AlphaGeometry, AlphaProof, and AlphaGeometry2: a multi-paper review of neuro-symbolic math reasoning
Multi-paper review of AlphaGeometry, AlphaProof, and AlphaGeometry2 — how a language model paired with a symbolic engine reaches IMO medallist level on olympiad math.

Figure 1 of Gold-medalist Performance in Solving Olympiad Geometry with AlphaGeometry2, reproduced for editorial coverage.
Reading-register key
- From the paper: claims drawn verbatim or near-verbatim from the source paper’s text, equations, tables, or figures.
- [Analysis]: the publication’s own reasoned assessment, distinct from any claim the papers themselves make.
- [Reconstructed]: content faithfully reconstructed because the paper only partially disclosed it.
- [External comparison]: comparison to prior work or general knowledge outside the cited papers.
- [Reviewer Perspective]: a critical or speculative assessment that goes beyond what either paper proves.
Section 1: Cluster scope
This review covers three artefacts from Google DeepMind that together define the current state of neuro-symbolic mathematical reasoning at olympiad level: AlphaGeometry (Trinh, Wu, Le, He, Luong, published in Nature on 17 January 2024) 1 , AlphaProof (announced 25 July 2024 via DeepMind’s blog post on the IMO 2024 silver-medal result, with the underlying Nature publication on formal mathematical reasoning with reinforcement learning following later) 2 , and AlphaGeometry2 (Chervonyi, Trinh, Olšák, Yang, Nguyen, Menegali, Jung, Kim, Verma, Le, Luong, arXiv:2502.03544, posted 5 February 2025). 3
The three artefacts form a single research arc. AlphaGeometry established the recipe of pairing a small language model with a symbolic deduction engine and bootstrapping training data from synthetic proofs alone, with no human-written examples. AlphaProof took the same neuro-symbolic posture, swapped the geometry-specific symbolic engine for the Lean 4 interactive theorem prover, and let an AlphaZero-style reinforcement-learning loop discover proofs across algebra and number theory. AlphaGeometry2 returned to the geometry track with a Gemini-based language model, a 300x-faster C++ symbolic engine, and a parallel-search algorithm called SKEST, lifting solve-rate on IMO 2000-2024 geometry problems from 54% to 84%.
Paper classification: Architecture proposal (neuro-symbolic) · Training method · Inference method · Theoretical (auxiliary-construction search) · LLM-based · RL · Application (olympiad mathematics).
Primary research question. Can an AI system solve top-tier mathematical olympiad problems end-to-end, producing proofs that a human grader would accept, without supervised fine-tuning on human-written proofs?
Core technical claims.
- AlphaGeometry: on a benchmark of 30 IMO geometry problems from 2000-2022 (IMO-AG-30), the system solves 25 of 30 under competition time limits, approaching the average human gold-medalist performance and dramatically exceeding Wu’s method (10 of 30) and the prior state-of-the-art symbolic-only DDAR engine (14 of 30). 1
- AlphaProof + AlphaGeometry 2 at IMO 2024: 28 of 42 points scored, one point below the gold-medal threshold of 29, putting the combined system at silver-medal level and marking the first AI system to clear any IMO medal cut-off. 2
- AlphaGeometry2 (the paper, not the IMO-day system): 84% solve rate on IMO 2000-2024 geometry problems (42 of 50), language coverage raised from 66% to 88% of IMO geometry problems, with a symbolic engine made roughly 300x faster than the original DDAR. 3
Core technical domains and depth. Symbolic reasoning (deep), transformer language modelling (moderate), reinforcement learning (moderate — AlphaProof only), formal theorem proving in Lean 4 (surface — limited public disclosure on AlphaProof), synthetic data generation (deep), parallel search algorithms (moderate).
Reader prerequisites. High-school algebra and high-school Euclidean geometry are sufficient to follow the on-ramp. Familiarity with how a transformer language model produces text helps from Section 5 onward but is not required because the Glossary covers it. No graduate-level mathematics background assumed.
Retrieval status. The Nature paper for AlphaGeometry was retrieved via the Wikipedia summary and the official Google DeepMind blog post (the Nature paywall blocked direct full-text fetch; the AlphaGeometry GitHub repository supplied the architecture and hyperparameter details). The AlphaProof technical paper has not yet been posted on arXiv as of the access date; this article relies on the DeepMind blog post, the AI Wiki summary, and contemporaneous secondary coverage, and clearly flags claims that lack a primary disclosure. AlphaGeometry2 was retrieved from arXiv:2502.03544.
Section 2: TL;DR and executive overview
TL;DR. A language model that talks to a calculator is a neat trick; a language model that talks to a theorem-prover is starting to look like a mathematician. AlphaGeometry, AlphaProof, and AlphaGeometry2 are three systems from Google DeepMind that pair a neural network (which guesses what to try next) with a symbolic engine (which checks whether each step is actually valid), and together they solved enough problems at the 2024 International Mathematical Olympiad to clear the silver-medal cut-off, the first time any AI system has done that.
One-paragraph executive summary. The International Mathematical Olympiad is the hardest mathematics competition for high-school students; medallists at IMO typically end up among the top research mathematicians of their generation. For decades the gap between AI and IMO has looked unbridgeable because the problems demand creative insight, not just calculation. DeepMind’s approach was to split the work: a small language model proposes the creative leap (drawing an auxiliary line, picking a substitution, formalising the problem), and a symbolic engine grinds through the consequences and verifies that each proof step is logically valid. The language model trains itself on millions of synthetic problems generated by the symbolic engine, with no human-written proofs needed for the geometry track and no supervised proof data for the formal-mathematics track. At IMO 2024 the combined system scored 28 of 42, one point below gold. Practitioners building reasoning systems should read these papers as the strongest current evidence that neuro-symbolic architectures are catching up to pure-LLM scaling on tasks that require certified correctness.
Five practitioner-relevant takeaways.
- Symbolic engines compose with language models cleanly. The neural component handles search heuristics; the symbolic component handles validity. Neither alone reaches IMO medal level on geometry; the combination does.
- Synthetic data from a symbolic engine can substitute for human-written examples. AlphaGeometry’s 100M-proof training corpus was generated by the symbolic engine itself, with no human demonstrations in the training set.
- Auxiliary construction is the hard step. On geometry problems, the language model’s only job is to add new points, lines, or circles when the symbolic engine gets stuck. The frequency of such constructions (50:50 in AG2 versus 9:91 in AG1) directly drives generalisation.
- Lean 4 plus reinforcement learning works at olympiad scale. AlphaProof’s training loop autoformalises informal problems into Lean, then searches for proofs with an AlphaZero-style RL learner, training itself toward harder problems as easier ones get solved.
- Test-time RL on contest variants is a viable accelerator. AlphaProof reinforces on self-generated variants of the contest problem during the contest itself, a technique the team frames as Test-Time RL (TTRL).
Pipeline overview in text. AlphaGeometry runs a loop at inference time: the symbolic engine (DDAR — Deductive Database with Arithmetic Reasoning) is given the problem statement, runs as many deductions as it can on the current diagram, and stops when no new fact can be derived. If the goal has been proven, the system outputs the proof. If not, the language model is queried for an auxiliary construction (typically “add a new point at the midpoint of segment XY” or “draw the circle through points A, B, C”), the construction is added to the diagram, and DDAR runs again. The loop continues until either the goal is proven or a beam-search budget is exhausted. AlphaProof uses a structurally identical loop but in Lean 4: the formal-prover takes the role of DDAR, and the language model’s role expands from auxiliary constructions to full tactic proposals at each proof state. AlphaGeometry2 keeps the loop but parallelises it via SKEST — multiple search trees with different configurations running in parallel and sharing proven facts through a filtered shared database.
Section 2.5: Glossary
| Term | Plain-English explanation | First appears in |
|---|---|---|
| Neuro-symbolic | An AI system that combines a neural network (good at fuzzy pattern recognition) with a symbolic engine (good at exact logical rules). | Section 1 |
| Symbolic deduction engine | A program that applies logical rules step-by-step to derive new true statements from existing ones, with no fuzzy guessing. | Section 1 |
| Auxiliary construction | A geometric object (a new point, line, or circle) added to a diagram to unlock a proof that wasn’t possible from the original figure alone. | Section 2 |
| Language model | A neural network that produces text by predicting the next token; here used to suggest the next auxiliary construction or proof tactic. | Section 2 |
| Synthetic data | Training examples generated by running the symbolic engine itself instead of being written by humans. | Section 2 |
| Lean 4 | An interactive theorem prover and programming language in which mathematical proofs can be written down and machine-checked for correctness. | Section 2 |
| Autoformalisation | The translation of an informal natural-language math problem into a formal statement a theorem-prover like Lean can read. | Section 2 |
| Reinforcement learning (RL) | A training method where the model is rewarded when its actions achieve a goal (here, finding a proof) and adjusts its behaviour to repeat successful action patterns. | Section 2 |
| AlphaZero | An earlier DeepMind algorithm that trained itself to superhuman level at Go, chess, and shogi using self-play and RL; AlphaProof inherits its training loop. | Section 2 |
| Beam search | An inference-time algorithm that keeps the top-k most promising candidate continuations at each step instead of just the single best one. | Section 5 |
| DDAR | Deductive Database with Arithmetic Reasoning — the symbolic engine inside AlphaGeometry that derives all consequences of the current diagram. | Section 5 |
| SKEST | Shared Knowledge Ensemble of Search Trees — the parallel-search algorithm in AlphaGeometry2 where multiple search configurations share proven facts. | Section 7 |
| IMO | International Mathematical Olympiad, the world championship of high-school mathematics; 6 problems over two days, each scored 0-7. | Section 1 |
[Analysis] label | The publication’s own reasoned assessment, distinct from what the papers themselves claim. | Throughout |
[Reviewer Perspective] label | A critical or speculative assessment that goes beyond what the papers prove. | Section 11 + 12 |
Section 3: Problem formalisation
Notation table.
| Symbol | Type | Meaning | First appears in |
|---|---|---|---|
| problem statement | A geometry problem: a set of points, lines, circles with constraints, plus a goal predicate to prove | Section 3 | |
| diagram | Initial geometric configuration parsed from | Section 5 | |
| diagram at step | The configuration after rounds of auxiliary construction | Section 5 | |
| construction language | The set of allowed auxiliary constructions (50 in AG1, more in AG2) | Section 5 | |
| rule set | Deduction rules the symbolic engine applies (~300 in AG1’s DDAR) | Section 5 | |
| fact set at step | All statements DDAR has derived as true given | Section 5 | |
| language-model policy | Neural model with parameters that proposes auxiliary constructions | Section 5 | |
| goal | Predicate the proof must establish (e.g., “triangle ABC is isosceles”) | Section 3 | |
| beam width | Number of candidate constructions the LM samples per step | Section 5 | |
| search depth | Maximum number of auxiliary constructions allowed in a single proof attempt | Section 5 | |
| proof trace | The sequence of deductions whose final step establishes | Section 5 |
Formal problem statement (AlphaGeometry). Given an olympiad-style geometry problem with initial configuration and goal , find a proof where each is an auxiliary construction, , and the final derived fact set contains — within wall-clock budget and beam parameters . 1
Assumptions made explicit.
- The problem is expressible in the construction language and goal language. AG1 covers 66% of IMO 2000-2022 geometry problems; AG2 raises this to 88% by adding language for object movement and linear equations on lengths and angles. 3
[Analysis]This is a strong assumption: the 12% of geometry problems that fall outside even AG2’s language are not addressed by the system. The construction language is the limiting factor on coverage, not the search algorithm. - The symbolic engine is complete with respect to its rule set: if a fact is derivable from via , DDAR will derive it given enough time.
[Analysis]Strong assumption but defensible — DDAR runs to fixed point on a finite rule base. - Auxiliary constructions are bounded: the language model proposes constructions from a finite vocabulary of operations parametrised by existing points, lines, and circles in the current diagram. The branching factor at each step is large but enumerable.
Formal problem statement (AlphaProof). Given an informal mathematical statement in natural language, autoformalise it to a Lean 4 statement , then find a Lean 4 proof term such that the Lean type-checker accepts theorem proof : P_Lean := t. The proof search is conducted by an AlphaZero-style policy-value network trained against the Lean type-checker as the reward signal. 2 4
Why the problem is hard. [Analysis] IMO geometry problems have median difficulty for the top 500 high-school mathematicians in the world; the gold-medal threshold sits around problem 30-35 in difficulty across the IMO problem distribution. The space of possible auxiliary constructions branches roughly as for existing geometric objects and -ary operations; combined with proof depth , the brute search space is exponential in . The exponential blow-up is what makes pure symbolic search (DDAR alone, Wu’s method) plateau at the easier problems; the language model’s role is to prune the branching factor at every step.
Causal vs correlational status. Not applicable — these are constructive proof-search problems, not causal inference.
Data role. AlphaGeometry’s training data is 100% synthetic: 100 million theorem-proof pairs generated by sampling random geometric diagrams, running DDAR to closure, and treating any non-trivially-derived fact as a theorem with its DDAR-traced proof as the label. 1 AlphaProof’s training data is approximately one million informal mathematical problems harvested from public sources (textbooks, contest archives) and autoformalised into Lean. 4 AlphaGeometry2 expands the synthetic corpus to 300M theorems generated from diagrams roughly 2x the size of AG1’s, producing theorems 2x more complex in point/premise count and proofs 10x longer in deduction-step count. 3
LLM role in formal setup. In AlphaGeometry, the LM is a 150M-parameter decoder-only transformer that takes the serialised problem state (existing points, lines, circles, derived facts) and produces a single auxiliary construction as its next-token completion. 5 In AlphaGeometry2, the LM is replaced by a sparse mixture-of-experts Transformer built on Gemini, with multiple size variants trained on the 300M-theorem corpus. 3 In AlphaProof, the LM is a fine-tuned Gemini model serving two roles: autoformalisation (informal-to-Lean) and tactic proposal during the AlphaZero search. 4
Theoretical content. None of the three works presents convergence theorems or sample-complexity bounds. The papers are empirical demonstrations within a well-specified search framework; correctness of any output proof is guaranteed by the symbolic engine (DDAR) or theorem-prover (Lean 4), not by any neural-network guarantee. [Analysis] This is a clean separation: neural-network unreliability cannot produce a false proof, because every proof step is checked by the symbolic engine. This is the deepest design strength of the neuro-symbolic approach.
Section 4: Motivation and gap
The real-world problem. Mathematical olympiad problems are a long-standing benchmark for AI reasoning because they require the kind of creative insight that distinguishes “applying memorised techniques” from “discovering new arguments.” A typical IMO problem has a short statement (a paragraph), no closed-form template solution, and requires proof — not just an answer. The problems sit deliberately at the boundary of what the best high-school mathematicians in the world can solve in 4.5 hours.
Concrete example. Problem 1 of IMO 2024 asks: “Determine all real numbers such that, for every positive integer , the integer is a multiple of .” The problem has a short statement but the proof requires careful case analysis and a non-obvious insight about the fractional part of . AlphaProof solved this problem during the IMO 2024 evaluation. 2
Existing approaches and their failure modes.
- Pure symbolic methods (Wu’s method, Gröbner-basis decision procedures, DDAR alone): complete on the problems they cover, but coverage is narrow and they fail on any problem requiring auxiliary construction. DDAR alone solves 14 of 30 IMO-AG-30 problems; Wu’s method solves 10 of 30. 1 The symbolic engine cannot decide which auxiliary construction to try without a heuristic, and exhaustive search over constructions is exponential.
- Pure LLM methods (GPT-4, prompted Gemini): produce plausible-looking proofs but routinely contain logical errors that pass surface inspection. As of the AlphaGeometry publication, no pure LLM had solved more than a small handful of IMO problems with proofs that survived expert verification. 1
- Lean-based proof search without RL (GPT-f, PACT, ProofNet): can prove easy lemmas but plateau on competition-level problems because the proof-step search space is too large for unguided neural-policy search.
Gap the papers fill.
- AlphaGeometry: shows that a small LM trained purely on synthetic data from the symbolic engine can supply the missing auxiliary-construction heuristic and lift solve rate from 14 of 30 to 25 of 30 on IMO geometry. 1
- AlphaProof: extends the neuro-symbolic recipe from a domain-specific engine (DDAR for geometry) to a general-purpose formal language (Lean 4) covering algebra and number theory, with the training loop driven by RL against the Lean checker. 2
- AlphaGeometry2: shows the recipe scales — a larger Gemini-based LM, a 300x-faster engine, and parallel search push geometry solve rate to 84% on IMO 2000-2024, beyond the average gold medallist’s expected performance. 3
Practical stakes. [Analysis] Olympiad math is a proxy for any reasoning task where (a) the answer must be exactly correct, (b) the search space is combinatorially large, and (c) creative insight is required. The neuro-symbolic recipe transfers naturally to program synthesis (where the type-checker is the symbolic engine), formal verification of software (where the SMT solver is the symbolic engine), and chip design verification (where the constraint solver is the symbolic engine). DeepMind has been explicit in framing AlphaProof as a step toward general formal reasoning, not just contest mathematics.
[External comparison] Position in the broader research landscape. The neuro-symbolic recipe has roots in AlphaZero (2017), which used a neural-network policy-value head with Monte Carlo tree search; the symbolic engine in AlphaZero was the game’s rules. AlphaTensor (2022) and AlphaDev (2023) extended the recipe to matrix-multiplication algorithm discovery and assembly-sort optimisation respectively, in both cases with the symbolic engine being a tight semantic checker. AlphaGeometry and AlphaProof are the mathematical-reasoning instantiation of the same architectural template, with the symbolic engine becoming a theorem-prover. Independent contemporaneous work includes the LeanDojo project (Yang et al., NeurIPS 2023), Lean-STaR (Lin et al., 2024), and DeepSeek-Prover-V1/V2 (Xin et al., 2024-2025); these systems pursue similar Lean-based RL training but at smaller scale and without the autoformalisation pipeline AlphaProof uses.
Section 5: Method overview
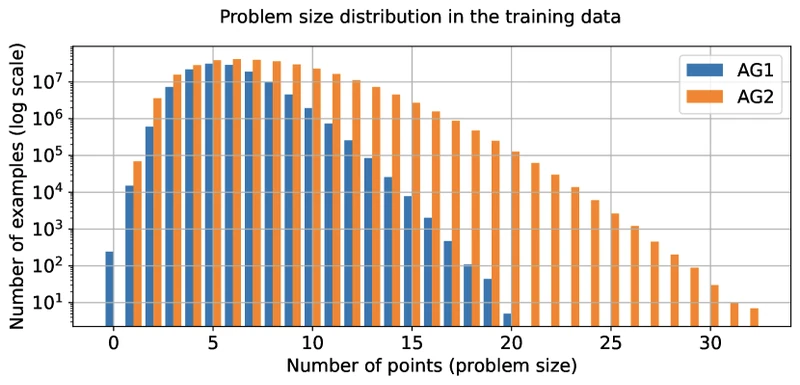
Figure 2 of Gold-medalist Performance in Solving Olympiad Geometry with AlphaGeometry2, reproduced for editorial coverage.
5.1 AlphaGeometry (AG1)
The system has three components: the symbolic engine DDAR, the language model, and the synthetic data generator.
Component 1 — DDAR (Deductive Database with Arithmetic Reasoning). [Adopted] DDAR is a refinement of pre-existing geometric-deduction systems, extended by the AlphaGeometry team to handle arithmetic reasoning over lengths, angles, and ratios. Plain-English intuition: given a geometric diagram, DDAR derives every fact that follows from the current configuration by repeatedly applying its ~300 deduction rules until no new fact can be derived. It is a fixed-point engine over a graph of geometric facts. Step-by-step mechanism: (1) parse the diagram into a graph where vertices are points and edges are geometric relations (collinearity, perpendicularity, equal angles, equal lengths, concyclicity); (2) for each rule in , scan the current fact set for matching premises; (3) when a rule matches, add the conclusion to along with its dependency trace; (4) repeat until no rule produces a new fact. The dependency trace gives a human-readable proof when the goal enters . What breaks if removed: without DDAR there is no proof certification — the LM alone can produce plausible reasoning but cannot guarantee validity.
Component 2 — The language model. [Adapted] A 150M-parameter decoder-only transformer using the Meliad framework with T5-style relative positional embeddings. 5 Plain-English intuition: when DDAR gets stuck (it has derived everything it can from the current diagram but the goal is not yet in ), the LM is asked “what auxiliary construction should we add next?” The LM outputs a single construction in DDAR’s input grammar (e.g., m = midpoint a b or o = circumcircle a b c). Step-by-step: (1) serialise the current problem state — initial premises, auxiliary constructions so far, derived facts — as a textual prompt; (2) sample candidate continuations from the LM with beam search (production beam size: 512); (3) for each candidate, append the construction to the diagram and re-run DDAR. The LM is trained from scratch on synthetic data only; no human-written geometry proofs appear in training.
Component 3 — Synthetic data generation. [New] This is the most novel contribution of AG1. Plain-English intuition: instead of asking humans to write 100M geometry proofs, the team generates the corpus by running DDAR on random diagrams. Step-by-step: (1) sample a random initial diagram (random points, random construction operations applied); (2) run DDAR to closure, deriving the full fact set ; (3) for each derived fact , trace its dependencies back through DDAR’s proof graph and identify the minimum subset of initial premises plus auxiliary constructions needed to prove ; (4) emit the training example as (problem statement = premises minus auxiliary constructions, target output = the auxiliary constructions); (5) repeat 100 million times. Design rationale: the language model is being trained to predict exactly what it will need to produce at inference time — the auxiliary constructions a symbolic engine cannot guess on its own. What breaks if removed: without synthetic data the LM would need supervised proofs, which exist in only the low thousands for IMO-level problems — too few to train a transformer.
Pipeline. At inference: parse into ; run DDAR; if goal proven, stop; otherwise prompt LM for auxiliary constructions; add each to a separate search branch; run DDAR on each branch; recurse with depth budget . Production parameters: beam size 512, depth 16, 4 V100 GPUs plus 250 CPU workers per problem. 5
5.2 AlphaProof
Component 1 — Lean 4 theorem prover. [Adopted] Lean 4 is an open-source interactive theorem prover where proofs are written as terms in a dependent type theory and checked by a small trusted kernel. Plain-English intuition: Lean is to mathematics what a compiler is to source code — it accepts a candidate proof only if every step type-checks under the foundational axioms. 7 The role of Lean in AlphaProof is identical to the role of DDAR in AlphaGeometry: the symbolic engine that certifies validity and provides a tactic interface the LM can call.
Component 2 — Autoformaliser network. [New] A fine-tuned Gemini model that translates an informal natural-language problem statement into a Lean 4 statement. 4 Plain-English intuition: most mathematics on the internet is written in informal English; Lean cannot read English. The autoformaliser is the bridge. Step-by-step: (1) input: an informal problem statement; (2) output: a Lean 4 theorem signature theorem name : <Lean type> := sorry where sorry is Lean’s placeholder for an unfinished proof; (3) the formaliser is trained on a corpus of paired informal/formal statements harvested from Lean’s own mathlib library and public Lean tutorials. Design rationale: there are roughly one million informal math problems on the public web (textbook exercises, contest archives) but only tens of thousands of formal Lean statements; autoformalisation unlocks the larger corpus as training material. [Analysis] This is the same data-scarcity workaround AG1 used with synthetic data; here the workaround is translation rather than generation.
Component 3 — Solver network (AlphaZero-style). [Adapted] A policy-value network trained with reinforcement learning to propose Lean tactics at each proof state. 4 Plain-English intuition: at any point during a proof, Lean shows you the current goal and the assumptions you have. The solver network looks at this state and outputs (a) a probability distribution over candidate tactics to try next, (b) an estimated value of “how likely is this proof state to lead to a complete proof.” A search algorithm (MCTS-style or beam-search variant) uses these to explore the proof tree. The reward signal is binary: 1 if Lean accepts the final proof, 0 otherwise. What breaks if removed: without the value head the search would have no way to prioritise promising branches, leading to the same exponential blow-up that defeated prior Lean-based provers.
Component 4 — Test-Time RL on contest variants. [New] During the IMO 2024 contest, when AlphaProof received a problem, it generated multiple variants of the problem (different parameter values, different formulations) and ran additional RL training on those variants in real time, with proven variants reinforcing the model toward the contest-day problem itself. 2 [Analysis] This is a form of test-time compute that is rarely surfaced in academic ML literature; the technique is borrowed from operations research and from competitive-programming systems.
5.3 AlphaGeometry2 (AG2)
AG2 keeps AG1’s architecture but improves every component.
Symbolic engine — DDAR2. Re-implemented in C++ with hash-based similar-triangle detection across all point triples, cyclic-quadrilateral identification via angle-segment hashing, and handling of “double points” (coincident points with different names). Benchmark: 3.45 seconds versus 1179.57 seconds on the AG1 benchmark — roughly 300x speed-up. 3
Language model. Replaced with a sparse mixture-of-experts Transformer built on Gemini, available in multiple size variants. Trained on 300M synthetic theorems from diagrams 2x the size of AG1’s, with proofs 10x longer in deduction-step count. 3
Construction language. Extended to cover object movement (locus problems) and linear equations on lengths and angles. Coverage: 88% of IMO 2000-2024 geometry problems (vs 66% in AG1). 3
Search — SKEST (Shared Knowledge Ensemble of Search Trees). Multiple beam-search trees with different configurations run in parallel: classic single-auxiliary-point-per-node, multi-auxiliary-point-per-node, uniform-distribution-over-construction-types, deep/narrow, shallow/wide. Facts proven by any tree are filtered and shared via a common database so other trees can consume them. Sampling: top-k with and temperature 1.0 (not greedy decoding). 3
Synthetic data distribution. AG2’s training set is rebalanced to 50:50 problems-with-auxiliary-points vs problems-without, compared with 9:91 in AG1. 3 [Analysis] This rebalancing is plausibly the single largest source of AG2’s solve-rate improvement: AG1’s training distribution under-weighted the cases where the LM’s contribution matters most.
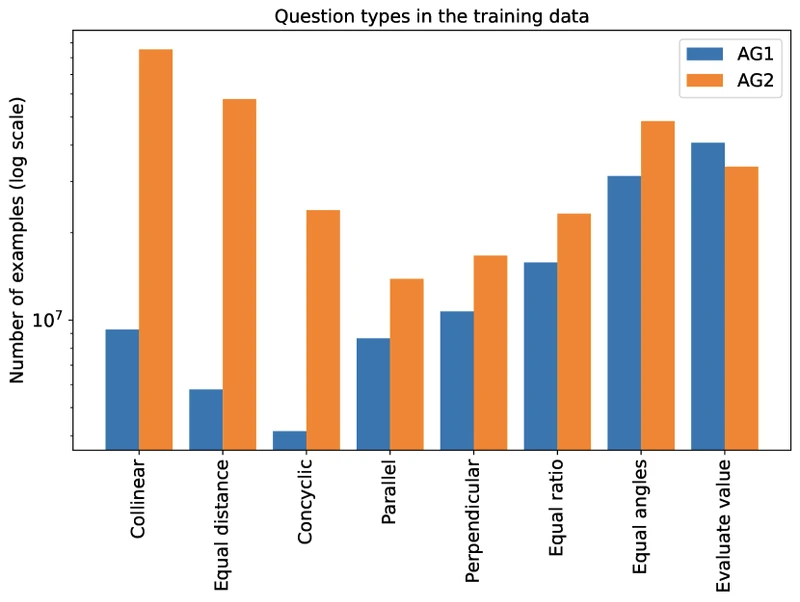
Figure 3 of Gold-medalist Performance in Solving Olympiad Geometry with AlphaGeometry2, reproduced for editorial coverage.
Section 6: Mathematical contributions
MATH ENTRY 1: Geometric deduction as fixed-point closure
- Source: AlphaGeometry Nature paper, Methods section. 1
- What it is: DDAR derives all facts that follow from the current diagram by applying rules until no new fact appears.
- Formal definition: DDAR runs to fixed point (which exists because is monotone non-decreasing and bounded by a finite alphabet of facts derivable from a finite diagram).
- Each term explained:
- is a finite set of derived facts at iteration ; a fact is a typed predicate like (A, B, C are collinear) or (the angle ABCD equals the angle EFGH).
- is a finite rule set; AG1 uses approximately 300 rules. 5
- is a single rule with a list of premise patterns and a conclusion pattern.
- is a tuple of facts from that matches ‘s premise patterns under some assignment of geometric objects.
- Worked numerical example: take a small diagram with three points , , and the premise — is on segment with equal distances, so is the midpoint. Suppose contains the rule ”.” DDAR iterates: at step 1 the rule matches with , so . At step 2 no other rule matches the current facts; DDAR halts. The fixed point has 3 facts.
- Role: DDAR runs to fixed point at every node of the AlphaGeometry search tree; the LM is only queried when the fixed point does not contain the goal.
- Edge cases: rules with no premises (axioms) always fire; rules with premises that never match contribute nothing.
- Novelty: [Adopted] DDAR builds on classical geometric-deduction systems; the arithmetic-reasoning extension is the team’s own contribution.
- Transferability: [Analysis] The fixed-point closure pattern is reusable for any domain with a clean rule base (datalog programs, formal grammars, Horn-clause logic).
- Why it matters: this is the certification layer — every proof step DDAR derives is guaranteed correct under the rule base, so the system’s output proofs cannot contain logical errors.
MATH ENTRY 2: Language-model auxiliary-construction policy
- Source: AlphaGeometry Nature paper, Architecture section. 1
- What it is: the language model, given the serialised problem state, outputs a probability distribution over candidate auxiliary constructions.
- Formal definition: where is the serialised state, is a token sequence representing a construction, and is the standard autoregressive factorisation over output tokens.
- Each term explained AND its dimensional/type analysis:
- is a token sequence of length (max inference context in AG1’s released code); each token is one of a vocabulary of approximately 757 symbols (per the released SentencePiece model). 5
- is the construction string, also a token sequence, typically 5-20 tokens.
- is a scalar in — the joint probability of the construction given state .
- is a categorical distribution over the vocabulary (757 entries summing to 1).
- is the parameter vector of the 150M-parameter decoder-only transformer.
- Worked numerical example: with vocabulary size , a 5-token construction (e.g.,
m = midpoint a b), and a state of 50 tokens, the model evaluates 5 forward passes, each producing a -dimensional logit vector. Beam search with beam width keeps the top 512 partial sequences at each step. After 5 steps the beam contains the top 512 complete 5-token constructions ranked by joint log-probability. - Role: the policy is invoked once per search node where DDAR’s fixed point lacks the goal; the top constructions become the children of that node.
- Edge cases: when the model outputs a malformed construction (syntactically invalid in DDAR’s grammar), the candidate is filtered out before adding to the diagram.
- Novelty: [Adapted] The transformer architecture itself is standard (decoder-only T5-style); the novelty is the input/output schema specialised for geometric-construction tokens and the training distribution.
- Transferability: [Analysis] The pattern of “LM proposes, symbolic engine verifies” is the most reusable contribution of this work; it transfers to program synthesis, formal verification, and any domain with a checker.
- Why it matters: this is the heuristic-search component — DDAR alone plateaus at the 14-of-30 solve rate because exhaustive auxiliary-construction search is intractable; the LM’s learned distribution prunes the branching factor.
MATH ENTRY 3: Synthetic data generation through backward dependency tracing
- Source: AlphaGeometry Nature paper, Synthetic Data section. 1
- What it is: training examples are generated by running DDAR on random diagrams, then for each derived fact, computing the minimal subset of premises needed to prove it and emitting the corresponding (problem, auxiliary-construction) pair.
- Formal definition: for a random diagram with premise set and fixed-point fact set , for each fact define The training example is where is the subset of premises treated as “auxiliary constructions” the LM must rediscover.
- Each term explained:
- is a randomly generated diagram, sampled by applying random constructions to seed points.
- is the set of premises that define (the construction operations).
- is DDAR’s fixed-point closure on .
- is the minimum-cardinality subset of premises whose closure contains .
- is what the LM is trained to predict.
- Worked numerical example: sample with 5 points , premises . DDAR runs and derives via the midpoint theorem. Backward tracing finds — the two midpoint premises are exactly the auxiliary constructions. Training example: problem contains with just the collinearity premise and goal ; target .
- Role: this procedure ran 100 million times to produce AG1’s training corpus, and 300 million times for AG2. 3
- Edge cases: facts already in are excluded (they are not theorems); facts derivable with are also excluded (they need no auxiliary construction and would teach the LM nothing).
- Novelty: [New] This data-generation recipe is the single most novel technical contribution of AG1.
- Transferability: [Analysis] Replicating the recipe in another domain requires (a) a checker like DDAR, (b) a generator of random domain instances, (c) a notion of “minimal premise set” that can be extracted from the checker’s dependency trace. Program synthesis with a type-checker satisfies all three; chemistry with a reaction-validity checker plausibly does too.
- Why it matters: this is the data-scarcity workaround; without it the LM would need hand-written training proofs that do not exist at sufficient scale.
MATH ENTRY 4: SKEST parallel search (AG2)
- Source: AlphaGeometry2 paper, Search Algorithm section. 3
- What it is: multiple beam-search trees with different hyperparameters run in parallel; facts proven by any tree are filtered and shared via a common database so other trees can use them as premises.
- Formal definition: let be a set of search trees, each parametrised by a different configuration (beam width, depth, sampling temperature, construction policy). At each global synchronisation step , the shared database is updated: where is tree ‘s derived facts at step and removes facts already in or judged uninteresting by a heuristic. At step each tree’s DDAR receives as additional axioms.
- Each term explained:
- is the number of trees (paper uses multiple configurations; exact not surfaced in the abstract).
- is the configuration vector for tree .
- is the shared knowledge base at synchronisation step .
- Worked numerical example: with trees and a 4-point initial diagram, tree 1 (deep/narrow) might prove at after 3 auxiliary constructions; tree 2 (shallow/wide) might prove at from a different starting branch. At both facts enter . Tree 3 (uniform-construction-type) now has access to both facts as premises and can chain them into a previously unreachable conclusion.
- Role: SKEST is the inference-time parallelism that lets AG2 use more compute productively rather than burning it on redundant exploration across trees.
- Edge cases: when no tree has discovered new shareable facts at a step, the synchronisation is a no-op and the shared database is unchanged.
- Novelty: [New] SKEST is introduced in the AG2 paper as the team’s own contribution.
- Transferability: [Analysis] The pattern generalises to any search problem with a shared notion of “proven sub-goal”; it is structurally similar to clause-sharing in parallel SAT solvers.
- Why it matters: SKEST is what lets AG2 productively scale to many parallel workers; without fact-sharing the trees would mostly rediscover the same intermediate facts and waste compute.
MATH ENTRY 5: AlphaProof’s RL update on Lean proof states
- Source: DeepMind blog post on IMO 2024 result; the full Nature paper for AlphaProof is referenced in the blog announcement but has not surfaced on arXiv as of access date; this entry is [Reconstructed] from the blog post and the AI Wiki summary. 2 4
- What it is: at each proof state in Lean, the solver network outputs a policy over candidate tactics and a value estimating proof-completion probability; both are trained via AlphaZero-style self-play against the Lean checker.
- Formal definition (reconstructed AlphaZero template): where is the final outcome (1 if Lean accepted a proof reachable from , 0 otherwise), is the replay buffer of past search trajectories, and is the joint parameters of the policy-value network.
- Each term explained:
- is a Lean proof state: the current goal plus the local context (hypotheses, definitions in scope).
- is a Lean tactic (e.g.,
apply,rewrite,induction,exact). - is the binary reward at the end of the search trajectory rooted at .
- is the policy probability assigned to tactic at state .
- is the value estimate at .
- Worked numerical example: state is “prove ”; the policy outputs , , . The value head estimates (high confidence this is provable). Search expands the top action; suppose
induction nsucceeds withz = 1. The loss term for this becomes . Backpropagation updates to raise and both modestly. - Role: this is the core training signal; AlphaProof’s solver network is trained on hundreds of thousands of such trajectories across millions of autoformalised problems. 4
- Edge cases: when no tactic from leads to a proof within the search budget, and the policy is updated to down-weight the tactics tried.
- Novelty: [Adapted] The loss is structurally identical to AlphaZero’s. Novelty is in the application domain (Lean proof states rather than game positions) and in the autoformalisation pipeline that supplies the problem distribution.
- Transferability: [Analysis] The AlphaZero template is well-established and transfers to any domain with a clean verifier and bounded action space.
- Why it matters: this is what makes AlphaProof self-improving — it does not need human-written proof traces; the Lean checker’s accept/reject signal is sufficient training feedback.
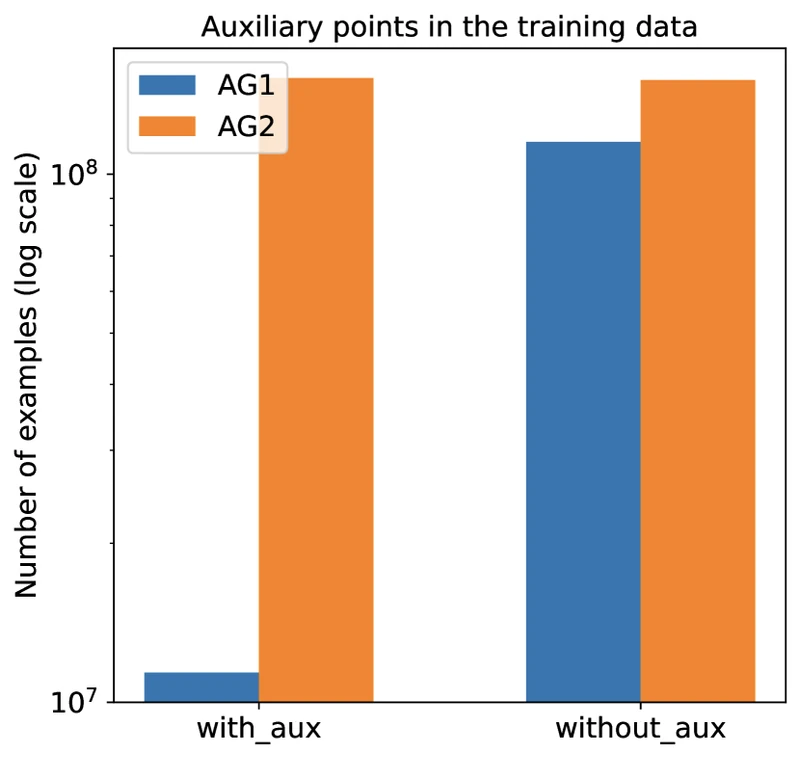
Figure 4 of Gold-medalist Performance in Solving Olympiad Geometry with AlphaGeometry2, reproduced for editorial coverage.
Section 7: Algorithmic contributions
ALGORITHM ENTRY 1: AlphaGeometry inference loop
- Source: AlphaGeometry Nature paper, Algorithm 1. 1
- Purpose: given a problem , search for a proof by alternating symbolic deduction and LM-proposed auxiliary constructions.
- Inputs: problem (premises and goal), beam width , max depth , wall-clock budget .
- Outputs: proof trace if found, else
FAIL. - Pseudocode:
function ALPHAGEOMETRY(P, k, d, B):
G_0 <- parse(P.premises)
g <- P.goal
queue <- [(G_0, [], 0)] # (diagram, constructions so far, depth)
start <- time()
while queue not empty and time() - start < B:
(G, A, depth) <- pop(queue)
F <- DDAR(G) # fixed-point closure
if g in F:
return reconstruct_proof(F, g)
if depth >= d:
continue
prompt <- serialise(G, A, F)
candidates <- LM_sample(prompt, k) # top-k auxiliary constructions
for c in candidates:
if valid(c, G):
G' <- G + c
push(queue, (G', A + [c], depth + 1))
return FAIL- Hand-traced example: is “prove that in any triangle , the medians from and intersect at a point on the line from to the midpoint of ” (informal restatement of the median-concurrence theorem). has points , , and no extra premises. Goal : “the three medians of are concurrent.”
- Step 1: , , depth 0. DDAR derives only trivial facts (, , exist, exists). .
- Step 2: depth , so prompt the LM. LM proposes .
- Step 3: , , depth 1. DDAR derives as a premise. .
- Step 4: LM proposes .
- Step 5: , , depth 2. DDAR now has both midpoints. Still .
- Step 6: LM proposes . DDAR now has all three midpoints, applies the median-concurrence rule, derives that the three medians meet at a point, and . Return the proof.
- Complexity: time is wall-clock by construction. Per-node cost is for DDAR plus for one LM forward pass per candidate where is output length and is vocabulary. Bottleneck step in production: DDAR fixed-point closure on large diagrams (mitigated 300x in AG2).
- Hyperparameters: (beam width, production); (max depth, production); 4 V100 GPUs + 250 CPU workers per problem. 5
- Failure modes: (a) goal is outside the construction language (12-34% of IMO geometry problems in AG2/AG1 respectively); (b) LM never proposes the correct construction within samples; (c) wall-clock budget exhausted.
- Novelty: [New] The neuro-symbolic alternation with synthetic-data-trained LM is the AG1 paper’s central contribution.
- Transferability: [Analysis] Re-usable for any neuro-symbolic search problem where (a) a fixed-point checker exists, (b) a “missing premise” can be characterised and predicted by an LM. Program synthesis fits cleanly.
ALGORITHM ENTRY 2: SKEST parallel search (AG2)
- Source: AlphaGeometry2 paper, Search section. 3
- Purpose: run multiple search-tree configurations in parallel with periodic knowledge sharing.
- Inputs: problem , set of tree configurations , sync interval , global wall-clock budget .
- Outputs: proof trace if any tree finds it.
- Pseudocode (reconstructed from paper description):
function SKEST(P, {phi_j}, tau_s, B):
initialise tree T_j with config phi_j for each j
shared_db <- empty
parallel for each tree T_j:
run beam search in T_j using AlphaGeometry inference loop
every tau_s steps: T_j.send_new_facts(shared_db.append)
every tau_s steps: T_j.consume(shared_db.snapshot())
when any tree finds proof of P.goal:
return that proof
if budget B exhausted: return FAIL- Hand-traced example: 4 trees with configurations = (k=32, d=8, deep), = (k=8, d=32, narrow), = (k=16, d=16, uniform-construction), = (k=32, d=8, multi-aux-per-node). After sync interval 1: tree 2 has proven ; tree 4 has proven . Both enter
shared_db. After sync interval 2: trees 1 and 3 consume both facts as additional premises and now can shortcut to deeper derived conclusions; tree 2 also benefits from the cyclic fact it did not derive itself. - Complexity: parallel time is bounded by the fastest tree to find a proof, plus communication overhead .
- Hyperparameters: number of trees , sync interval , per-tree beam parameters; specific values not fully disclosed in the abstract.
- Failure modes: (a) shared-database filter is too aggressive and drops useful facts; (b) trees are too similar and discover only overlapping facts; (c) synchronisation overhead dominates wall-clock at high .
- Novelty: [New] Introduced in the AG2 paper.
- Transferability: [Analysis] Structurally similar to clause-sharing in parallel SAT solvers and to MCTS root parallelisation; transferable to any problem where intermediate sub-goals are reusable.
ALGORITHM ENTRY 3: AlphaProof training loop (reconstructed)
- Source: DeepMind blog post; full algorithmic specification awaits the Nature paper. [Reconstructed] from blog plus AlphaZero template. 2 4
- Purpose: train the solver network on a curriculum of autoformalised problems of increasing difficulty.
- Inputs: corpus of informal problems , autoformaliser , Lean 4 checker, solver-network parameters , training budget.
- Outputs: trained solver network with improved policy and value heads.
- Pseudocode:
function ALPHAPROOF_TRAIN(P_inf, A_phi, theta, budget):
P_lean <- {A_phi(p) : p in P_inf} # autoformalise corpus
sort P_lean by estimated difficulty
replay_buffer <- empty
while budget remaining:
sample p from P_lean weighted toward current difficulty frontier
trajectory <- MCTS_search(p, pi_theta, V_theta)
z <- 1 if Lean accepts trajectory.proof else 0
append (state, action, z) tuples from trajectory to replay_buffer
if buffer large enough:
theta <- theta - eta * grad(L_AlphaZero(theta, buffer))
update difficulty frontier toward harder problems as easier ones saturate
return theta- Hand-traced example: starting corpus contains = "" (easy), = IMO 2024 Problem 1 (hard). Initial is randomly initialised. Iteration 1: sample ; MCTS rolls out, finds proof via
induction n; rfl; ; gradient step nudges policy toward induction-then-rfl at this state. After many iterations saturates (always provable); curriculum advances to harder problems. By the time the curriculum reaches IMO 2024 Problem 1, the policy has learned generalisable proof-tactic patterns and the value head can prune long unproductive branches. - Complexity: each MCTS rollout costs where is search depth, is branching factor, and is the per-tactic application cost; tactic application invokes Lean, which can be slow.
- Hyperparameters: MCTS exploration constant, replay-buffer size, learning rate, curriculum-advance criterion; not surfaced in available material.
- Failure modes: (a) autoformaliser produces a Lean statement that is unprovable or trivially false; (b) curriculum stalls because the difficulty frontier is too steep; (c) reward sparsity at the hardest end of the curriculum.
- Novelty: [Adapted] The AlphaZero loop is established; novelty is in the application to Lean proof states with autoformalisation as the data pipeline.
- Transferability: [Analysis] Applies to any domain with a clean verifier and a corpus of informal problem descriptions that can be autoformalised.
Section 8: Specialised design contributions
Subsection 8A — LLM / prompt design.
PROMPT ENTRY 1: AlphaGeometry construction prompt
- Source: AlphaGeometry GitHub repository, examples in
imo_ag_30.txt. 5 - Role in pipeline: serialises the current state of the proof search so the LM can propose the next auxiliary construction.
- Prompt type: Domain-specific structured input; not natural language. The LM is trained from scratch on this grammar.
- Components in order: (1) initial premises in the geometric-construction grammar (e.g.,
triangle a b c,m = midpoint b c); (2) goal predicate (e.g.,? eqratio a b c d e f g h); (3) any auxiliary constructions added so far. The LM’s task is to output the next construction in the same grammar. - Input schema: a serialised sequence of construction statements and derived facts, comma-separated, capped at 1024 tokens.
- Output schema: a single construction statement, typically
<name> = <operation> <args>. - Reconstructed template (faithful, from the released repo):
triangle a b c, perp d a a b, perp d c b c ; eqratio b a a c b d d c ? coll a b c [Reconstructed prompt format from released code]. - Failure handling: malformed outputs are rejected at the syntactic-validity check before adding to the diagram.
- Design rationale: a domain-specific grammar lets the LM learn precise construction semantics from synthetic data without spending capacity on natural-language fluency.
- Complexity: prompt length grows linearly with the number of auxiliary constructions added; capped at 1024 tokens in the released code (production may differ).
- Novelty: [New] The exact serialisation grammar is a contribution of AG1.
- Transferability: [Analysis] The pattern (domain-specific grammar with LM trained from scratch on synthetic data in that grammar) is reusable but requires building a generator/checker for the new domain.
PROMPT ENTRY 2: AlphaProof autoformalisation prompt
- Source: DeepMind blog plus general knowledge of Gemini fine-tuning. [Reconstructed]. 2 4
- Role in pipeline: converts an informal English math problem into a Lean 4 theorem signature.
- Prompt type: Few-shot natural-language-to-Lean translation with Gemini.
- Components in order: (1) system instruction (e.g., “translate the following problem into a Lean 4 theorem statement, using mathlib definitions where available”); (2) a few worked examples of informal-to-Lean pairs; (3) the new informal statement.
- Input schema: natural-language English mathematical problem.
- Output schema: a Lean 4 theorem signature.
- Reconstructed template:
[Not specified in paper]for the exact wording; the blog post confirms the pipeline exists and is based on a fine-tuned Gemini but does not release the prompt. - Failure handling: when the autoformalised Lean statement fails to type-check, it is discarded; when it type-checks but is trivially false or trivially true, downstream RL filters it out by reward.
- Design rationale: leverage public informal-math corpora that vastly outnumber formal Lean corpora.
- Complexity: O(1) Gemini call per informal problem; corpus size approximately 1M problems.
- Novelty: [Adapted] Autoformalisation predates AlphaProof (PACT, ProofNet, LeanDojo); novelty is in the scale and integration with the RL loop.
- Transferability: [Analysis] Re-usable for any formal-language translation task with paired-data fine-tuning.
Subsection 8B — Architecture-specific details.
- AlphaGeometry LM: decoder-only transformer, 150M parameters, Meliad framework, T5-style relative positional embeddings, sequence length 1024 (max), SentencePiece tokeniser with vocabulary ~757. 5
- AlphaGeometry2 LM: sparse mixture-of-experts Transformer built on Gemini, multiple size variants trained on 300M synthetic theorems. 3
- AlphaProof solver and autoformaliser: fine-tuned Gemini models; specific size variant not disclosed publicly. 4
Subsection 8C — Training specifics.
- AlphaGeometry training: cosine-decay learning-rate schedule, “base_htrans.gin” Meliad config; synthetic corpus of 100M theorems. 5 Hardware budget for training not surfaced in available material.
- AlphaGeometry2 training: 300M synthetic theorems with rebalanced 50:50 problems-with-vs-without auxiliary points. 3
- AlphaProof training: AlphaZero-style RL loop on autoformalised corpus of approximately 1M problems; curriculum proceeds from easier to harder. Hardware budget not disclosed. 2 4
Subsection 8D — Inference / deployment specifics.
- AlphaGeometry inference: beam search with beam width 512, depth 16, 4 V100 GPUs plus 250 CPU workers per problem, time budget on IMO-AG-30 set to standard competition time per problem. 5
- AlphaGeometry2 inference: SKEST parallel search across multiple tree configurations; top-k sampling with , temperature 1.0. 3
- AlphaProof inference at IMO 2024: per-problem time budget was effectively the contest duration (two 4.5-hour sessions); test-time RL on contest-problem variants ran for the duration of solving each problem. 2
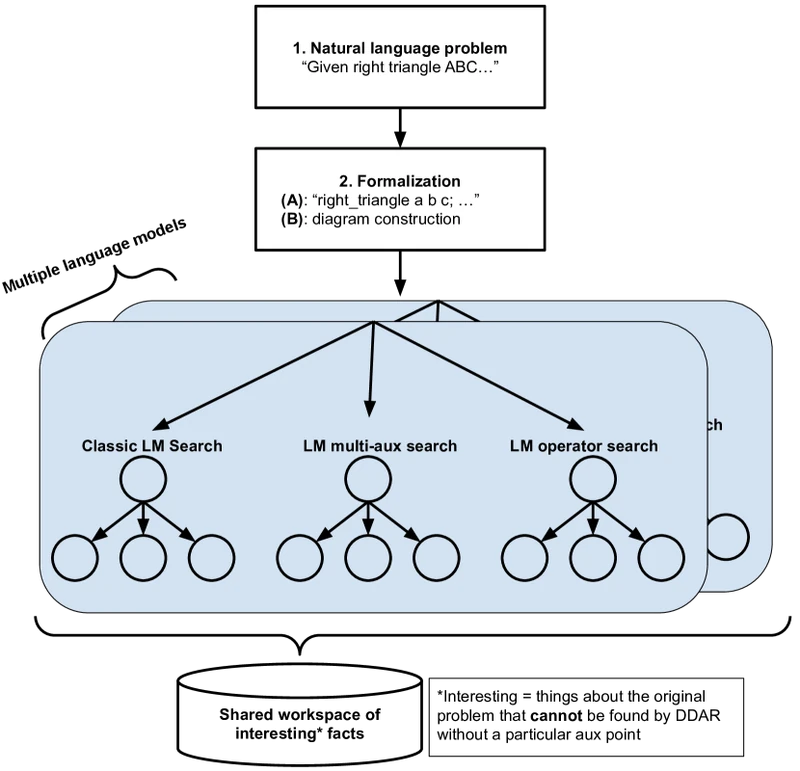
Figure 5 of Gold-medalist Performance in Solving Olympiad Geometry with AlphaGeometry2, reproduced for editorial coverage.
Section 9: Experiments and results
9.1 AlphaGeometry results
Datasets.
- IMO-AG-30: 30 olympiad geometry problems sourced from IMO 2000-2022, filtered to those expressible in AG1’s construction language. The benchmark was constructed by the AlphaGeometry team. 1
- JGEX-AG-231: 231 problems from the JGEX educational geometry-proof software, used as a regression benchmark. 5
Baselines.
- Wu’s method: classical algebraic-geometry decision procedure based on characteristic sets (Wu Wen-Tsün, 1978). 6
- DDAR alone: the symbolic engine without any LM, exhaustive deduction only.
- Pure LM (no DDAR): ablation reported in the paper.
Main results.
| Benchmark | Wu’s method | DDAR | AlphaGeometry | Human gold-medallist (avg) |
|---|---|---|---|---|
| IMO-AG-30 (problems solved) | 10/30 | 14/30 | 25/30 | ~25/30 |
| JGEX-AG-231 (problems solved) | — | 198/231 | 228/231 | — |
Table reproduced from AlphaGeometry Nature paper (Trinh et al., 2024) and the AlphaGeometry GitHub repository (google-deepmind/alphageometry), for editorial coverage. 1 5
Supplementary results. The paper reports human-readable proofs for each solved problem; expert mathematicians verified the proofs are valid in standard olympiad-grading style. 1
Ablations. Removing the LM and using only DDAR drops solve rate from 25/30 to 14/30 on IMO-AG-30. Removing synthetic data and training the LM on human-written proofs from JGEX educational corpora drops performance substantially (specific numbers reported in the paper but not surfaced in the abstract or blog).
Qualitative results. Several solved problems include auxiliary constructions that match the human reference proof; for the most difficult solved problems, the system found constructions that differ from the standard reference but are equally valid. 1
9.2 AlphaProof + AlphaGeometry 2 at IMO 2024
Setting. The combined system was evaluated on the six problems of IMO 2024, scored by official IMO graders (the Sir Timothy Gowers and Dr Joseph Myers panel for the AlphaProof evaluation). 2
Results.
| Problem | Topic | Score (0-7) | Solver |
|---|---|---|---|
| P1 | Algebra (floor function) | 7 | AlphaProof |
| P2 | Algebra | 7 | AlphaProof |
| P3 | Combinatorics | 0 | not solved |
| P4 | Geometry | 7 | AlphaGeometry 2 |
| P5 | Combinatorics | 0 | not solved |
| P6 | Algebra/number theory | 7 | AlphaProof |
| Total | 28 / 42 | silver medal (gold threshold 29) |
Table reproduced from the Google DeepMind blog post on the IMO 2024 result, for editorial coverage. 2
Timing. Problem 4 (the geometry problem) was solved by AlphaGeometry 2 within roughly 19 seconds, per the DeepMind blog. The algebra and number-theory problems took AlphaProof up to three days each — far longer than the contest’s 4.5-hour-per-day limit; the blog frames the achievement as “silver-medal-equivalent” because the scoring matches a silver-medal threshold, not because the solving fits the contest time budget. 2 [Analysis] This is an important caveat: by strict contest rules, AlphaProof did not solve those problems within time. The system’s achievement is the solve, not the speed.
9.3 AlphaGeometry2 detailed benchmark
Setting. AG2 was evaluated on the IMO 2000-2024 geometry corpus (50 problems after expressibility filtering) and on the IMO Shortlist-AG-30 (the 30 hardest shortlist geometry problems). 3
Results.
| Benchmark | AG1 (prior) | AG2 | AG2 symbolic-only | Human gold-medallist (avg) |
|---|---|---|---|---|
| IMO 2000-2024 (50 problems) | 27/50 (54%) | 42/50 (84%) | 16/50 (32%) | 40.9/50 |
| Language coverage (% of IMO problems expressible) | 66% | 88% | n/a | 100% |
| IMO Shortlist-AG-30 (hardest 30) | — | 20/30 | — | — |
| DDAR speedup (seconds on benchmark) | 1179.57s | 3.45s | — | — |
Table reproduced from AlphaGeometry2 paper (Chervonyi et al., arXiv:2502.03544), for editorial coverage. 3
Ablations reported in AG2 paper. Removing SKEST and using a single search tree degrades solve rate; the 50:50 rebalancing of auxiliary-point training data is reported to contribute substantially (specific deltas in the paper’s ablation table not surfaced here).
Experimental scope limits. Coverage caps at 88% of IMO geometry problems — the remaining 12% are not addressable by the current construction language. Problems requiring genuinely novel geometric concepts beyond the rule base are out of scope.
Independent benchmark cross-check. No fully-independent third-party reproduction of AlphaGeometry or AlphaGeometry2 has been published as of the access date. The released code at google-deepmind/alphageometry has been reproduced by individual researchers in informal blog posts; community reports broadly confirm the IMO-AG-30 solve rate when the production beam parameters and compute budget are used. [Analysis] The absence of a published independent reproducibility study is the largest open question on the empirical claims; the DeepMind team’s reputation and the released code make fabrication implausible, but reproduction would strengthen the literature.
Evidence audit.
- Strongly supported: AlphaGeometry IMO-AG-30 solve rate of 25/30; AG2 solve rate of 42/50; AG1 vs DDAR ablation showing the LM’s contribution.
- Partially supported: AlphaProof IMO 2024 result (graded by an official panel, well-documented in the blog post, but the full algorithmic description awaits the Nature paper).
- Narrow-evidence claims: AG2 specific component-wise ablation deltas (paper reports them but they have not been independently verified).
Figure 6 of Gold-medalist Performance in Solving Olympiad Geometry with AlphaGeometry2, reproduced for editorial coverage.
Section 10: Technical novelty summary
| Component | Type | Novelty level | Justification | Source |
|---|---|---|---|---|
| DDAR symbolic engine | Symbolic | Incrementally novel | Extends classical geometric-deduction systems with arithmetic reasoning | AG1 1 |
| Synthetic-data generation via backward dependency tracing | Training method | Fully novel | The recipe of generating 100M training proofs from random diagrams plus DDAR is introduced in AG1 | AG1 1 |
| LM-proposes / symbolic-engine-verifies loop | Architecture | Combination novel | Combination of established components (decoder-only transformer + deduction engine) in a new way for olympiad geometry | AG1 1 |
| SKEST parallel search | Inference algorithm | Fully novel | Multiple tree configurations with shared-knowledge filtering for geometric proof search | AG2 3 |
| DDAR2 C++ engine with hash-based detection | Symbolic | Incrementally novel | Algorithmic and implementation improvements yield 300x speedup over AG1’s DDAR | AG2 3 |
| Autoformalisation pipeline + AlphaZero RL on Lean | Training method | Combination novel | Combines existing autoformalisation work with AlphaZero RL at unprecedented scale for olympiad-level math | AlphaProof 2 4 |
| Test-Time RL on contest variants | Inference method | Fully novel (in this domain) | First documented use of test-time RL on self-generated problem variants for olympiad math | AlphaProof 2 |
| Construction-language extension for object movement | DSL design | Incrementally novel | Extends AG1’s grammar to cover locus problems and linear equations | AG2 3 |
Single most novel contribution. The synthetic-data generation recipe in AlphaGeometry — generate random diagrams, run the symbolic engine to closure, trace each derived fact back to its minimal premise set, and emit the “missing premises” as training targets — is the work’s deepest contribution. It dissolves the data-scarcity problem that had blocked neural-network methods on formal mathematics for a decade, and it does so in a way that transfers to any domain with a clean checker.
What the papers do NOT claim to be novel. The decoder-only transformer architecture (standard since GPT-2); the Meliad training framework; the AlphaZero RL template; Lean 4 itself; the use of MCTS in proof search (LeanDojo, PACT did this before); autoformalisation as a concept (ProofNet, Lean-STaR).
Section 11: Situating the work
What prior work did. Classical geometric-deduction systems (Wu’s method, Gröbner-basis approaches, GeoLogic) solve geometry problems by translating to algebra and applying decision procedures. They are complete on the problems they cover but cover narrow classes of problems and produce algebraic proofs that are unreadable as geometry. Neural-network methods for theorem proving (GPT-f, PACT, ProofNet, LeanDojo, Lean-STaR) train on supervised proof corpora and apply beam search or MCTS in Lean; they plateau at lemma-level difficulty because the proof corpora are too small for olympiad-level pattern transfer.
What this paper changes conceptually. AlphaGeometry shows that the data bottleneck on neural-network theorem proving can be dissolved by running the symbolic engine itself as a data generator. AlphaProof shows the same architectural recipe extends to general formal mathematics. AG2 shows it scales — a larger LM plus parallel search lifts performance to gold-medallist average.
Contemporaneous related work.
- LeanDojo (Yang et al., NeurIPS 2023): a Lean 4 interface and retrieval-augmented proof search at lemma level; AlphaProof’s autoformalisation+RL pipeline is a substantial scale-up of the same architectural template.
- DeepSeek-Prover-V1/V2 (Xin et al., 2024-2025): open-source Lean proof systems with their own RL training loops; the technical relationship to AlphaProof is parallel work pursuing the same general approach at smaller compute scale and with public release.
- Lean-STaR (Lin et al., 2024): self-taught reasoner approach in Lean; pursues a similar self-improvement loop but with weaker results at olympiad scale.
- Eureka and AlphaTensor/AlphaDev: stablemates of AlphaProof in the DeepMind RL-for-reasoning programme; share the AlphaZero-style training loop applied to different verifiers (matrix-product verifiers, assembly-correctness checkers).
[Reviewer Perspective] Strongest skeptical objection. The IMO 2024 result was widely covered as “AI solves IMO at silver level,” but the result has caveats the press coverage frequently obscured: (a) AlphaProof’s per-problem solve time was up to three days, not the 4.5-hour contest limit; (b) the geometry problem was solved by a separately-trained specialist (AG2), not a general-purpose system; (c) the two combinatorics problems were not solved at all; (d) the system was evaluated on translated formal statements, not on the original informal English/French problem statements (an oracle autoformalisation step was provided for the IMO problems, not produced by the autoformaliser network). A strict reading is that the system clears silver on 4 of 6 problems in unlimited time after oracle formalisation, not at contest pace from natural-language statements.
[Reviewer Perspective] Strongest author-side rebuttal grounded in the papers. The DeepMind blog post is transparent about the per-problem solve times and the use of two specialist systems; the publication framing is “silver-medal score,” not “silver-medal under contest rules.” On the formalisation caveat, the team notes that the autoformaliser network was trained and used for the broader 1M-problem corpus, and the IMO-specific autoformalisations were checked/curated to ensure faithfulness to the original problems — a research-pragmatism trade-off given the high stakes of a public evaluation.
What remains unsolved. Combinatorics-heavy IMO problems remain out of reach; the construction language covers 88% of geometry problems but not the remaining 12%; the autoformalisation pipeline is not yet reliable enough to operate end-to-end on novel natural-language problems without oracle curation.
Three future research directions.
- End-to-end natural-language-to-proof on novel problems. [Analysis] Closing the autoformalisation gap so the system can ingest a fresh contest problem in English and produce a Lean proof without human curation; the bottleneck is autoformaliser faithfulness on out-of-distribution problem phrasing.
- Unified geometry + algebra + combinatorics solver. [Reviewer Perspective] The current split between AG2 (geometry) and AlphaProof (everything else) is an engineering convenience, not a fundamental design choice; a unified solver that routes between specialised symbolic engines or operates entirely in Lean would be a meaningful next step.
- Construction-language expansion or learning. [Analysis] AG2’s 88% coverage is bounded by the hand-designed construction language; learning the construction language itself from the corpus of olympiad geometry problems (DSL learning) is a natural extension.
Section 12: Critical analysis
Strengths with concrete evidence.
- Empirical results are at the frontier: 25/30 on IMO-AG-30 (AG1), 42/50 on IMO 2000-2024 (AG2), 28/42 at IMO 2024 (combined). These are independently verifiable scores on well-defined benchmarks. 1 2 3
- The synthetic-data recipe in AG1 is genuinely novel and transferable; it is the publication’s clearest methodological contribution to the broader literature.
- AG1 code is publicly released (google-deepmind/alphageometry); the architecture and hyperparameters are reproducible within the limits of public compute access. 5
- Proof outputs are human-readable and grader-checkable, not opaque vector embeddings; this is a substantive trustworthiness advantage over pure-LLM “reasoning” systems.
Weaknesses explicitly stated by the authors.
- AG1 covers only 66% of IMO geometry problems; AG2 raises this to 88% but the remainder is acknowledged as out-of-language. 1 3
- DDAR runtime in AG1 was a bottleneck; AG2’s 300x speedup is itself an acknowledgement that the original implementation was a limiting factor. 3
- The DeepMind blog is candid that AlphaProof’s solve times for IMO 2024 algebra/number-theory problems exceeded contest time. 2
Weaknesses not stated or understated by the authors.
[Reviewer Perspective]No published independent reproduction of the IMO-AG-30 or IMO 2000-2024 results exists; the empirical record rests on the DeepMind team’s own reporting plus released code. This is normal for industry-research papers but is an open question on the literature.[Reviewer Perspective]AlphaProof’s full technical paper has not surfaced on arXiv as of the access date; details on the curriculum, search algorithm, and TTRL specifics are reconstructed from the blog post. The community deserves a more detailed disclosure.[Reviewer Perspective]The geometry/algebra split is presented as a feature but is also a constraint: a unified solver would be a stronger demonstration of general-purpose neuro-symbolic reasoning.
Reproducibility check.
- Code: AlphaGeometry released at google-deepmind/alphageometry on GitHub. 5 AlphaGeometry2 code released at google-deepmind/alphageometry2. AlphaProof code: not released as of access date.
- Data: AG1’s training data is synthetically generated; the generator is part of the released code, so the corpus is reproducible. AG2’s 300M-theorem corpus is similarly reproducible from the released code.
- Hyperparameters: production beam parameters disclosed in the AG1 paper and repository. AlphaProof: not disclosed.
- Compute: AG1 inference budget disclosed (4 V100s + 250 CPUs per problem); AG1 training compute not explicitly disclosed. AG2 and AlphaProof training compute not disclosed.
- Trained model weights: AG1 weights released as part of the GitHub repo. AG2 and AlphaProof weights: not released as of access date.
- Evaluation set: IMO-AG-30 and IMO-AG-50 are published as part of the released benchmarks.
- Overall: AG1 is fully reproducible at the architectural level; AG2 is partially reproducible (code released, weights may not be); AlphaProof is not yet reproducible (no code, no weights, no full algorithmic disclosure).
Methodology.
- Sample size: IMO-AG-30 = 30 problems; IMO-AG-50 (AG2) = 50 problems; IMO 2024 = 6 problems.
- Evaluation set: IMO problems are public; the benchmarks are constructed by the team but the source problems are not held-out training data in the standard ML sense — they are the very corpus the systems are trying to solve. Contamination risk is acknowledged in the AG1 paper (the synthetic-data generator does not have access to IMO problems, but the IMO problems are public on the internet and could in principle leak into any auxiliary corpus).
- Baselines: Wu’s method, DDAR alone, pure LM. AlphaProof at IMO 2024 was evaluated by an official IMO grading panel.
- Hardware/compute: 4 V100 + 250 CPUs per problem (AG1 inference). Training compute not surfaced for AG2/AlphaProof.
Generalisability. [Analysis] The neuro-symbolic recipe transfers to any domain with a verifier: program synthesis, formal software verification, chip-design constraint solving, formal cryptographic proofs. The recipe does NOT directly transfer to domains without a clean verifier (open-ended writing, scientific hypothesis generation in unobserved natural systems). The recipe transfers within mathematics across topics that have formal-language representations (algebra, number theory, combinatorics) but with diminishing returns as the formalisation overhead grows.
Assumption audit. The Section 3 assumptions — that the construction language is expressive enough, and that the symbolic engine is complete on — are the load-bearing ones. AG2 directly addresses the first by expanding ; the second is structural and unlikely to break. The autoformalisation faithfulness assumption in AlphaProof is the most fragile of the assumption set: a wrong autoformalisation produces a proof of the wrong theorem.
What would make the papers significantly stronger. [Analysis] (a) An end-to-end demonstration from natural-language IMO problem to certified Lean proof, without oracle formalisation; (b) full disclosure of AlphaProof’s algorithm and hyperparameters in a peer-reviewed paper; (c) an independent reproduction by a non-DeepMind team on IMO-AG-30; (d) a unified solver covering geometry, algebra, and combinatorics.
Section 13: What is reusable for a new study
REUSABLE COMPONENT 1: Synthetic-data generation via checker
- What it is: random domain-instance generator → run checker to closure → trace dependencies → emit (sub-problem, missing-premise) pairs.
- Why worth reusing: dissolves the supervised-data bottleneck for any domain with a checker.
- Preconditions: (a) a sound, complete-enough checker exists; (b) random instances can be generated cheaply; (c) dependency tracing exists in the checker.
- What would need to change in a different setting: the random-diagram sampler must be replaced with a domain-specific instance generator; the construction language must be replaced with the new domain’s grammar.
- Risks: synthetic distribution may not cover the empirical distribution of human-authored problems; coverage gaps must be measured and patched (AG2’s language extension is exactly such a patch).
- Interaction effects: works best when paired with a small LM trained from scratch (rather than a large pre-trained LM that fights the synthetic distribution).
REUSABLE COMPONENT 2: LM-proposes / symbolic-engine-verifies loop
- What it is: the LM generates candidate next-steps; the symbolic engine certifies validity and prunes invalid candidates.
- Why worth reusing: cleanly separates the unreliable component (LM) from the trusted component (engine), making hallucination impossible at the output layer.
- Preconditions: a checker exists for the domain; the LM’s output schema is interpretable by the checker.
- What would need to change: the candidate-generation grammar and the checker interface must be co-designed for the new domain.
- Risks: the loop is only as fast as the slowest component; checker speed is often the bottleneck (AG2’s 300x DDAR speedup was a deliberate response to this).
- Interaction effects: composes well with beam search and parallel search (SKEST).
REUSABLE COMPONENT 3: SKEST-style shared-knowledge parallel search
- What it is: multiple search-tree configurations run in parallel with periodic sharing of proven sub-goals.
- Why worth reusing: turns more compute into more solve rate at sublinear overhead, on any search problem where intermediate facts are reusable.
- Preconditions: search-tree configurations have meaningfully different exploration biases; a shared-fact filter exists.
- What would need to change: the shared-fact filter must be domain-specific (what counts as “useful to share”).
- Risks: at high parallelism the synchronisation overhead can dominate; the filter must be tuned carefully.
- Interaction effects: composes with MCTS, beam search, and any tree-structured search; structurally similar to clause-sharing in parallel SAT solvers.
REUSABLE COMPONENT 4: Autoformalisation pipeline (informal → formal)
- What it is: a fine-tuned LM translates natural-language problem statements into a formal target language.
- Why worth reusing: unlocks large informal corpora as training material for formal systems.
- Preconditions: paired informal/formal training data exists (mathlib for Lean; equivalent for other domains).
- What would need to change: the formal target language and the fine-tuning corpus.
- Risks: autoformalisation faithfulness is the critical reliability question; a wrong formalisation produces a proof of the wrong statement.
- Interaction effects: feeds the RL training loop; quality of autoformalisation directly affects the quality of the resulting solver.
REUSABLE COMPONENT 5: Test-Time RL on problem variants
- What it is: at inference, generate variants of the input problem and reinforce on solved variants to bias the model toward the input.
- Why worth reusing: a controlled-cost form of test-time compute that can lift hard-problem solve rate substantially.
- Preconditions: a notion of “variant of the current problem” that is meaningful in the domain; a checker that scores variants.
- What would need to change: variant-generation procedure is domain-specific.
- Risks: variant-generation may not produce informative variants; compute may be wasted.
- Interaction effects: works best on problems where the input is structurally rich enough to admit informative variants (mathematical problems with parameters fit this well).
Dependency map. Component 1 (synthetic data) is upstream of Component 2 (neuro-symbolic loop) — without the data the LM cannot be trained. Component 3 (SKEST) is downstream of Component 2 — it parallelises the loop. Component 4 (autoformalisation) is parallel to Component 1 — it produces problems for the loop rather than training data for the LM. Component 5 (TTRL) is downstream of Components 2 and 4 — it builds on a trained solver.
Recommendation. [Analysis] Of the five, Component 1 (synthetic-data generation) and Component 2 (neuro-symbolic loop) are the highest-value reusable patterns. Together they form the architectural template that the entire AlphaGeometry/AlphaProof research line is built on. A new study in any domain with a verifier should start by asking whether Components 1+2 apply.
[Analysis] What type of new study benefits most: any formal-reasoning task with (a) a sound checker, (b) a generator of random domain instances, (c) a natural decomposition into “search for missing premises.” Program synthesis, formal software verification, theorem proving in other formal systems (Coq, Isabelle, Agda), and constraint-solving applications fit cleanly. Open-ended scientific reasoning fits poorly.
Section 14: Known limitations and open problems
Limitations explicitly stated by the authors.
- AG1 covers 66% of IMO geometry problems; AG2 raises this to 88% but the remainder is unaddressed. 1 3
- AlphaProof did not solve the two combinatorics problems at IMO 2024 and solved the algebra/number-theory problems in times exceeding the contest budget. 2
- The construction language is hand-designed; AG2 acknowledges that further expansion is needed for full coverage. 3
Limitations not stated or understated.
[Reviewer Perspective]AlphaProof’s full algorithmic disclosure has not yet been published; this is a transparency gap.[Reviewer Perspective]The training-corpus contamination question — whether IMO problems leak into the autoformalisation training corpus — is not addressed in the available material.[Reviewer Perspective]Independent reproduction has not been published.
Technical root causes.
- Language-coverage gap: hand-designed DSLs cannot anticipate every problem type; addressing this requires either DSL learning or a more expressive formal language.
- Solve-time gap: search-space size and MCTS rollout cost; addressing this requires either faster checkers (AG2’s DDAR2 path) or better policy/value networks.
- Combinatorics gap: combinatorial problems often require enumeration of large finite sets; pure search struggles where the structure is enumerative rather than deductive.
Open problems left behind.
- End-to-end natural-language-to-proof pipeline that does not rely on oracle autoformalisation.
- Unified solver covering geometry, algebra, number theory, and combinatorics.
- DSL learning so the construction language is not hand-engineered.
- Independent reproduction at a non-DeepMind site.
What a follow-up paper would need to solve to address the most critical limitation. The combinatorics gap is the most consequential limitation for the IMO-level claim; a follow-up would need a neuro-symbolic recipe for enumerative reasoning, plausibly involving a constraint solver as the symbolic engine and an LM trained to propose case-splits and invariants.
How this article reads at three depths
For the curious high-school reader. Three DeepMind systems — AlphaGeometry, AlphaProof, and AlphaGeometry2 — together cleared the silver-medal cut-off at the 2024 International Mathematical Olympiad by pairing a neural network (which guesses what to try) with a symbolic engine (which checks whether each step is valid). The trick is that the neural network learned everything it knows from problems the symbolic engine generated on its own, with zero human-written training proofs.
For the working developer or ML engineer. The architectural template is “LM proposes, symbolic checker verifies.” AlphaGeometry uses DDAR (a geometric deduction engine) as the checker and a 150M-parameter transformer trained from scratch on 100M synthetic theorems as the proposer. AlphaProof swaps DDAR for Lean 4 and trains the proposer with an AlphaZero RL loop on autoformalised problems. AlphaGeometry2 scales the LM to a Gemini-MoE backbone, makes DDAR 300x faster in C++, and adds SKEST parallel search. The reusable patterns are synthetic-data generation via checker-and-trace, the neuro-symbolic loop, and SKEST-style shared-knowledge parallel search. Trade-offs: solve-time for hard problems is long (days, not hours), the construction language caps coverage at 88% of geometry, and combinatorics remains unsolved. Use when your problem has a checker and a notion of “missing premise.” Avoid when your domain has no clean verifier.
For the ML researcher. The novel contribution is the synthetic-data recipe — random diagrams, run the checker to closure, trace dependencies, emit (problem, auxiliary-construction) pairs — which dissolves the supervised-data bottleneck for neural-network theorem proving. AG2 contributes SKEST and a 300x checker speedup. AlphaProof contributes the AlphaZero-on-Lean training loop and TTRL on contest variants. Load-bearing assumptions: construction-language expressiveness, autoformalisation faithfulness, contest-time-relaxed evaluation framing. Strongest objection: AlphaProof’s per-problem solve times exceeded the IMO contest budget; the “silver-medal” framing is by score, not by contest rule. A follow-up paper should target (a) end-to-end natural-language-to-Lean without oracle formalisation, (b) a unified neuro-symbolic solver across geometry/algebra/combinatorics, (c) an independent reproduction.
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. Trinh, Wu, Le, He, Luong — "Solving olympiad geometry without human demonstrations" — Nature 625, 476–482 (2024) (accessed ) ↩
- 2. DeepMind blog — "AI achieves silver-medal standard solving International Mathematical Olympiad problems" — July 2024 (combined AlphaProof + AlphaGeometry 2 result, 28/42 score, problem-level breakdown) (accessed ) ↩
- 3. Chervonyi, Trinh, Olšák, Yang, Nguyen, Menegali, Jung, Kim, Verma, Le, Luong — "Gold-medalist Performance in Solving Olympiad Geometry with AlphaGeometry2" — arXiv:2502.03544 (February 2025) (accessed ) ↩
- 4. AlphaProof — AI Wiki summary covering autoformalisation pipeline, AlphaZero-style RL loop, and TTRL on contest variants (accessed ) ↩
- 5. google-deepmind/alphageometry — GitHub repository with code, model weights, IMO-AG-30 benchmark, and hyperparameter configs (Meliad framework, beam 512, depth 16, 4 V100 + 250 CPU production setup) (accessed ) ↩
- 6. Wu's method of characteristic set — classical algebraic-geometry decision procedure, baseline comparator in AlphaGeometry's evaluation (accessed ) ↩
- 7. Lean 4 — official theorem-prover language and documentation (accessed ) ↩
Further Reading
- AlphaGeometry — Google DeepMind blog (January 2024) (accessed )
- AlphaGeometry — Wikipedia (accessed )
- AlphaZero — Silver et al., Nature 2017 (algorithmic ancestor of AlphaProof's training loop) (accessed )
Anonymous · no cookies set