JEPA, I-JEPA, V-JEPA: Predicting in Latent Space Instead of Pixels
Multi-paper review of Joint Embedding Predictive Architectures: LeCun's framework, I-JEPA (Assran 2023), V-JEPA (Bardes 2024), feature-space prediction.
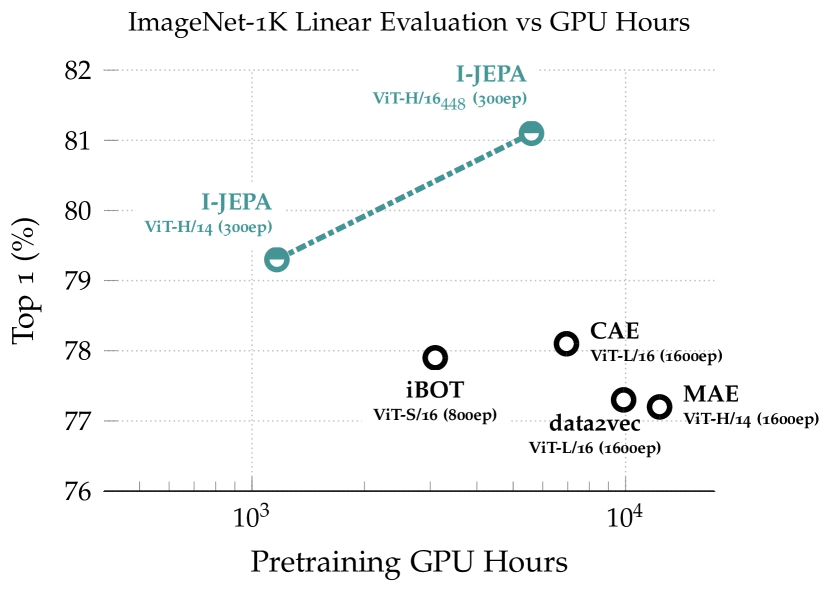
Figure 1 of I-JEPA (arXiv:2301.08243), reproduced for editorial coverage.
1. Umbrella scope and paper identities
This review covers three artefacts that together codify the Joint Embedding Predictive Architecture (JEPA) research line:
- LeCun (2022). A Path Towards Autonomous Machine Intelligence, OpenReview position paper version 0.9.2 6 . A framework essay that introduces JEPA as the centrepiece of a six-module cognitive architecture (perception, world model, configurator, cost, actor, short-term memory) and argues that machines should predict in abstract feature space rather than at the pixel level.
- Assran et al. (2023). Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture (I-JEPA), CVPR 2023 1 . The first large-scale empirical instantiation of JEPA on still images.
- Bardes et al. (2024). Revisiting Feature Prediction for Learning Visual Representations from Video (V-JEPA), arXiv:2404.08471 4 . Extends the I-JEPA recipe to video and isolates feature-space prediction as the load-bearing design choice.
Retrieval. I-JEPA was retrieved via the ar5iv HTML render 3 (which carried the method tables, ablations and the multi-block masking visualisation) and the arXiv abstract page 1 . V-JEPA was retrieved via the ar5iv render 5 and the arXiv abstract page 4 , with the official facebookresearch/jepa repository 9 consulted for hyperparameter defaults. LeCun’s 2022 position paper PDF returned binary content that could not be parsed by the fetch tool; the framework summary below is reconstructed from the OpenReview abstract 6 plus the 2023 follow-up tutorial paper by Dawid and LeCun 7 and is labelled [Reconstructed] where it goes beyond what the abstract directly supports.
Classification. Architecture proposal · Representation learning · Theoretical (LeCun framework) · Generative-vs-predictive contrast. Cross-cutting tags: world models, self-supervised learning, energy-based models.
Technical abstract (publication voice). JEPA is a self-supervised learning architecture family in which a context encoder, a target encoder (updated as an exponential moving average of the context encoder), and a small predictor network are trained jointly to make the predictor’s output match the target encoder’s embedding of a masked region. The loss is computed in embedding space, not pixel space. I-JEPA applies this recipe to still images and reports that a ViT-Huge/14 reaches 79.3% ImageNet linear-probe accuracy after 300 epochs on 16 A100 GPUs in under 72 hours 3 . V-JEPA scales the recipe to video using 2 million clips and a 3D tube-masking strategy, reaching 82.0% on Kinetics-400 and 71.4% on Something-Something-v2 under a frozen-backbone attentive-probe evaluation 5 . LeCun’s 2022 position paper frames JEPA as the perceptual front end of a broader cognitive architecture and as the building block for hierarchical world models 6 .
Primary research question. Can a self-supervised vision system learn semantically useful representations by predicting masked features in latent space — without pixel-level reconstruction, without contrastive negatives, without hand-crafted augmentations — and does that recipe transfer from images to video to broader world-model use?
Core technical claim. From the paper: predicting in the embedding space of a slowly-updated target encoder, with a sufficiently informative context block and semantically meaningful target blocks, yields representations competitive with or better than pixel-reconstruction (MAE) and view-invariance (DINO, iBOT) approaches at substantially lower compute 3 , and the same recipe extends to video 5 .
Core technical domains. Self-supervised learning (deep). Vision transformers and masking strategies (deep). Energy-based modelling and collapse prevention (moderate, mostly via LeCun’s framing). Action recognition and motion understanding evaluation (moderate). World-model framing (surface — LeCun’s framework is largely speculative and this article labels it as such where appropriate).
Reader prerequisites. High-school algebra is sufficient for the on-ramp. Familiarity with the transformer block, the concept of an embedding vector, and the idea of “masked language modelling” (BERT-style) helps but the Glossary in Section 2.5 covers every prerequisite term needed to read the rest of the article.
2. TL;DR and executive overview
TL;DR (three sentences). A new family of vision learning systems called Joint Embedding Predictive Architectures (JEPA) trains computers to look at part of an image or video and predict what the meaning of the hidden parts would be, rather than predicting the hidden pixels themselves. Two papers from Meta — I-JEPA for still images and V-JEPA for video — show this idea actually works: the resulting models match or beat older approaches at less than half the compute and without the hand-crafted “look at the same picture two different ways” tricks earlier methods relied on. The underlying motivation comes from a 2022 essay by Yann LeCun arguing that human-like AI will need to predict abstract features of the world, not photorealistic pixel grids, because most of the pixels in any real scene are unpredictable noise.
Executive summary. JEPA proposes a structural change to how vision models learn. Instead of asking the model to fill in masked pixels (like MAE) or to make two augmented views of the same image agree (like DINO or SimCLR), JEPA asks the model to predict the embedding (the compressed feature vector) that a slowly-updated copy of itself would produce on the masked region. The I-JEPA paper shows this trains faster than pixel methods and yields better off-the-shelf representations for linear classification and low-shot tasks; the V-JEPA paper shows the same trick extends to video, where pixel prediction is especially wasteful because most pixel-level variation across frames is irreducibly stochastic. The framework matters because it offers a tractable middle path between generative reconstruction (expensive, often unfocused) and contrastive learning (sensitive to augmentation choices).
Five practitioner takeaways.
- Predicting in feature space converges 2-5x faster than predicting in pixel space at matched accuracy 3 5 .
- The masking strategy is load-bearing: multi-block masking with semantically-sized target blocks beats random masking by a wide margin on I-JEPA’s ImageNet linear probe 3 .
- The target encoder must be a slow EMA of the context encoder — using the same encoder for both, or stopping gradient without EMA, causes representation collapse in practice 6 .
- V-JEPA’s frozen-backbone evaluation matters: the features are useful without fine-tuning, which is the practical regime for downstream multi-task deployment 5 .
- JEPA does not let you generate images or video — it learns representations, not samples; pair it with a separate decoder if generation is the downstream need.
Pipeline overview. Training-time: sample a context block from an image (or short video clip), sample several target blocks, encode the context with the context encoder, encode the full image with the EMA target encoder, run the predictor on the context embedding plus positional cues for the target locations, and minimise the L2 (I-JEPA) or L1 (V-JEPA) distance between the predicted and target embeddings. Inference-time: discard the predictor; use the context encoder alone as a frozen feature extractor; attach a linear probe, attentive probe, or full fine-tune head for the downstream task.
2.5 Glossary
| Term | Plain-English explanation | First appears in |
|---|---|---|
| Embedding | A list of numbers (typically a vector of 384 to 1280 values) that summarises the meaning of an image patch, a word, or a video clip. Two patches with similar meanings get similar embedding vectors. | Section 1 |
| Self-supervised learning | Training a model without human-provided labels by inventing a task the model can grade itself on, like filling in a masked patch. | Section 1 |
| Masking | Hiding part of the input (a patch of an image, a segment of audio) and asking the model to predict the hidden part from the visible part. | Section 1 |
| Encoder | A neural network that takes raw input (image pixels, video frames) and outputs an embedding. | Section 1 |
| Predictor | A second, usually smaller, neural network that takes the encoder’s output and predicts the embedding of the hidden region. | Section 1 |
| Exponential moving average (EMA) | A way to maintain a slowly-changing copy of a model’s weights by mixing in a small fraction of the latest weights each step. Used to keep the target side stable during training. | Section 1 |
| Linear probe | An evaluation method: freeze the encoder, train only a single linear layer on top for the downstream task, and measure accuracy. Tests whether the embedding alone is informative. | Section 1 |
| Vision Transformer (ViT) | The dominant modern vision architecture: split the image into 16x16 patches, treat each patch like a token, run a transformer over the token sequence. | Section 1 |
| Representation collapse | A failure mode in self-supervised learning where the encoder learns to output the same constant vector for every input — the loss goes to zero but the model is useless. | Section 2 |
[Analysis] label | The publication’s own reasoned assessment, distinct from what the paper itself claims. | Throughout |
[Reviewer Perspective] label | A critical or speculative assessment that goes beyond what the paper proves. | Sections 11 + 12 |
[Reconstructed] label | Content the publication faithfully reconstructed because the paper only partially disclosed it or the source could not be fully fetched. | Sections 3 + 5 |
[External comparison] label | A comparison to prior work or general knowledge outside the paper itself. | Sections 4 + 11 |
| ”From the paper:” prefix | Content directly supported by the paper’s text, equations, tables, or figures. | Throughout |
Figure 2 of I-JEPA (arXiv:2301.08243), reproduced for editorial coverage.
3. Problem formalisation
Notation.
| Symbol | Type | Meaning | First appears in |
|---|---|---|---|
| Tensor | The visible (context) portion of the input image or video | Section 3 | |
| Tensor | The hidden (target) portion to be predicted | Section 3 | |
| Function | Context encoder with trainable parameters | Section 3 | |
| Function | Target encoder, an EMA copy of , parameters not optimised by gradient | Section 3 | |
| Function | Predictor network with trainable parameters | Section 3 | |
| Vector | Embedding of the context | Section 3 | |
| Vector | Embedding of the target (no gradient through this) | Section 3 | |
| Vector | Positional information identifying where the target sits in the input | Section 3 | |
| Function | Distance function (L2 for I-JEPA, L1 for V-JEPA) | Section 3 | |
| Scalar | EMA momentum (0.996 to 1.0 for I-JEPA, 0.998 to 1.0 for V-JEPA) | Section 5 | |
| Integer | Number of target blocks sampled per image (M=4 for I-JEPA) | Section 3 |
Formal problem statement. Given an input partitioned into a visible context and a hidden target , learn parameters (encoder) and (predictor) such that
where is the stop-gradient operator and is maintained as . The objective is computed over a dataset of images (I-JEPA) or short video clips (V-JEPA).
Assumptions (from the paper).
- The target encoder , despite being a slow copy of , produces meaningful targets — i.e., its embeddings carry semantic structure rather than collapsing to a constant. This holds empirically in both papers; it is not proven analytically 3 5 .
- The masking distribution is such that the context block contains enough information to plausibly predict the targets. I-JEPA enforces this via a context-block scale range of (0.85, 1.0) of the image area; V-JEPA does so via short-range plus long-range 3D tube masking covering ~90% of the spatio-temporal volume on average 3 5 .
[Analysis] Potentially strong assumption.The target embedding’s stop-gradient prevents the trivial collapse where the encoder learns to output zeros, but does not by itself prevent partial collapse where the encoder ignores task-relevant variance. Both papers rely on architectural and masking choices to avoid this, not on an explicit regulariser like VICReg 11 .
Why the problem is structurally hard. Pixel-level prediction is hard because most pixel variation across natural images and especially video is irreducibly stochastic (the exact lighting, sensor noise, motion blur), so a model trained to minimise pixel-MSE wastes capacity on unpredictable detail. Feature-level prediction defers the choice of what to predict to the encoder itself: the encoder is incentivised to discard unpredictable detail because including it would make the target harder to match. This is the central thesis of LeCun’s 2022 framework 6 . [Analysis] The mathematical risk is that the encoder discards too much — collapsing to a constant — and the engineering of JEPA is largely about preventing that collapse without an explicit regulariser.
No causal claim. None of the three papers make causal-discovery claims; they are representation-learning papers.
Data assumptions. I-JEPA: ImageNet-1K (1.28M images) plus ImageNet-22K (14M images) for the largest variants 3 . V-JEPA: VideoMix2M, a curated mix of Kinetics-400/600/700 + Something-Something-v2 + HowTo100M totalling roughly 2 million clips 5 .
4. Motivation and gap
The real-world problem. A self-supervised vision system that learns useful representations from unlabelled images and video is the prerequisite for foundation models in vision, the perceptual front end of robotics policies, and the world-model component LeCun frames as essential for autonomous agents 6 . The two dominant pre-2022 approaches each had a load-bearing weakness.
Existing approaches and their failure modes.
- Masked Autoencoders (MAE) by He et al. 10 mask 75% of image patches and ask the decoder to reconstruct pixel values. The approach works but the resulting representations lag behind contrastive methods on linear-probe evaluations and the model spends substantial capacity learning to render texture detail.
- Contrastive / view-invariance methods (SimCLR, MoCo, DINO, iBOT) train an encoder to produce similar embeddings for two augmented views of the same image. Strong results on linear probes, but performance is sensitive to the choice of augmentations (colour jitter, random crop, Gaussian blur) and the augmentations themselves encode human priors about what should be invariant — priors that may not transfer outside natural-image domains.
- data2vec by Baevski et al. 14 introduced the feature-prediction objective with an EMA target encoder before I-JEPA. [External comparison] I-JEPA’s contribution relative to data2vec is the multi-block masking strategy (predicting several semantically-sized target blocks from a single large context block), which the I-JEPA ablations show is critical for the linear-probe result 3 .
The gap the papers claim to fill. I-JEPA claims to combine the off-the-shelf representation quality of contrastive methods with the augmentation-independence of masked-image-modelling, while training faster than either. V-JEPA claims to be the first system that demonstrates the same recipe scales to video and that feature prediction in particular (rather than pixel prediction) is the load-bearing choice 5 .
Why prior methods were insufficient per the papers. From I-JEPA: pixel-prediction methods underperform on linear probes because the encoder is forced to retain low-level texture information that downstream linear classifiers cannot use; view-invariance methods need augmentations to define what should be invariant, and the augmentations are hand-tuned per dataset 3 . From V-JEPA: pixel prediction in video is especially wasteful because motion-induced pixel changes carry high variance that the model spends capacity learning, while feature prediction lets the encoder discard motion noise it cannot predict 5 .
Practical stakes. [External comparison] The downstream applications most affected are video understanding (action recognition, video Q&A), robotics (where the encoder is the perceptual front end of a policy), and any setting where a frozen backbone needs to serve many heterogeneous downstream tasks without per-task fine-tuning.
Position in broader research landscape. [External comparison] JEPA sits between the generative-modelling line (autoregressive image and video models, diffusion models) which excels at sample generation but is expensive and not always representation-optimal, and the contrastive-learning line (SimCLR, MoCo, DINO, DINOv2 12 ) which produces strong representations but needs augmentation engineering. JEPA shares MAE’s masked-prediction backbone but moves the prediction target from pixels to features.
Figure 3 of I-JEPA (arXiv:2301.08243), reproduced for editorial coverage.
5. Method overview
JEPA in its general form has three components and one training rule. The two empirical papers instantiate these components specifically.
Component 1: the context encoder .
- Plain English: a vision transformer that takes the visible portion of the input and produces a sequence of patch embeddings.
- Exact mechanism: I-JEPA uses ViT-B/16, ViT-L/16, ViT-H/14, and ViT-H/16 backbones 3 ; V-JEPA uses ViT-L/16 and ViT-H/16 with a spatio-temporal patch size of (two adjacent frames per patch) 5 .
- Design rationale: ViT scales well and supports masked prediction naturally because the patch tokenisation gives the model a discrete grid of “things to mask.”
- What breaks if removed: the context encoder is the downstream representation — without it the architecture is empty.
- Classification:
[Adopted]from standard ViT literature (Dosovitskiy et al., 2020).
Component 2: the target encoder .
- Plain English: a slowly-updated copy of the context encoder whose job is to produce stable prediction targets.
- Exact mechanism: after each gradient step, with ramping from 0.996 to 1.0 over training (I-JEPA) or 0.998 to 1.0 over training (V-JEPA). The target encoder receives the full input, not the masked version, so its embeddings serve as targets for the predictor 3 5 .
- Design rationale: using the context encoder itself as the target source would invite trivial collapse (predict zero, get zero target, loss is zero). EMA gives a target that is similar enough to the current encoder to be reachable but lagged enough not to collapse with it.
- What breaks if removed: replacing EMA with a frozen random encoder destroys performance; using identity (no EMA at all) collapses (per I-JEPA’s design discussion and standard knowledge from BYOL-style self-supervised learning) 3 .
- Classification:
[Adopted]— the EMA target-encoder trick comes from BYOL (Grill et al., 2020) and was used in data2vec 14 before I-JEPA.
Component 3: the predictor .
- Plain English: a small transformer that takes the context embeddings and learnable mask tokens (one per target patch, parameterised by the target’s position) and outputs a predicted embedding for each target patch.
- Exact mechanism: I-JEPA uses a narrow ViT with embedding dim 384 and depth that varies by backbone — 6 layers for ViT-B/16, 12 layers for ViT-L/16 and ViT-H variants, 16 layers for ViT-G/16 3 . V-JEPA uses a 12-block predictor with embedding dim 384 5 .
- Design rationale: the predictor is intentionally narrow so that it cannot memorise — its job is to express the inferential rule “given this context embedding plus this target position, the target embedding should be X” rather than to do additional representation learning.
- What breaks if removed: without a predictor, the loss reduces to enforcing , which is the standard view-invariance objective and reintroduces the augmentation-engineering problem.
- Classification:
[New]in the I-JEPA specific instantiation (position-conditioned predictor over patch embeddings); the general idea of a separate predictor is[Adopted]from BYOL and data2vec.
The masking strategy (I-JEPA specifically). From the paper: M=4 target blocks are sampled per image, each with scale in (0.15, 0.2) of image area and aspect ratio in (0.75, 1.5). A single context block is sampled with scale in (0.85, 1.0) and unit aspect ratio. Any overlapping regions between context and any target are removed from the context before encoding, so the context never directly contains the targets 3 . The ablation in Table 7 of the paper shows multi-block (54.2% on the standard probe) substantially outperforms random masking (17.6%) and traditional block masking; the gap is large enough that the masking strategy is best understood as the I-JEPA contribution.
The masking strategy (V-JEPA specifically). From the paper: a 3D tube masking strategy that combines short-range masks (8 random blocks covering ~15% per frame) with long-range masks (2 random blocks covering ~70% per frame), each block extending across all 16 frames of the input clip (so masks are tubes, not per-frame patches). Average masking ratio is ~90% of the spatio-temporal volume 5 .
LeCun’s framework (the third paper). [Reconstructed] from the OpenReview abstract 6 and the Dawid-LeCun tutorial 7 : JEPA is presented as an energy-based model where the energy is low when is plausible given . A hierarchical JEPA (H-JEPA) stacks JEPAs at multiple temporal scales for planning. The broader cognitive architecture wraps the world model with a configurator (task selector), perception (current-state estimator), cost module (intrinsic and extrinsic objectives), short-term memory, and an actor that proposes actions. None of the cognitive-architecture modules beyond the perception/world-model JEPA itself have been empirically instantiated at scale as of the paper-publication date.
6. Mathematical contributions
MATH ENTRY [1]: The JEPA training objective.
- Source: I-JEPA Section 3 (“Method”), Eq. 1 3 ; V-JEPA Section 3, “Training objective” 5 .
- What it is: a regression loss in embedding space that asks the predictor’s output for a target patch to match the EMA target encoder’s embedding of that patch.
- Formal definition (I-JEPA, L2):
V-JEPA uses L1 in place of L2 over a single masking distribution 5 :
- Each term explained:
- is the context encoder’s output: a sequence of patch embeddings, each a vector of dimension (1280 for ViT-H/14)
- is the EMA target encoder’s output, same dimensionality
- stops gradient flow — the target side is treated as a constant during backpropagation
- is a positional embedding identifying which patch position the predictor should produce
- outputs a single -dimensional predicted embedding for patch
- is the set of patch indices belonging to target block , and for I-JEPA
- is the number of patches in target block
- Worked numerical example (small-scale). Take I-JEPA with a toy ViT-Tiny configuration: image size split into patches of size , so 64 patches total. Embedding dim . Suppose M=2 target blocks containing and patches respectively. For target block 1, the predictor outputs four 16-dim vectors; the target encoder produces four 16-dim ground-truth vectors. Suppose for patch the predictor outputs and the target encoder outputs ; the per-patch squared L2 distance is . Sum over the four patches of block 1, divide by 4, get the block-1 loss. Average block 1 and block 2 losses to get the per-image loss.
- Role: this loss is the entire training signal. There is no auxiliary contrastive loss, no reconstruction loss in pixel space, no negative-sample loss.
- Edge case: if identically (no EMA lag) and the predictor learns identity, the loss is zero with zero useful representation. The EMA mechanism plus the position-conditional predictor break this trivial solution by forcing the prediction to come from context patches, not target patches.
- Novelty:
[Adapted]. The general feature-prediction-with-EMA objective is[Adopted]from data2vec 14 ; the multi-block, position-conditional predictor formulation is[New]to I-JEPA 3 . - Transferability: [Analysis] The objective transfers cleanly to any input modality with a natural patch tokenisation (images, video, audio spectrograms, possibly point clouds), provided you can design a masking strategy that respects the modality’s structure.
- Why it matters: this single equation is the JEPA recipe. The rest of the engineering — masking, EMA schedule, predictor depth — exists to make this loss yield non-collapsed representations.
MATH ENTRY [2]: The EMA update rule.
- Source: I-JEPA Section 4 (“Hyperparameters”) 3 ; V-JEPA Section 4 5 .
- What it is: how the target encoder’s weights are maintained as a lagged version of the context encoder’s weights.
- Formal definition:
where are the context encoder’s weights at step and is the EMA momentum, scheduled to ramp linearly from to 1.0 over training.
- Each term and dimensional analysis:
- where is the total parameter count (e.g., 632M for ViT-H/14)
- , the EMA copy, same shape
- , scalar
- The update is element-wise across all parameters of the encoder; predictor parameters are not EMA-tracked
- Worked numerical example. Take a single scalar weight; suppose at step , and with . The update is — the target moves toward the current weights by 0.4% per step. Over 1,000 steps with a roughly stationary , the target catches up exponentially with a time constant of about 250 steps. At the time constant becomes ~1,000 steps.
- Role: provides a slowly-changing target signal. The schedule ramps toward 1.0 to slow the target further as training progresses, freezing the targets near the end of training.
- Edge case: exactly would freeze the target at initialisation, destroying learning. exactly would make target = current encoder, allowing trivial collapse. The schedule keeps in a useful range.
- Novelty:
[Adopted]. Standard since BYOL (Grill et al., 2020). - Transferability: [Analysis] Universal across self-supervised methods that use a stop-gradient target. The specific schedule ( start value and ramp rate) is usually tuned per architecture and dataset.
- Why it matters: the EMA target is the structural mechanism that prevents the JEPA loss from collapsing to zero with zero useful representation.
MATH ENTRY [3]: The energy-based view (LeCun’s framework framing).
- Source: LeCun’s 2022 position paper Section on JEPA 6 ; Dawid-LeCun 2023 tutorial 7 .
[Reconstructed]since the position paper PDF could not be fully fetched. - What it is: re-framing the JEPA loss as defining an energy function that is low when is compatible with .
- Formal definition:
- Each term: is a scalar energy; and are the context and target embeddings; is a distance function (L2 or L1 in the empirical papers).
- Worked example. Suppose and the predictor’s output , while . The L2 energy is . A different target would yield a much larger energy, e.g., near 4.0, reflecting that is implausible given .
- Role: positions JEPA within the energy-based model framework, which provides theoretical vocabulary for collapse, contrastive vs non-contrastive methods, and latent variables.
- Edge case: an energy function that assigns the same energy to all pairs is collapsed (uninformative). Avoiding this is the central training challenge.
- Novelty:
[Adapted]from classical energy-based models (Hinton’s contrastive divergence line) to the joint-embedding regime. - Transferability: [Analysis] The energy framing is a unifying theoretical lens. It does not by itself prescribe a training algorithm — the contrastive, distillation, regularised, and architectural-constraint training modes all instantiate it differently.
- Why it matters: provides the theoretical motivation for why one might believe feature prediction will work — it is the special case of energy-based learning where the energy factorises through a predictor.
Theoretical observation (V-JEPA, optimal predictor). From the paper: under the L1 training objective, the Bayes-optimal predictor satisfies , and the gradient on the encoder reduces to where MAD denotes median absolute deviation 5 . This is presented as motivation for L1 over L2 in the video setting where target distributions may be heavy-tailed (motion noise).
Step-by-step sketch of the optimal-predictor argument. Step 1: fix and consider the inner optimisation over . Step 2: for a fixed input embedding , the predictor outputs a single vector . Step 3: the L1 loss averaged over the conditional distribution of given is . Step 4: minimising this expectation over a scalar dimension is the classical result that the minimiser is the median (since the L1 expectation is minimised by the median in 1D). Step 5: applied dimension-wise, the optimal predictor is the per-coordinate median of the target embedding’s conditional distribution. Step 6: substituting this optimal predictor back into the loss yields an expression involving the median absolute deviation, which is what the encoder gradient reduces to. The argument is standard and the paper notes it without working through every step; the publication’s reconstruction here fills in the algebra.
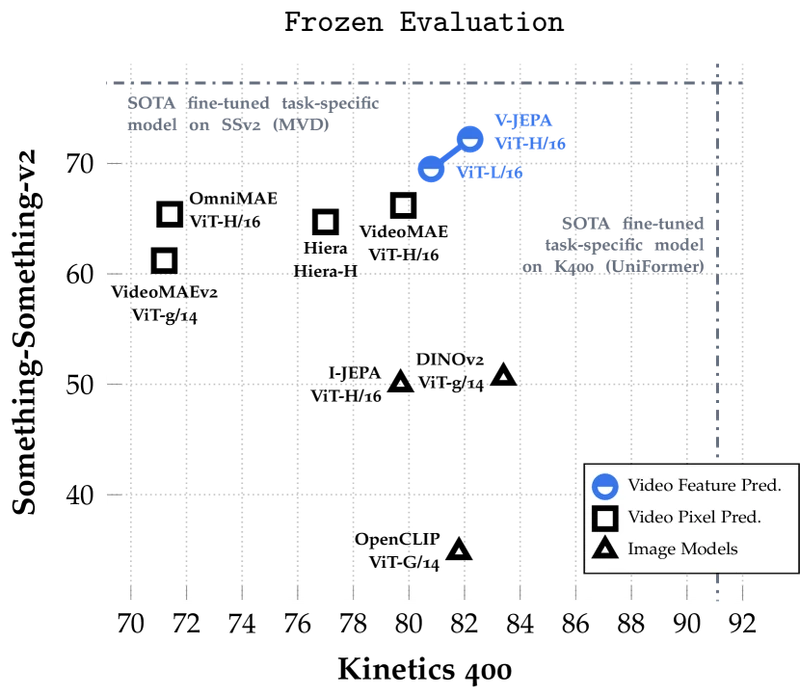
Figure 1 of V-JEPA (arXiv:2404.08471), reproduced for editorial coverage.
7. Algorithmic contributions
ALGORITHM ENTRY [1]: The I-JEPA training loop.
- Source: I-JEPA Section 3, Algorithm description + Section 4 hyperparameter table 3 .
- Purpose: one step of JEPA training on a single image (extended to a minibatch by averaging).
- Inputs:
- : an input image
- : current context-encoder and predictor weights
- : current EMA target-encoder weights
- : current EMA momentum
- Outputs: updated .
- Pseudocode:
# Input: image I, weights theta (context), phi (predictor),
# bar_theta (target), EMA momentum tau, M=4
# 1. Sample one context block and M target blocks
context_block, target_blocks = sample_multi_block_masks(
I,
context_scale=(0.85, 1.0),
target_scale=(0.15, 0.2),
target_aspect=(0.75, 1.5),
M=4
)
# 2. Remove from context any patches that overlap any target
context_patches = exclude_overlap(context_block, target_blocks)
# 3. Encode context and full image (targets via the EMA encoder)
s_x = encoder(context_patches; theta)
s_y_full = encoder(I; bar_theta)
s_y = stop_gradient([s_y_full[j] for j in target_blocks])
# 4. Predictor produces target-position embeddings
positional_queries = [position_embed(j) for j in target_blocks]
s_y_pred = predictor(s_x, positional_queries; phi)
# 5. Loss = mean over target blocks of patch-wise L2
loss = mean(
mean(l2_squared(s_y_pred[i], s_y[i]) for patches in block i)
for i in 1..M
)
# 6. Backpropagate to theta and phi only
theta, phi = optimizer_step(loss, [theta, phi])
# 7. EMA update of target encoder
bar_theta = tau * bar_theta + (1 - tau) * theta- Hand-traced example on minimal input. Suppose is a image, patch size , giving an patch grid. Step 1 samples context block covering patches (roughly 75% of area) and target blocks and similar. Step 2 removes any patches in or from the context (none here since target rows are outside context). Step 3: encoder runs over the context patches yielding of shape ; target encoder runs over all 64 patches yielding of shape ; we keep only the 4-patch slice for each target block. Step 4: predictor takes plus a learnable positional query for each target patch and outputs predictions of shape per block. Step 5: per-element squared difference between prediction and target, averaged. Step 6: backprop. Step 7: EMA update mixes 99.6% of the old target weights with 0.4% of the just-updated context weights.
- Complexity. Per step: for context encoding plus for the target encoder forward pass (no backward), plus for the predictor, where is total patches, is context patches, is patches per target block. The target encoder forward dominates because it runs on the full image; the context encoder backward is cheaper than a comparable MAE step because the predictor is narrow.
- Hyperparameters. Optimiser AdamW; learning rate linearly warmed up from to over 15 epochs then cosine-decayed to ; weight decay linearly increased from 0.04 to 0.4; batch size 2048; pretraining 300 epochs for ViT-H/14 and 600 for ViT-L/16; input resolution 224x224 (standard) or 448x448 (larger variants) 3 .
- Failure modes. Insufficient context scale (the paper’s ablation shows reducing context from (0.85, 1.0) to (0.40, 1.0) degrades performance substantially); target blocks too small (scale 0.075-0.1 yields only 19.2% on the standard probe); using a single global target block instead of M=4 distributed blocks underperforms 3 .
- Novelty:
[Adapted]. The training-loop scaffold (mask, encode, predict, EMA) is[Adopted]from data2vec; the multi-block masking + position-conditional predictor combination is[New]to I-JEPA. - Transferability. [Analysis] The structure ports directly to any masked-prediction setup with a ViT backbone. Hyperparameters (especially target block scale) almost certainly need re-tuning per modality.
ALGORITHM ENTRY [2]: The V-JEPA training loop.
- Source: V-JEPA Section 3, Algorithm description + hyperparameter table 5 .
- Purpose: one step of feature-prediction training on a single short video clip.
- Inputs: a 16-frame clip at resolution and temporal stride 4 (so the clip spans roughly 3 seconds of real time), .
- Outputs: updated .
- Pseudocode:
# Input: video clip V (16 frames x 224 x 224),
# weights theta, phi, bar_theta, EMA momentum tau
# 1. Spatio-temporal patchification: 16x16 spatial x 2 temporal
# Yields 16/2 * 14 * 14 = 1568 patches per clip
# 2. Sample 3D tube masks
short_range_masks = sample_blocks(
n_blocks=8, area_per_block=0.15,
aspect_ratio=(0.75, 1.5), temporal_extent="full"
)
long_range_masks = sample_blocks(
n_blocks=2, area_per_block=0.70,
aspect_ratio=(0.75, 1.5), temporal_extent="full"
)
target_patches = union(short_range_masks, long_range_masks)
context_patches = all_patches - target_patches
# Average masking ratio ~ 90 percent
# 3. Encode visible patches (context) and full video (targets)
s_x = encoder(context_patches; theta)
s_y_full = encoder(V; bar_theta)
s_y = stop_gradient(s_y_full[target_patches])
# 4. Predict masked patches conditioned on position
delta_y = [position_embed(j) for j in target_patches]
s_y_pred = predictor(s_x, delta_y; phi)
# 5. L1 loss in feature space
loss = mean_l1(s_y_pred, s_y)
# 6. Backprop and EMA update
theta, phi = optimizer_step(loss, [theta, phi])
bar_theta = tau * bar_theta + (1 - tau) * theta- Hand-traced example. Take a single 16-frame clip; after patchification with patch there are patches. With ~90% masking, roughly 1411 patches go to the target side and 157 remain as context. The context encoder runs on 157 tokens (a much shorter sequence than the full 1568), so the forward pass is cheap. The target encoder runs on the full 1568 tokens (this is the expensive forward, but no backward). The predictor’s input is 157 context tokens plus 1411 positional query tokens; its output is 1411 predicted embeddings of dim 1280. L1 distance averaged over the 1411 predictions yields the loss.
- Complexity. The context encoder’s forward pass on ~10% of tokens is roughly the cost of a full attention pass (attention scales quadratically). The target encoder’s forward pass on the full sequence is the bottleneck; the paper notes ~2x faster training overall than VideoMAE at matched accuracy 5 .
- Hyperparameters. Batch size 3072 (ViT-L/H@224) or 2400 (ViT-H@384); 90,000 iterations; learning rate with cosine decay to ; warmup over 12,000 iterations from ; AdamW; weight decay 0.04 to 0.4 linear schedule; EMA momentum 0.998 to 1.0 linear 5 .
- Failure modes. From the paper’s ablation: using only random tube masking (no short-range / long-range mix) costs 4.9 points on Kinetics-400 attentive probe; using pixel-space prediction instead of feature-space costs 5.1 points on K400 5 .
- Novelty:
[Adapted]. The training-loop scaffold is the same as I-JEPA; the 3D tube masking with short-range / long-range mix is[New]to V-JEPA. - Transferability. [Analysis] Generalises to any spatio-temporal modality (multi-view image, time-series with spatial structure). The masking-mix design is the part most likely to need re-tuning for non-video modalities.
8. Specialised design contributions
Subsection 8A — LLM / prompt design. Not applicable to this paper.
Subsection 8B — Architecture-specific details. From the papers:
- I-JEPA backbones: ViT-B/16, ViT-L/16, ViT-H/14, ViT-H/16, and ViT-G/16; predictor embedding dim fixed at 384 across backbones to keep it narrow; predictor depth 6 (ViT-B/16), 12 (ViT-L and ViT-H), 16 (ViT-G) 3 .
- V-JEPA backbones: ViT-L/16 and ViT-H/16, with spatio-temporal patches and a 12-block predictor 5 .
- Both papers use standard ViT design otherwise — pre-norm transformer blocks, learnable positional embeddings, GELU activations, sinusoidal positional encoding additions to the predictor for the target position .
Subsection 8C — Training specifics.
- I-JEPA hardware: ViT-H/14 trained on 16 A100 GPUs in under 72 hours for 300 epochs of ImageNet-1K 3 .
- V-JEPA hardware: the paper reports total training compute but does not give a precise GPU-hour breakdown; the paper notes ~2x faster than VideoMAE at matched accuracy 5 .
- Mixed precision (bfloat16) is used in both setups per the official repositories 8 9 .
- No curriculum learning; no data augmentation beyond random horizontal flip and standard ViT patch tokenisation. No colour jitter, no random resized crop, no Gaussian blur — the absence of these is itself a contribution since contrastive baselines depend on them.
Subsection 8D — Inference / deployment specifics.
- Inference uses the context encoder alone. The predictor and target encoder are discarded after training (the EMA target encoder can be kept as an alternative frozen backbone but the empirical papers report the context encoder’s representation).
- Frozen-backbone evaluation: I-JEPA uses standard linear probe on global average pooled patch tokens. V-JEPA uses an attentive probe, a small transformer head over patch tokens with learnable query tokens — the paper reports this gives +17.3 points on K400 over plain average pooling 5 , suggesting V-JEPA’s features are distributed rather than concentrated in any single token.
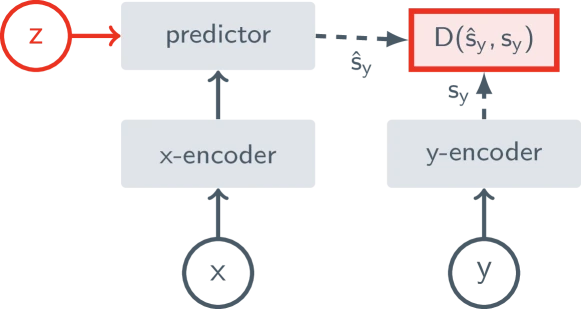
Figure 2 of V-JEPA (arXiv:2404.08471), reproduced for editorial coverage.
9. Experiments and results
Datasets (I-JEPA). ImageNet-1K (1.28M images) for the main results; ImageNet-22K (14M images) for the ViT-G/16 results. Downstream transfer to CIFAR-100, Places205, iNaturalist 2018, and Clevr/Count and Clevr/Dist for low-level vision evaluation 3 .
Datasets (V-JEPA). VideoMix2M (curated combination of Kinetics-400/600/700 + Something-Something-v2 + HowTo100M, ~2M clips). Frozen evaluation on K400, K600, K700, SSv2, AVA action detection, plus image-domain evaluation on ImageNet-1K, Places205, and iNaturalist 2021 5 .
Baselines (I-JEPA). MAE (pixel reconstruction) 10 , data2vec (feature prediction with single masking) 14 , iBOT (view-invariance + token-level objective), DINO (view-invariance) 3 .
Baselines (V-JEPA). VideoMAE 13 , VideoMAEv2, OmniMAE, Hiera, DINOv2 12 , plus pixel-prediction ablations of V-JEPA itself 5 .
Main quantitative results — I-JEPA (ImageNet linear probe, top-1).
| Method | Backbone | Epochs | ImageNet-1K linear |
|---|---|---|---|
| MAE | ViT-H/14 | 1600 | 76.6% |
| data2vec | ViT-L/16 | 1600 | 77.3% |
| I-JEPA | ViT-H/14 | 300 | 79.3% |
| I-JEPA | ViT-H/16 (448 res) | 300 | 81.1% |
Source: I-JEPA Tables 1 and 2 3 , reproduced for editorial coverage. Note the epoch column — MAE and data2vec are trained ~5x longer.
Low-shot ImageNet (1% labels).
| Method | Backbone | Top-1 (1% labels) |
|---|---|---|
| MAE | ViT-H/14 | 50.0% |
| iBOT | ViT-L/16 | 71.6% |
| I-JEPA | ViT-H/14 | 73.3% |
| I-JEPA | ViT-H/16 (448 res) | 77.3% |
Source: I-JEPA Table 3 3 , reproduced for editorial coverage.
Main quantitative results — V-JEPA (frozen evaluation, attentive probe).
| Method | Backbone | K400 | SSv2 | ImageNet-1K |
|---|---|---|---|---|
| VideoMAE | ViT-L/16 | 77.8% | 65.5% | — |
| OmniMAE | ViT-L/16 | 74.2% | 61.3% | 71.4% |
| Hiera | Hiera-H | 77.0% | 64.4% | — |
| DINOv2 (image only) | ViT-g/14 | 78.4% | 50.0% | 86.2% |
| V-JEPA | ViT-L/16 | 80.8% | 69.5% | 74.8% |
| V-JEPA | ViT-H/16 (384 res) | 82.0% | 72.2% | 77.9% |
Source: V-JEPA Tables 4 and 5 5 , reproduced for editorial coverage. V-JEPA leads on motion-heavy SSv2 by 22.2 points over DINOv2 while trailing on still-image ImageNet (image-pretrained DINOv2 is stronger there).
Ablations.
- I-JEPA: pixel-space vs feature-space prediction (Table 5) — feature space wins by ~26 points on the standard 1% probe metric 3 .
- I-JEPA: multi-block (54.2%) vs random masking (17.6%) vs traditional block masking (36.9%) on the standard probe — multi-block is the load-bearing design choice 3 .
- V-JEPA: feature-space vs pixel-space prediction — feature space wins by 5.1 points on K400 frozen probe and 0.2 points on SSv2 5 .
- V-JEPA: attentive probe vs average pooling — attentive adds 17.3 points on K400 and 16.1 points on SSv2 5 .
Hyperparameter sensitivity. I-JEPA’s ablations document sensitivity to target-block scale (catastrophic collapse below 0.075) and context scale (substantial degradation below 0.4) 3 . V-JEPA documents sensitivity to the short-range / long-range masking mix and to EMA decay schedule 5 .
Qualitative results. I-JEPA’s Figure 7 visualises predictor outputs decoded via a separate trained decoder, showing that the predictor reconstructs plausible target content rather than memorising pixel details 3 . V-JEPA does not provide pixel reconstructions (the model never sees pixels in the loss); the paper’s qualitative analysis relies on downstream task performance.
Independent benchmark cross-checks. [Analysis + External comparison] As of the publication of the V-JEPA paper, V-JEPA’s frozen-backbone SSv2 number (72.2%) is the SOTA among self-supervised video methods reporting frozen-backbone results; pixel-based VideoMAE leads under full fine-tuning on some metrics 5 . Independent reproductions of I-JEPA exist via the facebookresearch/ijepa repository 8 ; the broader research community has reproduced the linear-probe numbers but no formal third-party reproducibility paper is published as of this article’s writing. The official V-JEPA code is available 9 but the VideoMix2M curation list, while described in the paper, is harder to reproduce exactly without the original dataset access lists.
Experimental scope limits. I-JEPA’s evaluation is largely ImageNet-centric with transfer to a handful of standard benchmarks; the paper does not evaluate on dense prediction tasks like semantic segmentation or object detection at scale. V-JEPA evaluates on standard video benchmarks but does not evaluate on open-ended video Q&A, action localisation in long videos, or temporal forecasting tasks. Neither paper evaluates the world-model claim from LeCun’s framework — that JEPA features support planning or model-based control — directly.
Evidence audit.
- Strongly supported. Feature-space prediction outperforms pixel-space prediction at matched compute on the chosen benchmarks (I-JEPA ablation Table 5; V-JEPA Table 1).
- Strongly supported. I-JEPA achieves competitive ImageNet linear-probe accuracy at substantially lower compute than MAE and data2vec.
- Strongly supported. V-JEPA features transfer to motion-heavy tasks like SSv2 better than image-pretrained baselines including DINOv2.
- Partially supported. The claim that JEPA representations are “augmentation-free” is true in the strict sense that no colour jitter or random crops are used, but the masking strategy itself is a form of structured data augmentation. [Analysis] The two papers do not make this explicit framing distinction; the publication’s reading is that masking is augmentation by another name, but is a far smaller engineering surface than the contrastive augmentation pipeline.
- Claims relying on narrow evidence. Generalisation to non-ImageNet image domains (medical imaging, satellite imagery) is not evaluated in either paper. Generalisation of V-JEPA outside the curated VideoMix2M video distribution is not evaluated.
10. Technical novelty summary
| Component | Type | Novelty level | Justification | Source |
|---|---|---|---|---|
| Multi-block masking (I-JEPA) | Masking strategy | Incrementally novel | Combines block masking ideas with a position-conditional predictor; ablation shows it is the load-bearing choice | I-JEPA Section 3 3 |
| Feature-space prediction with EMA target | Training objective | Adopted (from data2vec) | Same core objective as data2vec but with multi-block masking and a narrower predictor | I-JEPA + V-JEPA 3 5 14 |
| 3D tube masking with short/long range mix (V-JEPA) | Masking strategy | Incrementally novel | Extends I-JEPA’s spatial multi-block to video with explicit short/long range mix | V-JEPA Section 3 5 |
| L1 prediction loss in video setting | Loss function | Incrementally novel | Motivated by median-of-target-distribution argument; differs from I-JEPA’s L2 | V-JEPA Section 3 5 |
| Attentive probe for frozen-backbone eval | Evaluation method | Adopted | Reused from prior frozen-evaluation literature; not introduced here | V-JEPA Section 4 5 |
| JEPA as energy-based world model | Framework framing | Novel framing | First articulation of feature-prediction as energy-based building block for world models | LeCun 2022 6 |
| Hierarchical JEPA (H-JEPA) | Framework | Speculative | Proposed but not empirically realised in any paper as of writing | LeCun 2022 6 |
| Configurator / actor / cost cognitive architecture | Framework | Speculative | Schematic only, no empirical instantiation | LeCun 2022 6 |
Single most novel contribution. The empirical demonstration that feature-space prediction with multi-block masking yields representations competitive with or better than the dominant alternatives at substantially less compute, and that the recipe transfers to video without modification of the core objective. The I-JEPA + V-JEPA pair, taken together, is the contribution — neither paper alone establishes the recipe’s robustness; both together do 3 5 .
What the papers do not claim as novel. Vision transformer backbones (Dosovitskiy et al.), the EMA target-encoder trick (BYOL), the masked-image-modelling paradigm (BEiT, MAE), the energy-based model formalism (LeCun + Hinton lineage), the attentive probe evaluation method.
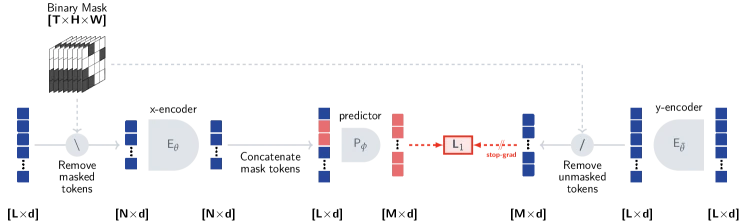
Figure 3 of V-JEPA (arXiv:2404.08471), reproduced for editorial coverage.
11. Situating the work
What prior work did. [External comparison] The self-supervised vision literature pre-2023 split into three camps: pixel reconstruction (MAE, BEiT), contrastive view-invariance (SimCLR, MoCo, DINO, iBOT), and feature prediction with EMA targets (data2vec). Each had a load-bearing weakness — pixel methods underperformed on linear probes, contrastive methods were augmentation-sensitive, and data2vec used a single-mask strategy that did not scale efficiency-wise.
What this paper changes conceptually. I-JEPA + V-JEPA reframe self-supervised vision learning around two coupled choices: (1) predict in feature space, and (2) design the masking strategy to produce semantically meaningful targets rather than rely on augmentations. The energy-based framing in LeCun’s 2022 paper positions this as the perceptual front end of a broader autonomous-agent architecture — though that broader architecture remains largely speculative 6 .
Contemporaneous related work.
- DINOv2 (Oquab et al., 2023) 12 — strongest contemporaneous self-supervised image baseline; uses iBOT-style training at much larger scale. DINOv2 beats I-JEPA on still-image linear-probe ImageNet (86.2% vs 81.1%) but trails V-JEPA on motion-heavy video benchmarks by ~22 points on SSv2, suggesting the two methods learn complementary structure. [External comparison]
- VideoMAE / VideoMAEv2 (Tong et al., 2022; Wang et al., 2023) 13 — primary contemporaneous video self-supervised baseline. Same masked-prediction backbone, pixel-space loss. V-JEPA’s ablation isolates feature-space prediction as the source of its gains over VideoMAE rather than the masking strategy alone.
- VICReg (Bardes, Ponce, LeCun, 2022) 11 — a related Meta-AI line on collapse prevention via explicit variance/covariance regularisation. JEPA does not use VICReg’s regulariser; it relies on the EMA + position-conditional predictor architecture instead. [Analysis] The relationship is that VICReg was the “regularised JEPA training mode” envisaged in LeCun’s framework, but I-JEPA and V-JEPA empirically avoid collapse without it.
[Reviewer Perspective] Strongest skeptical objection. The empirical papers report strong linear-probe and frozen-attentive-probe numbers, but the world-model framing in LeCun’s 2022 paper is far less validated. JEPA features have not been shown to support planning, model-based control, or any task that exercises the H-JEPA or configurator/actor proposals. A skeptical reviewer would argue that I-JEPA and V-JEPA are excellent representation-learning papers misleadingly packaged under a world-model banner that the empirical work does not earn.
[Reviewer Perspective] Strongest author-side rebuttal grounded in the papers. The papers do not claim to deliver a world model — they claim to demonstrate the feature-prediction objective at the heart of the JEPA framework. The framework essay is explicitly speculative; the empirical papers are scoped to representation learning and they back up the scoped claim. The criticism is directed at the framework essay’s positioning, not at the empirical work itself.
What remains unsolved.
- How to use JEPA features for planning, control, or model-based decision-making (the LeCun framework’s central promise).
- How to build hierarchical JEPAs (H-JEPA) that operate at multiple temporal scales — no empirical realisation exists at scale.
- How to make JEPA features competitive with image-pretrained DINOv2 on still-image benchmarks while retaining the video advantage (V-JEPA trails DINOv2 by ~8 points on ImageNet).
- How to scale the dataset beyond VideoMix2M; the paper notes the dataset itself is a bottleneck.
Three future research directions.
- JEPA + policy learning for robotics. [Analysis] V-JEPA’s motion-heavy SSv2 lead suggests the features encode motion-relevant abstractions that pixel-trained methods miss. A natural next step is to use V-JEPA’s frozen features as the perceptual front end of a robot policy and evaluate on real manipulation benchmarks. Grounded in V-JEPA’s empirical gap rather than the LeCun framework’s vision.
- Hierarchical JEPA realisation. [Reviewer Perspective] Empirically realise H-JEPA at multiple temporal scales — short-range JEPA at the second scale, long-range JEPA at the minute scale — and evaluate on video forecasting / future-feature prediction. This is the most-cited unrealised part of the LeCun framework.
- JEPA outside vision. [Analysis] Audio (audio-JEPA), tabular time-series, point clouds. The objective requires only a tokenisation and a masking strategy; the empirical question is whether feature-prediction beats pixel/sample-prediction on those modalities the way it does on images and video.
12. Critical analysis
Strengths with concrete evidence.
- Empirical efficiency: I-JEPA’s ViT-H/14 reaches 79.3% ImageNet linear probe in 300 epochs vs. MAE’s 76.6% in 1600 epochs 3 . The 5x epoch reduction is the largest single-paper compute-efficiency gain in 2023-vintage self-supervised vision.
- Architectural simplicity: no contrastive negatives, no view-augmentation pipeline, no pixel decoder — the JEPA training loop is shorter than either contrastive or generative baselines.
- Cross-modality generalisation: V-JEPA inherits I-JEPA’s recipe with minor modification (3D masking, L1 loss) and works without major hyperparameter re-tuning 5 .
- The ablations are decisive — pixel vs feature prediction, multi-block vs random masking, context-scale sensitivity — they isolate the load-bearing design choices clearly.
Weaknesses explicitly stated by the authors.
- I-JEPA: the method’s representations may underperform on certain dense prediction tasks where pixel-level signal is needed; the paper does not benchmark semantic segmentation at scale 3 .
- V-JEPA: video pretraining datasets remain “too constrained” lacking the visual diversity of internet-scale image data, limiting ImageNet performance relative to DINOv2 (77.4% vs 86.2%) 5 .
Weaknesses not stated or understated by the authors.
- [Reviewer Perspective] The “augmentation-free” framing is somewhat overstated. Multi-block masking with carefully-tuned scale ranges is a structured augmentation; the ablation showing catastrophic failure at scales (0.075, 0.1) demonstrates the engineering surface is non-trivial.
- [Reviewer Perspective] The world-model framing imports promises from the LeCun 2022 essay that the empirical papers do not address. A reader of the V-JEPA paper might expect demonstrations of planning, action prediction, or model-based control; the paper delivers representation-learning benchmarks. The gap between framing and delivery is real.
- [Reviewer Perspective] No analytical theory of collapse prevention is offered. The architectural choices that prevent collapse (EMA, narrow position-conditional predictor) are empirically motivated; an adversarial reviewer could argue that subtle implementation choices may matter more than the paper’s main equations suggest, and the lack of a closed-form collapse argument is a real weakness.
Reproducibility check.
- Code: Released for both I-JEPA 8 and V-JEPA 9 as official Meta-AI repositories.
- Data: I-JEPA uses public ImageNet-1K and ImageNet-22K. V-JEPA’s VideoMix2M is described in the paper but the exact clip list / curation requires reconstructing from the listed source datasets.
- Hyperparameters: Both papers publish full hyperparameter tables; the repositories carry training configs.
- Compute: I-JEPA reports 16 A100s for 72 hours for ViT-H/14 3 . V-JEPA reports relative speedup (~2x faster than VideoMAE) but does not provide a precise compute table at the level I-JEPA does.
- Trained model weights: I-JEPA weights released under Meta’s permissive research license 8 ; V-JEPA weights released similarly 9 .
- Evaluation sets: Standard public benchmarks (ImageNet, Kinetics, SSv2, AVA).
- Overall: Both papers are largely reproducible — strong for representation-learning standards. The V-JEPA dataset curation is the weakest link.
Methodology disclosure.
- Sample size — I-JEPA: 1.28M images (ImageNet-1K) or 14M (ImageNet-22K). V-JEPA: ~2M video clips.
- Evaluation set — I-JEPA: ImageNet-1K val (50k images) plus held-out transfer benchmarks; standard splits; no contamination check reported. V-JEPA: K400/K600/K700/SSv2/AVA validation splits; no contamination check between VideoMix2M training and downstream eval reported (Kinetics is in both training and evaluation, which the paper notes as expected for the frozen-evaluation setting).
- Baselines — I-JEPA: MAE, data2vec, iBOT, DINO. V-JEPA: VideoMAE, VideoMAEv2, OmniMAE, Hiera, DINOv2.
- Hardware / compute — I-JEPA: 16 A100 GPUs for 72 hours for ViT-H/14 3 . V-JEPA: not precisely disclosed; the paper notes “~2x faster than VideoMAE” but does not give a wall-clock GPU-hour figure 5 .
Generalisability. [Analysis] The JEPA recipe is general (any masked-prediction setup, any tokenised input modality). The specific masking strategies and hyperparameters likely need re-tuning per modality. The world-model claim is not empirically generalisable from these papers.
Assumption audit. The strong assumption that EMA + narrow predictor + multi-block masking is sufficient to prevent collapse holds empirically across two large-scale studies. If a different modality or dataset breaks the assumption, the JEPA recipe likely needs an explicit regulariser (VICReg-style) added.
What would make the papers significantly stronger. [Analysis] An empirical demonstration of JEPA features supporting planning, model-based control, or any task that exercises the H-JEPA proposal would close the framing-to-delivery gap. A formal collapse-prevention argument (even partial) would strengthen the theoretical underpinning. Semantic segmentation and detection benchmarks would close the dense-prediction evaluation gap I-JEPA notes.
13. What is reusable for a new study
REUSABLE COMPONENT [1]: Feature-prediction loss with EMA target encoder.
- What it is: the core JEPA training objective (MATH ENTRY 1) plus the EMA update rule (MATH ENTRY 2).
- Why worth reusing: empirically demonstrated to converge faster than pixel prediction at matched final accuracy on two distinct modalities.
- Preconditions: a tokenisation that admits patch-level masking; a backbone capable of attending over partial inputs (ViT or similar).
- What would need to change in a different setting: the masking strategy almost certainly; the loss norm (L1 vs L2) may need adjustment based on target distribution heaviness; the EMA schedule may need re-tuning.
- Risks: representation collapse if the predictor is too expressive or the masking is too lenient.
REUSABLE COMPONENT [2]: Multi-block masking (I-JEPA) or short/long-range tube masking (V-JEPA).
- What it is: the structured masking distributions that produce semantically meaningful target regions.
- Why worth reusing: ablations isolate the masking strategy as the load-bearing design choice in both papers.
- Preconditions: the input modality must admit a spatial (or spatio-temporal) block structure.
- What would need to change: block scale ranges and aspect ratios need re-tuning per modality.
- Risks: insufficient context scale or undersized targets cause catastrophic collapse (I-JEPA ablations).
REUSABLE COMPONENT [3]: Narrow position-conditional predictor.
- What it is: a small ViT predictor (depth 6-16, width 384) that conditions on context embeddings plus target position queries.
- Why worth reusing: keeps the predictor expressive enough to encode the inferential rule but narrow enough to prevent memorisation.
- Preconditions: target positions must be representable as embeddings (true for any patch-based tokenisation).
- What would need to change: predictor depth scales sublinearly with backbone size; width is held fixed in both papers.
- Risks: too wide a predictor risks the predictor doing the encoding work and the backbone collapsing.
REUSABLE COMPONENT [4]: Attentive probe for frozen-backbone evaluation (V-JEPA).
- What it is: a small transformer head with learnable query tokens, attached to a frozen backbone for downstream evaluation.
- Why worth reusing: V-JEPA’s ablation shows +17.3 points on K400 over plain global average pooling — implies frozen backbones with distributed information benefit substantially from attentive aggregation.
- Preconditions: a frozen backbone producing patch-token outputs.
- What would need to change: number of query tokens and head dimensions are evaluation-specific.
- Risks: minor — the attentive probe is small relative to the backbone.
Dependency map. Components 1 and 2 are tightly coupled: the multi-block masking only makes sense in the context of a feature-prediction loss with stop-gradient targets, and the EMA target encoder is the mechanism that makes that loss non-trivial. Component 3 (narrow predictor) interacts with Components 1 and 2 — a wider predictor would invite collapse even with the same masking and loss. Component 4 (attentive probe) is independent and reusable in any frozen-backbone evaluation.
Recommendation. [Analysis] For a new study, the highest-value components are (1) the feature-prediction loss with EMA targets and (2) the masking strategy template. These two together encode the JEPA recipe; the rest is implementation detail.
What type of new study benefits most. [Analysis] Studies that need a frozen perceptual backbone for downstream multi-task evaluation, especially in video or motion-heavy settings where pixel prediction is wasteful. Robotics policy learning, video understanding research, and audio-spectrogram representation learning are natural fits.
14. Known limitations and open problems
Limitations explicitly stated by the authors.
- I-JEPA: dense-prediction tasks (semantic segmentation, fine-grained detection) not benchmarked at scale 3 .
- V-JEPA: video pretraining dataset diversity is limited; ImageNet trails DINOv2 substantially 5 .
- V-JEPA: precise compute budget not disclosed at the level I-JEPA discloses.
Limitations not stated (publication-side, source-grounded).
- [Reviewer Perspective] No closed-form or even partial-form collapse-prevention argument; the empirical evidence is strong but the theory is gestural. This matters if practitioners want to extend the recipe to new modalities without exhaustive empirical re-validation.
- [Reviewer Perspective] The “world-model” framing from LeCun 2022 is not empirically backed by either paper. A returning reader of the V-JEPA paper expecting planning or model-based control demonstrations does not get them. The publication’s reading is that the framework essay’s positioning is more aspirational than the empirical work supports — the empirical papers should be read as excellent self-supervised representation-learning work, not as world-model deliveries.
- [Reviewer Perspective] No evaluation on non-natural-image domains (medical imaging, satellite, biology). Whether the JEPA recipe transfers to domains where multi-block masking semantics differ is open.
Technical root cause of each limitation.
- Dense prediction gap: the multi-block masking produces semantically-sized targets but does not specifically train for pixel-localised representation needed for segmentation boundaries.
- ImageNet gap (V-JEPA): video pretraining data, even at 2M clips, contains far less appearance diversity than image-pretrained DINOv2’s curated 142M images.
- Collapse-prevention theory gap: the JEPA loss with stop-gradient has multiple degenerate solutions analytically; the EMA + narrow predictor + masking choices empirically select a non-degenerate one without a proof.
Open problems left behind.
- Closed-form characterisation of when the JEPA loss + EMA + masking combination yields non-collapsed representations.
- H-JEPA (hierarchical JEPA) empirical realisation at scale, with planning and forecasting evaluations.
- JEPA generalisation to non-vision modalities at I-JEPA-comparable scale.
- World-model evaluation: integration of JEPA backbones into model-based RL or robotic planning.
What a follow-up paper would need to solve to address the most critical limitation. [Analysis] The most critical limitation, given the breadth of the LeCun framework’s promises, is the world-model evaluation gap. A follow-up paper would need to (1) integrate a V-JEPA backbone into a planning loop on a standard benchmark (e.g., DeepMind Control Suite or RoboHive), (2) compare against pixel-based world models (DreamerV3, TD-MPC2), and (3) demonstrate that V-JEPA features yield better planning performance specifically because of the feature-prediction objective rather than incidental architectural choices. Such a paper would close the framing-to-delivery gap that the current JEPA empirical work leaves open.
How this article reads at three depths
For the curious high-school reader. JEPA is a way to train computers to “see” by playing a fill-in-the-blank game with images and video — but the blank is filled in meaning rather than pixels. Two real Meta papers (I-JEPA for images, V-JEPA for video) show this works better and faster than older approaches. The bigger idea is that the AI researcher Yann LeCun thinks predicting meanings instead of pixels is the path to AI systems that understand the world like humans and animals do.
For the working developer or ML engineer. JEPA replaces pixel-reconstruction (MAE) or contrastive-augmentation (DINO) self-supervised vision training with feature-space prediction using an EMA target encoder, a narrow position-conditional predictor, and structured multi-block masking. I-JEPA hits 79.3% ImageNet linear probe in 300 epochs on 16 A100s vs MAE’s 76.6% at 1600 epochs — a 5x compute reduction with better accuracy. V-JEPA extends to video with 3D tube masking and L1 loss, beating VideoMAE on frozen-backbone K400 (82.0% vs 77.8%) and SSv2 (72.2% vs 65.5%). The recipe is open-source (facebookresearch/ijepa and facebookresearch/jepa), the hyperparameters are documented, and the masking strategy is the load-bearing design choice — re-tune it for your modality before assuming the rest transfers.
For the ML researcher. The novel contribution is the empirical demonstration that feature-space prediction with multi-block masking is robust enough to deliver SOTA self-supervised results on two distinct modalities without explicit collapse-prevention regularisation. The narrow position-conditional predictor and the EMA target encoder do the collapse-prevention work that VICReg or contrastive negatives do elsewhere. Open theoretical questions: closed-form characterisation of when the architectural choices yield non-degenerate solutions; whether H-JEPA admits empirical realisation; whether JEPA features support planning or model-based control. The LeCun 2022 framework essay’s world-model framing is not earned by the empirical I-JEPA / V-JEPA work; treat the empirical papers as excellent representation-learning contributions and read the framework essay separately as speculative scaffolding. The strongest follow-up direction is integrating a V-JEPA backbone into a model-based RL or robot policy loop and benchmarking against pixel-based world models.
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. I-JEPA arXiv abstract page (Assran, Duval, Misra, Bojanowski, Vincent, Rabbat, LeCun, Ballas, 2023) (accessed ) ↩
- 2. I-JEPA PDF on arXiv (accessed ) ↩
- 3. I-JEPA HTML render on ar5iv — primary source for method, ablations, and hyperparameter tables (accessed ) ↩
- 4. V-JEPA arXiv abstract page (Bardes, Garrido, Ponce, Chen, Rabbat, LeCun, Assran, Ballas, 2024) (accessed ) ↩
- 5. V-JEPA HTML render on ar5iv — primary source for method, results, and ablations (accessed ) ↩
- 6. LeCun (2022). A Path Towards Autonomous Machine Intelligence v0.9.2 OpenReview entry (accessed ) ↩
- 7. Dawid, LeCun (2023). Introduction to Latent Variable Energy-Based Models: A Path Towards Autonomous Machine Intelligence (accessed ) ↩
- 8. I-JEPA official implementation (facebookresearch/ijepa) (accessed ) ↩
- 9. V-JEPA official implementation (facebookresearch/jepa) (accessed ) ↩
- 10. He, Chen, Xie, Li, Dollar, Girshick (2022). Masked Autoencoders Are Scalable Vision Learners (MAE) (accessed ) ↩
- 11. Bardes, Ponce, LeCun (2022). VICReg: Variance-Invariance-Covariance Regularization (accessed ) ↩
- 12. Oquab et al. (2023). DINOv2: Learning Robust Visual Features without Supervision (accessed ) ↩
- 13. Tong, Song, Wang, Wang (2022). VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training (accessed ) ↩
- 14. Baevski, Hsu, Xu, Babu, Gu, Auli (2022). data2vec: A General Framework for Self-Supervised Learning (accessed ) ↩
Anonymous · no cookies set