LLM evaluation benchmarks in 2026: MMLU-Pro, GPQA, SWE-Bench and the verification problem
Multi-paper review of MMLU-Pro, GPQA, SWE-Bench, and SWE-Bench Verified: how each was built, what they measure, where contamination and saturation bite.
Reading-register key
From the paper: — directly supported by the paper. [Analysis] — the publication’s reasoned assessment. [Reconstructed] — faithful reconstruction from partial disclosure. [External comparison] — comparison to prior work or general knowledge. [Reviewer Perspective] — critical or speculative.
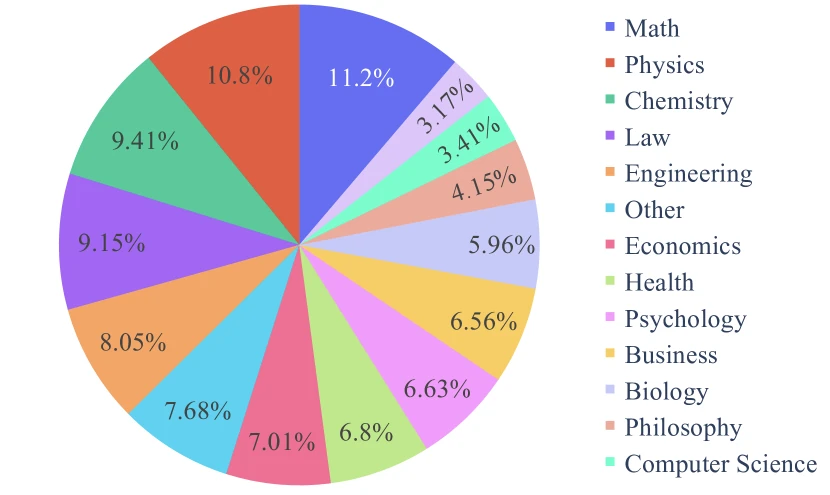
Figure 1 of MMLU-Pro (arXiv:2406.01574), reproduced for editorial coverage.
Section 1 — Paper identity and scope
This multi-paper review covers three benchmark papers and one verification effort that together define how the field measured LLM capability between late 2023 and 2026.
- Wang et al., MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark. arXiv:2406.01574, NeurIPS 2024 Datasets and Benchmarks track (Spotlight). The successor to MMLU that grows the choice set from 4 to 10 options and pushes the question pool toward reasoning rather than recall.
- Rein et al., GPQA: A Graduate-Level Google-Proof Q&A Benchmark. arXiv:2311.12022, November 2023. A 448-question PhD-level science benchmark built by domain experts under a multi-stage validation pipeline designed to defeat web search.
- Jimenez et al., SWE-bench: Can Language Models Resolve Real-World GitHub Issues? arXiv:2310.06770, ICLR 2024. 2,294 software-engineering tasks drawn from real merged pull requests across 12 Python repositories, evaluated by running the project’s own unit tests.
- OpenAI, Introducing SWE-bench Verified. August 2024 blog post and dataset release. A 500-sample subset of SWE-Bench that OpenAI’s professional annotators re-validated for test-scope correctness and issue clarity. 1
Classification. All four are Benchmark contributions. MMLU-Pro and GPQA are knowledge-and-reasoning multiple-choice; SWE-Bench and its Verified subset are agentic code-modification tasks with executable evaluation. None propose new models or new training methods.
Technical abstract (this publication’s voice). MMLU-Pro is a content-and-format refresh of MMLU that delivered 16-33 percentage-point accuracy drops across frontier models and reduced prompt-sensitivity variance from 4-5% to 2% across 24 prompt templates. GPQA is a deliberately small, human-anchored difficulty test: PhD-level domain experts score 65-74%, motivated non-experts with unrestricted internet score 34%. SWE-Bench made evaluation executable, patches are scored by running real test suites, and exposed that mid-2023 frontier models resolved under 5% of issues; SWE-Bench Verified later filtered out 1,794 instances that the original authors’ construction pipeline had let through with under-specified issues or out-of-scope tests.
Primary research question. Can language-model benchmarks remain discriminative as model capability scales, and what construction choices make a benchmark resist saturation, contamination, and gaming?
Core technical claim. Across the three benchmark papers: difficulty is a function of construction discipline, not raw question count. MMLU-Pro’s 10-choice format and reasoning bias, GPQA’s expert-pair validation and Google-proof filter, and SWE-Bench’s executable scoring each encode a different theory of what makes a benchmark hard. [Analysis], by May 2026 the field has stress-tested all three theories and found each addresses one failure mode while leaving others open.
Core technical domains. Benchmark design (deep), evaluation methodology (deep), software engineering agents (moderate, SWE-Bench only), data contamination analysis (moderate), psychometric reliability (surface).
Reader prerequisites. High-school algebra; basic familiarity with what a language model is. The Glossary in Section 2.5 brings the reader up to speed on accuracy / multiple-choice / unit test / contamination / saturation. No graduate ML background assumed.
Section 2 — TL;DR and executive overview
TL;DR. When AI benchmarks become too easy, researchers can’t tell which model is better. This article reviews three benchmarks that tried to stay hard: MMLU-Pro (harder multiple-choice questions, 10 answer options instead of 4), GPQA (PhD-level science questions designed to defeat web search), and SWE-Bench (real GitHub bugs scored by running the project’s tests). All three have since been partially “broken”, either by models getting much better, or by the discovery of construction flaws.
Executive summary. Each benchmark encodes a theory of difficulty. MMLU-Pro bets that more reasoning and more distractors make questions harder. GPQA bets that expert-authored, expert-validated PhD science questions stay hard even with internet access. SWE-Bench bets that running real unit tests on real patches is the most honest scoring rule. Frontier models score 80-94% on the first two as of mid-2026; SWE-Bench Verified climbed from a 1.96% top score in October 2023 to above 90% by April 2026. The contamination problem, the saturation problem, and the leaderboard-gaming problem are all live concerns the original papers did not fully solve.
Five practitioner takeaways.
- A 5-point gap on MMLU-Pro between two frontier models in 2026 is mostly noise; prompt format and CoT prompt choice move the number by 2-3 points on their own. 2
- GPQA Diamond’s top four scores in April 2026 span 0.5 percentage points, roughly one question on a 198-question test. Treating this as a real ranking is unsound. 3
- SWE-Bench Verified is now a closed gap; OpenAI publicly announced in 2026 it would no longer evaluate frontier models on it as a frontier-coding measure. 4
- The original SWE-Bench’s gap between Verified and full-set scores was around 8-10 percentage points on the same model, which is the construction-noise floor for executable benchmarks.
- Contamination analyses across the literature now report 1-45% contamination across major benchmarks; reproducible evaluation requires either held-out questions or trajectory-level execution traces. 5
Pipeline overview. All three benchmarks are evaluation-time only: there is no training procedure to summarise. The pipeline is (1) score a candidate model on the benchmark questions / tasks, (2) compare against published baselines, (3) report a single accuracy or resolution rate.
Section 2.5 — Glossary
| Term | Plain-English explanation | First appears in |
|---|---|---|
| Benchmark | A fixed set of questions or tasks used to score how good an AI model is. Scores are comparable across models because everyone sees the same inputs. | Section 1 |
| Multiple-choice question | A question with a fixed set of answer options (e.g., A, B, C, D); the model picks one. Accuracy = fraction picked correctly. | Section 2 |
| Distractor | A wrong answer option in a multiple-choice question that is plausible enough to tempt a careless reader. More plausible distractors = harder test. | Section 5 |
| Chain-of-Thought (CoT) | A prompting style where the model writes out its reasoning step-by-step before giving the final answer. Often improves accuracy on hard questions. | Section 2 |
| Saturation | A benchmark is “saturated” when top models score so close to 100% (or to each other) that the benchmark can no longer distinguish between them. | Section 2 |
| Contamination (or data leakage) | When the model has seen the benchmark questions during training. The model is then memorising, not reasoning. Inflates the score. | Section 4 |
| Unit test | A small piece of code that checks whether another piece of code does what it’s supposed to. SWE-Bench uses real project unit tests to score a model’s patches. | Section 5 |
| Patch | A specific set of code changes — usually shown as added and removed lines. SWE-Bench asks the model to produce a patch that fixes a real bug. | Section 5 |
| Resolution rate | The fraction of SWE-Bench tasks where the model’s patch passes the project’s tests. SWE-Bench’s accuracy metric. | Section 2 |
| Oracle retrieval | An experimental setup where the model is handed the exact code files the human fix touched, instead of having to find them. Upper-bound on what retrieval-style code agents can do. | Section 5 |
| BM25 retrieval | A classical text-search algorithm. In SWE-Bench, it stands in for a realistic “search the repo” step that an agent would actually do. | Section 5 |
| Diamond / Main / Extended | The three GPQA subsets, in order of difficulty (Diamond hardest, Extended largest). Diamond is the subset most papers report. | Section 5 |
[Analysis] label | The publication’s own reasoned assessment, distinct from what any paper claims. | Throughout |
[Reviewer Perspective] label | A critical or speculative assessment that goes beyond what the papers prove. | Section 11, 12 |
[External comparison] label | A comparison to prior work or general knowledge outside the four papers under review. | Section 4, 11 |
| ”From the paper:” prefix | Content directly supported by one of the four papers’ text, tables, or figures. | Throughout |
Section 3 — Problem formalisation
| Symbol | Type | Meaning | First appears in |
|---|---|---|---|
| Set | The full pool of benchmark questions or tasks | Section 3 | |
| Integer | Question count; 12,032 (MMLU-Pro), 448 (GPQA Main), 2,294 (SWE-Bench) | Section 3 | |
| Function | A model under test; maps a question to an answer | Section 3 | |
| String / Index | The correct answer for question | Section 3 | |
| Real in | Accuracy of on , i.e., fraction correct | Section 3 | |
| Integer | Number of answer choices in a multiple-choice question; (MMLU), (MMLU-Pro) | Section 5 | |
| Boolean | For SWE-Bench: whether ‘s patch on task passes the project’s FAIL_TO_PASS and PASS_TO_PASS tests | Section 5 | |
| Real in | SWE-Bench resolution rate | Section 5 | |
| Real | Standard deviation of across prompt templates; lower is more robust | Section 6 | |
| Real in | Contamination — fraction of present (verbatim or near-verbatim) in ‘s training data | Section 6 |
Formal problem statement (knowledge benchmarks). Given a question pool where each has a ground-truth answer drawn from a -way choice set, the benchmark estimates a model’s capability via . A benchmark is discriminative on a model population if the accuracy distribution across models has high variance; saturated if the top models cluster near a ceiling.
Formal problem statement (executable benchmarks). Given a task pool where each is a triple (issue description, codebase snapshot, oracle test suite), the model produces a patch , and the benchmark scores if and only if every test in ‘s FAIL_TO_PASS subset passes after applying AND every test in the PASS_TO_PASS subset still passes. The resolution rate aggregates across tasks.
Explicit assumption list.
- Independence of questions. Standard accuracy treats as i.i.d. samples; MMLU-Pro and GPQA both inherit this. [Analysis] Potentially strong assumption, questions in the same subject category are not independent under contamination, and a model that has seen the textbook a category was drawn from will get correlated lifts.
- Static ground truth. is fixed. From the paper: GPQA’s expert pipeline already documents 4.6% of questions where the second expert validator overturns the writer; the “ground truth” is built on majority opinion, not formal proof. (Section 3.1 of GPQA.)
- Test suite as oracle (SWE-Bench). From the paper: (Jimenez et al., Section 4), instances are kept only if the FAIL_TO_PASS set is non-empty; the suite is treated as fully specifying correctness. [Analysis] This is the assumption SWE-Bench Verified later challenged: a flaky test or an out-of-scope test breaks the oracle.
- Closed-book evaluation. All three benchmarks assume the model has not seen the questions. None of the original papers proves this assumption holds for the models they evaluate.
Structural reasons each problem is hard. Building a benchmark that survives a generation of model scaling means questions must (1) require capabilities that scale slowly, (2) carry no train-time leakage signal, and (3) admit machine-checkable answers. The three papers each prioritise one constraint and partially relax the others.
Section 4 — Motivation and gap
Real-world stakes. Frontier-lab capability claims, regulatory testimony, model-release marketing, and procurement decisions in the public sector all anchor on benchmark scores. [External comparison] By mid-2024, MMLU was scoring above 86% on GPT-4-Turbo and above 88% on Claude 3 Opus, close enough to a ceiling that 1-point movements stopped meaning anything. From the paper: Wang et al. open MMLU-Pro by noting “leading models have approached saturation” on MMLU, with prompt-format choice moving scores by 4-5%.
Existing-approaches failure modes (MMLU’s specific gaps). From the paper: Section 1 of MMLU-Pro names three failure modes, saturation, format sensitivity, and a knowledge bias that rewards recall over reasoning. Each is documented quantitatively in Section 4.
Existing-approaches failure modes (executable code). From the paper: HumanEval and MBPP, the dominant pre-SWE-Bench code benchmarks, were already near 90% on frontier models in 2023 but tested isolated function synthesis on under-200-line problems. Jimenez et al. (Section 1) argue the real bottleneck is multi-file, repo-scale reasoning, patching a real bug requires localising the relevant code, understanding existing structure, and emitting an edit that doesn’t break unrelated tests. HumanEval cannot test any of that.
Existing-approaches failure modes (knowledge benchmarks more broadly). From the paper: GPQA opens by observing that the scalable-oversight research program, how do you supervise a system that knows more than you, needs hard questions where humans-with-tools fail. Pre-existing benchmarks were either too easy (TriviaQA, SciQ) or too easy to look up (MMLU questions reliably surfaced in the first Google result).
Gap each paper claims to fill.
- MMLU-Pro: a drop-in replacement for MMLU with the same multi-task coverage but harder, more reasoning-biased, less prompt-fragile.
- GPQA: a small, expensive-to-construct, deliberately Google-proof reasoning benchmark for scalable-oversight research.
- SWE-Bench: the first repo-scale, executable code benchmark drawn from real GitHub history rather than synthetic puzzles.
- SWE-Bench Verified: an audit of SWE-Bench’s construction noise; a smaller, human-validated subset that produces less ambiguous resolution rates.
Position in the research landscape. [External comparison] These four sit alongside a wider 2023-2026 wave of benchmark refreshes: BIG-Bench Hard, GAIA, AgentBench, OpenAI’s SimpleQA, the ARC-AGI puzzles, FrontierMath, HLE (Humanity’s Last Exam), and the contamination-focused MMLU-CF and LiveBench. The shared belief is that capability measurement is a moving target and benchmarks need a rolling refresh cadence the field has not yet institutionalised. [Analysis] No single benchmark in this cluster has displaced MMLU’s role as the de-facto knowledge baseline; the field measures across a portfolio.
Section 5 — Method overview

Figure 2 of MMLU-Pro (arXiv:2406.01574), reproduced for editorial coverage.
5.1 MMLU-Pro construction
From the paper: (Wang et al., Section 3 + Appendix A).
- Source composition. 12,032 final questions drawn from four sources: original MMLU (6,810 questions, 56.6%), STEM website scrape (4,083, 33.93%), TheoremQA (598, 4.97%), and SciBench (541, 4.50%).
- Filtering MMLU. From the original ~14k MMLU questions, the authors remove items where (a) GPT-4 and three other models all answer correctly with high confidence (signalling triviality), and (b) human reviewers flag ambiguous or noisy items.
- 10-choice expansion. For each retained question, the authors use GPT-4 to generate six additional plausible distractors, raising from 4 to 10. Distractors are then filtered by domain-expert review and by an automated heuristic that drops options no model ever picks.
- Category structure. 14 disciplines: math, physics, chemistry, law, engineering, business, biology, economics, computer science, philosophy, psychology, history, health, other. Math is the largest category (~10% of the pool).
- Reasoning bias. TheoremQA and SciBench contributions are deliberate: their questions require multi-step symbolic reasoning rather than recall. This is the primary lever the authors expect to depress accuracy.
Connection to pipeline. Evaluation is single-pass on the 12k pool; the paper reports accuracy under both direct-answer and Chain-of-Thought prompting, with five-shot exemplars drawn from the category-specific dev set. From the paper: CoT exemplars are GPT-4-generated and human-validated.
Classification. [Adapted] from MMLU (Hendrycks et al. 2021) with the 10-choice expansion + reasoning-source mixing being the genuinely novel construction lever.
5.2 GPQA construction
From the paper: (Rein et al., Section 3).
- Domain selection. Three sciences only, biology, physics, chemistry, chosen because they have well-defined ground-truth questions at the graduate-coursework level.
- Writer recruitment. PhD candidates and PhD-holders in the three domains, recruited via Upwork. Writers receive $10 per question plus performance bonuses (see Section 5.3 below).
- Four-stage validation pipeline. Writer authors a question with a clearly correct answer and three plausible distractors. Expert validator 1 (same domain) attempts the question, then provides feedback. Writer revises. Expert validator 2 (also same domain) attempts the revised version. Non-expert validators (three skilled validators from other domains) attempt the final version with unrestricted web access excluding LLM assistants.
- Subset structure. Extended (546 questions), every question that passed the writer + first expert. Main (448 questions), questions both expert validators answered correctly OR demonstrated post-hoc agreement on. Diamond (198 questions), Main subset filtered to only questions where two-thirds of non-experts answered incorrectly (the “Google-proof” filter).
- Compensation structure as a difficulty incentive. Writers earn $10 base + $20 per correct expert validation + $15 per incorrect non-expert validation + $30 bonus for the both-correct/both-incorrect-non-expert outcome. [Analysis] The compensation structure aligns the writer’s incentives with the benchmark’s stated goal, produce a question hard for non-experts but solvable by experts.
Connection to pipeline. Evaluation is a single-pass 4-choice multiple-choice score; most papers report Diamond accuracy because it is the strictest filter.
Classification. [New] construction methodology, the expert-pair-plus-non-expert pipeline with explicit financial incentives is novel; the multiple-choice format is [Adopted].

Figure 3 of MMLU-Pro (arXiv:2406.01574), reproduced for editorial coverage.
5.3 SWE-Bench construction
From the paper: (Jimenez et al., Section 3).
- Repo selection. 12 popular Python projects, chosen for high star count, active issue tracking, and a non-trivial unit-test suite: Django, SymPy, scikit-learn, matplotlib, Pylint, pytest, Requests, Astropy, Seaborn, Sphinx, Flask, xarray.
- PR scraping. Merged pull requests in each repo are scraped and filtered to those that (a) link to an issue, (b) modify at least one source file, and (c) modify at least one test file.
- Executable filtering. For each candidate PR, the construction pipeline checks out the parent commit, applies the test changes, applies the source changes, and verifies that at least one test in the PR’s test changes transitions from FAIL to PASS. The FAIL_TO_PASS set is recorded; the PASS_TO_PASS set captures pre-existing passing tests in the same suite. Instances where the suite is non-deterministic or the test pipeline cannot be reproduced are discarded.
- Final pool. 2,294 task instances, each carrying (issue description, parent-commit codebase, FAIL_TO_PASS set, PASS_TO_PASS set, gold patch). Average instance has 9.1 FAIL_TO_PASS tests, 120.8 total tests, 195-word issue description.
Evaluation protocol. Model is shown the issue description and a subset of the repository. The model outputs a patch. The scoring harness applies the patch, runs the FAIL_TO_PASS and PASS_TO_PASS sets, and scores 1 if both pass entirely.
Two retrieval conditions. Oracle, the model is handed exactly the files the gold patch modified. BM25, the model retrieves files from the repo using sparse text search keyed on the issue description.
Classification. [New], the executable-from-real-PR construction pipeline is the genuinely novel contribution.
5.4 SWE-Bench Verified construction
From the paper: (OpenAI blog post, August 2024).
- Annotator recruitment. 93 professional software developers (Python, several years of experience) hired through a contracting partner.
- Per-sample review. Each of the 2,294 SWE-Bench samples is reviewed for four criteria: (a) issue description is well-specified, (b) test suite scope matches the issue, (c) development environment is reliably reproducible, (d) gold patch is sensible.
- Verified subset. 500 samples are retained as Verified, these meet all four criteria. The remaining 1,794 are flagged with at least one issue.
- Re-scoring frontier models. OpenAI re-scores GPT-4o on the full 2,294 set vs the 500 Verified set and documents the resolution-rate gap as evidence the original construction was systematically under-counting model capability.
Classification. [Adapted], a post-hoc filtering layer on top of Jimenez et al.’s benchmark; no new task instances.
Figure 4 of MMLU-Pro (arXiv:2406.01574), reproduced for editorial coverage.
Section 6 — Mathematical contributions
The three benchmark papers are construction papers, not theory papers; their mathematical surface is narrow but worth pinning down precisely.
MATH ENTRY 1: Accuracy on a multiple-choice benchmark.
- Source: (Wang et al., Section 4; Rein et al., Section 4; standard).
- What it is: the fraction of questions a model answers correctly.
- Formal definition:
- Each term explained AND its dimensional/type analysis:
- is the model’s selected answer, an index in for multiple-choice
- is the ground-truth answer, an index in
- is an indicator function, 1 if true, 0 if false
- is the question-pool size, 12,032 for MMLU-Pro, 198 for GPQA Diamond
- is a real number in
- Worked numerical example: a 4-question mini-benchmark with . Model picks answers ; gold answers are . Indicators are . Accuracy . On a 198-question benchmark like GPQA Diamond, each question contributes percentage points; a single right or wrong answer moves the headline number by half a point.
- Role: the single number every leaderboard tracks.
- Edge cases: ties between candidate answers (most evaluation harnesses break ties deterministically by lowest index); refusals (typically scored as wrong).
- Novelty:
[Adopted], accuracy is standard. - Transferability: trivially transferable to any multiple-choice benchmark.
- Why it matters: the half-point-per-question arithmetic explains why the 94.2-94.6% spread at the top of GPQA Diamond is statistically meaningless, it’s one question.
MATH ENTRY 2: Random-baseline accuracy under K-choice format.
- Source: (Wang et al., Section 4, the motivation for moving from to ).
- What it is: the accuracy a model achieves by guessing uniformly at random.
- Formal definition:
- Each term explained: is the number of answer choices.
- Worked numerical example: on MMLU’s format, random guessing scores 25%. A model scoring 35% has only +10 points of signal above noise. On MMLU-Pro’s format, random guessing scores 10%. The same +10 points of signal-above-random now corresponds to a 20% headline accuracy. The 10-choice format expands the dynamic range between random and ceiling by 15 percentage points.
- Role: sets the floor for what a non-trivial score means.
- Edge cases: when distractors are not equally plausible, the effective for a naive model is lower than the nominal , this is why MMLU-Pro’s distractor-generation step matters as much as the count.
- Novelty:
[Adopted], elementary statistics. - Transferability: applies to every multiple-choice benchmark.
- Why it matters: the move from to is doing more than just “make the multiple-choice harder”, it is buying 15 points of headroom before the benchmark saturates.
MATH ENTRY 3: SWE-Bench resolution rate.
- Source: (Jimenez et al., Section 4).
- What it is: the fraction of tasks where the model’s patch satisfies all required tests.
- Formal definition: where
- Each term explained AND dimensional/type analysis:
- is the task pool, 2,294 for full SWE-Bench, 500 for Verified
- is the per-task pass/fail indicator
- “FAIL2PASS pass” means every test in the FAIL_TO_PASS set passes after the patch
- “PASS2PASS pass” means every test in the PASS_TO_PASS set still passes after the patch
- Worked numerical example: a 5-task mini-benchmark. Task 1, patch passes 8 of 9 FAIL_TO_PASS, score 0. Task 2, patch passes all FAIL_TO_PASS but breaks one PASS_TO_PASS, score 0. Task 3, patch passes everything, score 1. Task 4, patch is empty (model refuses), score 0. Task 5, patch passes everything, score 1. Resolution rate . The example shows the rule is conjunctive, partial credit is not awarded.
- Role: the SWE-Bench leaderboard’s single number.
- Edge cases: flaky tests (a PASS_TO_PASS test that intermittently fails) cause non-determinism; SWE-Bench Verified’s main fix is filtering these out. Tests with timing-dependent outcomes also cause noise.
- Novelty:
[Adapted]from standard test-pass-rate metrics in CI; the construction pipeline that produces a clean FAIL2PASS/PASS2PASS split is the novel piece. - Transferability: directly transferable to any test-suite-based code benchmark, Defects4J, BugsInPy, RepoBench all use variants of this rule.
- Why it matters: the conjunctive rule is what makes SWE-Bench honest, a patch that fixes the bug but breaks an unrelated test fails. This is what production code review demands.
MATH ENTRY 4: Prompt-sensitivity variance.
- Source: (Wang et al., Section 4.3).
- What it is: the spread in a model’s accuracy across different prompt templates for the same benchmark.
- Formal definition: where is the accuracy under the -th prompt template and is the mean.
- Each term explained: in the MMLU-Pro experiments. is computed under each of 24 prompt templates that vary instruction phrasing, exemplar order, and answer-format wording.
- Worked numerical example: model accuracies across 4 prompt templates are . Mean . Squared deviations . Variance . Std dev . From the paper: MMLU-Pro reports across 24 templates compared to on the original MMLU.
- Role: a benchmark with high prompt sensitivity cannot be trusted to rank models, a prompt-engineering optimisation alone can swap their order.
- Edge cases: 24 templates is a small sample; the true depends on how “different” the templates are. MMLU-Pro’s authors do not bound the population from which templates are drawn.
- Novelty:
[Adopted], std dev is elementary; applying it as a benchmark-quality metric is[Adapted]from psychometric reliability literature. - Transferability: directly transferable.
- Why it matters: the 2% prompt-sensitivity number is one of MMLU-Pro’s strongest claims to actually being a better benchmark. [Analysis] It is also the claim hardest to independently verify, because the 24 templates are paper-specific.
MATH ENTRY 5: Contamination rate.
- Source: ([External comparison], MMLU-CF, arXiv:2412.15194; widely used in contamination literature).
- What it is: the fraction of benchmark questions present (verbatim or near-verbatim) in a model’s training data.
- Formal definition: where is an n-gram or embedding-similarity match above a threshold.
- Each term explained: if some sequence of contiguous tokens in also appears in (typical for “13-gram overlap”). Embedding-based variants compare semantic similarity above a threshold .
- Worked numerical example: a 100-question benchmark; 13-gram overlap finds 8 questions whose stems appear verbatim in Common Crawl, plus 15 whose answers appear in the same paragraph in Wikipedia. Conservative contamination = 8/100 = 8%. Expansive contamination (including the answer-adjacent matches) = 23/100 = 23%. [External comparison] MMLU-CF’s authors report MMLU contamination ranging from 1% to 45% depending on threshold and matching method (see arXiv:2412.15194).
- Role: the most-cited measure of why a benchmark may no longer be valid.
- Edge cases: paraphrased contamination, when the training data has a paraphrased version of the question, escapes n-gram match and only embedding-based methods catch it.
- Novelty:
[Adopted]from the broader contamination literature; MMLU-Pro and GPQA do not include a formal contamination analysis at construction time. [Reviewer Perspective] This is the most-cited construction-time gap across both papers. - Transferability: directly transferable, with the caveat that training-data access is required.
- Why it matters: a benchmark score is only meaningful conditional on . None of the three benchmark papers prove this; the field has had to backfill the analysis.
Section 7 — Algorithmic contributions
ALGORITHM ENTRY 1: SWE-Bench evaluation harness.
- Source: (Jimenez et al., Section 4 and the SWE-Bench GitHub repo).
- Purpose: deterministically score a candidate patch against a frozen task instance.
- Inputs: task instance (carrying repo URL, parent commit hash, issue text, FAIL_TO_PASS set, PASS_TO_PASS set, golden patch), candidate patch produced by the model.
- Outputs: pass/fail boolean.
- Pseudocode:
def evaluate_patch(task, candidate_patch):
# 1. Set up a fresh container at the parent commit
container = docker.create_image(task.dockerfile)
container.checkout(task.repo_url, task.parent_commit)
# 2. Apply the candidate patch
success = container.apply_patch(candidate_patch)
if not success:
return False # patch did not apply cleanly
# 3. Run the FAIL_TO_PASS test set
for test in task.fail_to_pass:
result = container.run_test(test, timeout=task.timeout)
if result.status != "PASS":
return False
# 4. Run the PASS_TO_PASS test set
for test in task.pass_to_pass:
result = container.run_test(test, timeout=task.timeout)
if result.status != "PASS":
return False
return True- Hand-traced example: task from Django, FAIL_TO_PASS =
[test_a, test_b], PASS_TO_PASS =[test_c, test_d, test_e]. Candidate patch modifiesdjango/db/models/query.py. Step 1: container at commitabc123, Django checked out. Step 2: patch applies cleanly, success=True. Step 3:test_aruns and passes;test_bruns and fails (assertion error on line 42 of test_b). Function returns False. The model gets 0 on this task. Note thattest_c/test_d/test_eare not even reached, the FAIL2PASS failure short-circuits. - Complexity: time dominated by container build (1-5 minutes per task) plus test execution (seconds to minutes per test); memory bounded by Docker image footprint. Total evaluation of the full 2,294-task pool takes O(hours) on a 16-core machine.
- Hyperparameters:
timeout(default 300s per test in the SWE-Bench reference harness), Docker image (per-repo; pinned in the official harness). - Failure modes: flaky tests fail intermittently; timeouts on slow CI; container build failures on stale dependencies. SWE-Bench Verified’s primary value is filtering tasks whose evaluation is sensitive to these failure modes.
- Novelty:
[New]as applied to a benchmark, the executable-evaluation pattern is borrowed from CI, but stitching it onto a benchmark with frozen task instances and 2,294 reproducible Docker images is novel construction work. - Transferability: directly reused by Aider, OpenHands, SWE-Agent, Devin, and most 2024-2026 coding-agent harnesses; the FAIL2PASS/PASS2PASS contract is now standard.
ALGORITHM ENTRY 2: GPQA four-stage validation pipeline.
- Source: (Rein et al., Section 3).
- Purpose: produce a question whose correct answer is robust to expert disagreement and inaccessible to non-experts.
- Inputs: a candidate question draft from a writer.
- Outputs: question accepted into Extended / Main / Diamond, or rejected.
- Pseudocode:
def validate_question(draft, writer, expert_pool, non_expert_pool):
# Stage 1: First expert validation
e1 = sample_from(expert_pool, exclude=[writer])
e1_answer, e1_feedback = e1.attempt(draft, allow_feedback=True)
# Stage 2: Writer revision
revised = writer.revise(draft, feedback=e1_feedback)
# Stage 3: Second expert validation (post-hoc, no feedback loop)
e2 = sample_from(expert_pool, exclude=[writer, e1])
e2_answer = e2.attempt(revised, allow_feedback=False)
# Stage 4: Non-expert validation
non_expert_answers = []
for ne in sample_from(non_expert_pool, k=3):
ne_answer = ne.attempt(revised,
web_access=True,
llm_assist=False,
time_limit=None)
non_expert_answers.append(ne_answer)
# Bucket the question
expert_correct = (e1_answer == revised.gold) and (e2_answer == revised.gold)
non_expert_correct = sum(a == revised.gold for a in non_expert_answers)
if not e1_answer == revised.gold:
return REJECTED
if expert_correct:
if non_expert_correct <= 1:
return DIAMOND
else:
return MAIN
else:
return EXTENDED # passed e1 but e2 disagreed- Hand-traced example: writer is a chemistry PhD; question is about a kinetics calculation. Stage 1: expert 1 (also a chemistry PhD) attempts the question, gets it right, leaves feedback that one of the distractors is too implausible. Stage 2: writer replaces the weak distractor with a stronger one. Stage 3: expert 2 (chemistry PhD) attempts the revised version and answers correctly. Stage 4: three non-experts (a physics PhD, a biology PhD, an EE PhD) attempt it with web access; two get it wrong, one gets it right. Bucket:
expert_correct= True,non_expert_correct= 1, so the question is DIAMOND. - Complexity: 5+ human attempts per question; From the paper: the average non-expert spends 37 minutes on a single question. Total wall-clock per question is multiple hours of paid expert and non-expert time. At 448 Main questions, this is the most expensive construction process of the three benchmarks under review.
- Hyperparameters: the bonus structure ($10 base, $20 per expert correct, $15 per non-expert incorrect, $30 both-expert-correct-and-non-expert-incorrect bonus) is the most consequential, it shapes writer incentives.
- Failure modes: writer adversarial behaviour (gaming the bonus by writing questions that are confusing rather than hard); expert pool depletion (a 3-domain pool runs out of distinct expert pairs at scale).
- Novelty:
[New], the explicit financial incentive structure aligned with the difficulty target is the key innovation. - Transferability: applicable to any expert-knowledge domain where PhD-level human raters are accessible.
ALGORITHM ENTRY 3: MMLU-Pro 10-choice expansion.
- Source: (Wang et al., Appendix B).
- Purpose: expand each 4-choice MMLU question to 10 choices with new plausible distractors.
- Inputs: an original MMLU question (stem + 4 options + correct index).
- Outputs: a 10-choice question with the original 4 options plus 6 new distractors.
- Pseudocode:
def expand_to_ten(question, gpt4, expert_reviewer):
stem = question.stem
original_options = question.options # 4 options
correct = original_options[question.correct_index]
# 1. Generate 6 candidate distractors via GPT-4
candidates = []
for _ in range(20): # over-generate
candidate = gpt4.generate(
prompt=f"Generate a plausible-but-wrong answer to: {stem}\n"
f"The correct answer is: {correct}\n"
f"Existing distractors: {original_options[:3]}\n"
f"Generate a new plausible distractor."
)
candidates.append(candidate)
# 2. Filter for novelty (no near-duplicates of existing options)
candidates = dedupe(candidates, threshold=0.85)
# 3. Expert review — keep distractors that are plausible but wrong
accepted = []
for c in candidates:
if expert_reviewer.is_plausible(c) and not expert_reviewer.is_correct(c):
accepted.append(c)
if len(accepted) == 6:
break
if len(accepted) < 6:
return None # question skipped if not enough good distractors
# 4. Final 10-choice question
all_options = original_options + accepted
shuffle(all_options)
new_correct_index = all_options.index(correct)
return Question(stem=stem, options=all_options, correct_index=new_correct_index)- Hand-traced example: original MMLU question: “What is the half-life formula for a first-order reaction?” Options: . Correct = first option. Step 1: GPT-4 generates 20 candidate distractors. Step 2: dedupe to 12. Step 3: expert reviewer keeps 6 plausible ones, e.g., . Step 4: shuffle all 10. New correct index is 3 (say).
- Complexity: 20 GPT-4 generations per question, expert review per distractor. At 12,032 retained questions, this is O(240,000) GPT-4 calls plus thousands of expert-reviewer hours.
- Hyperparameters: dedupe threshold (0.85 in the paper), over-generation count (20), candidate-acceptance count target (6).
- Failure modes: GPT-4 generates options that are subtly correct (the “Yes/No/All-of-the-above” failure mode); GPT-4 generates options that no model would ever pick. The paper’s heuristic filter (drop options no model ever picks across an evaluation pass) addresses the second failure.
- Novelty:
[Adapted], using a model to generate distractors is borrowed from RACE++ and AGIEval; the heuristic filter is the new piece. - Transferability: applies to any multiple-choice benchmark refresh.
Section 8 — Specialised design contributions
Subsection 8A, LLM / prompt design.
Two of the four papers use an LLM in the construction pipeline.
PROMPT ENTRY 1: MMLU-Pro distractor generation (Wang et al.).
- Source: (Wang et al., Appendix B).
- Role in pipeline: generates candidate distractor options for 10-choice expansion.
- Prompt type: Zero-shot generation with few-shot examples for some categories.
- Components: question stem, correct answer, existing 3 distractors, generation instruction.
- Input schema: structured text containing stem, correct, existing wrong options.
- Output schema: a single candidate distractor string.
- Reconstructed template (the paper does not publish verbatim prompts; this is
[Reconstructed]from the description and the github repo):
Given the following multiple-choice question:
Question: {stem}
Correct answer: {correct}
Existing wrong answers: {existing_distractors}
Generate one additional plausible but incorrect answer choice for this question.
The new option should:
- Be a plausible candidate a knowledgeable but careless student might pick
- NOT be a paraphrase of the correct answer
- NOT be a paraphrase of any existing wrong answer
New option:- Failure handling: dedupe-based filtering; expert review.
- Design rationale: over-generation + filtering is more robust than one-shot generation.
- Complexity: 20 GPT-4 calls per retained question.
- Novelty:
[Adapted]from prior distractor-generation literature. - Transferability: applies to any multiple-choice benchmark refresh.
PROMPT ENTRY 2: Model evaluation prompt for MMLU-Pro.
- Source: (Wang et al., Section 4.2, evaluation protocol).
- Role: presents a question to the model under test.
- Prompt type: 5-shot Chain-of-Thought.
- Reconstructed template (
[Reconstructed]):
The following are multiple choice questions (with answers) about {category}.
{exemplar_1_question}
{exemplar_1_choices_A_through_J}
Answer: Let's think step by step.
{exemplar_1_reasoning}
The answer is ({exemplar_1_letter}).
[... four more exemplars ...]
{actual_question}
{actual_choices_A_through_J}
Answer: Let's think step by step.- The model then generates reasoning followed by “The answer is (X)” where X is parsed by regex.
- Failure handling: when the model emits no parseable letter, the answer is scored wrong.
- Novelty:
[Adopted]from MMLU’s original evaluation harness with the CoT addition.
Subsection 8B, Architecture-specific details. Not applicable to this paper cluster, none introduce architectural changes.
Subsection 8C, Training specifics. Not applicable, these are evaluation-only artefacts.
Subsection 8D, Inference / deployment specifics. Not applicable in the architectural sense, but the evaluation infrastructure matters: SWE-Bench’s official harness runs every task inside a Docker container with pinned dependencies; reproducing the published results requires the harness, not just the model.

Figure 5 of MMLU-Pro (arXiv:2406.01574), reproduced for editorial coverage.
Section 9 — Experiments and results
9.1 MMLU-Pro main results
From the paper: (Wang et al., Table 2, 3, 5).
| Model | MMLU | MMLU-Pro | Delta |
|---|---|---|---|
| GPT-4-Turbo | 86.5% | 63.7% | -22.8 |
| GPT-4o | 88.0% | 72.6% | -15.4 |
| Claude-3-Opus | 88.2% | 68.5% | -19.7 |
| Claude-3-Sonnet | 81.5% | 56.5% | -25.0 |
| Gemini-1.5-Pro | 85.9% | 69.0% | -16.9 |
| Llama-3-70B-Instruct | 82.0% | 56.2% | -25.8 |
| Mixtral-8x22B | 77.8% | 49.5% | -28.3 |
Table reproduced from MMLU-Pro Section 4.1 (arXiv:2406.01574) for editorial coverage.
The drops range from 15.4 (GPT-4o) to 28.3 (Mixtral-8x22B) percentage points. From the paper: CoT vs Direct delta on MMLU-Pro for GPT-4o is +19.1 points, compared to +1.5 points on original MMLU, strong evidence that MMLU-Pro’s questions reward reasoning rather than recall. Prompt sensitivity drops from 4-5% on MMLU to ~2% on MMLU-Pro across 24 templates (Section 4.3).
9.2 GPQA main results
From the paper: (Rein et al., Table 2, Section 4.1).
| Model | Extended | Main | Diamond |
|---|---|---|---|
| GPT-4 (few-shot CoT) | 38.7% | 39.7% | 38.8% |
| Llama-2-70B-chat | 30.4% | 29.1% | 28.1% |
| GPT-3.5-Turbo | 28.2% | 28.0% | 29.6% |
| Random baseline (4-choice) | 25.0% | 25.0% | 25.0% |
| Domain experts (humans) | — | — | 65% (74% excluding self-identified errors) |
| Non-expert humans (with web) | — | — | 34% |
Table reproduced from GPQA Section 4 (arXiv:2311.12022) for editorial coverage.
At publication, GPT-4 sits roughly halfway between non-expert humans and domain-expert humans on Diamond. From the paper: the gap between Main and Diamond on the same models is within 1.5 percentage points, the Diamond subset is harder for non-experts but not visibly harder for models, suggesting models and humans rely on different difficulty axes.
9.3 SWE-Bench main results
From the paper: (Jimenez et al., Table 3).
| Model | Oracle retrieval | BM25 retrieval |
|---|---|---|
| Claude 2 | 4.8% | 1.96% |
| GPT-4 | 1.7% | 0.0% |
| ChatGPT-3.5 | 0.52% | 0.20% |
| SWE-Llama-13B | 4.0% | 0.70% |
| SWE-Llama-7B | 3.0% | 0.70% |
Table reproduced from SWE-Bench Section 5 (arXiv:2310.06770) for editorial coverage.
Even with oracle retrieval, where the model is handed the exact files the gold patch modifies, the best 2023 system resolves under 5% of tasks. From the paper: longer context does not help; in fact resolution rates drop as context length grows, suggesting localisation is the bottleneck.
9.4 SWE-Bench Verified — the construction-noise audit
From the paper: (OpenAI blog, August 2024). OpenAI’s annotators flagged 38.3% of the 2,294 SWE-Bench instances as having at least one of: underspecified issue, out-of-scope tests, unreliable environment, or non-sensible gold patch. The Verified 500-instance subset retains only instances that pass all four checks.
On the 500-instance Verified subset, GPT-4o resolution rate jumps from 16.0% (full SWE-Bench, August 2024) to 33.2% (Verified, August 2024), [Analysis] a 17-point gap that is the construction-noise floor for the original benchmark.
9.5 2026 leaderboard state (cross-checks)
[External comparison] By May 2026 the leaderboards have moved substantially:
- MMLU-Pro: frontier models reportedly cluster in the 78-85% range, with the original Wang et al. 63-72% range now a generation behind. 6
- GPQA Diamond: Epoch AI’s tracker shows the top four frontier models within 0.5 percentage points of each other in April 2026, roughly one question on the 198-question test. [Analysis] The benchmark is at-or-near saturation; ranking models on this single number is unreliable. 3
- SWE-Bench Verified: reported top scores cross 88-92% by mid-2026, and OpenAI publicly announced it would no longer evaluate frontier coding models on this benchmark, citing saturation and construction limits. 4 [Analysis] In under 30 months the benchmark went from 4.8% top score to “saturated and retired by its biggest user.” This is the fastest benchmark lifecycle in recent ML history.
9.6 Evidence audit
Strongly supported. The original papers’ construction methodology is well-documented and reproducible. MMLU-Pro’s 16-33-point drop from MMLU and CoT-vs-Direct gap are robust across model families. GPQA’s human-baseline gap between experts and motivated non-experts is the most-cited construction artefact in the cluster.
Partially supported. Prompt-sensitivity reductions in MMLU-Pro depend on the 24-template pool the authors chose; a different pool may produce different variance. SWE-Bench’s claim that “oracle retrieval is an upper bound” is empirically supported in the original paper but later work showed iterative agentic loops can outperform oracle-single-shot, so the “upper bound” framing was specific to single-shot evaluation.
Narrow evidence. Contamination claims, neither MMLU-Pro nor GPQA conducts a formal contamination analysis at construction time. Subsequent work (MMLU-CF, decontamination audits in the LLama 3 / GPT-4 technical reports) backfills this for MMLU but not for MMLU-Pro or GPQA.
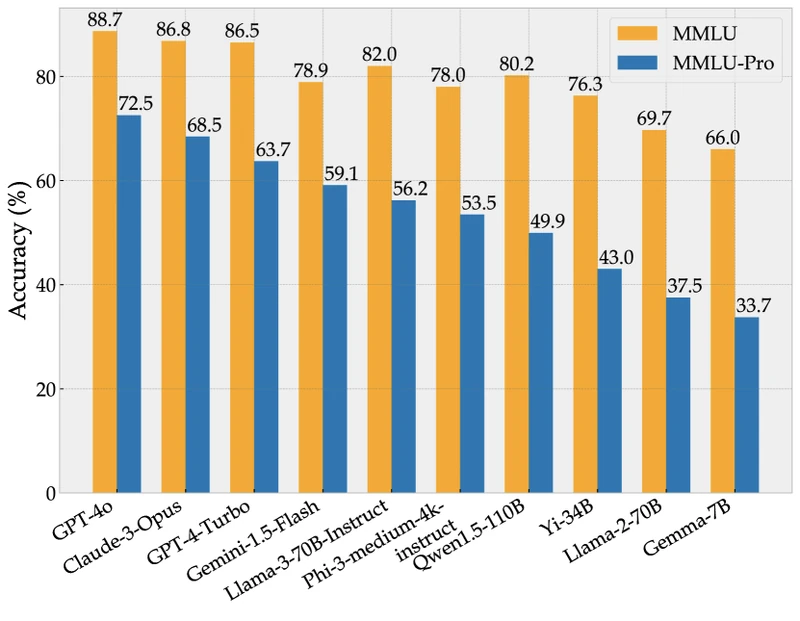
Figure 6 of MMLU-Pro (arXiv:2406.01574), reproduced for editorial coverage.
Section 10 — Technical novelty summary
| Component | Type | Novelty level | Justification | Source |
|---|---|---|---|---|
| 10-choice expansion of MMLU questions | Construction | Incrementally novel | Distractor generation is [Adapted]; the count expansion to is [New] as a benchmark-design lever | Wang et al. Section 3 |
| GPT-4-generated distractors filtered by expert | Pipeline | Incrementally novel | Generate-then-filter is adopted from prior MCQA construction; expert-review filter is the local addition | Wang et al. Appendix B |
| 24-template prompt-sensitivity audit | Evaluation | Incrementally novel | Std-dev across prompts is standard; using it as a benchmark-quality KPI is mostly new in 2024 | Wang et al. Section 4.3 |
| Four-stage expert-pair + non-expert validation | Construction | Fully novel | Compensation-aligned expert-pair pipeline with non-expert Google-proof gate is unique to GPQA | Rein et al. Section 3 |
| Diamond / Main / Extended subset structure | Benchmark | Combination novel | The three-tier difficulty filter built from the validation pipeline | Rein et al. Section 3.3 |
| Executable PR-derived task instances | Construction | Fully novel | First repo-scale benchmark with FAIL2PASS/PASS2PASS contract from real merged PRs | Jimenez et al. Section 3 |
| Oracle vs BM25 retrieval split | Evaluation | Incrementally novel | Standard retrieval comparison; the use as a benchmark stratification is new | Jimenez et al. Section 5 |
| Per-instance human verification for benchmark filtering | Audit | Fully novel | OpenAI’s 93-annotator review with 4-criterion checklist is a new pattern for post-hoc benchmark cleanup | OpenAI Verified blog |
Single most novel contribution. [Analysis] SWE-Bench’s executable-from-real-PR construction pipeline. The combination of (a) scraping merged PRs, (b) requiring tests in the diff, (c) executing the test transition to confirm correctness, and (d) packaging the result as a frozen task instance is the most architecturally novel piece across the four papers. It is also the one with the deepest downstream influence, every executable code benchmark since 2024 inherits some version of this pattern.
What the papers do NOT claim novel. MMLU-Pro’s category structure is inherited from MMLU. GPQA’s multiple-choice format is standard. SWE-Bench’s underlying Docker-based evaluation harness adapts CI conventions from continuous-integration practice. None of the four papers claims a novel scoring metric, accuracy and resolution rate are both standard.
Section 11 — Situating the work
Prior work. From the paper: MMLU (Hendrycks et al. 2021) established the multi-task multiple-choice baseline; HumanEval (Chen et al. 2021) and MBPP (Austin et al. 2021) established the code-benchmark baseline; QASPER, TriviaQA, and TheoremQA established narrower QA baselines. MMLU-Pro and GPQA explicitly position against MMLU; SWE-Bench positions against HumanEval and MBPP.
Conceptual changes. MMLU-Pro changes the choice cardinality and reasoning bias of multiple-choice benchmarks; GPQA changes the construction discipline by treating PhD-level expert validation as a non-negotiable; SWE-Bench changes the scoring substrate by replacing model-graded or string-match scoring with executable tests.
Contemporaneous related work (≥2 papers cited).
- [External comparison] BIG-Bench Hard (Suzgun et al. 2022 / 2023): the prior generation’s attempt to surface MMLU-resistant tasks. MMLU-Pro absorbs some of BBH’s reasoning-bias instinct but ships as a drop-in MMLU replacement rather than a separate benchmark, which is the architectural choice the field rewarded with adoption.
- [External comparison] GAIA (Mialon et al. 2023): contemporary with GPQA, similar in philosophy, small, hand-crafted, expert-validated, tool-use-friendly. GAIA targets general assistant capabilities; GPQA targets science-domain reasoning. They are complementary rather than competing.
- [External comparison] MMLU-CF (Wang et al. 2024 / ACL 2025): explicitly addresses the contamination gap that MMLU-Pro does not. [Reviewer Perspective] If a future paper wanted to retire MMLU-Pro for the same reasons MMLU-Pro retired MMLU, it would lean on this contamination thread.
Strongest skeptical objection. [Reviewer Perspective] All three benchmark papers commit the same construction-time error: they evaluate the difficulty of their benchmark against the current frontier model (GPT-4 in 2023, GPT-4o in 2024). A benchmark that is hard for GPT-4 is not guaranteed to remain hard for GPT-6. SWE-Bench’s 30-month arc from 4.8% to 90%+ is the most extreme demonstration. The construction process needs to anticipate models 2-3 generations ahead, and none of the four papers does.
Strongest author-side rebuttal. From the paper: The papers do not claim to be future-proof. MMLU-Pro frames itself as a “more challenging” successor, not a permanent measure. GPQA explicitly motivates itself as a scalable-oversight research tool, the benchmark’s value persists even after model accuracy exceeds expert accuracy, because the gap itself is the research object. SWE-Bench Verified’s existence is OpenAI’s own implicit acknowledgment of the original’s limits and a tacit confirmation of the rolling-refresh model.
What remains unsolved. Three things. First, no benchmark in this cluster has a construction-time contamination guarantee. Second, none has a published refresh cadence, there is no MMLU-Pro 2.0 with new questions on a quarterly schedule, despite the field needing one. Third, leaderboard hosting and submission protocols remain ad hoc, there is no community-managed evaluation infrastructure analogous to ImageNet’s ILSVRC era.
Three future research directions (each grounded in a paper-specific gap).
- [Analysis] Per-question-difficulty IRT modelling. Item-response-theory methods could turn accuracy into a model-trait estimate that is robust to a small set of saturated questions. GPQA Diamond, with its 198-question size, is the natural testbed because the model-trait estimate has the highest variance per question added or removed.
- [Analysis] Hold-out evaluation servers. A community-managed server holds the questions; the model is submitted; only an aggregate score returns. This is the standard fix for contamination and the natural follow-up to SWE-Bench Verified’s audit model.
- [Reviewer Perspective] Process-grading vs outcome-grading on SWE-Bench. Resolution rate scores patch correctness; it says nothing about patch quality, security, or maintainability. The next generation of code benchmarks needs trajectory-level signals, which files the agent opened, which tests it added, whether it introduced regressions in code review.
Section 12 — Critical analysis
Strengths.
- From the paper: MMLU-Pro’s CoT-vs-Direct gap is a clear positive signal that the benchmark rewards reasoning rather than recall (Wang et al. Table 5, +19.1 points for GPT-4o).
- From the paper: GPQA’s compensation-aligned validation pipeline is the most reproducible “expert benchmark” construction protocol in the literature; the writer-validator-bonus structure is fully documented (Rein et al. Section 3).
- From the paper: SWE-Bench’s executable scoring is the most theoretically clean, no judge-LLM, no string-match, no preference rating. A patch either passes the tests or it does not.
Weaknesses stated by the authors.
- From the paper: Wang et al. acknowledge (Section 6) that MMLU-Pro’s distractor-generation step depends on GPT-4, which itself may have seen MMLU during training. The construction process cannot be fully model-independent.
- From the paper: Rein et al. acknowledge (Section 6) that GPQA’s 448 questions is small; sample-size bounds on accuracy are wide. They also note the three-domain restriction.
- From the paper: Jimenez et al. acknowledge (Section 6) that single-shot, single-patch evaluation is a simplification of real software-engineering workflow which is iterative, multi-turn, and involves test-writing.
Weaknesses NOT stated or understated by the authors.
- [Reviewer Perspective] No paper in the cluster ships a contamination analysis at construction time. [External comparison] MMLU-CF’s authors (arXiv:2412.15194) document this gap for MMLU and quantify contamination at 1-45% across major benchmarks depending on threshold, that critique applies in full to MMLU-Pro until a similar analysis is run. 5
- [Reviewer Perspective] GPQA’s expert-validation step has a documented 14.6% writer-validator disagreement rate (Section 3.1), i.e., 1 in 7 questions ships into the Extended set without two-expert consensus. The Diamond subset filters this but still inherits the implicit assumption that majority opinion approximates ground truth.
- [Reviewer Perspective] SWE-Bench’s 38.3% construction-noise rate (revealed by OpenAI’s audit) is a serious indictment of the original construction pipeline’s filters. The audit found that one in three tasks had issues that made deterministic scoring unreliable.
Reproducibility check.
| Paper | Code | Data | Eval set | Compute reported | Weights | Overall |
|---|---|---|---|---|---|---|
| MMLU-Pro | GitHub released | Hugging Face release | Public | Yes | N/A (not a model) | Fully reproducible |
| GPQA | GitHub released | Public | Public | Yes | N/A | Fully reproducible |
| SWE-Bench | GitHub released | Public | Public | Yes (per-task Docker) | N/A | Fully reproducible |
| SWE-Bench Verified | Annotation logs released | 500 instances public | Public | N/A | N/A | Fully reproducible |
Methodology disclosure callout.
- Sample size. MMLU-Pro: 12,032 questions. GPQA Main: 448, Diamond: 198, Extended: 546. SWE-Bench: 2,294 tasks. SWE-Bench Verified: 500 tasks.
- Evaluation set. All four benchmarks make their full evaluation set public; the test/dev split exists for MMLU-Pro (small per-category dev set for CoT exemplars) and GPQA (no formal split, the entire set is used for evaluation). Contamination-check status: not formally audited at construction time for any of the four.
- Baselines. MMLU-Pro: GPT-4-Turbo / GPT-4o / Claude-3-Opus / Claude-3-Sonnet / Gemini-1.5-Pro / Llama-3-70B-Instruct / Mixtral-8x22B / others. GPQA: GPT-4 / Llama-2-70B / GPT-3.5-Turbo / human baselines (expert + non-expert). SWE-Bench: GPT-4 / Claude 2 / ChatGPT-3.5 / SWE-Llama-7B / SWE-Llama-13B. SWE-Bench Verified: GPT-4o re-scored.
- Hardware/compute. MMLU-Pro and GPQA evaluation is inexpensive (single-pass inference on a few thousand questions). SWE-Bench evaluation requires per-task Docker containers; the official harness recommends a 16-core machine with 32 GB RAM and Docker; full benchmark run is a few hours.
Generalisability. [Analysis] MMLU-Pro’s construction methodology generalises to any multi-task knowledge benchmark. GPQA’s expert-pair pipeline generalises to any domain with accessible PhD-level raters and a tolerance for ~$50-100 per question construction cost. SWE-Bench’s PR-derived pipeline generalises to any open-source project with a working test suite, and has been extended to Java (SWE-Bench-Java), to multilingual (Multi-SWE-Bench), and to live new PRs (SWE-Rebench).
Assumption audit. The most fragile assumption across all three benchmarks is closed-book evaluation. None of the papers can prove the models they evaluate did not see the questions during training. The field’s de-facto response has been to release new benchmarks faster than models can be retrained, a structurally unsustainable workaround.
What would make the papers significantly stronger. [Analysis]
- For MMLU-Pro: a construction-time contamination scan against Common Crawl and public training data with explicit thresholds.
- For GPQA: a larger Diamond subset (target 500+), the 198-question size means any single question miscoring moves the headline by 0.5 percentage points.
- For SWE-Bench: trajectory-level scoring as a second metric alongside binary resolution.
Section 13 — What is reusable for a new study
REUSABLE COMPONENT 1: SWE-Bench’s executable-evaluation harness.
- What it is: the Docker-based per-task evaluation runner with FAIL2PASS/PASS2PASS scoring.
- Why worth reusing: it is the de-facto standard for any code-modification benchmark.
- Preconditions: target repos must have a working test suite and reproducible Docker setup.
- What would need to change: language support (the original is Python-only; SWE-Bench-Java and others extend it).
- Risks: flaky tests propagate as construction noise, the SWE-Bench Verified audit revealed 38.3% of original tasks had this issue.
- Interaction effects: tightly coupled to SWE-Bench’s task-instance format.
REUSABLE COMPONENT 2: GPQA’s compensation-aligned validation pipeline.
- What it is: a four-stage writer/expert-pair/non-expert validation flow with bonuses keyed to difficulty.
- Why worth reusing: the cheapest known method to produce expert-validated, Google-proof multiple-choice questions.
- Preconditions: accessible PhD pool in the target domain; budget of ~$50-100 per question.
- What would need to change: distractor-generation prompts and the non-expert allowance (e.g., banning LLM assistants but allowing search) must be re-specified for the target domain.
- Risks: writer adversarial behaviour gaming the bonus; expert pool depletion at scale.
- Interaction effects: independent of any specific model.
REUSABLE COMPONENT 3: MMLU-Pro’s 10-choice expansion lever.
- What it is: expanding from 4 to 10 to buy headroom against saturation.
- Why worth reusing: it is the simplest construction-time intervention that materially depresses naive accuracy.
- Preconditions: ability to generate plausible distractors at scale; expert review capacity.
- What would need to change: the distractor-generation prompt needs domain-specific examples.
- Risks: if distractors are insufficiently plausible, models converge to near-original 4-choice accuracy because the extra 6 options are effectively dead.
- Interaction effects: pairs naturally with CoT-required formats.
REUSABLE COMPONENT 4: SWE-Bench Verified’s human-annotation-audit checklist.
- What it is: a 4-criterion checklist applied per task to filter construction noise.
- Why worth reusing: it is the only published, applied benchmark-cleanup methodology in the cluster.
- Preconditions: budget for a professional annotator pool.
- What would need to change: the four criteria are SWE-Bench-specific; new benchmarks need their own criterion list.
- Risks: annotator inter-rater agreement is not reported in OpenAI’s release notes.
Dependency map. The four components are largely independent. SWE-Bench’s harness depends on Docker-pinnable repos. GPQA’s validation pipeline depends on an expert-rater pool. MMLU-Pro’s 10-choice expansion depends on a generation-capable LLM. The Verified audit depends on a professional annotator pool. None of the four depends on the others.
Recommendation. [Analysis] The highest-value components for a new benchmark project are SWE-Bench’s executable-evaluation harness (because it answers the hardest design question, what counts as correct) and GPQA’s compensation-aligned pipeline (because it produces the highest-quality questions per dollar spent). The MMLU-Pro 10-choice lever is easy to copy but produces only incremental difficulty; the Verified audit checklist is a useful post-hoc tool rather than a primary construction lever.
Type of new study that benefits most. A new evaluation benchmark in a previously-unbenchmarked domain (legal reasoning, medical diagnosis, scientific peer review). The component mix is: GPQA pipeline for question construction, SWE-Bench harness if the evaluation is executable, MMLU-Pro 10-choice if executable evaluation is not available.
Section 14 — Known limitations and open problems
Limitations explicitly stated.
- MMLU-Pro: depends on GPT-4 for distractor generation (Section 6).
- GPQA: small sample size; three-domain restriction; non-expert pool not domain-randomised (Section 6).
- SWE-Bench: single-shot single-patch evaluation; 12-repo Python-only restriction (Section 6).
- SWE-Bench Verified: no public inter-annotator-agreement statistics; the 500-sample retention rate is given without uncertainty bounds.
Limitations NOT stated, sourced from independent commentary.
- [External comparison] The MMLU-CF authors (arXiv:2412.15194) document that the contamination problem MMLU-Pro inherits is severe (1-45% across benchmarks); MMLU-Pro does not formally audit for this. 5
- [External comparison] Epoch AI’s GPQA Diamond tracker shows the top four frontier models cluster within 0.5 percentage points by April 2026, i.e., the Diamond subset has functionally saturated. [Reviewer Perspective] This is not a flaw of the benchmark per se but the lack of a refresh path is a flaw of the paper’s roadmap. 3
- [External comparison] OpenAI’s own May 2026 retirement of SWE-Bench Verified as a frontier-coding evaluation surface signals the benchmark has aged out faster than its authors anticipated. 4
Technical root causes.
- Saturation root cause: the question pool is finite and the model-capability axis the benchmark measures is gradient-able under continued pretraining + post-training. Without an automated refresh mechanism, every benchmark has a finite half-life.
- Contamination root cause: training data is web-scale; benchmarks are public; n-gram overlap is statistically unavoidable. The only structural fix is private hold-out sets.
- Construction-noise root cause: real-world data (GitHub PRs, expert-written questions) contains errors; the original construction pipelines did not include a per-instance audit pass.
Open problems.
- A community-managed benchmark refresh cadence with hold-out evaluation infrastructure.
- A construction-time contamination guarantee compatible with public benchmarks.
- A multi-axis scoring metric for SWE-Bench-style executable benchmarks (resolution + quality + security + maintainability).
What a follow-up paper would need to solve. [Analysis] The most consequential single follow-up would be a hold-out evaluation protocol with a community-managed server. This requires both technical infrastructure (private question pool, model-submission API, leaderboard with rate limits) and governance (who decides when the questions are refreshed, who has access to the hold-out, how challenges are arbitrated). The closest analog is ImageNet’s ILSVRC era; the field has not yet reproduced that institutional pattern for language-model evaluation.
How this article reads at three depths
For the curious high-school reader. AI researchers use “benchmarks”, fixed sets of test questions, to measure which model is best. This article looks at three of the most-used benchmarks from 2023-2024 and what happened to them by 2026. The short story: each benchmark was built with a clever idea (harder questions, PhD-level questions, real software bugs), and each one has been partly beaten by newer models. The takeaways are that benchmarks have a shelf life, that “best model” is harder to measure than it looks, and that the field is still figuring out how to keep benchmarks honest.
For the working developer or ML engineer. MMLU-Pro grew the answer choices from 4 to 10 and dropped scores by 16-33 points; that delta is mostly real for the model-capability question, but prompt format still moves the number by ~2 points. GPQA Diamond is now at saturation (top four models within 0.5 percentage points as of April 2026); use it as one signal in a portfolio, not as a ranker. SWE-Bench Verified is the most useful benchmark in this cluster for picking a coding agent in 2026, until it saturates, which it largely has. Practical advice: do not pick a model on a single benchmark score; cross-check at least three benchmarks plus your own internal eval set; treat anything claiming SOTA on a 2-year-old benchmark with extreme skepticism.
For the ML researcher. The most architecturally novel contribution in this cluster is SWE-Bench’s executable-from-real-PR construction pipeline; everything else is incrementally novel construction discipline. The load-bearing assumption across all four papers is closed-book evaluation, none proves it, the field has been backfilling contamination audits. The strongest objection is that the benchmarks evaluate difficulty against the current frontier rather than 2-3 generations ahead; SWE-Bench’s 30-month arc from 4.8% to 90%+ is the canonical demonstration. A follow-up that solved hold-out evaluation infrastructure with a community-managed server would close the largest open gap; this is the ImageNet-ILSVRC pattern the field has not yet reproduced for LLM benchmarks.
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. OpenAI — Introducing SWE-bench Verified, August 13 2024 (announcement page; cross-referenced via DEV Community summary and SWE-bench leaderboard) (accessed ) ↩
- 2. MMLU-Pro Section 4.3 reports prompt-sensitivity standard deviation of approximately 2% across 24 prompt templates, compared to 4-5% on the original MMLU benchmark (accessed ) ↩
- 3. Epoch AI GPQA Diamond tracker — top four frontier models cluster within 0.5 percentage points as of April 2026; saturation analysis (accessed ) ↩
- 4. OpenAI — Why we no longer evaluate SWE-bench Verified, OpenAI announcement page on benchmark saturation (accessed ) ↩
- 5. MMLU-CF: A Contamination-free Multi-task Language Understanding Benchmark (ACL 2025) — reports contamination ranging from 1% to 45% across major benchmarks depending on threshold and matching method (accessed ) ↩
- 6. MMLU-Pro leaderboard via the official Hugging Face leaderboard maintained by the paper authors (accessed ) ↩
Further Reading
- Rein et al. — GPQA: A Graduate-Level Google-Proof Q&A Benchmark (arXiv:2311.12022) (accessed )
- Jimenez et al. — SWE-bench: Can Language Models Resolve Real-World GitHub Issues? (arXiv:2310.06770, ICLR 2024) (accessed )
- SWE-bench Verified leaderboard (accessed )
- SWE-bench GitHub repository (accessed )
Anonymous · no cookies set