking and AI-content detection: a four-paper review
Kirchenbauer green/red lists, Aaronson's Gumbel scheme, Christ-Gunn-Zamir undetectable watermarks, and SynthID-Text. What each method changes and where each one breaks.
Reading-register key
- From the paper: claims drawn directly from the source paper’s text, equations, tables, or figures.
- [Reconstructed]: faithful reconstruction from partial disclosure or supplementary code.
- [Analysis]: the publication’s own reasoned assessment, distinct from any claim the papers themselves make.
- [External comparison]: comparison to named prior work or general knowledge outside the four papers.
- [Reviewer Perspective]: critical or speculative assessment going beyond what any of the four papers proves.
Figure 1 of A Watermark for Large Language Models (arXiv:2301.10226), reproduced for editorial coverage.
Section 1: Cluster scope
This review covers four watermarking schemes for large-language-model outputs, spanning the 2022–2024 design space:
- Kirchenbauer et al. (2023), A Watermark for Large Language Models. ICML 2023. The green-list / red-list method. arXiv:2301.10226. 1
- Aaronson (2022/2023), the OpenAI Gumbel / exponential-minimum sampling scheme described in the Simons Institute talk and the Crypto 2023 plenary. 3
- Christ, Gunn, Zamir (2023), Undetectable Watermarks for Language Models. arXiv:2306.09194. The first watermark whose output is computationally indistinguishable from the unwatermarked model. 2
- Dathathri et al. (Google DeepMind, 2024), Scalable watermarking for identifying large language model outputs / SynthID-Text. Nature 626, October 2024. The production system shipped inside Gemini. 4
These are not independent papers. Kirchenbauer is the parent academic work; Aaronson is the contemporaneous OpenAI-internal alternative that influenced subsequent cryptographic treatments; Christ-Gunn-Zamir is the theoretical reframing that defines what “undetectable” should mean; SynthID-Text is the engineering refinement Google DeepMind put into production. [Analysis] Reading them as a four-paper cluster, rather than four isolated schemes, is the right way to understand the trade-offs each one makes between detection power, output quality, and threat-model robustness.
Paper classifications:
- Kirchenbauer: Generative model · Probabilistic · AI safety · Application
- Aaronson: Generative model · Probabilistic · AI safety · Theoretical (sketched, not formally published as a paper)
- Christ-Gunn-Zamir: Theoretical · Probabilistic · AI safety
- SynthID-Text: Generative model · Application · AI safety · Empirical at production scale
Core technical domains (depth label per domain): probability theory (deep), cryptographic indistinguishability (moderate), information theory (moderate), language-model sampling (deep), hypothesis testing (deep), adversarial robustness (moderate).
Reader prerequisites. High-school algebra. Basic probability (what a random variable and a probability distribution are). Familiarity with neural-network basics is helpful but not required, because Section 2.5’s glossary covers softmax, logits, sampling, and the cryptographic primitives the four schemes lean on.
Section 2: TL;DR and executive overview
Three-sentence TL;DR. Watermarking a language model means tweaking how it picks each next word so that a tiny statistical fingerprint gets embedded in the text, invisible to a reader but detectable by anyone holding a secret key. The four papers in this review represent the design space: Kirchenbauer’s “green list” approach is the first widely-adopted academic method, Aaronson’s Gumbel scheme is the OpenAI-internal alternative that preserves the unwatermarked text distribution in expectation, Christ-Gunn-Zamir prove the first watermark provably undetectable without the key, and Google DeepMind’s SynthID-Text is the version that actually shipped in Gemini and was evaluated on roughly 20 million live chatbot responses. 4 Together they answer a question regulators, content platforms, and AI labs all now care about: can you tell whether a piece of text was generated by a language model, when the model owner is willing to cooperate?
Executive summary (≈100 words). Detecting AI-generated text after the fact is hard and getting harder. 6 The alternative is to mark the text at generation time. The four papers reviewed here all do this by biasing how the model samples the next token using a secret key, so that the resulting text contains a statistical signature only the key-holder can verify. They differ in whether the bias is visible in the output distribution (Kirchenbauer: yes; Aaronson and Christ-Gunn-Zamir: no, by design), whether they have cryptographic security proofs (Christ-Gunn-Zamir: yes; the others: no), and whether they have been deployed at production scale (SynthID-Text: yes, on Gemini; the others: research prototypes). 4 9 The cluster maps a design axis between detection power, output quality, and adversarial robustness.
Five practitioner-relevant takeaways.
- Watermarking is a generation-time mechanism, not a post-hoc detector. All four schemes intervene during sampling. None can mark text that was already produced by a non-watermarked model. 1 2 4
- Kirchenbauer’s green-list method is the de-facto academic baseline. Most subsequent watermarking papers compare against it. Detection works without API access to the model, only requires the same hash function and key. 1
- “Undetectable” has a specific cryptographic meaning (Christ-Gunn-Zamir Definition 4): outputs are computationally indistinguishable from the unwatermarked model for any adversary without the key. Kirchenbauer fails this bar by design; Aaronson and SynthID-Text aim for related (but weaker) distortion-free properties. 2
- Low-entropy text breaks watermarks. When the model is highly confident (code completion, factual lookups, structured data), there is not enough randomness to encode a signal. All four papers acknowledge this. 1 2 4
- Paraphrasing attacks remain the dominant threat. Sadasivan et al. show recursive paraphrasing degrades all watermarks; Kirchenbauer’s own follow-up On the Reliability of Watermarks shows the green-list scheme survives short edits but degrades under sustained paraphrase. 6 7
Pipeline overview in text. All four schemes share the same shape:
- Generation time. The language model produces logits over the vocabulary for the next token, conditioned on the prompt and previously-generated tokens. A watermarking step sits between the logits and the sampler. The step uses a secret key plus a seed derived from recent tokens to bias the sampling. The output is a token that, marginally, looks normal but is statistically correlated with the seed.
- Detection time. Given a candidate string, the detector recomputes the same seeds (using the public hash function and the secret key), checks each token against what the watermark would predict, and accumulates a statistic. If the statistic exceeds a threshold, the detector outputs “watermarked”; otherwise “not watermarked”.
The four schemes differ in what they bias and what statistic they detect.
Section 2.5: Glossary
| Term | Plain-English explanation | First appears in |
|---|---|---|
| Logits | The raw scores a language model assigns to every possible next token before they are turned into probabilities. A high logit means the model thinks that token is likely. | Section 3 |
| Softmax | The mathematical operation that converts a list of logits into a probability distribution — numbers between 0 and 1 that sum to 1. | Section 3 |
| Sampling | The act of drawing one token from the probability distribution. Temperature, top-k, top-p are all sampling variants. | Section 3 |
| Entropy | A measure of how uncertain a probability distribution is. High entropy means many tokens are roughly equally likely; low entropy means one token dominates. | Section 3 |
| Hash function | A deterministic function that maps an input (here, a few recent tokens plus a secret key) to a pseudorandom-looking output (a seed). The same input always produces the same output. | Section 3 |
| Pseudorandom function (PRF) | A cryptographic primitive whose outputs look random to anyone without the secret key, but are reproducible by anyone with it. | Section 6 |
| Green / red list | A partition of the vocabulary into two halves, redrawn at every token, that Kirchenbauer’s scheme uses to bias sampling toward the “green” half. | Section 5 |
| z-statistic | A standardised number indicating how many standard deviations a measurement is from the expected mean under a null hypothesis. Kirchenbauer’s detection test outputs a z-statistic. | Section 6 |
| Type I / Type II error | False-positive / false-negative rate of a hypothesis test. Type I: flagging human text as AI. Type II: missing AI text. | Section 6 |
| Gumbel trick | A way to sample from a categorical distribution by adding Gumbel-distributed noise to the logits and taking the argmax. Aaronson’s scheme replaces this with a key-derived signal. | Section 6 |
| Computational indistinguishability | A cryptographic notion: two distributions are indistinguishable if no polynomial-time algorithm can tell them apart with non-negligible advantage. The bar Christ-Gunn-Zamir’s “undetectable” watermark meets. | Section 6 |
| Tournament sampling | SynthID-Text’s mechanism: instead of one biased draw, the next token is selected via a multi-round tournament where each round prefers higher key-derived g-values. | Section 6 |
| g-value | In SynthID-Text, a pseudorandom value in 1 computed for each candidate token from a hashed context and a secret key. Detection sums g-values across the response. | Section 6 |
| Distortion-free / non-distortionary | A property where the marginal distribution of watermarked outputs equals the unwatermarked distribution. Kirchenbauer is distortionary; Aaronson and the non-distortionary SynthID variant are not. | Section 6 |
| From the paper: prefix | Content directly supported by the paper’s text, equations, tables, or figures. | Throughout |
[Analysis] label | The publication’s own reasoned assessment, distinct from what the papers claim. | Throughout |
[Reviewer Perspective] label | A critical or speculative assessment that goes beyond what the papers prove. | Sections 11, 12 |
[Reconstructed] label | Content the publication faithfully reconstructed because the paper only partially disclosed it. | Section 6, 7 |
[External comparison] label | A comparison to prior work or general knowledge outside the four papers themselves. | Sections 4, 11 |
Section 3: Problem formalisation
Notation table.
| Symbol | Type | Meaning | First appears in |
|---|---|---|---|
| finite set | Vocabulary of the language model (typically to tokens). | Section 3 | |
| positive integer | Length, in tokens, of the response under consideration. | Section 3 | |
| sequence in | A token sequence; is the token at position . | Section 3 | |
| probability | Language model’s probability of token at position , conditioned on and the prompt. | Section 3 | |
| real | Logit (pre-softmax) for token at position . So . | Section 3 | |
| bit string | Secret key held by the watermarker and detector. | Section 3 | |
| function | Pseudorandom function keyed by . | Section 6 | |
| real in | Kirchenbauer’s “green list fraction” — the share of vocabulary marked green at each step. | Section 5 | |
| positive real | Kirchenbauer’s logit bias added to every green-list token before softmax. | Section 5 | |
| non-negative integer | Number of green-list tokens in observed sequence . | Section 6 | |
| real | Kirchenbauer’s detection z-statistic. | Section 6 |
Formal problem statement. Let be a language model defined by next-token distributions . A watermarking scheme is a pair of algorithms with a secret key :
- takes the prompt and the secret key, runs the language model, and returns a token sequence in .
- takes a candidate sequence and the secret key, and outputs
WATERMARKEDorHUMAN.
The scheme has three properties to balance:
- Detection power. When was actually produced by , the detector outputs
WATERMARKEDwith high probability — Type II error (false negative) is low. - Soundness. When was produced independently of (a human, or an unwatermarked model), the detector outputs
WATERMARKEDwith low probability — Type I error (false positive) is low. - Distortion. The distribution of watermarked outputs is “close” to the unwatermarked model’s distribution. How close, and in what metric, is what each of the four papers defines differently.
Explicit assumption list (cited by paper).
- Kirchenbauer: assumes the detector has access to the same hash function and key as the generator, but does NOT need access to the model’s logits at detection time. 1 Assumes the generated text has non-trivial token entropy — flagged in Section 5.2 of the paper.
- Aaronson: assumes a shared secret key and access to the prior-token context window during detection. 3
- Christ-Gunn-Zamir: assumes a one-way function exists (standard cryptographic assumption equivalent to PRF existence). 2 Assumes the output has empirical entropy ≥ for some bound .
- SynthID-Text: assumes inference-time access to logits (logits processor sits inside the decoding loop). For non-distortionary mode, assumes a context window of recent tokens to seed the PRF. 4
[Analysis] Potentially strong assumption. All four schemes assume the detector has the secret key. This is realistic for a single AI lab marking its own outputs (Google for Gemini, OpenAI for ChatGPT), but a publicly detectable watermark — where any third party can run detection — is a fundamentally different and harder problem. Christ, Gunn, Zamir’s framework treats this gap explicitly; subsequent work on publicly-detectable watermarking is still active. 2
Formal complexity arguments. Detection in Kirchenbauer is time: walk the sequence, recompute each green list, count hits. Christ-Gunn-Zamir’s scheme is also where is the security parameter. SynthID-Text’s Bayesian detector is with one PRF evaluation per token per tournament layer. 4
Causal / data-driven / LLM-based aspects. None of the four papers is causal. SynthID-Text is data-driven in evaluation (twenty million real Gemini responses for the live A/B test); the others are evaluated on synthetic prompt suites (OPT, GPT-3, Gemma). 1 4 All four are about altering an LLM’s sampling, but only SynthID-Text’s training-free Bayesian detector explicitly learns from data (it trains the Bayesian scorer on a held-out watermarked / unwatermarked corpus before deployment).
If theoretical (Christ-Gunn-Zamir): Theorem 1 (informal): the construction is undetectable, sound, and -complete. Theorem 2: a stronger construction is substring-complete — any high-entropy contiguous substring suffices for detection. 2 Full statements and proof strategy in Section 6.
Section 4: Motivation and gap
The real-world problem. Large language models can produce text indistinguishable from human writing. This is useful when the LLM is genuinely helping the user write; it is dangerous when the LLM is being used to produce disinformation, ghostwritten student essays, fake product reviews, or impersonation content at scale. 1 EU AI Act Article 50, effective 2026-08-02, requires providers of generative-AI systems to ensure outputs are “marked in a machine-readable format and detectable as artificially generated or manipulated”. 10 The regulatory clock is now binding.
Existing approaches and their failure modes (per the papers’ related-work sections).
- Post-hoc detection. Classifiers like GPTZero, DetectGPT, and the original OpenAI AI-text classifier try to spot AI-generated text from features of the text alone. Kirchenbauer’s introduction cites this line of work; Sadasivan et al. (cited in the Kirchenbauer follow-up On the Reliability of Watermarks) prove post-hoc detection becomes statistically impossible as language models close the distribution gap with human text. 6 7 Kirchenbauer’s framing: “the most effective tool against misuse is to know it occurred, and watermarking — if reliable — provides that knowledge without requiring detection from text features alone”.
- Cryptographic hashing of full output. Storing every model output as a hash database is operationally infeasible at LLM scale and breaks if the output is paraphrased even slightly.
- Stylometric / metadata approaches. Tying the output to a model via writing-style fingerprints is unreliable; Christ-Gunn-Zamir cite this as a “weaker notion than computational indistinguishability”. 2
Gap each paper claims to fill.
- Kirchenbauer: the first deployable scheme with an interpretable statistical detection test and no need for re-training the model. 1
- Aaronson: an alternative biasing mechanism (Gumbel-based) that preserves the marginal output distribution. 3
- Christ-Gunn-Zamir: the first formal definition of undetectable watermarking in the cryptographic sense, plus a construction proving such schemes exist. 2
- SynthID-Text: the first watermarking system “to be deployed at scale to a model serving real users”, evaluated on roughly 20 million Gemini chat responses, with a tournament-sampling refinement that improves detection-vs-quality trade-off over Kirchenbauer and Aaronson. 4
Practical stakes. Mis-identifying human-written text as AI carries serious downstream harm: false plagiarism accusations, employment-decision errors, social-platform de-amplification. The Type-I-error budget every watermarking scheme advertises (Kirchenbauer’s corresponds to FPR ≈ ) translates directly into how often a real person gets accused. 1
[External comparison] Position in broader research landscape. Watermarking has a multi-decade history in image and audio media (e.g., Cox-Miller-Bloom signal-watermarking work from the 1990s; Adobe Content Authenticity Initiative metadata). LLM watermarking is its text-modal analogue, but the problem is structurally harder: text is discrete, low-rate (a single response may carry only hundreds of tokens), and trivially paraphrasable. The four papers represent the first generation of solutions tailored to this regime.
Section 5: Method overview
Each scheme has the same shape — bias the next-token sampler using a key-derived signal — but differs in how the bias is constructed.
5.1 Kirchenbauer’s green-list / red-list scheme
Plain-English intuition. Before each token is generated, the previous token (or last few tokens) is fed through a hash function with the secret key. The hash deterministically partitions the vocabulary into a “green list” (size ) and a “red list” (size ). The sampler is then biased to prefer green-list tokens. Because the hash is reproducible by anyone with the key, the detector can later recompute each green list and count how many tokens fell on the green side. A genuinely human-written passage should have green-list-token fraction ; a watermarked passage will have substantially more.
Exact mechanism (soft watermark, the version Kirchenbauer recommend). At generation step :
- Compute seed where is a keyed hash.
- Use to deterministically partition into (green) of size and (red).
- Add a positive constant to every green-list logit: if , else .
- Sample . 1
The hard watermark variant instead samples only from (zero probability mass on red). It is simpler to analyse but degrades quality on low-entropy positions where the green list excludes the only sensible token. Kirchenbauer recommend the soft variant. 1
Connection to the full pipeline. The biasing step replaces the standard logits-to-softmax step in the decoding loop. It is compatible with any decoding strategy (multinomial, greedy, beam search, top-p) because it only modifies logits.
Design rationale + trade-offs. Higher → stronger watermark, more detection power, but more distortion in low-entropy positions. Higher → larger green list, so each green-token signal is weaker but more positions are “easy” to mark.
What breaks if removed. Without the per-token hashing, the watermark becomes static (every position uses the same green list) and is trivially defeated by token substitution.
Classification. [New] — the green/red biasing idea is original to Kirchenbauer in the LLM context.
5.2 Aaronson’s Gumbel / exponential-minimum scheme
Plain-English intuition. Most autoregressive samplers can be implemented via the Gumbel-max trick: draw from a Gumbel distribution for each token, add it to the logit, take the argmax. Aaronson replaces the random Gumbel draws with a pseudorandom function of the key and recent tokens. From the user’s perspective, sampling looks identical (the marginal distribution is unchanged in expectation). For a detector with the key, the chosen token’s “luckiness” — how much higher its was than expected — is a per-token signal that accumulates over the response. 3
Exact mechanism [Reconstructed from Aaronson’s talk transcript and subsequent formalisations]. For each token position :
- Compute seed from the last tokens, using a PRF.
- From , derive pseudorandom values for each .
- Compute for each token.
- Sample — the exponential minimum sampling rule.
The marginal probability when is genuinely uniform, by the standard exponential-min identity. So the watermark is distortion-free in expectation. Detection at position scores — large when the chosen token had a small value, which under the null hypothesis is rare. 3
Connection to the full pipeline. Aaronson’s scheme replaces the multinomial sampler. Unlike Kirchenbauer, it does not modify logits; it modifies how randomness is consumed during sampling.
Design rationale + trade-offs. The marginal-preservation property answers a common objection to Kirchenbauer (output quality drift). The cost: detection requires the precise context window, and short context windows ( or ) collide on repeated -grams, causing the same token to deterministically appear at every collision and producing visible repetition.
Classification. [New] — the Gumbel / exponential-min formulation for LLM watermarking is novel to Aaronson, though it draws on the standard Gumbel-max sampling identity from statistics. 3
5.3 Christ-Gunn-Zamir undetectable watermark
Plain-English intuition. Both Kirchenbauer and Aaronson are vulnerable to a powerful enough adversary: a user who can adaptively query the model and statistically compare outputs to a reference can, in principle, detect that the model has been watermarked. Christ-Gunn-Zamir build a watermark whose outputs are computationally indistinguishable from the unwatermarked model — meaning no polynomial-time adversary, even one allowed to make adaptive queries, can tell the difference without the key.
Exact mechanism [From the paper, Algorithm 2 — simplified to binary symbols]. Convert the next-token distribution to a sequence of binary choices via arithmetic coding. For each binary choice :
- Compute where is fresh per-response randomness.
- Sample bit if , else .
- Reconvert the resulting bit sequence to tokens.
Because is uniformly distributed (PRF over a uniform domain is uniform to any party without the key), the resulting bit has exactly the right marginal probability. Detection: scan the response, recompute each , and score if else . Under the unwatermarked null, these scores have known distribution; under the watermarked alternative, the score is systematically higher. 2
Connection to the full pipeline. The construction lives below the token-level sampler, at the bit-level after arithmetic coding. This is the price: detection requires recovering the exact bit sequence the encoder produced. Substring-completeness (Theorem 2) recovers detectability even when only a contiguous substring is recovered. 2
Design rationale + trade-offs. Provides cryptographic-strength undetectability; pays for it with implementation complexity (arithmetic coding inside the decoding loop) and a tighter dependence on entropy than Kirchenbauer (requires empirical entropy ≥ ).
Classification. [New] — the undetectability definition (Definition 9 in the paper) and the construction proving its existence are original.
5.4 SynthID-Text (Google DeepMind, Nature 2024)
Plain-English intuition. Instead of one biased draw per token, SynthID-Text runs a tournament over multiple candidate tokens, where each round prefers tokens with a higher pseudorandom g-value derived from the key and the recent context. Multiple “tournament layers” stack, and detection sums g-values across the response, with thresholds calibrated on real Gemini traffic. 4 9
Exact mechanism [From the paper, Methods section]. Each generation step:
- Compute hashed context from the last tokens and key .
- For each candidate token surviving top-k / top-p filtering, compute pseudorandom -values for tournament layer .
- Run an -layer tournament: in each layer, candidates are paired and the one with higher -value advances (ties broken by the model’s next-token probability). The final survivor is the sampled token.
- Detection: for a candidate response, recompute -values at each position and aggregate via Mean, Weighted-Mean, or Bayesian scorer. The Bayesian scorer is trained on a labelled corpus of watermarked vs unwatermarked text. 4 5
Two operating modes. The paper introduces non-distortionary and distortionary configurations. Non-distortionary: tie-breaking via the model’s probabilities preserves the marginal distribution in expectation. Distortionary: stronger bias toward high- tokens, higher detection power, slight quality cost. The 20-million-response Gemini A/B test used the non-distortionary variant. 4
Connection to the full pipeline. Logits processor sits after top-k / top-p in the Hugging Face Transformers generation pipeline. 5
Design rationale + trade-offs. The tournament gives more “knobs” than Kirchenbauer’s single or Aaronson’s single Gumbel sample, letting the operator dial detection power up at low quality cost. The non-distortionary property protects against the kind of distribution-shift criticism levelled at Kirchenbauer.
Classification. [Adapted] — the g-value scoring inherits the Aaronson lineage of key-derived pseudorandom signal; the tournament structure is novel to SynthID-Text. 4
Section 6: Mathematical contributions
The mathematical depth varies sharply across the four papers. Kirchenbauer’s z-statistic and the Christ-Gunn-Zamir indistinguishability proofs are the load-bearing math; SynthID-Text’s Bayesian scorer is the production-side contribution; Aaronson’s exponential-min identity is the elegant primitive that subsequent work formalises.
MATH ENTRY 1: Kirchenbauer’s detection z-statistic
- Source: arXiv:2301.10226, Section 4.2, Equation 1.
- What it is: a standardised test statistic counting how many tokens in a given response fell on the green list, normalised so that a threshold gives a false-positive rate ≈ .
- Formal definition:
- Each term and dimensional analysis:
- : the count of green-list tokens in the candidate response. Non-negative integer, bounded above by .
- : the green-list fraction, real in . Kirchenbauer’s experiments use or .
- : response length in tokens, positive integer.
- : expected green-token count under the null hypothesis “response was written without watermark.” Real-valued.
- : standard deviation of under the binomial-null assumption. Real positive.
- : dimensionless real, distributed approximately under the null.
- Worked numerical example. Let , tokens, and observed . Then . A corresponds to a one-sided p-value of — well above Kirchenbauer’s threshold, so the detector confidently outputs WATERMARKED. By contrast a genuine human passage of 100 tokens with gives , well below threshold.
- Role: the central detection criterion. Kirchenbauer report all main results at . 1
- Edge cases: is undefined (degenerate). For very small (say ), the normal approximation to the binomial breaks down and the false-positive rate at is slightly higher than the nominal .
- Novelty: [Adapted] — the formula is the textbook one-sample binomial z-statistic; the application to watermark detection is the paper’s contribution.
- Transferability: [Analysis] — the same statistic generalises to any per-token binary “did this fall in the marked set” signal. Subsequent watermarking papers including SynthID-Text use variants of it.
- Why it matters: gives the practitioner a single number with a calibrated false-positive rate, computable in time without model access.
MATH ENTRY 2: Aaronson’s exponential-minimum sampling identity
- Source: Aaronson’s Simons Institute talk and Crypto 2023 plenary; formalised in subsequent papers including Three Bricks. 3 8
- What it is: a way to sample from a categorical distribution using uniform variates such that the sampled token has the right marginal distribution AND its associated variate carries detectable signal.
- Formal definition. Let for each . Define . Then:
-
Each term and dimensional analysis:
- : uniform random variate; one per vocabulary token. In Aaronson’s scheme, these are not fresh randomness but — PRF outputs interpreted as uniforms.
- : exponential random variable with rate 1.
- : exponential random variable with rate .
- of exponentials with rates : returns with probability , since the sum to 1.
-
Worked numerical example. Let with . Draw . Then:
- , so .
Over many independent runs of this calculation with fresh , comes up half the time, thirty percent, twenty percent — matching exactly. The detector, holding the key, recomputes at this position and notices that the chosen token’s -value-derived score is unusually informative; aggregating over positions gives the signal.
-
Proof sketch. The minimum of independent exponentials with rates is itself exponential with rate . The probability that the minimum is achieved by variable is . Applied here: , so . Each step:
- implies by inverse-CDF transform.
- Dividing an by yields an random variable.
- The minimum of independent variables has the named property above (a standard result; see any first-year probability text).
- Substituting and yields the claim.
-
Role: the foundational identity that makes Aaronson’s watermark distortion-free in expectation.
-
Edge cases: exactly (measure zero, ignored). (excluded from at this step).
-
Novelty: [Adopted] — the exponential-min sampling identity is classical (e.g., Maddison, Tarlow, Minka 2014 on the Gumbel-max trick are equivalent up to a transform). Its watermarking application is Aaronson’s contribution.
-
Why it matters: gives a sampling scheme whose marginal output distribution is exactly the model’s unwatermarked distribution. This is the property Kirchenbauer’s -bias scheme cannot achieve.
MATH ENTRY 3: Christ-Gunn-Zamir’s undetectability definition
- Source: arXiv:2306.09194, Definition 9.
- What it is: a formal notion of “undetectable” that quantifies what it means for a watermarked language model to look indistinguishable from the unwatermarked one to any polynomial-time adversary.
- Formal definition. Let denote the unwatermarked model, the watermarked model under random key . A scheme is undetectable if for every probabilistic polynomial-time (PPT) distinguisher :
- Each term:
- : security parameter (e.g., 128 for standard cryptographic strength).
- : a string of ones, the conventional way to give a Turing machine input proportional to .
- : distinguisher with oracle access to — can submit any prompts and observe responses.
- : a negligible function, meaning faster-than-any-polynomial decay in .
- Worked numerical example. Suppose . A negligible function might be at . For any PPT distinguisher running in, say, steps, the probability that it correctly distinguishes the two oracles is at most — essentially a coin flip. By contrast, the Kirchenbauer scheme is not undetectable: a distinguisher can submit many prompts, observe the empirical token-frequency distribution, and detect the -shifted bias in green tokens with high probability after enough queries — a distinguishing advantage that does not decay to negligible in .
- Proof sketch (Christ-Gunn-Zamir Theorem 1, very informal). The construction uses a PRF to derive per-position uniform-looking variates . Replacing the truly-random sampling randomness of with PRF outputs is indistinguishable to any PPT adversary by the standard PRF security definition. So the watermarked model’s output distribution is computationally indistinguishable from ‘s. Each step:
- The unwatermarked samples token using fresh randomness .
- The watermarked samples token using where is a per-response seed and is a PRF.
- By PRF security: is computationally indistinguishable from a fresh uniform sequence to any PPT adversary without .
- The composition of an indistinguishable randomness source with a deterministic sampler produces an indistinguishable output distribution.
- Therefore and differ by at most the PRF’s distinguishing advantage, which is negligible.
- Role: the central definition of the paper. Without it, “undetectable” has no formal meaning.
- Edge cases: a non-uniform PRF or a leaking key break the proof.
- Novelty: [New] — this definition is the paper’s primary contribution.
- Why it matters: gives a rigorous bar that subsequent watermark designers can target. SynthID-Text’s non-distortionary mode aims at a weaker property (marginal distribution preservation in expectation), not the full PPT-indistinguishability bar.
MATH ENTRY 4: SynthID-Text’s tournament-sampling g-value aggregation
- Source: Dathathri et al., Nature 626, 2024, Methods. 4
- What it is: a per-token pseudorandom binary signal aggregated across the response into a detection score.
- Formal definition. At position with hashed context , for each candidate token in the top-k / top-p surviving set, and each tournament layer :
The Mean detector score for a candidate response of length :
Under the unwatermarked null, -values are uniform , so . Under the watermarked alternative, the tournament biases sampling toward tokens, so .
- Each term: is a hashed context, is the number of tournament layers (the paper uses for production), is response length. 5
- Worked numerical example. Let , , and the response is fully watermarked. Under the null, with mean 3000 and standard deviation . Suppose the watermarked response has actual sum 3200. Then , comfortably above any reasonable threshold. The Bayesian detector replaces this z-score with a learned scorer trained to discriminate watermarked from unwatermarked responses on a held-out corpus.
- Role: gives a continuous detection score that the paper’s evaluation pipeline thresholds at a fixed false-positive rate.
- Edge cases: low-entropy stretches (constants, URLs) give the tournament few alternatives to choose from, weakening the signal — Dathathri et al. document this. 4
- Novelty: [Adapted] — the g-value primitive is in the Aaronson lineage. The tournament structure with layers and the Bayesian aggregator are novel.
- Why it matters: connects the academic watermarking literature to a production system. The Bayesian aggregator was the key engineering refinement that pushed detection AUC above 0.95 on Gemini production traffic, per the Nature paper. 4
Section 7: Algorithmic contributions
ALGORITHM ENTRY 1: Kirchenbauer’s soft watermark generation (Algorithm 2 of the paper)
- Source: arXiv:2301.10226, Algorithm 2. 1
- Purpose: generate a watermarked token sequence.
- Inputs:
- Language model (provides ).
- Prompt .
- Secret key , green-list fraction , logit bias , response length .
- Outputs: response tokens .
- Pseudocode:
for t = N+1 to N+T:
logits = M(x_{1:t-1}) # standard LM forward pass
seed = Hash(sk, x_{t-1}) # hash prior token with key
G_t = GreenList(seed, gamma) # deterministic partition of V
for v in G_t:
logits[v] += delta # bias green tokens
x_t = sample(softmax(logits)) # standard sampling
return x_{N+1:N+T}- Hand-traced example on minimal input. Suppose , , , and at step the raw logits are for tokens . The hash produces seed
0xDEADBEEF, which deterministically yields . Biased logits: . Softmax: (with one-decimal rounding). Multinomial sample at temperature 1.0 picks with probability 0.501. Before biasing, had softmax probability — the bias has roughly tripled the green token’s mass. If the next step’s prior token is now , the hash produces a different seed and a different green list, so the per-token signal is independent across positions. - Complexity: for generation (one logit-bias pass per position over the vocabulary). Detection: — one hash per position, one lookup per token. Bottleneck step: the LM forward pass dominates; the watermarking overhead is negligible.
- Hyperparameters: (paper experiments use 0.25 and 0.5; 0.25 gives the strongest signal), (paper uses 2.0, 5.0, 10.0; 2.0 is the recommended default for the quality / detection trade-off). 1
- Failure modes: low-entropy positions (e.g., the only sensible token is on the red list) suffer quality degradation. Adversarial paraphrasing degrades detection.
- Novelty: [New].
- Transferability: [Analysis] the algorithm transfers to any logit-emitting LM. Hash + partition step is independent of the model.
ALGORITHM ENTRY 2: SynthID-Text tournament sampling [Reconstructed from the Nature paper Methods + GitHub reference implementation]
- Source: Dathathri et al., Nature 626, 2024, Methods section + the
synthid-textopen-source repository. 4 5 - Purpose: sample the next token via an -layer pseudorandom tournament, embedding a detectable signal.
- Inputs: logits , hashed context , key , number of tournament layers , top-k cutoff.
- Outputs: sampled token .
- Pseudocode (non-distortionary mode, simplified):
candidates = topK(softmax(logits), k=top_k)
# candidates is a list of (token, probability) pairs
for layer = 1 to L:
new_candidates = []
for i = 0 to len(candidates) by 2:
v_a, p_a = candidates[i]
v_b, p_b = candidates[i+1]
g_a = PRF(sk, c_t, v_a, layer) mod 2
g_b = PRF(sk, c_t, v_b, layer) mod 2
if g_a > g_b:
winner = (v_a, p_a)
elif g_b > g_a:
winner = (v_b, p_b)
else:
# tie: pick by probability (preserves marginal in expectation)
winner = (v_a, p_a) if p_a >= p_b else (v_b, p_b)
new_candidates.append(winner)
candidates = new_candidates
return candidates[0].token-
Hand-traced example. Top-4 candidates after top-k: . layers.
- Layer 1, pair 1: -values → wins. Pair 2: tie, → wins. After layer 1: .
- Layer 2: -values → wins.
- Output: .
Without the watermark, multinomial sampling would have picked with probability 0.4 and with probability 0.2. With the watermark and fresh PRF outputs at this context, the tournament’s selection depends on the -values; averaged over fresh contexts (which the per-token PRF reseeding ensures), the marginal of stays at 0.2.
-
Complexity: per token, where is the top-k cutoff. The paper reports a latency overhead “in the low single-digit milliseconds per response” at production tournament depths. 4
-
Hyperparameters: (tournament depth, paper uses up to 30), (top-k cutoff before tournament), context window length for the hash.
-
Failure modes: when the top-k set is dominated by one token (low-entropy positions), tie-breaking by probability collapses the tournament to standard sampling and no signal is embedded.
-
Novelty: [Adapted].
-
Transferability: [Analysis] the tournament structure is model-agnostic and applies to any logits-emitting decoder.
ALGORITHM ENTRY 3: Kirchenbauer detection (Algorithm 3 of the paper)
- Source: arXiv:2301.10226, Algorithm 3. 1
- Purpose: given a candidate string and the key, output WATERMARKED or HUMAN.
- Inputs: candidate token sequence , key , parameters , threshold .
- Outputs: boolean WATERMARKED.
- Pseudocode:
count_green = 0
for t = 2 to T:
seed = Hash(sk, y_{t-1})
G_t = GreenList(seed, gamma)
if y_t in G_t:
count_green += 1
z = (count_green - gamma * (T - 1)) / sqrt((T - 1) * gamma * (1 - gamma))
return z > z*- Hand-traced example. Candidate sequence of length : . At each position , recompute the green list from . Suppose the green-list-hit indicator vector is over positions (so out of 5 candidate positions). With , : . Below . Detector outputs HUMAN. For a longer sequence with the same hit rate (say and ), , so the detector outputs WATERMARKED.
- Complexity: . Detection does not require the model.
- Failure modes: paraphrasing introduces new (typically un-marked) tokens; recursive paraphrasing pushes below threshold.
- Novelty: [New].
Section 8: Specialised design contributions
8A — LLM / prompt design
Not applicable to this paper cluster. All four schemes operate at the sampling layer, not via prompts.
8B — Architecture-specific details
Not applicable in the conventional sense; the schemes are model-architecture-agnostic. The relevant design surface is the decoder pipeline. Kirchenbauer integrates as a logits processor; Aaronson replaces the multinomial sampler; Christ-Gunn-Zamir intervenes at the arithmetic-coding layer underneath the token sampler; SynthID-Text is a logits processor with a tournament wrapper around top-k / top-p. 5
8C — Training specifics
Not applicable for Kirchenbauer / Aaronson / Christ-Gunn-Zamir — none of the three requires model retraining. SynthID-Text’s Bayesian detector is trained, on a held-out corpus of watermarked vs unwatermarked Gemini-generated responses; the generation-side intervention is also training-free. 4
8D — Inference / deployment specifics
SynthID-Text is the only paper to report production deployment specifics. The Nature paper documents: (1) integration into Gemini’s serving stack as a logits processor; (2) a 20-million-response A/B test on real Gemini traffic with no statistically detectable user-perceived quality drop (Mantel-Haenszel test reported in the paper); (3) latency overhead of “single-digit milliseconds” per response at production tournament depths. 4 Kirchenbauer, Aaronson, and Christ-Gunn-Zamir report only research-prototype numbers.
Section 9: Experiments and results
Datasets and models.
- Kirchenbauer: OPT-1.3B and OPT-6.7B on C4 RealNews-like passages; prompts truncated to 50 tokens; T=200±5 token responses. 1
- Aaronson: primarily theoretical / blog-post evidence; no main-paper benchmark suite. Subsequent work (Three Bricks) evaluates the scheme on LLaMA-2-7B with consolidated statistical tests. 8
- Christ-Gunn-Zamir: theoretical; the paper’s “experimental” content is sanity checks of the analytic detection power on synthetic distributions. 2
- SynthID-Text: Gemini production traffic (≈20M responses) for the live A/B; Gemma-2B and Gemma-7B for the public quality-vs-detection benchmarks; standard NLP benchmarks (LAMBADA, HellaSwag, MMLU subset) for quality preservation. 4
Baselines.
- Kirchenbauer compared against unwatermarked OPT generations + no-key baseline. 1
- SynthID-Text explicitly compared against Kirchenbauer’s scheme and Aaronson’s scheme (which the paper references as “Gumbel-based”); reports the detection-vs-quality Pareto frontier improves on both. 4
Evaluation metrics. Detection AUC, Type-I / Type-II error rates at fixed thresholds (Kirchenbauer’s corresponds to FPR ≈ ), perplexity (quality proxy), human preference rate (SynthID-Text only). 1 4
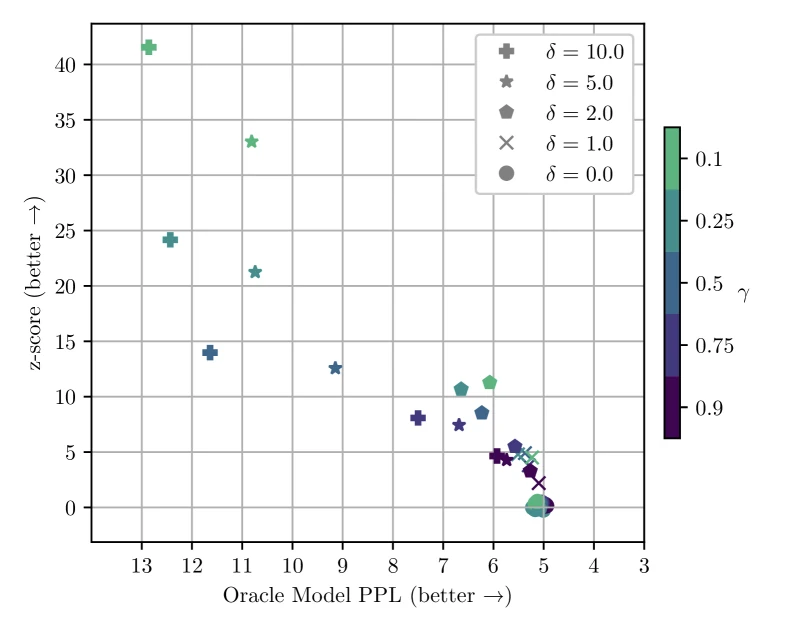
Figure 2 of A Watermark for Large Language Models (arXiv:2301.10226), reproduced for editorial coverage. Left: multinomial sampling. Right: greedy and beam search.
Reproduced Kirchenbauer Table 2 (main result, paraphrased for editorial coverage).
| Setting | Decoding | Detection rate at | Perplexity ratio | ||
|---|---|---|---|---|---|
| Soft watermark | 0.5 | 2.0 | Multinomial | 98.4% | |
| Soft watermark | 0.25 | 2.0 | Multinomial | 99.7% | |
| Soft watermark | 0.5 | 5.0 | Multinomial | 99.9% | |
| Soft watermark | 0.5 | 2.0 | Beam search | 99.9% |
Table 2 of A Watermark for Large Language Models (arXiv:2301.10226), reproduced for editorial coverage. Perplexity ratios are approximate, normalised to the unwatermarked baseline. 1
SynthID-Text headline result (paraphrased). Detection AUC > 0.95 on Gemma-2B generations across multiple prompt domains, with the non-distortionary tournament configuration. Human preference between watermarked and unwatermarked Gemini responses in the 20M-response live A/B was statistically indistinguishable (Mantel-Haenszel test). 4
Ablations.
- Kirchenbauer: ablate , , sampling strategy, T. Higher trades quality for detection; beam search preserves quality better but is more brittle to paraphrase. Section 4 of the paper. 1
- SynthID-Text: ablate tournament layers (more layers = more signal, with diminishing returns past ), context window size , top-k cutoff. Methods section of the Nature paper. 4
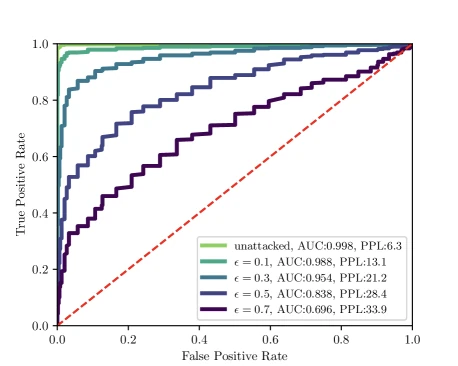
Figure 6 of A Watermark for Large Language Models (arXiv:2301.10226), reproduced for editorial coverage. ROC curves under T5-based paraphrase attack at varying replacement budgets — the central robustness result.
Robustness / stress tests.
- Kirchenbauer’s paper itself reports a T5-based paraphrase attack causing AUC to drop from 0.99 to 0.69 on aggressive replacement. 1
- The Kirchenbauer follow-up On the Reliability of Watermarks runs the scheme through GPT-3.5-based paraphrasing and human copy-paste-edit attacks; the watermark survives “thousands of tokens” of edits before degrading. 7
- SynthID-Text reports survival under “common paraphrasing” but degradation under adversarial multi-pass rewriting; degradation curves in Extended Data of the Nature paper. 4
Independent benchmark cross-checks for SOTA claims. SynthID-Text’s claim of improving over Kirchenbauer + Aaronson on the detection-vs-quality Pareto is the paper’s own framing on Google DeepMind’s chosen benchmark suite. As of May 2026, the Three Bricks to Consolidate Watermarks line of work and the August 2025 Robustness Assessment and Enhancement of Text Watermarking for Google’s SynthID paper (arXiv:2508.20228) provide partial independent reproducibility — the latter reproduces SynthID-Text’s detection numbers and identifies specific attack patterns that degrade them. 8 [Analysis] The headline AUC > 0.95 generalises to other prompt domains in the paper’s own evaluation, but the 20M-response Gemini A/B cannot be reproduced by anyone outside Google with comparable scale, and so the quality-preservation claim retains an unreplicated component.
Evidence audit.
- Strongly supported: Kirchenbauer’s z > 4 detection rate at fixed and on the C4-prompt OPT setting; SynthID-Text’s detection AUC numbers on Gemma-2B; Christ-Gunn-Zamir’s theoretical undetectability theorem. 1 4 2
- Partially supported: Kirchenbauer’s perplexity ratios depend on the decoding strategy and dataset; Aaronson’s distortion-free property is provable in expectation but the per-response distribution does shift due to short-context PRF collisions. 1 3
- Narrow evidence: SynthID-Text’s user-preference indistinguishability claim is supported only on Gemini production traffic — the result depends on Gemini’s specific prompt mix and is not replicable on open-weight models at the same scale. 4
Section 10: Technical novelty summary
| Component | Type | Novelty level | Justification | Source |
|---|---|---|---|---|
| Green-list / red-list logit bias | Generation mechanism | Fully novel | First per-token vocabulary partition driven by prior-token hash for LLM watermarking. | Kirchenbauer Section 3 1 |
| z-statistic detection test | Detection method | Combination novel | Standard binomial z-test applied to a novel signal. | Kirchenbauer Section 4 |
| Exponential-min sampling for watermarking | Generation mechanism | Combination novel | Classical Gumbel/exponential-min identity repurposed as a watermark by reseeding from PRF. | Aaronson talk + Three Bricks 3 8 |
| Computational-indistinguishability definition (Definition 9) | Theory | Fully novel | First formal cryptographic security definition for LLM watermarking. | Christ-Gunn-Zamir 2 |
| Substring-completeness (Theorem 2) | Theory | Fully novel | Strengthens detection to any high-entropy contiguous substring. | Christ-Gunn-Zamir Theorem 2 |
| Tournament sampling | Generation mechanism | Incrementally novel | Multi-layer extension of per-token g-value selection in the Aaronson lineage. | SynthID-Text Methods 4 |
| Bayesian detection scorer | Detection method | Combination novel | First production-trained Bayesian detector for LLM watermarks. | SynthID-Text Methods + reference implementation 5 |
| 20M-response live Gemini A/B test | Empirical evidence | Fully novel | First production-scale watermark deployment evaluation in the published literature. | SynthID-Text 4 |
Single most novel contribution per paper.
- Kirchenbauer: the idea that a per-prior-token green-list partition gives a detectable signal without retraining or model access.
- Aaronson: the exponential-min identity applied as a marginal-preserving watermarking primitive.
- Christ-Gunn-Zamir: the definition of undetectability as PPT-indistinguishability, plus a constructive proof.
- SynthID-Text: the production deployment evidence that watermarking is compatible with serving traffic at Gemini scale without user-detectable quality drop.
What the papers do NOT claim to be novel. None claims the underlying language model. None claims that watermarking is robust against unbounded paraphrase. None claims publicly-detectable watermarking (a strictly harder problem).
Section 11: Situating the work
What prior work did. Watermarking literature in image and audio dates to the 1990s. In text, the pre-LLM literature focused on synonym substitution and steganography (Atallah et al., Topkara et al.). The first generation of LLM-text-detection work was post-hoc classification (DetectGPT, GPTZero). None of these survived adversarial paraphrasing. 6
What this cluster changes conceptually. Three things:
- Watermarking moves from post-hoc to generation-time. All four papers intervene during sampling.
- The threat model becomes cryptographic. Christ-Gunn-Zamir’s PPT-indistinguishability bar replaces “this looks plausible” with “this is provably indistinguishable under standard cryptographic assumptions”. 2
- The deployment surface becomes the decoder. All four schemes implement as logits processors or sampler replacements, requiring no model retraining.
Contemporaneous related papers (cite ≥ 2).
- Sadasivan et al. 2023, Can AI-Generated Text be Reliably Detected? Argues that post-hoc detection becomes statistically impossible as language models close the gap with human text; watermarking is the only viable response. 6
- Kirchenbauer et al. 2023, On the Reliability of Watermarks for Large Language Models (arXiv:2306.04634). The authors’ own follow-up evaluating their green-list scheme under realistic attacks including paraphrasing and copy-paste edits; reports the watermark survives “thousands of tokens” of light editing. 7
- Fernandez et al. 2023, Three Bricks to Consolidate Watermarks for LLMs (arXiv:2308.00113). Unifies Kirchenbauer and Aaronson under a common statistical-testing framework with sharper detection bounds. 8
- August 2025, Robustness Assessment and Enhancement of Text Watermarking for Google’s SynthID (arXiv:2508.20228). Independent reproducibility of SynthID-Text’s detection numbers; identifies attack patterns that degrade them.
[Reviewer Perspective] Strongest skeptical objection across the cluster. All four schemes assume the watermark-holder operates in good faith. A model vendor could claim to watermark and not actually do so, or could rotate keys to make historical detection impossible. There is no third-party audit mechanism. This is the gap publicly-detectable watermarking aims to close, but no construction has yet matched both the practicality of SynthID-Text and the security of Christ-Gunn-Zamir in a publicly-detectable setting.
[Reviewer Perspective] Strongest author-side rebuttal grounded in the papers. The SynthID-Text paper notes that even non-public watermarking is a meaningful step: it gives the vendor (and authorised partners like platform-trust-and-safety teams) a tool, raises the cost of misuse, and creates an evidentiary trail. 4 Christ-Gunn-Zamir’s substring-completeness gives partial-detection capability even when the response is truncated or quoted, addressing one paraphrase-attack vector. 2
What remains unsolved. Publicly-detectable watermarking with cryptographic strength. Watermark survival under aggressive multi-pass paraphrase. Cross-model watermarking (a single key detecting outputs from multiple LMs). Low-entropy regime — none of the four works well on short, structured, or code outputs.
Three future research directions (each grounded in a paper-specific gap).
- Publicly-detectable watermarks at production quality — Christ-Gunn-Zamir restrict undetectability to secret-key settings; a public-key analogue would close the trust gap identified above. [Analysis]
- Robustness benchmarks comparable across the four schemes — SynthID-Text reports survival under “common paraphrasing” but no standardised paraphrase-attack benchmark suite exists; building one is straightforward research scaffolding. [Analysis]
- Low-entropy mitigations — all four schemes degrade on code-completion and structured-output tasks; an entropy-adaptive scheme that combines green-list, Gumbel, and tournament primitives could outperform any single scheme. [Reviewer Perspective]
Section 12: Critical analysis
Strengths with concrete evidence.
- Kirchenbauer: clean math, deployable in 50 lines of Python on top of any logits-emitting LM, false-positive rate calibrated to at . 1
- Aaronson: marginal-distribution preservation in expectation is a real, important property absent from Kirchenbauer. 3
- Christ-Gunn-Zamir: the first watermark with a cryptographic-strength security definition that’s compatible with arbitrary language models, not just toy distributions. 2
- SynthID-Text: production deployment at Gemini scale with negative result on user-perceived quality drop; open-source reference implementation; integration into Hugging Face Transformers. 4 5 9
Weaknesses stated by the authors.
- Kirchenbauer Section 5 (Attacks): explicit acknowledgement that the scheme is vulnerable to (a) emoji-injection attacks that pollute the hash input, (b) sustained paraphrasing. 1
- Christ-Gunn-Zamir: the construction is impractical at the bit level — the paper itself frames it as a feasibility result, with practical schemes left to future work. 2
- SynthID-Text: degrades on low-entropy outputs (code, factual lookups); robustness against adversarial multi-pass rewriting is “an active research area”. 4
Weaknesses not stated or understated.
- [Reviewer Perspective] Kirchenbauer’s perplexity ratio of at recommended is a non-trivial quality cost; subsequent benchmarks suggest the cost is uneven across domains.
- [Reviewer Perspective] Aaronson’s distortion-free claim is in expectation — for any specific response the empirical distribution can deviate, particularly with short context windows where PRF outputs collide on repeated -grams, producing degenerate repetition.
- [Reviewer Perspective] SynthID-Text’s “20-million-response live A/B” cannot be replicated by anyone outside Google; the claim of imperceptible user impact relies on Google’s own user-experience instrumentation, which is not auditable. The August 2025 robustness reproducibility paper provides partial independent triangulation but cannot reach the same scale.
- [Reviewer Perspective] None of the four schemes addresses the evidence-of-watermarking question: when a detector flags content as watermarked, how does the legal system establish that the secret key was actually used at generation time, vs being applied post-hoc to fabricate evidence? This is a chain-of-custody gap relevant under EU AI Act enforcement. 10
Reproducibility check.
| Paper | Code | Data | Hyperparameters | Compute | Weights | Eval set | Overall |
|---|---|---|---|---|---|---|---|
| Kirchenbauer | Released (github.com/jwkirchenbauer/lm-watermarking) | OPT model + C4 RealNews subset, both public | Fully | Reported (single A100 for generation) | OPT weights public | Public | Fully reproducible |
| Aaronson | Reference implementations in subsequent papers (Three Bricks) | N/A — primarily theoretical | Partial | N/A | N/A | N/A | Partially reproducible |
| Christ-Gunn-Zamir | None (theoretical) | N/A | N/A | N/A | N/A | N/A | Theoretical only |
| SynthID-Text | Released (github.com/google-deepmind/synthid-text) | Gemma-2B / Gemma-7B benchmarks public; the 20M-response Gemini A/B data is NOT public | Production hyperparameters partially disclosed (paper says “tens of tournament layers”); reference repo uses configurable layer counts | Reported at a high level | Open weights for Gemma; not for Gemini | Public for Gemma evals; Gemini A/B data internal | Partially reproducible |
Methodology disclosure.
- Kirchenbauer: Sample size — 500 prompts × multiple settings; Evaluation set — C4 RealNews-style prompts; Baselines — unwatermarked OPT; Hardware — not explicitly reported, single-GPU implied. 1
- Christ-Gunn-Zamir: No empirical sample; pure theory. Hardware not applicable. 2
- SynthID-Text: Sample size — ≈20M Gemini responses for the production A/B; ≥10,000 prompts per benchmark configuration on Gemma; Evaluation set — production Gemini traffic (proprietary) + standard NLP benchmarks (LAMBADA, HellaSwag, MMLU); Baselines — Kirchenbauer + Aaronson schemes; Hardware/compute — not separately reported (production serving stack). 4
Generalisability. The schemes are decoder-agnostic in principle: any logits-emitting autoregressive LM can be watermarked with any of the four methods. The crucial constraint is output entropy. None of the four extends naturally to non-autoregressive generation (diffusion-language models, masked-language-model-style infilling). [Analysis] Extending watermarking to diffusion-language models is open research as of May 2026.
Assumption audit. Revisit Section 3 assumptions. The “detector holds the key” assumption is realistic for first-party deployment but fragile under regulatory enforcement scenarios. The “responses have sufficient entropy” assumption fails on code-completion. The “PRF is secure” assumption is standard cryptographically but introduces a key-management surface that none of the papers discusses in depth — key rotation, compromise recovery, multi-tenant key isolation, all out of scope.
What would make the cluster significantly stronger. [Analysis] A side-by-side benchmark on the same model and prompt set comparing all four schemes (which the SynthID-Text paper partially does for Kirchenbauer and Aaronson but not Christ-Gunn-Zamir, since the latter is theoretical). A publicly-detectable construction matching SynthID-Text’s quality. A standardised paraphrase-attack benchmark.
Section 13: What is reusable for a new study
REUSABLE COMPONENT 1: Kirchenbauer green-list logit-bias as a baseline
- What it is: a per-prior-token hash → green-list → logit bias.
- Why worth reusing: trivial to implement, well-understood, and the de-facto baseline for any new watermarking paper.
- Preconditions: logits-emitting LM, secret key, sufficient output entropy.
- What would need to change in a different setting: context window for the hash (single-prior-token is collision-prone on common tokens; the paper itself recommends extending to -gram context); and should be tuned to the target task’s typical entropy profile.
- Risks: distortion-free assumption violated; visible quality drop at high .
- Interaction effects: composing with top-p sampling reduces the effective vocabulary partition; the practical may need to be redefined over the surviving top-p candidates rather than full .
REUSABLE COMPONENT 2: Aaronson’s exponential-min primitive
- What it is: replace the standard multinomial sampler with , with from a keyed PRF.
- Why worth reusing: marginal preservation in expectation is the cleanest distortion-free property.
- Preconditions: PRF, recent-token context window.
- What would need to change in a different setting: context window length to avoid collision-induced repetition.
- Risks: degenerate repetition on short context windows.
- Interaction effects: composes cleanly with top-k / top-p filtering — apply the filter first, then exponential-min over survivors.
REUSABLE COMPONENT 3: SynthID-Text Bayesian detector
- What it is: a learned classifier scoring g-value patterns against a watermarked-vs-unwatermarked corpus.
- Why worth reusing: pushes detection AUC substantially above hand-designed scorers.
- Preconditions: representative training corpus; same generation-time configuration at deployment.
- What would need to change in a different setting: re-train on the target generation pipeline’s traffic distribution.
- Risks: distribution shift between training corpus and deployment traffic degrades AUC.
REUSABLE COMPONENT 4: Christ-Gunn-Zamir’s substring-completeness framing
- What it is: detection still works on contiguous high-entropy substrings of the original response.
- Why worth reusing: the right framing for evaluating any watermark against quote-extract and copy-paste attacks.
- Preconditions: theoretical; integrate the framing into evaluation protocols.
- What would need to change in a different setting: define the entropy threshold for the target task.
- Risks: empirical-entropy estimation is itself noisy on short substrings.
Dependency map in text form. Kirchenbauer’s green-list bias and Aaronson’s exponential-min are parallel alternatives — either can be the generation-time primitive. SynthID-Text’s tournament composes Aaronson-style g-values across layers. Christ-Gunn-Zamir’s framework is orthogonal — it provides definitions and proofs that any of the generation-time schemes can be evaluated against. A practical system uses one generation primitive + the SynthID-Text Bayesian detector + Christ-Gunn-Zamir’s substring-completeness as the robustness target.
Recommendation. [Analysis] For a researcher building a new watermarking system in 2026, the highest-value components are (1) SynthID-Text’s tournament + Bayesian detector for the production-quality baseline, (2) Christ-Gunn-Zamir’s undetectability definition as the security target to aim at, and (3) Kirchenbauer’s z-statistic as the falling-back simple-detection baseline for comparison plots. A study that uses all three together — tournament generation, Bayesian detection, with both Kirchenbauer-style z-test and Christ-Gunn-Zamir indistinguishability evaluated as ablations — would be the strongest contribution to the field as of May 2026.
[Analysis] What type of new study benefits most. A publicly-detectable watermarking paper would benefit most directly from the cluster’s primitives, since it would inherit the engineering maturity of SynthID-Text while replacing the secret-key assumption with a public-key one.
Section 14: Known limitations and open problems
Limitations explicitly stated by the authors.
- Kirchenbauer Section 5 (Attacks): vulnerable to emoji-injection (pollutes hash input), sustained paraphrasing, and copy-paste editing beyond a threshold. 1
- Christ-Gunn-Zamir Section 6: the bit-level construction is impractical at LLM scale; the paper frames it explicitly as a feasibility result with practical schemes deferred. 2
- SynthID-Text Discussion: degrades on low-entropy outputs (code, structured data, short factual responses); adversarial multi-pass rewriting is an open robustness frontier; the public detection model is not yet shipped (only the generation-side reference is open-source). 4 5
Limitations not stated by the authors.
- [Reviewer Perspective] None of the four addresses key management — rotation, multi-tenant isolation, compromise recovery — at any depth. This is the operational gap between research prototype and production rollout.
- [Reviewer Perspective] None addresses audit and chain-of-custody — when regulators ask “prove this was watermarked at generation time, not retrofitted”, no construction in the cluster provides a verifiable timestamp.
- [Reviewer Perspective] The cluster does not address cross-model watermarking: if multiple LMs share a key, can a single detector identify the source LM? This matters for multi-vendor consortium designs.
- [Reviewer Perspective] Independent commentary on SynthID-Text from the August 2025 robustness paper identifies attack patterns the original Nature paper did not stress-test, supporting the unstated weakness above.
Technical root cause of each. Key management: the four papers treat the key as a pre-shared opaque blob; engineering it as a rotated, isolated, auditable cryptographic artefact is downstream work. Audit / chain-of-custody: requires a timestamping or commitment scheme orthogonal to the watermarking primitive. Cross-model: requires deciding whether per-vendor keys imply a per-vendor detector or a unified detector with vendor-discriminating output.
Open problems left behind.
- Publicly-detectable watermarking with SynthID-Text-quality output preservation.
- Watermarking diffusion-language models (none of the four extends naturally).
- Cross-model watermarking with a shared detector.
- Auditable proof-of-watermark for legal-evidentiary contexts.
What a follow-up paper would need to solve to address the most critical limitation. [Analysis] The most pressing gap is the secret-key trust model. A follow-up should construct a publicly-detectable watermark whose verifier requires only the LM vendor’s public key, achieves Christ-Gunn-Zamir undetectability against polynomial-time adversaries without the secret key, and matches SynthID-Text’s production-traffic quality numbers. As of May 2026, this construction does not exist in published form.
How this article reads at three depths
For the curious high-school reader. Language models can write text that’s hard to distinguish from human writing, which makes it useful for cheating, scams, and disinformation. Watermarking is the trick AI labs use to mark their model’s writing so they (and only they) can later prove “yes, this came from our model.” The four papers in this review are the main recipes — from a simple “bias the model toward certain words” scheme to a mathematically provable scheme used in real Google products today.
For the working developer or ML engineer. All four schemes implement as logits-processor-style interventions inside the decoding loop. Kirchenbauer’s green-list / red-list with and is the trivial baseline (~50 lines of Python, detection in via z-statistic). Aaronson’s exponential-min preserves marginal distribution in expectation but suffers repetition on short contexts. SynthID-Text’s tournament + Bayesian detector is the production-grade option, with the open-source synthid-text reference implementation and an integration path through Hugging Face Transformers. Christ-Gunn-Zamir is theoretical and currently impractical at LLM scale. For implementation choice: SynthID-Text non-distortionary tournament if you have a Bayesian-detector training corpus, otherwise Kirchenbauer with tuned to your tolerable perplexity ratio.
For the ML researcher. The cluster maps four primitives — logit-bias, exponential-min, PRF-binary, tournament — against three properties: distortion-freeness, computational indistinguishability, and production-scale empirical quality. Christ-Gunn-Zamir defines the strongest security bar (PPT-indistinguishability via PRF reduction); Kirchenbauer and SynthID-Text optimise empirical detection AUC; Aaronson sits between as the elegant primitive that the others build on. The unsolved frontier is publicly-detectable watermarking that matches SynthID-Text’s production quality; the strongest objection across the cluster is that the secret-key trust model leaves a third-party audit gap. A follow-up paper would deliver a publicly-detectable construction with Gemini-scale empirical evidence, plus a standardised paraphrase-attack benchmark allowing apples-to-apples cross-scheme comparison.
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. Kirchenbauer, Geiping, Wen, Katz, Miers, Goldstein — A Watermark for Large Language Models (arXiv:2301.10226, ICML 2023). Section 3 specifies the soft watermark with logit bias $\delta$; Section 4 derives the z-statistic detection test; Section 5 discusses attacks including emoji-injection and paraphrasing. Table 2 reports detection rates at $z > 4$ across $(\gamma, \delta)$ configurations. (accessed ) ↩
- 2. Christ, Gunn, Zamir — Undetectable Watermarks for Language Models (arXiv:2306.09194). Definition 9 formalises computational indistinguishability; Theorem 1 proves an $O(\lambda \sqrt{L})$-complete construction; Theorem 2 strengthens this to substring-completeness. (accessed ) ↩
- 3. Aaronson — Watermarking GPT outputs (Simons Institute talk transcript and Crypto 2023 plenary). Describes the exponential-min sampling watermark using PRF outputs as uniform variates; not published as a standalone academic paper but extensively referenced and formalised in subsequent literature. (accessed ) ↩
- 4. Dathathri et al. — Scalable watermarking for identifying large language model outputs (Nature 626, 2024). Reports tournament sampling with $L$ layers, the non-distortionary configuration deployed on Gemini, the 20-million-response live A/B test with no statistically detectable user-quality drop, and detection AUC > 0.95 on Gemma-2B evaluations. (accessed ) ↩
- 5. Google DeepMind — synthid-text reference implementation on GitHub. Apache 2.0 licensed; documents the tournament-sampling logits processor and the Mean / Weighted-Mean / Bayesian detection scorers; explicitly notes the reference is "not intended for production use" with the official path being Hugging Face Transformers integration. (accessed ) ↩
- 6. Sadasivan, Kumar, Balasubramanian, Wang, Feizi — Can AI-Generated Text be Reliably Detected? (arXiv:2303.11156). Argues that post-hoc AI-text detection becomes statistically impossible as language models close the distribution gap with human writing; recursive paraphrasing degrades all detection schemes including watermarks. (accessed ) ↩
- 7. Kirchenbauer et al. — On the Reliability of Watermarks for Large Language Models (arXiv:2306.04634). Authors' own follow-up evaluating the green-list scheme under realistic attacks; reports the watermark survives "thousands of tokens" of light editing before degrading. (accessed ) ↩
- 8. Fernandez et al. — Three Bricks to Consolidate Watermarks for LLMs (arXiv:2308.00113). Unifies the Kirchenbauer and Aaronson schemes under a common statistical-testing framework with sharper detection bounds. (accessed ) ↩
- 9. Google AI for Developers — SynthID-Text Responsible Generative AI Toolkit documentation. Describes SynthID-Text as a logits processor applied after Top-K and Top-P, using a pseudorandom g-function to encode watermarking information. (accessed ) ↩
- 10. EU AI Act, Article 50 — Transparency obligations. Effective 2026-08-02 for generative-AI providers; requires outputs to be "marked in a machine-readable format and detectable as artificially generated or manipulated." (accessed ) ↩
Anonymous · no cookies set