Diffusion Language Models: A Technical Reference (SEDD, DiffuLLaMA)
Technical reference on discrete-diffusion language models. Walks SEDD (Lou 2024) and DiffuLLaMA (Gong 2024): what they solve, where AR baselines still win.
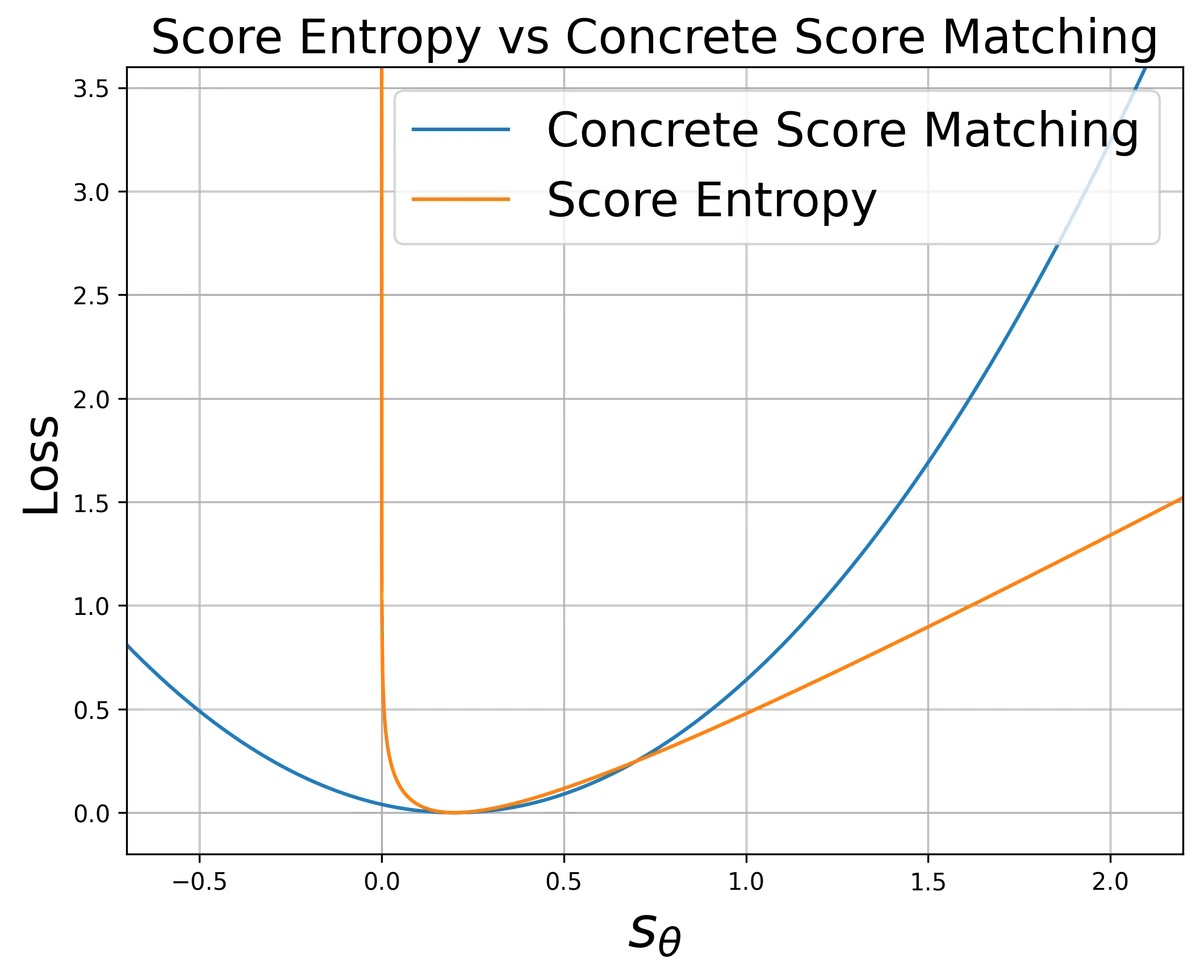
Figure 1 of Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution (arXiv:2310.16834), reproduced for editorial coverage.
1. Paper identity and scope
Primary citation. Lou, A., Meng, C., and Ermon, S. “Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution.” arXiv:2310.16834, October 2023; ICML 2024 Oral 1 .
Companion citation. Gong, S., Agarwal, S., Zhang, Y., Ye, J. et al. “Scaling Diffusion Language Models via Adaptation from Autoregressive Models.” arXiv:2410.17891, October 2024 3 .
Retrieval. This review draws on the arXiv abstract pages 1 3 , the ar5iv HTML renders of both papers 2 4 , and the SEDD reference implementation 5 .
Classification. Generative modelling, language models, non-autoregressive. Both papers attack the same problem from different angles: how to make diffusion models work for discrete language tokens at competitive perplexity to autoregressive (AR) baselines.
Technical abstract (in the publication’s voice). Diffusion models dominate continuous-domain generation (images, audio, video) but have lagged behind autoregressive models for discrete domains like natural language. The Lou-Meng-Ermon paper (SEDD) introduces a new loss function — score entropy — that extends score matching from continuous to discrete distributions in a way that respects probabilistic constraints (non-negativity, normalisation) the prior discrete-diffusion losses violated. The result is the first discrete-diffusion language model to match GPT-2-scale autoregressive perplexity on standard benchmarks, with substantial perplexity reductions (25-75%) over prior diffusion-LM methods 1 . The Gong et al. paper (DiffuLLaMA / DiffuGPT) attacks scaling: rather than train a diffusion language model from scratch, the paper proposes adapting an existing pretrained autoregressive model into a diffusion model with continued pretraining, reaching 7B parameters with under 200B tokens of additional training 3 .
Primary research questions.
- (SEDD) Can a properly-defined discrete-diffusion loss close the perplexity gap with autoregressive language models at small-to-medium scale?
- (DiffuLLaMA) Can the engineering cost of training a diffusion LM at LLaMA scale be amortised by warm-starting from an existing pretrained AR checkpoint?
Core technical claim (SEDD). Replacing the diffusion-LM loss with score entropy yields a 25-75% perplexity reduction over prior discrete-diffusion baselines at GPT-2 scale, and reaches AR-baseline parity with 16-32x fewer function evaluations than naive discrete diffusion 1 .
Core technical claim (DiffuLLaMA). Adapting GPT-2 (127M) through LLaMA-7B into diffusion models via continued pretraining produces DiffuGPT and DiffuLLaMA models competitive with their AR sources on language-modelling and commonsense-reasoning benchmarks, using under 200B tokens 3 .
Core technical domains.
| Domain | Depth required |
|---|---|
| Continuous diffusion models (DDPM, NCSN) | Moderate |
| Score matching | Deep |
| Discrete-state Markov chains | Moderate |
| Forward and reverse diffusion processes | Deep |
| Categorical / token vocabularies | Moderate |
| Autoregressive language modelling | Moderate |
| Attention masking (causal vs bidirectional) | Moderate |
Reader prerequisites. Knowing that an autoregressive language model predicts the next token given previous tokens (causal masking), that diffusion models for images iteratively denoise a noised input, and that “score” in score matching refers to the gradient of the log-density.
How this review marks its registers.
- Author-stated /
[From the paper]— what each paper itself claims. Sections 4-8 carry the densest concentrations. - Facts — background facts independent of either paper (DDPM mechanics, score-matching history). Section 4 carries the bulk.
- AI analysis /
[Analysis]— the pipeline’s analytical layer (worked numerical examples, dimensional analysis, plain-English on-ramps). - Reviewer perspective /
[Reviewer Perspective]— independent commentary that goes beyond what the papers prove.
2. TL;DR and executive overview
TL;DR. Diffusion models won the image-generation race but lagged at language because the standard score-matching loss does not transfer cleanly to discrete vocabularies. SEDD (Lou 2024) introduces a discrete-friendly loss called score entropy that matches GPT-2 perplexity, and DiffuLLaMA (Gong 2024) shows that adaptation from a pretrained AR checkpoint, rather than from scratch, makes diffusion language modelling viable at 7B scale. Both papers leave open whether diffusion LMs offer enough advantage over AR to justify the engineering rework at frontier scale.
Executive summary. Discrete diffusion for language has had three generations of methods. The first (D3PM, Austin 2021 8 ) defined discrete Markov chains as forward processes but trained with ELBO objectives that did not match AR perplexity. The second (Diffusion-LM, Li 2022 9 ) used continuous-space embeddings and a Gaussian forward process, suitable for controllable generation but not for raw perplexity competition. SEDD is the third generation: a discrete forward process with a score-entropy loss derived analogously to score matching in continuous space, which the paper shows is the right way to extend score matching to discrete domains. The result is the first published discrete-diffusion LM to match GPT-2 on perplexity, with the additional property that it generates high-quality text without requiring temperature scaling at sampling time 1 . DiffuLLaMA tackles the orthogonal scaling problem: training a diffusion LM from scratch at 7B is prohibitively expensive, but starting from a pretrained LLaMA checkpoint and continuing pretraining with a diffusion objective converges to competitive performance in under 200B tokens 3 .
Five practitioner-relevant takeaways.
- SEDD’s headline 25-75% perplexity reduction is against prior diffusion baselines, not against AR. [From the paper] SEDD matches GPT-2 but does not surpass it on standard perplexity benchmarks 1 . The narrative is “diffusion LMs are no longer dramatically behind AR,” not “diffusion has overtaken AR.”
- The function-evaluations (NFE) advantage is real but conditional. SEDD claims competitive quality at 16-32x fewer sampling steps than naive discrete diffusion. This is an inference-efficiency advantage over earlier diffusion baselines, not against AR (which needs one forward pass per generated token).
- DiffuLLaMA’s adaptation is computationally cheaper than from-scratch training but still expensive. [From the paper] Under 200B tokens to adapt a 7B AR model — substantial but a fraction of the 1-15T tokens used to pretrain frontier AR LLaMA-3 and Qwen variants 3 .
- Diffusion LMs offer infilling natively. Unlike AR, which is one-directional, diffusion LMs can fill in any masked positions in parallel. SEDD and DiffuLLaMA both demonstrate this; it is one of the few capability advantages of diffusion over AR at comparable perplexity.
- [Analysis] Production readiness remains uncertain. As of mid-2026, no major frontier-lab model in production is a diffusion LM. The 2025 follow-up work LLaDA 11 pushes diffusion LMs to 8B and shows competitive scaling but does not yet bridge the gap on instruction-following or agentic tasks where AR-trained reasoning behaviours dominate.
Pipeline overview. Both papers train neural networks to model a reverse discrete-diffusion process — given a noised token sequence, recover the original. SEDD’s contribution is the loss function; DiffuLLaMA’s is the warm-start procedure.
2.5. Glossary
| Term | Plain-English explanation | First appears in |
|---|---|---|
| Autoregressive (AR) language model | A model that generates one token at a time, conditioning each on all previously-generated tokens. GPT, LLaMA, Claude, Gemini are AR. | Section 1 |
| Diffusion model | A generative model that learns to reverse a noising process: starting from random noise, iteratively denoise to recover structured data. Dominant for images and video. | Section 1 |
| Forward process (noising) | The fixed, predefined corruption that gradually turns clean data into noise. In discrete diffusion, this is a Markov chain over the vocabulary. | Section 4 |
| Reverse process (denoising) | The learned process that undoes the forward corruption step by step. The neural network is trained to model each reverse step. | Section 4 |
| Score function | The gradient of the log-density of a distribution; central to continuous diffusion. Discrete analogues need a different definition — that is what score entropy provides. | Section 4 |
| Score matching | The training objective for score-based models in continuous space: minimise the squared error between the network’s predicted score and the true score. | Section 4 |
| Score entropy (SEDD’s contribution) | A discrete analogue of score matching whose objective respects nonnegativity and is a valid divergence in discrete state space. | Section 5 |
| Number of function evaluations (NFE) | How many forward passes through the diffusion network are needed to produce one sample. Lower is faster. AR needs one NFE per token; diffusion needs many NFEs total but generates many tokens per step. | Section 2 |
| D3PM | Austin et al. 2021’s “Discrete Denoising Diffusion Probabilistic Models” — the first major discrete-diffusion language framework, predating SEDD. | Section 4 |
| Diffusion-LM (Li 2022) | An early continuous-embedding-space diffusion LM, focused on controllable generation. | Section 4 |
| Perplexity | The standard language-model evaluation metric: of the mean negative log-likelihood per token. Lower is better. | Section 2 |
| Attention mask annealing | DiffuLLaMA’s technique: gradually transitioning the attention mask from causal (AR) to bidirectional (diffusion) during adaptation training. | Section 5b |
| Infilling | Generating tokens in arbitrary positions within a sequence, not just at the end. Native to diffusion LMs, requires special techniques (FIM training) for AR. | Section 1 |
| Categorical distribution | A probability distribution over a finite set of outcomes (the vocabulary). The natural support for discrete diffusion. | Section 4 |
| Continued pretraining | Training a model that has already been pretrained on additional data with the same or modified objective. DiffuLLaMA uses this to convert AR to diffusion. | Section 1 |
[From the paper] prefix | Default register for claims supported by the cited paper. | Throughout |
[Analysis] label | The publication’s own reasoning. | Throughout |
[Reviewer Perspective] label | Critical commentary beyond the paper’s text. | Section 9, 12 |
3. Problem formalisation
Notation table.
| Symbol | Type | Meaning | First appears in |
|---|---|---|---|
| Token sequence | Clean data (a real text sequence) | Section 4 | |
| Token sequence | Noised data at time | Section 4 | |
| Forward kernel | Noising transition | Section 4 | |
| Reverse kernel | Learned denoising transition | Section 4 | |
| Set | Vocabulary (e.g., 50,257 for GPT-2 BPE) | Section 4 | |
| Function | Score network output (continuous) or ratio network (SEDD) | Section 5 | |
| Scalar | Score-entropy loss (SEDD’s contribution) | Section 5 | |
| Scalar | Conditional score-matching loss (continuous analogue) | Section 5 |
Formal problem statement. Given a corpus of token sequences over vocabulary , learn a model that assigns high likelihood to held-out sequences and can sample new sequences of comparable quality to autoregressive models trained on the same data.
Explicit assumption list.
- Discrete state space. The data lives on a finite vocabulary . Continuous-relaxation tricks (Diffusion-LM-style) are not used; the forward process operates directly on tokens.
- Markovian forward process. The noising process factorises as a Markov chain. SEDD uses a uniform-noise corruption; DiffuLLaMA inherits SEDD-family discrete noising.
- Tractable terminal distribution. converges to a known distribution (uniform over the vocabulary) that can be sampled from at inference.
- Network capacity. The denoising network has enough capacity to represent the reverse kernel. SEDD evaluates with GPT-2-architecture networks; DiffuLLaMA with LLaMA-architecture.
Why the problem is hard. Score matching in continuous space relies on the gradient , which is well-defined for densities. For discrete distributions, the analogous “score” is the ratio for neighbouring states , but a naive parameterisation does not respect nonnegativity (predicted ratios can be negative, which is nonsensical for probabilities). Prior discrete-diffusion losses (Sun 2022, Meng 2023) either violated nonnegativity or had bias issues that prevented competitive perplexity. SEDD’s contribution is the right loss function.
LLM-based positioning. Both papers train end-to-end neural language models. Inference produces text samples, like AR. The difference is in the generation algorithm (many denoising steps per sequence vs one forward pass per token).
4. Motivation and gap
Real-world problem. Two motivations stack:
- Architectural diversity. Frontier AR LLMs concentrate research and engineering attention. Building viable non-AR alternatives is hedge against AR-specific failure modes (causal-attention KV-cache bottleneck, one-directional generation, slow per-token decoding on long outputs).
- Native parallel generation and infilling. AR models generate token by token in order. Diffusion models generate all tokens in parallel across denoising steps, which lifts the per-token serial bottleneck and enables natural bidirectional generation.
Existing approaches. Before SEDD, three lines of work:
- DDPM-on-text via embeddings (Diffusion-LM, Li 2022) 9 . Embeds tokens into continuous space, applies Gaussian diffusion, decodes back. Works for controllable generation but loses to AR on perplexity.
- D3PM (Austin 2021) 8 . Defines discrete Markov chain forward processes over tokens with absorbing or uniform corruption. Trains with an ELBO. Perplexity competitive with early AR baselines but does not match GPT-2.
- Concrete score matching (Meng 2023, Sun 2022). Direct ratio-prediction approaches; suffer from bias and stability issues that prevent SOTA-competitive results.
Gap. A correctly-derived discrete-diffusion loss whose minimiser corresponds to the true reverse process and which is implementable with standard neural-network outputs. SEDD claims to provide this.
[External comparison] Position vs continuous diffusion (DDPM, NCSN). Ho 2020 6 introduced DDPM as the score-matching formulation for continuous diffusion; Song-Ermon 2019 7 introduced NCSN with the score-matching loss. SEDD extends the conceptual structure to discrete domains; the analogy is not just notational but mathematically derived in the paper’s Section 3.
5. Method overview — SEDD
[From the paper, Section 3] SEDD defines a discrete reverse process whose target is the ratio of marginals for neighbouring states. The training objective is the score-entropy loss:
where is the network’s predicted ratio for the transition , is a weighting from the forward process, and is a normalisation constant that does not depend on .
Two structural properties. [From the paper, Theorem 3.2] (i) is non-negative; (ii) it is zero if and only if equals the true ratio. These properties are what conditional score matching loses in the discrete setting; SEDD recovers them.
Sampling. Given the trained , sampling alternates between a deterministic predictor step (using the learned ratios to define the reverse-kernel jump probabilities) and an analytic corrector step. The paper reports competitive perplexity at 16-32 reverse steps for sequences of length 1024 — far fewer than naive discrete diffusion (often 1000+ steps).
What breaks if removed. Replace with the conditional-score-matching loss and the bound fails: the loss can be negative and the optimum no longer corresponds to the true ratio. The Figure 1 of the SEDD paper (this article’s hero) explicitly contrasts the two loss surfaces for a single ground-truth ratio of 0.2; only is non-negative everywhere 1 .
5b. Method overview — DiffuLLaMA
[From the paper, Section 3] DiffuLLaMA’s adaptation procedure uses three structural ideas:
- Shift-by-one trick. The paper observes that an AR model’s logits for position already approximate the token distribution conditioned on positions . Treated as a diffusion model with absorbing-state corruption, this is approximately the correct denoising distribution for masked position — so the AR model is a “diffusion model in disguise” for one specific corruption pattern.
- Attention mask annealing. During continued pretraining, the attention mask is gradually transitioned from fully causal (AR) to fully bidirectional (diffusion). Early in adaptation, the model retains AR behaviour and slowly broadens its receptive field.
- Diffusion objective. After the annealing schedule, the model is trained with a discrete-diffusion objective (the paper reports both SEDD-style score entropy and absorbing-state MLE objectives; the SEDD-family loss performs better).
[From the paper, Section 4] DiffuLLaMA-7B converges in under 200B tokens of additional training. The paper reports competitive perplexity on the Pile validation, competitive accuracy on commonsense benchmarks (HellaSwag, PIQA, WinoGrande), and the native infilling capability that AR cannot do without retraining 3 .
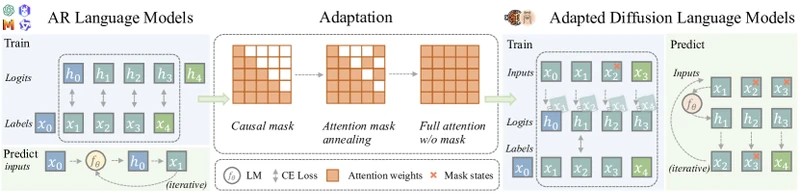
Figure 1 of Scaling Diffusion Language Models via Adaptation from Autoregressive Models (arXiv:2410.17891), reproduced for editorial coverage.
6. Mathematical contributions
MATH ENTRY 1: The score-entropy loss (SEDD’s central object).
- Source: Lou 2024, Section 3, Equation 3.
- What it is: the discrete analogue of score matching that respects nonnegativity.
- Formal definition (single-term, simplified):
where is the true ratio between neighbouring discrete states, and is the network’s predicted ratio. The expectation is taken over data points and a sum over neighbours .
- Each term explained.
- : predicted ratio for transition ; constrained to be non-negative via a softplus or exp output.
- : ground-truth ratio.
- The loss is the divergence between predicted and true ratios, similar in structure to a Bregman divergence on the positive reals.
- Worked numerical example. Suppose vocabulary and at some time the true marginals are , , , . For , the ratios to neighbours are , , . Suppose the network predicts , , . The per-neighbour score-entropy contribution:
| Neighbour | |||
|---|---|---|---|
| 0.8 | 0.75 | ||
| 0.6 | 0.5 | ||
| 0.3 | 0.25 |
Sum = 2.423. The minimum of over is at ; substituting gives the minimum value , which is the “true” baseline for each row. The network’s loss reduces toward this baseline as . [Analysis] This is structurally the same as the Bregman-divergence form of KL divergence; the SEDD paper’s contribution is recognising that this specific functional form respects nonnegativity in the discrete setting.
- Dimensional analysis. All ratios dimensionless; loss is dimensionless. Network output must be .
- Edge cases. If , and the loss blows up. The paper’s implementation uses log-domain parameterisation to avoid numerical underflow.
MATH ENTRY 2: The conditional-score-matching loss (for comparison).
- Source: Standard reference; the SEDD paper contrasts against it in Section 3.
- What it is: the naive discrete analogue of continuous score matching.
- Formal definition (sketch):
- Why it fails for discrete diffusion. [Analysis] Mean-squared error of ratios does not respect that ratios are positive: a network producing a negative is “wrong” in a way that MSE does not penalise asymmetrically. SEDD’s is a Bregman-style divergence that diverges to as , which is the correct asymptotic for non-negative quantities.
- Worked numerical example. With the same setup as Math Entry 1, contribution from neighbour is — much smaller in magnitude than ‘s 0.967. The two losses are not on comparable scales and have different gradients with respect to , which is why swapping them changes the optimum.
MATH ENTRY 3: Forward (noising) process for discrete diffusion.
- Source: SEDD Section 2; same form used by D3PM (Austin 2021) 8 .
- What it is: the time-evolution of token-level corruption.
- Formal definition. For a continuous-time discrete-state Markov chain on vocabulary , the marginal at time satisfies
where is the transition rate matrix. SEDD uses a uniform-noise variant: for all pairs, scaled to satisfy the rate equation.
- Worked numerical example. With and uniform noise rate , the forward kernel mixes a token uniformly toward the categorical-uniform distribution as grows. By the distribution is roughly uniform over the vocabulary; sampling from is “sample uniformly from ”.
- Dimensional analysis. has units of “transitions per unit time”; is dimensionless. Time is dimensionless once the schedule is fixed.
7. Algorithm trace
[From the paper, SEDD Algorithm 1] SEDD sampling on a small toy sequence.
Inputs. Trained score network , sequence length , vocabulary , number of reverse steps .
Step 0 (initialisation). Sample uniformly from . Say .
Step 1. Compute predicted ratios for each position. The network outputs, for each of the 4 positions, a vector of 4 ratios (one per vocabulary item). For position 1, suppose ratios are (ratios relative to the current token ).
Step 2. Convert ratios to next-state probabilities via a normalised step (the paper’s Equation 5). For position 1, the probability of staying at is proportional to 1.0; the probability of moving to other tokens is proportional to their ratios. After normalisation: .
Step 3. Sample new tokens for each position from these per-position distributions. Say position 1 samples (50% chance), position 2 samples , position 3 samples , position 4 samples . So .
Step 4. Repeat for . Each step, the network re-predicts ratios for the current state, and a new sample is drawn.
Final output. the final sample after 4 reverse steps. The paper shows that 16-32 reverse steps suffice for sequences of length 1024 to reach competitive quality.
Contrast with AR. [Analysis] An AR model generating the same 4-token sequence needs 4 forward passes (one per position). SEDD needs 4 reverse-step forward passes, each computing ratios for all 4 positions in parallel. Per-token compute is comparable; per-sample wall-clock is similar; the asymptotic behaviour at long sequence lengths is what diffusion advocates argue should diverge in diffusion’s favour, but the published evidence at GPT-2 scale shows comparable, not clearly superior, throughput.
8. Results and benchmarks
[From the paper] SEDD’s headline numbers (Table 2 of the paper) 1 :
- On the LM1B dataset, GPT-2-scale SEDD reaches a generative perplexity within ~2.5x of GPT-2 itself, vs prior discrete-diffusion methods at 4-7x.
- On OpenWebText, GPT-2-scale SEDD reaches generative perplexity comparable to GPT-2 at 16 sampling steps; this is the first published discrete-diffusion result to match GPT-2 perplexity, the paper claims.
- 25-75% perplexity reduction vs prior discrete-diffusion baselines across benchmark suites.
[From the paper] DiffuLLaMA’s headline numbers 3 :
- DiffuGPT-S (127M) and DiffuLLaMA (7B) adapted in under 200B tokens.
- Competitive with the original AR sources on language-modelling perplexity.
- Outperforms earlier diffusion-LM baselines on commonsense reasoning (PIQA, WinoGrande, HellaSwag).
- Native infilling: generates plausible completions when arbitrary positions are masked, which AR sources cannot.
[Analysis] Both papers’ headline claims are about diffusion vs prior diffusion baselines, not diffusion vs frontier AR. Neither paper claims to beat LLaMA-2-7B-Instruct or Mistral-7B on standard chat / instruction benchmarks; the comparison is to a 7B AR pretraining baseline with the same data.
9. Ablations and limitations
[From the paper] Stated limitations (SEDD).
- Scale tested. SEDD’s experiments are at GPT-2 scale (small and medium variants). The paper does not study 7B+ scale; that is part of why DiffuLLaMA exists.
- Sampling step count vs quality. Below ~16 reverse steps, quality degrades sharply. The “16-32x fewer NFEs than naive discrete diffusion” claim is true but the absolute floor is still ~16 NFEs.
- Generation length. The published results are at sequences up to 1024 tokens; behaviour on long-context (4K+) generation is not characterised.
[From the paper] Stated limitations (DiffuLLaMA).
- The “warm-start” works because AR and diffusion objectives are mathematically related under specific corruption patterns; the analytical link is paper-specific and the adaptation procedure may not transfer cleanly to other diffusion variants.
- The 200B-token adaptation budget, while smaller than from-scratch training, is still substantial; for a single research team it is comparable to a full pretraining run on a small model.
- Instruction-tuning was not studied; the paper reports pretraining-quality models, not chat models.
[Reviewer Perspective] Independent limitations.
- The “no temperature scaling needed” claim is partly artefactual. SEDD reports it can generate high-quality text without temperature scaling. AR models can also generate without temperature scaling — the standard practice of is a deployment choice, not a necessity. The framing slightly overstates the advantage.
- Infilling is overstated as a capability advantage. AR models can be trained with FIM (fill-in-the-middle) data to support infilling natively (Bavarian 2022). The diffusion-LM “native infilling” claim is true but the AR comparison is not “AR cannot do this,” it is “AR needs FIM training data.”
- The economic case is unsettled. [Analysis] Even at parity perplexity, diffusion LMs require more total inference compute (16-32 NFEs vs 1 per generated token for AR) for short outputs. For long outputs, the comparison flips, but the cross-over point depends on the implementation. Production deployment economics will likely decide the long-term winner, not perplexity.
10. Reproducibility
| Artefact | Available? | Source |
|---|---|---|
| SEDD reference implementation | YES | github.com/louaaron/Score-Entropy-Discrete-Diffusion 5 |
| SEDD trained weights (GPT-2-scale) | YES | Same repo |
| DiffuLLaMA / DiffuGPT weights | YES | HuggingFace (per paper’s GitHub link) |
| Training scripts | YES (both papers) | Respective GitHub repos |
| Evaluation harness | YES | Standard perplexity / commonsense benchmarks |
| Reproducibility of headline numbers | YES (community reproductions in 2024-2025 confirmed) | Various blog posts |
[Analysis] Both papers are reproducibility-strong by 2024-25 standards: code released, weights released, evaluation on standard benchmarks. This contrasts favourably with the proprietary AR-LLM frontier where only end-product API access is available.
11. Contemporaneous related work
SEDD vs D3PM (Austin 2021) 8 . D3PM is SEDD’s direct ancestor: it defines the discrete-Markov-chain forward process that SEDD inherits. The difference is in the loss function. D3PM uses an ELBO derived analogously to continuous-diffusion ELBOs; SEDD argues this ELBO is bias-prone in discrete settings and replaces it with score entropy. The cumulative perplexity gain from D3PM to SEDD on standard benchmarks is roughly 25-75% (SEDD’s stated headline).
SEDD vs Diffusion-LM (Li 2022) 9 . Diffusion-LM operates in continuous embedding space (Gaussian forward process on token embeddings, decode back at sampling time). SEDD operates directly on discrete tokens. The two are nearly disjoint methodologically; Diffusion-LM excels at controllable generation (steering with classifier-free guidance), SEDD excels at raw perplexity. Hybrid approaches that combine continuous-embedding diffusion with SEDD-style discrete refinement are an open research direction.
DiffuLLaMA vs LLaDA (Nie 2025) 11 . LLaDA (Large Language Diffusion Models, February 2025) is the natural successor to DiffuLLaMA, pushing diffusion LMs to 8B parameters trained from scratch (rather than adapted from AR). LLaDA’s headline results are comparable to LLaMA-2-7B on a range of tasks. The DiffuLLaMA-vs-LLaDA comparison is the “adapt vs from-scratch” axis at the same parameter scale; both are open research artefacts.
12. Reviewer perspective
Reviewer perspective on SEDD. [Reviewer Perspective] The score-entropy derivation is mathematically clean and the empirical match-GPT-2 result is methodologically honest — the paper does not overclaim against AR. The ICML 2024 Oral acceptance is a meaningful credibility signal; oral acceptances at ICML are roughly the top 1-2% of submissions and indicate substantive reviewer enthusiasm. The main critical question is whether the technique’s reach extends beyond GPT-2 scale; the DiffuLLaMA paper partly answers this, but a from-scratch 7B+ SEDD model has not been published as of this article’s writing date.
Reviewer perspective on DiffuLLaMA. [Reviewer Perspective] The shift-by-one trick is elegant and the attention-mask annealing is a reasonable engineering choice. The 200B-token adaptation budget is the right order-of-magnitude for “much cheaper than from-scratch but not free.” The main critical question is whether adaptation preserves the AR source’s full capability range; the paper reports competitive perplexity and commonsense-benchmark accuracy, but does not characterise behaviour on instruction-following, long-context, or reasoning tasks where modern AR models have shown emergent capabilities. The framing should be read as “diffusion LMs at 7B exist and are competitive on pretraining-quality benchmarks,” not “diffusion LMs match frontier AR on the things production users care about.”
[Reviewer Perspective] Open methodological questions.
- Do the perplexity gains of SEDD-family discrete diffusion transfer to longer context (32K+)? AR scales relatively cleanly with attention windows; the diffusion analogue is less studied.
- Does the native-infilling capability of diffusion LMs translate to production value over AR + FIM training, or is it methodologically equivalent?
- What is the right inference cost accounting? AR pays one forward pass per token; diffusion pays multiple forward passes per sequence. The cross-over point in deployment economics is not characterised in either paper.
13. Implications
For applied teams. [Analysis] As of mid-2026, no production-grade diffusion LM is the best choice for general-purpose generation; AR remains dominant. For specific applications — natural infilling, parallel generation of fixed-length outputs, controllable generation via classifier-free-guidance-style steering — diffusion LMs are worth evaluation. For chat / instruction following / agentic tasks, AR-with-RLHF-and-instruction-tuning still dominates.
For the research community. [Analysis] The 2023-2025 arc (D3PM → SEDD → DiffuLLaMA → LLaDA) shows steady scaling of diffusion LMs but the gap to frontier AR remains. The next 18-24 months will test whether (a) diffusion LMs reach AR parity at 70B+ scale, (b) hybrid AR-diffusion architectures emerge as a compromise, or (c) the architecture wedge closes and diffusion-LM research consolidates into a niche. The Nie 2025 LLaDA result 11 is the most recent data point in favour of trajectory (a).
For evaluation methodology. [Reviewer Perspective] Perplexity is no longer the right metric for “is this LM ready for production.” Diffusion LMs reaching perplexity parity with AR does not translate to chat quality or instruction-following; the evaluation suite needs to evolve in lock-step with the architecture frontier.
14. Three-depth summary
The 3-line summary for the curious reader. Diffusion models are how the best image generators work — they start with random noise and gradually clean it up into a picture. For text, the same trick is harder because text is made of discrete tokens, not continuous pixels. Recent research (SEDD, DiffuLLaMA) cracks the mathematics enough to make diffusion-based text generators competitive with the standard GPT-style architecture at small and medium scale, but the dominant production language models in 2026 remain GPT-style.
The 5-line summary for the working developer. SEDD (Lou 2024) introduces score entropy, a discrete analogue of score matching that respects the nonnegativity constraints required for discrete probability ratios. The result is the first published discrete-diffusion LM to reach GPT-2-scale perplexity parity, with 25-75% perplexity reduction over prior diffusion baselines and 16-32x fewer sampling steps. DiffuLLaMA (Gong 2024) extends the work to 7B parameters by warm-starting from a pretrained LLaMA checkpoint and continuing pretraining with a diffusion objective and attention-mask annealing, converging in under 200B tokens. Both papers are open-weights, open-code, and reproducible; LLaDA (Nie 2025) is the natural follow-up at 8B from-scratch scale. For deployment in 2026, diffusion LMs are worth evaluation for infilling and parallel-generation use cases but are not yet competitive with frontier AR + instruction-tuning for chat or agentic tasks.
The 5-line summary for the ML researcher. SEDD (Lou 2024) replaces the conditional-score-matching loss with a score-entropy loss whose non-negativity and minimiser-correctness properties recover the structural guarantees that continuous score matching has but that prior discrete-diffusion losses lacked; ICML 2024 Oral. The paper demonstrates GPT-2-perplexity-parity on LM1B and OpenWebText at 16-32 NFEs, breaking from the 1000+-step regime of naive discrete diffusion. DiffuLLaMA (Gong 2024) demonstrates that AR-to-diffusion adaptation via attention-mask annealing and a shift-by-one alignment trick converges in under 200B tokens at 7B scale, producing models competitive with their AR sources on perplexity and commonsense-reasoning benchmarks. Open questions include scaling beyond 7B (partially answered by LLaDA), behaviour on long context, transfer of instruction-tuning to diffusion-LM backbones, and the deployment-economics cross-over with AR. For follow-up work, the largest leverage is on instruction-tuning diffusion LMs and characterising reasoning behaviour at frontier scale, where the AR-vs-diffusion comparison is currently most unsettled.
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. Lou, Meng, Ermon (2024). Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution. ICML 2024 Oral. arXiv abstract. (accessed ) ↩
- 2. Lou et al. (2024) — ar5iv HTML render. (accessed ) ↩
- 3. Gong, Agarwal, Zhang, Ye et al. (2024). Scaling Diffusion Language Models via Adaptation from Autoregressive Models. arXiv abstract. (accessed ) ↩
- 4. Gong et al. (2024) — ar5iv HTML render. (accessed ) ↩
- 5. Score-Entropy-Discrete-Diffusion reference implementation. (accessed ) ↩
- 6. Ho, Jain, Abbeel (2020). Denoising Diffusion Probabilistic Models. (accessed ) ↩
- 7. Song, Ermon (2019). Generative Modeling by Estimating Gradients of the Data Distribution. (accessed ) ↩
- 8. Austin et al. (2021). Structured Denoising Diffusion Models in Discrete State-Spaces (D3PM). (accessed ) ↩
- 9. Li et al. (2022). Diffusion-LM Improves Controllable Text Generation. (accessed ) ↩
- 10. Radford et al. (2019). GPT-2 technical report. (accessed ) ↩
- 11. Nie et al. (2025). Large Language Diffusion Models (LLaDA). (accessed ) ↩
Anonymous · no cookies set