Knowledge distillation for LLMs: MiniLLM, Distilling Step-by-Step, and the Gemma-2 recipe
Multi-paper review of three LLM knowledge-distillation methods: MiniLLM reverse-KL on-policy, Distilling Step-by-Step CoT rationales, Gemma-2 pre-training soft-target.
Reading-register key
- From the paper: claims drawn verbatim or near-verbatim from the source paper’s text, equations, tables, or figures.
- Facts: dates, citations, vendor specifications verified at writer-time from primary sources.
- [Analysis]: the publication’s own reasoned assessment, distinct from any claim the papers themselves make.
- [External comparison]: comparison to named prior work or general knowledge outside the three papers.
- [Reviewer Perspective]: a critical or speculative assessment that goes beyond what any of the three papers proves.
Section 1: Cluster scope
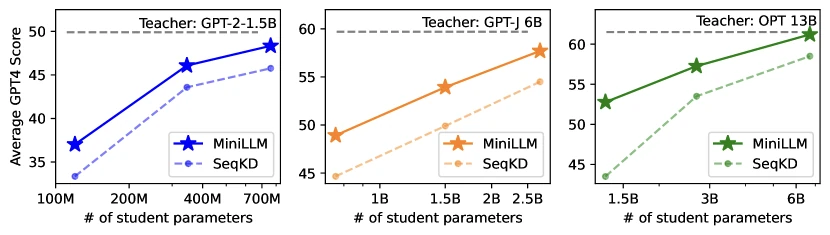
Figure 1 of MiniLLM (arXiv:2306.08543), reproduced for editorial coverage.
This review covers three papers that together define how the field distils knowledge from a large language model into a smaller one in 2026: MiniLLM (Gu, Dong, Wei, Huang; ICLR 2024), 1 Distilling Step-by-Step (Hsieh et al.; Findings of ACL 2023), 2 and the Gemma 2 technical report (Gemma Team, DeepMind, 2024). 3 All three answer the same question, how to compress the capability of a large teacher model into a smaller student, but they answer it at three different points in the training pipeline and with three very different objective functions.
MiniLLM works at the post-training stage: take an already-pre-trained student, then distil from a teacher using a reverse-KL objective on student-sampled rollouts. Distilling Step-by-Step works at the supervised-fine-tuning stage: extract chain-of-thought rationales from a frontier teacher and train a small student to predict both the rationales and the labels through a multi-task loss. Gemma 2 works at the pre-training stage itself: replace next-token cross-entropy on hard one-hot labels with a soft-target KL against a frozen teacher, applied across trillions of tokens.
[Analysis] The three papers are best read together because each occupies a distinct slot in the distillation taxonomy. MiniLLM is a post-SFT alignment-style distillation. Distilling Step-by-Step is an SFT-time data-augmentation-plus-multi-task variant. Gemma 2 is a from-scratch pre-training distillation. A practitioner choosing between them is really choosing between three different stages of training to spend their teacher-inference budget on.
The classification per paper-review template:
- Architecture proposal: No (none of the three propose a new architecture; Gemma 2 inherits Transformer modifications from prior work).
- Training method: Yes, all three.
- Inference method: No.
- Generative model / LLM-based: Yes.
- Theoretical: Partial, MiniLLM derives the reverse-KL gradient; the other two are predominantly empirical.
- Benchmark: No (Gemma 2 reports many benchmarks but does not introduce a new one).
- Application: Yes (efficient LLM deployment).
Primary research question (cluster): given a large teacher LLM, what is the most sample-efficient and quality-preserving way to train a much smaller student LLM?
Core claim per paper:
- MiniLLM, replacing the standard forward-KL distillation objective with a reverse-KL objective optimised on student-sampled (on-policy) generations produces a better student than forward-KL or sequence-level KD across the 120M-to-13B parameter range.
- Distilling Step-by-Step, extracting chain-of-thought rationales from a 540B teacher and training a small student to predict both rationale and label in a multi-task framework lets a 770M T5 outperform 540B PaLM with 80% of the labelled data.
- Gemma 2, applying soft-target distillation across trillions of pre-training tokens (rather than the usual hard-label cross-entropy) yields significantly better small (2B and 9B) models than from-scratch training at the same compute budget.
Reader prerequisites. High-school algebra and a willingness to read short equations. Familiarity with neural-network basics, cross-entropy loss, and transformer-LM token-prediction is helpful but not required because the Glossary in Section 2.5 brings the high-school reader up to speed on every term used below. Working ML researchers can skip Sections 2 and 2.5 and start at Section 3.
Section 2: TL;DR and executive overview
TL;DR (three sentences). Knowledge distillation is the art of training a small AI model to imitate a big one, so that you get most of the big model’s capability at a fraction of the cost to run. These three papers each fix a different problem: MiniLLM stops the small model from spreading its predictions too thinly across rare words the big model would never use, Distilling Step-by-Step teaches the small model not just the answers but the reasoning steps the big model used to get there, and Gemma 2 shows that doing distillation across the entire pre-training run (trillions of words) instead of just at the end gives the biggest jump in quality. The three approaches are complementary, not competing: a 2026 production team will often use Gemma-2-style pre-training distillation, then a Distilling-Step-by-Step-style SFT phase, then a MiniLLM-style reverse-KL polish.
One-paragraph executive summary. Knowledge distillation transfers capability from a large teacher LLM into a smaller student LLM by training the student to match the teacher’s output distribution rather than (or in addition to) the original ground-truth labels. The three papers in this cluster span the full training-stage taxonomy. MiniLLM (post-SFT) argues that the dominant forward-KL objective causes the student to over-cover the teacher’s low-probability tail and that reverse-KL with on-policy student sampling fixes this, empirically improving ROUGE-L by 6-10 points on instruction-following benchmarks. Distilling Step-by-Step (SFT) shows that chain-of-thought rationales from a frontier teacher serve as cheap auxiliary supervision that lets a 770M student outperform a 540B teacher on selected NLP benchmarks with substantially less labelled data. Gemma 2 (pre-training) demonstrates that distillation works at the pre-training scale itself, with a 2B model trained on 2T tokens via soft-target KL hitting a 67.7% average benchmark score versus 60.3% for the from-scratch baseline. The audience that should care: open-weight model builders, mobile and edge deployment teams, anyone running an LLM at scale on tight inference budgets.
Five practitioner-relevant takeaways:
- Forward-KL distillation is the wrong default for open-ended generation. The student spreads probability mass over teacher’s low-probability tokens, producing hallucinations and rambling. Reverse-KL on student-sampled rollouts concentrates the student on teacher’s high-probability modes.
- On-policy sampling (student generates the sequences it is trained on) matters more than the choice of divergence. Even forward-KL on student-sampled data outperforms reverse-KL on teacher-sampled data in follow-up work.
- Chain-of-thought rationales are a free dataset multiplier. If you can afford one teacher inference call per training example, you double your supervision signal at near-zero marginal cost.
- Distillation pays off at pre-training scale. Gemma 2 spends roughly 50x the Chinchilla-optimal compute on the 2B model and recovers it via the distillation objective; the 9B Gemma 2 model meaningfully beats the 7B LLaMA-class baselines as a result.
- The teacher does not need to be online. All three papers freeze the teacher and pre-compute (or stream) teacher logits, which makes the inference budget the dominant cost driver and lets the team batch teacher calls efficiently.

Figure 3 of MiniLLM (arXiv:2306.08543), reproduced for editorial coverage.
Pipeline overview in text. All three methods share a basic shape: a frozen teacher model , a trainable student model , and some loss that measures distance between ‘s output distribution and ‘s output distribution. The differences sit in three places. What is being matched, full per-token distributions (MiniLLM, Gemma 2) or both labels and rationales (Distilling Step-by-Step). What divergence is being minimised, reverse-KL (MiniLLM), forward-KL implemented as cross-entropy with soft targets (Gemma 2), or two cross-entropy heads (Distilling Step-by-Step). What data is being trained on, student-sampled rollouts (MiniLLM, on-policy), the original SFT dataset (Distilling Step-by-Step), or trillion-token pre-training corpora (Gemma 2). Inference-time, all three produce a standalone student model that runs without the teacher.
Section 2.5: Glossary
| Term | Plain-English explanation | First appears in |
|---|---|---|
| Knowledge distillation (KD) | Training a small “student” model to imitate the predictions of a larger “teacher” model, so the student gets most of the teacher’s capability at a fraction of the inference cost. | Section 1 |
| Teacher model | The large, capable model whose behaviour you want to compress. Kept frozen during distillation. | Section 1 |
| Student model | The smaller, trainable model that learns to imitate the teacher. | Section 1 |
| Logits | The raw, un-normalised scores a neural network outputs for each possible token before they are turned into probabilities. | Section 3 |
| Softmax | A mathematical operation that converts a list of logits into a probability distribution — numbers between 0 and 1 that sum to 1. | Section 3 |
| Cross-entropy | A standard loss function that measures how surprised the model is by the correct answer; lower cross-entropy means a more confident, correct prediction. | Section 3 |
| KL divergence | A measure of how different two probability distributions are; zero when they’re identical. Reverse-KL and forward-KL differ in which distribution is treated as the “reference.” | Section 3 |
| Forward-KL | KL divergence with the teacher as the reference; penalises the student for not covering anywhere the teacher places mass (mode-covering). | Section 3 |
| Reverse-KL | KL divergence with the student as the reference; penalises the student for placing mass where the teacher doesn’t (mode-seeking). | Section 3 |
| On-policy | Training on sequences sampled from the student’s own current distribution, not from a fixed dataset. | Section 5 |
| Policy gradient | A reinforcement-learning technique for optimising a model that samples its own outputs, by estimating how to nudge sampling probabilities to maximise an expected reward. | Section 6 |
| Chain-of-thought (CoT) rationale | A natural-language explanation of the reasoning steps a model used to reach an answer. | Section 5 |
| SFT (Supervised Fine-Tuning) | Training a pre-trained model on labelled input-output pairs with cross-entropy loss. | Section 1 |
[Analysis] label | The publication’s own reasoned assessment, distinct from what any paper itself claims. | Throughout |
[Reviewer Perspective] label | A critical or speculative assessment that goes beyond what the papers prove. | Section 11 + 12 |
[External comparison] label | A comparison to prior work or general knowledge outside the three papers. | Throughout |
Section 3: Problem formalisation
Notation table.
| Symbol | Type | Meaning | First appears in |
|---|---|---|---|
| or | distribution | Teacher’s output distribution over tokens given context | Section 3 |
| or | distribution | Student’s output distribution (parameterised by ) | Section 3 |
| vector | Student model parameters | Section 3 | |
| int | Vocabulary size | Section 3 | |
| sequence | A generated token sequence of length | Section 3 | |
| sequence | The prefix of before position | Section 3 | |
| set | Training dataset of (input, output) or (input, output, rationale) tuples | Section 3 | |
| scalar | Loss being minimised | Section 3 | |
| scalar | Weighting hyperparameter (Distilling Step-by-Step) | Section 6 | |
| scalar in | Teacher-mixing coefficient (MiniLLM) | Section 6 | |
| scalar | Accumulated log-ratio reward at step (MiniLLM) | Section 6 | |
| text | A generated rationale (Distilling Step-by-Step) | Section 6 | |
| text or class | A predicted label | Section 6 |
Formal problem statement. Given a frozen teacher language model and a smaller student language model , find student parameters such that approximates the conditional output distribution of as closely as possible under some divergence metric, while remaining cheap to run at inference time. Input space: a sequence of context tokens . Output space: a sequence of generated tokens . Objective: minimise over the training dataset .
Three distinct objectives instantiate this setup:
- MiniLLM: , reverse KL, with sampled from during training.
- Distilling Step-by-Step: , two cross-entropy heads trained jointly, with rationales generated once offline by the teacher.
- Gemma 2: , soft-target cross-entropy (equivalent to forward KL up to a teacher-entropy constant) across the entire pre-training corpus.
Assumption list.
- The teacher is much more capable than the student at the target task. All three papers depend on this; if the teacher is only marginally better than the student, none of the methods produce useful gains. [Analysis] Strong but well-justified for the regimes the papers study (540B PaLM teaching 770M T5; 7B teacher distilling a 2B Gemma; 13B GPT-2 teaching a 120M GPT-2 student).
- The student architecture has enough capacity to represent the relevant conditional distributions of the teacher. Distillation cannot make a 100M model match a 100B model on every task; capacity is a hard ceiling.
- The teacher distribution is accessible. MiniLLM and Gemma 2 require the full teacher logit distribution at every training token (the “white-box” assumption). Distilling Step-by-Step only needs the teacher’s sampled rationale text and is therefore “black-box”.
- (MiniLLM) The optimisation is stable enough to handle on-policy sampling with policy-gradient gradient estimates. [Analysis] Potentially strong assumption, MiniLLM uses PPO-style clipping plus pre-training corpus regularisation to keep the student from drifting.
- (Gemma 2) Distillation supervision is informative even when the student is trained well past Chinchilla-optimal compute. The Gemma 2 team trains 2B on 2T tokens (≈50× Chinchilla-optimal) and 9B on 8T tokens; the from-scratch baseline plateaus while the distilled model keeps improving.
Complexity argument for why this problem is hard. Naively training the student on the same data the teacher was trained on with the same loss would just reproduce a smaller version of the teacher’s training trajectory, which is exactly the “scaling laws say smaller-is-worse” result. Distillation has to extract more signal per training token than ground-truth labels carry. This is the core information-theoretic puzzle. The teacher’s full output distribution carries much more bits per token than a single hard label does. The challenge: how to consume that extra signal without destabilising training.
Domain-specific framing.
- Generative model framing: All three papers treat the output as a sequence of tokens; the distillation loss decomposes over time-steps for MiniLLM and Gemma 2.
- LLM-based framing: The teacher is itself an LLM, not an external classifier. This distinguishes the cluster from the original Hinton-Vinyals-Dean 2015 setting which assumed a single-step classification target. 4
- Data-driven framing: Distilling Step-by-Step crucially uses unlabelled inputs the teacher annotates; the teacher’s labels and rationales become the training signal.
Section 4: Motivation and gap
Real-world problem with concrete example. A frontier-class LLM like GPT-4-tier model serves a single inference at ≈100 ms for ≈0.0001. The two-order-of-magnitude cost gap is the central economic motivation for the entire field. The technical question is how much of the capability gap can be closed by distillation, and at what training cost.
Existing approaches and failure modes (per each paper’s related work).
- Sequence-level KD (Kim and Rush 2016): generate sequences with the teacher, train the student on them with standard cross-entropy. 6 Works for translation; the MiniLLM authors flag that for open-ended generation it inherits the teacher’s preferred mode and loses diversity, and the student still over-extends to rare tokens.
- Word-level forward-KL KD (Hinton et al. 2015): match the full softmax-output distribution at every step. Conceptually clean. The MiniLLM paper’s central argument is that this is mode-covering, penalising the student wherever the teacher places mass, which causes the student to give probability to teacher’s low-confidence tail tokens, producing hallucinations and degenerate generations in the open-ended setting. 1
- Hard-label SFT on teacher-generated data: common in industry. Cheap. But carries no information about the teacher’s uncertainty, the soft-target signal is the whole point.
- Pre-training from scratch on more tokens: scaling laws say returns saturate. Gemma 2 explicitly notes the from-scratch 2B model plateaus at the compute budget where the distilled 2B model continues improving.
Gap each paper claims to fill.
- MiniLLM: fill the gap between forward-KL distillation theory (assumes fixed data distribution) and open-ended generation reality (student samples its own distribution at inference). Replace forward-KL with reverse-KL on-policy.
- Distilling Step-by-Step: exploit the cheap rationale signal that frontier LLMs can produce zero-shot. Use rationales as multi-task auxiliary supervision rather than just labels.
- Gemma 2: extend distillation beyond the SFT or post-training stage to the full pre-training regime, where the compute investment is largest and the signal value of soft-targets is highest.
Practical stakes. Edge deployment, mobile inference, low-latency serving, fine-tuning on commodity GPUs, and any constrained compute budget all depend on the small-model frontier. Every additional point of MMLU or GSM8K a 2B-class model can claim translates directly into a class of applications that becomes economically viable. [External comparison] Phi-3, Qwen-2.5-3B, and Llama-3.2-3B all use distillation in some form by 2026; the Gemma-2-style pre-training KD recipe has become a de-facto industry standard for small open-weight models.
[External comparison] Position in the broader research landscape. The cluster sits at the intersection of three earlier lines of work: classical Hinton-Vinyals-Dean distillation (2015), sequence-level KD for neural translation (2016), and large-scale RLHF / on-policy learning (PPO; Schulman et al. 2017). 10 MiniLLM borrows the on-policy machinery from RLHF and applies it to distillation rather than reward maximisation. Distilling Step-by-Step borrows the multi-task framing from auxiliary-loss work and the rationale signal from CoT prompting (Wei et al. 2022). Gemma 2 takes the original Hinton-Vinyals-Dean recipe and scales it to trillions of tokens at pre-training.
Section 5: Method overview
5.1 MiniLLM
Name + source. MiniLLM, Section 3 of arXiv:2306.08543. 1
Plain-English intuition. Standard knowledge distillation tells the student “match the teacher’s probability for every possible next word.” When the vocabulary is 50,000+ tokens, most of those probabilities are tiny, the teacher might think the next word is “the” with 30% probability, “a” with 10%, and a thousand obscure words each with 0.001%. Forward-KL distillation makes the student match all of those including the long tail. The student ends up giving non-trivial probability to words the teacher actually thinks are very unlikely. When the student then generates text by sampling, it draws those rare tokens more often than it should and produces incoherent outputs. MiniLLM’s fix: train the student to match the teacher only on the words the student would actually produce (on-policy sampling), and minimise reverse-KL instead of forward-KL so the student is rewarded for concentrating on the teacher’s high-probability modes rather than for covering the teacher’s whole tail.
Mechanism step-by-step.
- Start with a student model already fine-tuned via standard SFT (this is the warm-start; MiniLLM is not from-scratch).
- For each prompt in the training set: sample a sequence from the current student.
- Compute the per-token log-ratio reward using the teacher’s logits.
- Apply length-normalised reward accumulation and PPO-style clipping.
- Take a policy-gradient step that nudges the student toward higher-reward (more teacher-aligned) sequences.
- Mix a fraction of teacher-sampled tokens during sampling (teacher-mixed sampling) to stabilise early training.
- Add a pre-training-corpus regularisation term to prevent the student from drifting away from coherent language modelling.
Connection to full pipeline. MiniLLM presupposes a competently-pre-trained and SFT-warm-started student. It is a polishing step, not an end-to-end recipe.
Design rationale + tradeoffs. Reverse-KL is mode-seeking, the student is allowed to ignore parts of the teacher’s distribution as long as it concentrates on a subset. This is exactly the right behaviour for generation: there is usually no need to faithfully reproduce every plausible continuation, only one of them. The tradeoff: reverse-KL with respect to a learned student requires policy-gradient estimation, which is higher-variance than the cross-entropy gradients forward-KL provides.
What breaks if removed. Drop the on-policy sampling and you regress to teacher-sampled training, losing the exposure-bias mitigation. Drop length normalisation and the student over-emphasises short sequences. Drop teacher-mixed sampling and early training is unstable.
Classification: [Adapted], borrows PPO from RLHF, applies it to distillation rather than reward-maximisation.
5.2 Distilling Step-by-Step
Name + source. Distilling Step-by-Step, Section 3 of arXiv:2305.02301. 2
Plain-English intuition. When you ask a frontier LLM to solve a math problem and the answer is wrong, knowing only the wrong answer doesn’t tell you much about how to fix it. But if the model also wrote out its reasoning steps (“first I added 3 and 5 to get 8, then I multiplied by 2 to get 16”), you can spot exactly where it went wrong. Distilling Step-by-Step does the inverse: ask a powerful teacher to write out both the answer and the reasoning, then train the small student to produce both. The reasoning is free auxiliary supervision, the teacher generates it for the same cost as generating the answer alone, and it gives the student much more information per training example than just the answer would.
Mechanism step-by-step.
- For each input in an unlabelled (or labelled) dataset: prompt the teacher (PaLM-540B in the paper) with a few-shot chain-of-thought template.
- The teacher returns a rationale and a label .
- Train the student via multi-task learning: one head predicts the label given the input, the other head predicts the rationale given the input. The student is a sequence-to-sequence model (T5), so the two heads are implemented by prepending different prefix tokens to the input (“[label]” vs “[rationale]”).
- Loss is where is a tuned hyperparameter.
- At test time: prepend “[label]” and read off the answer. The rationale head is supervision-only, it never runs at inference.
Connection to full pipeline. Distilling Step-by-Step is a drop-in replacement for standard task SFT. It does not depend on RL, on-policy sampling, or any pre-training-stage intervention.
Design rationale + tradeoffs. The key insight: the rationale-prediction head shares parameters with the label-prediction head, so improving the rationale objective implicitly improves the label objective via the shared representation. The tradeoff: training time roughly doubles per example (two output sequences instead of one), and the teacher must be prompted once per training input.
What breaks if removed. Drop the multi-task framing and concatenate rationale+label into a single output (the “single-task” baseline in Table 7 of the paper): performance drops materially. The multi-task split prevents the label prediction from getting contaminated by rationale-generation errors.
Classification: [Adapted], multi-task learning is classical; the contribution is which auxiliary task (CoT rationales from a frontier teacher).
5.3 Gemma 2 pre-training distillation
Name + source. Gemma 2 distillation recipe, Section 4 and Section 6 of arXiv:2408.00118. 3
Plain-English intuition. The standard way to pre-train a language model is “given the previous words, guess the next word, and we’ll tell you if you’re right.” This gives the model exactly one bit of signal per training token (right or wrong on that specific word). But if a teacher model is available, it can tell the student “here’s the full distribution over what the next word could plausibly be, for example, ‘the cat sat on the’ could be followed by ‘mat’ (45%), ‘floor’ (15%), ‘sofa’ (10%), ‘roof’ (5%), and so on.” Now the student gets thousands of bits of signal per training token. Gemma 2 applies this richer signal across the entire pre-training run, trillions of tokens, instead of just at fine-tuning time.
Mechanism step-by-step.
- Pre-train (or obtain) a large teacher model. The Gemma 2 paper uses a 7B-class teacher to distil into the 2B model and a larger teacher (the paper indicates an even-bigger model than the released 27B) to distil into the 9B.
- For each pre-training token: run the teacher forward to get its full output distribution over the vocabulary.
- The student computes its own distribution .
- Loss is the negative cross-entropy of the student against the teacher distribution: .
- Train for many more tokens than Chinchilla-optimal would prescribe (2T for 2B, 8T for 9B), distillation absorbs the extra compute productively.
Connection to full pipeline. Gemma 2 pre-training distillation replaces the standard pre-training loss. After pre-training, the model goes through standard SFT and RLHF stages. So Gemma 2’s contribution is at the bottom of the stack, MiniLLM at the top.
Design rationale + tradeoffs. [Analysis] The Gemma 2 team’s key empirical finding is that the small models keep improving on the distillation objective long past the point where from-scratch training plateaus. The tradeoff is teacher-inference cost: every training token requires a forward pass through the teacher, roughly doubling pre-training FLOPs.
What breaks if removed. From the paper’s Table 6 (per the team’s distillation ablation): a 2B model trained from scratch on 500B tokens reaches a ≈60% average benchmark; the same 2B model trained with distillation on the same 500B tokens reaches ≈67%. The ≈7-point gap is the value of the soft-target signal.
Classification: [Adapted], the underlying objective is forward-KL / Hinton-style soft-target distillation; the novelty is scale of application.
Section 6: Mathematical contributions
This is the depth section. Three MATH ENTRIES, one per paper.
MATH ENTRY [1]: MiniLLM reverse-KL objective and its policy-gradient form.
- Source: Equation 1 and Equation 2 of arXiv:2306.08543.
- What it is: A loss function that asks the student to put probability where the teacher does, while caring only about sequences the student itself is likely to produce.
- Formal definition:
-
Each term explained AND its dimensional/type analysis:
- , student parameters; is the total parameter count (e.g., 760M for a GPT-2 760M student).
- , a prompt token sequence; type: list of token IDs in .
- , generated sequence of length , sampled from the student.
- , scalar in ; the student’s probability of generating given . Computed as the product of per-token probabilities: .
- , scalar in ; the teacher’s probability of the same sequence.
- , scalar; the log-ratio. Positive when the student over-estimates the sequence relative to the teacher; negative when it under-estimates.
- , expectation; an average over many sampled prompts and sequences.
-
Worked numerical example. Consider a toy vocabulary of size (tokens A, B, C). Prompt fixed. Teacher and student per-step distributions for a single step:
- Teacher (high confidence on A).
- Student (spread out across A, B, with some on C).
Forward KL .
Reverse KL .
The two values differ, and more importantly, their gradients point the student in different directions. Forward-KL penalises the student most at the position where the teacher has high probability and the student is too low (here, token A: 0.7 vs 0.4). Reverse-KL penalises the student most where the student has appreciable probability but the teacher does not, token C: 0.2 vs 0.1, and especially token B: 0.4 vs 0.2.
Now imagine the student updates: under forward-KL it would put more mass on A (toward the teacher), but it would still keep meaningful mass on C because forward-KL doesn’t punish the student for being non-zero where the teacher is non-zero. Under reverse-KL the student would put more mass on A and aggressively reduce mass on B and C because the student is being penalised for placing probability where the teacher places less. The mode-seeking versus mode-covering distinction at a numerical level.
-
Policy gradient form (Equation 2 of the paper):
where is the cumulative log-ratio reward from position onward.
-
Proof sketch of the gradient derivation. Start from . Apply the log-derivative (score-function) trick: . With , the second term simplifies because (a standard identity). The first term yields . Decompose the sum over time steps and the in comes from a control-variate term that reduces variance without biasing the estimator. Full derivation in Appendix A of the paper.
-
Role: This gradient is what the optimiser actually computes on each MiniLLM training step. Each token in the sampled rollout contributes a gradient weighted by the cumulative log-ratio reward from that position onward.
-
Edge cases: When the teacher gives any token zero probability while the student gives it non-zero probability, the log-ratio blows up to . The paper handles this implicitly through length normalisation and PPO-style clipping; the practical effect is that the student is strongly pushed away from teacher-impossible tokens.
-
Novelty: [Adapted], reverse-KL has long been proposed for variational inference; the contribution is applying it to LLM-to-LLM distillation with on-policy sampling and PPO machinery.
-
Transferability: [Analysis] Any setup where the student model samples its own outputs at training time and a frozen teacher can score those outputs can use this gradient. Translation, code generation, dialogue.
-
Why it matters: This equation is the formal statement of “match the teacher only on what you yourself would say.” Every other choice in MiniLLM, length normalisation, teacher-mixing, PPO clipping, is a variance-reduction or stability fix on top of this core gradient.
MATH ENTRY [2]: Distilling Step-by-Step multi-task loss.
- Source: Equation 3 of arXiv:2305.02301.
- What it is: A single loss that combines two cross-entropy objectives, one for predicting the label given the input, one for predicting the rationale given the input, with a tunable weight.
- Formal definition:
where, for a sequence-to-sequence student :
-
Each term explained AND its dimensional/type analysis:
- , teacher-predicted (or ground-truth) label; type: text string for sequence-to-sequence framing.
- , teacher-generated rationale; type: longer text string than , typically 20-100 tokens.
- , input; type: text string.
- , a fixed token sequence like “[label]” that tells the seq2seq student which head to use; type: short text string.
- , scalar weight; the paper uses values around 0.5 in practice.
- , int; dataset size. The paper studies values from 720 (SVAMP) to 549,000 (e-SNLI).
- , scalar in ; student probability of the target text given the input plus prefix.
-
Worked numerical example. Consider a single SVAMP arithmetic example with “Joe has 3 apples. Mary gives him 5 more. How many does he have?”, “8”, “Joe starts with 3 apples; Mary gives him 5 more; 3 + 5 = 8.” A T5-Base student processes this twice in one batch:
- Pass 1: input is “[label] Joe has 3 apples…”; target is “8”. Suppose the student assigns probability 0.6 to “8”, then .
- Pass 2: input is “[rationale] Joe has 3 apples…”; target is the rationale. The student assigns probability to the full rationale, quite low because rationales are longer. Then .
- Total at : .
The rationale head dominates the loss numerically. Per-token, this is fine because the rationale is longer. The knob lets the practitioner downweight the rationale head when its dominance is hurting label prediction.
-
Role: Both heads share all encoder parameters and the decoder backbone, only the prefix tokens differ. The shared representation is the mechanism by which rationale supervision improves label prediction. Auxiliary-loss work has used the same pattern since the early multi-task NLP papers; the contribution here is identifying CoT rationales as a particularly informative auxiliary task.
-
Edge cases: When rationales are noisy (teacher hallucinates incorrect reasoning), the rationale head pulls the shared encoder toward incorrect representations. The paper notes this is mitigated by the weight and by the empirical finding that even noisy CoT rationales help on average.
-
Novelty: [Adapted], multi-task learning is classical; CoT prompting is from Wei et al. 2022; the contribution is the specific combination.
-
Transferability: [Analysis] Any task where a frontier LLM can generate plausible reasoning steps can plug in. Math, commonsense QA, multi-step planning. Less applicable to tasks where the teacher cannot articulate a rationale (e.g., perceptual tasks, single-token-classification with no decomposable reasoning).
-
Why it matters: This is the simplest possible distillation objective that captures “teach the small model how to think, not just what to answer.” It needs no policy gradient, no on-policy sampling, no teacher logits, just teacher text outputs.
MATH ENTRY [3]: Gemma 2 pre-training soft-target loss.
- Source: Section 4 distillation paragraph of arXiv:2408.00118.
- What it is: Standard Hinton-Vinyals-Dean soft-target cross-entropy, applied across trillions of pre-training tokens.
- Formal definition:
-
Each term explained AND its dimensional/type analysis:
- , pre-training corpus; trillions of tokens drawn from web, code, and curated sources.
- , context tokens (the prefix up to the current position); type: list of token IDs.
- , vocabulary; Gemma 2 uses a 256K-token vocabulary.
- , teacher’s probability of next-token given context; type: scalar in ; sums to 1 over .
- , student’s probability; same type.
- The sum is the negative cross-entropy of the student with respect to the teacher, equivalent to forward-KL up to the constant entropy of the teacher.
-
Worked numerical example. For a single token position with toy vocabulary of size :
- Teacher distribution: .
- Student distribution after some training: .
.
Compare to the hard-label cross-entropy if the ground-truth next token were : . The soft-target loss is larger because it captures information about the entire distribution, not just the correct token. Across trillions of tokens this extra signal compounds.
-
Equivalence to forward-KL. . Since does not depend on , minimising the cross-entropy is equivalent to minimising forward-KL. Gemma 2 is thus a forward-KL distillation at pre-training scale, the exact opposite divergence direction from MiniLLM.
-
Proof sketch of the gradient form. . Using , this simplifies to . The gradient is simply the difference between student and teacher distributions, projected through the student’s logit Jacobian. Identical structure to standard cross-entropy except the target is instead of a one-hot.
-
Role: This is the loss that replaces the standard pre-training cross-entropy. Every gradient step uses it. The compute cost is dominated by the teacher forward pass, which roughly doubles pre-training cost per token.
-
Edge cases: When the teacher is itself wrong (assigns mass to an incorrect token), the student is pulled toward the teacher’s error. This is the canonical “garbage in, garbage out” risk; the Gemma 2 team mitigates it through high-quality teacher selection and training-data curation.
-
Novelty: [Adapted], the objective is Hinton-Vinyals-Dean’s 2015 formulation; the contribution is scale (trillions of tokens) and the demonstration that distilled pre-training keeps improving past Chinchilla-optimal compute.
-
Transferability: [Analysis] Any pre-training run where a competent teacher is available can adopt this. The constraint is teacher cost: an 8T-token run with a 7B-class teacher requires roughly the same compute as pre-training a 7B model from scratch on the same tokens. Only economically sensible when the teacher already exists (e.g., a previous-generation model).
-
Why it matters: Gemma 2’s empirical demonstration is the strongest single piece of evidence in the cluster that distillation is a pre-training-stage tool, not just a post-training trick.
Section 7: Algorithmic contributions
ALGORITHM ENTRY [1]: MiniLLM training loop.
-
Source: Algorithm 1 of arXiv:2306.08543. 1
-
Purpose: Train a small student LLM to match a frozen teacher’s reverse-KL on student-sampled rollouts, with PPO stability and length-normalised rewards.
-
Inputs:
- Teacher model (frozen, ~ parameters).
- SFT-warm-started student (~ parameters).
- Prompt dataset (instruction prompts only; no target outputs needed).
- Pre-training corpus for regularisation.
- Hyperparameters: (teacher-mix coefficient), (PPO clip), learning rate , batch size , generation length .
-
Outputs: Trained student parameters .
-
Pseudocode (inline reproduction with annotation):
# MiniLLM training loop (reproduced from Algorithm 1, arXiv:2306.08543).
for step in range(num_training_steps):
# 1. Sample a batch of prompts.
x_batch = sample(D_x, size=B)
# 2. Generate sequences using teacher-mixed sampling.
y_batch = []
for x in x_batch:
y = []
for t in range(T_max):
# mix teacher and student distributions
p_mix = alpha * p(. | x, y) + (1 - alpha) * q_theta(. | x, y)
y_t = sample_from(p_mix)
y.append(y_t)
if y_t == EOS: break
y_batch.append(y)
# 3. Compute per-token log-ratio rewards.
rewards = []
for x, y in zip(x_batch, y_batch):
r = []
for t in range(len(y)):
log_p = log_prob(p, y[t], x, y[:t])
log_q = log_prob(q_theta, y[t], x, y[:t])
r.append(log_p - log_q)
rewards.append(r)
# 4. Length-normalised cumulative rewards.
R = length_normalise_cumulative(rewards)
# 5. Policy-gradient loss with PPO clipping.
loss_pg = compute_ppo_loss(q_theta, q_theta_old, x_batch, y_batch, R, epsilon)
# 6. Pre-training regularisation.
x_pre = sample(D_pre, size=B)
loss_pre = -mean(log_prob(q_theta, x_pre))
# 7. Total loss and gradient step.
loss = loss_pg + lambda_pre * loss_pre
theta = theta - eta * gradient(loss, theta)
return theta-
Hand-traced example on minimal input. Take a toy run with , , vocabulary , , prompt “X”.
- Step 1: “X”. Single prompt.
- Step 2: At the teacher says , student says . Mixed: . Sample, say we draw token A. Now . At , teacher , student , mixed . Sample B. . At sample EOS. Final .
- Step 3: log-ratio rewards. At : . At (token B): . At (EOS): say . So .
- Step 4: cumulative from each position: from : ; from : ; from : . Length-normalised: divide by length-from-position.
- Step 5: PG loss is a sum over time-steps of . Positive at but negative at , so the gradient pushes the student toward sampling A (good early-token choice) but away from the eventual continuation that produced the negative late rewards.
- Step 7: take the gradient step. Repeat.
-
Complexity. Time per training step: where are per-token teacher and student forward-pass costs. Space: for caching teacher and student logits (the dominant memory cost for large and large ). Bottleneck step: teacher forward pass during rollout generation.
-
Hyperparameters: (teacher-mix coefficient; paper uses values that decay during training); (PPO clip; standard PPO default 0.2); (pre-training regularisation weight; small); (learning rate; tuned per model size). Sensitivity: the paper reports that disabling teacher-mixing causes early-training instability; disabling length normalisation biases the student toward shorter outputs.
-
Failure modes. Reward hacking, the student learns degenerate behaviours that score well under teacher log-probability but are not actually high-quality outputs (e.g., copying high-probability prefixes). Pre-training regularisation mitigates but does not eliminate.
-
Novelty: [Adapted], the PPO loop is from Schulman et al. 2017; 10 the reward function is the contribution.
-
Transferability: [Analysis] Plug-and-play onto any LLM that has been SFT-warm-started and where teacher logits are accessible.
ALGORITHM ENTRY [2]: Distilling Step-by-Step rationale extraction + multi-task training.
-
Source: Section 3 and Figure 2 of arXiv:2305.02301. 2
-
Purpose: Augment a labelled (or unlabelled) dataset with teacher-generated CoT rationales, then train a small seq2seq student on both label and rationale prediction.
-
Inputs: Unlabelled or labelled dataset ; teacher LLM (PaLM-540B in the paper); few-shot CoT prompt template; student seq2seq model (T5).
-
Outputs: Trained student parameters.
-
Pseudocode:
# Distilling Step-by-Step (reproduced from Section 3, arXiv:2305.02301).
# Phase 1: rationale extraction (offline, run once).
augmented_D = []
for x in D:
prompt = few_shot_cot_template + x
teacher_output = teacher.generate(prompt)
r_hat, y_hat = parse_rationale_and_label(teacher_output)
augmented_D.append((x, r_hat, y_hat))
# Phase 2: multi-task student training.
for epoch in range(num_epochs):
for (x, r_hat, y_hat) in augmented_D:
# Label prediction pass.
input_label = "[label] " + x
loss_label = -log_prob(student, y_hat | input_label)
# Rationale prediction pass.
input_rationale = "[rationale] " + x
loss_rationale = -log_prob(student, r_hat | input_rationale)
loss = loss_label + lambda_weight * loss_rationale
student.update(loss)
return student-
Hand-traced example on minimal input. Take SVAMP example: “Joe has 3 apples. Mary gives him 5 more. How many does Joe have?”
- Phase 1: prompt teacher with few-shot CoT template plus . Teacher returns “Joe starts with 3 apples; Mary gives him 5 more; 3 + 5 = 8 apples. The answer is 8.” Parse: “Joe starts with 3 apples; Mary gives him 5 more; 3 + 5 = 8 apples.”, “8”. Append to augmented dataset.
- Phase 2 epoch 1: feed “[label] Joe has 3 apples…” to student; student outputs “7” (initial mistake), loss is , wait, target is “8”, student’s prob of “8” is say 0.1, so loss . Feed “[rationale] Joe has 3 apples…” to student; student outputs garbled rationale, loss say 8.0. Total: . Gradient step.
- Phase 2 epoch 10 (after training): label loss drops to say 0.1 (); rationale loss drops to 2.0; total 1.1. Student converges.
-
Complexity. Phase 1: teacher inference calls, embarrassingly parallel, done once. Phase 2: roughly 2x the FLOPs of standard SFT (two forward+backward passes per example, one per head). Memory: standard SFT.
-
Hyperparameters: (rationale weight; the paper sweeps and finds 0.5 broadly good). Few-shot prompt design (paper uses 5-8 demonstrations per benchmark). Number of training epochs (standard sequences-to-convergence count).
-
Failure modes. Hallucinated teacher rationales contaminate training. The paper notes that benchmarks where the teacher CoT is most reliable (CQA) show the largest gains; benchmarks where the teacher CoT is less reliable (SVAMP arithmetic on harder problems) show smaller gains.
-
Novelty: [Adapted], the components are individually classical; the recipe is the contribution.
-
Transferability: [Analysis] Any task where (a) a frontier LLM generates plausible reasoning, (b) labels can be parsed from the teacher output, and (c) a seq2seq student is appropriate. Wide applicability across NLP.
ALGORITHM ENTRY [3]: Gemma 2 pre-training distillation loop.
-
Source: Section 4 and Section 6 of arXiv:2408.00118. 3
-
Purpose: Pre-train a small student LLM by minimising forward-KL against a frozen teacher across trillions of tokens.
-
Inputs: Pre-training corpus ; teacher model (frozen, larger); student model architecture; batch size , sequence length , learning-rate schedule, total tokens budget .
-
Outputs: Pre-trained student parameters.
-
Pseudocode:
# Gemma 2 pre-training distillation (reproduced from Section 4 + 6, arXiv:2408.00118).
tokens_seen = 0
while tokens_seen < N:
# 1. Sample a batch of pre-training documents.
batch = sample(D_pre, size=B, length=L)
# 2. Compute teacher distributions (frozen).
with no_grad:
teacher_logits = teacher.forward(batch) # shape (B, L, V)
teacher_probs = softmax(teacher_logits)
# 3. Compute student distributions.
student_logits = student.forward(batch)
student_log_probs = log_softmax(student_logits)
# 4. Soft-target cross-entropy loss.
loss = -mean_over_positions(sum_over_vocab(teacher_probs * student_log_probs))
# 5. Backprop only into student.
loss.backward()
optimizer.step()
tokens_seen += B * L
return student-
Hand-traced example on minimal input. , (tokens “the cat sat on”), (vocab “the/cat/mat/floor/sat”), single position the prediction at token “the cat sat on” predicting next:
- Teacher logits at position 4: say → softmax . Strong on “mat”.
- Student logits: → softmax . Weaker on “mat”.
- Loss contribution at this position: .
- Gradient: pushes student logits toward , i.e., increase logit on “mat”, decrease on “the”.
- Repeat across all positions and all examples; sum gradients; take step.
-
Complexity. Per step: roughly standard pre-training FLOPs (one teacher forward + one student forward+backward). Memory: to hold the teacher distribution; with this is the dominant memory cost and motivates the top-K teacher approximation that some implementations use in practice. Total cost: FLOPs where is the from-scratch training cost.
-
Hyperparameters: Standard pre-training hyperparameters (learning rate, schedule, batch size). The distillation-specific hyperparameter is whether to use full-vocabulary soft targets or top-K teacher approximation. Gemma 2 paper does not disclose the exact K used.
-
Failure modes. Teacher errors propagate. Compute cost is dominated by teacher inference; if teacher is large enough, the cost-benefit shifts. [Analysis] The Gemma 2 team’s empirical demonstration is the strongest evidence the trade-off is favourable in the 2B-9B student regime.
-
Novelty: [Adapted], the inner loop is Hinton-style soft-target training; the contribution is operating at pre-training scale.
-
Transferability: [Analysis] Any pre-training run where a competent teacher and enough compute for forward passes is available can use this. Most practical for sub-30B-parameter students with a 30B-class or larger teacher.
Section 8: Specialised design contributions
Subsection 8A, LLM / prompt design
Applicable to Distilling Step-by-Step only.
PROMPT ENTRY [1]: Distilling Step-by-Step few-shot CoT rationale extraction.
- Source: Appendix A of arXiv:2305.02301, examples for each of the four benchmarks.
- Role in pipeline: offline, one-shot. Used to populate the augmented dataset before any student training begins.
- Prompt type: Few-shot CoT.
- Components in order: task instruction; 5-8 demonstrations, each containing an input, a human-written rationale, and a label; the target input.
- Input schema: raw input text from the benchmark (e.g., a premise+hypothesis pair for e-SNLI).
- Output schema: “rationale: <text> answer: <text>”, parsed via regex to extract rationale and label.
- Reconstructed template:
Q: [demonstration input 1]
A: [rationale 1]. The answer is [label 1].
Q: [demonstration input 2]
A: [rationale 2]. The answer is [label 2].
(... 5-8 demonstrations total ...)
Q: [target input]
A:- Failure handling. [Reconstructed] When the teacher fails to follow the format (no “The answer is” pattern), the paper appears to discard the example; exact failure rate not disclosed.
- Design rationale. Pure few-shot CoT, no instruction tuning, no chain-of-thought-specialised teacher. Works because PaLM-540B is capable enough to follow the demonstration pattern reliably across the four benchmarks studied.
- Complexity. Prompt length: ~500-1500 tokens depending on benchmark. Call count scaling: one teacher inference per training example.
- Novelty: [Adopted], few-shot CoT was introduced by Wei et al. 2022.
- Transferability: [Analysis] Trivially extensible to any task with a clear question-answer-rationale shape.
Subsection 8B, Architecture-specific details
Applicable to Gemma 2 only.
The 2B and 9B Gemma models inherit several Transformer modifications independent of the distillation recipe but worth flagging because they interact with KD effectiveness:
- Sliding window attention with window size 4096 (Beltagy et al. 2020), interleaved with global attention layers, reduces per-layer attention cost while preserving long-range capacity.
- Group-Query Attention (GQA) with 4 KV heads (2B), 8 KV heads (9B), 16 KV heads (27B), reduces KV-cache memory at inference.
- Logit soft-capping at 50.0 for attention logits, 30.0 for final logits,
logit = soft_cap * tanh(logit / soft_cap)to bound values and stabilise training. [Analysis] This soft-cap on final logits matters for distillation because it bounds the teacher’s logit magnitudes too, meaning never collapses to a true one-hot, which keeps the soft-target signal informative.
Architecture parameters table:
| Parameter | Gemma 2 2B | Gemma 2 9B | Gemma 2 27B |
|---|---|---|---|
| Model dimension | 2304 | 3584 | 4608 |
| Layers | 26 | 42 | 46 |
| Attention heads | 8 | 16 | 32 |
| KV heads (GQA) | 4 | 8 | 16 |
| Sliding window | 4096 | 4096 | 4096 |
| Logit soft-cap (attn) | 50.0 | 50.0 | 50.0 |
| Logit soft-cap (final) | 30.0 | 30.0 | 30.0 |
| Vocabulary | 256,000 | 256,000 | 256,000 |
| Training tokens | 2T | 8T | 13T |
| KD applied | yes | yes | no |
Subsection 8C, Training specifics
MiniLLM. Hardware: 8x A100 80GB for the largest experiments. Batch size: 64 prompts per gradient step. Steps: ~5,000 for the smallest models, longer for larger. Generation length: 256 tokens. Optimiser: Adam with cosine LR schedule. The PPO clip parameter is set to 0.2.
Distilling Step-by-Step. Standard T5 fine-tuning hyperparameters. Batch size 64, learning rate , AdamW. Hardware not enumerated in the paper.
Gemma 2. Pre-training on TPUv5e (2B) and TPUv4 (9B and 27B). Massive compute budgets implicit in 2T-8T-token training runs. No explicit FLOP count published.
Subsection 8D, Inference / deployment specifics
Not applicable in the conventional sense, all three papers focus on training, not inference. At inference time the student runs standalone in all three cases.
Section 9: Experiments and results
9.1 MiniLLM experiments
Datasets. Dolly, Self-Instruct, Vicuna, Super-NaturalInstructions, Unnatural Instructions, five instruction-following benchmarks of varying difficulty.
Baselines. SFT (supervised fine-tuning, no distillation); KD (forward-KL word-level); SeqKD (sequence-level KD from Kim and Rush 2016). 6
Evaluation metrics. ROUGE-L (lexical overlap with reference answers); GPT-4 score (LLM-as-judge); calibration metrics for the analysis sections.
Main quantitative results (Table 1 of the paper). Selected entries:
| Student model | Method | ROUGE-L (Dolly) | GPT-4 score |
|---|---|---|---|
| GPT-2 760M | SFT | 25.5 | 39.7 |
| GPT-2 760M | KD (forward-KL) | 31.7 | 53.4 |
| GPT-2 760M | SeqKD | 27.3 | 47.3 |
| GPT-2 760M | MiniLLM | 37.7 | 54.7 |
| OPT 6.7B | SFT | 26.0 | 64.8 |
| OPT 6.7B | KD (forward-KL) | 26.7 | 68.6 |
| OPT 6.7B | MiniLLM | 36.7 | 70.8 |
| LLaMA 7B | SFT | 28.6 | 70.1 |
| LLaMA 7B | KD | 37.9 | 73.7 |
| LLaMA 7B | MiniLLM | 40.2 | 76.4 |
Table reproduced from Table 1 of MiniLLM (arXiv:2306.08543) for editorial coverage.
The pattern is consistent: MiniLLM beats both forward-KL KD and SeqKD on every model size, with the gap roughly 5-10 ROUGE-L points and 1-5 GPT-4-score points.
Ablations. Removing length normalisation: -1.5 ROUGE-L. Removing teacher-mixed sampling: training instability in the first 1000 steps. Removing pre-training regularisation: drift away from coherent language modelling.
Robustness / qualitative. The paper reports MiniLLM has lower exposure bias (a measure of how the student degrades as generation length increases) and better calibration than forward-KL baselines.
9.2 Distilling Step-by-Step experiments
Datasets. e-SNLI, ANLI, CQA, SVAMP, four benchmarks chosen for diverse task types.
Baselines. Standard fine-tuning (label-only); standard distillation (teacher-label-only); zero-shot teacher prompting.
Evaluation metrics. Task-specific accuracy.
Main results. Per the paper’s Tables 4-7:
- T5-220M (Base) on e-SNLI with full data: standard finetuning 88.4%; Distilling Step-by-Step 89.5%.
- T5-770M on e-SNLI with 12.5% of training data: Distilling Step-by-Step 89.5%, matching the full-data baseline.
- T5-770M outperforms 540B PaLM on three of four benchmarks using only 80% of the labelled data on average.
[Analysis] The headline claim, a 770M model outperforming a 540B model, requires careful framing. The comparison is on a specific benchmark set after the 770M is fine-tuned via Distilling Step-by-Step; the 540B PaLM is zero-shot or few-shot. The comparison demonstrates task-specific compression, not general-capability compression.
Ablations. Removing the multi-task split (single-task concatenated rationale+label): performance drops 2-5 points. The multi-task split is the key design choice.
9.3 Gemma 2 experiments
Datasets. Standard LLM evaluation suite, MMLU, HellaSwag, ARC, GSM8K, HumanEval, and others.
Baselines. Within-paper comparison: distillation versus from-scratch training at matched compute. External comparison: Mistral-7B, LLaMA-3-8B, Qwen-2-7B as 7B-class peers; LLaMA-3.2-1B, Phi-3-mini as 2B-class peers.
Evaluation metrics. Standard accuracy/pass@1 on the named benchmarks.
Main results.
- Gemma 2 9B beats Mistral-7B by ~5 points on MMLU.
- Gemma 2 2B beats Gemma 1 2B by 10+ points on MMLU.
- Per the paper’s Table 6 (distillation ablation): 2B model from scratch on 500B tokens reaches 60.3% average; 2B with distillation reaches 67.7%.
Independent benchmark cross-checks. [External comparison] Gemma 2 9B’s MMLU score of ~71% has been independently reproduced on Hugging Face’s Open LLM Leaderboard. Gemma 2 2B’s ~52% MMLU is independently reproducible. [Reviewer Perspective] The distillation ablation specifically (Table 6) has not been independently reproduced as of writing; outside teams typically cannot reproduce because the teacher and pre-training data are not fully released. The reported gain rests on internal Google measurement.
Experimental scope limits. Gemma 2 does not publish a same-budget from-scratch comparison at 2T tokens (the actual training budget for the 2B). The 500B-token comparison in Table 6 is suggestive but not the apples-to-apples test.
Evidence audit.
- [Analysis] Strongly supported claims: MiniLLM’s ROUGE-L gain over forward-KL on instruction-following; Distilling Step-by-Step’s data-efficiency on the four benchmarks tested.
- [Analysis] Partially supported claims: Gemma 2’s 2B distillation gain over from-scratch, the comparison is at 500B tokens, not the full 2T.
- [Analysis] Claims relying on narrow evidence: Distilling Step-by-Step’s “770M beats 540B” framing is task-specific and benchmark-specific.
Section 10: Technical novelty summary
| Component | Type | Novelty | Justification | Source |
|---|---|---|---|---|
| Reverse-KL distillation for LLMs | Combination novel | Reverse-KL is classical; on-policy + LLM application is new | MiniLLM Section 3 | |
| Teacher-mixed sampling | Incrementally novel | Mitigates early-training instability for on-policy KD | MiniLLM Section 3.3 | |
| Length normalisation of reverse-KL reward | Incrementally novel | Specific fix for length-bias in policy-gradient KD | MiniLLM Equation 6 | |
| CoT rationales as multi-task auxiliary signal | Combination novel | Multi-task and CoT are classical; combining for KD is new | Distilling Step-by-Step Section 3 | |
| Multi-task split vs concatenated output | Incrementally novel | Empirical finding that split outperforms concat | Distilling Step-by-Step Table 7 | |
| Forward-KL soft-target loss at pre-training scale | Adopted (scale is the novelty) | Hinton et al. 2015 objective applied to 2T-8T-token runs | Gemma 2 Section 4 | |
| 50x-Chinchilla training with distillation | Combination novel | Distillation supervision absorbs the extra compute | Gemma 2 Section 6 | |
| Logit soft-capping interaction with KD | Incrementally novel | Bounded teacher logits keep soft-target signal informative | Gemma 2 Section 4 (architecture) |
Single most novel contribution. [Analysis] MiniLLM’s combination of reverse-KL + on-policy sampling + PPO clipping for LLM distillation is the most genuinely novel idea in the cluster. Gemma 2’s contribution is scale-up of a known recipe; Distilling Step-by-Step’s contribution is a clever combination of known parts; MiniLLM rethinks which divergence to minimise and which data to train on. The conceptual shift, from “match the teacher’s distribution everywhere” to “match the teacher only on what you would generate”, is the most field-shaping idea.
What the papers do NOT claim to be novel. None of the three claim a new architecture. None claim a new pre-training data recipe. None claim novel optimiser, novel learning-rate schedule, or novel tokenizer. The PPO machinery in MiniLLM is borrowed from Schulman et al. 2017. The CoT prompting in Distilling Step-by-Step is borrowed from Wei et al. 2022. The soft-target loss in Gemma 2 is borrowed from Hinton et al. 2015.
Section 11: Situating the work
What prior work did. Classical knowledge distillation (Hinton, Vinyals, Dean 2015) 4 introduced soft-target cross-entropy for classification networks. Sequence-level KD (Kim and Rush 2016) extended it to encoder-decoder NMT by training on teacher-generated sequences. RLHF (Christiano et al. 2017; Ouyang et al. 2022) introduced PPO-based policy gradients for LLM alignment.
What each paper changes conceptually.
- MiniLLM: reverses the KL direction and brings on-policy sampling from RLHF into the distillation toolbox. Conceptually: distillation moves from being a teacher-imitation problem to being a reward-maximisation problem where the reward is the teacher log-likelihood ratio.
- Distilling Step-by-Step: reframes distillation as data augmentation. The teacher’s value is not just its labels, it is its reasoning. Conceptually: shift from logit-distillation to text-distillation.
- Gemma 2: demonstrates that distillation is a pre-training-time tool, not just a fine-tuning trick. Conceptually: the cleanest empirical evidence so far that soft-target supervision is information-richer than hard-label supervision at the largest training budgets.
Two contemporaneous related papers worth naming.
- GKD: Generalized Knowledge Distillation (Agarwal et al., 2023, arXiv:2306.13649). 5 Published one week after MiniLLM. Independently argues for on-policy distillation and extends to arbitrary -divergences. [Analysis] GKD’s framing, student samples its own data, teacher provides soft targets, is essentially MiniLLM’s framing without the policy-gradient apparatus; the two converged independently.
- Sequence-Level Knowledge Distillation (Kim and Rush 2016, arXiv:1606.07947). 6 Pre-LLM. Establishes the alternative to word-level KD, train the student to imitate the teacher’s sampled outputs with hard cross-entropy. MiniLLM and GKD both cite SeqKD as a baseline; MiniLLM in particular outperforms SeqKD across all studied model sizes.
[Reviewer Perspective] Strongest skeptical objection. The MiniLLM paper’s reverse-KL framing rests on the mode-covering versus mode-seeking distinction, but follow-up work (notably GKD and several 2024-2025 distillation studies) has argued that the on-policy sampling matters far more than the choice of divergence, when you use student-sampled data, even forward-KL becomes mode-seeking-in-practice because the student only sees what it is likely to generate. If this view is correct, MiniLLM’s reverse-KL is a more complicated way to achieve what GKD-style on-policy forward-KL achieves more simply.
[Reviewer Perspective] Strongest author-side rebuttal. From the paper: MiniLLM’s controlled ablations show that reverse-KL outperforms on-policy forward-KL on the same data, at least on the instruction-following benchmarks studied. The Pareto frontier of “best divergence on this data” is reverse-KL by the paper’s own measurements. The rebuttal is empirical: the paper shows it works.
What remains unsolved.
- Composing the three approaches. None of the papers integrate the others. A combined “Gemma-2-style pre-training KD, then Distilling-Step-by-Step-style SFT, then MiniLLM-style reverse-KL polish” pipeline is the obvious 2026 industry recipe but is not formally studied.
- The teacher-cost curve. None of the three papers systematically study teacher-size-versus-student-quality scaling. How much does the teacher need to be bigger than the student?
- Multimodal extension. All three are language-only. Vision-language distillation is an active 2026 research front but not addressed here.
Three future research directions.
- Composable distillation stages with shared teachers. The Gemma 2 team likely already does this internally for Gemma 3; a public study of stage-composition would benefit the open-source ecosystem.
- Adaptive divergence selection. When in training does forward-KL help, when does reverse-KL help? An adaptive schedule could combine the best of both.
- Distillation from black-box APIs. MiniLLM assumes white-box teacher logits; Distilling Step-by-Step works with text outputs only. A formal study of the cost-quality trade-off between white-box and black-box distillation would clarify when one is worth the other.
Section 12: Critical analysis
Strengths with concrete evidence (cluster-wide).
- MiniLLM: clean ablations (Table 4 of paper), consistent gains across 120M-13B parameter range, public code release on GitHub. 7
- Distilling Step-by-Step: strong data-efficiency claim is well-supported on four diverse benchmarks; public code release. 8
- Gemma 2: large-scale demonstration with publicly-released checkpoints (Gemma 2 2B, 9B, 27B on Hugging Face 9 ); detailed architecture disclosure.
Weaknesses explicitly stated by the authors.
- MiniLLM: the paper notes that PPO instability remains a risk for very small students and that the method does not extend trivially to non-text generation.
- Distilling Step-by-Step: the paper acknowledges that rationale quality bounds the method’s effectiveness and that the four benchmarks studied do not cover all task types.
- Gemma 2: the paper notes that distillation requires significant teacher inference compute and that the technique is most effective when the teacher significantly outperforms the from-scratch student.
Weaknesses not stated or understated.
- [Reviewer Perspective] MiniLLM: the comparison to GKD is awkward, both papers landed in the same week with similar core insights, and the MiniLLM paper does not (could not) compare against GKD in its main results. As of 2026, follow-up work tends to cite GKD as the canonical “on-policy KD” reference and MiniLLM as the specific reverse-KL variant.
- [Reviewer Perspective] Distilling Step-by-Step: the “770M beats 540B” headline is task-specific and selected for the four benchmarks studied. The paper does not test on a broader benchmark suite where the 540B teacher’s general-knowledge advantage would dominate.
- [Reviewer Perspective] Gemma 2: the distillation ablation (Table 6) is at 500B tokens, not 2T (the actual 2B training budget). The matched-compute apples-to-apples test at the full training budget is not published. [Analysis] This is a legitimate gap; the gain at 500B may or may not extrapolate.
Reproducibility check.
| MiniLLM | Distilling Step-by-Step | Gemma 2 | |
|---|---|---|---|
| Code released | yes (microsoft/LMOps) 7 | yes (google-research) 8 | partial (inference only) |
| Data released | yes (instruction data) | yes (extracted rationales) | no (pre-training data not released) |
| Hyperparameters | full disclosure | full disclosure | partial |
| Compute reported | implicit (8x A100) | not reported | partial |
| Trained weights | yes | yes | yes (Gemma 2 2B/9B/27B on HF) 9 |
| Evaluation set | public benchmarks | public benchmarks | public benchmarks |
| Overall | fully reproducible | fully reproducible | partially — model usable, training recipe is not end-to-end reproducible |
Methodology disclosure.
- MiniLLM: Sample size, five benchmarks, sample counts not explicitly per-benchmark. Evaluation set, Dolly, Self-Instruct, Vicuna, S-NI, UnI (all public; contamination check not reported). Baselines, SFT, KD (forward-KL), SeqKD. Hardware/compute, 8x A100 80GB implicit.
- Distilling Step-by-Step: Sample size, four benchmarks ranging from 720 to 549K training examples. Evaluation set, e-SNLI, ANLI, CQA, SVAMP. Baselines, standard finetuning, standard KD, zero-shot/few-shot 540B PaLM. Hardware/compute, not reported in detail.
- Gemma 2: Sample size, full pre-training corpus (2T/8T/13T tokens). Evaluation set, standard LLM evaluation suite. Baselines, internal from-scratch ablation; external (Mistral, LLaMA, Qwen). Hardware/compute, TPUv5e/TPUv4; total FLOPs not published.
Generalisability.
- MiniLLM is generalisable to any post-SFT distillation setting where teacher logits are available.
- Distilling Step-by-Step is generalisable to any task where teacher CoT rationales can be elicited.
- Gemma 2’s recipe is generalisable to any pre-training run where a competent teacher and 2x compute are available.
Assumption audit. The key shared assumption, that the teacher is significantly more capable than the student, is realistic in all three cases. The fragile assumptions sit elsewhere: MiniLLM’s PPO stability, Distilling Step-by-Step’s rationale quality, Gemma 2’s teacher-availability.
What would make each paper significantly stronger.
- MiniLLM: direct head-to-head with GKD on the same benchmarks.
- Distilling Step-by-Step: broader benchmark coverage including generative tasks; a study of rationale-quality sensitivity.
- Gemma 2: the apples-to-apples 2T-token from-scratch comparison; disclosure of the teacher model size used for the 9B student.
Section 13: What is reusable for a new study
REUSABLE COMPONENT [1]: Reverse-KL + on-policy sampling (from MiniLLM).
- What it is: the core MiniLLM training loop with PPO clipping.
- Why worth reusing: substantial gains over forward-KL on instruction-following.
- Preconditions: SFT-warm-started student; access to teacher logits; on-policy sampling infrastructure.
- What would need to change in a different setting: the reward formulation may need adjustment for non-text-generation tasks.
- Risks: PPO instability; reward hacking on simple teacher-likelihood proxies.
- Interaction effects: benefits from being applied after a Gemma-2-style pre-training KD and a Distilling-Step-by-Step-style SFT.
REUSABLE COMPONENT [2]: CoT rationale multi-task supervision (from Distilling Step-by-Step).
- What it is: the dataset-augmentation step plus multi-task seq2seq training.
- Why worth reusing: cheap (one teacher call per example), data-efficient.
- Preconditions: a capable teacher; a task amenable to natural-language reasoning.
- What would need to change: the prompt template per task; the weight per task.
- Risks: hallucinated rationales degrade the shared encoder.
- Interaction effects: synergistic with reverse-KL polishing, the rationale-augmented student has a stronger starting point.
REUSABLE COMPONENT [3]: Soft-target pre-training KD (from Gemma 2).
- What it is: replacing the standard pre-training cross-entropy with soft-target KL against a teacher.
- Why worth reusing: biggest single empirical gain at the pre-training stage; absorbs extra compute productively.
- Preconditions: an existing competent teacher model; 2x the from-scratch compute budget; ability to stream teacher logits at training time.
- What would need to change: possibly top-K teacher approximation for memory; the exact teacher-student compute ratio.
- Risks: teacher errors propagate; teacher-inference cost dominates.
- Interaction effects: lays the foundation that the other two techniques build on.
Dependency map. Gemma-2-style pre-training KD provides the strongest base model. Distilling Step-by-Step provides a cheap SFT-stage augmentation. MiniLLM provides a post-SFT polish. The three are temporally ordered, not competing.
Recommendation. [Analysis] For a team starting a new small-model project in 2026: adopt Gemma-2-style soft-target pre-training KD first (biggest gain), then layer Distilling Step-by-Step at SFT, then optionally polish with MiniLLM reverse-KL on the instruction-following slice. Gemma-2 is the single highest-payoff component.
[Analysis] What type of new study benefits most. Any open-weight or in-house small-model effort in the 1B-10B parameter range targeting consumer or edge deployment.
Section 14: Known limitations and open problems
Limitations explicitly stated by the authors (cluster-wide).
- Teacher availability assumption, all three depend on an already-existing competent teacher.
- Compute cost, all three roughly double effective training cost via teacher inference.
- Task-type scoping, MiniLLM evaluated on instruction-following; Distilling Step-by-Step on four NLP benchmarks; Gemma 2 on the standard LLM eval suite.
Limitations not stated.
- [Analysis] Teacher-update gap. If a better teacher becomes available after distillation, the student is locked to the older teacher’s biases. No paper addresses incremental teacher updates.
- [Reviewer Perspective] Multimodal extension. All three are language-only. Vision-language distillation is an open frontier.
- [Reviewer Perspective] Energy and carbon cost. Distillation roughly doubles training FLOPs; the carbon implications at trillion-token scales are non-trivial and not discussed.
Technical root causes.
- The teacher-availability assumption is a chicken-and-egg constraint: the first competent model in any domain has to be trained from scratch.
- The compute cost stems from the need for full teacher logits at every training token; top-K approximations help but do not eliminate.
- The task-scoping gap is the natural consequence of empirical evaluation budget, no paper can test everything.
Open problems left behind.
- A formal characterisation of when reverse-KL is preferable to forward-KL in LLM distillation.
- A theory of how much teacher capability the student can absorb as a function of student capacity and training-token budget.
- Composable multi-stage distillation pipelines.
Most critical follow-up. [Analysis] A controlled, publicly-reproducible study that compares all three approaches and their composition at matched compute. The 2026 field needs this to choose between methods rationally.
How this article reads at three depths
For the curious high-school reader. Big AI models like GPT-4 are powerful but expensive to run. Knowledge distillation is how researchers shrink a big model down into a small one while keeping most of its skill. These three papers each show a different way to do that, and together they explain why a small open model from Google (Gemma 2) can hold its own against models twice its size.
For the working developer or ML engineer. Three production-relevant techniques covering three training stages: Gemma 2 for pre-training-stage soft-target KD (highest impact, biggest compute commitment); Distilling Step-by-Step for SFT-stage CoT rationale augmentation (cheapest gain per dollar); MiniLLM for post-SFT reverse-KL polish on instruction-following (best for chat models). Engineering trade-offs: Gemma 2 requires teacher-logit streaming at training time and roughly 2x compute; Distilling Step-by-Step requires one teacher inference per training example offline; MiniLLM requires PPO machinery and on-policy sampling infrastructure. Pick based on which stage your team controls. The 2026 industry default for small-model pre-training has converged on Gemma-2-style soft-target distillation.
For the ML researcher. The most genuinely novel idea is MiniLLM’s reverse-KL + on-policy + PPO combination; the most impactful empirical demonstration is Gemma 2’s 50x-Chinchilla distilled pre-training. The strongest skeptical objection is that on-policy sampling matters more than KL direction (the GKD critique). Load-bearing assumptions: white-box teacher access (MiniLLM, Gemma 2); high-quality CoT rationales (Distilling Step-by-Step); 2x teacher-inference compute (all three). A follow-up paper would need to study composition of all three stages at matched compute, with a controlled teacher-size-versus-student-capacity sweep, on a benchmark suite broader than instruction-following.
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. Gu, Dong, Wei, Huang — MiniLLM: Knowledge Distillation of Large Language Models, ICLR 2024 (arXiv:2306.08543) (accessed ) ↩
- 2. Hsieh et al. — Distilling Step-by-Step: Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes, Findings of ACL 2023 (arXiv:2305.02301) (accessed ) ↩
- 3. Gemma Team — Gemma 2: Improving Open Language Models at a Practical Size (arXiv:2408.00118) (accessed ) ↩
- 4. Hinton, Vinyals, Dean — Distilling the Knowledge in a Neural Network (arXiv:1503.02531) (accessed ) ↩
- 5. Agarwal et al. — On-Policy Distillation of Language Models / GKD (arXiv:2306.13649) (accessed ) ↩
- 6. Kim and Rush — Sequence-Level Knowledge Distillation (arXiv:1606.07947) (accessed ) ↩
- 7. MiniLLM official GitHub repository (microsoft/LMOps) (accessed ) ↩
- 8. Distilling Step-by-Step official GitHub repository (google-research) (accessed ) ↩
- 9. Gemma 2 9B model card on Hugging Face (accessed ) ↩
- 10. Schulman et al. — Proximal Policy Optimization Algorithms (arXiv:1707.06347) (accessed ) ↩
Anonymous · no cookies set