What Is Mixture-of-Experts (MoE) and Why Does It Matter for LLM Inference Cost?
Mixture-of-Experts splits a transformer's feed-forward layers into experts and activates only a few per token. The result: cheaper inference for dev teams.
The short answer
Mixture-of-Experts (MoE) is the architectural pattern where a transformer’s feed-forward layers are split into multiple parallel “experts,” and a small router selects only a subset of them per token. The result is a model with the parameter count of a much larger dense model but the inference compute of a much smaller one.
Mixtral 8x7B, the canonical open-weight example released by Mistral, has roughly 46.7 billion total parameters but activates only about 12.9 billion of them on any given forward pass. 1 For dev teams running LLM inference on rented GPUs, MoE matters because it cuts FLOPs per token (cheaper compute) without sacrificing capability. The trade is RAM: every expert has to be loaded into VRAM whether it fires or not, and routing introduces its own overhead. Cheaper to run, more expensive to host.
What MoE actually is
A standard transformer block has two parts: an attention layer and a feed-forward network (FFN). In a dense model, every token passes through the same FFN. The FFN is also where most of the parameters live; it dominates the parameter budget of large models.
MoE replaces that single FFN with a set of FFNs, each called an expert. Above them sits a small neural network called the router (or gating network), which looks at each incoming token and decides which experts should process it. The router is typically a single linear layer followed by a softmax, and its output is a probability distribution over the experts. 2 Formally, for an input token and a learned gating matrix , the router computes:
In practice, the router does not pick just one expert. It picks the top-K, where K is a small number, usually 1 or 2. Mixtral 8x7B uses 8 experts with top-2 routing, meaning each token is processed by exactly 2 experts, and the outputs are combined as a weighted sum based on the router’s scores. 1 DeepSeek’s V3 architecture pushes this much further with 256 routed experts plus 1 shared expert, with top-8 routing among the routed experts (the shared expert fires on every token). 3
The original idea goes back to Shazeer et al. in 2017, who introduced the sparsely-gated MoE layer for language modeling and machine translation. 4 The recent revival is what put MoE inside frontier-scale LLMs.
How a MoE forward pass works
The diagram below shows the routing pattern at a single transformer layer for a single token. The token comes in, the router scores all experts, the top-2 fire, and their outputs are combined.
Diagram by Neural Tech Daily.
The output of the layer is the weighted sum of the active experts’ outputs, weighted by the router’s softmax scores:
where is the -th expert and is the router’s score for that expert.
The mechanic is the load-bearing piece. The router is small and fast. The experts are big but only a few of them run. So the compute per token scales with active parameters, not total parameters. The model still benefits from the diversity of having eight different FFNs available, because different experts learn to specialise on different patterns during training.
The choice of K (how many experts fire) is a knob. Higher K means more compute per token but a richer combination of expert outputs. Lower K means cheaper but more brittle. Top-2 has become the practical default for inference-cost-sensitive deployments.
The math: total vs active params
This is the table that tells the whole story.
| Model | Total params | Active params per token | Active fraction |
|---|---|---|---|
| Mixtral 8x7B 1 | ~46.7B | ~12.9B | ~28% |
| Llama 4 Scout 6 | 109B | 17B | ~16% |
| Llama 4 Maverick 6 | 400B | 17B | ~4% |
| DeepSeek V3 3 | 671B | 37B | ~5.5% |
| Llama 3 70B (dense, for comparison) | 70B | 70B | 100% |
A dense Llama 3 70B and a Mixtral 8x7B both fit a roughly comparable hardware envelope, but Mixtral activates only about 13B parameters per token where Llama activates 70B. That is a roughly 5x reduction in compute at inference. Capability sits closer to a 30B-class dense model than a 13B one, because the 47B of total parameters all contribute during training and the router learns to dispatch tokens to the right specialists at run time.
Llama 4 Scout and Maverick, released by Meta in April 2025, push the envelope further at both ends. 6 Scout activates 17B parameters out of 109B total across 16 experts and fits a single H100 in fp8; Maverick activates the same 17B out of 400B total across 128 experts plus a shared expert, and targets multi-GPU serving. The active-parameter count is identical, but the latent capacity differs by almost 4x.
DeepSeek V3 takes the same idea further again. The 671B total / 37B active split means the model has the latent capacity of a frontier dense system but the inference compute of a mid-size model. This is why MoE has become the default architecture choice at frontier scale: it is the only known way to keep adding parameters without a linear blow-up in serving cost.
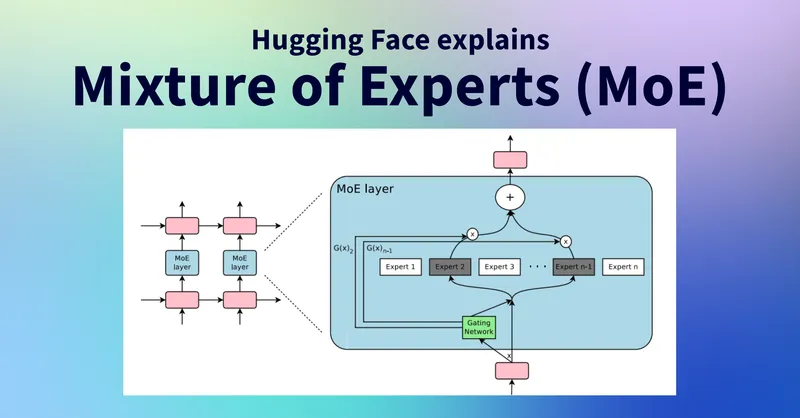
Image: Hugging Face — Mixture of Experts Explained, used for editorial coverage of the MoE inference-cost framing.
Why it matters for inference cost
Inference cost on rented GPUs has two pieces: compute and memory. MoE moves them in opposite directions.
Compute scales with active parameters, which means tokens-per-second on a given GPU is closer to a 13B dense model than a 47B one for Mixtral. Per-token cost on a managed inference API typically tracks active parameters, so the user-facing price comes down. For a dev team running its own inference on rented A100 or H100 GPUs, the wall-clock latency at batch size 1 is competitive with the smaller dense model. That is the headline win.
Memory scales with total parameters, which means VRAM requirements track the bigger number. Mixtral 8x7B needs roughly 90 GB in fp16 to load all experts, even though only 13B of that fires on any single token. 5 A single A100 80GB is not enough; you either need quantisation, an H100, or a multi-GPU split. That is the real cost the headline numbers do not foreground.
There is also routing overhead. 2 The router fires on every token and adds a small fixed cost. At small batch sizes this is negligible; at large batch sizes the load-balancing across experts becomes a real engineering problem, because a batch where all tokens want the same two experts will saturate those two and idle the other six.
What it doesn’t help with
MoE is an inference-side architecture. It does not magically make training cheaper, and it does not improve raw quality on tasks that the underlying experts are not specialised for. The frontier-scale MoE wins are mostly about serving economics at a given quality bar, not about a new capability axis.
A few specific things MoE does not solve:
- Quality on out-of-distribution inputs. If the router has not seen something like a token before, the routing decision is no better than picking experts at random.
- Cold-start latency. Loading 90 GB of weights takes roughly the same time as a comparable dense model — disk-to-VRAM bandwidth is the bottleneck, not architecture.
- Memory-bound serverless inference. If the GPU sits cold most of the time and pays for VRAM continuously, MoE’s compute savings do not offset the memory cost.
- Fine-tuning simplicity. MoE models are noticeably harder to fine-tune than dense models because the router and the experts can drift out of sync during gradient updates.
The economics depend on call patterns. High-throughput serving with consistent batch sizes is where MoE shines. Sporadic, low-utilisation workloads often run cheaper on a smaller dense model.
When to deploy a MoE model
For a team picking an open-weight model for production inference in mid-2026, the question is mostly about utilisation. MoE is the right call when batch sizes are reliably large enough to amortise the VRAM cost across many tokens per second. Mixtral 8x7B, Llama 4 Scout / Maverick, and DeepSeek V3 are the three obvious candidates, each fitting a different envelope. Hugging Face’s MoE explainer is the clearest single primer on the architecture and the trade-offs. 2
Llama 4 Scout fits where the VRAM budget is a single H100 (or two A100 80GBs in fp8) and the quality bar is mid-tier; its 17B active / 109B total split is the most accessible MoE option for teams without multi-GPU serving infrastructure. 6 Llama 4 Maverick targets the same active-parameter envelope but with frontier-class capacity, suitable for multi-GPU clusters where the 400B total parameter count can be sharded. DeepSeek V3 sits at the top of the open-weight quality bar, with the 671B total / 37B active split giving the latent capacity of a closed frontier model on a serving budget that, while still demanding, is well below dense-frontier-model costs. Mixtral 8x7B remains the well-understood baseline for teams wanting a smaller, more battle-tested option.
If your inference traffic is spiky, your batch sizes are small, or your VRAM envelope is constrained to a single A100 80GB, a dense 13B–30B model is usually the safer default. If you can afford the memory and the throughput justifies the load, MoE gives you frontier-class quality at mid-size compute cost.
What to test
Before committing to a MoE deployment, run two evaluations on your own traffic. First, benchmark wall-clock latency at your real batch size, not the idealised throughput numbers in vendor benchmarks. Routing-induced load imbalance shows up here, and the gap between ideal and observed throughput tells you how aggressively to scale. Second, measure per-correct-answer cost rather than per-token cost. MoE models often produce shorter, more confident outputs on tasks they specialise in, which can shift the cost-per-correct-answer numbers favourably even when raw token cost looks similar.
If both benchmarks land where the architecture promises, the savings are real. If either disappoints, fall back to the dense baseline.
Honest caveats
This article aggregates public model cards, the cited arXiv papers, and the Hugging Face MoE explainer; it does not include independent benchmarks of Mixtral 8x7B, Llama 4, or DeepSeek V3 on production cloud GPUs. The active-parameter and total-parameter figures cited above are taken from the model cards and arXiv papers; the per-token cost dynamics can vary substantially across inference engines (vLLM, TensorRT-LLM, llama.cpp). Verify on your own workload before committing to a deployment.
Architecture details for proprietary frontier models (GPT-4, Claude 3, Gemini) are not public, and any speculation about whether they use MoE belongs in a separate post.
How this article was made: an autonomous AI pipeline researched, drafted, fact-checked, and reviewed this piece, aggregating publicly-available information from the sources consulted below. AI (artificial intelligence) can make mistakes, so please cross-check the consulted sources before acting on anything here. Neural Tech Daily is not liable for decisions or outcomes based on this article.
Sources consulted
Cited Sources
- 1. Jiang et al. — Mixtral of Experts (arXiv:2401.04088); architecture details for Mixtral 8x7B with 8 experts, top-2 routing, ~46.7B total / ~12.9B active parameters per forward pass (accessed ) ↩
- 2. Hugging Face — Mixture of Experts Explained; covers gating-network design, top-K routing, load-balancing, and the dense-vs-MoE compute tradeoff in plain English (accessed ) ↩
- 3. DeepSeek-V3 model card on Hugging Face; documents 671B total / 37B active parameters, 256 routed experts plus 1 shared expert, with top-8 routing among the routed experts per MoE layer (accessed ) ↩
- 4. Shazeer et al. — Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer (arXiv:1701.06538); the original sparsely-gated MoE paper that established the modern routing pattern (accessed ) ↩
- 5. Mistral AI — Mixtral-8x7B-Instruct-v0.1 model card on Hugging Face; documents memory footprint, quantisation options, and serving guidance for the 8x7B sparse-MoE checkpoint (accessed ) ↩
- 6. Meta AI — The Llama 4 herd (release blog, 2025-04-05); documents Llama 4 Scout (17B active / 109B total, 16 experts) and Llama 4 Maverick (17B active / 400B total, 128 experts plus 1 shared expert); cross-reference Hugging Face's [Welcome Llama 4 Maverick & Scout](https://huggingface.co/blog/llama4-release) for serving guidance (accessed ) ↩
Further Reading
- DeepSeek — official site (model family overview) (accessed )
- Hugging Face — Welcome Llama 4 Maverick & Scout (accessed )
Anonymous · no cookies set